
AMD’s Zen 4 Part 1: Frontend and Execution Engine

AMD’s Zen 4 architecture has been hotly anticipated by many in the tech sphere; as a result many rumors were floating around about its performance gains prior to its release. In February 2021 we published an article that claimed a 29% IPC increase for Zen 4. You can consider this our formal retraction of that article. Anything said in that article is invalid; however, I (Cheese) don’t regret publishing that article because it caused me to reevaluate what this site would become, and I am very glad that I did. I would like to think that we have grown from just another rumor site into a very well respected site that does very technical deep dives in the spirit of Real World Tech and Anandtech.
Speaking of technical deep dives, we’re splitting our coverage of Zen 4 into two parts. This part will focus on the frontend and parts of the out of order execution engine. We will go over the memory subsystem from the data side in another article, as well as AVX-512.
Overview and Block Diagram
From 1000 feet up, Zen 4 looks a lot like Zen 3, but with upgrades scattered throughout the pipeline. We can compare Zen 4’s situation to Zen 2’s. In both cases, AMD is evolving a solid architecture while porting it to a new process node.

Moving to a new process node involves effort and risk. Intel mitigated this risk with the well known “Tick-Tock” strategy. Each “Tick” represented a major microarchitecture change, while each “Tock” was a port to a new process node with very minor changes. Unlike Intel in the early 2010s, AMD takes roughly two years to move to a new process node. Zen 2 came in mid 2019, about two years after Zen 1’s early 2017 release, and moved from 14 nm to 7 nm. Zen 4 released in late 2022, about two years after Zen 3’s late 2020 release, and moved from 7 nm to 5 nm. AMD’s strategy is thus best described as “Tick-Nothing-TickTock”.
Here’s Zen 3 for comparison:

