
Intel's Clearwater Forest E-Core Server Chip at Hot Chips 2025
Sometimes, the solution to a problem is more E-Cores

E-Cores have been a central fixture of Intel's client CPU strategy for the past few years. There, they help provide performance density and let Intel compete with AMD on multithreaded applications. But performance density isn't just useful in the client scene. The past few years have seen a number of density focused server designs, like Ampere's 80 core Altra and 192 core AmpereOne as well as AMD's 128 core Bergamo. Intel doesn't want to be left out of the density-optimized server segment, and their E-Cores are perfect for breaking into that market.

Clearwater Forest uses Skymont E-Cores, giving it a huge jump in per-core performance over the Crestmont E-Cores used in Intel’s prior Sierra Forest design. Skymont is wider and has more reordering capacity than its predecessor. In a client design, its performance is not far off that of Intel’s P-Cores, so it provides substantial single-threaded performance. Skymont cores are packed into quad core clusters with a 4 MB L2.
Packaging and Physical Aspects
Skymont clusters are then packed onto compute dies fabricated on Intel’s 18A node, because CPU cores have the most to gain from an improved process node. A compute die appears to contain six Skymont clusters, or 24 cores.
Intel’s 18A node features a number of improvements related to density and power delivery. These should help Skymont perform better while using less area and power. While not mentioned in Intel’s presentation, it’s notable that Intel will be implementing Skymont on both their 18A node in Clearwater Forest, as well as TSMC’s 3nm node in Arrow Lake. It’s a showcase of the company’s ability to be process node agnostic, drawing a contrast with how older Intel cores went hand-in-hand with Intel nodes.

Compute dies are placed on top of Intel 3 base dies using 3D stacking. Base dies host the chip’s mesh interconnect and L3 slices. Placing the L3 on separate base tiles gives Intel the die area necessary to implement 8 MB L3 slices, which gives a chip 576 MB of last level cache. Clearwater Forest has three base dies, which connect to each other over embedded silicon bridges with 45 micron pitch. For comparison, the compute dies connect to the base dies using a denser 9 micron pitch, if I heard the presenter correctly.

Intel’s mesh can be thought of as a ring in two directions (vertical and horizontal). Clearwater Forest runs the vertical direction across base die boundaries, going all the way from the top to the bottom of the chip. The base dies host memory controllers on the edges as well, and cache slices are associated with the closest memory controller in the horizontal direction. I take this to mean the physical address space owned by each cache slice corresponds to the range covered by the closest memory controller. That should reduce memory latency, and would make it easy to carve the chip into NUMA nodes.

