
Genoa-X: Server V-Cache Round 2

Last year we posted an article about Milan’s V-cache performance where we dived into the bandwidth and latency performance of the then-latest innovation by AMD to increase performance of its CPUs. Now, we have already done an article about Zen 4’s V-Cache and what it looks like so this article will be looking more at the memory system and the socket-to-socket performance of Genoa-X.
Latency
AMD stated in ISSCC 2023 that the added latency for Zen 4’s V-cache is the same 4 cycles as Zen 3’s V-cache.

We see this behavior on the 7950X3D very clearly, however on Genoa-X the behavior is quite different from what we would expect.

Genoa-X starts to increase in latency around 32MB which at first would imply that maybe we aren’t seeing V-Cache, however when we get to the bandwidth section you’ll see that we are indeed working with V-Cache. So we don’t quite know why we are seeing this behavior1.
Moving to Genoa-X versus Milan-X and Sapphire Rapids (SPR) makes for an interesting comparison.

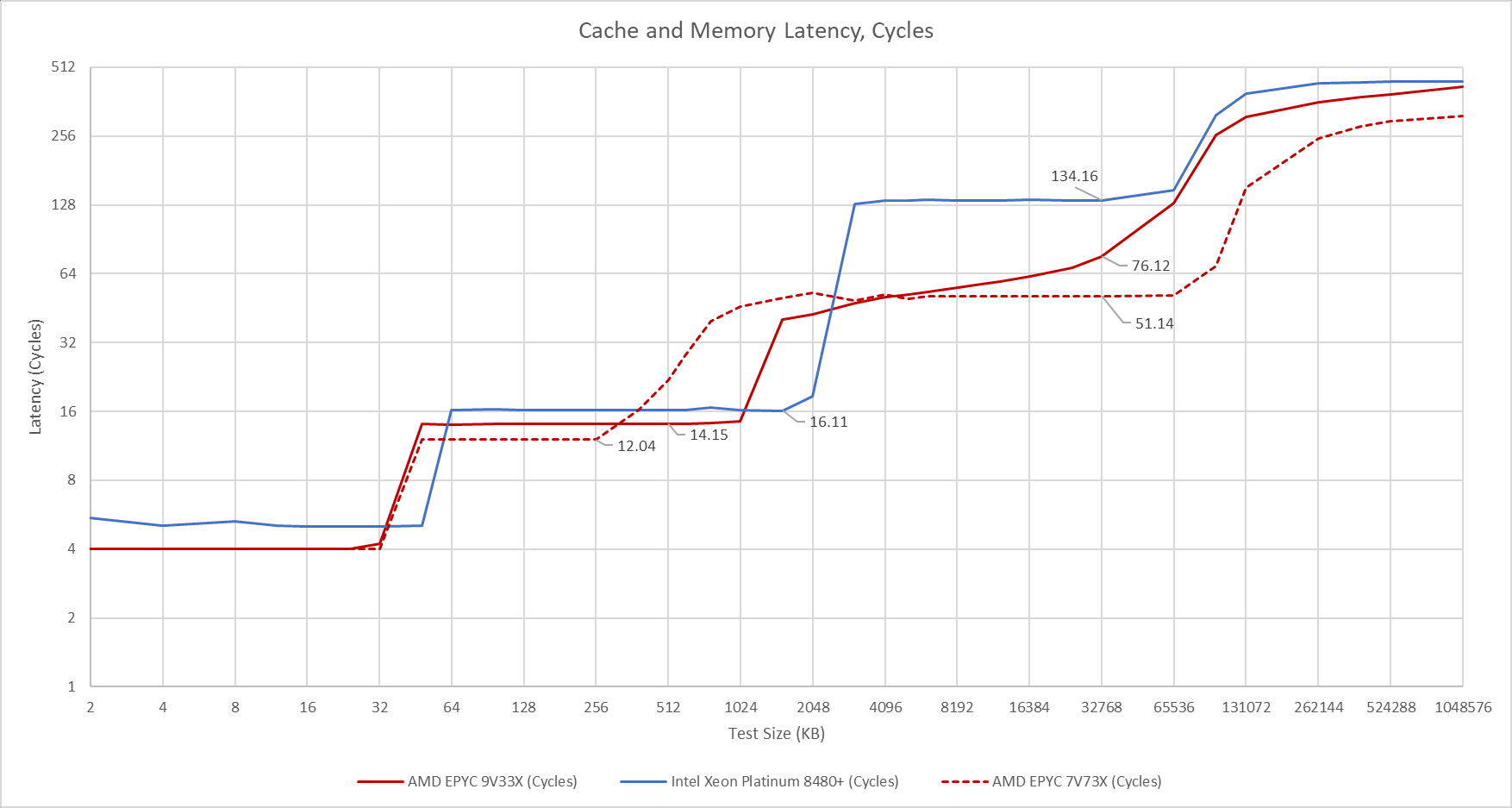
Looking at Genoa-X compared to Milan-X, that odd L3 latency creeps up again. Running off the published numbers, the latency should be no different from what we see on desktop which would mean a 4 cycle increase for the L3 on Genoa-X from Milan-X’s 50 cycle L3. What we can see is that Genoa-X is running its cores at a slightly higher clock speed of around 3.7GHz compared to Milan-X’s 3.5GHz which is a small but notable increase. However, Milan-X does have better memory latency compared to Genoa-X. Now moving to Genoa-X versus SPR and we can see even with the odd latency behavior that SPR’s mesh is far from low latency. However, a large bright spot on SPR is the 2MB L2 for each core, and the memory latency between Genoa-X and SPR is nearly identical and Milan-X taking the win here.
Cache Bandwidth
When we move to bandwidth, we see a much clearer picture compared to latency.

