
Graviton 3: First Impressions


In late May of 2022, AWS released Graviton 3 to the general public. Graviton 3 was the first ARM CPU to introduce the SVE instruction set to a widely accessible server CPU.
Before Graviton 3’s general availability, Neoverse N1 dominated the ARM server landscape. AWS’s previous flagship offering, Graviton 2, implements 64 Neoverse N1 cores at 2.5 GHz. Microsoft’s Azure and Oracle’s OCI both use Ampere Altra, which puts 80 Neoverse N1 cores on mesh and clocks them at 3 GHz. We’ll therefore draw comparisons between Graviton 3 and Neoverse N1. We’ll supplement that with data on AMD’s Zen 3 and Intel’s Ice Lake SP (Sunny Cove). As of mid 2022, those are the newest widely deployed x86 chips used in cloud environments and will therefore be Graviton 3’s most immediate competitors.
TheNextPlatform makes a convincing argument that Graviton 3 is based off a modified Neoverse V1 core.
Branch Prediction: A Huge Step Forward
Compared to N1, ARM has dramatically improved the branch predictor and makes large strides in both speed and accuracy. A quick glance at Graviton 3’s pattern recognition capabilities makes it clear that it’s a completely different class from N1.

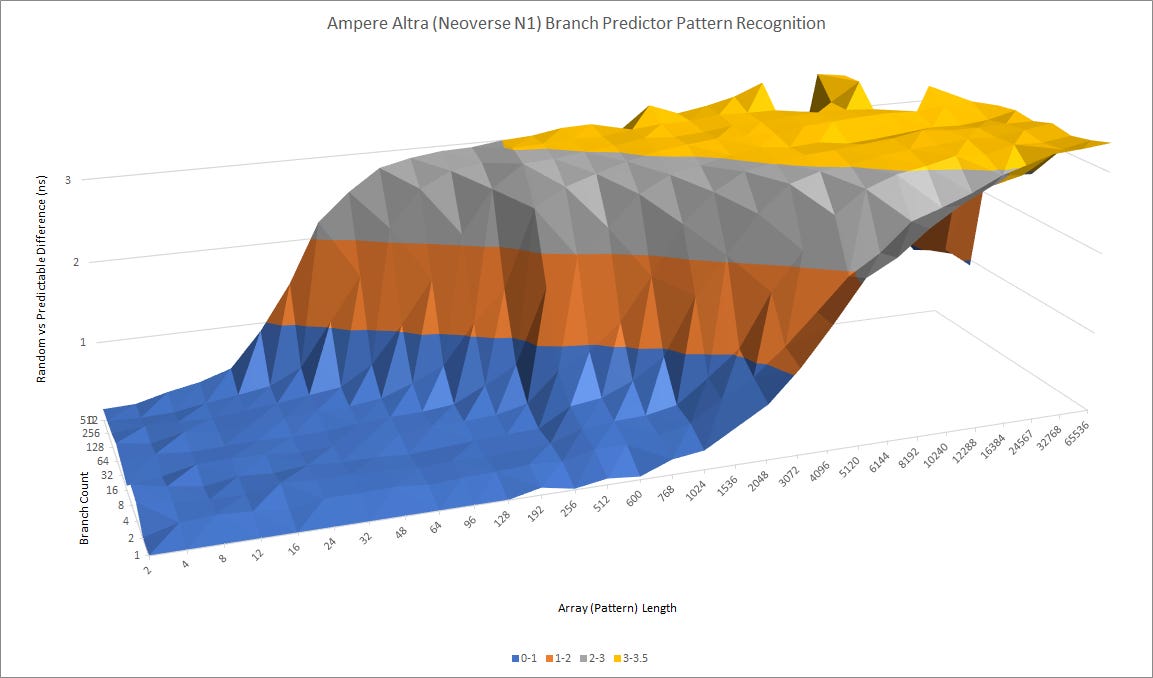
In the cloud market, Graviton 3’s primary x86 competition will be Intel’s Ice Lake SP and AMD’s Zen 3 based Milan. Zen 3 seems to use an overriding predictor with an incredibly capable but slightly slower second level, while Ice Lake’s takes a very similar approach to Graviton 3. Both Intel and ARM appear to use a single level predictor that can recognize very long patterns, though not to the same extent as AMD.

