
AMD’s 7950X3D: Zen 4 Gets VCache

Compute performance has been held back by memory performance for decades, with DRAM performance falling even further behind with every year. Caches compensate for this by trying to keep frequently used data closer to the CPU core. As DRAM performance became more and more inadequate, caching setups grew more sophisticated to cope. The late 2000s saw CPUs transition to a triple level cache hierarchy, in order to get multiple megabytes of on-chip cache.

AMD launched the Ryzen 7 5800X3D roughly a year ago, with a 64 MB cache die stacked on top of the regular core die. This wasn’t the first attempt to dramatically increase caching capacity. But VCache stands out because it combined high capacity caching with very high performance. On the consumer side, the 5800X3D performed very well in gaming workloads, while VCache-equipped Milan chips targeted HPC applications.
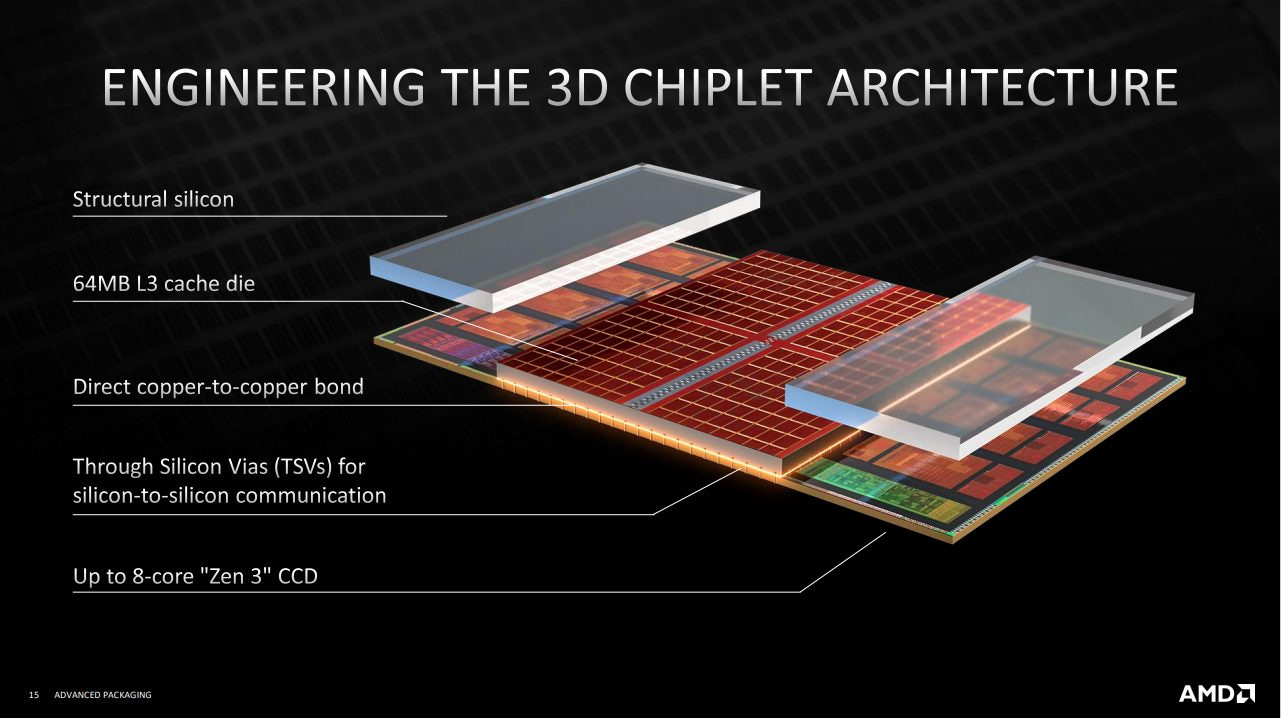
This year, AMD is trying to repeat Zen 3’s “VCache” success in their new Zen 4 lineup. Zen 4 benefits from both an improved core architecture, and a newer 5 nm process node. For the L3 cache, 5 nm means a dramatic area reduction. The column of TSVs (through-silicon vias) used to connect stacked cache also saw a nice area reduction, even though IO usually sees less gain from process node shrinks.

