
iGPU Cache Setups Compared, Including M1

Like CPUs, modern GPUs have evolved to use complex, multi level cache hierarchies. Integrated GPUs are no exception. In fact, they’re a special case because they share a memory bus with CPU cores. The iGPU has to contend with CPUs for limited memory bandwidth, making caching even more important than with dedicated GPUs.
At the same time, the integrated nature of integrated GPUs provides a lot of interesting cache design options. We’re going to take a look at paths taken by AMD, Intel, and Apple.
Global Memory Latency
GPUs are given a lot of explicit parallelism, so memory latency isn’t as critical as it is for CPUs. Still, latency can play a role. GPUs often don’t run at full occupancy – that is, the amount of parallel work they’re tracking isn’t maximized. We have more on that in another article, so we’ll go right to the data.
Testing latency is also a good way of probing the cache setup. Doing so with bandwidth isn’t as straightforward because requests can be combined at various levels in the memory hierarchy, and defeating that to get clean breaks between cache levels can be surprisingly difficult.

The Ryzen 4800H’s cache hierarchy is exactly what you’d expect from AMD’s well known GCN graphics architecture. Each of the 4800H’s seven GCN-based CUs have a fast 16 KB L1 cache. Then, a larger 1 MB L2 is shared by all of the CUs. AMD’s strategy for dealing with memory bus constraints appears quite simple: use a higher L2 capacity to compute ratio than that of discrete GPUs. A fully enabled Renoir iGPU has 8 CUs, giving 128 KB per CU. Contrast this with AMD’s Vega 64, where 4 MB of L2 gives it 64 KB per CU.

Apple’s cache setup is similar, with a fast L1 followed by a large 1 MB L2. Apple’s L1 is half of AMD’s size at 8 KB, but has similar latency. This low latency suggests it’s placed within iGPU cores, though we don’t have a test to directly verify this. Compared to AMD, Apple’s L2 is a bit lower latency, which should help make up for the smaller L1. We also expect to see a 8 MB SLC, but that doesn’t really show up in the latency test. It could be the somewhat lower latency area up to 32 MB.
Then, we have Intel. Compared to AMD and Apple, Intel tends to use a less conventional cache setup. Right off the bat, we’re hitting a large cache shared by all of the GPU’s cores. It’s at least 1.5 MB in size, making it bigger than AMD and Apple’s GPU-level caches. In terms of latency, it’s somewhere between AMD and Apple’s L2 caches. That’s not particularly good, because we don’t see a smaller, faster cache in front of it. But its large size should help Intel keep more memory traffic within the iGPU block. Intel should have smaller, presumably faster caches in front of the large shared iGPU-level cache. But we weren’t able to see them through testing.
Like Apple, Intel has a large, shared chip-level cache that’s very hard to spot on a latency plot. This is strange – our latency test clearly shows the shared L3 on prior generations of Intel integrated graphics.

From this first glance at latency, we can already get a good idea of how each manufacturer approaches caching. Let’s move on to bandwidth now.
Global Memory Bandwidth
Bandwidth is more important to GPUs than to CPUs. Usually, CPUs only see high bandwidth usage in heavily vectorized workloads. For GPUs though, all workloads are vectorized by nature. And bandwidth limitations can show up even when cache hitrates are high.

AMD and Apple’s iGPU private caches have roughly comparable bandwidth. Intel’s is much lower. Part of that is because Alder Lake’s integrated graphics have somewhat different goals. Comparing the GPU configurations makes this quite obvious:

AMD’s Renoir and Apple’s M1 are designed to provide low end gaming capability to thin and light laptops, where a separate GPU can be hard to fit. But desktop Alder Lake definitely expects to be paired with a discrete GPU for gaming. Understandably, that means Intel’s iGPU is pretty far down on on the priority list when it comes to power and die area allocation. Smaller iGPUs will have less cache bandwidth, so let’s try to level out the comparison by using vector FP32 throughput to normalize for GPU size.

