
Zhaoxin Part 3: A Sort of Anti-Climax

I’ll be blunt here, this part will seem like an anti-climax compared to Part 2 of this series but I hope to nicely wrap up this series with this as the conclusion piece of what we know about how the changes talked about in Part 2 have affected the performance of the Lujiazui architecture and the potential future of Zhaoxin products and microarchitectures.
A Note on the Benchmarks used for this Piece
There is no perfect benchmark that can spit out one single number that tells you how much better CPU X compared to CPU Y because every workload is different and every use case is different; the benchmarks that we chose for this article were benchmarks that either are freely available or ones in which we were able to get a license for.
With that said, for this piece we used Cinebench R11.5, Cinebench R20, and Geekbench 5. Now we wanted to run both our standard suite of tests found in our N1 deep dive piece, Cinebench R15, and UL’s PCMark, however the VIA system would not run either Cinebench R15 or PCMark. PCMark just refused to even open on the VIA and Cinebench R15 would just crash on both the VIA and Zhaoxin systems which we suspect is down to the poor driver support for the integrated graphics on these systems.
Also, please keep in mind that we had to clock normalize by either dividing or multiplying the clock speed of the CPU in question to an arbitrary clock speed. This is unfortunately is not a good method to try and get a performance per clock comparison however, this was the best that we could do because we did not have control of the CPU clock ratios. We also had to divide the Zhaoxin’s R20 scores by two because we only had the multi thread scores due to the VIA not being able to finish the R20 single thread test.
Cinebench R11.5
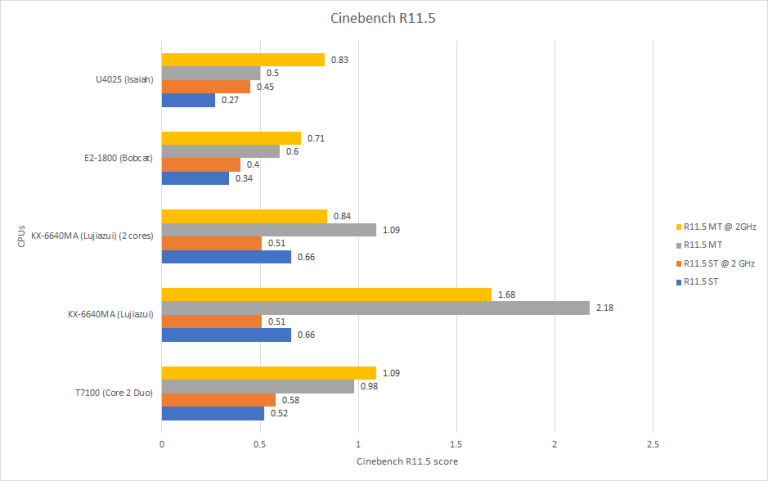
Starting off with Cinebench R11.5, which would have been a common benchmark around the time of the launch of the VIA Nano and the Intel Core 2 T7100, looking at just the raw single thread results Isaiah is taking up the rear with Lujiiazui at the front of the pack. However when we look at the single thread clock normalized results things change, Isaiah now pulls ahead of Bobcat and Merom pulls in front of Lujiazui. While our clock normalized results shows that Lujiazui has about 13 to 14 percent perfomance per clock increase over Isaiah, this is not a good start for Lujiazui to be losing to an architecture that is a decade and a half old at the time of writing this piece considering that Lujiazui is the newest architecture that Zhaoxin offers.
The story arguably gets even worse with the multithreaded results. Now, the KX-6640MA that we tested is a 4 core CPU and unfortunately Zhaoxin does not sell a 2 core version, so we do have an extrapolated result for a 2 core version which was dividing the 4 core result by the single core result to get the ratio between the two results, dividing the ratio by 2, then multiplying the divided ratio by the single tread result which is not ideal but it does show something interesting. Now a note on the memory configuration of the Zhaoxin, we ran the Zhaoxin with both single channel DDR4 2666 and dual channel DDR4 2400 and there was only minimal changes to any of our results. That lack of change along with the fairly poor multithread ratio suggests either that cores are being bandwidth starved due to the poor L2 or that the cores simply can not take advantage of the near doubling of the bandwidth that the dual channel memory gives it in Cinebench R11.5.