AMD has also expanded VCache’s scope within their consumer lineup. Instead of just one VCache SKU limited to eight cores, Zen 4 gets VCache in higher core count chips as well. However, there’s a twist. SKUs with more than eight cores only have VCache implemented on one of the core chiplets, meaning that only half of the cores benefit from increased L3 size. This behavior is somewhat awkward for regular users, but provides an excellent opportunity for us to isolate the effect of increased L3 capacity.

Here, we’re testing the 7950X3D, which offers 16 cores across two CPU chiplets (CCDs). The first chiplet has 96 MB of L3 cache, while the second has a regular 32 MB L3 setup.
Clock Behavior
AMD’s stacked cache is less tolerant of high voltage, preventing the VCache cores from boosting as high as their vanilla counterparts. This creates a difficult optimization problem, because one CCD is not clearly better than the other. If an application already sees high hitrate with a 32 MB L3, or has a hot working set so large that going to 96 MB of L3 makes a minimal difference, it could perform better on the non-VCache CCD. Conversely, a large L3 hitrate increase from VCache could provide enough performance per clock gain to outweigh the second CCD’s frequency advantage.
Addition latency is one cycle on pretty much all CPUs, so we’re using dependent register to register additions to measure each core’s maximum boost clock. VCache cores generally stayed around the 5.2 GHz range, while normal cores could reach 5.5 GHz and beyond. The best core on the non-VCache CCD came within margin of error of the advertised 5.7 GHz boost clock.

On average, the normal CCD clocks around 7% higher. For comparison, the regular 7950X had about a 3% clock difference between its two CCDs. While this is a lot of clock speed variation, it’s better than the VCache clock variation on Zen 3. The highest clocking Zen 3 VCache part, the Ryzen 7 5800X3D, had a 4.5 GHz boost clock. Without VCache, the top end Ryzen 9 5950X could reach 5.05 GHz, or around 10% higher clocks. Zen 4 enjoys higher absolute clock speeds too. Every single core on the VCache-enabled chiplet could clock comfortably above 5 GHz, providing a clock speed advantage over all Zen 3 SKUs.

An interesting aside, the 7950X3D can clock higher than the 5800X3D, even with a BIOS version that doesn’t nominally support Zen 4’s VCache. ASRock’s site states that the B650 PG Lightning gets VCache support with BIOS version 1.18. Conveniently for me, my ASRock B650 PG Lightning board was happy to boot with the 7950X3D using an old BIOS version from the factory. Evidently it didn’t fully support VCache, because VCache-enabled cores were capped at 4.63 GHz, while regular cores could only hit 4.78 GHz. Both speeds are still quite high in an absolute sense, and are a bit above the 5800X3D’s 4.5 GHz boost clock. That said, a BIOS update is definitely recommended, even if the CPU boots out of the box.
VCache Latency
Zen 4’s VCache implementation incurs a minor latency penalty. We can isolate cycle count differences by testing pointer chasing latency with boost off, and then multiplying results by the 4.2 GHz base clock. A core with VCache takes about 4 extra cycles to get data from L3, which isn’t a bad tradeoff for getting a much larger L3 cache.
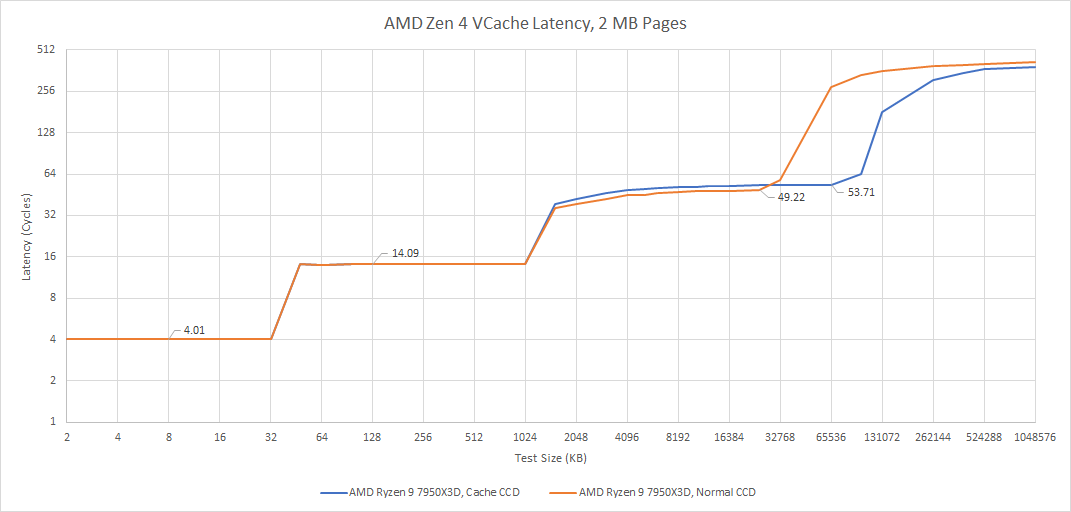
The small cycle count difference doesn’t tell the full story, because the true latency penalty is made worse by VCache’s clock speed deficit. But taking 1.61 ns longer isn’t too bad for getting triple the L3 capacity.