Frontend: Branch Predictor
A CPU’s branch predictor is responsible for steering the pipeline in the correct direction. An accurate branch predictor will reduce wasted work, improving both performance and power efficiency. As CPUs increase their reordering capacity, branch prediction accuracy becomes even more important, because any work queued up after a mispredicted branch is useless.
Direction Prediction
Like other CPUs in the Zen series, Zen 4’s direction predictor has two overriding levels. Making a predictor that’s both very fast and very accurate can be challenging, so designers often have to make tradeoffs between speed and accuracy. An overriding predictor tries to get the best of both worlds with a speed-optimized L1 predictor, and an accuracy-optimized L2 that overrides it if predictions disagree.
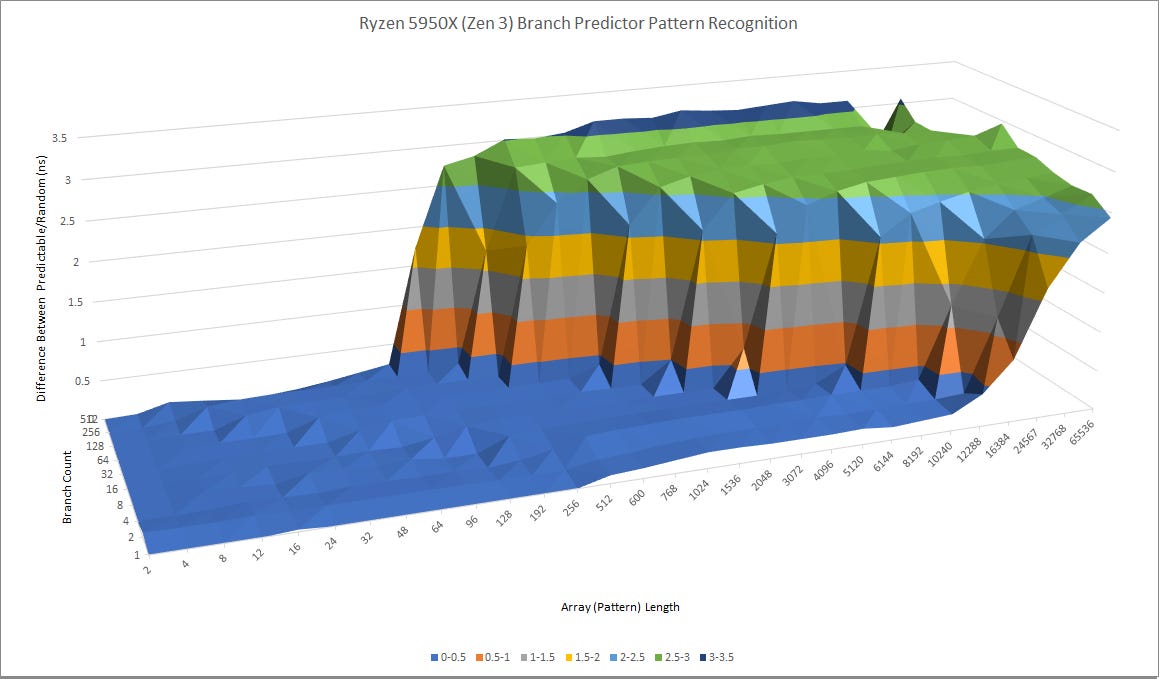
Zen 4 and Zen 3 seem to have similarly capable L1 predictors, but AMD has dramatically beefed up Zen 4’s L2 predictor. Zen 3’s second level predictor was already no slouch, but Zen 4 takes things to the next level. It can recognize extremely long patterns and has enough storage to perform very well, even with a lot of branches in play.
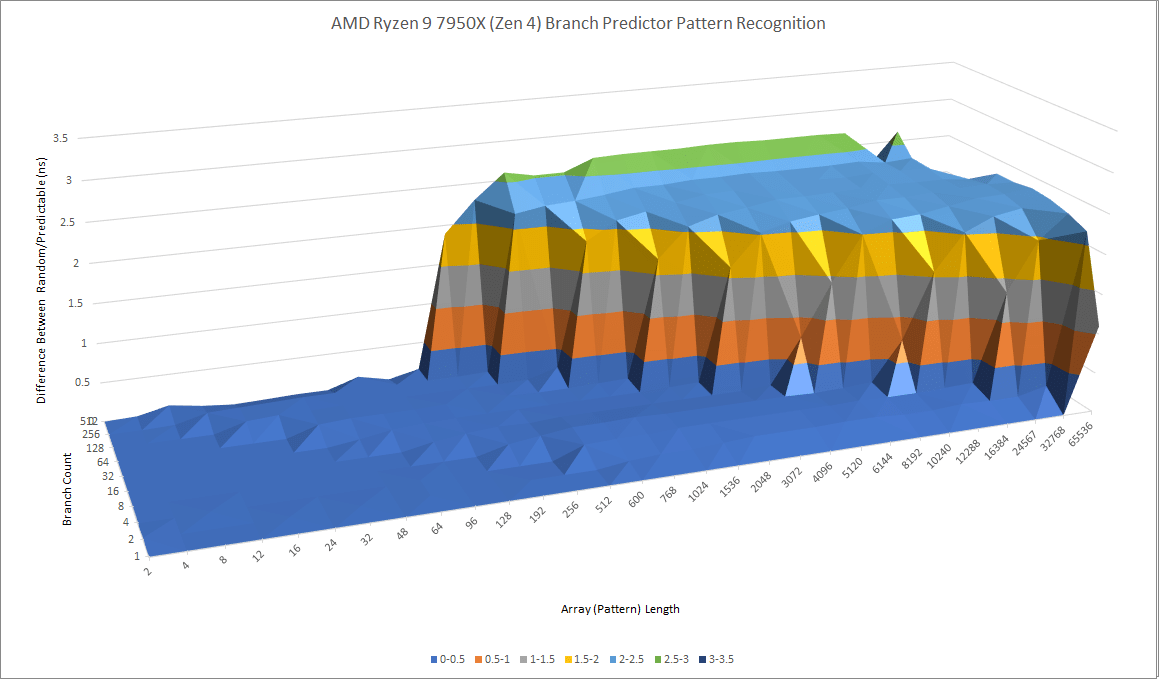
Intel’s Golden Cove takes a different approach. Like earlier Intel big cores, it uses a single level direction predictor. Golden Cove’s pattern recognition capabilities land somewhere between that of Zen 4’s L1 and L2 predictors.
