
Intel Meteor Lake’s NPU

AI is a hot topic and Intel doesn’t want to be left out, so their Meteor Lake mobile processor integrates a Neural Processing Unit (NPU). Intel internally refers to the NPU as “NPU 3720”, though I haven’t seen that name used in marketing materials. I’ll be covering that NPU as implemented in Intel’s Core Ultra 7 155H, in Asus’s Zenbook 14. The NPU 3720 uses a wide array of execution units running at a relatively low 1.16 GHz clock speed, and aims to handle machine learning with better power efficiency than other hardware.

This article will be relatively short because I don’t have time to fully investigate the NPU. Even a slightly unconventional CPU or GPU requires a lot of test writing and validation to understand, as well as plenty of research. Deep diving an NPU is a bit much for a free time, unpaid project.
High Level Organization
Intel’s NPU efforts are based off Movidius’s designs, which started as flexible digital signal processors (DSPs). Intel acquired Movidius in 20162, and added large arrays of multiply-accumulate (MAC) units to the platform. AI workloads do a lot of matrix multiplication, and MAC units are perfect for that. The NPU 3720’s MAC array is split across two Neural Compute Engine (NCE) tiles and can perform 4096 INT8 MACs per cycle. That works out to 9.5 TOPS at the NPU’s modest 1.16 GHz clock speed.

Like a GPU, the NPU works like a PCIe device and takes commands from the host. Instead of building a custom command processor, Intel uses Movidius’s 32-bit LEON microcontrollers. LEON use the SPARC instruction set and run a real time operating system. One of those cores, called “LeonRT”, initializes the NPU and processes host commands. Further down, “LeonNN” sends work to the NCE’s compute resources, acting as a low level hardware task scheduler. Both LEON cores use the SPARC instruction set and have their own caches. The NPU also uses Movidius’s SHAVE (Streaming Hybrid Architecture Vector Engine) DSPs, which sit alongside the MAC array. These DSP cores handle machine learning steps that can’t be mapped onto the MAC array.
Accelerator design is all about closely fitting hardware to particular tasks. That extends to the NPU’s memory hierarchy. Each NCE has 2 MB of software managed SRAM. Because they aren’t caches, the NPU doesn’t need to store tag or state arrays to track what’s in the cache. Accesses can directly pull data out of SRAM storage, without tag comparisons or address translation for virtual memory. But lack of cache places a heavier burden on Intel’s compiler and software, which has to explicitly move data into SRAM.

At the system level, the NPU sits on Meteor Lake’s Scalable Fabric alongside the chip’s iGPU and CPU cores. It shares the LPDDR5 memory subsystem with everything else on Meteor Lake. Like the iGPU and other devices, operating system drivers access the NPU as if it were a PCIe device.
Neural Compute Engine Architecture
An NCE tile’s MAC array is further divided into 512 MAC Processing Engines (MPEs), each capable of four INT8 multiply accumulate operations per cycle. FP16 MACs execute at half rate.

I couldn’t find much info on the SHAVE DSP cores, but I was able to get somewhere north of 50 FP32 GFLOPS via the OpenCLOn12 platform. The DPU can’t do FP32, so the test probably hit the SHAVE cores. Movidius’s 2011 SHAVE cores seem to have a single 128-bit vector datapath, which would be good for 37 GFLOPS at 1.16 GHz. Intel might have iterated on the SHAVE cores to boost their vector throughput. Still, the SHAVE cores aren’t supposed to do heavy lifting like the DPU. Instead, they support additional data types like FP32, as well as transcendental operations and data type conversion. However, data type support is still limited compared to a CPU or GPU. It can’t cope with FP64, which can be a surprisingly nasty issue.
LevelZeroCompilerInDriver: Failed to compile network. Error code: 2013265924. Failed to find FP64 for timestep
Intel OpenVINO, trying to compile Stable Diffusion’s UNET model for the NPU
I was able to get 1.35 TFLOPS of FP16 throughput by throwing MatMul operations through Intel’s NPU acceleration library. The NPU should be capable of 4.7 FP16 TFLOPS, so I’m not getting as close to theoretical as I would like. Small matrix sizes suffer because it takes time to get work started on the NPU. CPU cores have an advantage there because CPU vector units have negligible startup time and data is likely pre-loaded into cache. Large matrix sizes are better at showing off the NPU’s potential, though memory bandwidth limitations can show up there. But at those large matrix sizes, Meteor Lake’s iGPU can get pretty competitive even when handling FP32.

