
Neoverse N1 vs Zen 2: ARM in Practice

Previously, we looked at ARM and x86 and concluded high performance designs wouldn’t get a significant advantage by using either instruction set. That article focused narrowly on the respective ISAs, and assumed equal ecosystem and implementation goals. Today, we’ll look at ARM and x86 in practice – specifically Neoverse N1 with a quad core Ampere Altra cloud instance, and Zen 2 in the 3950X with SMT turned off and four cores enabled.
For this review, we need to constantly be aware that Zen 2 and N1 have different implementation goals. Like Neoverse N1, Zen 2 was announced in 2019 and uses TSMC’s 7 nm process. They overlap in the server and datacenter role, but similarities end there. Neoverse N1 is closely related to Cortex A76, which saw use in several cell phone SoCs. In contrast, Zen 2 targets everything from laptops to desktops to servers and supercomputers which means that Zen 2 is deeper, wider, and clocks higher than N1 and because Zen 2 is designed to hit higher performance levels than N1, we’re going to focus more on whether the respective cores are performing as they should, rather than who wins in absolute terms.
Public Key Crypto
To start, we’ll do some RSA2048 asymmetric crypto benchmarks with OpenSSL. This integer heavy workload is particularly applicable to web servers. Signs/s here is as an upper bound to how many HTTPS connections per second the CPU can handle. At lower CPS, public key crypto can still consume quite a bit of CPU time, so a higher score is important because it leaves more CPU cycles free for other request processing logic.
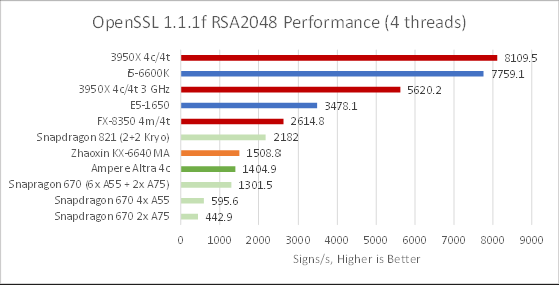
Ampere Altra’s N1 cores perform poorly. Zen 2 is over four times faster at 3 GHz, or over five times faster when boosting. Cloudflare mentions the ARM instruction set is less efficient because it lacks an instruction for 64-bit multiplication, and x86 has special instructions that can do two add-with-carry operations per cycle. But clearly this can be worked around: a 5 year old Snapdragon 821 outperforms Altra by 55% despite running at lower clocks.
Furthermore, Sandy Bridge doesn’t support ADCX/ADOX but still turns in a reasonable performance, albeit with its three integer pipes running near full tilt – performance counters showed them busy over 70% of the time. Neoverse N1 has three ALU pipes, but can’t match the a CPU with two ALUs (the FX-8350) in performance per clock. This looks like an architectural deficiency in Neoverse N1 that we hope ARM will address.
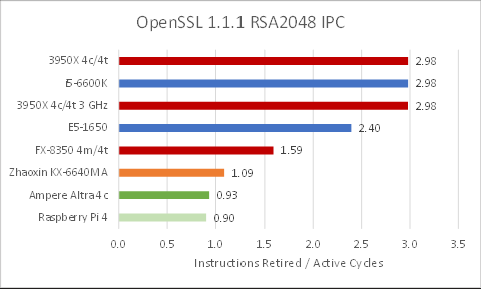
Neoverse’s low IPC shows it’s not crunching through a ton of extra instructions. N1 simply isn’t able to bring the power of its three integer pipes to bear for this task. ARM Ltd has quite some room for improvement here.
File Compression
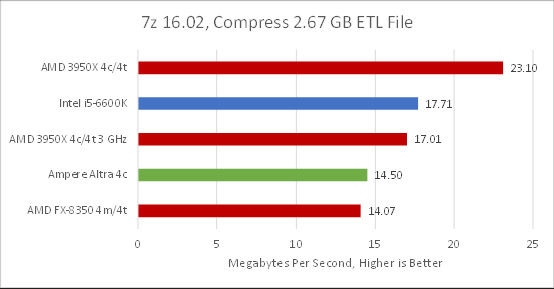
At default settings, 7z emphasizes compression efficiency over speed, making it very compute heavy. Zen 2 pulls ahead by almost 60% when it’s allowed to boost, showcasing AMD’s high performance design. At matched clocks, Zen 2 pulls ahead of Neoverse N1 by 17.3%. In terms of performance per clock, that puts N1 about a generation behind Zen 2. That’s a reasonable result for N1 considering its design goals.
