
Testing AMD’s Bergamo: Zen 4c Spam

Server CPUs have pushed high core counts for a long time, though they way they got high core counts has varied. Bergamo is AMD’s move to increase core counts beyond what scaling up an interconnect can do, by using density focused Zen 4c cores. It’s a strategy with parallels to Intel’s upcoming Sierra Forest and Ampere’s server CPUs. Ampere in particular has shown there’s a market for server chips that prioritize core count, especially with cloud providers that rent compute capacity by the core. More cores lets them serve more customers with each physical server.

Beyond cloud providers, density focused designs can provide higher performance with highly parallel applications. Improving per-core performance quickly runs into diminishing returns, so adding more cores is an easier way to improve performance.
To hit those markets, Bergamo uses a density focused variant of AMD’s Zen 4 cores. Zen 4’s architecture remains untouched, but Zen 4c uses a physical implementation that trades high clock speeds for reduced area usage and better power efficiency at low clocks. More Zen 4c cores fit into the same silicon area, allowing higher core couts.

At the system level, Bergamo reuses AMD’s Zen 4 server (Genoa) platform. Core Complex Dies, or CCDs, are arranged around a center IO die to create a hub and spoke configuration. Of course, Bergamo swaps out the standard Zen 4 CCDs in favor of Zen 4c versions.
Acknowledgment
Before we get into the article, we would like to thank Hot Aisle for access to the system for 2 weeks so that we could run all of our tests and benchmarks.
The Zen 4c CCD
Zen 4(c) cores are built into clusters, which AMD refers to as Core Complexes, or CCX-es. A Zen 4 CCX has eight cores with 32 MB of shared L3 cache. Zen 4c uses smaller cores and cuts shared L3 capacity down to 16 MB, much like mobile designs. That lets AMD put two CCX-es on the same CCD.
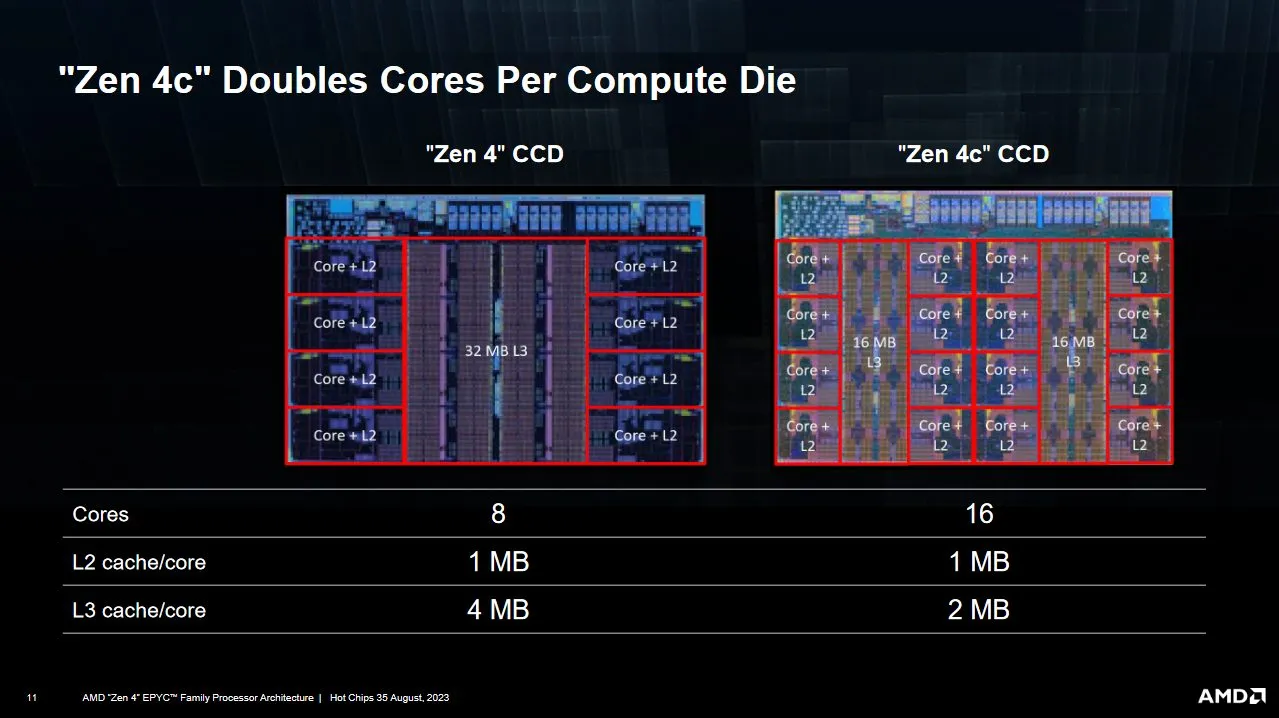
The result is twice as many cores in roughly the same area.