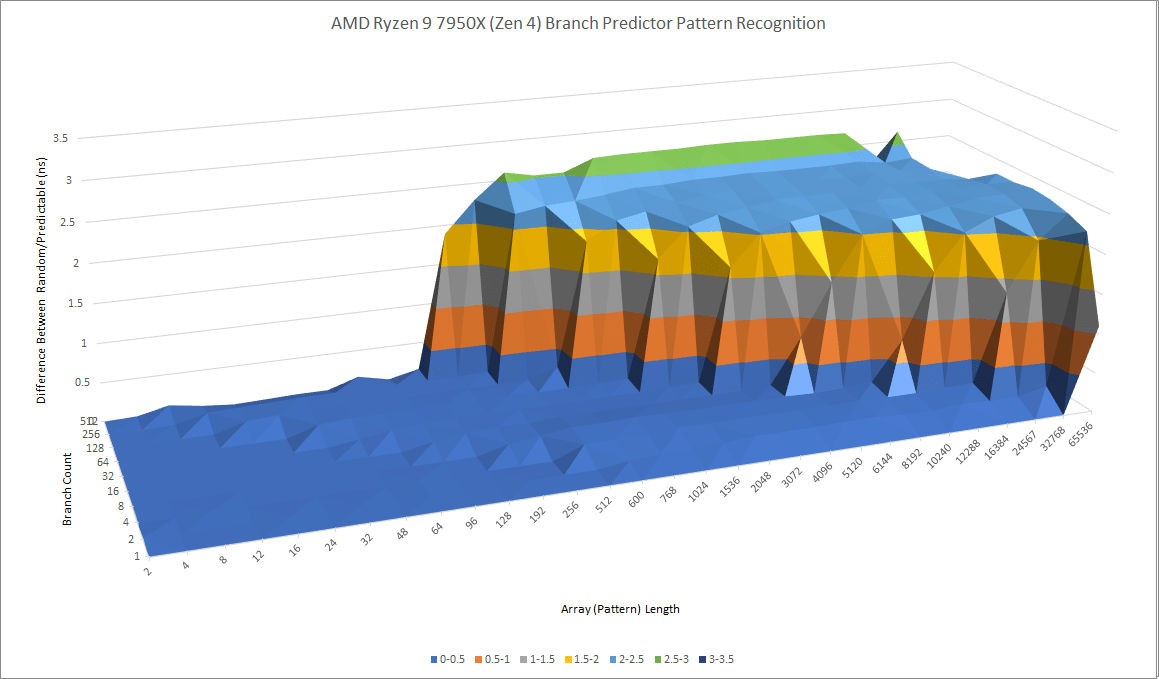
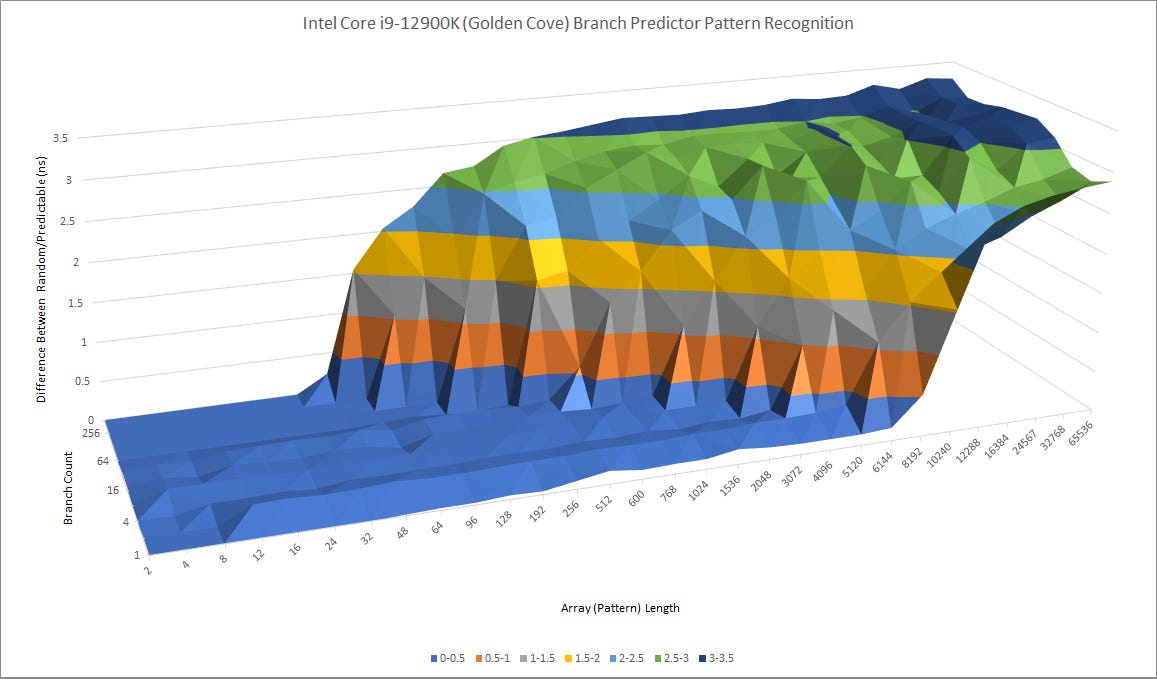
Golden Cove might enjoy an advantage with moderately difficult branches that can be handled by its predictor, but not by AMD’s L1 predictor. Then, Zen 4 will lose frontend bandwidth to L2 overrides. If a program has a lot of difficult to predict branches, Zen 4 will have a significant advantage; Golden Cove will suffer more expensive mispredicts. Mispredicts can be especially costly on Golden Cove, which relies on keeping more instructions in flight to cope with its higher cache latency. Tracking a lot of instructions in your core doesn’t help if you suffer a mispredict and end up throwing them out.
Branch Target Tracking
Having an accurate branch predictor is good, but speed is important too. You don’t want to stall your pipeline too often because you’re waiting for the branch predictor to provide the next fetch target. Like Zen 3, Zen 4 has a two level branch target buffer (BTB) setup with an impressively large and fast first level. Zen 3’s L1 BTB could track 1024 branch targets and handle them with 1 cycle latency, meaning that the frontend won’t need to stall after a taken branch if the target comes from the L1 BTB. Zen 4’s L1 BTB keeps the same 1 cycle latency, but improves capacity. Depending on branch density, Zen 4’s L1 BTB can track up to 3072 branch targets, though in practice it’ll probably be able to track 1024 to 2048 targets.

