
Bulldozer, AMD’s Crash Modernization: Frontend and Execution Engine


AMD’s K7 Athlon architecture formed the basis of the company’s CPU offerings for around a decade. Athlon did very well against Intel’s P6 based Pentium III. K8 got the basics right, introduced 64-bit support and an integrated memory controller. And remained reasonably competitive against Netburst. But after 2006, Intel’s Core 2 got the basics right while bringing a larger and more advanced core. In response, AMD evolved their Athlon architecture yet again to create the 10h family, codenamed “Greyhound” (K10), known as Phenom on the desktop market. We’ll cover that another day. But as 2010 rolled around, Intel’s Nehalem overhauled their core to core interconnect and brought in their own memory controller. AMD found themselves with an outdated architecture that was getting harder and harder to evolve. At the same time, Intel was steadily eroding all of AMD’s traditional advantages. AMD had to do something big, or the company would have no chance of catching Intel.
That’s where Bulldozer comes in. Instead of trying to push the basic Athlon architecture further, AMD went for a completely different, thoroughly modern design. Bulldozer was designed to be wider, deeper, and more flexible than an evolved 10h core could reasonably be. In some areas, it was even more advanced than its primary Intel competition, Sandy Bridge.

Today, we know how that went. Each tech enthusiast probably associates various things when the name “AMD FX” or “Bulldozer”. Some of them might had some positive experiences when it came to overclocking but that’s about it. Most people know FX as the CPUs from AMD that ran slow, hot and were power hungry. Some might even know that its failure nearly bankrupted AMD because of its non competitive performance. It was slower than its own predecessor, Greyhound, in single core performance and only about had similar multi core performance (Phenom II X6 1100T vs FX-8150) while having two more “cores”. Additionally the power draw of the chip under maximum load was also higher. Against Intel’s Sandy Bridge the end result becomes even questionable.
But as you might think, nobody at AMD envisioned it that way in the planning or design stages. No engineer would ever start working with the idea to “build a shit product”; a recent chat with an engineer who was at AMD during Bulldozer’s development gave us additional insight on what the original goals for the architecture were. AMD originally wanted Bulldozer to be like K10, but with a shared frontend and FPU. In one architecture, AMD would improve single threaded performance while massively increasing multithreaded performance, and move to a new 32 nm node at the same time. But those goals were too ambitious, and AMD struggled to keep clock frequency up on the 32 nm process. This resulted in cuts to the architecture, which started to stack up.
We will be using various code names throughout the article so here is a little overview to not get lost.

Block Diagram
Bulldozer was a new, unconventional design, with massive differences compared to previous AMD architectures. Each module was designed to run two threads. The frontend, FPU, and L2 cache are shared by two threads, while the integer core and load/store unit are private to each thread. That improves area efficiency because the frontend and FPU take a lot of area. It also makes sense because the frontend is more than adequate to feed a single thread, and the FPU is only heavily used in certain applications.
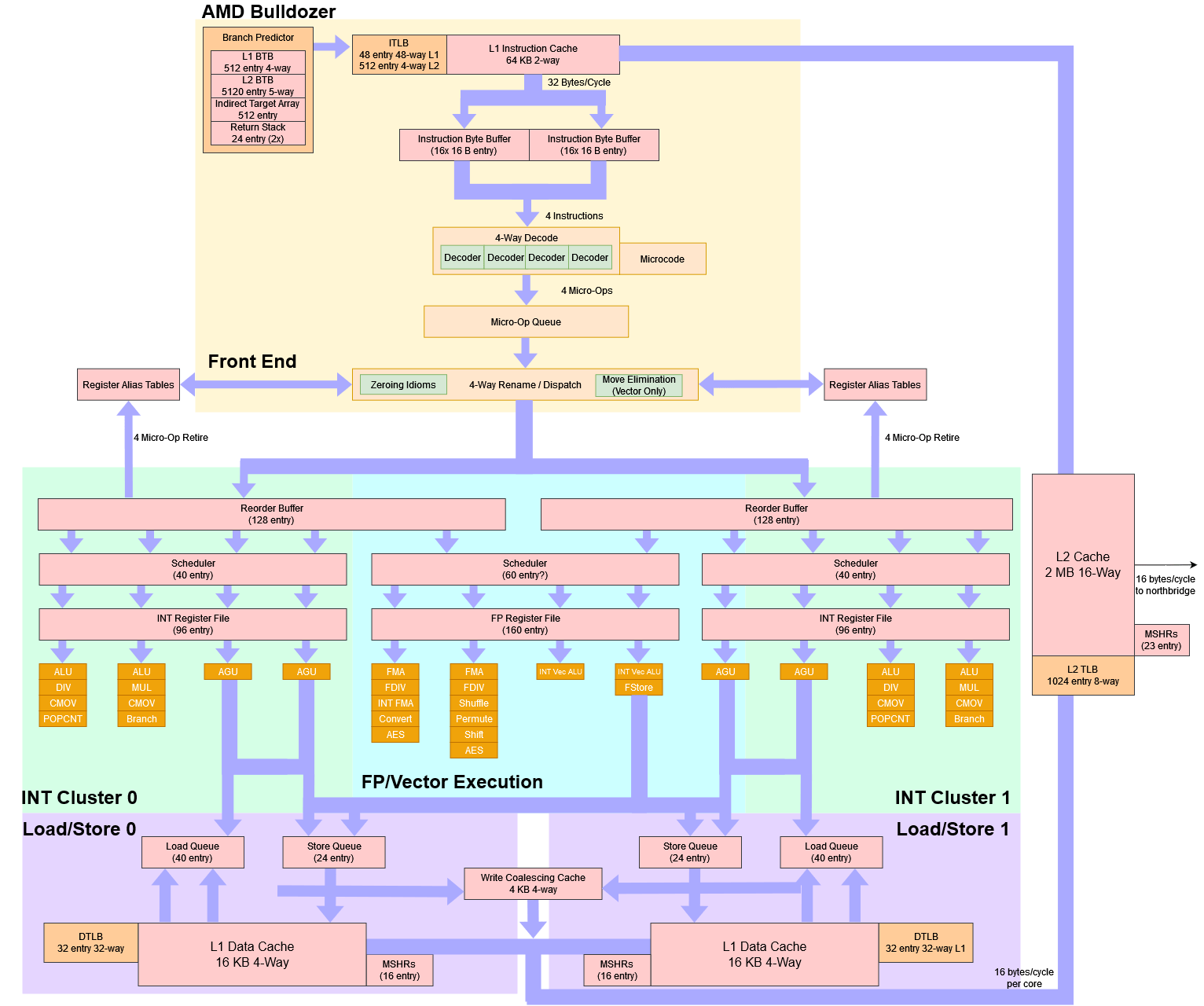
From a physical point of view, a Bulldozer module does vaguely resemble K10 with a shared frontend and FPU. Like K10 and previous Athlon-derived architectures, the core is laid out with fetch, decode, integer execute, load/store, and FPU blocks running across the width of the core, in that order.
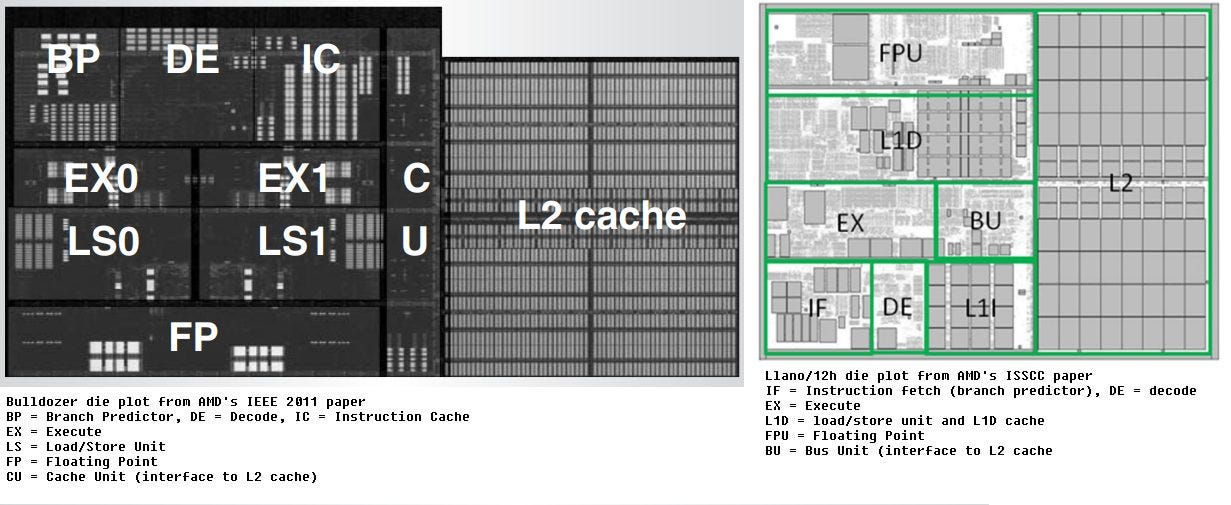
Each Bulldozer module occupies 30.9 mm2, including the L2 cache, and contains 213 million transistors. On the same process node, a Llano core takes 9.69 mm2 excluding the L2 cache.
Frontend: Branch Prediction
The branch predictor sits at the very start of the CPU’s pipeline, and is responsible for quickly and accurately telling it where to fetch instructions from. AMD had a solid branch predictor when Athlon debuted in 1999, but Intel had expended considerable effort into creating more branch predictors. This wasn’t a huge problem for AMD in the early 2000s, because the potential in Netburst’s advanced branch predictor was hidden behind that architecture’s flaws. But by the late 2000s, K8’s branch predictor was no match against Core 2’s, and the P6 based Core 2 didn’t have a pile of show stopping penalties. AMD’s disadvantage only increased as time went on, so Bulldozer got a massive branch predictor overhaul.