VCache Bandwidth
Just like Zen 3’s VCache implementation, the stacked cache works by giving each L3 cache slice extra capacity. The on-CCD interconnect remains largely unchanged, with a bidirectional ring connecting cores to the cache slices. Therefore, we don’t expect significant bandwidth differences beyond the hit from reduced clock speed.

Starting with a single core, the 7950X3D’s non-VCache CCD gains a 11% L3 bandwidth lead, which is almost in line with the clock speed difference. If we turn off boost and divide by the 4.2 GHz base clock to get bytes per cycle, we see nearly identical L3 bandwidth.
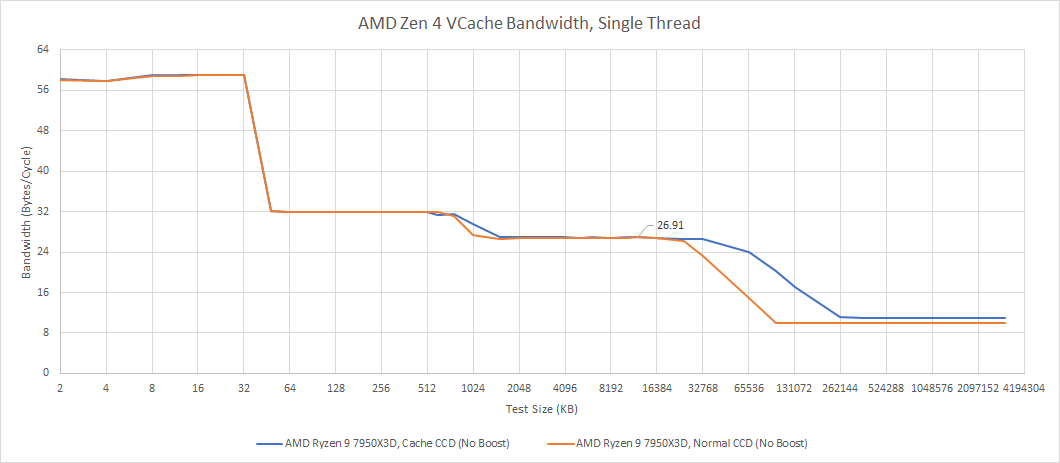
Loading all cores in the CCD reveals that VCache impacts clocks under heavy load too, even though voltages are lower than with single core boost. When reading from a L3-sized region, the VCache CCD sustained 4.8 GHz. The non-VCache held 5.15 GHz.