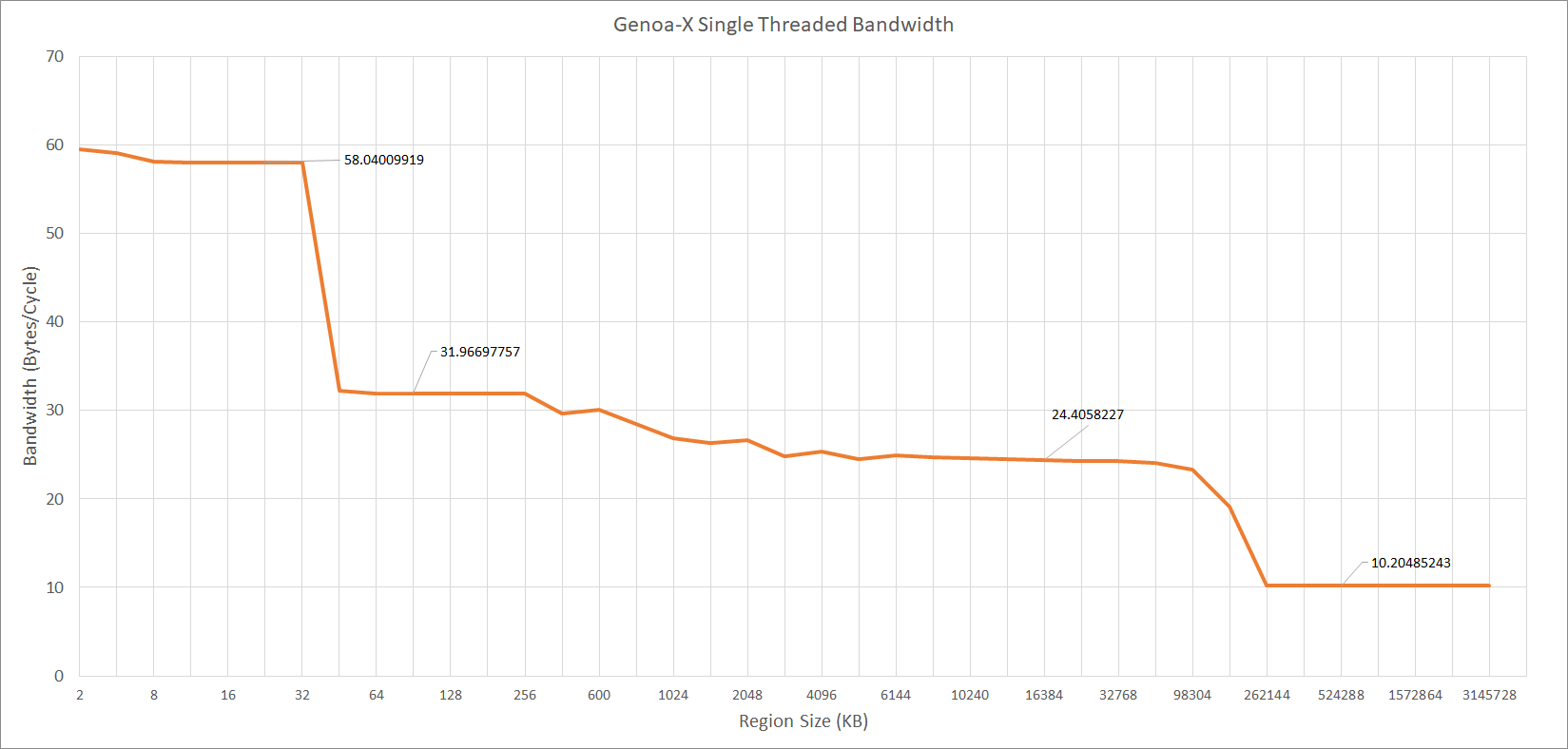
Single threaded bandwidth tests show that we are definitely dealing with a V-Cache chip here. We are seeing around 90GB/s of bandwidth from L3. This translates into just over 24 bytes per cycle, which is very good for a 32 byte ring.