Cinebench R20
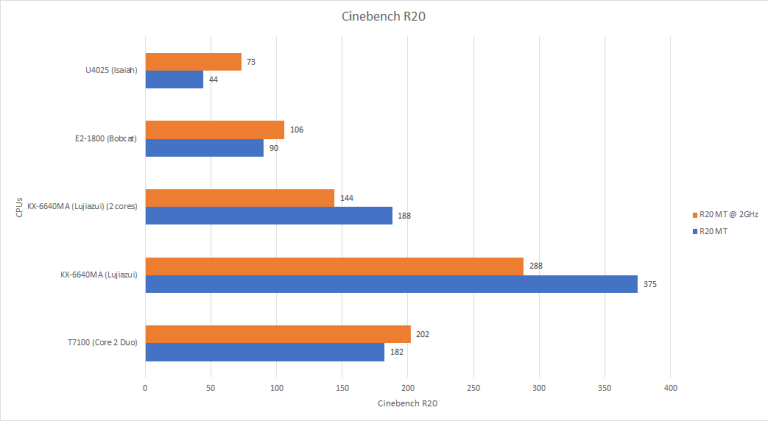
Moving on to a more modern benchmark in the form of Cinebench R20 and this is a much more promising result for Lujiazui. Looking at the clock (and core) normalized results first, Lujiazui is getting double the performance per clock of Isaiah which for a generational increase is very impressive. However, note has to be made that Cinebench R20 can take advantage of AVX acceleration which no CPU tested has other then the Zhaoxin which does diminishes its win over Isaiah and Lujiazui still loses to Merom once again. Also something else to notice here is that in this more modern application, Bobcat takes the lead over Isaiah even in the clock normalized results in R20 which is the opposite of R15 where Isaiah beat Bobcat.