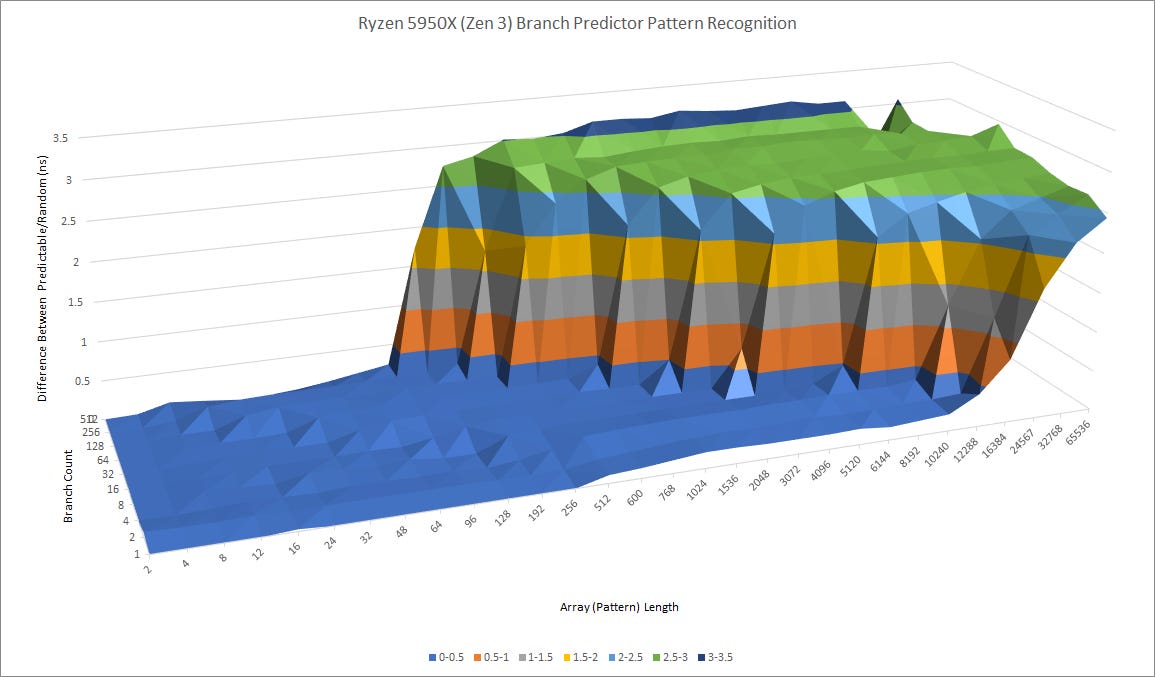
When a lot of branches are in play, Ice Lake holds a small advantage over Graviton 3. Graviton 3 can recognize patterns up to 16 long with 512 branches, while Ice Lake can handle patterns twice as long at the same branch count. Again, AMD seems to have a ton of branch history storage, as its able to handle patterns up to 96 long with 512 branches.