Performance takes a nose dive at 7168×7168. VTune showed very low memory bandwidth from the NPU but no other metrics. Maybe the NPU is optimized for smaller models, and runs into TLB misses if memory footprint gets too big. Or maybe, the NPU gets limited by DMA latency as data spills out of SRAM.

GPUs have plenty fused multiply-add units because graphics rendering also involves matrix multiplication. With a big power budget, fast caches, and lots of memory bandwidth, even older discrete GPUs like Nvidia’s GTX 1080 will beat up the NPU and take its lunch money.

Newer GPUs like AMD’s RX 6900XT are on a different planet. GPU performance scales well with process node shrinks and higher power budgets, so the 6900 XT can deliver massive matrix multiplication throughput even without tensor cores.
Memory Subsystem
The NPU enjoys relatively fast access to 128 KB of storage. At 16.02 ns, the NPU sees slightly less latency than RDNA 2’s scalar cache (17.8 ns), and lands between Nvidia Ampere and Ada Lovelace’s L1 cache latencies. I don’t know how the NPU handled the latency test, but I suspect it ran from the SHAVE DSPs.

Even though the latency test suggests there’s a cache, it doesn’t behave like a conventional cache. Varying the pointer chasing stride did not change the results until stride length exceeded 128 KB. If you think of it in cache terms, it has a single 128 KB line. If you want to go further, it’s both direct-mapped and fully associative. Achievement unlocked, I guess?

More likely we’re not looking at a cache. Instead, there’s probably 128 KB fast memory kept close to the load/store unit. Software handles misses and loads 128 KB of data to satisfy it. The 237 ns of latency at 512 KB is probably the NPU loading 128 KB from the NCE’s scratchpad memory at over 500 GB/s. DRAM latency is atrocious at nearly a microsecond. Intel’s datasheet suggests does address translation (MMU) right before requests flow out of the device.

OpenCL’s local memory maps better to the NPU’s scratchpad memory, since both are non-coherent, directly addressed memory spaces. Again the NPU sees excellent latency characteristics. CPUs have better latency of course, but the NPU is up there with recent GPUs.
Link Bandwidth
Like the iGPU, the NPU should enjoy fast access to the CPU’s memory space. Copying data to and from NPU memory doesn’t involve going over a PCIe bus. However, the NPU does far worse when transferring data with OpenCL’s clEnqueueWriteBuffer and clEnqueueReadBuffer commands.

Meteor Lake’s iGPU was able to exceed 19 GB/s when moving data from CPU to GPU memory spaces. The NPU could not break 10 GB/s. It either has a narrower connection to Meteor Lake’s Scalable Fabric, or has less capable DMA engines.
Stable Diffusion v1.5
Stable Diffusion generates images from text prompts. It starts from random noise, and iterates its way to a final image with UNET denoising steps. Running a lot of UNET steps can take a while even on powerful hardware, making it a good candidate for acceleration.

Getting Stable Diffusion working was a challenge. I tried to modify OpenVINO’s Stable Diffusion pipeline to compile models for the NPU. UNET failed to compile because it needed FP64. Furthermore, the VAE decoder model failed to compile because the NPU didn’t support a certain operator:
Cannot create ScaledDotProductAttention layer __module.vae.decoder.mid_block.attentions.0/aten::scaled_dot_product_attention/ScaledDotProductAttention id:111 from unsupported opset: opset13
Intel OpenVINO, trying to compile the VAE Decoder for the NPU
Then I tried to modify an ONNX Stable Diffusion pipeline to hit the NPU via DirectML. But the NPU is a special case. Of course that’s not straightforward either. Traditionally applications access DirectML by creating a DirectX12 device from a DXGI (DirectX Graphics Infrastructure) device. The NPU can’t render graphics or drive a display, so it’s not a DXGI device. StackOverflow posts on setting ONNX’s device_id didn’t help.
So I dug through ONNX source code, which indicated I had to set a device filter instead of a device ID. If course, the relevant code I was trying to hit was ifdef-ed out of existence, so I gave up after spending a couple more hours trying to build ONNX from source with the define set.