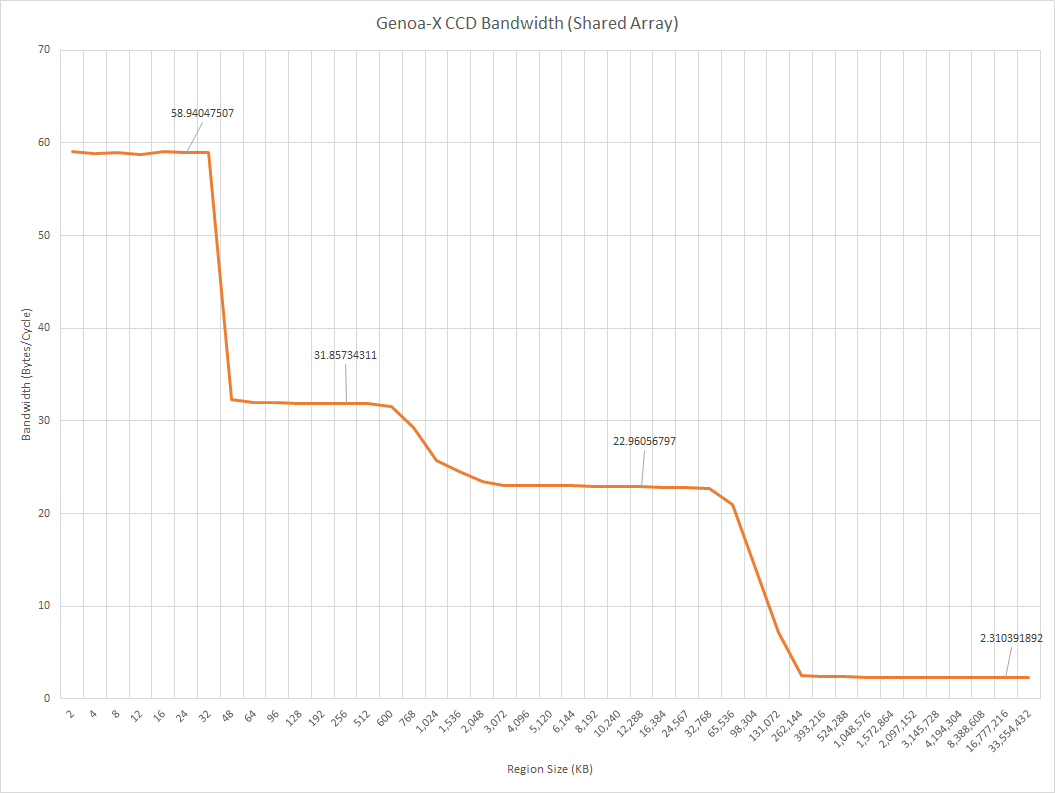
Now looking at the bandwidth of a single CCD and we can see that the 8 cores can pull nearly 700GB/s from the L3, which is quite impressive. You only lose about 1.5 bytes per cycle compared to the single threaded bandwidth, which is very impressive. What is less impressive is that one CCD can only pull just under 70GB/s of bandwidth from memory, which is not ideal considering that a single core can pull around 37GB/s alone; so 2 cores can max out the memory bandwidth of a single CCD.

And finally looking at the whole chip bandwidth, we see that the total L3 bandwidth is around 7TB/s, which is frankly insane considering that there is over 1 gigabyte of L3 on the chip. Moving to the memory bandwidth of the whole chip and we see that Genoa-X can pull around 375GB/s out of the theoretical 460GB/s from 12 channels of DDR5-4800. This means that Genoa can get around 81% of its theoretical memory bandwidth. This is roughly equivalent to our prior Sapphire Rapids testing.
Speaking of a bandwidth comparison to Milan and SPR, it’s time to look at those.

Starting with the single threaded bandwidth comparison and we see that Genoa-X and Milan-X are near copies of each other, the more interesting thing here is looking at SPR versus the AMD competitors. SPR has the advantage in bandwidth at the L1 and L2 cache levels by roughly 30%, however once you are out into the L3 and memory regions and then the bandwidth advantage swings massively in favor of the AMD processors by a factor of 2 to 3x.
Moving to 8 cores and the story changes a little bit.