We’ve seen claims online that Zen 4 has a 1.5K entry L1 BTB. In our tests, Zen 4 might occasionally be able to store two branch targets in each BTB entry. Optimization manuals for prior Zen CPUs detail this mechanism.
Each BTB entry can hold up to two branches if the branches reside in the same 64-byte aligned cache line and the first branch is a conditional branch.
Software Optimization Guide for AMD Family 17h Processors
Our test didn’t show this behavior with prior Zen CPUs, because we only used unconditional branches. Zen 4 might have made the BTB entry sharing scheme more flexible, explaining how we see 3072 branch targets tracked when branches are spaced by 8 bytes.
Zen 4’s L2 BTB sees a slightly size increase as well, with capacity going from 6656 entries on Zen 3 to 8192 on Zen 4. More significantly, Zen 4’s L2 BTB is faster: Zen 3 suffered a three cycle penalty when it needed a branch target from its L2 BTB. Zen 4 brings that penalty down to just one cycle.

Intel’s Golden Cove has a more complex triple level BTB setup. You could even count it as four levels, if you consider GLC’s ability to do two taken branches per cycle. Compared to Zen 4, Golden Cove will be faster for small branch footprints with 128 or fewer branches. Zen 4 will hold an advantage with more branches in play until its 8K L2 BTB capacity is exceeded, after which Golden Cove’s larger last level BTB should put Intel ahead again.
Indirect Branch Prediction
Indirect branches can go to more than one target. Think of them as an option to implement a switch-case statement. They add another dimension of difficulty to branch prediction, because the predictor has to choose between several possible targets. AMD’s CPUs have a separate indirect target array for handling branches that go to multiple targets. In our testing, Zen 4 seems to be able to track up to 3072 branch targets without significant penalty. For a single branch, Zen 4 sees increasing penalties as the number of targets goes past 32, but there’s no clear spike up after that to indicate mispredicts.


Compared to Zen 3, Zen 4 clearly has better tracking capabilities for indirect branches. Penalties are also lower for getting a target out of the indirect target array.
Zen 4 does better than Golden Cove when a lot of indirect branches are in play, but Golden Cove can cope better when a few branches go to a lot of targets. Both architectures seem to take some sort of penalty when they have to select between a lot of targets, but the branch’s behavior is still within the predictor’s tracking capabilities.

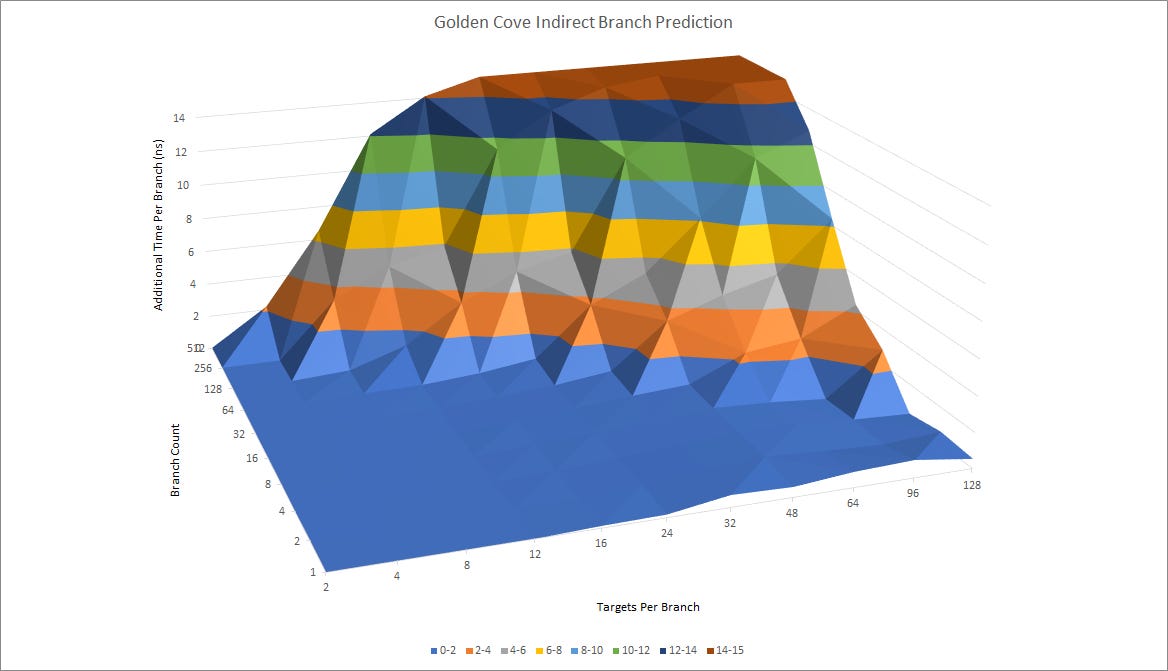
One guess is that Zen 4 has a larger but slower indirect target array. Optimization manuals for prior Zen generations suggest that the indirect target array works as an overriding predictor. If the branch happens to go to the same place it went last time, Zen can use its faster main BTBs to provide the target, meaning that latency for an indirect branch is associated with how many targets it has. We see less of an increase in branch latency as the number of targets increases on Golden Cove, suggesting that Intel is using a different mechanism.
Return Prediction
Call and return pairs are a special case of indirect branches, because returns usually go back to where the function was called from. CPUs use a special return stack to take advantage of this behavior. On a call, the CPU pushes the address of the next sequential instruction onto the stack. When there’s a return, it pops the address off the return stack. This very simple mechanism provides very accurate prediction for returns, because call and return pairs are usually matched. However, a very deep sequence of calls can overflow the stack.