Eventually I came across Intel’s OpenVINO GIMP plugin, which does use Stable Diffusion. Intel’s GIMP plugin loads an opaque blob instead of compiling an off-the-shelf model. I’m guessing Intel internally built the blob, getting around any restrictions that would prevent it from working on the NPU. They also converted it to INT8, which makes sense because the NPU can execute INT8 at full rate. Stable Diffusion’s off-the-shelf model primarily uses FP32. Since I have no way to generate my own blobs, I can’t use Stable Diffusion’s newer 2.0 model. If I want to use the NPU, I’m stuck generating 512×512 images using the 1.5 version.
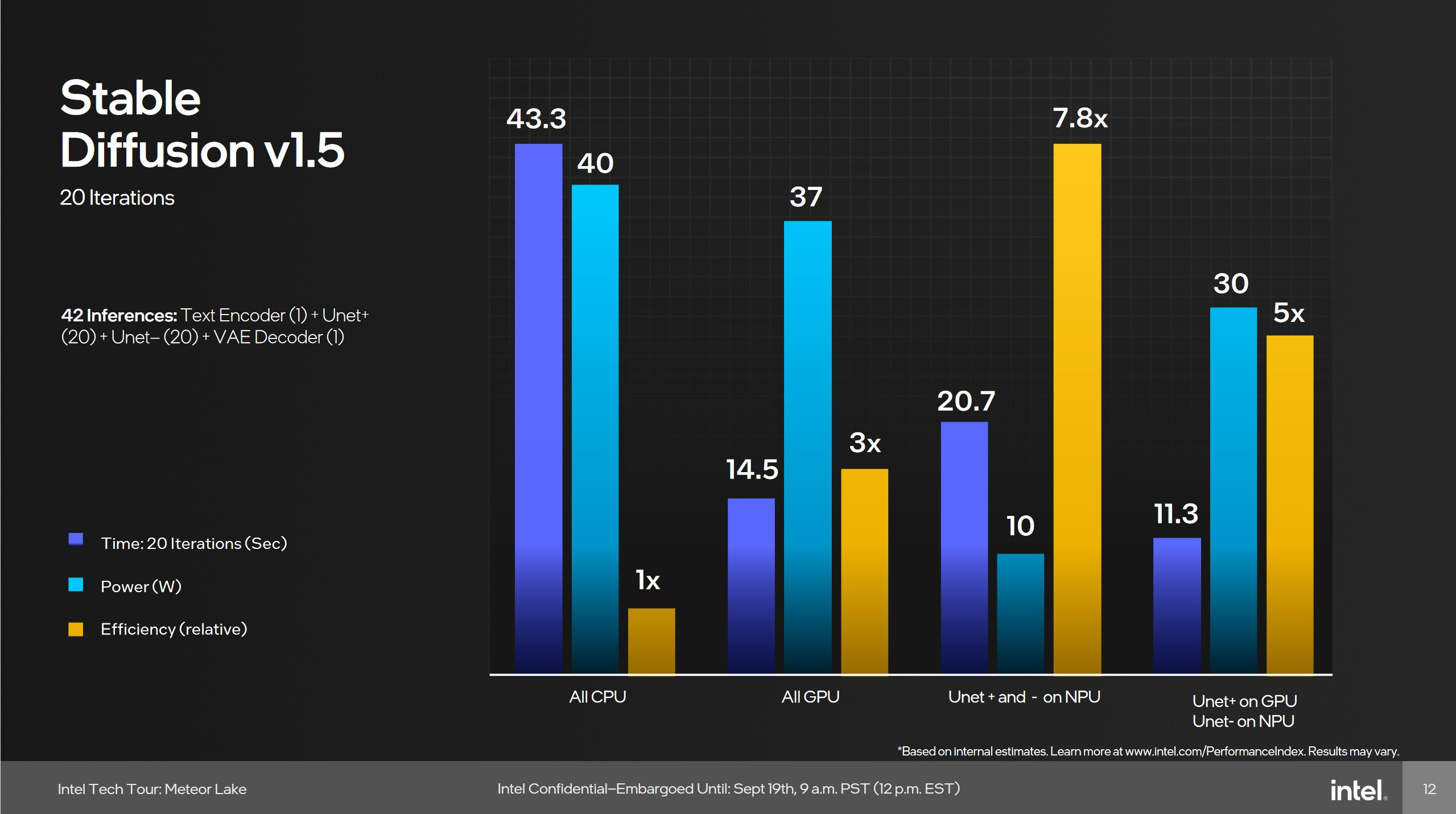
Stable Diffusion’s UNET step can be further broken into a UNET+ and UNET- step. The UNET- step applies to a negative prompt. Intel’s GIMP plugin by default runs the UNET+ on the NPU and UNET- on the iGPU. I edited the code to run both steps on the NPU, and both steps on the iGPU as well. For comparison, I used Olive+DirectML to run the stock Stable Diffusion 1.5 model on both Meteor Lake’s iGPU and a discrete GPU.

