
Hot Chips 2023: Arm’s Neoverse V2


Arm has a long history in making low power CPUs, but have been trying to expand their reach into higher power and higher performance segments. At Hot Chips 2023, Arm presented the Neoverse V2, the newest member of their line of high performance server cores.
A new challenger re-enters the ring
Neoverse V2 itself is far from a new announcement, with the core being announced in September of 2022, almost a full year ago. The core has been announced long enough that we are now seeing the design being implemented in products, with the first known implementation being NVIDIA’s new Grace processor. Whilst this is far from unusual in terms of integration timelines, it does beg the question of how much more we can now learn from Arm about the technical details of the core design.
As mentioned previously, the Neoverse family has been expanding at a rather rapid pace, with the Neoverse N1 and V1 cores now being joined by Neoverse N2 and V2. Many chips have been produced using these core designs, with some of the most noteworthy being the widely deployed Ampere Altra and Altra Max, AWS Graviton 2 and 3, and the previously mentioned NVIDIA Grace chip. Ampere Altra and AWS Graviton have both made significant headways into the cloud computing market, with many organisations choosing to adopt these platforms as a way to improve energy and cost efficiency for their services.

NVIDIA Grace is the latest in this pack to have released and has had a number of design wins already. The Venado supercomputer at Los Alamos National Laboratory in New Mexico, USA has been announced as the first customer featuring Grace and Grace-Hopper superchips. NVIDIA claims that Venado can achieve ’10 exaflops of peak AI performance’, whatever that means in terms of comparable figures. Following this, the MareNostrum 5 supercomputer in Spain has been announced with a 2 petaFLOP CPU partition based on the Grace Superchip.
Whilst these wins may seem positive for the adoption of Arm in wider ecosystems, they still face an uphill battle, as competition from Intel and AMD grows stronger. The recent introduction of the Bergamo platform from AMD poses the greatest threat to the Arm server ecosystem so far, with nearly full Zen 4 performance in a 128 core cloud-optimised chip promising binary compatibility for existing workloads. AMD and Intel still also hold the crown for HPC wins, with the Intel-based Aurora and AMD-based El Capitan both anticipated to achieve exascale FP64 compute within the next year.
The Neoverse V2 Core
Neoverse V2 is an eight-wide out-of-order core with substantial execution resources and scheduling capacity. It aims to provide a generational performance increase over Neoverse V1, which should be expected because V1 is based off Cortex X1, while V2 is based off Cortex X3.
Frontend
At the frontend, Arm put a lot of work into improving performance with large, branchy instruction footprints. Much of this focuses on getting the branch predictor to run further ahead, hiding L1i miss latency. Neoverse V2 increases BTB capacity to a massive 12K entries, matching Golden Cove’s ability to remember taken branch targets. More BTB capacity lets the branch predictor stay ahead of the frontend for larger branch footprints. An 8-table TAGE predictor helps provide high prediction accuracy when dealing with conditional branches. Neoverse V2’s predictor can also track longer history lengths, helping it capture correlations between branches that are farther apart in the instruction stream.

Arm called their 64 KB L1 instruction cache small, which is an interesting comment considering AMD and Intel have settled on even smaller 32 KB instruction caches. Arm may have profiled a lot of workloads with code footprints that exceed 64 KB. In that case, Neoverse V2’s support for a larger 2 MB L2 cache would help keep more code close to the core.
For applications with smaller instruction footprints and higher IPC potential, Arm has optimized the frontend to handle taken branches faster. iTLB bandwidth has doubled, likely allowing two lookups per cycle when taken branches are frequent, but instruction footprint is small enough to not cause iTLB misses. Higher micro-op cache bandwidth helps mitigate the impact of losing frontend throughput around taken branches. However, this comes at the cost of a smaller micro-op cache. Arm is likely giving up on trying to keep most of a program’s instruction footprint within the micro-op cache, and instead focuses on capturing the hottest loops.
Neoverse V2’s micro-op cache bandwidth increase is matched by a corresponding increase in renamer bandwidth, bringing core width to eight micro-ops per cycle.

Because of the decrease in micro-op cache capacity, Neoverse V2 will use its conventional fetch and decode path more often. Therefore, Arm has increased decoder width from 5-wide to 6-wide, giving Neoverse V2 as much per-cycle decode throughput as Intel’s Golden Cove. A larger queue in front of the decoders helps absorb hiccups in instruction fetch, while renamer checkpoints let the core recover quickly from a branch mispredict. I assume the checkpoint saves register alias table state, allowing register renaming to resume as soon as instructions on the correct path become available. This feature is common to most modern CPUs, and can let the CPU hide the branch misprediction penalty by continuing to execute older operations in the backend while the frontend works on refilling the pipeline.
Backend
Once micro-ops have been renamed, they’re allocated into Neoverse V2’s out-of-order backend. Arm has equipped Neoverse V2 with ample scheduler capacity, continuing a trend we’ve seen with Cortex A710 and Cortex X2.