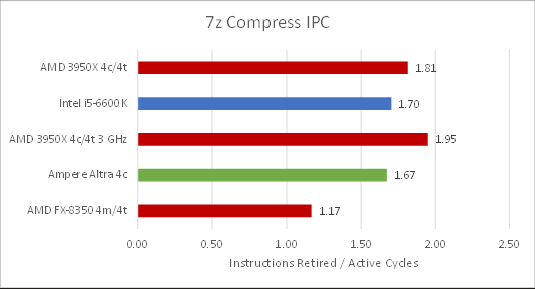
Zen 2’s IPC increases by 7.7% at lower clocks, which suggests 7z hits memory a lot (memory latency and bandwidth don’t scale with increased clock speed). Neoverse N1’s performance per clock is neck and neck with Skylake’s, probably because the i5-6600K’s smaller L3 suffers more misses.
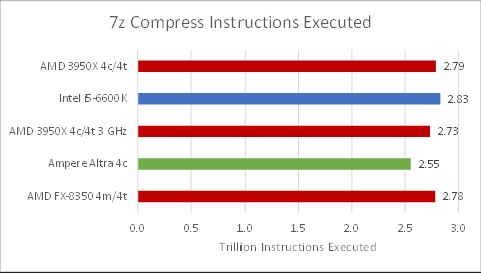
The x86 based chips here executed more instructions. Maybe that’s WSL overhead in translating Linux system calls to Windows ones. Or maybe sampling performance counters every second on x86 introduced more overhead than whatever perf stat did on ARM. In any case it’s not a big difference and IPC values are roughly comparable.
Code Compilation
Compilation performance can be very important for developers working on large projects, which can take hours to compile. Here, we’re compiling Gem5, a CPU simulator for microarchitecture research.
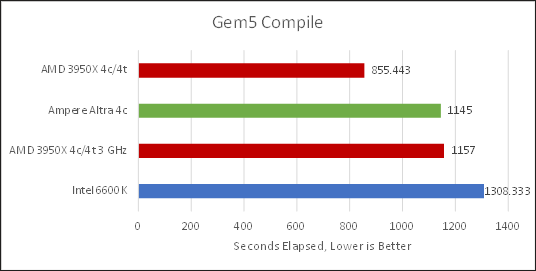
Neoverse N1 turns in an excellent performance, leading Zen 2 by 1% when clocks are matched. That’s impressive considering N1’s smaller core design. Zen 2 of course pulls ahead when it’s allowed to run at full tilt, but that only makes it finish the job 25.2% faster – certainly a noticeable difference, but nowhere near as big as we’ve seen elsewhere. Meanwhile, Skylake suffers an unexpected loss.
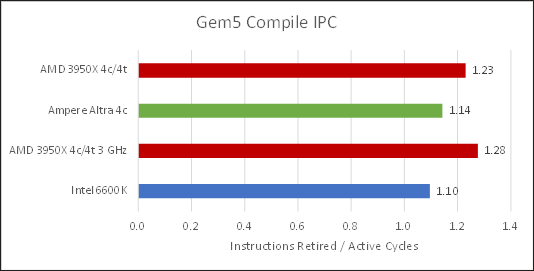
Like 7z, lower IPC at higher clocks suggests a lot of cache misses. IPC is also a bit low across all processors here. We didn’t dig further because of time constraints, but usually low IPC means cache and memory access are bigger factors than core throughput.
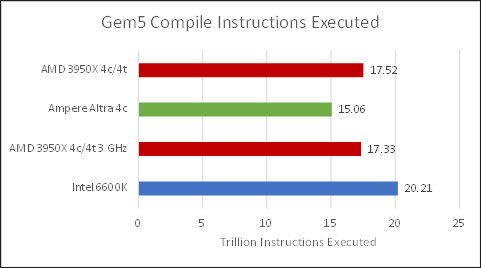
The x86 chips executed more instructions during the compile test, and by a bigger margin than we saw with 7z file compression. I wonder if the compiler is going down different optimization paths depending on the architecture it’s being compiled on, since the difference between Zen 2 and Skylake’s instruction counts is too big to be measurement error.