In just about every area, Bulldozer is a massive improvement over K10. Unfortunately for AMD, Intel managed to continue iterating at an impressive pace, and the branch predictor is no exception. Sandy Bridge has an excellent branch predictor, and can recognize longer patterns than Bulldozer.

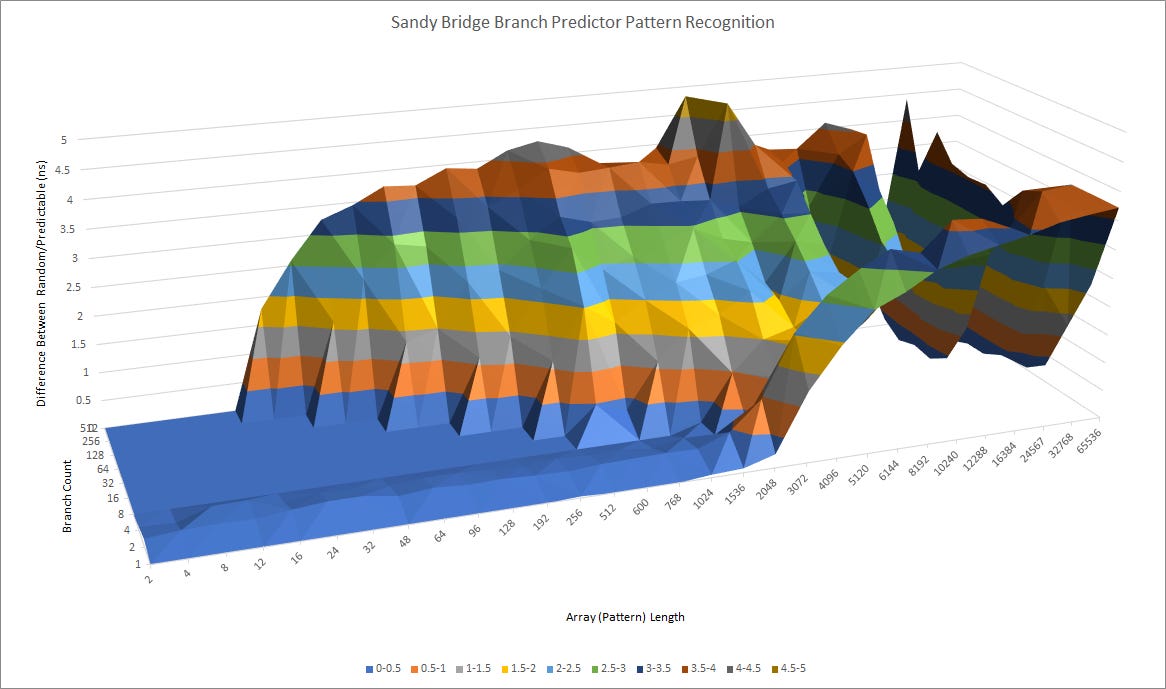
Sandy bridge is also better at handling large branch footprints, and can still handle moderate history lengths with 512 branches. Bulldozer really starts to struggle at that point. Indexing into the history table with a 2-bit hash of the branch address probably leads to a lot of aliasing with a lot of branches in play.
Branch Target Tracking
Branch predictors have to be fast as well, to avoid stalling the pipeline too much waiting for the next branch target. Bulldozer focuses on increasing branch tracking capacity compared to K10, rather than speed. However, AMD did decouple the branch predictor from the instruction fetch stage, giving the frontend a bit more queueing capacity to prevent branch predictor delays from starving the pipeline. Instead of getting predictions at the L1i fetch stage, the predictor runs ahead and populates a queue of fetch targets for each thread.
In theory, that should allow Bulldozer to retain high instruction fetch bandwidth even in the face of instruction cache misses, as long as the BTB is large enough to cover an application’s branch footprint, and the direction predictor is accurate enough. However, our testing shows that’s not the case. We see taken branch latency increase as the test loop spills out of the 64 KB L1i, indicating that the prediction queue or the L1i miss queue don’t have enough entries to hide L2 latency. AMD states that on an L1i miss, Bulldozer does next-line prefetch. If that’s true, and Bulldozer doesn’t use the prediction queue to continuously queue up L1i miss requests, that would explain the poor behavior we see when fetching code from L2.
Decoupling the branch predictor from L1i also removes the branch tracking restrictions that plagued K7, K8, and K10. Those architectures could fail to predict a branch because the predictor can’t track it. Compilers worked around this to some extent by padding or using longer encodings. Of course, that’s a messy solution because it sacrifices code density. Bulldozer gets rid of that limitation.