As for execution units, Neoverse V2 gets an additional two ALU pipes, meaning the core has six pipes capable of handling simple, common integer operations. Scheduler queues are arranged similarly to what we saw on Cortex A710 and Cortex X2. Two of the schedulers are each capable of picking two micro-ops per cycle to feed an ALU and branch pipe. Other schedulers are single ported and feed a single ALU pipe.
Vector and FP execution are handled by two dual-ported schedulers with 28 entries each. The scheduler arrangement is thus similar to Cortex X2s, where a pair of 23-entry schedulers feed four vector pipes. Cortex X2 and Cortex A710 both place a non-scheduling queue in front of the FP execution cluster, helping reduce renamer stalls when a lot of long latency FP operations are in play. Neoverse V2 almost certainly does the same.
Load/Store
Memory accesses get their addresses calculated by one of three AGU pipes. Each pipe has a 16 entry scheduling queue, providing ample scheduling capacity for in-flight memory operations. Prior Cortex X and Neoverse V series CPU appear to have some sort of non-scheduling queue in front of the AGU schedulers, and Neoverse V2 likely does as well. Also, store queue size has increased by 11% over Cortex X2, providing a total of 80 entries.

Like Cortex A710 and Cortex X2, two of the pipes are general purpose and can handle both loads and stores. The third pipe only handles loads. Neoverse V2 can therefore sustain three memory operations per cycle. This figure matches some x86 CPUs like AMD’s Zen 3 and Zen 4, but Intel and AMD’s CPUs generally have a data cache bandwidth advantage thanks to 256-bit (or greater) access widths using vector instructions. For integer code, which does cover a lot of target workloads like web servers, Neoverse V2 should be a very strong contender.
Address translation is handled by a 48 entry DTLB. Data footprints that exceed 192 KB are handled by a L2 TLB of unspecified size. Neoverse V1 has a decently sized 2048 entry L2 TLB, so hopefully ARM has at least maintained the same level of TLB coverage.
Memory Subsystem
To handle L1D (and L1i) misses, Arm uses a 2 MB, 8-way set associative L2 cache. The L2 is a banked structure capable of providing 64 bytes per cycle to L1 with 10 cycle load to use latency. At 3 GHz, that would be 3.33 ns, matching the 7950X3D’s L2 latency in absolute time, assuming boost is turned off to put the Zen 4 chip at 4.2 GHz. Sapphire Rapids would have slightly higher L2 latency at 4.24 ns.
Arm also uses the L2 cache to ensure instruction cache coherency. The L2 is inclusive of L1i contents, letting it act as a snoop filter for the L1i without having to check the L1i for every incoming probe. This is just one way to ensure L1i coherency. AMD’s old Opterons apparently kept a separate set of L1i tags to handle cross-core snoops instead of making the L2 inclusive. An inclusive L2 lets ARM handle coherency without worrying about snoops contending with regular data traffic at L1, but does mean some L2 capacity is taken up duplicating L1 contents.
Therefore, ARM only allows the L2 to be configured to 1 MB or 2 MB capacities. Both L2 setups are 8-way set associative and use four banks. In contrast, the client-oriented Cortex X3 offers 512 KB or 1 MB L2 configurations. In low core count mobile SoCs, instruction cache coherency is less important, so Cortex X3 can use a smaller, non-inclusive L2.
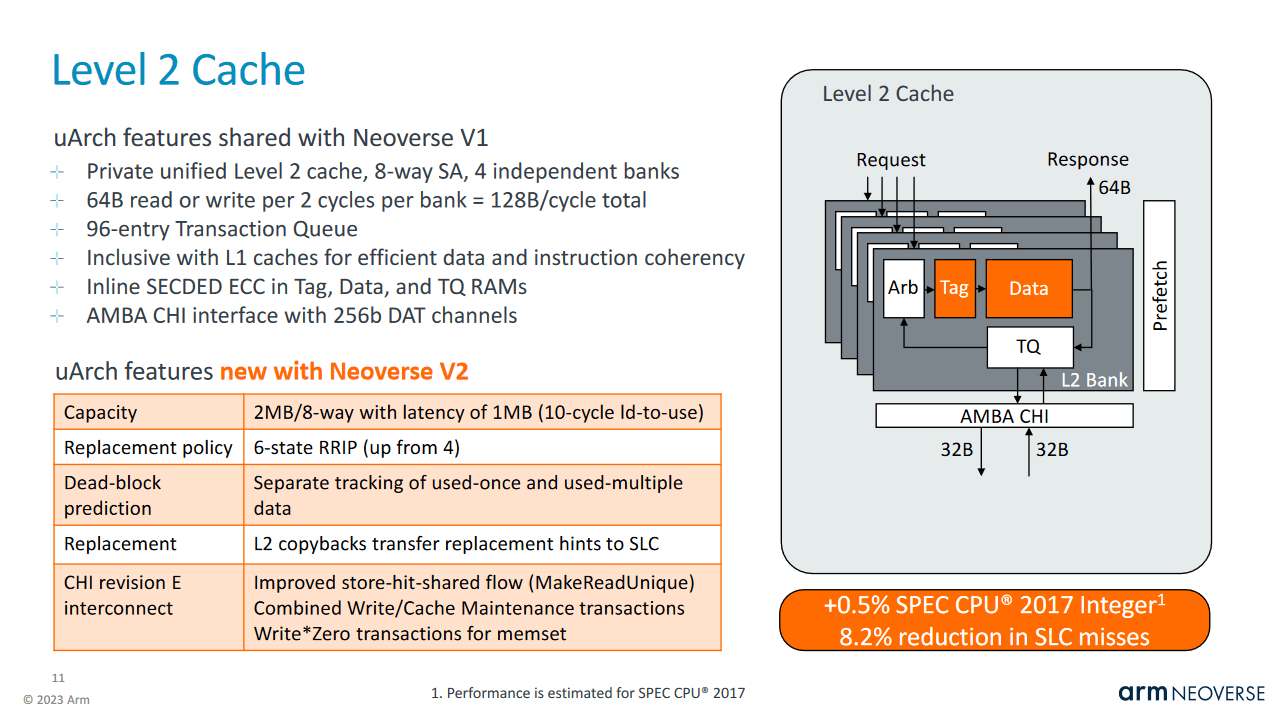
L2 misses are queued into a very large 96 entry transaction queue. For comparison, Intel’s Golden Cove can track 48 outstanding demand L2 misses. The transaction queue could be larger than 48, with some entries reserved for instruction-side requests, but V2 likely has a larger queue. Neoverse V2 likely has the same transaction queue configuration as Neoverse V1, where 92 entries can be used for outstanding read transactions. From there, requests are satisfied via a bidirectional 32 byte per cycle interface to the rest of the system.