Video Encoding: libx264
H.264 may be an aging video standard, but it enjoys widespread support unlike newer, more efficient standards. Even a remotely modern video card or mobile device has hardware accelerated H.264 decode for smooth playback at low power and minimal CPU usage. More importantly, the libx264 encoder’s age means it’s very mature and features hand optimized assembly code for 64-bit ARM, or aarch64.
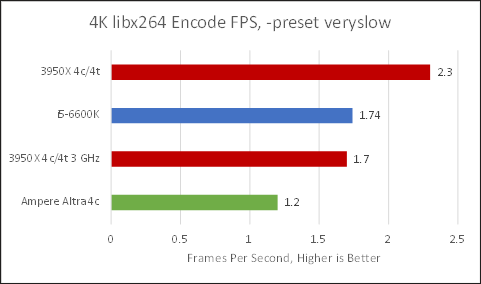
Neoverse N1 isn’t the best choice for downsizing your gaming recordings or compressing video clips for Discord upload. Zen 2 at matched clocks is 41.6% faster, or 91.6% faster when boosting. Interestingly, the output files for ARM and x86 did not match. The one generated by ARM was a touch larger and had imperceptibly worse quality (SSIM = 0.985163 for ARM and 0.985166 for x86) despite -crf 25 getting passed to both. This suggests the coders favored a performance oriented optimization scheme when optimizing the encoder for ARM.
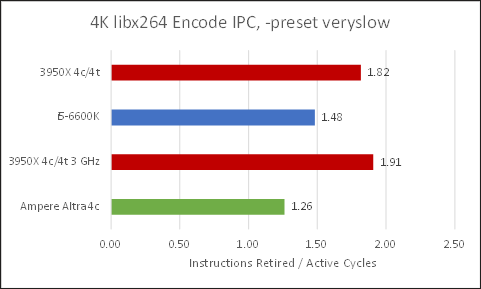
Much like 7z compression, we see an IPC increase at lower clock speeds for Zen 2. Now, Neoverse N1’s 1.26 IPC isn’t bad and the ARM based CPU can handle H.264 encoding in a pinch but, Intel and AMD’s chips do a much better job, with Zen 2 taking a significant lead.
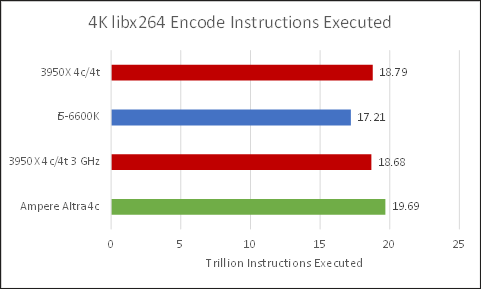
Even though libx264 can use AVX instructions on x86 processors, executed instruction counts are roughly similar across all CPUs here indicating that libx264 is pretty well optimized for both instruction sets.
Video encoding: Newer Video Standards
HEVC/libx265 can offer the same visual quality as libx264 with 25-50% smaller files (according to ffmpeg.org), making it an attractive option for archiving videos.
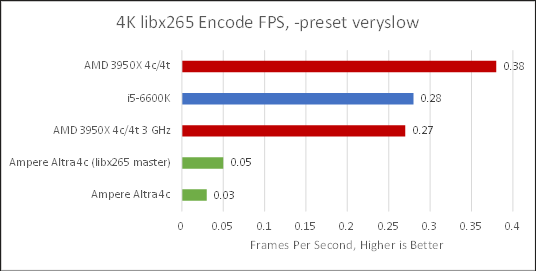
If you were thinking of using Neoverse N1 to archive some huge gaming recordings while taking advantage of HEVC’s efficient compression, well just forget about it.
With ffmpeg from Ubuntu 20.04’s packages, Neoverse N1 took almost 15 hours to finish encoding the test clip, while Zen 2 finished the same task in just over one and a half hours. Zen 2 was about 9x faster when clocks were matched.
Note, there are two Ampere Altra results here, because I noticed that Ubuntu 20.04’s ffmpeg didn’t utilize NEON instructions. A look at x265 source code showed aarch64 hand optimized assembly was only added in early 2020, so I cloned the latest master and built ffmpeg from source with it and with NEON instructions in play, N1 was 66% faster. However, Zen 2 at 3 GHz is still 5.4x faster and I’m not even going to talk about clock boosting.
