
The Weird and Wacky World of VIA, the 3rd player in the “Modern” x86 market

Header Image credit goes to Martijn Boer.
In the world of x86 CPUs there are two major players, Intel and AMD. However, there is one (well two but that will be expanded on later) other company that designs and produces CPUs that are fully compatible with modern x86 extensions, yes even AVX, and that company is VIA.
How VIA got the x86 license is a bit of a messy story that involves the purchase of both Cyrix from National Semiconductor and Centaur Technology from Integrated Device Technology, but in the end VIA ended up with an x86 license and is currently designing and developing x86 compatible CPUs.
VIA’s Cores through Time
When VIA acquired Cyrix and Centaur, there were several cores in design. From Cyrix there was a brand new core by the name of Jalapeno. Jalapeno was a spicy 2-wide out of order design with an on-die RIMM memory controller. Cyrix also had a more modest Cayenne (later renamed Joshua) core which was less a revolution and more an evolution of the MII. Meanwhile, VIA got the Samuel core from Centaur.
VIA scraped both cores from Cyrix, Joshua and Jalapeno, and purchased the Samuel core from Centaur as VIA were focusing on low power designs which neither the Joshua or Jalapeno core were targeting.
The Samuel core and its many derivatives were used in the Cyrix III (later renamed to the C3 as it was not based on Cyrix tech) all the way up to the VIA C7.
The Samuel core which dates back to 2000 was replaced in 2008 by the Isaiah core. The Samuel core which dates back to 2000 was replaced in 2008 by the Isaiah core. Isaiah was a very ambitious design at the time, a low-power fully out-of-order core in 2008 was not trivial, considering the nodes from the time, and as a reminder Intel’s Bonnell core was a dual issue in-order core also from 2008. Yes ARM did have a out-of-order core in 2008 in the form of the Cortex A9 but as pointed out in our article about how ISA doesn’t matter, A9 lost to Bonnell in terms of both power and performance so for VIA to also trying a fully out-of-order CPU in 2008 was an ambitious project. Isaiah was first fabbed on Fujitsu 65nm and then later shrunk to TSMC 40nm. Furthermore, it was shrunk even more down the line from the aforementioned TSMC 40nm to TSMC 28nm and renamed Isaiah II.
VIA’s latest core built on TSMC N16, CNS, has yet be be released in any shipping products, is a very large jump compared to Isaiah. In the grand scheme of CPU design, in the year 2021, it looks to be fairly lackluster, however, and is nowhere near as ambitious as Isaiah sadly.
VIA’s Isaiah: You Call This Low-Power?
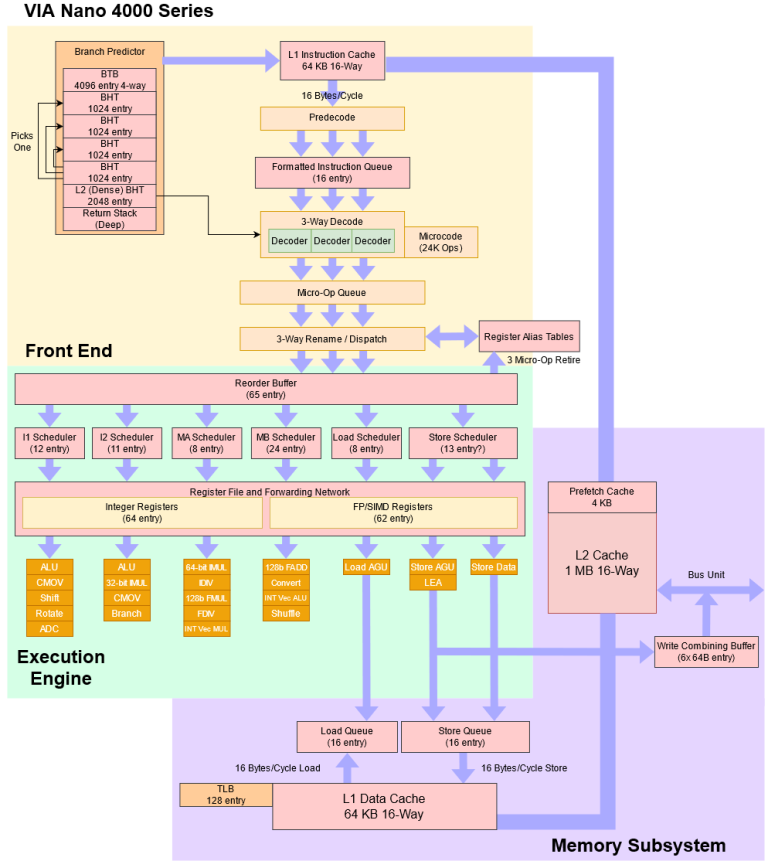
Isaiah is very complex for a low-power core. That’s clear just from a mile high block diagram.