Genoa-X separates itself out from Milan-X by running at a higher clock speed when a whole CCD is active with Genoa-X leading about around 10 to 20%. However a big bottleneck of both Genoa-X and Milan-X is that the GMI link to the IO die does limit the amount of memory bandwidth that a single CCD can get.
Moving to the comparison between SPR and Genoa-X and the gap between SPR and Genoa-X in the L1 and L2 realms narrows due to Genoa-X maintaining a higher clock speed. Interestingly enough, the gap between SPR’s L3 and Genoa-X’s L3 stays roughly the same however a major advantage for SPR is the amount of memory bandwidth that 8 cores can access which is roughly double that of Genoa-X.
Now, we couldn’t compare a full Genoa-X chip to either a full SPR or Milan-X chip however the general trend would likely be that SPR would have the most L1 and L2 bandwidth with Genoa-X close behind, Genoa-X having the most L3 bandwidth and the most memory bandwidth due to having a 768b (960b including ECC bits) DDR5 bus compared to SPR’s 512b (640b including ECC bits) DDR5 bus and Milan-X’s 512b (640b including ECC) DDR4 bus.
Core to Core Latency
The core to core latency of Genoa-X looks very similar to Milan-X.


The interesting part here isn’t actually Genoa-X but in fact comparing Sapphire Rapids to Genoa-X. Due to the large changes in the mesh design of Sapphire Rapids, it has seen a large latency hit compared to the prior generation Ice Lake. This means that there may be workloads that have a performance decrease on Sapphire Rapids compared to Ice Lake. Whereas going from Milan to Genoa likely wouldn’t see that decrease.
Socket to Socket Bandwidth
Socket to socket bandwidth is a metric which is often overlooked. During Genoa’s launch AMD highlighted that Genoa can be configured with either 3 or 4 xGMI links to a second CPU for either a total of 384GB/s or 512GB/s of bi-directional bandwidth between the 2 sockets.

Based on the unidirectional bandwidth, this system looks to be configured with 3 xGMI links. The theoretical unidirectional bandwidth is 192GB/s and we got about 128GB/s which means that we are only getting about 67% of theoretical which isn’t great. However this test was written on the fly2 so it may not be the best test for theoretical bandwidth, but it’s not an unreasonable test in an actual production environment.
Cross-Node Latency
Genoa-X sees slightly higher latency than Milan-X when a core on one NUMA node accesses memory on another. This test is different from the core to core latency test because the data is not contested and there are no cache to cache transfers taking place. Instead, one core is simply pulling data from DRAM in another NUMA node.

Cross-node accesses within the same socket are relatively cheap on AMD’s platform, compared to Intel’s old cluster-on-die (CoD) implementation on Broadwell. However, cross-socket accesses go the other way. All three platforms land in the same ballpark, although Milan-X is clearly a bit faster and Genoa-X is a bit slower. Higher memory latency for DDR5 may play a role, because Genoa-X also sees higher latency for local memory accesses.
Conclusion
In conclusion, Genoa-X is a refinement on Milan-X. The Genoa-X system we tested had a very stable clock speed of 3.7GHz which is honestly incredible for a 96 core server CPU. It really is significant that this CPU can hold 3.7GHz with all cores under non-trivial workloads. The rated all-core boost clock is 3.42GHz, which likely will only be seen in super heavy all core workloads. Then looking at the comparison to SPR shows just how much of an advantage Genoa-X has in terms of clock speed, L3 latency, L3 bandwidth, and total chip memory bandwidth.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.
Footnotes
This is not a TLB miss penalty. I (Clam) have a separate test written that does pointer chasing at the 4K page granularity. It also hits different cachelines within each 4 K page as much as possible in order to avoid conflict misses with VIPT L1 caches. That result is compared with pointer chasing with 64B cacheline granularity, using the same number of cachelines. Subtracting the two allows us to infer TLB miss penalties. On Zen 4, missing the L1 DTLB and getting the address translation from the L2 DTLB incurs a seven cycle penalty. With hugepages, we don’t see that penalty within a L2 cache sized region, where it would normally appear with 4K pages.
I (Clam) adapted the existing memory bandwidth test to measure cross-node performance with two nodes, because the test system was configured in NPS2 mode. That means each socket gets exposed as two NUMA nodes, with nodes 0 and 1 on one socket, and nodes 2 and 3 on another. If each socket is one NUMA node, testing cross-socket bandwidth would be easy because you’d just use numactl to bind cores to one node and memory to another. In this case, I spawned threads and allocated their memory so that their memory allocations would alternate between two remote nodes. For example, thread 0 would have memory from node 2, thread 1 would have memory from node 3, thread 2 from node 2, and so on.