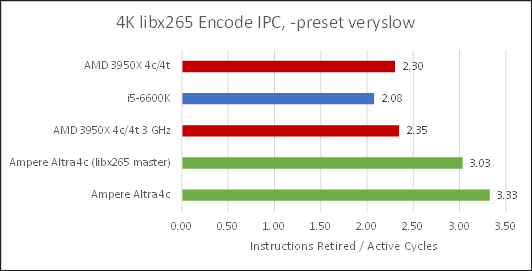

Performance counters showed Neoverse N1 executing an order of magnitude more instructions than x86 chips to complete the same task. IPC was high and N1 was crunching though those simpler instructions faster, but that’s nowhere near enough to make final performance comparable. It’s a train wreck for Neoverse N1, though the core itself isn’t directly at fault. Rather, ARM is poorly supported because it hasn’t been used much for these workloads. Things work the other way too: ARM cores aren’t optimized for video encode. ARM’s traditional strength has been in mobile SoCs that offloaded video encoding to separate blocks in the SoC, trading compression efficiency and quality for lower power consumption.
I also tried libaom-av1, an encoder for the cutting edge AV1 codec. AV1’s compression is even more efficient than HEVC. Zen 2 achieved 0.3 FPS with libaom-av1, while Ampere Altra was still going after several days. I haven’t tested SVT-AV1, but I expect similarly bad results because video encoding relies heavily on hand-optimized assembly and x86’s wide adoption brings it more developer attention.
3D Rendering
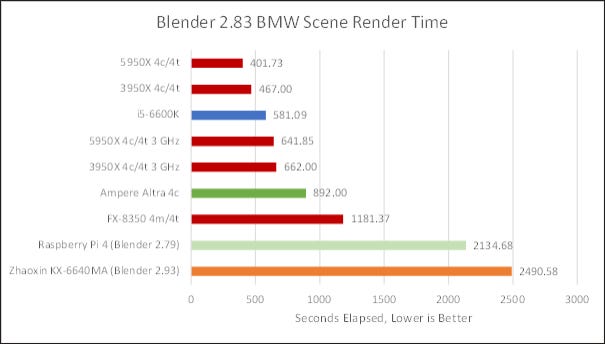
Blender is a popular and free 3D rendering program. With the sample BMW scene, Ampere Altra takes 91% longer than Zen 2 to finish, but the gap closes to 34.7% when clock speeds are matched.
3D rendering is again not a workload that ARM is familiar with optimizing for, and N1 is roughly two CPU generations behind Zen 2. People aren’t using ARM’s chips to render car commercials, animated movies, or real estate previews. Intel and AMD’s chips are obviously better choices, but N1 is a lot better than nothing.
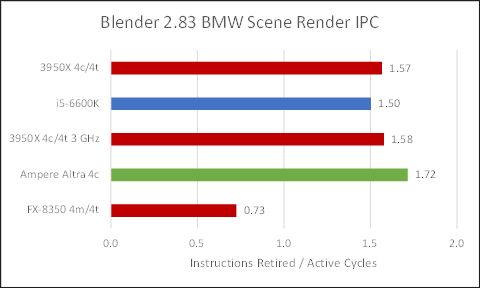
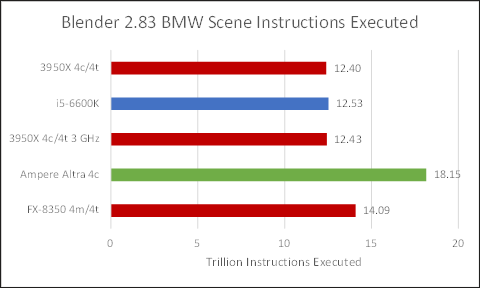
Ampere Altra executes around 45% more instructions than x86 based chips, so I’m guessing that AVX2 provides Intel and AMD with a nice advantage. But unlike the situation with newer video codecs, Neoverse N1 stays within the same ballpark. The difference in executed instruction count isn’t massive, and N1 does crunch through the simpler instructions a bit faster.