At the system level, V2 cores are linked to each other and various forms of IO by Arm’s CMN-700 mesh interconnect. The CMN-700 mesh is also responsible for ensuring coherency with a distributed snoop filter setup. If implementers want to blow their reticle limits, CMN-700 can support ridiculously giant configurations with a 12×12 mesh and 512 MB of last level cache.

Mesh latency is often high, so Arm has invested a lot of effort into mitigating that via aggressive prefetching. Like most CPUs, they have prefetchers at both the L1 and L2 cache levels. The L1 prefetcher can use virtual addresses, letting it prefetch across page boundaries and initiate page walks. In addition to the standard suite of stride and region prefetching, Neoverse V2 can dereference pointers with a “Sampling Indirect Prefetch” prefetcher.

Arm attributes a rather hefty 5.3% performance uplift to hardware prefetching improvements when running single-threaded SPEC2017 integer workloads. More aggressive prefetching helps when you’re primarily latency bound and have plenty of bandwidth available, and a single threaded workload usually falls into that category. SPEC in particular tends to have a large data footprint, likely contributing to the large impact estimated by Arm.
For their performance estimates, Arm used a saner configuration with 32 Neoverse V2 cores at 3 GHz and 32 MB of last level cache, and clocked the mesh at 2 GHz. This isn’t a true configuration implemented in silicon. Rather, Arm is simulating this configuration and estimating SPEC2017 scores using “reduced benchmarks”. This likely refers to taking instruction traces of portions of SPEC2017 benchmarks and evaluating performance with those, because running traces that cover a full benchmark run would be impractical.

Assuming Arm’s engineers have done a reasonably good job of taking traces that correlate well with full benchmark performance, Neoverse V2 sees a 13% increase in SPEC2017 performance. A large portion of performance increase comes from more aggressive hardware prefetching. Smaller but still significant gains come from increasing scheduler sizes and optimizing the load/store unit. Arm determined gains from changes to individual core blocks by applying that change in isolation on top of a Neoverse N1 base. Improvements in aggregate are a bit lower than the sum of the individual improvements.