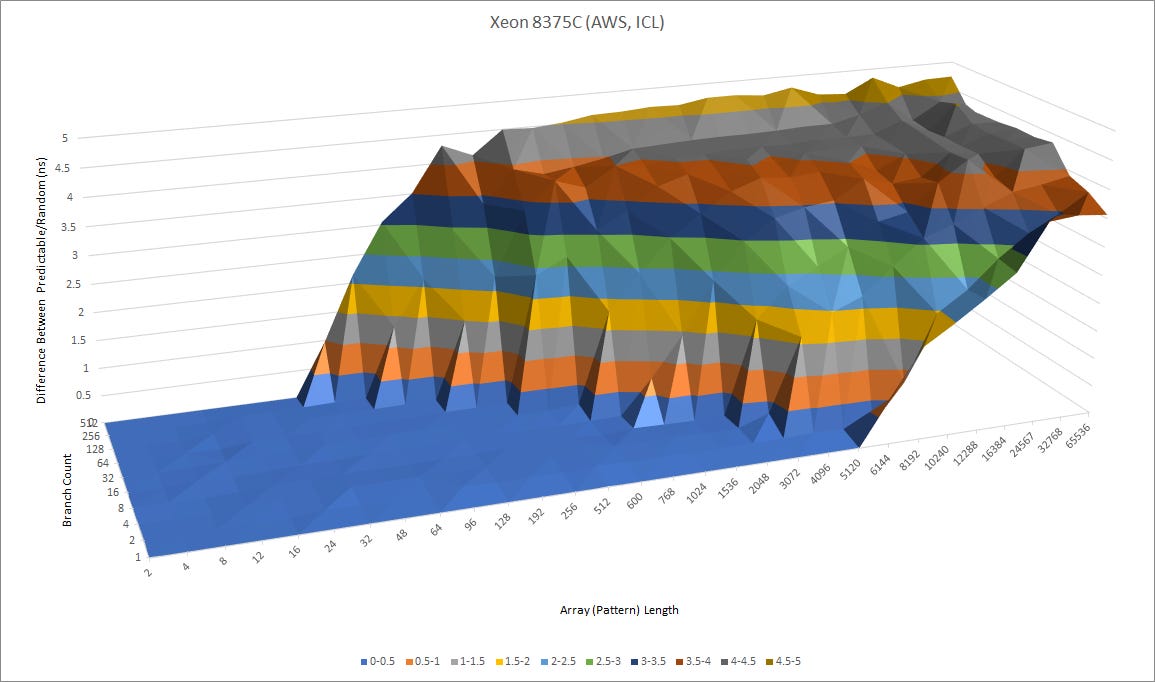
Graviton 3 also has an impressively fast BTB (branch target buffer) setup, letting it handle taken branches with very little penalty. A micro-BTB allows the core to handle two taken branches per cycle, a capability that we’ve only seen on Golden Cove and Rocket Lake so far. But Graviton 3’s micro-BTB capacity is bigger than the equivalent on those Intel CPUs. Golden Cove can only track 32 branches and handle them at two per cycle, while Rocket Lake can do so with eight.

ARM has also equipped Graviton 3 with a very large main BTB that probably has 4K entries, and a L2 BTB that could have up to 10K entries. The main BTB provides zero-bubble taken branch capability that exceeds Zen 3’s. Even hitting the L2 BTB is not very expensive, with just one or two pipeline bubbles per branch with 10K branches in play. So far, we’ve only seen Golden Cove implement a bigger BTB.

All in all, Graviton 3 has a branch predictor that’s comparable to the best from Intel and AMD. Each CPU manufacturer makes different tradeoffs, and each branch predictor has its unique advantages, but Graviton 3’s predictor shows ARM’s determination to compete with the best around. It’s a huge step away from the mediocre implementation in Neoverse N1 and should go a long way to making the most out of Graviton 3’s increased reordering capacity.
Frontend: A Familiar Pattern, with Tricks
Graviton 2 and 3 both feature a four-wide decoder, but the difference ends there. Behind the decoder, ARM has implemented a large micro-op cache with 3K entries. Graviton 3’s frontend therefore shows a passing resemblance to those of Intel and AMD.

Compared to Neoverse N1, Graviton 3’s decoders are far more capable. They’re capable of fusing a variety of instruction pairs. This includes x86-style jump fusion, where a flag-setting instruction and adjacent conditional jump can be fused into a single micro-op. To make our lives difficult, Graviton 3 also implements CNS-style NOP fusion. Pairs of NOPs can be fused into a single micro-op in the frontend. Because Graviton 3 has micro-op cache capable of caching fused micro-ops, NOPs will execute at 12 per cycle.

To get around this, we filled the test array with instructions that simply set a register to zero. These can’t be fused the same way NOPs can, but can pass through the renamer at 6 per cycle and are eliminated there.
In terms of instruction fetch bandwidth, Graviton 3 shows similar characteristics to Zen 3. Both have large micro-op caches, and both can sustain 6 IPC. Beyond L2, Zen 3 has a substantial advantage, because AMD’s architecture prioritizes L3 performance instead of trying to create single unified cache across the chip. Compared to its predecessor on the cloud scene, Neoverse N1, Graviton 3 enjoys increased instruction bandwidth thanks to its micro-op cache. Fetch bandwidth from L1D seems to be equal as both architectures (actually all architectures in this comparison) use 4-wide decoders. But further down the cache hierarchy, Graviton 3 enjoys far better instruction bandwidth.