However, AMD did little to improve the branch predictor’s speed. The new two-level BTB arrangement provides more branch target tracking capacity, but the second level BTB is very slow. Taking a branch target from it costs 5 cycles. The first level BTB is smaller than the one in K10, but no faster. Bulldozer is thus unable to handle taken branches back to back, meaning that loop unrolling is still important for AMD.
Sandy Bridge in contrast can handle up to eight taken branches without stalling the frontend at all. Intel also has a larger 4096 entry L1 BTB that’s as fast as the 512 entry L1 BTB on Bulldozer. So even though both architectures have a 4-wide frontend on paper, Bulldozer is going to lose a lot more frontend throughput around taken branches.

Bulldozer and Sandy Bridge can both hide taken branch latencies to some extent when running two threads in a module or core. With another independent chain of branch targets, the L1 BTBs on both CPUs can provide a taken branch target every cycle. However, Sandy Bridge still has a significant advantage if Bulldozer has to hit the L2 BTB, which can only provide a taken branch target once every three cycles.
For return prediction, Bulldozer has a 24 entry return stack. Contemporary Intel architectures have 16 entry return stacks, so Bulldozer’s is quite large. The return stack is duplicated to handle two threads, just like in Sandy Bridge.
Frontend: Fetch and Decode
Not everything about K10 needed an overhaul. Like K10, Bulldozer uses a large 64 KB, 2-way instruction cache. Bulldozer’s L1i is physically implemented as an 8×2 array of 4 KB bank macros, using 8T SRAM. Predecode information is stored alongside the instruction cache in two separate arrays, indicating that 8 KB of storage is used to store predecode data. The instruction cache can deliver 32 bytes per cycle, although a single thread can’t make full use of that bandwidth. With 8 byte NOPs and one thread, we average 22-23 bytes per cycle of instruction bandwidth. Running two threads in a module brings that up to just about 32 bytes per cycle, in line with AMD’s documentation.
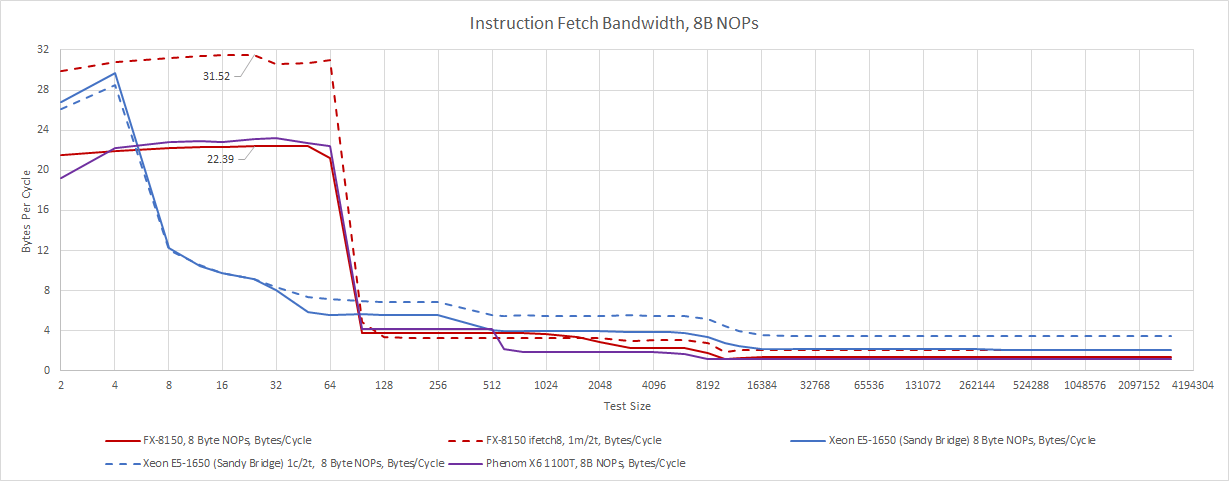
Sandy Bridge takes a different, high tech approach to instruction delivery. A 1536 entry micro-op cache holds decoded instructions, and can effectively provide 32 instruction bytes per cycle. This micro-op cache has its roots in Netburst’s trace cache, but doesn’t try to function as a L1i. Instead, Sandy Bridge backs the op cache with a conventional 32 KB instruction cache capable of delivering 16 bytes per cycle. Unlike Bulldozer, Sandy Bridge doesn’t need a second thread to hit full fetch bandwidth. But the micro-op cache is relatively small, and Bulldozer will have a fetch bandwidth advantage if both CPUs have to pull instructions from their L1i caches.
Both CPUs suffer when running code out of L2 or L3, but Bulldozer is worse. Like Phenom, Bulldozer exceeds four bytes per cycle on average from L2. Running two threads in the module doesn’t help L2 bandwidth, but slightly helps in L3 sized regions. Sandy Bridge isn’t great either, but does achieve better code fetch bandwidth out of its L2 and L3 caches. The two architectures therefore trade blows depending on code footprint sizes. Bulldozer is hurt more by L1i misses, but has a larger L1i that should suffer from fewer misses. Sandy Bridge is better at either very small or very large code footprints.
With shorter 4 byte NOPs, which are more representative of typical instruction lengths found in scalar integer code, fetch bandwidth considerations pretty much go away. Bulldozer’s frontend can deliver 4 instructions per cycle from the instruction cache, regardless of whether both threads in the module are active. Sandy Bridge can too, as long as it doesn’t suffer instruction cache misses.
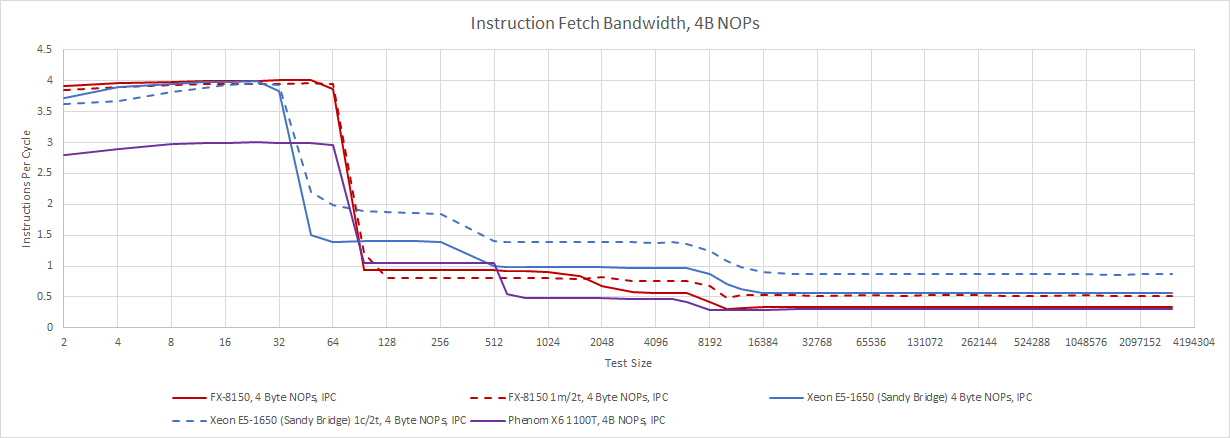
Past L1i, Bulldozer is stuck at about 1 IPC. Absolute instruction fetch bandwidth is mostly unchanged from the 8 byte NOP test. Again, we see Bulldozer’s advantage with a large instruction cache. Sandy Bridge does better with very large code footprints, especially if an application can use enough threads to take advantage of SMT.
Rename/Allocate
After the frontend has brought instructions into the core, the renamer is responsible for allocating resources in the backend to track them for out of order execution. The rename stage is also a convenient place to pull some tricks that expose more instruction level parallelism to the backend. For example, certain operations like subtracting a value from itself or XOR-ing a value with itself will always result in zero, and are commonly used to zero a register. There’s no need to wait for the previous value of the register to be ready before executing such an operation, and the renamer can make that clear to the backend. Bulldozer’s renamer can break dependencies in this case to expose more parallelism to the backend, but can’t eliminate zeroing idioms the way Sandy Bridge can.