Each base die hosts four compute dies, or 96 Skymont cores. Across the three base dies, Clearwater Forest will have a total of 288 cores - twice as much as the 144 cores on Sierra Forest.
IO dies sit at the top and bottom of the chip, and use the Intel 7 process because IO interfaces don’t scale well with improved process nodes. Intel reused the IO dies from Sierra Forest. There are definitely parallels to AMD reusing IO dies across generations, which streamlines logistics and saves on development cost.
Interconnect and Memory Subsystem
Skymont basically has two interconnect levels in its memory hierarchy: one within the cluster, and one linking the system as a whole. Within the cluster, each Skymont core has the same L2 bandwidth as Crestmont, but aggregate L2 bandwidth has increased. From prior measurements, this is 64B/cycle of L2 bandwidth per core, and 256B/cycle of total L2 bandwidth. The prior Crestmont generation had 128B/cycle of L2 bandwidth within a cluster.
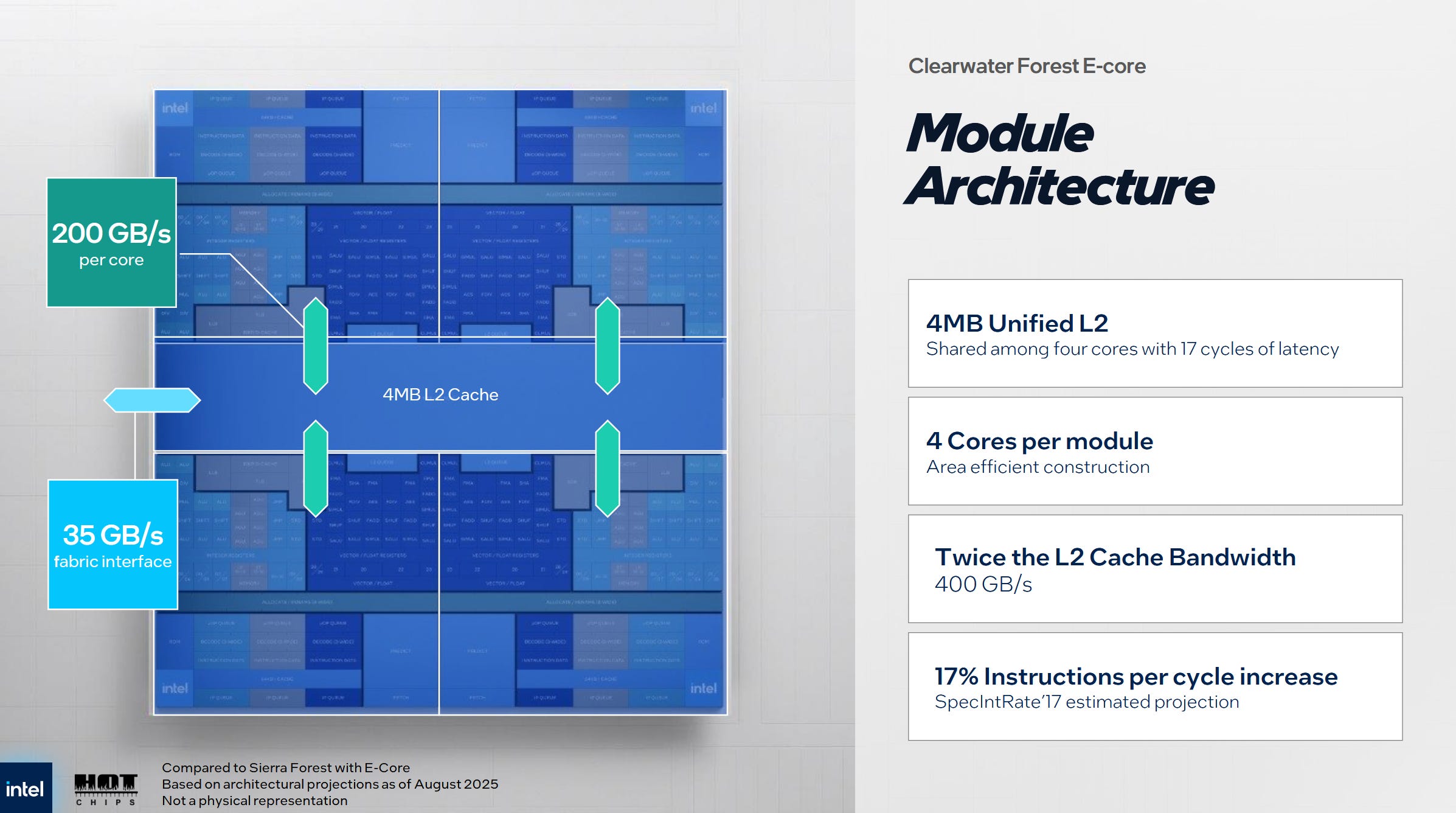
A Skymont cluster can sustain 128 L2 misses out to the system level interconnect. Getting more misses in flight is crucial for hiding memory subsystem latency and achieving high bandwidth. Intel notes that a Skymont cluster in Clearwater Forest has 35 GB/s of fabric bandwidth. I suspect this is a latency-limited measured figure, rather than something representing the width of the interface to the mesh. On Intel’s Arrow Lake desktop platform, a 4c Skymont cluster can achieve over 80 GB/s of read bandwidth to L3. That hints at high L3 latency, and perhaps a low mesh clock. In both cases, Skymont’s large 4 MB L2 plays a vital role in keeping traffic demands off the slower L3. In a server setting, achieving a high L2 hitrate will likely be even more critical.

