
Skymont in Desktop Form: Atom Unleashed

Skymont is Intel's newest E-Core architecture. E-Cores trace their lineage to low power and low performance Atom cores of long ago. But E-Cores have become an integral part of Intel's high performance desktop strategy, letting Intel maintain competitive multithreaded performance against AMD's high core count chips. Skymont made its debut in Intel's Lunar Lake mobile CPUs, replacing Crestmont E-Cores from the prior Meteor Lake chips. Intel showed off impressive gains against low power Crestmont cores in Meteor Lake. However, gains over standard E-Cores were minimal.

Much of this came down to cache setup. Skymont served double duty in Lunar Lake, improving multithreaded performance while sitting on a low power island to reduce power draw during light tasks. The latter requirement forced Skymont off the ring bus, leaving the Skymont cluster with no L3 cache. Lunar Lake did have a 8 MB memory side cache, but the memory side cache is both smaller and much higher latency than the L3. Rather than boosting CPU or GPU performance, Lunar Lake’s memory side cache was really meant to help blocks without large caches of their own. The NPU and display engine are prominent examples.

Desktop chips don’t have to worry about every last watt, so Arrow Lake feeds Skymont with a more performance oriented system architecture. Skymont clusters sit on the same high speed ring bus as the P-Cores, and share the same 36 MB L3. Intel’s L3 as of late hasn’t been a particularly high performance cache, and Arrow Lake is no different. L3 load-to-use latency from a Skymont core approaches 69 cycles, which is substantially worse than in competing AMD designs.

Cycle count latency is very similar to Meteor Lake. Crestmont had about 69 cycles of load-to-use latency from a smaller 24 MB L3. However, Arrow Lake’s higher power budget allows higher clocks, and with that comes lower actual latency. Compared to Meteor Lake, Arrow Lake gives its E-Cores a 50% L3 capacity increase with better latency.
Higher clocks help at faster cache levels too. Skymont regressed L1D latency to 4 cycles, compared to three cycles on Crestmont. Lunar Lake’s similar E-Core clocks meant just over a 25% L1D latency regression compared to Crestmont. On Arrow Lake, the gap narrows to 8%. L2 latency improves too, giving Arrow Lake’s E-Cores both a large and relatively fast L2.
L3 Bandwidth, or L2 Miss Bandwidth
Like prior E-Cores and their Atom ancestors, Skymont is implemented in quad core clusters with a shared L2 cache. L2 miss traffic from all cores in the cluster must pass through the off-cluster interface, which can act as a bandwidth pinch point. On Lunar Lake, that off-cluster interface leads to Intel’s Scalable Fabric. On Arrow Lake, it leads to a higher speed ring bus.

Here, I want to see how quickly I can move data through that potential pinch point. To do so, I’m looking at bandwidth with a test size that fits within L3. For Lunar Lake, which doesn’t give Skymont a L3, I’m using a 10 MB test size that should fit within the total 4 + 8 MB capacity of the L2 cache and memory side cache. That assumes the memory side cache is not inclusive of L2. More accurately, I’m estimating L2 miss bandwidth here. But on most platforms, that’s L3 bandwidth, and I’ll refer to it as L3 bandwidth for simplicity.

Arrow Lake’s Skymont cluster enjoys a 37% increase in L3 bandwidth compared to Meteor Lake. Quad core E-Core clusters on Meteor Lake, Lunar Lake, and even Alder Lake from several years ago all had about 60 GB/s of L2 miss bandwidth. Arrow Lake’s bandwidth increase is nice to see. Bandwidth to a high latency data source, like L3 or DRAM, is often limited by memory level parallelism capabilities. Arrow Lake’s Skymont clusters likely get a larger queue for tracking L2 misses between the L2 complex and the rest of the system.
Like an E-Core cluster, high performance cores have one interface to L3. A P-Core should therefore have similar L2 miss bandwidth to a quad core E-Core cluster. However, that’s not the case. A Lion Cove P-Core on Arrow Lake can only achieve 54.2 GB/s of read bandwidth from L3, while a Skymont cluster can get over 80 GB/s. Curiously, that’s reversed on Meteor Lake. A Redwood Cove P-Core can sustain 72.2 GB/s of L3 bandwidth, which is more than the ~59 GB/s possible from a Crestmont cluster.

I also tested with a read-modify-write pattern to see whether a core or cluster’s L2 to L3 interface has separate read and write paths. AMD’s Zen 2 has 32 bytes per cycle of bandwidth from the core to L3, in both the read and write directions. Arrow Lake’s Skymont cluster is similar in that respect, achieving twice as much bandwidth with an even mix of read and write traffic. Crestmont from Meteor Lake sees less bandwidth with this pattern, suggesting that reads and writes contend for the same resource.