Intel’s cache bandwidth now looks better, at least if we compare from L2 onward. Bytes per FLOP is roughly comparable to that of other iGPUs. Its shared chip-level L3 also looks excellent, mostly because its bandwidth is over-provisioned for such a small GPU.
As far as caches are concerned, AMD is the star of the show. Renoir’s Vega iGPU enjoys higher cache bandwidth to compute ratios than Intel or Apple. But its performance will likely be dependent on cache hitrate. L2 misses go directly to memory, because AMD doesn’t have another cache behind it. And Renoir has the weakest memory setup of all the iGPUs here. DDR4 may be flexible and economical, but it’s not winning any bandwidth contests. Apple and Intel both have a stronger memory setup, augmented by a big on-chip cache.
Local Memory Latency
GPU memory access is more complicated than on CPUs, where programs access a single pool of memory. On GPUs, there’s global memory that works like CPU memory. There’s constant memory, which is read only. And there’s local memory, which acts as a fast scratchpad shared by a small group of threads. Everyone has a different name for this scratchpad memory. Intel calls it SLM (Shared Local Memory), Nvidia calls it Shared Memory, and AMD calls it LDS (Local Data Share). Apple calls it Tile Memory. To keep things simple, we’re going to use OpenCL terminology, and just call it local memory.
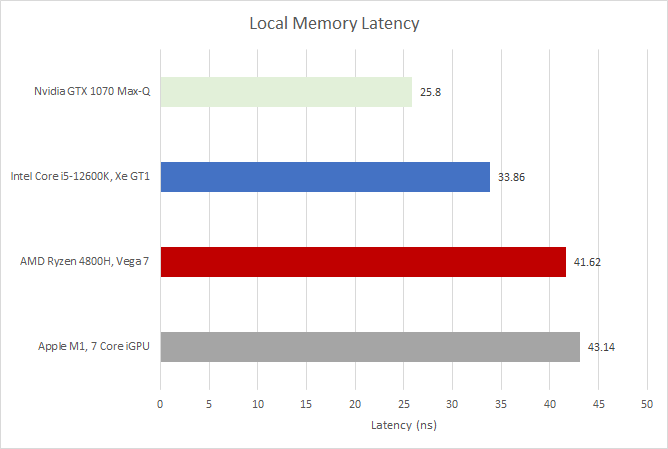
AMD and Apple take about as long to access local memory as they do to hit their first level caches. Of course, latency isn’t the whole story here. Each of AMD’s GCN CUs has 64 KB of LDS – four times the capacity of its L1D cache. Bandwidth from local memory is likely higher too, though we currently don’t have a test for that. Clinfo on M1 shows 32 KB of local memory, so M1 has at least that much available. That figure likely only indicates the maximum local memory allocation by a group of threads, so the hardware value could be higher.
Intel meanwhile enjoys very fast access to local memory, as does Nvidia, which is here for perspective. Their story is an interesting one too. Prior to Gen10, Intel put their SLM along the iGPU’s L3, outside the the subslices (Intel’s cloest equivalent to GPU cores on Apple and CUs on AMD). For a long time, that meant Intel iGPUs had unimpressive local memory latency.