Move elimination is another trick. Because Bulldozer’s ROB holds pointers to physical registers, copying values between registers can be as simple as having the renamer point two architectural registers to the same physical one. Bulldozer can do this for vector registers, letting it “execute” register to register copies within the renamer.
x86 CPUs had to do some form of move elimination on the floating point side for decades, in order to break dependencies when dealing with the x87 register stack. AMD has long used a separate renamer to do this within the floating point unit, and extending that to eliminate MOVs with SSE registers probably wasn’t much of a stretch. Eliminated moves don’t consume an execution pipe and don’t require a physical register to be allocated. There’s unfortunately no move elimination on the scalar integer side, but for perspective, Sandy Bridge has no move elimination at all.
Out of Order Execution
AMD completely overhauled the out of order execution engine in Bulldozer. Athlon and Phenom used a hybrid scheme, with a ROB+RRF setup for the integer side, and a PRF setup for the FP/vector side. Bulldozer ditches this and goes all in with a modern PRF scheme everywhere. Intel did the same thing with Sandy Bridge, ditching Nehalem’s ROB+RRF setup, which dates back to Intel’s old P6 architecture, in favor of a PRF scheme.
In the old ROB+RRF scheme, renamed registers are simply result fields in the ROB. That makes renaming simple, because every instruction allocated into the backend simply writes its result back into the ROB. The renamer doesn’t have to worry about finding free entries in a separate register file. Storing results in the ROB also means you can’t run out of registers for renaming until the ROB fills, simplifying tuning and performance analysis.
But this scheme has disadvantages too. When instructions retire, their results have to be physically copied into a separate retired register file (RRF). Register count also has to grow with ROB size, which isn’t ideal because a lot of instructions like compares, branches, and stores don’t need to write a result into a register. Renamed registers or result field slots for those instructions end up being unused. In contrast, the PRF based scheme in Bulldozer and Sandy Bridge stores results in separate physical register files. The ROB only holds pointers to the register file entries. When instructions are retired, only the pointers have to be copied. That reduces data movement, especially when dealing with large vector registers. With the PRF scheme, Intel and AMD were both able to massively increase reordering capacity.
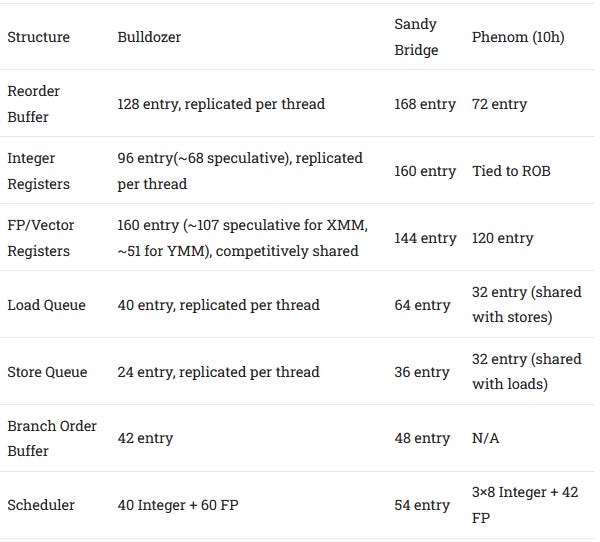
AMD’s case is especially significant, because the ROB size increases by a whopping 77% over K10. K10 ran into ROB capacity limits a lot, and Bulldozer aims to address that.
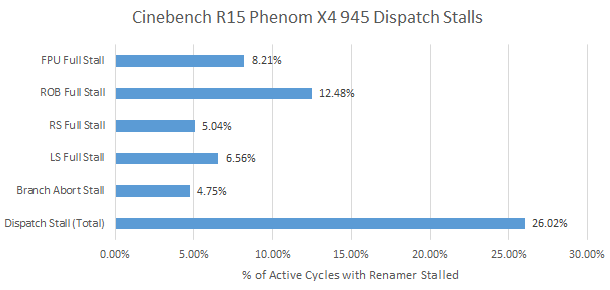
K10 could also suffer heavily from branch mispredicts, because the backend could not accept new instructions until the mispredicted branch was retired. That’s because K10 only kept two sets of register alias tables (RAT) – one for retired state, and one for the latest speculative state at the renamer. After a branch mispredict, the speculative RAT would obviously be incorrect. To recover that scenario, K10 would let the mispredicted branch retire, and then copy known-good retired state to speculative state. But up until the mispredicted branch retired, the backend would not be able to allocate resources for any instructions coming from the frontend. That’s the “branch abort stall” above.
Bulldozer avoids that kind of stall by keeping snapshots of RAT states, in a structure called a “mapper checkpoint array”. After a mispredict, Bulldozer can restore RAT state using a checkpoint, instead of waiting for the branch to retire. The backend can then start accepting instructions from the frontend even while the mispredicted branch is still in-flight. In some cases, the latency of branch mispredict can be completely hidden behind other long latency instructions.
Integer Execution
Other K10 weaknesses were corrected in Bulldozer too. K10 had small, distributed schedulers for its integer side, and these could often fill up. Bulldozer switches to a 40 entry, four port, unified scheduler. This scheduler covers 31% of reorder buffer capacity, making it similar to Sandy Bridge’s in that respect. However, Sandy Bridge uses the same scheduler to handle floating point and vector operations.
But implementing a large scheduler is not easy. To keep clock speeds up and power consumption down, AMD made changes to the scheduling algorithm. Generally, CPU designers try to make sure the oldest ready instruction sitting in the scheduler gets executed, similarly to how a restaurant may try to prioritize a customer who has been waiting the longest.
Choosing the oldest instruction first is a known good heuristic as it is more likely that an older instruction blocks execution of later dependent operations. However, an oldest-first heuristic requires tracking the age of entries in the scheduler, which has a hardware cost.
Henry Wong, A Superscalar Out-of-Order x86 Soft Processor for FPGA
Intel’s P6 architecture used a collapsing priority queue to make sure the schedulers always sent the oldest ready instruction for execution. AMD’s Bulldozer presentation at ISSCC 2011 suggests some of AMD’s previous architectures may have done the same. However, a shifting, collapsing structure would be too power hungry. So, Bulldozer uses an ancestry table that tracks the oldest instruction and prioritizes it for execution. This method should get some of the benefits of a true oldest-first scheme, while avoiding the costs of a collapsing priority queue. If the oldest instruction isn’t ready to execute, other instructions are selected depending on where they physically are in the scheduler, which doesn’t correspond to age.
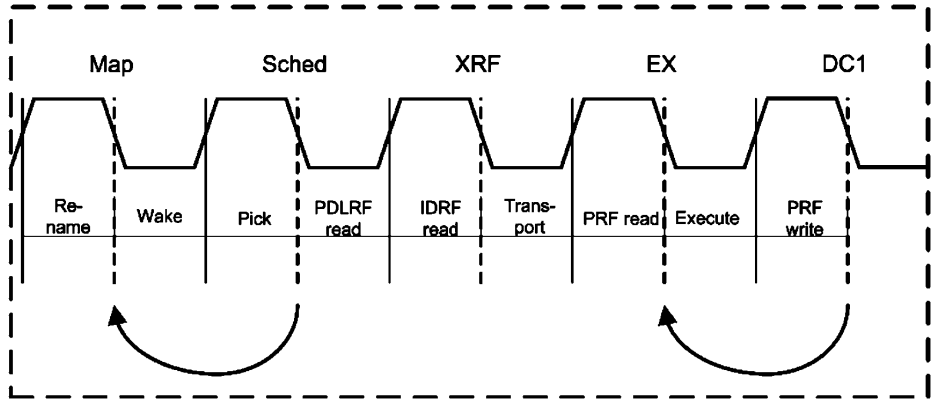