The Core Ultra 9 285K runs its ring bus at 3.8 GHz, while the Core Ultra 7 155H uses a 3.3 GHz ring clock. Therefore, Arrow Lake’s Skymont cluster benefits both higher ring bus clocks and better bandwidth per ring bus cycle. That’s in line with what I expect for a higher performance desktop design.
SPEC CPU2017
SPEC CPU2017 is an industry standard benchmark. CPU designers use traces collected from SPEC workloads to inform tuning decisions, and system builders present SPEC CPU2017 results to set performance expectations. Here, I’m running SPEC CPU2017’s rate tests with a single copy to evaluate per-core performance.
Higher clock speed and a high performance memory subsystem combine to let an Arrow Lake Skymont core score 51% and 63% higher than its Lunar Lake counterpart in SPEC CPU2017’s integer and floating point test suites, respectively. Seeing such massively improved performance is refreshing after seeing Lunar Lake’s Skymont core post a SPEC CPU2017 integer score nearly identical to Crestmont’s. An Arrow Lake Skymont core actually scores closer to AMD’s last generation Zen 4 than a Lunar Lake Skymont core.
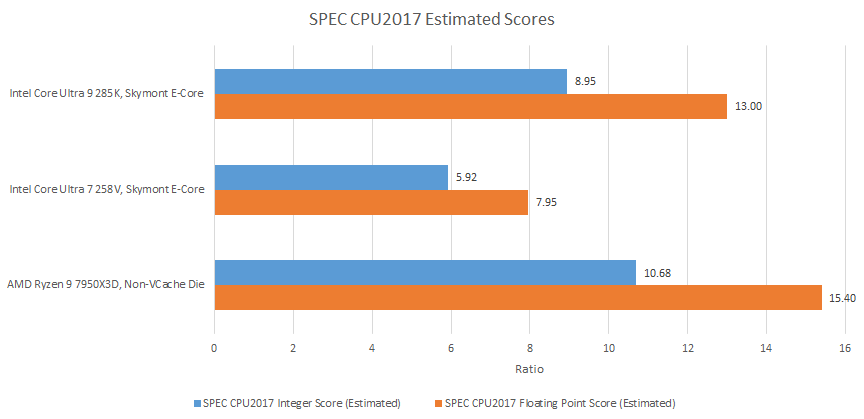
Even though Zen 4 leads by 19.4% and 16.96% in the integer and floating point suites respectively, Arrow Lake’s Skymont cores get close in a few workloads. Zen 4 squeaks by with a 8.25% lead in 525.x264, and just a 5.88% lead in 500.perlbench.

Meanwhile, Zen 4 still holds an impressive 40.67% lead in 557.xz, and a 32.75% lead in 505.mcf. SPEC CPU2017’s floating point suite has more extreme outliers both ways. 521.wrf sees Zen 4 destroy Skymont with a 70% lead. 538.imagick actually sees the density optimized and lower clocked Skymont core win against Zen 4 by a 15% margin. 507.cactuBSSN is also interesting, because somehow Lunar Lake’s Skymont core got destroyed in that test.

From a first look at performance counters, Arrow Lake’s Skymont can take high IPC workloads and run wild with them. 525.x264, 548.exchange, and 500.perlbench all show high IPC potential on other cores, and Skymont excels in them. In the floating point suite, Skymont even breaks the 5 IPC mark on 538.imagick.

Intel has published Skymont’s performance monitoring events in JSON form, giving me an opportunity to evaluate Arrow Lake’s memory subsystem further. Skymont has high reordering capacity and thus plenty of ability to keep going in the face of latency, but high cache hitrates are crucial to letting the core shine. Arrow Lake’s larger L3 is instrumental to letting Skymont reach high IPC on 500.perlbench, because that workload spills out of the 4 MB L2. Lunar Lake’s 8 MB memory side cache only catches about 34% of L2 misses, while Arrow Lake’s 36 MB L3 enjoys 97% hitrate and can service hits with lower latency too. From 500.perlbench, Skymont sometimes has enough reordering capacity to maintain good performance even with Arrow Lake’s mediocre L3 latency. But no core can do well in the face of Lunar Lake’s high latency memory side cache or LPDDR5X, and Skymont is no exception.