Like prior Zen generations, Zen 4 has a return stack with 32 entries. However, AMD seems to have made improvements so that a single thread can use all 32 entries. Intel’s Golden Cove probably has a return stack, since that’s such an effective way of predicting returns, but doesn’t behave like other CPUs tested here. It’s very fast when calls only go two-deep, but then slows down and doesn’t see a sharp increase in time per call/return pair afterward. Intel might be smoothly transitioning to using its indirect predictor on returns if the return stack overflows.
Frontend: Fetch Bandwidth
Once the branch predictor has determined where to go next, it’s time to fetch the instructions. Zen 4, like previous Zen generations, can accelerate this process with a large micro-op cache. Compared to Zen 3, Zen 4 increases the micro-op cache’s size from 4K to 6.75K entries. Our testing with 8B NOPs doesn’t show much of a micro-op cache capacity increase, as fetch bandwidth drops after 32 KB. Most likely, the L1i is inclusive of the micro-op cache.

Beyond the micro-op cache and L1i, instruction fetch bandwidth drops but remains very decent. Zen 4, Zen 3, and Golden Cove can all sustain approximately 16 bytes per cycle from L2, and slightly above 10 bytes per cycle from L3. That should be enough to prevent instruction bandwidth bottlenecks in all but the highest IPC code with large instruction footprints, because average instruction length is typically under eight bytes even in vectorized code.

To complicate microbenchmarking, Zen 4’s seems to handle NOPs in pairs, in a Graviton 3 like move. We get a ridiculous 12 NOPs per cycle out of the micro-op cache. AMD says the micro-op cache delivers 9 ops per cycle, but throughput is limited by the 6-wide renamer downstream. What’s probably happening is that each renamer slot can handle two NOPs per cycle. To get around this, we’re using an instruction that XORs a register with itself. XOR-ing a register with itself is a common way of zeroing a register, and most renamers will eliminate that.

But the important part is, XOR r,r behaves like a normal instruction all the way up to the renamer. We can also see the difference between micro-op cache and L1i throughput now. Once Zen 4 misses the op cache, throughput is limited by the 4-wide decoders. Like prior Zen generations, the L1i can probably provide more instruction fetch bandwidth than lower cache levels. But the size of Zen 4’s op cache means that it can probably handle most situations that would demand a lot of instruction bandwidth. If a program has a large enough code footprint to spill out of the op cache, and has a lot of long instructions, it’ll probably spill out of L1i as well.
Rename/Allocate
On a CPU with out of order execution, the renamer acts as a bridge between the in-order frontend and the out of order backend. Its main job is to allocate backend resources to track in-flight operations, so they can be properly committed in program order. The renamer is also a convenient place to pull a grab bag of tricks to make backend operation more efficient. Zen 4’s renamer is able to break dependencies between zeroing idioms and register to register MOVs, and behaves a lot like Zen 3’s.
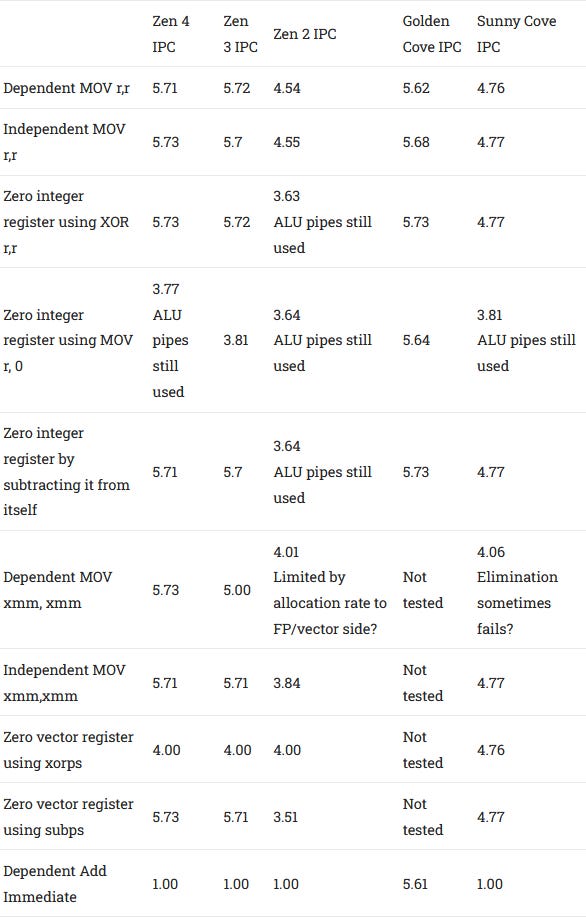
Golden Cove’s renamer is slightly more capable, and can eliminate the MOV r,0 case as well. It can also handle adding small immediate values (values provided in the instruction, rather than from a register) without using ALUs downstream.
Renamer tricks can go further, saving backend resources by not allocating registers for those cases. Eliminated MOVs can be handled by pointing multiple architectural registers to the same physical one, meaning that no extra physical registers have to be allocated for such MOVs. If the renamer knows a register’s value has to be zero, it can remember that by setting a bit in the register alias table instead of allocating a real integer register. Zen 4’s renamer does this too, inheriting characteristics from previous Zen generations, particularly Zen 3.