Architecture Details and Microbenchmarks
Branch Predictor Accuracy
Now that benchmarks are out of the way, let’s put aspects of ARM’s Neoverse N1 architecture under a microscope, starting with the branch prediction. Branch prediction has long been an optimization target for CPU architects and every new generation of CPUs from every maker features branch prediction tweaks.
Let’s start with accuracy first, since that tends to be the biggest factor as we saw in our Zen 3 bottlenecks article. If you send the CPU down the wrong path, you waste power and time executing the wrong instructions only to throw them out which makes better branch prediction accuracy both a power and a performance win.
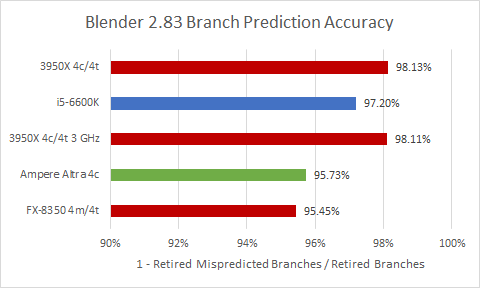
Zen 2’s branch predictor takes the lead in Blender, with Skylake’s coming in second. Piledriver’s comparatively worse performance shows how far AMD has come. Meanwhile Neoverse N1 pulls ahead of Piledriver, but ARM’s branch predictor is a clear step behind AMD and Intel’s.
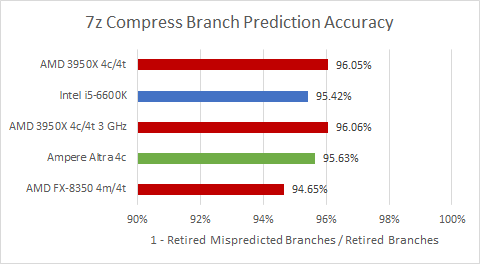
Zen 2’s branch predictor takes another win here. 7z’s branches are a bit harder to predict than Blender’s, but Ampere suffers less which is enough for it to take a slight win over Skylake.
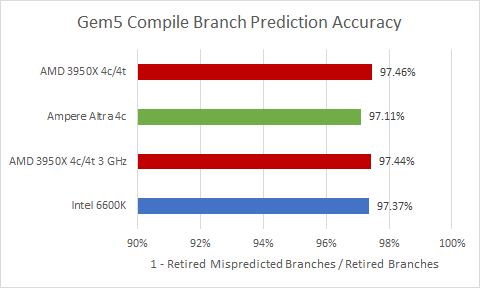
When compiling code, everyone lands surprisingly close together. Zen 2 is still ahead, but only by a hair. There are probably some rarely hit or hard to predict branches that mess up everyone’s branch predictors.
And now on to something new for us, Microbenchmarking the finer details of the BPU
To see how well each CPU can remember patterns, we create an array that’s randomly filled with 1s and 0s and have a branch that’s taken if it sees a 0. For short array lengths, the predictor should be able to remember the pattern and perfectly predict the branch. And like we said previously, this is our first attempt at dissecting BPU pattern recognition, so please bear with us while we make this test, and especially our interpretation of dirty data, as accurate as possible.
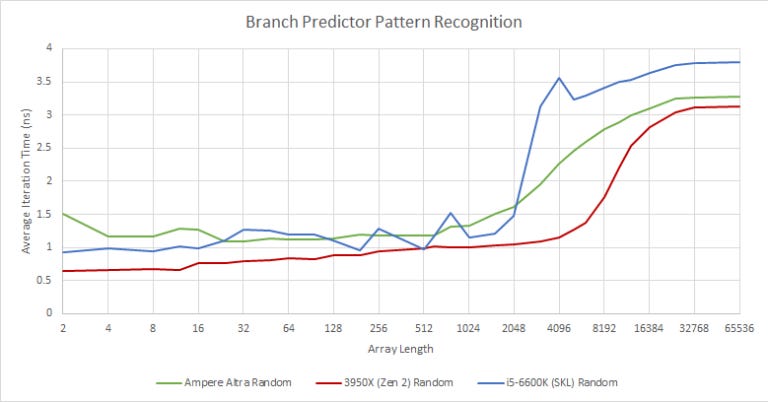
The results for the 6600K aren’t clean, so I tried again on a cloud instance which ended up much cleaner.