For comparison, here’s Intel’s Pentium III, which was discontinued just a year before Isaiah launched as VIA Nano.
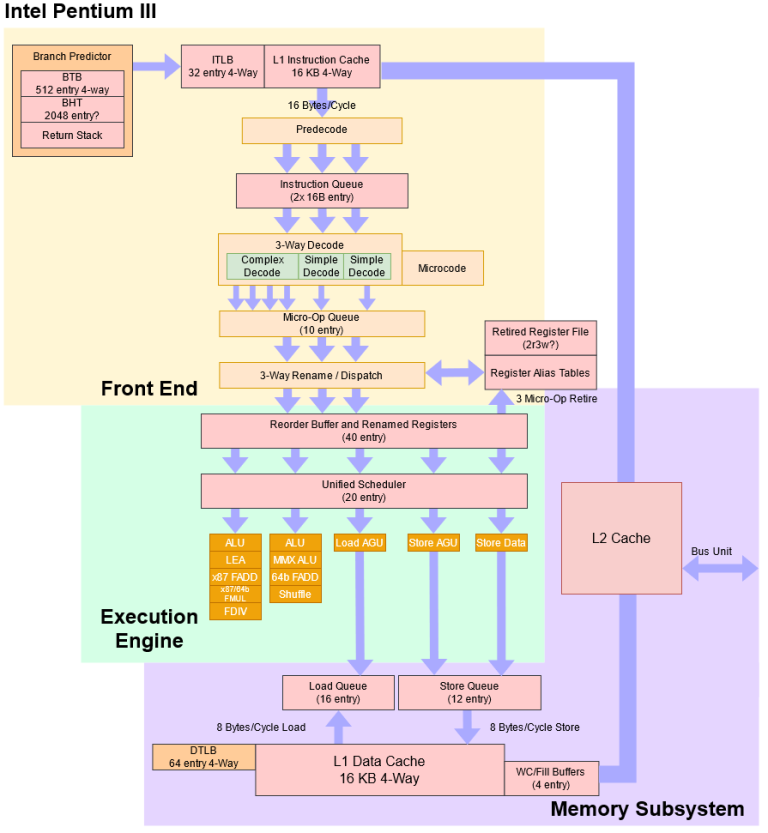
Compared to Intel’s prior “big core”, VIA Nano is giant. It’s deeper and wider with bigger L1 caches, but VIA’s engineers didn’t stop there.
Let’s start with the branch predictor, where VIA took things to the next level.
The Complex Maze that is Isaiah’s Branch Predictor
The branch prediction unit (BPU) tells the core where to fetch the next instruction from. If there’s no branch, obviously you just keep fetching instructions in a straight line. But if there is, the BPU must decide whether the branch is taken. If it is taken, the BPU needs to determine where the branch is going (and preferably do so quickly to avoid keeping the instruction fetch unit waiting).
Let’s look at speed first. As described in our previous article, this test shows how fast the BPU can provide the branch target.
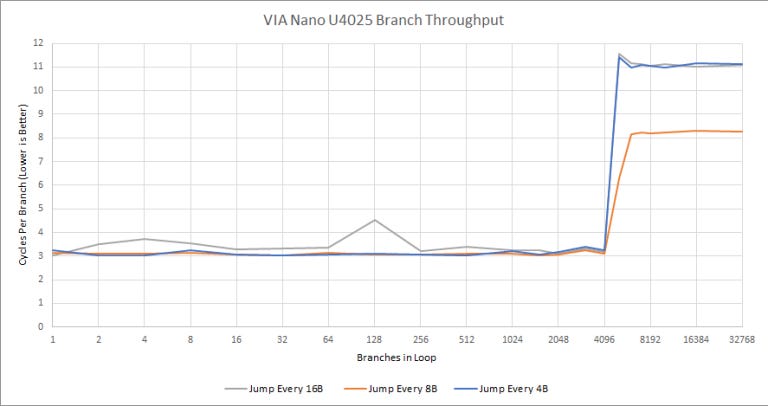
VIA says they used a 4096 entry 4-way BTB to cache branch targets, and our results confirm that. For 2008, that’s insane. AMD’s Bobcat only has a 512 entry BTB. Even big cores like Intel’s Conroe and AMD’s K8/K10 only had 2048 entries. Intel didn’t bring out a 4096 entry BTB until Sandy Bridge in 2011.