Geekbench 5
Isaiah versus Lujiazui
The Geekbench portion of this review will be split in to several sections with the first section being the comparison of Isaiah to Lujiazui.
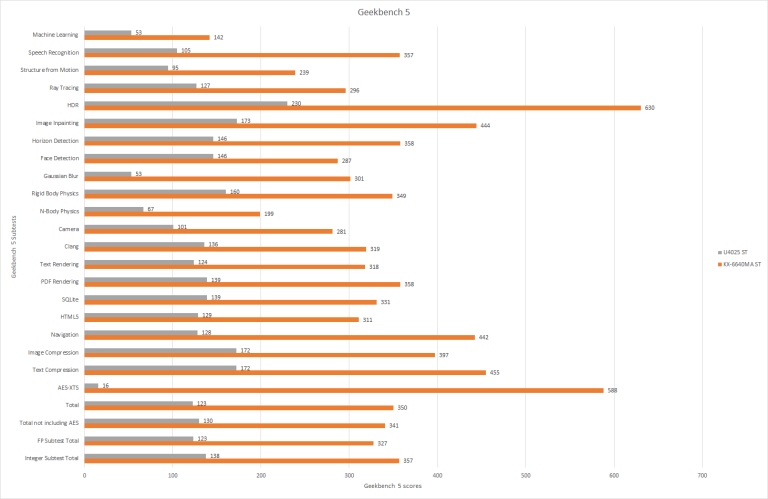
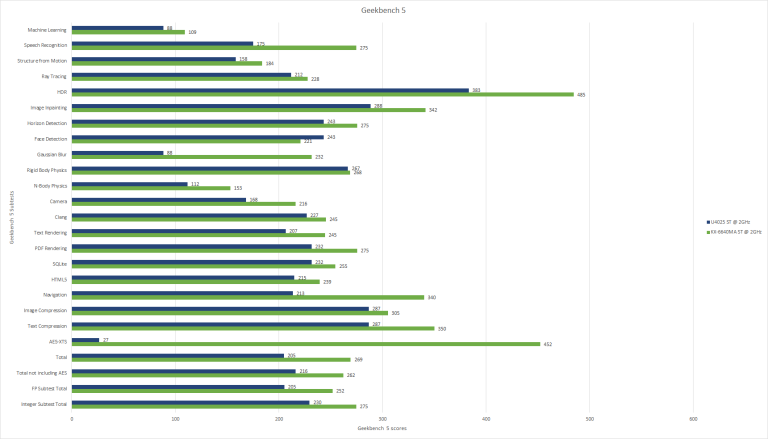
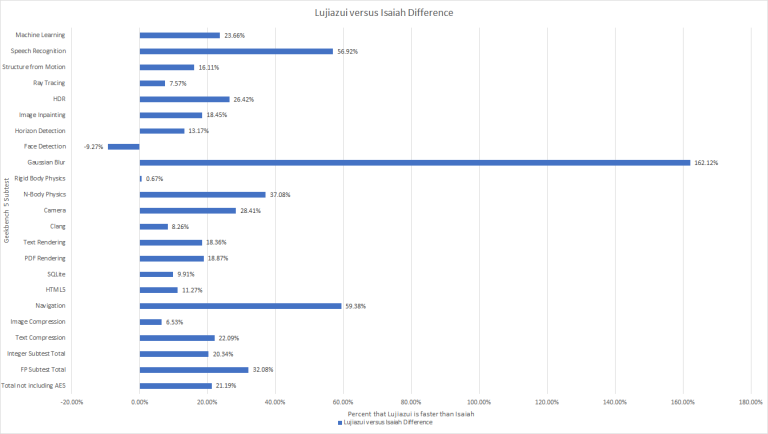
Looking at the raw Geekbench 5 scores, Lujiazui just runs away with the win but the KX-6640MA is also at over double the clock speed of the U4025 so you would expect Lujiazui to win but one place where Lujiazui has a huge lead over Isaiah is in the AES subtest and the reason for this is that Lujiazui has cryptograph acceleration and Isaiah, nor any of the other CPUs in this test, simply does not.
