
Do IBM’s Giant L3 and V-Cache Represent the Future?

IBM showed off a giant 256 MB L3 during its Telum presentation at Hot Chips 2021, and ignited discussion about whether that represents the future of caches. That’s not the first time we’ve seen big caches brought up. Just a few years ago, AMD advertised Zen 2’s 16 MB CCX-level cache as “GameCache” to emphasize the performance gains it provided in gaming. And AMD showed love for cache again with 3D V-Cache, which gives Zen 3 a 96 MB LLC.
So why have we seen so many consumer chips with smaller cache sizes? What if we bolt an IBM-style 256 MB L3 cache onto something resembling a Zen 3 core? Let’s give it a try and simulate what happens.
Latency – A 256 MB Cache Isn’t Free
From Hot Chips slides, IBM Telum’s runs at “5+ GHz base clock”, and the 256 MB L3 has an average latency of 12 ns (60 cycles at 5 GHz). Zen 3’s 32 MB L3 has an average latency of 46 cycles, according to its optimization guide. I gathered about 350 instruction traces and ran simulations to judge the benefits of using IBM’s larger, higher latency cache:
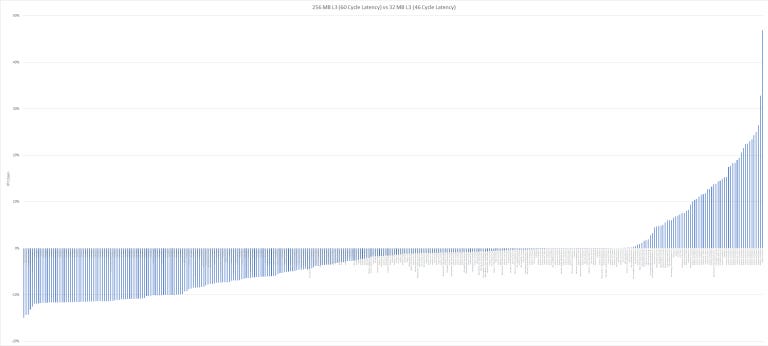
Some traces showed gigantic performance gains with a 256 MB cache. But a lot didn’t show much benefit, and some even lost IPC. In some particularly bad cases, IPC loss hovers around 10%. Intel and AMD’s single threaded performance has been extremely close for the last couple generations, so 10% lower IPC can be a heavy blow. Let’s dig a bit deeper.
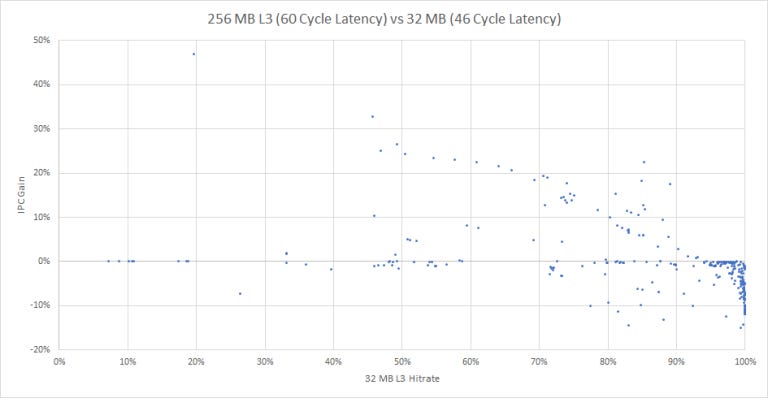
A lot of workloads don’t benefit because hitrate was already very high with a 32 MB L3. When there’s little room to improve hitrate, higher latency on the 256 MB cache often hurts IPC. Other traces have such massive working sets that an 8x increase in cache capacity doesn’t increase hitrate by enough to overcome the latency deficit.
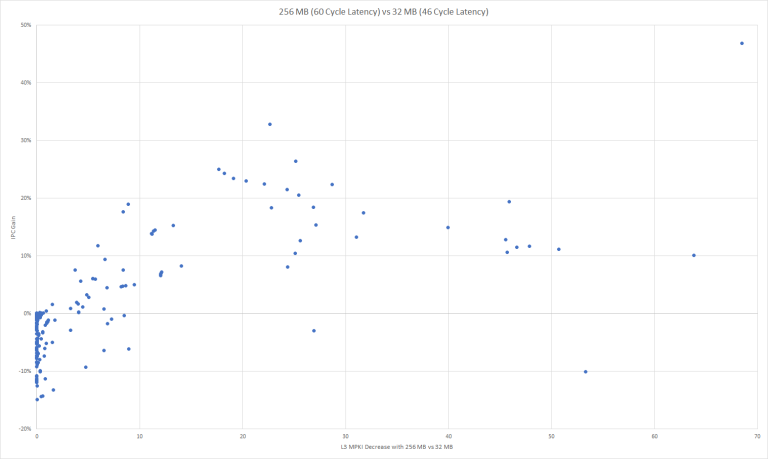
Here’s another way of looking at things – you need a substantial reduction in L3 miss rate to make a larger, higher latency cache worthwhile. Otherwise, you’re just wasting die area and power while possibly losing performance.