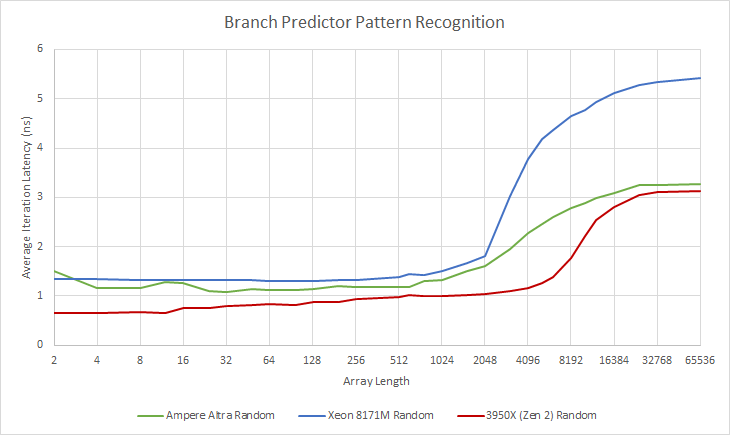
Neoverse N1 sees a tick up starting after 512, which gets sharper after 2048. Skylake sees a sharp slowdown past 2048, and Zen 2 does too past 4096. Zen 2’s branch predictor seems to have the most powerful pattern recognition capabilities. That may explain AMD’s edge in branch prediction accuracy.
Branch Predictor Speed
Accuracy may be the most important factor, but you can’t spend forever thinking about where to go. If you deliver branch targets faster, the instruction fetch stage stalls less and keeps the core better fed. To speed things up, branch predictors keep a cache of branch targets, called the branch target buffer (BTB). That lets them remember where a branch will go without waiting for the branch instruction itself to arrive from cache/memory.
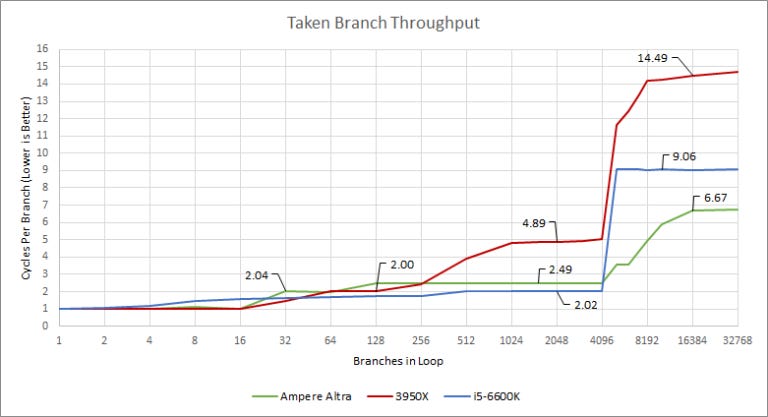
Cortex A76 was designed with branch heavy web workloads in mind, and it shows. ARM opted for a fast L2 BTB and relatively fast branch address calculation for BTB misses. Similarly, Intel has gone for a very large and fast L1 BTB (they haven’t named it, I’m just calling it that). It probably has 4096 entries, and only incurs a one cycle penalty. Intel’s branch target calculation is also relatively fast (in absolute time, considering the higher frequency).
In contrast, Zen 2’s BPU slows down when there are lot of branch targets to track. Its L2 BTB is large, but has a 4 cycle penalty. AMD has gone for a slower branch predictor, favoring accuracy at the expense of speed.
Register File Sizes
Unlike Intel and AMD, ARM is rather tight lipped about microarchitectural details, which means we’ll just measure things we’re curious about ourselves.
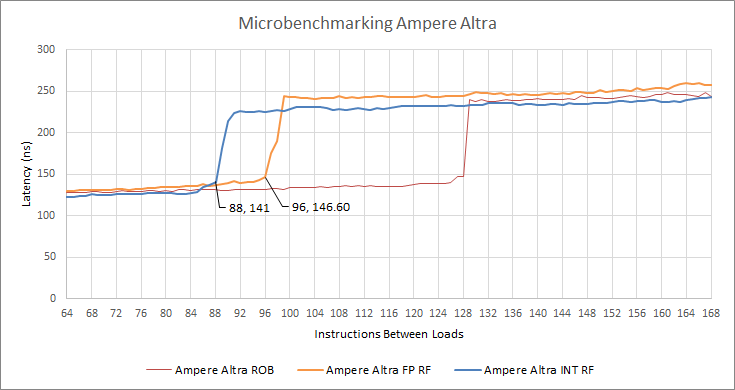
N1 appears to have 88 integer registers and 96 FP/SIMD registers for renaming. 64-bit ARM architecturally has 32 integer registers and 32 FP/SIMD registers, so the physical register file size is probably 120 integer registers and 128 FP/SIMD registers.