But this huge BTB doesn’t come for free and ends up being a bit slow. Nano can only do one taken branch every three cycles. Or alternatively, the instruction fetch unit sits around doing nothing for two cycles (bubbles) after a taken branch while the branch predictor grabs the branch target out of the BTB.
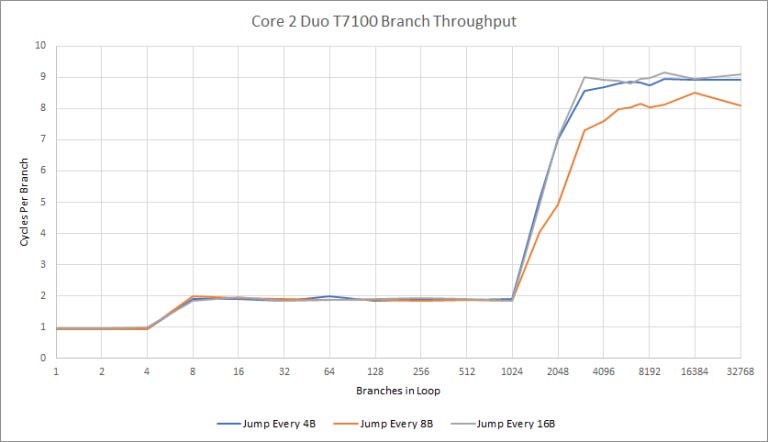
Core 2 uses a smaller and faster BTB capable of handling a taken branch every two cycles. If there are four or fewer taken branches in play, Core 2 can do “zero bubble” branch prediction.
Now let’s look at Bobcat’s approach.
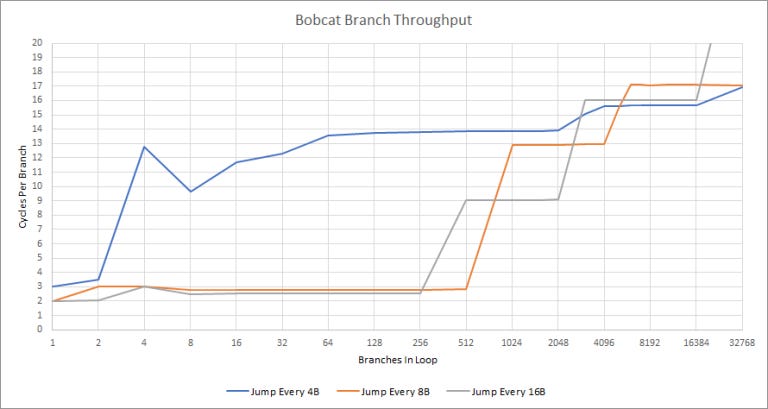
Bobcat’s BTB isn’t as big as VIA’s, but it’s slightly faster. In the best case, Bobcat can do a taken branch every two cycles. Unlike VIA, Bobcat is also sensitive to branch spacing and can only utilize its maximum BTB capacity if branches are moderately spaced. Dense branches cause catastrophically bad behavior for Bobcat. It looks even worse than missing the BTB, so maybe Bobcat’s BTB isn’t even tagged at 4 byte granularity and ends up feeding wrong branch targets to the frontend, causing mispredicts.
Now that we’ve covered how fast the branch predictor is, let’s see how well it can track patterns. That should correlate well with how accurate it is. Unfortunately, we can’t compare real world accuracy because we couldn’t get performance counters to work on the Nano.
The X axis shows how long the repeating pattern is for each branch, while the Y axis shows how many branches are in play. The Z axis shows how much longer each branch took on average when the pattern was random, versus all 0s (branch always taken). We’re looking at the ‘wall’ here, and how far it is away from the origin. The farther, the better.