When code rarely misses L2, Skymont is at its best and can push beyond 4 or 5 IPC. At the other end of the spectrum, low IPC workloads are often ones that aren’t cache friendly or have a lot of branches. Any time you see cache miss rate go up, Skymont’s IPC goes way down. Of course that applies to all cores, but it relatively hurts Skymont more. For example, 523.xalancbmk is very bound by backend memory access latency on Zen 4, and is also very backend bound on Skymont. Like with 500.perlbench, Arrow Lake’s L3 is able to contain the vast majority of L3 misses, but this time the IPC gain over Lunar Lake is just 25.23%. It’s a reminder that even though Arrow Lake has a higher performance memory subsystem than Lunar Lake, it still suffers higher L3 and DRAM access latency than Zen 4.

From the frontend side, branch prediction accuracy remains an important factor. 505.mcf and 557.xz also show huge leads for Zen 4. 505.mcf is a low IPC workload that’s hit hard by backend memory access latency and frontend branching even on Zen 5. In that test, Skymont drops a lot of performance from bad speculation (usually mispredicts). Unlike on AMD’s Zen 4/5, Skymont’s performance counters only track backend bound slots without further breaking it down into core bound and memory latency bound categories. But I suspect much of the performance loss from a full backend is down to memory latency, given 505.mcf’s cache unfriendly nature.
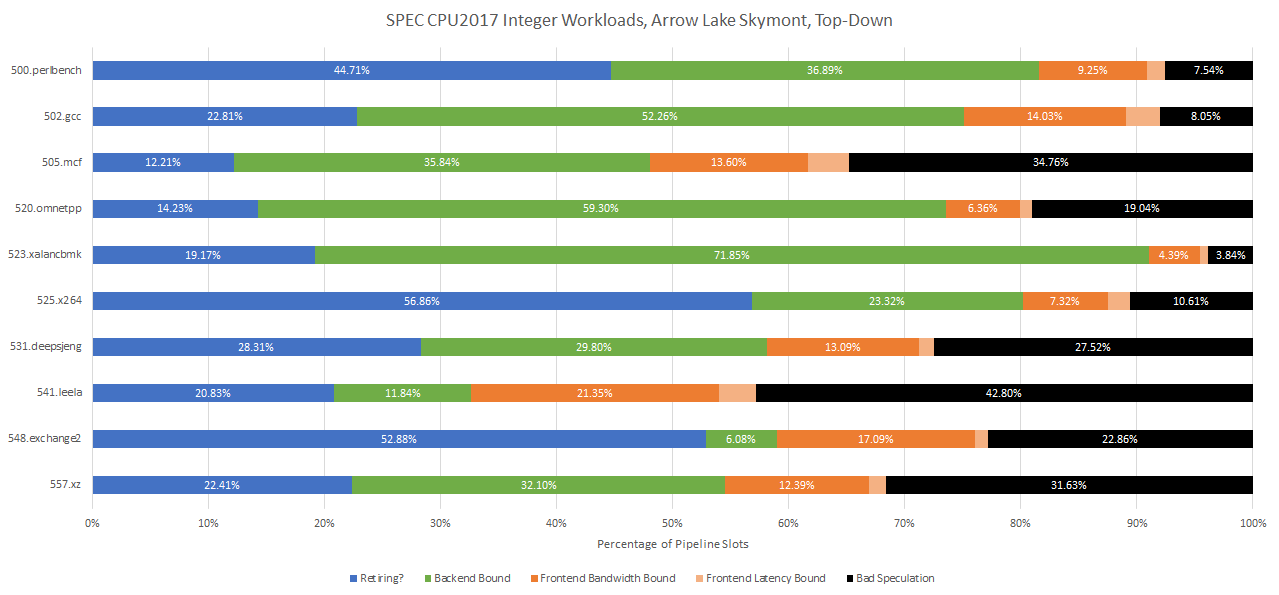
557.xz isn’t necessarily a low IPC workload, as Zen 4 can almost average 2 IPC on it. But Skymont can’t quite get there because it loses a lot of throughput to branch mispredicts. Of course for every 557.xz or 505.mcf, there’s a case like 538.imagick. If you can keep the bulk of your data in the fastest caches and have plenty of instruction level parallelism, Skymont can hit very hard.
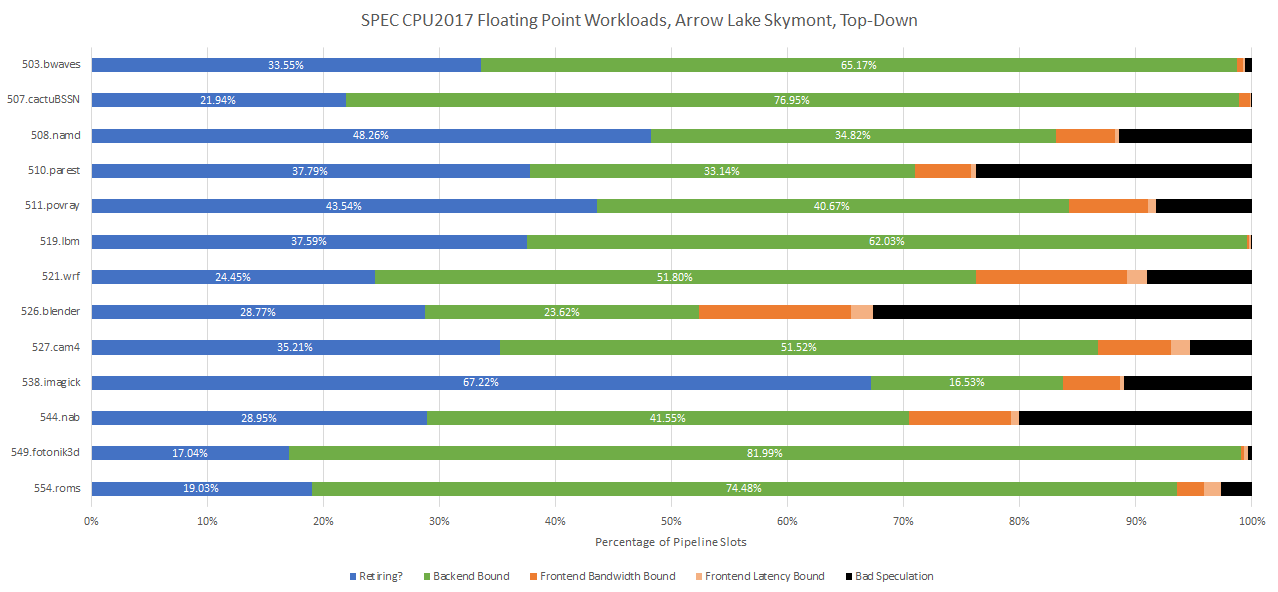
From a top-down view, Skymont is very backend bound. Skymont does have a huge 416 entry reorder buffer compared to Crestmont’s 256 entries. Even Zen 4 only has a 320 entry reorder buffer. Reorder buffer capacity however only sets a cap on how many instructions a core can have in flight. Actual reordering capacity can be lower if another resource gets exhausted first.