With these optimizations, Bulldozer implements a big unified scheduler without needing a pile of extra pipeline stages. Contrast that with Netburst, which has more than twice as many pipeline stages from rename to execute.
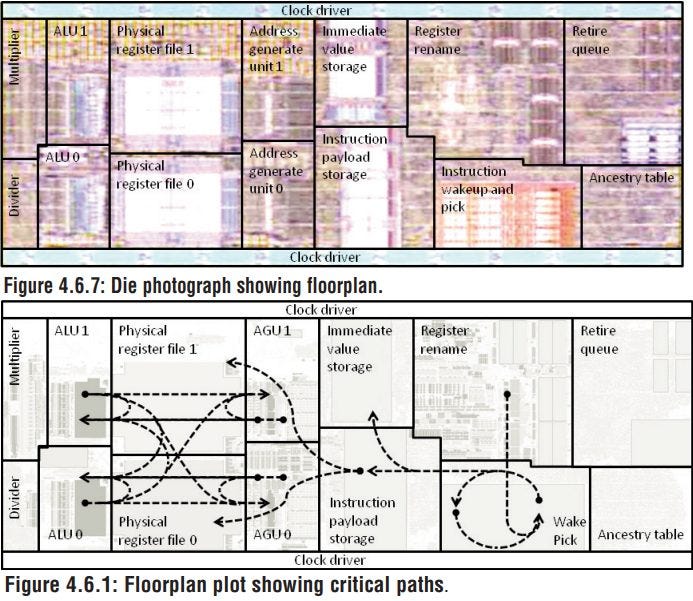
AMD made other changes to increase clock speed without excessive pipelining, and these are quite visible in the per-thread integer execution engine. Besides switching to a PRF scheme to minimize data movement, Bulldozer duplicates the integer register file to reduce critical path lengths. Each register file copy has four read ports and four write ports. Reads can come from either register file depending on the execution pipe involved, while writes are written into both register file copies. The integer RF thus effectively has eight read ports and four write ports. Most of the scheduling structures are parity protected.

Bulldozer’s integer execution units are rather light compared to both Sandy Bridge and K10. There are only two ALU pipes capable of handling common operations like adds and compares. Execution unit throughput is typically not a bottleneck, especially with K10, which had over-provisioned integer execution resources to enable its simple three-lane layout. But AMD might have gone too far in the space saving direction. Bulldozer’s frontend can deliver four instructions per cycle to a single thread, and most other 4-wide CPUs have three or more ALUs.
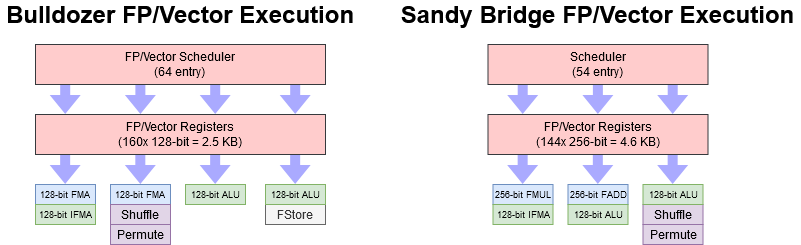
FP and Vector Execution
Bulldozer’s FPU can accept four operations per cycle from the frontend. The four operations that come in on a single cycle have to be from a single thread, but if two threads are active and using FP/vector instructions, the FPU can switch which thread it’s receiving operations for every cycle.
Because the FPU is designed to handle two threads, its out-of-order bookkeeping resources are overpowered for a single thread. The 60 entry unified scheduler by itself is larger than the 54 entry unified scheduler that Sandy Bridge uses to handle all instructions, and much larger than the 42 entry FPU scheduler in K10. Bulldozer’s FP register file is no joke either, with 160 entries. That’s enough to cover most of a single thread’s ROB, after excluding registers used to hold architectural state across both threads. K10 only has 120 FP registers and Sandy Bridge only has 144.
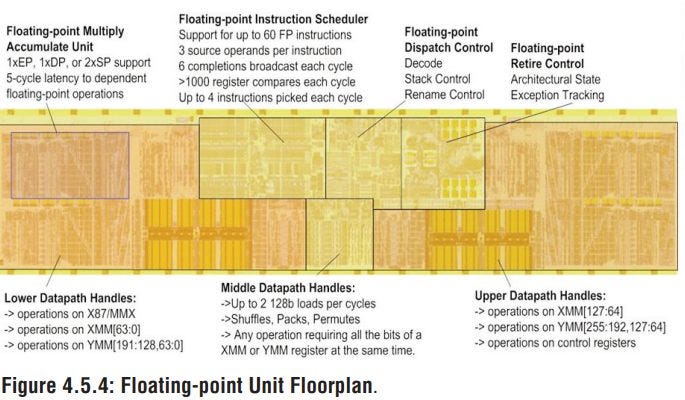
Physically, the register file is split into two 10-bank arrays located on either side of the FPU, where they’re close to the most commonly used vector and FP execution units. One array is wider than the other to handle 80-bit x87 operations. Units that have to access lanes across an entire vector register are placed between the two register file arrays. AMD’s ISSCC 2011 presentation states that the FP register file can support 10 reads and 6 writes per cycle2, and has a total of 13 read and 7 write buses to the execution units1. That should be enough bandwidth to feed the FPU’s four execution pipes.
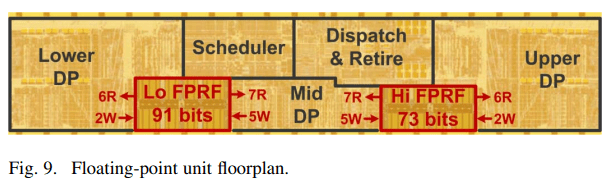
Unlike some SMT implementations, there’s no strict partitioning or watermarking of FPU registers or scheduler capacity when a module has two threads active. In fact, if one thread is only running integer instructions, FPU operation is indistinguishable from single threaded mode.
AMD says the FPU is thread agnostic, and it does feel like the FPU is simply handed instructions from the frontend and told which integer core to report completion to. If both threads are using the FPU, its resources are competitively shared. We see a very slow increase in the total latency of two cache misses, instead of a sharp increase when the register file or scheduler capacity is exceeded.
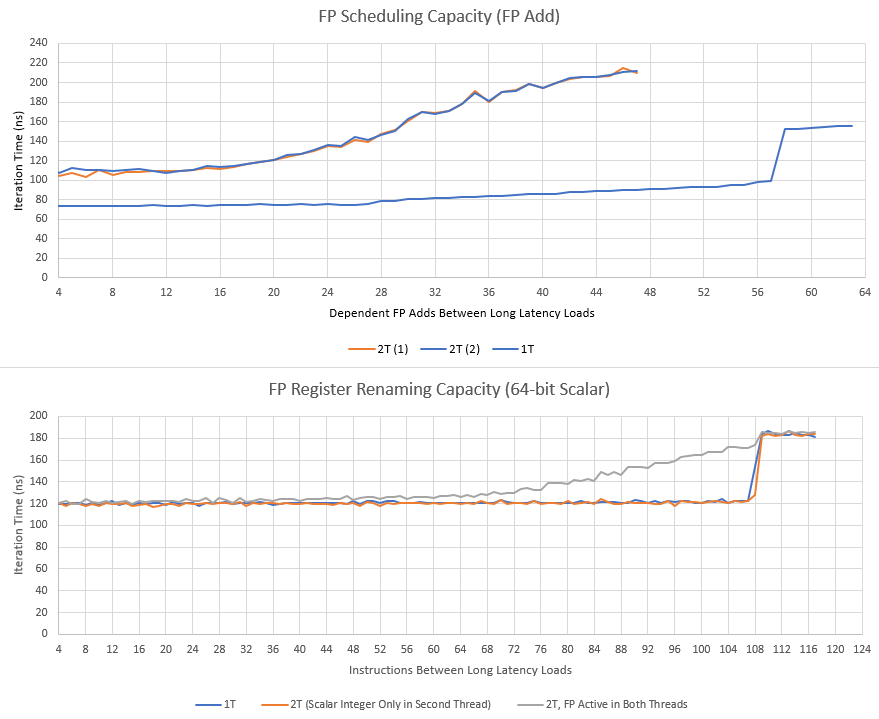
As we get towards maximum scheduler or RF capacity, each thread has a lower probability of getting the reordering capacity it needs to execute both long latency loads in parallel. Contrast that with Sandy Bridge, where the FP register file is strictly partitioned with both threads active.