In most cases, Zen 4 can avoid allocating a physical register when a zeroing idiom is recognized. However, 128-bit XMM registers are an exception. Starting with Zen 3, zeroing one with XORPS or SUBPS will eat a vector register. This is a bit of a surprise, because Zen 2 could avoid register allocation in those cases. Perhaps Zen 2 tracks 128-bit halves of its 256-bit vector registers independently, but Zen 3 and Zen 4 do tracking at 256-bit granularity. Executing a VZEROUPPER instruction before the test sequence doesn’t make a difference.
Intel can avoid allocating a register in all of the cases we tested, and this capability goes back at least to Skylake. AMD is still catching up even in 2022, though these are relatively minor details.
Out of Order Resources
Like previous Zen generations, Zen 4 makes incremental improvements to out of order buffer sizes. Structure size changes range from a 25% increase in ROB capacity, to nothing at all with the store queue. For the structures that changed, entry count typically increases by 10-20%. Overall, these changes are slightly larger than the ones we saw going from Zen 1 to Zen 2.

Compared to its primary Intel rivals, Zen 4 remains a rather small core in terms of reordering capacity. Many key structures are even smaller than Sunny Cove’s, let alone Golden Cove’s. But as we noted in our Golden Cove article, Intel needs more reordering capacity to deal with their higher latency cache setup.
In some areas, Zen 4 also punches a bit harder than its headline reorder buffer capacity suggests. We measured 202 integer registers (out of 224) available to hold speculative results, which covers 63% of ROB capacity. On Golden Cove, we measured around 242 integer registers, or 47.2% of ROB capacity. Golden Cove is thus more likely to have its reordering capacity limited by lack of integer registers, and that’s made worse because Golden Cove seems to be less efficient at using its physical register file. For Zen 4, a measured reordering capacity of 202 integer additions means that 22 physical integer registers were used to hold non-speculative results. Assuming Intel didn’t reduce the integer register file size between Sunny Cove and Golden Cove, our measured result of 242 integer registers means that 38 were not available to hold speculative results.
Zen 4’s reorder buffer is also special, because each entry can hold up to 4 NOPs. Pairs of NOPs are likely fused by the decoders, and pairs of fused NOPs are fused again at the rename stage. While this is unlikely to have a major effect in actual code, it was funny to measure a reordering capacity of 1265 NOPs. We used a custom test with up to 128 integer adds, 128 floating point adds, 40 stores, and 55 branches (in that order) to confirm AMD’s published 320 entry ROB capacity.
Scheduling and Execution
Scheduler and execution pipe layout were not changed from Zen 3. Zen 3’s scheduler setup is a significant upgrade from Zen 2, and provides a lot of flexibility on the integer side by sharing scheduling queues between ALU and AGU ports. On the floating point and vector execution side, Zen 3 and Zen 4 retain the large non-scheduling queue found in previous Zen generations, but move from a unified quad-port scheduler to two triple port schedulers. In practice, this should behave a lot like a unified scheduler, because both schedulers have similar pipes attached to them.
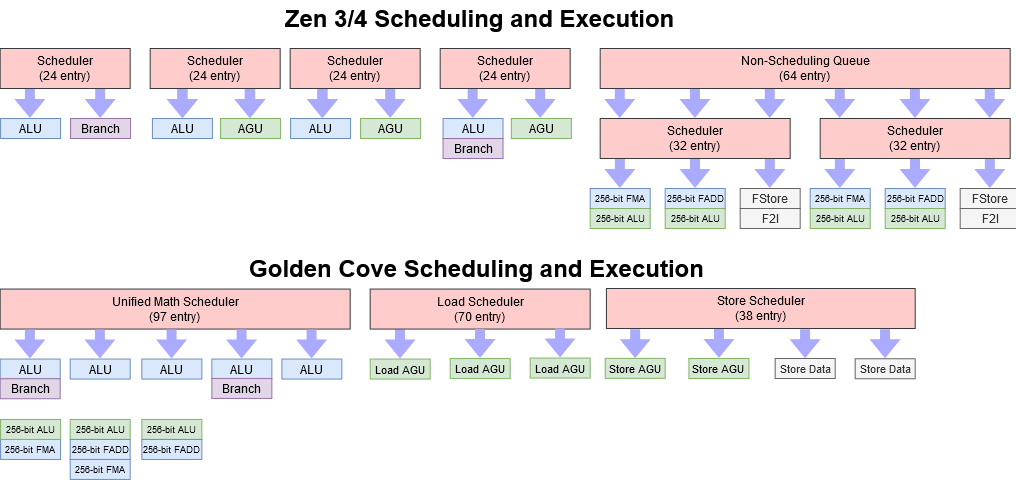
Scheduler structures tend to be expensive, in terms of both power and area. A scheduling queue potentially has to check every entry every cycle, to see if it’s ready to execute. To make things even harder, it has to be able to send an instruction for execution on the same cycle it gets marked ready. Delaying by even one cycle can cause a devastating 10% IPC decrease, all by itself. All of that gets harder and harder to pull off at high clocks.
AMD likely opted to focus on increasing clock speed instead of boosting scheduler capacity. Increasing scheduling queue size runs into diminishing returns. On the other hand, performance usually scales very well with clock speed. That is, IPC usually doesn’t see too big of a decrease as clock speed increases, as long as your cache setup is good enough at preventing memory bottlenecks. AMD’s engineers probably saw that they could get a larger overall performance increase by running the core at higher clocks, than increasing IPC with a beefed up scheduler setup.
AVX-512 Implementation
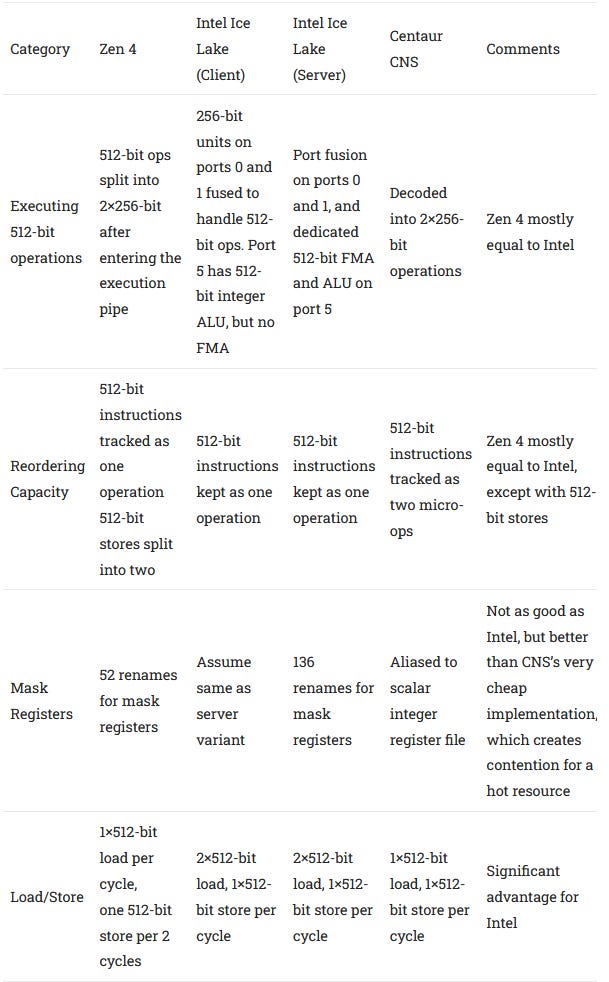
Zen 4 is the first AMD architecture to implement the AVX-512 instruction set extension. As we noted in our coverage of the Gigabyte leak, Zen 4 is about on par with Ice Lake in terms of AVX-512 feature support. In terms of implementation, Zen 4 aims for a power, area, and performance balance that lands between Centaur CNS’s, and that of Intel’s server chips.