Some of the changes Arm put a lot of effort into have relatively low impact on SPEC2017 with a simulated single threaded run. With a multithreaded run, where one copy of the workload is run on each core, Arm projects a much higher performance uplift.
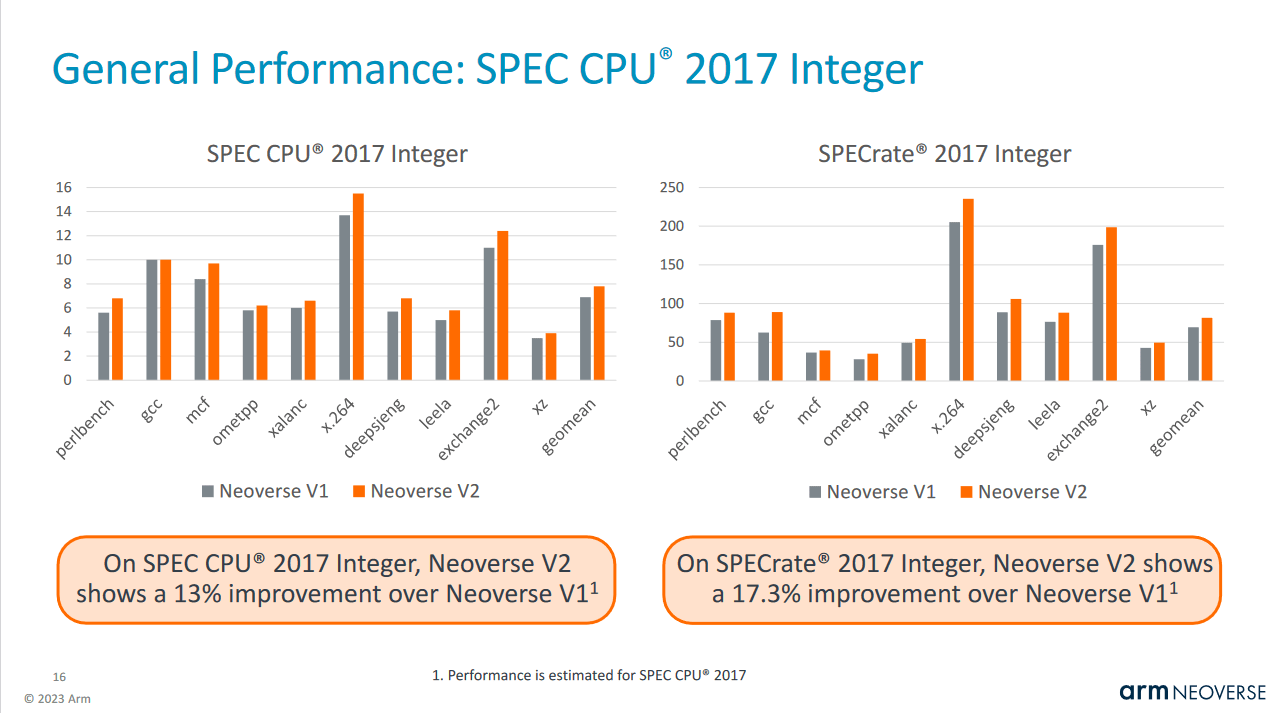
Here, we get better scaling by the V2’s larger L2 cache, the improved prefetchers, and overall more efficient use of system resources.
Magnus Bruce, commenting on V2’s larger projected gain in SPECrate 2017
Multithreaded loads tend to place higher bandwidth demands on shared system resources like L3 cache and memory bandwidth. SPECrate 2017 is a special case of this because every core is running an independent copy of the test. A larger L2 cache helps take stress off the mesh interconnect and L3 cache, making L3 bandwidth issues less likely.
Area
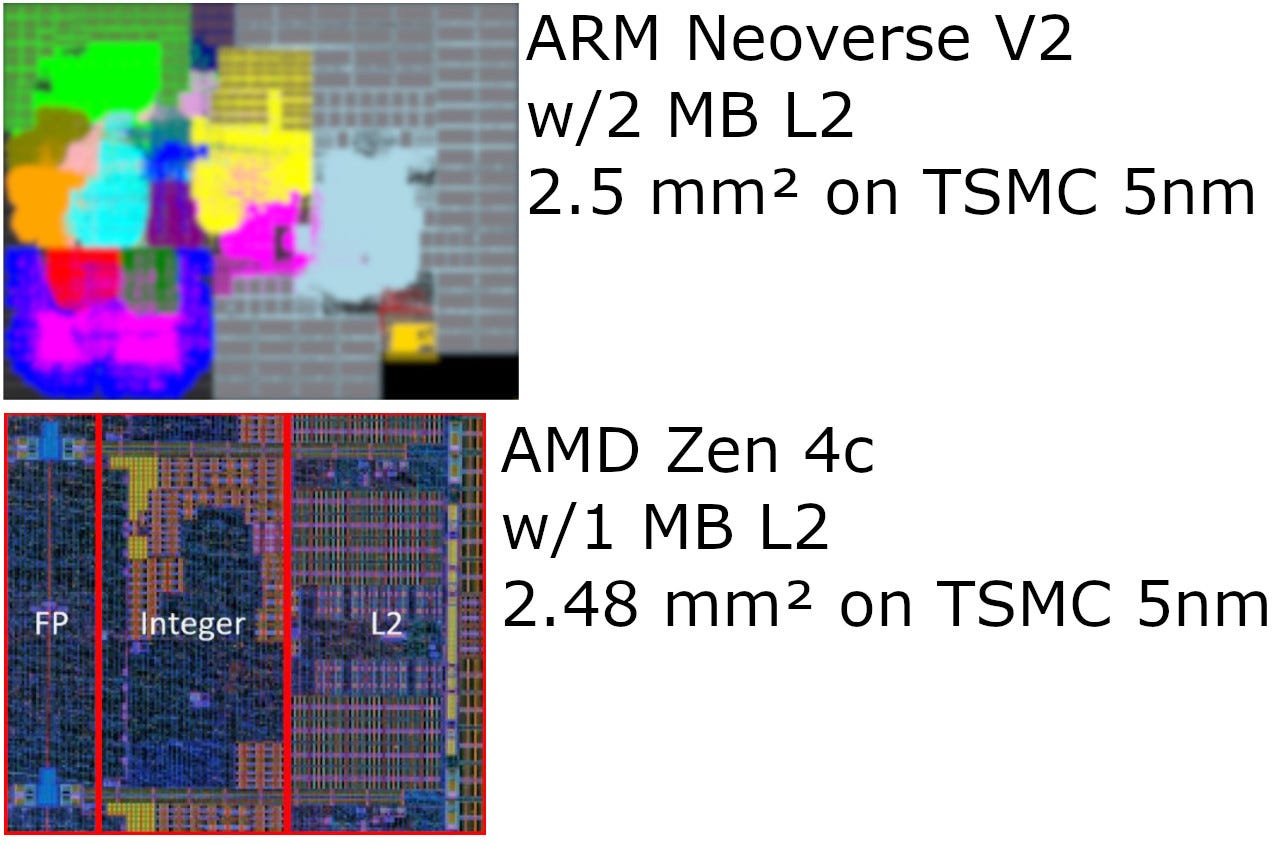
Neoverse V2 occupies similar area to Arm’s prior V1 core after a process shrink.