Sandy Bridge’s scheduler appears to be watermarked, so that one thread is not allowed to use more than about 40 entries when its sibling thread is active.

Bulldozer’s FPU therefore has a pretty simple SMT implementation. Unlike Sandy Bridge, it doesn’t reconfigure itself depending on whether it’s handling one or two threads. The load balancing policy could be as simple as letting the frontend arbitrate between two threads, and throttling FPU instruction delivery for one thread if necessary to ensure fairness. This simplicity can come with corner-case advantages too, like letting one thread get unrestricted access to FPU resources if the sibling thread is only executing scalar integer instructions.
FPU Execution Units, and AVX Implementation
We recently covered the AVX-512 implementations in Zen 4 and Cannon Lake, so it’s only fitting that we cover Bulldozer’s introduction of AVX to AMD’s lineup. AVX extends the vector registers to 256-bit and adds floating point instructions that operate on 256-bit vectors. Bulldozer decodes 256-bit instructions into two 128-bit micro-ops, and tracks them throughout the pipeline. The main benefit from AVX is therefore increased code density.
In contrast, Sandy Bridge implements 256-bit physical registers and FP execution units, giving Intel far better reordering capacity and throughput for AVX code. However, Bulldozer does have a trick up its sleeve with FMA (fused multiply add) support. A FMA instruction computes a*b+c in one go, taking advantage of how the last step of a multiplication operation involves adding a batch of partial sums. With FMA, a Bulldozer module can match a Sandy Bridge core’s floating point throughput.
Of course, this only works if you can use the output of a multiply operation in an add operation. Two totally independent add and multiply operations won’t benefit. Another problem is that Bulldozer uses FMA4 instructions, which specify a d = a*b+c operation. Intel never supported FMA4. When Haswell introduced FMA to Intel’s lineup, it used FMA3, meaning that one of the source operands would be overwritten. Intel’s dominant market position meant FMA4 never gained widespread software support. AMD introduced FMA3 support with Piledriver, and software standardized on that.
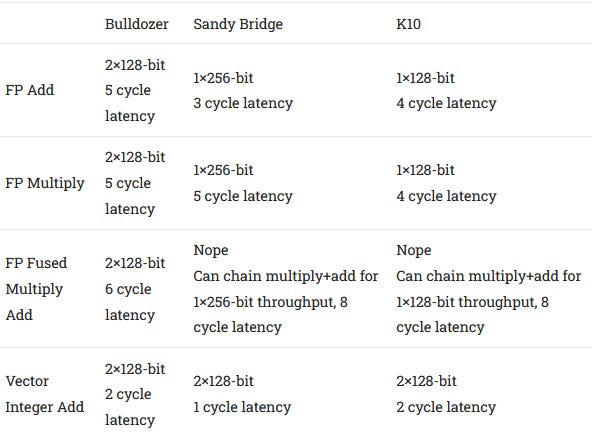
Bulldozer’s FMA latency is rather high at 6 cycles, probably because it’s AMD’s first attempt at a FMA implementation. Targeting high clock speeds on a disappointing process node probably didn’t help things either. But in fairness to Bulldozer, Haswell enjoyed a much better process node with Intel’s 22 nm and was only one cycle better with 5 cycle FMA latency.
Context matters too. Software takes time to adopt a new ISA extension, so AVX usage was very rare right after Bulldozer and Sandy Bridge’s launches. Bulldozer’s FPU setup makes a lot of sense for existing software that only uses scalar or 128-bit vector instructions. For example, Bulldozer’s FMA units are also used to handle adds and multiplies, meaning that two ports are available for both operations. Sandy Bridge only has one FP add port and one FP multiply port, making it prone to port bottlenecks if FP code doesn’t have a roughly even mix of adds and multiplies.
Overall, AMD’s FPU is a large improvement over the one present in K10. Throughput is increased by a more flexible pipe layout, where two pipes can handle both FP adds and multiplies. For low-threaded performance, the FPU can give each thread massive resources for FPU reordering, such that reordering limits are likely to be hit elsewhere. Even with two threads active, the FPU can give each thread pretty decent reordering capacity. The greatest weakness in Bulldozer’s FPU is likely its execution latency. But FP code tends to be less latency sensitive, and the FPU has plenty of scheduling capacity to absorb short term spikes. Scheduler capacity will of course be shared if two threads are using the FPU, but in that case, execution latency is mitigated by the explicit parallelism provided by a second thread.
Load/Store
Each Bulldozer thread executes memory operations through a pair of AGU pipes. Like the ones in prior AMD CPUs, these AGUs are relatively powerful and can handle indexed addressing with no penalty. The load/store unit tracks in-flight memory operations using separate queues for loads and stores. The load queue has 40 entries, and the store queue has 24 entries. Bulldozer’s approach has more in common with Sandy Bridge, which also has separate load and store queues (just larger ones than Bulldozer). In K10, a single unified queue handled both loads and stores. Splitting up the load and store queues is probably an acknowledgement that K10’s scheme was inefficient. Loads are far more common than stores, and tracking stores requires more storage. That’s because pending store data also has to be kept around, in addition to the store address.
Once addresses have been generated, the load/store unit checks to make sure memory dependencies are satisfied. That is, an in-flight load may get its data forwarded from an older store. Bulldozer’s mechanism for doing this is an improvement over K10. It no longer suffers from false dependencies when the load and store both touch the same 4B aligned region, but don’t actually overlap. With scalar integer memory accesses, Bulldozer can do fast forwarding in all cases where the load and store address match exactly. K10’s forwarding mechanism would fail if either memory access crossed a 16 byte boundary. But this advantage isn’t so clear cut, because K10 generally has lower latencies. If the load is misaligned, store forwarding takes 13-14 cycles on Bulldozer. That’s much better than the 35-39 cycle failure case, but K10’s failure case takes 12-13 cycles. Bulldozer only has an advantage if the store is misaligned, but the load isn’t. There, K10 takes a 10 cycle penalty, while Bulldozer can handle it in 8 cycles (which is the same as the happy path forwarding latency). In cases where both architectures can pull off fast-path forwarding, K10 is generally faster with 4-5 cycle forwarding latency.