AMD had a long tradition of supporting longer vector lengths by decoding them into two micro-ops. Bulldozer supported AVX by breaking 256-bit operations into two 128-bit micro-ops. K8 did the same, breaking 128-bit SSE operations into two 64-bit operations. This strategy let AMD support a new instruction set extension with very little power and area overhead, but also meant that they didn’t benefit much when applications did take advantage of wider vectors. In contrast, Intel brought full-width AVX execution when Sandy Bridge came out. Server Skylake did the same with AVX-512.
Zen 4 partially breaks this tradition, by keeping instructions that work on 512-bit vectors as one micro-op throughout most of the pipeline. Each AVX-512 instruction thus only consumes one entry in the relevant out-of-order execution buffers. I assume they’re broken up into two operations after they enter a 256-bit execution pipe, meaning that the instruction is split into two 256-bit halves as late as possible in the pipeline. I also assume that’s what AMD’s “double pumping” is referring to. Compared to Bulldozer and K8’s approach, this is a huge advantage. Tracking two micro-ops for every 256-bit or 128-bit instruction meant those older architectures couldn’t use wider vectors to keep more work in flight. However, Zen 4’s approach is slightly more expensive in terms of area and power, because the vector registers were extended to be 512 bits wide.
512-bit stores are an exception to the rule. They’re still decoded into two micro-ops, which means they consume two valuable store queue entries. The store queue can be a pretty hot structure, especially since stores have to stay there until retirement because only known-good data can be committed to cache. AMD’s store queue is a lot smaller than Intel’s, so if there’s one serious shortcoming of Zen 4’s AVX-512 implementation, it’s how stores are handled.
This is likely because AMD didn’t implement wider buses to the L1 data cache. Zen 4’s L1D can handle two 256-bit loads and one 256-bit store per cycle, which means that vector load/store bandwidth remains unchanged from Zen 2. The Gigabyte leak suggested alignment changed to 512-bit, but that clearly doesn’t apply for stores.