Meteor Lake’s iGPU has no problem beating the NPU, as Intel’s slide suggests. My “All GPU” result of 1.38 iterations per second aligns very closely with Intel’s 20 iterations over 14.5 seconds, or 1.379 iterations per second. The iGPU has a noticeable 62% performance advantage over the NPU, even while chugging a full-fat FP32 model. If I level the playing field by handing Intel’s INT8 model to the iGPU, its lead extends to a massive 261%. Finally, a discrete GPU like AMD’s RX 6900 XT is 6.7 times faster even when using FP32.
Final Words
Engineers have been designing accelerators as long as computing existed. Hardware that closely fits certain tasks can get you better performance or lower power consumption. Meteor Lake’s NPU aims to do that for machine learning workloads. It focuses on INT8 and FP16, only makes a token effort for FP32, and doesn’t even try for FP64. Its memory subsystem is simplified, taking advantage of predictable data movement in machine learning workloads. Stepping back, the Meteor Lake NPU shows the value of Intel’s past acquisitions. It also showcases Meteor Lake’s Scalable Fabric, which lets Intel host accelerators with more flexibility than the prior Sandy Bridge style system architecture.

But the NPU has shortcomings. Accelerators inherently have less flexibility than general purpose designs. No one expects an NPU to handle general purpose compute, but the NPU 3720’s limited data type support can prevent it from running certain ML models. Custom accelerator designs need a software ecosystem built around them. Running Stable Diffusion on the NPU was a frustrating and limited experience. The average consumer in 2024 might be comfortable using several programming languages and working their way through open source code to use an accelerator. But they’ll have to work from off-the-shelf models, not pull an opaque blob out of thin air. Perhaps the NPU works better in other situations. I intend to investigate that eventually when I have spare time and excess sanity.

For models that work, the NPU provides lower power consumption but not necessarily better performance. Meteor Lake reports power for the CPU cores, iGPU, and System Agent. The NPU is part of the System Agent, and power for that block rarely exceeded 7W under an NPU workload. In contrast, iGPU power could reach 20W. But in exchange, the iGPU provides performance and flexibility the NPU can’t match. If you don’t need to run machine learning workloads on the go, a discrete GPU provides an order of magnitude higher performance. Certainly an NPU might be useful in specific circumstances, but the “AI PC” label feels out of touch.
Think of an AI PC as a supercharged personal computer, tailor-made with the right hardware and software to handle AI…
ZDNET article titled “What is an AI PC?”
Any PC with a midrange discrete GPU can handle AI as long as you don’t run out of video memory. GPUs already have the right software to handle AI. In fact, they can run a wider variety of models than the NPU without requiring special effort. I can use Stable Diffusion’s newer 2.0 model to generate higher resolution 768×768 images with GPU acceleration, and it’s still faster than using the NPU to generate 512×512 images with a mystery INT8 blob. From my perspective, any enthusiast gaming desktop is already an “AI PC”. And I’d be fine with calling the Asus Zenbook 14 an “AI PC” with or without the NPU.

Meteor Lake’s NPU is a fascinating accelerator. But its has narrow use cases and benefits. If I used AI day to day, I would run off-the-shelf models on the iGPU and enjoy better performance while spending less time getting the damn thing running. It probably makes sense when trying to stretch battery life, but I find myself almost never running off battery power. Even economy class plane seats have power outlets these days. Hopefully Intel will iterate on both hardware and software to expand NPU use cases going forward. GPU compute evolved over the past 15 years to reach a reasonably usable state today. There’s something magical about seeing work offloaded to a low power block, and I hope the same evolution happens with NPUs.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.
References
Intel Core Ultra Processors (PS Series) Datasheet
Thank you for the write up
very good article! 👍