L3 differences are visible from a latency test. Curiously the 16 MB L3 has similar latency to AMD’s highest capacity VCache L3 setup. VCache puts a 64 MB cache die on top of a standard Zen 4 CCD, providing 96 MB of total L3. VCache adds a couple cycles of latency, and we curiously see something similar with Zen 4c’s 16 MB L3.

A smaller L3 will result in a lower hitrate, which in turn creates more memory traffic. Servers already have less memory bandwidth per core than client CPUs do. Bergamo pushes core counts even higher but uses the same 768-bit DDR5 memory configuration as Genoa. To really shine, Bergamo will need programs that don’t suffer a lot of misses with a 16 MB L3. In the other direction, lower clock speeds should lower per-core bandwidth demands because there’s less compute power to feed.

Lower clock speeds also affect latency. Even with the Ryzen 7950X3D locked to its 4.2 GHz base clock, latency differences can be quite dramatic. 16.89 ns of L3 latency is a lot worse than 13.35 ns, especially when vanilla Zen 4 has a larger L3 to start with. DRAM latency is also lower on the client platform, at around 86.9 ns compared to 120 ns on server.
The two CCX-es on a CCD share one interface to the IO die, leading to interesting bandwidth scaling behavior we load one CCX at a time. Consecutive pairs of CCX-es seem to be located on the same die and see less scaling, leading to a stepped pattern. Memory bandwidth scales far better if we load one cluster on each die first. In fact, maximum bandwidth can nearly be achieved with one CCX loaded on each CCD.

With all cores loaded, Bergamo achieved just short of 360 GB/s of DRAM read bandwidth. It’s not quite the 460 GB/s theoretically possible from a 768-bit DDR5-4800 configuration, but bandwidth is still impressive in an absolute sense. For comparison, John D. McCaplin at TACC measured 237 GB/s of DDR5 read bandwidth from Sapphire Rapids. Bandwidth further increases to 378 GB/s with a read-modify-write pattern, creating an equal amount of read and write traffic. That’s over 82% of theoretical, and a pretty good result.
Dual Socket Characteristics
Another way of scaling up core counts within one sever is to put more sockets in it. Bergamo can be set up in a dual socket configuration, letting it scale to 256 cores. The two sockets are connected with Infinity Fabric links, letting cores on one socket access DRAM attached to the other at relatively high bandwidth. However, getting to memory on the other socket (remote memory) still comes with a performance penalty compared to accessing directly connected DRAM (local memory). Latency differences are clearly visible once accesses spill into DRAM if we allocate memory physically located on the other socket.

While the latency penalty is quite large, it’s roughly in line with Milan-X, or Zen 3 server with VCache. Both Milan-X and Genoa-X (Zen 4 server with VCache) were set up in NPS2 mode in a cloud environment. Our Bergamo test system used NPS1 mode, so a socket appears as one NUMA node. Because NPS2 mode might change cross-socket latency characteristics, drawing conclusions on relatively small differences isn’t advisable.

What we can see though, is that older designs do have some advantages. The Xeon E5-2660v4 uses Intel’s older Broadwell architecture, and is equipped with lower latency DDR4. Couple that with fewer cores in a relatively small monolithic die, and memory latency for both remote and local accesses is better than Bergamo’s. Even though going cross-socket on Broadwell adds more additional latency, the configuration ends up performing quite well anyway. Going further along that route, Intel’s Westmere from 2010 has even better latency characteristics. With just 6 cores per socket, Westmere’s interconnect is far less complex than the ones on modern server CPUs. Combine that with low latency DDR3 controllers, and Westmere can access memory attached to the other socket with similar latency to accessing the local DRAM pool on Zen 3 and Zen 4 server chips.
Cross-socket links also come with a bandwidth penalty. On Bergamo, one socket can read from the other’s DRAM pool at over 120 GB/s. Genoa-X wins by a hair, possibly because the NPS2 configuration reduces contention on the IO die’s Infinity Fabric setup. Both Zen 4 server chips enjoy much higher cross-socket bandwidth than the prior gen Milan-X. However, cross-socket bandwidth is less than half of local DRAM bandwidth on Zen 3 and Zen 4, so a non-NUMA setup would leave a lot of memory bandwidth on the table. To really benefit from today’s very high core count servers, you want your applications to be NUMA-aware.