Nano uses a very complex direction predictor with four Branch History Tables (BHTs). Three of them predict whether a branch is taken, while the fourth predicts which prediction to use. This ‘tournament’ style predictor with competing prediction methods isn’t new, but saw more use on very high performance, high power designs. For example, DEC’s Alpha EV5 had three BHTs – one with local history, one with global history, and one for the meta predictor (that selects between the previous two). VIA didn’t disclose the exact prediction methods in play. But from the graph above, its pattern recognition abilities are quite impressive.
For perspective, compare this to Core 2, a contemporary “big core” design. Intel’s BPU uses a 8-bit Global History Buffer1.
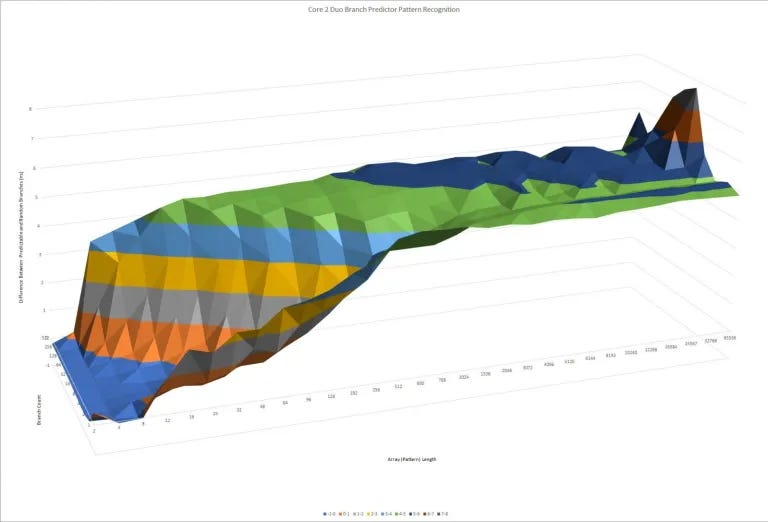
And as you can see, in this test, Isaiah’s BPU wins hands down.

Bobcat lands somewhere in between. It’s not quite as good as Isaiah, but is better than Core 2.
Taking a step back, VIA preferred a more complex frontend design. The instruction cache is large with high associativity. Decode is 3-wide (wider than any low power x86 core until Intel’s Goldmont came out in 2016). And the branch predictor is incredibly sophisticated for 2008. For Bobcat, AMD opted for a narrower frontend with smaller caches and a less capable (but lower latency) branch predictor.
VIA kept the same philosophy for Isaiah’s backend.
A Very Capable Out of Order Engine
A 65 entry reorder buffer (ROB) is massive for the time, for context Bobcat has a 56 entry ROB and is 3 years newer. This beefiness also follows in the integer and floating point register files where Isaiah has 46 integer and 48 SIMD/FP registers for renaming. Comparatively, Bobcat has 34 integer registers and 21 FP registers available for renaming.
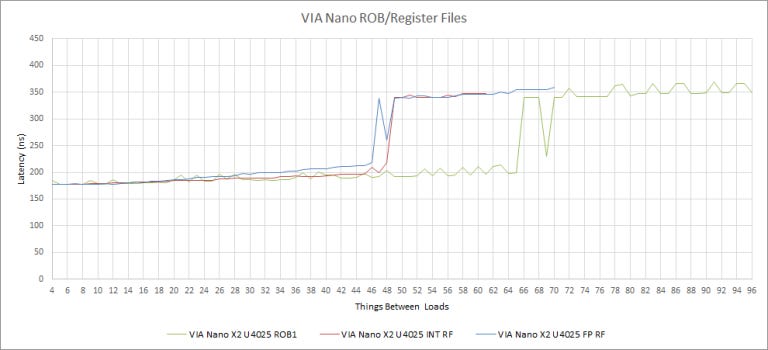
We got some mixed results with our microbenchmarks in regards to Isaiah’s ROB size. On Windows we observed a 48 entry ROB, however on Linux saw a 65 entry ROB. We have not observed that kind of discrepancy with any other CPU in our testing; we went with the higher value because it’s clear that Isaiah’s ROB can hold more than 48 micro-ops.