Starting with Gen 11, Intel thankfully moved the SLM into the subslice, making the local memory configuration similar to AMD and Nvidia’s. Apple likely does the same (putting “tile memory” within iGPU cores) since local memory latency on Apple’s iGPU is also quite low.
CPU to GPU Copy Bandwidth
A shared, chip-level cache can bring other benefits. In theory, transfers between CPU and GPU memory spaces can go through the shared cache, basically providing a very high bandwidth link between the CPU and GPU. Due to time and resource constraints, slightly different devices are tested here. But Renoir and Cezanne should be similar, and Intel’s behavior is unlikely to regress from Skylake’s.
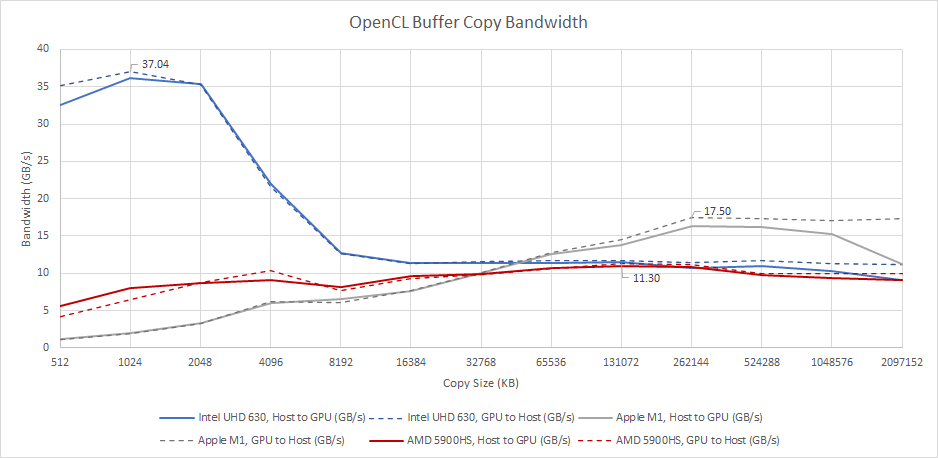
Only Intel is able to take advantage of the shared cache to accelerate data movement across different blocks. As long as buffer sizes fit in L3, Skylake handles copies completely within the chip, with performance counters showing very little memory traffic. Larger copies are still limited by memory bandwidth. The Core i7-7700K tested here only has a dual channel DDR4-2400 setup, so that’s not exactly a strong point.
Apple in theory should be able to do the same. However, we don’t see an improvement for small copy sizes that should fit within M1’s system level cache. There are a couple of explanations. One is that M1 is unable to keep CPU to GPU transfers on-die. Another is that small transfers are kept on-die, but commands to the GPU suffer from very high latency, resulting in poor performance for small copies. Intel’s Haswell iGPU suffers from the same issue, so the second is a very likely explanation. When we get to larger copy sizes, M1’s high bandwidth LPDDR4X setup does a very good job.
AMD’s performance is very easy to understand. There’s no shared cache, so bandwidth between the CPU and GPU is limited by memory bandwidth.
Finally, it’s worth noting that all of the iGPUs here, as well as modern dedicated GPUs, can theoretically do zero-copy transfers by mapping the appropriate memory on both the CPU and GPU. But we currently don’t have a test written to analyze transfer speeds with mapped memory.
Final Words
GPUs tend to be memory bandwidth guzzlers, and feeding an integrated GPU is particularly challenging. Their memory subsystems are typically not as beefy as those of dedicated GPUs. To make matters worse, the iGPU has to fight with the CPU for memory bandwidth.
Apple and Intel both tackle this challenge with sophisticated cache hierarchies, including a large on-chip cache that serves the CPU and GPU. The two companies take different approaches to implementing that cache, based on how they’ve evolved their designs. Intel has the most integrated solution. Its L3 cache does double duty. It’s tied very closely to the CPU cores on a high speed ring interconnect, in order to provide low latency for CPU-side accesses. The iGPU is simply another agent on the ring bus, and L3 slices handle iGPU and CPU core requests in the same way.

Apple uses more specialized caches instead of trying to optimize one cache for both the CPU and GPU. M1 implements a 12 MB L2 cache within the Firestorm CPU cluster, which fills a similar role to Intel’s L3 from the CPU’s perspective. A separate 8 MB system level cache helps reduce DRAM bandwidth demands from all blocks on the chip, and acts as a last stop before hitting the memory controller. By dividing up responsibilities, Apple can tightly optimize the 12 MB L2 for low latency to the CPU cores. Because the L2 is large enough to absorb the bulk of CPU-side requests, the system level cache’s latency can be higher in order to save power.
M1 still has a bit of room for improvement. Its cache bandwidth to compute ratio could be a touch higher. Transfers between the CPU and GPU could take full advantage of the system level cache to improve bandwidth. But these are pretty minor complaints, and overall Apple has a pretty solid setup.