Now looking at the clock normalized results, Lujiazui pulls out wins for the most part but there are a few subtests where there was minimal improvement over Isaiah and even one subtest, face detection, where there was a regression in the clock normalized results. However on average, Lujiazui is roughly 20 to 30 percent faster then Isaiah per clock which is inline with Zhaoxin’s claim of a 25% increase in performance per clock.
Lujiazui versus the Competition: Integer Subtests
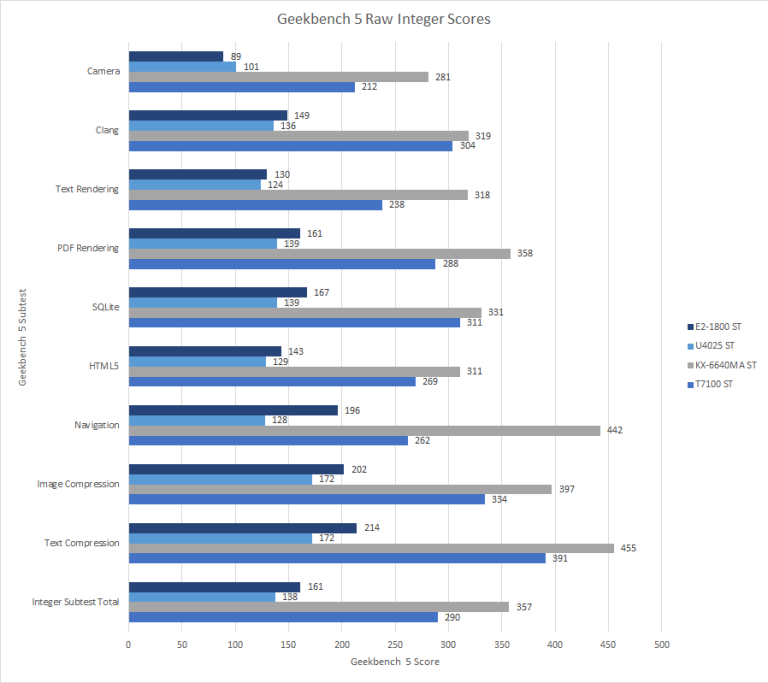
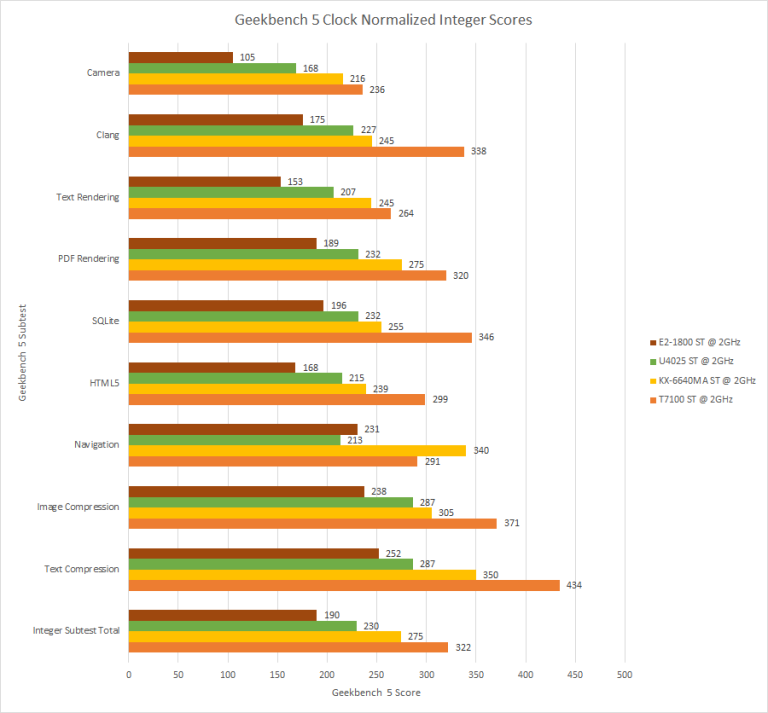
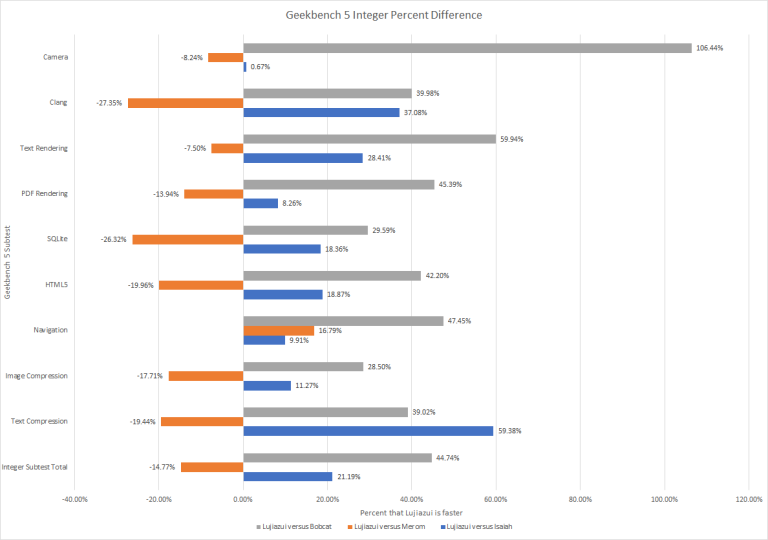
Comparing Lujiazui to the other architectures in Geekbench 5’s Integer subtests shows that while Lujiazui is beating the pants off of Bobcat, it is still behind Merom with the only place where Lujiazui takes a win versus Merom is in the Navigation subtest.