ARM has likely given Graviton 3 deeper fetch queues, letting the core use its large BTB to aggressively prefetch instructions. That’s complemented by Graviton 3’s superior L3 implementation, which provides lower latency compared to Ampere Altra and Graviton 2. Fetch bandwidth for very large instruction footprints still isn’t comparable to that of Intel’s Ice Lake SP or AMD’s Milan, but ARM is definitely making progress.
We’ve also seen various sources state that Neoverse V1 has a 5-wide instruction decoder. If Graviton 3 is based off V1, the decoder seems to have been cut down to 4-wide. Once we leave the 3K entry micro-op cache, we don’t see more than 4 instructions per cycle even when the test loop fits within the 64 KB L1 instruction cache. The same test instructions can exceed 4-per-cycle throughput when running from the micro-op cache, pointing to a fetch and decode bandwidth throughput limitation, rather than a pipeline bottleneck further on.
Graviton 3’s Renamer: Emerging Capabilities
Graviton 3’s renamer appears to be 6 wide, letting the core match Zen 3 in overall width. In terms of renamer optimizations, Graviton 3 makes improvements over Neoverse N1. But being a CPU maker is hard, because your competitors are always improving too. AMD introduced extremely capable move elimination with Zen, while Intel did the same with Sunny Cove. Both of those x86 CPUs can eliminate register to register move instructions at a rate matching the renamer’s width.

Graviton 3 cannot do the same. MOVs are clearly not eliminated, because throughput appears limited by ALU port count. Like Neoverse N1, Graviton 3 can sometimes break dependencies between register to register MOVs, but has very limited capabilities in that area.
The rename stage can also break dependencies and/or eliminate instructions that set a register to zero regardless of its previous value. From what we can tell, only move-zero-to-register instructions are completely eliminated, and achieve a throughput equal to the renamer’s width. Graviton 3 has an advantage over Ice Lake in this regard, as Intel’s renamer can break dependencies when zeroing idioms are detected, but cannot eliminate them. Zen 3 has equivalent capability – it can recognize common x86 zeroing idoms and eliminate them.
Out of Order Structure Sizes
We’re still busy picking apart AWS’s new cloud CPU. In this preview, we’re going to present some raw test results and plausible explanations, since the results are not always straight forward.
Let’s start with the reorder buffer size. The size of this structure corresponds to how many micro-ops the CPU’s execution engine can track. Normally we’d test this with NOPs, but Graviton 3’s NOP fusion capability complicates result interpretation. A test with NOPs suggests that Graviton 3’s ROB has 512 entries. But the ROB’s actual capacity could be 256 entries, if each entry is storing a fused micro-op that represents two NOPs.

So, we ran an additional test that alternates between integer and FP instructions. Reordering capacity with this test exceeds 256 entries, suggesting that Graviton 3 indeed has 512 ROB entries, and fused NOPs are un-fused after they pass the renamer. If this interpretation is correct, ARM has given Graviton 3 an out of order window larger than that of Zen 3 and Ice Lake.
As we move on to reverse engineering register file sizes, another quirk shows up. Graviton 3 seems to have 125 vector registers that are 256-bit wide, but can use a single vector register to track two scalar FP registers. Strangely, it doesn’t seem capable of using a single 256-bit SVE register to track two 128-bit NEON registers.