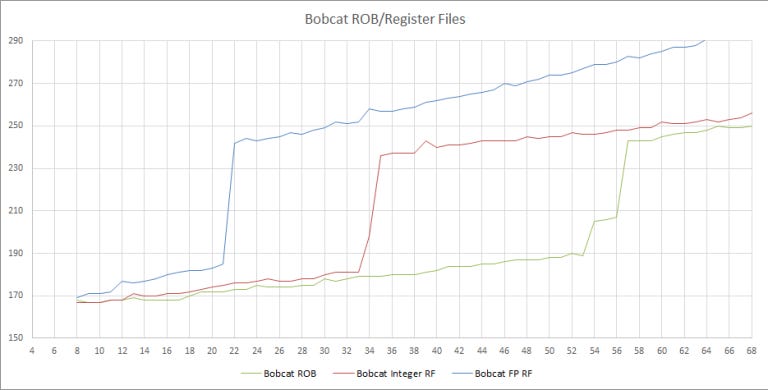
AMD’s Bobcat didn’t emphasize FP/SIMD reordering capacity as much as VIA did. The difference here is especially exaggerated because we used 128-bit packed integer operations to test the FP/SIMD register file. Bobcat breaks those into 2×64-bit operations, and thus consumes two 64-bit registers for each 128-bit operation.
VIA says in the Isaiah whitepaper that both the load and store queues are 16 entries each and our microbenchmarks show this for the most part.
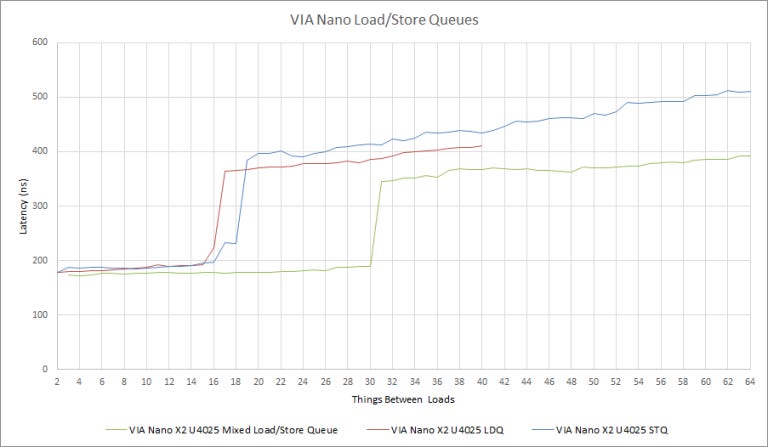
Compared to Bobcat, Isaiah as 6 more load queue entries but 6 fewer store queue entries. Core 2 has 4 more load queue entries and double the store queue entries that Isaiah has.
The load/store unit is one of the only places where Isaiah looks normal for a low power architecture. It’s laid out differently than Bobcat, and has a slightly bigger store queue than Intel’s older Pentium III.
A Big Distributed Scheduler
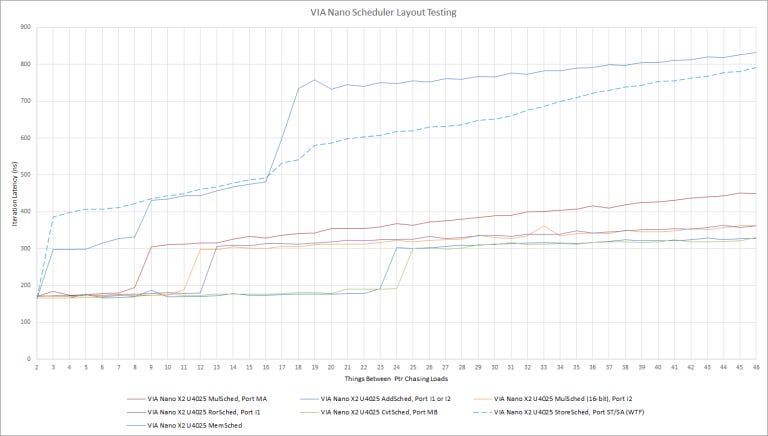
We couldn’t directly measure the store scheduler’s size. Unlike newer CPUs, Nano does not allow a load to execute ahead of a store with an unknown address. This restriction is understandable, as this memory dependency speculation just debuted in Intel’s Core 2 architecture. AMD didn’t do this until Bulldozer launched in 2011.
In the Isaiah whitepaper, VIA says there are a total of 76 entires across all of the reservation stations. To estimate the store scheduler’s size, we subtracted our estimates for the other schedulers from 76, to get 13 entries.
