
AMD's Turin: 5th Gen EPYC Launched
5 Gigahertz Server CPUs

Hello you fine Internet folks, for today we have a video and an article for y’all.
Unlike our prior Granite Rapids coverage where we just had a video, we have had hands-on with Turin, specifically the AMD EPYC 9575F, thanks to Jordan from StorageReview.
This article is going to be a little different from our usual. It’s going to be shorter than usual because we have already covered the Zen 5 core both in mobile and in desktop and the differences between them, so this article will be focused on the memory subsystem changes that Turin has.
Serve the Home has an excellent article that has the slides that AMD has put out for the launch of Turin. But because we have our own data, I thought that our data would be more interesting to dive into.
Memory Bandwidth
First, looking at the 1T results, we see that the 9575F can pull around 52 GB/s of memory read bandwidth, 48 GB/s of memory write bandwidth, and 95 GB/s of memory add (Read-Modify-Write) bandwidth.
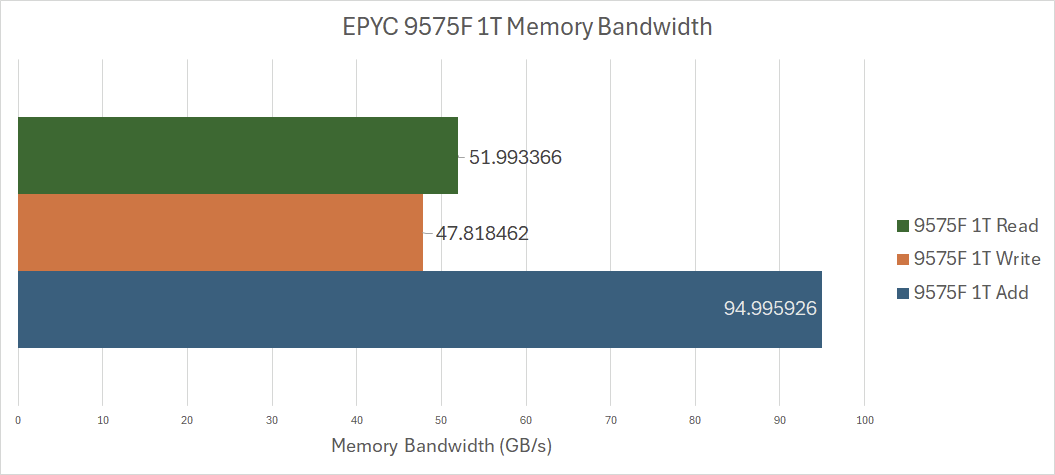
And looking at the results for how much memory bandwidth a single CCD can get, we can see that a single core can use just under half the total CCD memory read bandwidth, about 55% the total CCD memory write bandwidth, and over two-thirds the total CCD memory add bandwidth.

Looking a bit closer at these results, you’ll notice that the 9575F has significantly higher bandwidth to a CCD compared to the desktop Zen 5 parts. And the reason for this is the 9575F has GMI3-W which means that it has 2 GMI links to the IO die instead of the single GMI link that the 9950X gets.
And this is not only the only change to the GMI links on server. The GMI write link is now 32B per GMI link instead of the 16B per GMI link that you’d see on desktop Zen 5.
Before moving to the full socket memory performance for the 9575F, let’s clear up the memory speeds that Turin supports. Turin has 12 channels of memory that can run up to DDR5-6400MT/s, however 6400MT/s is only supported on specific validated systems and only for 1 DIMM per channel.

The system we had access to was running 6000MT/s for its memory, and DDR5-6000 MT/s is what most systems will support in a 1 DIMM per channel configuration. Should you want to run 2 DIMMs per channel, then your memory speeds drop to 4400 MT/s; and if you run 1 DIMM per channel in a motherboard with 2 DIMMs per channel then expect 5200 MT/s for your memory speed.