Older server CPUs like Broadwell really start to fall behind here, showing the limitations of older interconnect technologies. However, Broadwell’s cross-socket links still cover a larger percentage of local DRAM bandwidth. That makes a non-NUMA setup more practical. A dual setup E5-2660v4 setup can achieve 101 GB/s of read bandwidth without NUMA, compared to 129 GB/s in cluster-on-die mode (NPS2). A 21% bandwidth reduction isn’t ideal of course, but a hypothetical non-NUMA Bergamo setup would face a more severe 32.2% bandwidth reduction. Westmere has the lowest bandwidth figures, but has the best ratio of cross-socket bandwidth to local DRAM bandwidth. Running Westmere in a non-NUMA setup could probably be done with little bandwidth penalty, as long as you don’t get latency limited.
Testing Bergamo with a read-modify-write pattern nearly doubles cross-socket bandwidth, indicating the cross-socket links are duplicated in each direction. It’s cool to see over 200 GB/s of bandwidth possible between sockets. Some low end GPUs like the RX 6600 have comparable VRAM bandwidth.
Core to Core Latency
Modern CPUs might have a lot of cores, each with their own caches. However, caches have to be transparent to programs. That creates a problem if one core writes to its own cache, and code running on another core wants to read that data. Cache coherency mechanisms help ensure programs can pass data between cores, but managing that quickly gets hard as core count increases and interconnects get more complex.
We can test how fast the interconnect can pass data between cores by having two cores alternately increment one value in memory. Testing one core pair at a time would be ideal, but Bergamo’s extremely high core count would make a normal run take forever. Therefore, I modified my core to core latency test to check multiple core pairs in parallel. I also avoided testing core pairs in parallel if a test thread in one pair would use the same physical core as a thread in another pair. The results here might show slightly higher latency than a hypothetical run with one core pair tested a a time.

Since Zen, AMD has handled coherency at two levels. Each core complex maintains L2 shadow tags that track addresses cached in each core’s L2. Because L2 caches are inclusive of L1 contents, covering L2 is sufficient to cover L1 caches too. If an access hits in the L2 shadow tags, the core to core transfer can be carried out within the cluster with low latency. Cross cluster transfers get handled by AMD’s Infinity Fabric, which maintains probe filters to track what’s cached in each cluster. Data transfers between clusters incur higher latency, especially if the clusters are located on different sockets.
Bergamo can see somewhat high latencies, showing that such high core counts come with difficulty. The worst measured latency was just over 212 ns, and most cross socket accesses averaged around 200 ns. Cross-cluster transfers within a socket can often be handled with 100-120 ns of latency. Intra-cluster latency is of course very low at around 30-40 ns. Overall, latency characteristics are in the same ballpark as on Genoa-X, so AMD’s system architecture is doing a a decent job handling the higher core count.

Intel’s Sapphire Rapids enjoys better latency characteristics with intra-socket latency staying under 100 ns, and cross-socket latency somewhere around 120-150 ns. However, Sapphire Rapids maxes out at much lower core counts.
Some Light Benchmarking
With Bergamo, AMD now has three different Zen 4 CCDs. A standard Zen 4 CCD has eight cores and 32 MB of L3. A VCache variant expands L3 capacity to 96 MB but keeps the same core count. Bergamo’s Zen 4c CCD doubles core count but halves per-cluster L3 capacity. All three CCD types use the same Infinity Fabric interface to the IO die. I have a Ryzen 7950X3D with one VCache CCD and one standard Zen 4 CCD.
That provides a fun opportunity to compare all three CCDs, though not on even footing. On my 7950X3D, a single CCD achieves 53.05 GB/s of read bandwidth compared to 48 GB/s on Bergamo, likely due to Infinity Fabric clock differences. Bergamo’s Zen 4c CCDs therefore face the double whammy of having less memory bandwidth on tap, while needing more bandwidth due to higher core counts and less cache capacity per cluster. Zen 4 can also achieve higher clock speeds, but I’m leveling the playing field on that front by capping my 7950X3D to 3.1 GHz.
libx264 Transcode
libx264 is a video codec that’s supported just about everywhere. Here I’m transcoding a 4K gameplay clip. With matched clock speeds, a vanilla Zen 4 cluster on the 7950X3D is 4.2% faster than a Zen 4c cluster on Bergamo. The VCache cluster enjoys a more significant 13.8% lead.