Thus, the break down of the individual scheduling queues is as follows:
Integer 1 – 12 entires
Integer 2 – 11 entries
Media A – 8 entries
Media B – 24 entries
Load – 8 entries
Store – Most likely 13 entries
Relative to Bobcat, Isaiah has 14 more SIMD scheduler entries total, 7 more Integer scheduler entries, and 13 more Load/Store entries, or to put it another way “Bloody Huge”. Now, Core 2 has a fully unified 32 entry scheduler, which while smaller then both Isaiah and Bobcat in terms of number of entries, is more flexible and can do well with fewer entries.
Nano’s Wide and Fast Execution Engine
For a low power architecture, Nano’s designers built a very powerful execution engine. The Media A (MA) and Media B (MB) ports feature 128-bit wide execution units and datapaths, matching Intel’s Core 2 in vector throughput. Low power cores didn’t have that kind of vector throughput until AMD’s Jaguar architecture debuted in 2013. The MA/MB schedulers together have 32 entries – more than the SIMD scheduler on AMD’s Bobcat and Jaguar.
VIA’s engineers didn’t stop at hitting big core FP/SIMD capability on a “low power” core. According to Agner’s instruction tables, floating point addition latency is just two cycles, faster than any contemporary (or modern) CPU. FP multiply latency is three cycles. For comparison, Skylake does floating point adds and multiplies with four cycle latency, and Zen 3 does both with three cycle latency.
Similarly, Nano’s L1D can return data in two cycles. If that’s not impressive enough already, remember that it’s with a 64 KB 16-way cache. Assuming address generation and TLB lookup takes a cycle, Nano is checking 16 tags and getting data back in one cycle. That’s insane. At the time, 3 cycle L1D latencies were typical, with 64 KB 2-way (Athlon) or 32 KB 8-way (Core 2) caches. Today, L1D latency is around 4 cycles (or 5 cycles on Intel’s Ice Lake and Tiger Lake cores).
Wrapping Up: Hitting the Wrong Target?
Isaiah is unique and very ambitious. Perhaps too ambitious for its own good.
In places Isaiah, remember this is a “Low-Power” design, is bigger than Core 2 which only came out a scant 18 months before Isaiah on a similar class of node. In almost all areas, Isaiah is also wider than Bobcat which came out 3 years after Isaiah, on a smaller node than Isaiah’s launch node.
Now to add some anecdotal evidence, when I was testing all 3 platforms for this article, the Nano output either similar amounts or seemingly more heat than the Core 2 Duo. For some context, the Nano was able to keep my coffee above lukewarm which is quite impressive; the Bobcat system was easily the coolest of the three.
Clearly Nano wasn’t very low power. But it also wasn’t high performance, so Nano’s priorities need some explaining. I especially wonder why Nano’s design team used full 128-bit vector execution units, and made them very low latency. That can’t have been cheap in terms of power. One possibility is that VIA’s engineers targeted multimedia applications like video playback. That would explain why Nano’s FP/SIMD ports are named “Media A” and “Media B”. But hardware video decoders became very prevalent not long after Nano debuted, leaving Nano’s powerful vector units in an awkward spot.
Isaiah’s large, fast L1D and powerful branch predictor are also culprits. Low latency and high associativity scream high power and low clocks. The branch predictor is a bit more difficult to analyze. Nano went all out for accuracy, but paid the price in frontend latency. With 20-20 hindsight, we can see AMD reduce branch predictor related frontend bubbles generation after generation, and conclude that branch predictor speed is more important than VIA thought it was.
Ultimately, Isaiah represents an ambitious attempt by VIA to compete with AMD and Intel. There’s no doubt VIA had a capable and determined engineering team. But creating a successful CPU is all about anticipating important workloads and correctly tuning the architecture for them. Intel and AMD correctly guessed that video playback would be offloaded. Also, Intel/AMD are larger companies with extensive simulation resources that can better guide engineering decisions. Both developed low power architectures that were narrower and less sophisticated architectures than Isaiah, but more than made up for it with higher clock speed and careful resource allocation.
Now in the very beginning I said how there is a fourth x86 design house, and that is true, however Zhaoxin is a joint venture between VIA and the Shanghai Municipal Government. If you paid attention to our ISA doesn’t matter article you would know that we have a Zhaoxin CPU, in-house, ready for testing. Because of time constraints, the full in-depth dive into that CPU will have to wait for a part 2 to this article. However, from what testing we have done with Zhaoxin’s newest microarchiture, Lujiazui, it’s more evolutionary than revolutionary.