Power Consumption
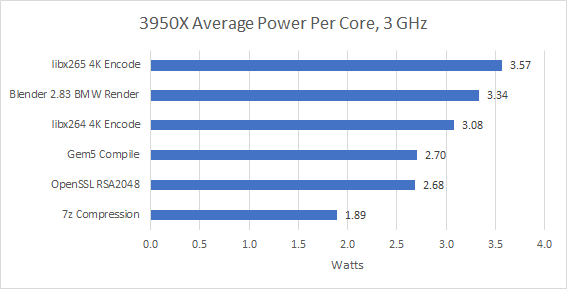
Unfortunately we have no way to measure Neoverse N1’s power draw. We’re running from within a cloud VM, and we don’t see any power monitoring facilities. ARM claims N1 draws 1-1.8 W per core at 2.6-3.1 GHz. Our Ampere Altra test instance runs at 3 GHz, so power draw is probably closer to 1.8 W per core.
If we take ARM’s word, a Zen 2 core at 3 GHz typically draws 48% to 98% more power than a N1 core, with the higher end representing workloads that hammer Zen 2’s AVX2 units. Zen 2’s performance advantage at matched clocks is usually less than that, so Neoverse N1 takes a power efficiency win – assuming we’re not talking about libx265 along with assuming that ARM’s estimates are realistic.
Conclusion
Neoverse N1 is a credible effort by ARM to break into the server market. While performance per core doesn’t reach Zen 2 levels, it’s at least in the same ballpark for most non-vectorized workloads. If we ignore the poor showing in public key crypto, N1 is pretty close to Zen 2 in file compression and code compilation.
However, Zen 2 pulls farther ahead when applications take advantage of AVX2, which uses vectors twice as wide as ARM’s NEON instructions. Blender and H.264 encoding are examples. While ARM gets wider vectors with the SVE instruction set extension, there are no consumer or server ARM CPUs shipping with SVE support (including N1).
In the worst cases, N1 is let down by software ecosystem support. Video encoding with newer codecs is an egregiously bad case. Cutting edge encoders like libaom-av1 are straight up unusable with ARM because there’s no hand-optimized assembly. x86 benefits from lots of developer attention thanks to its wide market share, and that can’t be ignored. While not covered here, there’s a lot of software with no ARM support at all. And binary translation can bring heavy performance penalties.
In fairness to N1, it’s probably only deployed by companies who know exactly what they want to run, have tested those workloads, and can dedicate developer resources to optimizing for ARM whenever necessary. However, software ecosystem may present a challenge if ARM wants to break into the PC market, where consumers may be in for some surprises.
Overall, N1 is the best server CPU we’ve seen from ARM Ltd and we’re excited to see more competition in the server market. I personally hope ARM will try to break into the PC market, as competition is needed there. It’s a tough market to break into. But as Intel said in their recent presentation about fabrication technology, it’s easier to be second place in a bike race than first. Intel and AMD have already shown what works and what doesn’t, so ARM should have a smooth path to being competitive.
Setup
The 3950X had one core enabled per CCX, to give it dual CCD mode while satisfying the restriction that each CCX in a CCD must have the same number of active cores. DDR4-3333 16-18-18-38 dual channel memory was used, with matched FCLK. The DIMMs are specified for DDR4-3200, but remain stable with a small overclock.
The i5-6600K was run at its default all-core turbo frequency of 3.6 GHz with matched ring clock. For memory, Skylake had dual channel DDR4-2133 15-15-15-35. We didn’t match memory between Zen 2 and Skylake because Skylake was not stable when using the faster memory sticks with their DDR4-3200 XMP profile.
The FX-8350 was allowed to run at its stock frequency, which stayed around 4-4.2 GHz. DDR3-1866 10-11-10-30 was used.