Even though L3 latency is likely high and bandwidth is mediocre, Clearwater Forest’s huge 576 MB L3 capacity might provide a notable hitrate advantage. AMD’s VCache parts only have 96 MB of L3 cache, and cores in one cluster can’t allocate into another cluster’s L3. Intel sees ~1.3 TB/s of DRAM read bandwidth using DDR5-8000, which is very fast DDR5 for a server setup.
In a dual socket setup, UPI links provide 576 GB/s of cross-socket bandwidth. That’s quite high compared to read bandwidth that I’ve measured in other dual socket setups. It’d certainly be interesting to test a Clearwater Forest system to see how easy it would be to achieve that bandwidth.
Intel also has a massive amount of IO in Clearwater Forest, with 96 PCIe Gen 5 lanes per chip. 64 of those lanes support CXL. Aggregate IO bandwidth reaches 1 TB/s.
Final Words
Skymont is a powerful little core. If it performs anywhere near where it is on desktop, it should make Intel very competitive with AMD as well as the newest Arm server chips. Of course, core performance depends heavily on memory subsystem performance. L3 and DRAM latency are still unknowns, but I suspect Clearwater Forest will do best when L2 hitrate is very high.
For their part, Intel notes that 20 Clearwater Forest server racks can provide the same performance as 70 racks, presumably using Intel’s older server chips using P-Cores. Intel used SPEC CPU2017’s integer rate benchmark there, which runs many copies of the same test and thus scales well with core count.
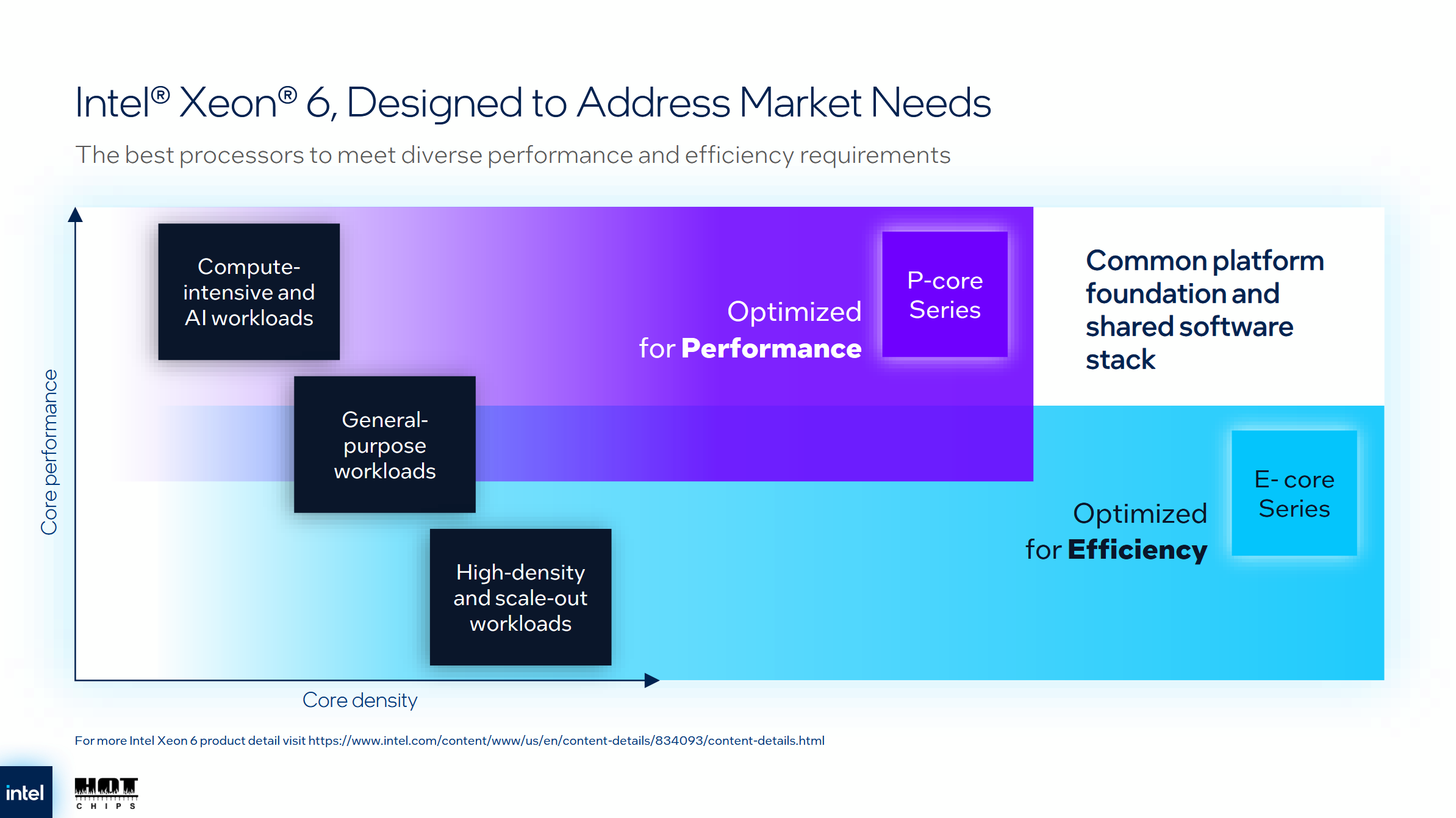
Evaluating Clearwater Forest is impossible before actual products make their way into deployments and get tested. But initial signs point indicate Intel’s E-Core team has a lot to be proud of. Over the past ten years, they’ve gone from sitting on a different performance planet compared to P-Cores, to getting very close to P-Core performance. With products like Clearwater Forest and Arrow Lake, E-Cores (previously Atom) are now established in the very demanding server and client desktop segments. It’ll be interesting to see both how Clearwater Forest does, as well as where Intel’s E-Cores go in the future.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
I thought Clearwater Forest used Darkmont cores?
to be fair, " twice as much as the 144 cores on Sierra Forest" is only true because Sierra forrests top model 6900E never launched. But it was announced several times with 288C and it would have been needed to counter AMD Bergamo yet alone recent Turin dense.
According to Phoronix a 2P XEON 6766E is close in general Linux performance to a single socket Epyc 9754. Thats not great. CWF is desperately needed by intel DCG, not only to close the gap in performance but more to actually be available. Lets hope the chiplet approach makes them achieve the scale they need to actually release a 288C model this time around.