Vector execution throughput for the most common operations has also been largely unchanged since Zen 2, which was the first AMD architecture to bring full-width AVX execution. Zen 2, 3, and 4 all have two 256-bit FMA units and four 256-bit ALUs. At first this might seem unexciting. But in a lot of workloads, feeding the execution units is more important than having a lot of them. Against Intel, Zen 4 has competitive vector throughput already. Intel doesn’t have a significant throughput advantage unless we look at server variants of their architectures, which have an extra 512-bit FMA unit on port 5.
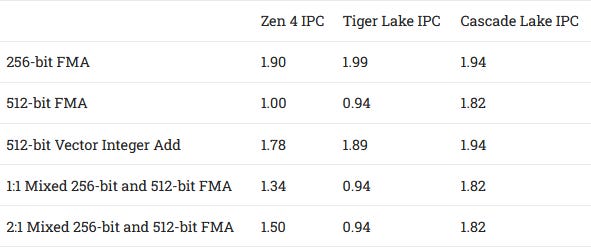
While Intel’s client architectures have comparable vector throughput to Zen 4, 512-bit operations through 256-bit pipes are handled differently. Intel fuses two 256-bit units across ports 0 and 1 to handle a 512-bit operation. This leads to some interesting characteristics when mixing 256-bit FMA instructions with 512-bit ones. Intel is stuck at one vector operation per cycle, likely because 256-bit FMA units on ports 0 and 1 have to be set to 1×512-bit or 2×256-bit mode, but cannot be in both modes at once.
AVX-512 also allows masking for most operations via a set of K (mask) registers. To handle that, Zen 4 adds a relatively small mask register file. With around 52 renames for mask registers, this register file is much smaller than what we see on Skylake-X or Ice Lake. In terms of maximum reordering capacity, Zen 4 is closer to Ice Lake than Skylake-X, so AMD didn’t put a lot of emphasis on this structure. To summarize the various AVX-512 implementation decisions:
Zen 4 sees larger gains from AVX-512 than Centaur CNS, which implements AVX-512 support with the absolute minimum of die area overhead. Intel in turn sees larger gains than Zen 4. Golden Cove with AVX-512 enabled actually outperforms Zen 4 in this benchmark, in both scaling and absolute performance. But that may be a moot point this generation because Intel couldn’t enable AVX-512 support in their hybrid client chips.

In summary, AMD’s AVX-512 implementation focuses on better feeding their existing execution capacity, and only using additional die area and power where it’ll make the most impact. The most expensive change probably had to do with extending the vector register file to make each register 512-bits wide. AMD also had to add a mask register file, and other logic throughout the pipeline to handle the new instructions. Like Intel’s client implementations, AMD avoided adding extra floating point execution units, which would have been expensive. Unlike Intel, AMD also left L1D and L2 bandwidth unchanged, and split 512-bit stores into two operations.
The result is a very credible first round AVX-512 implementation. Compared to Intel, AMD still falls short in a few key areas, and is especially at a disadvantage if AVX-512 code demands a lot of load/store bandwidth and fits within core-private caches. But while Zen 4 doesn’t aim as high as Intel does, it still benefits from AVX-512 in many of the same ways that client Intel architectures do. AMD’s support for 512-bit vectors is also stronger than their initial support for 128-bit vectors in K8 Athlons, or 256-bit vectors from Bulldozer to Zen 1. Zen 4 should see clear benefits in applications that can take advantage of AVX-512, without spending a lot of power or die area.
Part 1 Conclusion
Zen 4 introduces substantial frontend and execution engine improvements. Branch predictor and micro-op cache improvements let the frontend bring instructions into the core faster, and build on top of Zen 3’s already strong frontend. Increased reordering capacity in the backend lets Zen 4 better absorb cache and execution latency.
However, AMD left the execution units and scheduler setup mostly unchanged. Execution units aren’t a big deal because Zen 3 already had plenty of execution capacity, and feeding the execution units is more important than adding more. However, not beefing up any scheduling queues is a bit surprising though. AMD boosted scheduling capacity and made at least minor scheduler layout changes with every prior Zen generation. Zen 3 already had plenty of scheduling capacity in a flexible layout, so Zen 4’s identical setup is not weak by any means. But scheduling capacity might become more of a limiting factor as other components see improvements. Zen 4 will generally be a strong performer with integer code, though IPC increases take a back seat to clock speed boosts.
Zen 4 also falls behind in load and store bandwidth. Its L1D can provide 512 bits of load bandwidth and 256 bits of store bandwidth per cycle. That puts Zen 4’s L1D bandwidth in line with Zen 2 and Zen 3 on AMD’s side, or Haswell and client Skylake on Intel’s side. Zen 4 will still be a strong performer in code that uses 256-bit vectors (or smaller), though perhaps not quite up to Golden Cove’s level.
However, AMD has an ace up its sleeve with AVX-512 support. If code uses new AVX-512 instructions and features that have optimized paths on Zen 4, but no straightforward AVX2 equivalents, Intel will find themselves at an uncomfortable disadvantage. Zen 4 might not have an all-out AVX-512 implementation. But it’s still more than strong enough to beat the stuffing out of an otherwise competitive opponent that lacks AVX-512 support, given the right application.
That of course assumes that both processors aren’t bottlenecked by their memory subsystem. In well threaded, vectorized applications, cache and memory performance can be extremely important. That’s a complicated topic, and we’ll be covering Zen 4’s load/store subsystem, and data-side memory hierarchy in a followup article.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.
Updates
11-7-2022: Removed permute units from Zen 4 execution unit diagram