Compared to K10, Bulldozer has more robust checks, but also suffers higher latencies – especially if those checks fail. K10 is much simpler and has to hit a slow path more often, but has a short pipeline and recovers relatively quickly. Failed store forwarding on Bulldozer generally incurs a hefty 35 cycle penalty. This increases to 39 cycles if the load is misaligned, and can reach 42-43 cycles if the load crosses a 64B cacheline boundary. K10’s worst penalty is 12-13 cycles when both the load and store are misaligned. Elsewhere, the failure case is generally 10-11 cycles.

In cases where loads are independent and no forwarding is needed, Bulldozer’s more robust load/store unit can make it faster too. On K10, misaligned accesses carry a significant penalty, with a pair of misaligned loads and stores completing once every 3-4 cycles. On Bulldozer, the data cache probably has three separate ports (two read and one write), giving it more bandwidth to handle misaligned accesses. However, Bulldozer does take a slight penalty with misaligned loads that come within a 4B aligned 32B sector accessed by a store. There’s probably some kind of coarse, fast path check in Bulldozer, with a more thorough check for forwarding happening if the initial check indicates a possible overlap.
Sandy Bridge has a similar coarse, fast check. But Intel does this on aligned 4 byte boundaries, making it a finer check than Bulldozer’s. Across the board, Sandy Bridge’s load/store unit is far more flexible and robust. It can do fast-path store forwarding for all cases where the load is contained within the store, even with misaligned accesses. As a cherry on top, Intel generally enjoys lower penalties too. Compared to Bulldozer, the fast forwarding case is faster (6 cycles vs 8), and the failure case is less punishing (17-25 cycles, vs 36-42 cycles).
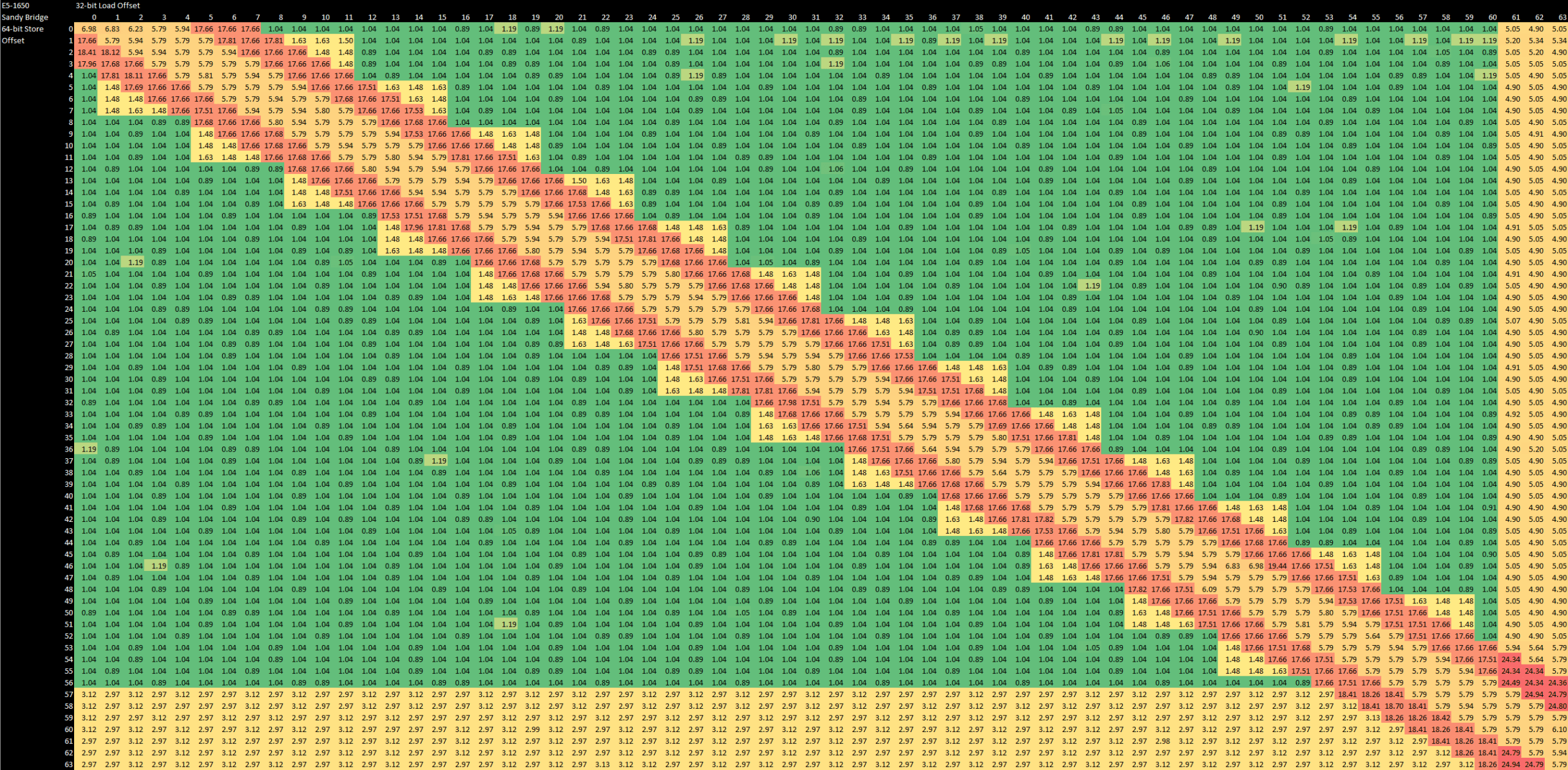
Intel also suffers less from misaligned access penalties, and only has to do extra L1D accesses if a load or store crosses a 64B cacheline boundary. Like K10, Bulldozer’s L1D generally handles operations in 16B aligned chunks, making it more susceptible to misaligned access penalties.
However, Bulldozer still handles a few corner cases better. Like with K10, there’s no extra penalty if a load crosses a 4K page boundary, while Sandy Bridge takes a 35 cycle penalty. The situation flips with stores, where Sandy Bridge can handle split-page writes with a 25 cycle penalty. Bulldozer takes 37-38 cycles to do so. That represents a large regression from K10, which didn’t suffer any notable 4K page crossing penalties. I’m guessing that AMD’s TLBs are able to read out two entries in a single cycle, while Intel’s can’t. However, Bulldozer’s write through L1D probably throws a wrench in the works when dealing with stores.