Neoverse V2 has comparable core area to AMD’s Zen 4c. AMD’s density optimized Zen 4 variant has a larger 6-pipe FPU with 256-bit vector execution and 512-bit vector register file entries. Neoverse V2 instead uses the area to implement twice as much L2 capacity and a 64 KB L1 cache. Both cores appear to spend substantial area on their branch predictor and load/store units.
Final Words
Arm has been trying to move into higher performance segments with their Neoverse V and Cortex X series for a few generations. Neoverse V2 is their latest effort in the server side, and looks to be a serious contender. It has similar reordering capacity to Zen 4c, but more execution units and pipeline width. Vector execution, traditionally a weak point for Arm’s low power CPUs, has been substantially improved. Depending on where you look, Neoverse V2 and Zen 4c trade blows. If you wanted an efficient, dense core capable of very high performance, either core could fit the role. That should worry AMD because Bergamo is expensive and could be undercut by Neoverse V2. Intel should be especially worried because their reply in the high density segment is still some time away.
Unsurprisingly, there are also still many organizations holding out on adopting Arm-based CPU products for their compute estate. Difficulties in migrating software and concerns around performance impact stand out as reasons why many choose to stick with the incumbent Intel and AMD processors. But underlying these reasons is a significant sticking point – Arm’s Cortex and Neoverse cores still haven’t demonstrated a clear performance leadership within the wider market. With Neoverse V2, Arm is looking to take a further step towards taking this crown away from the incumbents.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.