What about V-Cache?
We don’t know what AMD V-Cache’s latency will look like, so we ran two sets of simulations. One set simulated a 96 MB L3 with the same latency as the 32 MB one (46 cycles). That represents a best case scenario, where 3D stacking lets AMD employ a huge cache without the latency hits that traditionally accompanied larger caches.
Then, we ran another set of simulations with a 52 cycle latency V-Cache. A 6 cycle latency hit is roughly similar what AMD suffered when increasing L3 capacity from 8 to 16 MB (+4c), and from 16 MB to 32 MB (+7c). That’s a worst case scenario that assumes AMD doesn’t benefit much from 3D stacking and shorter wire lengths.
First, let’s start with the best case scenario:
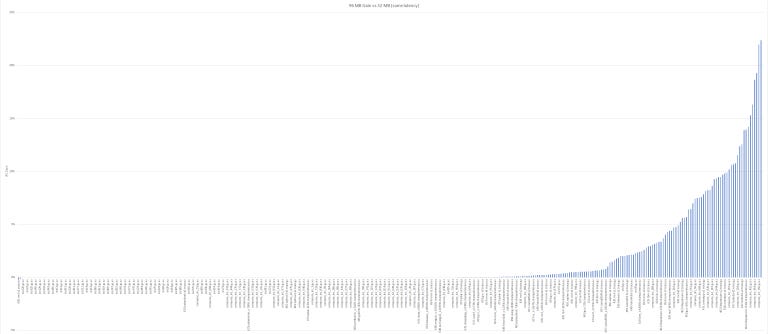
As expected, a 96 MB L3 with no added latency brings huge performance boosts without regressing elsewhere. But if we take an extra 6 cycles to get to L3, the story changes:
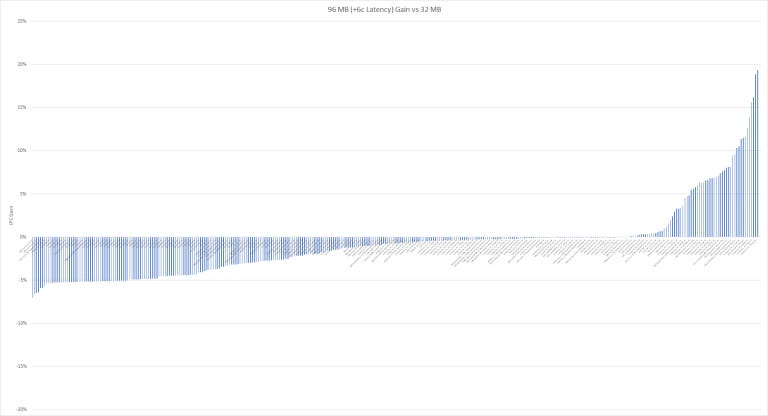
With 52 cycles of latency, the situation gets more complicated. It’s basically a moderate version of the 256 MB one above. Some traces see almost a generational IPC gain. At the other end, latency sensitive traces that fit within 32 MB regress a bit, but most of them don’t lose more than 5%. For sure, a 5% IPC loss is undesirable, but will be hard to feel in typical usage. That is, as long as typical usage doesn’t involve comparing benchmark scores or staring at framerate counters.
Where Does Gaming Stand?
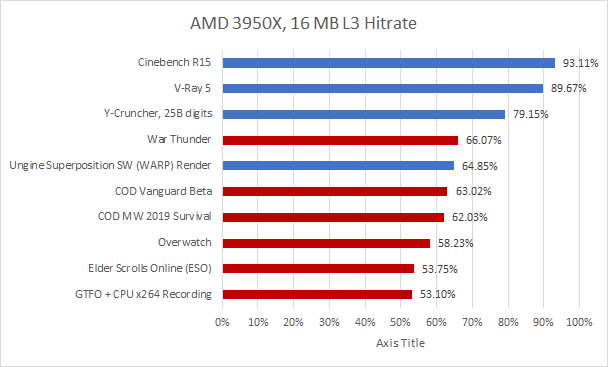
I don’t have a way of collecting instruction traces for games (at least if I don’t feel like getting banned, don’t ask me how I know). But I can measure L3 miss rates per instruction on my 3950X, and use that to roughly guess where games would land.