4K Aliasing
Bulldozer and Sandy Bridge both only check a subset of address bits when initially determining whether memory accesses are independent, and higher address bits are not included. Specifically, they don’t check more than the first 12 bits. That makes sense, because you don’t even know what the higher bits are until you’ve finished a TLB lookup. After all, there’s nothing wrong with aliasing multiple pages in virtual address space to a single page in physical memory (although doing so may make you a horrible person).
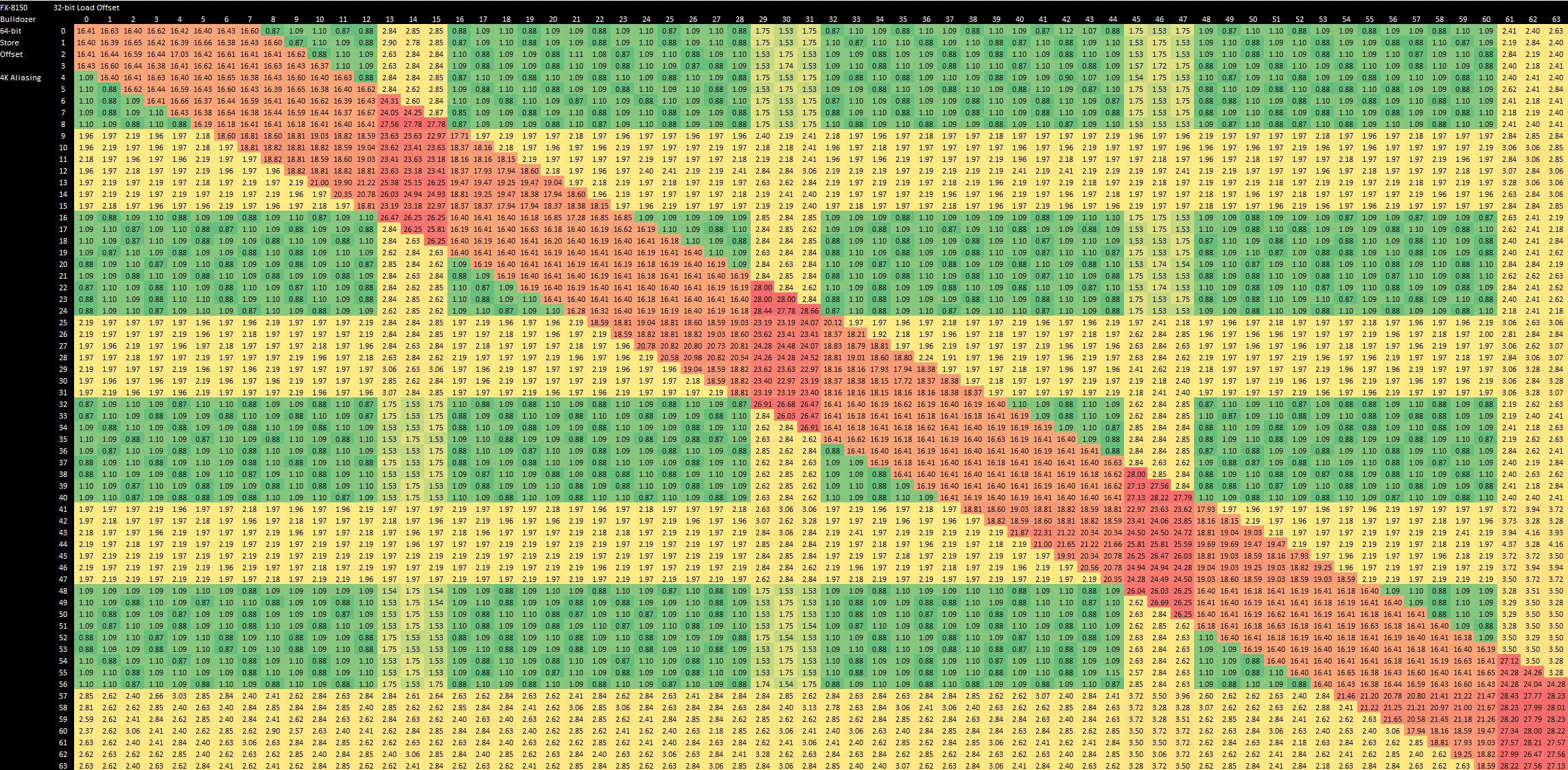
Both cores therefore lose ILP from false dependencies when a load and store are spaced by 4096 bytes, even though the accesses don’t overlap. But Bulldozer suffers far higher penalties when this happens, generally taking 16 cycles to sort itself out and realize there’s actually no dependency. The penalty can go as high as 27 cycles if the accesses are misaligned. This isn’t as bad as the failed store forwarding penalty, but still high enough to suggest that Bulldozer’s not doing a full address comparison until quite late in the load/store pipeline.

In contrast, Sandy Bridge seems to figure out that everything is actually fine quite early in its load/store pipeline, typically resulting in a 3-4 cycle penalty for the load. If both accesses are misaligned, this penalty increases to 8-9 cycles, but that’s still better than on Bulldozer.
Brief Words on Part 1
AMD has implemented a modern execution engine into the Bulldozer core. Compared to Athlon, the Bulldozer foundation gives AMD’s engineers a lot of flexibility to allocate resources. Bulldozer addresses a lot of Athlon’s traditional bottlenecks, like low integer scheduling capacity.
Not all of the modernization efforts can show their full potential. For example, improvements in the branch predictor and load/store unit are blunted by higher latency. A focus on multithreaded performance meant sacrifices to the reordering capacity and integer execution resources available to a single thread. But from an architectural “bling” perspective, Bulldozer undeniably has more in common with today’s architectures than the likes of Athlon or P6.
At the same time, AMD brought some of Athlon’s strengths forward. Bulldozer’s frontend retains a high capacity 64 KB L1i with predecode information. But the core is only part of the story. Out of order execution aims to keep the execution units fed in the face of cache and memory latency, and we’ll look at what the core has to deal with in Part 2.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.
 |
|