In SPEC CPU2017’s integer workloads, Skymont’s reorder buffer capacity is often not a limiting factor. Its schedulers often fill up first, causing lost renamer slots and thus core throughput. Skymont’s load/store queues are also prone to filling up in several of the lower IPC workloads like perlbench, gcc, mcf, and omnetpp. Allocation restrictions also pop up from time to time. That’s likely when the renamer has more micro-ops ready than a backend scheduler or queue can accept that cycle.

In SPEC CPU2017’s floating point workloads, Skymont sometimes fully utilizes its ROB capacity. But when it’s pushed hard to hide latency in low IPC workloads like 554.roms or 549.fotonik3d, Skymont’s scheduler layout and load buffer become significant limitations. Skymont does have an impressive number of total scheduler entries, but tuning a distributed scheduler can be difficult because there are so many degrees of freedom. As for the load queue, going from 80 to 114 entries doesn’t give same percentage increase in capacity as Skymont’s ROB size increase.
Vector Performance
SPEC CPU2017 is a portable source code benchmark, which means compiler code generation plays a crucial role. Compilers are usually pretty bad at emitting vectorized code, but vector extensions like AVX can play a crucial role in some applications.
libx264 Video Encoding
libx264 is one such example. Software video encoding offers better compression efficiency than hardware encoders, though at the cost of being more computationally intensive. libx264 has custom code paths for just about every level of ISA extension support including AVX-512. I wanted to revisit libx264 performance with Zen 2, because Gracemont could get close to Zen 2’s performance but fell behind with libx264. Zen 2 is also organized into quad core clusters, much like Gracemont and Skymont.
With one thread per physical core, Skymont maintains both higher clock speeds and better average IPC for an overall 10% win. It’s great progress, since vector execution was one of Atom’s traditional weaknesses.
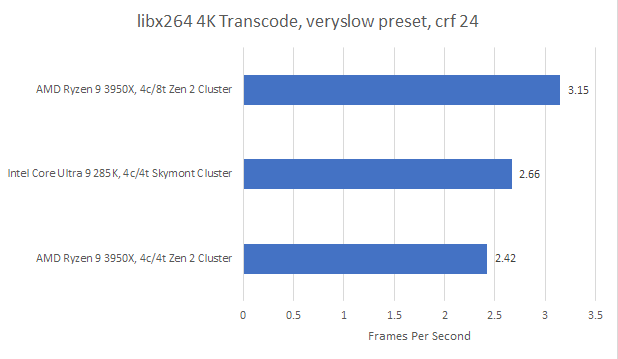
From another angle though, Zen 2 achieves a massive 30% performance gain from SMT. That puts it well ahead of Skymont, despite being a much smaller core that clocks lower under multithreaded load. Like Zen 4, Zen 2 has low latency caches that put less pressure on its small out-of-order execution engine. Thread level parallelism helps hide even that latency, making better use of Zen 2’s execution resources.
Y-Cruncher
Y-Cruncher computes digits of Pi, and here I’m telling it to compute 2.5 billion digits. Y-Cruncher will happily use the best vector ISA extensions you can give it, including AVX-512. Of course, Zen 2 and Skymont don’t support AVX-512, so AVX2 will suffice.
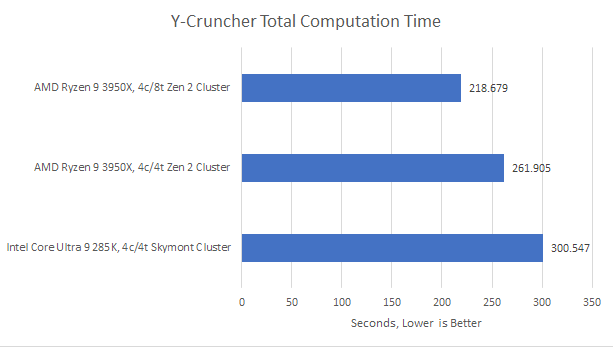
This time, Skymont fails to match Zen 2, even with equal thread counts. Keeping 256-bit instructions as a single micro-op also helps efficiently utilize reordering capacity, and Y-Cruncher takes advantage of wide vectors even more than libx264 does.
Final Words
Skymont is a very wide core with deep reordering capacity and an almost comically high execution port count. Despite being density optimized, Skymont is still capable of moderately high clock speeds. It’s a potent combination, and shows there’s real ambition behind Intel’s E-Core effort. I feel like Intel’s E-Core team wanted to approach P-Core performance territory by aiming for massive IPC while clocking only somewhat lower.
But going for high performance in a modern CPU is an incredibly difficult task, and any core is at the mercy of the memory subsystem it sits on. That’s on full display with Lunar Lake and Arrow Lake. The latter’s better memory subsystem and bigger power budget do a lot to show off Skymont’s potential. And Skymont is very impressive if given a high IPC workload that fits within L1 or L2. In those cases, it can take on a last generation high performance core like Zen 4 and come out ahead. Even in more difficult workloads, Skymont can give a good account of itself. It can’t match Zen 4 overall, but lands within striking distance more often than I’d expect from a density optimized core.

The overall performance picture though, is that Skymont is still not at the same level as a high performance core. It’s behind in SPEC CPU2017’s integer suite, which represents a favorable set of workloads for a wide core with relatively weak vector execution. In vector-heavy workloads, it’s still hit or miss against Zen 2. Thus Skymont lacks the performance to replace Lion Cove or take on AMD’s best.
I can understand why people might be tempted to look at Skymont’s 8-wide, high clocking core, and wonder if it’s on its way to becoming a P-Core replacement. I don’t think it’s there yet. Skymont still has to work within tight area restrictions. A huge branch predictor like the one on Zen 4 won’t align with that goal, even if branch prediction is critical to some workloads. Intel’s memory subsystem, even the one in Arrow Lake, has relatively high latency. A core with more reordering capacity is in a better place to mitigate that latency. That means a ROB adequately supported by other resources like schedulers and load/store queues. Both are expensive structures that are likely difficult to grow within a small die area budget. Natively handling wide vectors is also not on the menu for a density optimized core.
Even with those weaknesses in mind, Skymont is the closest Intel’s Atom line has come to being a true high performance contender. For now, Skymont’s strength is still in numbers. But it’s so very close to taking on last-generation high performance cores, and Intel’s E-Core team deserves praise for their efforts. I’m excited to see what they come up with next.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
This is the first time that Atom actually captures my interest. From its lame first releases, crushed by Bobcat etc, to its mobile failures, and E-cores proving to be mostly a break compared to well executed SMT of "full fat" cores - this now is different. Let's hope Intel does not mess this up in its current state of disorganization
I'll read it in a moment, since I love architectural deep dives. But question first:
Do you have Patreon or Discord at least? That was TL;DR, I decided to spare you rest and will put it in reply so that people are less assaulted by my off-topic ramblings.