AMD’s caching setup is bare-bones in comparison. Renoir (and Cezanne) are basically a CPU and GPU glued together. Extra GPU-side L2 is the only concession made to reduce memory bandwidth requirements. And “extra” here only applies in comparison to discrete GCN cards. 1 MB of L2 isn’t anything special next to Apple and Intel, both of which have 1 MB or larger caches within their iGPUs. If the L2 is missed, AMD goes straight to memory. Memory bandwidth isn’t exactly AMD’s strong point, making Renoir’s lack of cache even worse. Renoir’s CPU-side setup isn’t helping matters either. A L3 setup that’s only 1/4 the size of desktop Zen 2’s will lead to additional memory traffic from CPU cores, putting even more pressure on the memory controller.
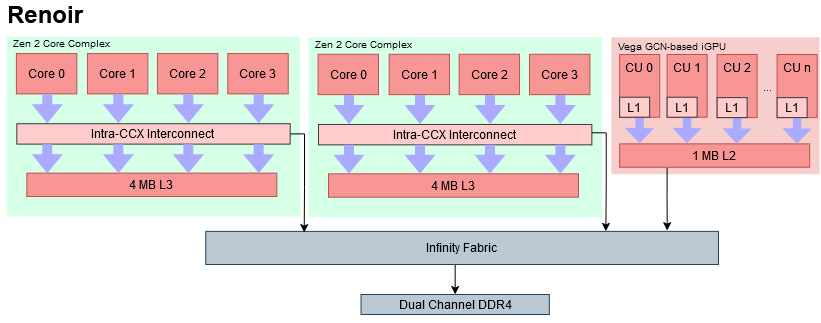
AMD’s APU caching setup leaves a lot to be desired. Somehow, AMD’s iGPU still manages to be competitive against Intel’s Tiger Lake iGPU, which speaks to the strength of their GCN graphics architecture. I just wish they took advantage of that potential to deliver a killer APU. After all, AMD has a lot of low hanging fruit to improve with. RDNA 2 based discrete GPUs use a large “Infinity Cache” sitting behind Infinity Fabric to reduce memory bandwidth requirements. Experience gained implementing that cache could trickle down to AMD’s integrated GPUs.
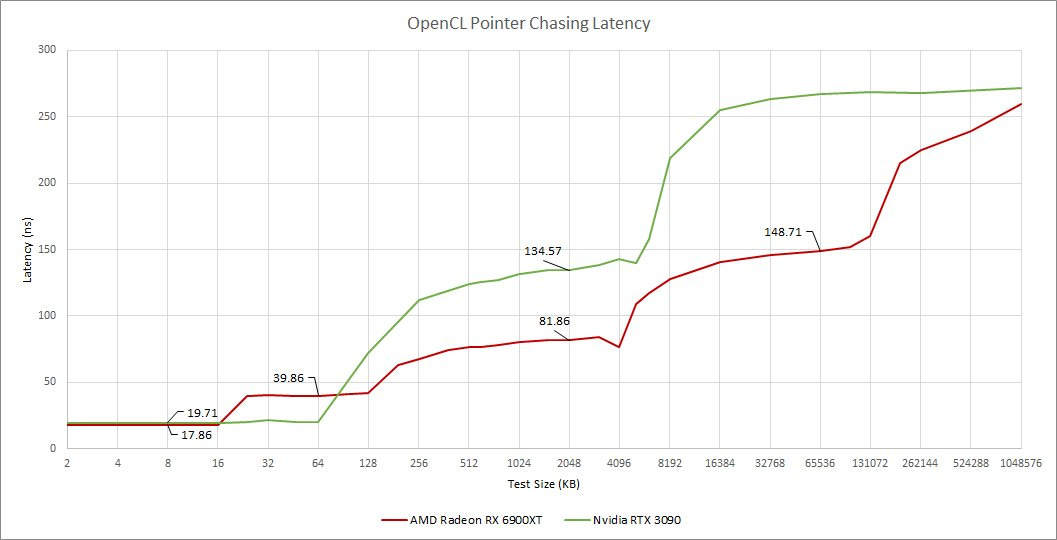
It’s easy to imagine an Infinity Cache delivering benefits beyond reducing GPU memory bandwidth requirements too. For example, the cache could enable faster copies between GPU and CPU memory. And it could benefit CPU performance, especially since AMD likes to give their APUs less CPU-side L3 compared to desktop chips.
But such a move is unlikely with in the next generation or two. With AMD moving to LP/DDR5, the bandwidth boost along with large architecture changes allowed AMD to double iGPU performance with Rembrandt. Factor in Renoir and Cezanne’s already adequate graphics performance, Intel’s inability to capitalize on their superior cache setup, and Apple’s closed ecosystem, there’s little pressure on AMD to make aggressive moves.
Infinity cache on an APU will also require significant die area to be effective. Hitrate with a 8 MB system level cache is abysmal:
Cache hitrate tends to increase with the logarithm of size, so AMD would probably want to start with at least 32 MB of cache to make it worth the effort. That means a bigger die, and unfortunately, I’m not sure if there’s a market for a powerful APU in the consumer x86 realm.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.
Test Setup

Thanks for this article. Do you know whether AMD's latest APUs (Strix Halo or Strix Point) are able to do direct memory transfers on-chip between CPU cache and GPU memory? My understanding of your article is that as of 2022, transfers had to go out to main memory (slower), but Apple chips could direct-transfer (faster), and so I am hoping that AMD has added this feature in their upcoming and recently released chips.