Another strange observation is that Graviton 3’s register files are more appropriately sized for a 256 entry ROB, if we exclude the core’s huge renaming capacity for scalar floating point registers.
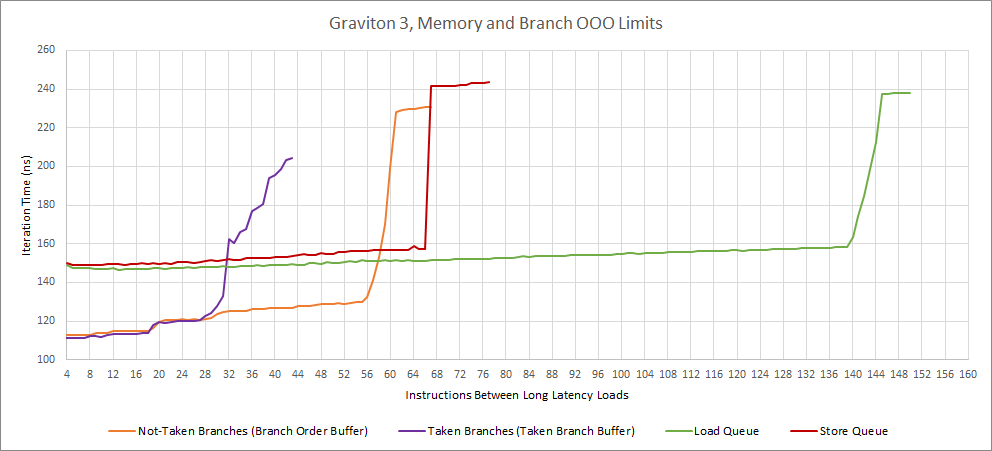
Graviton 3’s load queue capacity also stands out. Other structure sizes remain modest and roughly in line with what we see on Zen 2 and Zen 3.
Scheduler Layout
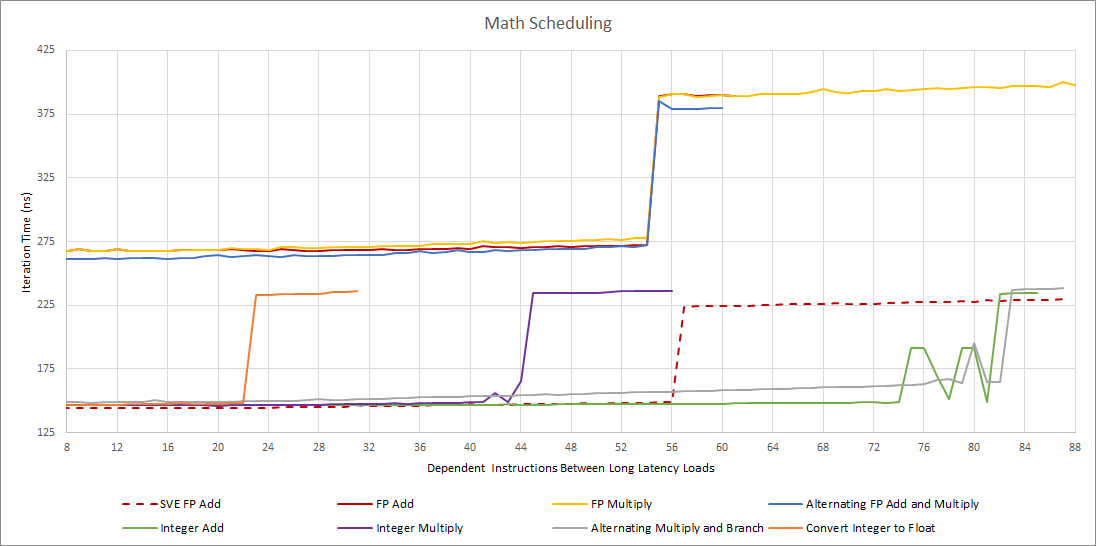
Reverse engineering a distributed scheduler layout is very difficult, time consuming, and error prone. It’s why this is a preview rather than a proper deep dive. Instead of testing a ton of instruction types and combinations to come up with a mostly plausible scheduler layout, we’ll present approximate measured scheduler capacities for a few instruction types.

Graviton 3 has plenty of scheduler entries to go around for common operations. While we still aren’t certain about exactly how the scheduler is laid out, it’s clear that Graviton 3 is a big jump over Neoverse N1. At first glance, it seems roughly comparable to Zen 3 and Ice Lake, at least in terms of scheduler entries available for common operations.
Here’s one plausible layout for Graviton 3’s scheduler:

Execution Units
Graviton 3’s execution units are reasonably powerful and in line with what we expect from a high performance core. There are four integer ALUs compared to Neoverse N1’s three, and three memory pipelines versus Neoverse N1’s two. Graviton 3’s floating point and vector execution side gets the biggest upgrade, and feels like a doubling of Neoverse N1’s vector/FP execution resources with a large unified scheduler. 256-bit SVE floating point adds and multiplies can each execute at up to two per clock, giving Graviton 3 comparable floating point throughput to x86 cores with AVX support.
Graviton 3 also inherits Neoverse N1’s vector and floating point execution latencies, except for slightly dropping integer multiply latency.