However, a die-to-die comparison puts Bergamo a hefty 69.4% ahead. It might not two times faster, but it’s still a good result because performance doesn’t scale linearly with core count. Not all applications will load 32 threads, and libx264 doesn’t do that on the 7950X3D. With that in mind, Zen 4c is doing a great job at packing more compute performance into a single compute die.

Bergamo also provides a fun opportunity to see how much a smaller L3 hurts. Dropping capacity from 32 to 16 MB reduces hitrate from 64.3% to 57.6%.
7-Zip Compression
Here I’m compressing a 2.67 GB file. This isn’t the built in 7-Zip benchmark, which scales across as many cores as you can give it and tests both compression and decompression. 7-Zip can’t take advantage of that many cores when actually compressing a large file. This time, the vanilla Zen 4 CCX is 36.9% faster. Still, the Zen 4c CCD flips things around with a 34.7% performance advantage over the Zen 4 CCD when 7-Zip is allowed to use threads across both CCX-es.

Checking performance counters shows less of a L3 hitrate difference than with libx264. Having 32 MB of L3 helps, but the client platform’s much better memory latency probably accounts for most of its performance advantage.

VCache however really shines in 7-Zip. It’s more than 11% faster than the vanilla Zen 4 CCX, and 52% faster than a Zen 4c CCX. Even with everyone running at 3.1 GHz, it’s amazing to see how much performance difference there can be across three implementations of the same architecture.
It’s also good to see the Zen 4c CCD providing a hefty multithreaded performance uplift despite Infinity Fabric bandwidth limits and lower cache capacity. Intel is using a completely separate E-Core architecture to get area efficient multithreaded performance. AMD is doing exactly the same thing, just with a different physical implementation of the same architecture.
Final Words
Bergamo is AMD’s entry into the density focused server market, and gets there ahead of Intel’s Sierra Forest. AMD’s strategy deserves a lot of credit here. Using the same Zen 4 architecture lets AMD support the same ISA extensions across their server and client lineup. Validation and optimization effort carries over from Zen 4, saving time. Finally, reusing the server platform and IO die further drives down development time and costs. Zen 4c CCDs fit in where normal Zen 4 or VCache CCDs would.

AMD’s server platform also leaves potential for expansion. Top end Genoa SKUs use 12 compute chiplets while Bergamo is limited to just eight. 12 Zen 4c compute dies would let AMD fit 192 cores in a single socket. Of course having the physical space necessary doesn’t mean it’s possible. For example, various logic blocks might use 7-bit core IDs, capping core count to 128. But it does show how much potential AMD has to build even higher core count server CPUs. That potential extends to client offerings too. Just as a VCache die acts as a drop-in replacement to improve gaming performance, adding a Zen 4c die could be an interesting way to scale multithreaded performance.

Intel’s Sierra Forest also reuses the platform and IO chiplets. However, Sierra Forest’s E-Cores have a different core architecture than the P-Cores in Granite Rapids. It’s a lot of extra work and causes mismatched ISA extension support across P-Cores and E-Cores. In exchange, Intel’s E-Cores can optimize for density on both the architecture and physical level, making them even smaller than Zen 4c. Sierra Forest can have up to 144 cores to Bergamo’s 128.
Besides Intel, Ampere is a contender to watch. Ampere One offers up to 192 cores using the company’s in-house Siryn architecture. Google Cloud has Ampere One in preview, and we look forward to checking out what those cores look like whenever those instances become generally available.
Again, we would like to thank Jon and Clint at Hot Aisle for letting us use the system, and if you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.