Now, actually diving into the memory of the full 9575F and we see that we can get nearly 99% of the theoretical 576 GB/s of memory bandwidth using reads. Writes and adds are still an impressive 435 GB/s and 453 GB/s respectively.
We also tested the socket to socket bandwidth on AMD’s Volcano Platform which only has 3 GMI links between the two 9575Fs.
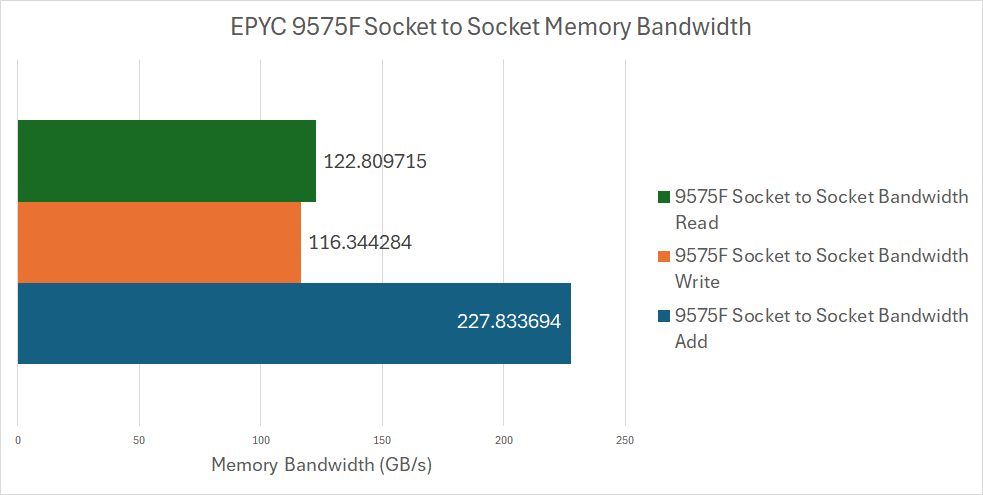
These results are very similar to our Bergamo results, which isn’t surprising because that system also had the same 3 GMI link setup.
Memory Latency
Moving to memory latency, we see that Turin’s unloaded memory latency is very similar to Genoa’s unloaded memory latency.

At Hot Chips 2024, Ampere Computing showed a graph demonstrating the loaded memory latency of an AmpereOne chip and AMD’s Genoa CPU. Now Chester wanted to make a test similar to this, so he made a loaded latency test.
The way that this test works is that it runs our memory bandwidth benchmark on either 7 cores on a CCD or 7 CCDs on the 9575F. This ensures that the IOD to CCD link or the whole memory system is fully loaded. Then, with the 8th core or 8th CCD, we run the memory latency test to see what the latency of the fully loaded system is.

When a single CCD is loaded up on the 9575F, we see about a 39 nanosecond increase between the unloaded and loaded latency.

When the whole system is loaded, we see about a 31 nanosecond increase between unloaded and loaded system latency.
Looking at the single CCD results compared to the fully loaded system results, the 9575F has very similar memory latency behavior regardless if a single CCD is loaded or if the whole system is loaded.
And lastly, everyone’s favorite graph, the core to core latency graph.

For convenience, the list below are the numbers from the chart because a chart this big can be hard to read.
Intra-CCD latency: ~45ns
Inter-CCD latency: ~150ns
Socket to Socket latency: ~260ns
This is a latency increase compared to Genoa, especially within a CCD.
Clock Speed
Now, a note about the clock speeds we saw with the 9575F. All 64 cores could hit up to 5GHz in single threaded test. This is quite impressive, but we were able to get all 8 cores in a CCD to run at 5GHz in our memory bandwidth testing.
And with all 128 threads chugging away on Cinebench 2024, we saw the 9575F sticking around the 4.3GHz range. Wendell from Level1Techs saw about 4.9GHz all core on a web server/TLS transaction workload, which is a less vectorized workload.
Conclusion
Realistically, AMD’s Turin is the generational update you’d normally expect. Not only does AMD have high core count SKUs (9755, 9965), which the hyperscalers will be picking up, they now also have lower core count, very high frequency SKUs (9575F) which the traditional enterprise market will appreciate. Apparently we now think 64 cores is ‘lower core count’. What a world we live in.
Turin isn’t the step-function revolution that Naples to Rome was; it’s more akin to the evolution we saw with Milan to Genoa, which was a memory bandwidth increase, a core increase, and a core update. Nonetheless, this generation is set to excite a lot of people, as there’s lots of value here in a very competitive ecosystem.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.
What about avx-512 performance? (Yeah, also for LLM inference!)
Could you benchmark llama.cpp/olllama?