Two cycle floating point addition latency is very impressive, and matches Intel’s Golden Cove. Of course, that’s a lot easier to achieve for ARM, since Graviton 3 runs at very low clocks. FP multiplication latency is roughly comparable with that of other server CPUs, and nothing really stands out. Vector integer execution latency is fine as well, if a bit higher than Zen 3 and probably higher than what it should be given Graviton 3’s low clock speed.
In terms of execution throughput, Graviton 3 probably has four 128-bit vector/FP pipes, since it’s able to do more than one SVE instruction per cycle for all of the operations (FP add, FP multiply, integer add) we tested. Theoretically, this would let Graviton 3 achieve impressive throughput for NEON and scalar FP operations, but we weren’t able to exceed three instruction per cycle throughput for NEON FP add/multiply and integer adds. This could be explained by a register file bandwidth limitation, in terms of inputs per cycle needed.

Still, more testing has to be done to verify this.
Cache and Memory Access
Latency
Graviton 3 retains a 4 cycle, 64 KB L1D. However, ARM has improved latency throughout the cache hierarchy. L2 capacity has stayed the same, while latency drops by two cycles. L3 latency was horrible on Ampere Altra, and it’s thankfully much better with Graviton 3.
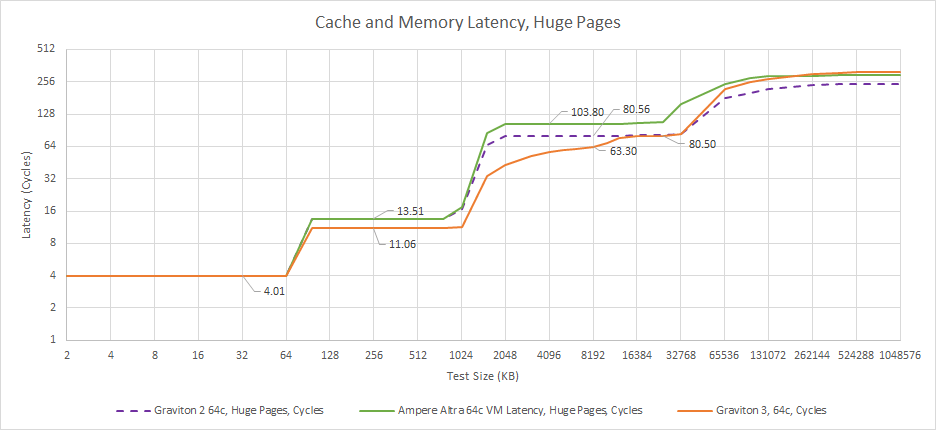
Graviton 2 and Ampere Altra use the same core with identical L2 implementations. The two designs mostly differ in the L3, where Graviton 2 achieves slightly less terrible latency, probably thanks to a smaller mesh. If we plot latencies in actual time, Graviton 3’s lowered cycle counts are somewhat countered by Ampere Altra’s higher clocks.
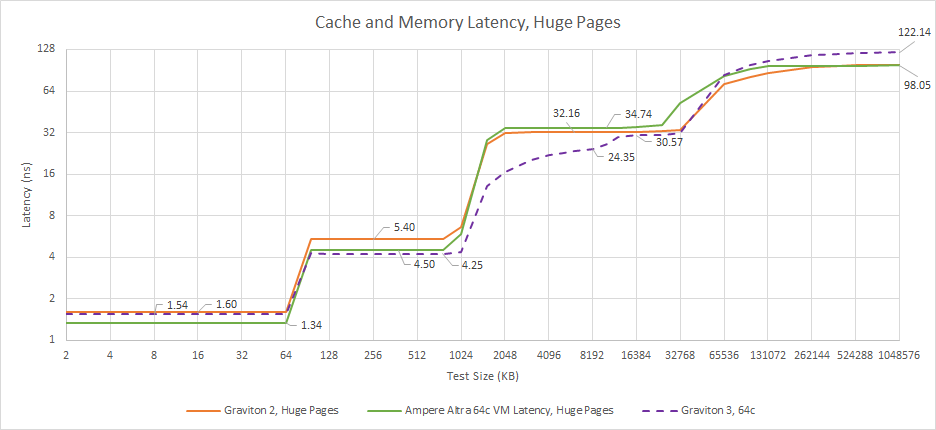
Out in memory, Graviton 3 noticeably regress in latency compared to Ampere Altra and Graviton 2. That’s likely due to DDR5, which has worse latency characteristics than DDR4. Graviton 3 also places memory controllers on separate IO chiplets, as detailed by SemiAnalysis, which could exacerbate DDR5’s latency issues.
Ice Lake and Graviton 3 take roughly parallel caching strategies. Both implement a chip-wide unified L3. And both give their cores large private L2 caches to insulate them from L3 latency. AMD takes a different approach, giving up a chip-wide cache in favor of giving each core cluster a very fast L3.