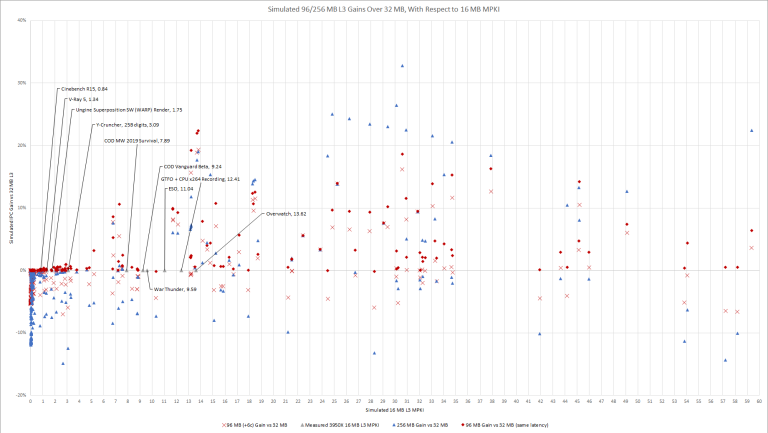
Plotting IPC gains for three different simulated cache configurations, against simulated 16 MB L3 hitrate on the X axis. Labeled points represent real world L3 MPKI, collected using the 3950X’s L3 performance counters.
Larger caches certainly look promising for games. Interestingly, the 96 MB configurations appear optimal for game-like L3 miss rates. The huge 256 MB IBM-style cache doesn’t show its strength until you’re exceeding 20 MPKI on a 16 MB L3.
But of course, games aren’t everything. I’ve also marked data points for some non-gaming benchmarks, because AMD’s Zen chips are expected to handle a wide variety of workloads. Traces with similar L3 MPKI to those benchmarks saw almost no gain even when given a 96 MB cache “for free” (no extra latency). For those benchmarks, you really want a faster cache, even if it’s smaller.
Therefore, AMD’s V-Cache is not a completely superior solution. Rather, it’s an acknowledgement that a one-size-fits-all approach to L3 size no longer cuts it. I suspect AMD will offer both V-Cache and non V-Cache variants of future chips, allowing customers to choose what’s best for their workload. We already saw hints that Genoa would have non V-Cache configurations (no mention of L3 sizes greater than 32 MB in the leaked PPR).
Latency Speculation

AMD claims a 15% IPC uplift in games. That’s a lot closer to our best case results than our worst case (+6c) ones. Tomshardware also reported AMD saying “the latency impact is minimal.” That suggests a very small V-Cache latency penalty – probably around a couple cycles if I had to guess. Maybe V-Cache will come with very few downsides, and consumers will mainly be weighing V-Cache’s cost against its benefits.
Conclusion – Huge Caches Aren’t for Everything
IBM has been using large caches for several generations. Z15 had a 256 MB 32-way chip level cache in 2019, and Z14 had a 128 MB one in 2017. Z15 and Z14 both achieved that on an older node, namely GlobalFoundries’s 14nm process. If AMD (or Intel) wanted to use a giant cache, they had years to look at what IBM was doing. And before Telum, AMD was a node ahead of IBM. So is IBM just crazy good? Or is AMD getting lazy? Neither.
AMD’s is likely targeting a wider variety of workloads than IBM, including many that are latency sensitive but don’t have huge memory footprints. I’m guessing AMD’s internal simulations showed a fast but modestly sized L3 gave the best performance for these loads. Likely, further simulations showed that a bigger L3 would benefit other applications (games), creating a justification for V-Cache. Meanwhile, IBM seems to be optimizing exclusively for big working sets that are less sensitive to latency.
Of course, it’d be nice to get the best of both worlds with a low latency 256 MB cache, but that doesn’t exist. And if it did, it would be ridiculously expensive. With current fabrication and packaging technology, V-Cache looks like the next best thing.
If you like what we do and you would like to help us with acquiring more things to test, then head on over to our Patreon if you want to chip in a few bucks.
Simulation Setup
Simulations were run with ChampSim, and traces were gathered from several places. Some were used for a ML prefetching competition. Some were provided by Qualcomm Datacenter Technologies and used to judge the Championship Value Prediction competition. I also used ChampSim’s traces, provided by Professor Daniel Jimenez at Texas A&M. Each trace was run for 1 billion instructions, with 20 million warmup instructions.
Simulation parameters were chosen to approximate a Zen 3 core. For caches, we used:

The SRRIP replacement policy was used for the L3.
Other simulation parameters:

Closing Notes
Simulations are hard, especially when it comes to collecting traces. We weren’t able to run as many traces as we wanted to, because simulations take a lot of time to run. My 3950X was pegged for days simulating several different configurations. The subset of Qualcomm client (compute_int) and server (srv) traces used here weren’t chosen in any particular way. They were simply the first ones to get extracted out of a giant zip file before I ran out of hard drive space. So take the results here with a grain of salt.