Lujiazui versus the Competition: Floating Point Subtests
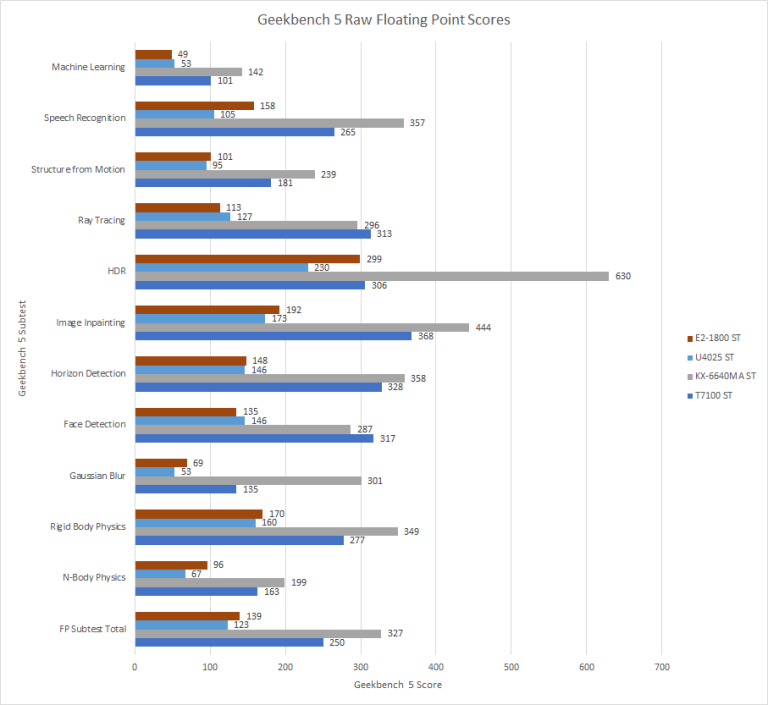
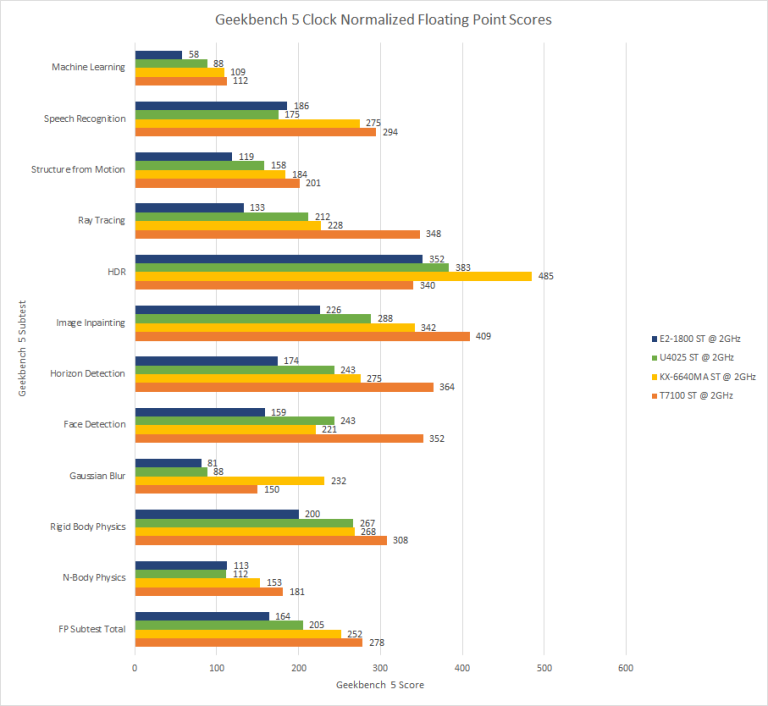
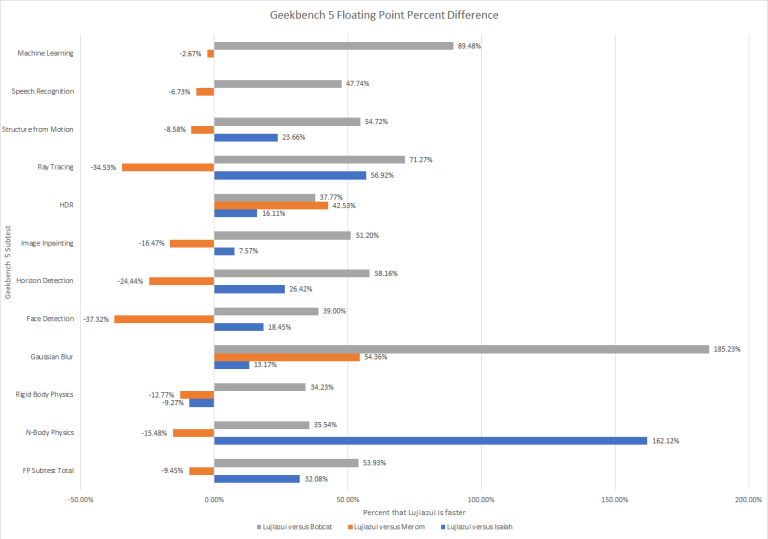
Now comparing Lujiazui in Geekbench 5’s Floating Point subtests to the competition is a little more positive compared to the Integer subtests and there are now 2 subtests where Lujiazui beats Merom and in the FP subtests, Lujiazui just kicks Bobcat to the curb and it is no contest.