The x86 competitors also use architectures that are multi-purpose at heart. Sunny Cove (used in Ice Lake) and Zen 3 serve double duty in client platforms, where they can reach clock speeds well over 4 GHz to maximize thread-limited performance. This design characteristic surfaces in the cloud too, where Milan-based Epyc and Ice Lake Xeons clock significantly higher than Graviton 3. We therefore see a huge difference when looking at latency in actual time, instead of clock cycles.

Zen 3 and Ice Lake both have smaller, faster L1 caches. At L2, the pattern repeats. Ice Lake’s higher latency in cycle counts is completely reversed by its higher clocks, letting it edge out Graviton 3. Intel and ARM’s mesh based L3 are roughly comparable, depending on where in the latency plot you look. Again, AMD opts for a very fast, non-unified L3.
DDR5’s latency regression shows up again as we look at larger test sizes. Intel uses DDR4 controllers on a monolithic die, achieving very low memory latency for a server chip. AMD’s Epyc uses chiplets, and is thus a very interesting comparison to Graviton 3. Despite both incurring a cross-chiplet penalty, AMD’s memory access latency is approximately 10 ns lower than Graviton 3’s. I’m chalking up that difference to DDR5.
Bandwidth
With core counts matched, Graviton 3’s caches turn in a reasonable performance, providing bandwidth improvements across the board compared to Ampere Altra. If SVE comes into play, Graviton 3’s L1 and L2 cache bandwidth goes miles above Neoverse N1’s.

But it’s not that impressive compared to its x86 competitors. Thanks to high clocks and similarly wide vector width, Zen 3’s caches pull well ahead of Graviton’s. Ice Lake takes this further with even higher clocks and twice the vector width, giving it unmatched per-core L1D bandwidth. Intel’s server architecture also has a wide 64 byte/cycle path to L2. Using 256-bit SVE load instructions can close the gap a bit, but there’s no getting around low clocks.
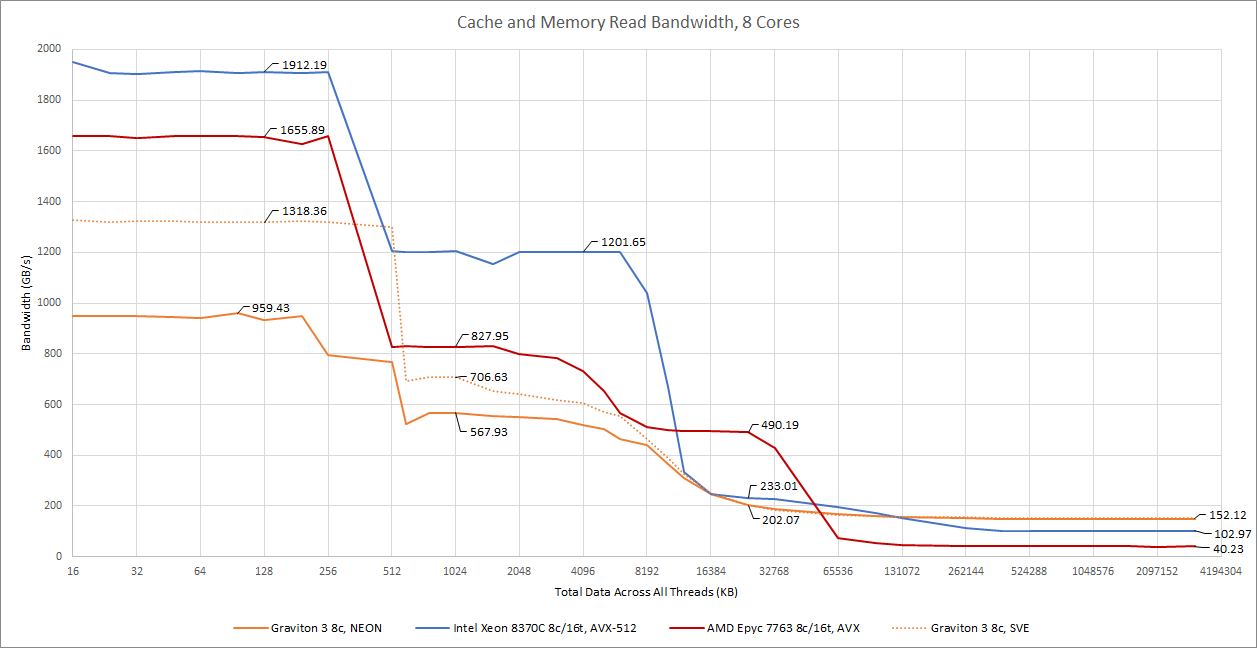
DDR5 didn’t do well in our memory latency tests, but its advantage really shows with bandwidth tests. Graviton 3 has a large memory bandwidth lead over its x86 competitors.
We don’t have much data for whole server chips, mostly because we’re not a large tech site that can easily get our hands on server stuff. But here’s a comparison with the data we have:

As expected, Graviton 3 has a massive advantage over Neoverse N1. Compared to Epyc with V-Cache, it’s ahead in L1, L2, and memory bandwidth. However, AMD’s huge, fast L3 still gives it a lead for certain test sizes.
Initial Thoughts
SVE Support
Graviton 3 is notable because it’s the first 64-bit ARM server CPU for general purpose use with SVE support. Fujitsu’s A64FX came first, but that was a chip specifically designed for supercomputers, and not for general purpose use. We’ve also seen SVE2 support on a few recently released high end cell phones, but not on other server chips.
In the near future, that’s likely to be a limited advantage. There’s practically no software out there with SVE support. GCC will flat out refuse to emit SVE instructions (at least in our limited experience), even if you use assembly, so we used Clang to assemble our test code. And in the next few years, uptake is likely to be slow. SVE market penetration is nowhere near that of AVX(2), making SVE’s situation reminiscent of AVX-512’s when Skylake-X came out in 2017.
So Graviton 3 will have to wait for a few years before we can tell if SVE gives it a notable advantage. But there are problems with that too. SVE2 is already out, and if software uses instructions in SVE2 that aren’t present in SVE, Graviton 3 will be left behind.
Against the Competition
AWS’s Graviton 3 uses a much beefier core architecture than Neoverse N1. N1 is the current mainstay of ARM server offerings, which means Graviton 3 is the highest performing, widely available ARM CPU in the cloud. And it’s likely to stay in that spot for the next few years.
Against its x86 competition, Graviton 3’s per core performance is likely to be a lot closer to that of Zen 3 and Ice Lake than N1 was. With respect to branch prediction, reordering capacity, execution resources, and core width, ARM’s V1 microarchitecture (assuming that’s what Graviton 3 is based off) is in the same ballpark as Intel and AMD’s current server offerings. But I don’t expect Graviton 3 to match AMD and Intel. There’s a huge clock speed difference between Graviton 3 and its x86 competitors, and it’s not like V1 is bigger and beefier.
From Amazon’s Perspective
The design seems to be very narrowly targeted at maximizing compute density in the cloud. To that end, AWS has chosen very conservative core clocks. At 2.6 GHz, Graviton 3 clocks a mere 100 MHz over its predecessor, Graviton 2, without increasing per-chip core count. Graviton 3 therefore gets almost all of its performance advantage from performance-per-clock gains.
Amazon has thus chosen to use TSMC’s cutting edge 5 nm process to reduce power consumption. TSMC’s 7 nm process already did wonders for low power designs, and 5 nm would take this even further. While Graviton 3 is a beefier core than N1, it’s nowhere near as ambitious as Intel’s Golden Cove, and should still be considered a moderate design. Such a core running at 2.6 GHz on 5 nm should absolutely sip power. That in turn lets AWS pack three of these chips into a single node, increasing compute density. The final result is a chip that lets AWS sell each Graviton 3 core at a lower price, while still delivering a significant performance boost over their previous Graviton 2 chip.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.