Lujiazui versus the Competition: Rounding out the Totals
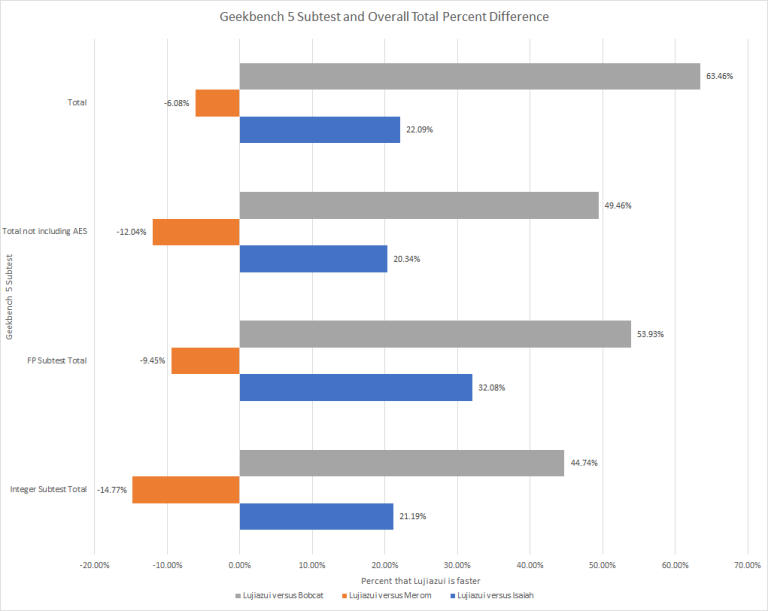
In the end, even when factoring in the AES acceleration that Lujiazui, Lujiazui still loses to a 15 year old architecture which needless to say is not a good look for Lujiazui or Zhaoxin if they are truly are trying to catch Intel and AMD.
The Future of Zhaoxin and their Architectures
Well….. this section has had to have a rewrite due to Centaur seemingly being acquired by Intel in the past week or so. The relationship between Centaur and Zhaoxin is a complex one that we outlined in Part 1 of this series but the short of it is that Zhaoxin uses modified versions of Centaur’s architectures rather then making a new design completely from scratch so with Intel grabbing the people from Centaur’s design office in Austin, the future for Zhaoxin is not looking too bright at the moment however the details of this deal are far from clear at the moment.
However, lets assume that at the very least Centaur sent over the design for their CNS microarchitecture to Zhaoxin before the buyout by Intel. The CNS architecture will be a very large uplift over Lujiazui with Geekbench 5 giving CNS roughly a 2x increase in performance per clock over Lujiazui. However in Geekbench 5, CNS has roughly the same performance per clock as Sandy Bridge which is a decade old architecture which while an improvement over Lujiazui, still is not close to where Intel and AMD is in terms of performance per clock.
Now, if Centaur did not transfer CNS’s IP to Zhaoxin then Zhaoxin is going to have to iterate on Lujiazui which is even further behind Intel and AMD then CNS is however I think that Zhaoxin can take some queues from Jaguar’s improvement’s to Bobcat which yielded a roughly 50 percent performance per clock increase. What AMD did was increase the size of certain structures in the core like the AGU scheduler and improved the L1 and L2 BTBs along with reducing latency of certain math operations. AMD also widened the FPU pipes from 64b to 128b, which is already the case for Lujiazui but Zhaoxin could make the FPU pipes 256b wide to improve AVX operations which is a large weakspot for Lujiazui.
Now something interesting we were told by AtopNUC, the makers of the Zhaoxin system we used for our testing, is that Zhaoxin apparently will be launching a new CPU series later this year. Now what that series could be, I am unsure however my best guess is that it is that it could be Lujiazui with proper AVX2 support considering that there is a GCC optimization target that has roughly the ISA level of Haswell but has a few missing instructions which exclude Intel and AMD CPUs from the possible CPUs it could be.
Regardless, if Zhaoxin does what to try and match AMD and Intel then they have a long road ahead of them however, they did achieve the 25 percent performance per clock improvement over Isaiah that they claimed so kudos to them for achieving that feat.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way.