Curiously, the bandwidth difference is a bit larger than clock speed differences alone would suggest. With boost turned off and all cores running at 4.2 GHz, we can divide by clock frequency to get bandwidth in bytes per cycle.

VCache indeed has slightly lower bandwidth than its vanilla counterpart. Per core, we’re averaging 18.45 bytes per cycle on the VCache CCD, compared to 20.8 on the regular one. I’m not sure why this is the case. I compared the results with performance counters by multiplying L3 hit count by 64 bytes. Measured bandwidth and bandwidth reported by performance counters line up.
L3 Hitrate Examples
Performance counters are useful for more than sanity-checking test results, because we can also use them to see how well VCache deals with various programs. Specifically, we’ll be monitoring L3 hitrate from the L3 cache’s perspective, and not the core perspective. That means we’re counting speculative L3 accesses, and not distinguishing between prefetch and demand requests.

Boost is disabled, keeping clocks capped at 4.2 GHz for consistency. The GPU used is a RDNA 2 based Radeon RX 6900 XT, which also had its clock speed set to 2 GHz for consistency. We’re not going to be looking at absolute framerates here. Rather, performance counters will be used to look at IPC differences. Other sites already have plenty of data on how Zen 4’s VCache performs across a variety of scenarios, so we won’t rehash that.
GHPC
GHPC is an indie game that tries to be user-friendly while accurately depicting fire control systems on various armored vehicles. It also lets you remove turrets from T-72s with fantastic visual effects.

This game can suffer from both CPU and GPU bottlenecks. It also doesn’t load a lot of cores, which means it can be locked to one CCD without worries about running out of cores to run the game’s threads. Because visual effects (especially smoke) are quite heavy on the GPU side, I’ll be using IPC to isolate CPU performance.

VCache provides a notable 33% L3 hitrate increase here. Bringing average hitrate to 78% is more than enough to compensate for the slight L3 latency increase. GHPC enjoys a 9.67% IPC gain from running on the VCache CCD, so the other CCD should fall short even with its higher clock speed.
Cyberpunk 2077
We’re using the built in benchmark with raytracing set to ultra, because it’s repeatable. The benchmark run ends up being GPU bound, partially because the GPU is set to consistent clocks. Cyberpunk only sees a 0.5 FPS gain from using VCache. But that’s not the point here.

With affinity set to the VCache CCD, IPC increased from 1.26 to 1.43. That’s a 13.4% increase, or basically a generational jump in performance per clock. VCache really turns in an excellent performance here. L3 hitrate with VCache is 63.74% – decent for a game, but not the best in absolute terms. Therefore, there’s still plenty of room for improvement. Modern CPUs have a lot of compute power, and DRAM performance is so far behind that a lot of that CPU capability is left on the table. Cyberpunk 2077 is an excellent demonstration of that.
DCS
Digital Combat Simulator (DCS) is a plane game. Here, we’re running a scenaro with a lot of planes, a lot of ships, and maybe a few missiles. The game is left in map view, and none of the vehicles are player-controlled to keep things consistent.
Also, the simulation is sped up to increase CPU load. We’re also testing using the open beta’s multithreading build, which honestly doesn’t seem very multithreaded. During the simulation, there were two to three cores loaded.

VCache enjoys higher hitrate again as we’d expect, but this time the benefit is extremely small because DCS barely saw any L3 misses to begin with. Even without VCache, L3 misses per 1K instructions (MPKI) was just 0.35. VCache brings that down to 0.28, but there’s not a lot of room to improve hitrate in this scenario. DCS actually ends up losing a bit of IPC, likely due to increased L3 latency. Admittedly this is a very limited test that doesn’t reflect actual gameplay, but it does show a scenario where cache latency can matter more than capacity.
COD Black Ops Cold War
COD (Call of Duty) Black Ops Cold War is an installment in the popular Call of Duty series. I’m testing it by playing rounds of Outbreak Collapse in Zombies mode, which has a lot of zombies running around the screen. This isn’t a perfectly repeatable scenario because it involves multiplayer, so there will be more margin of error in this case.
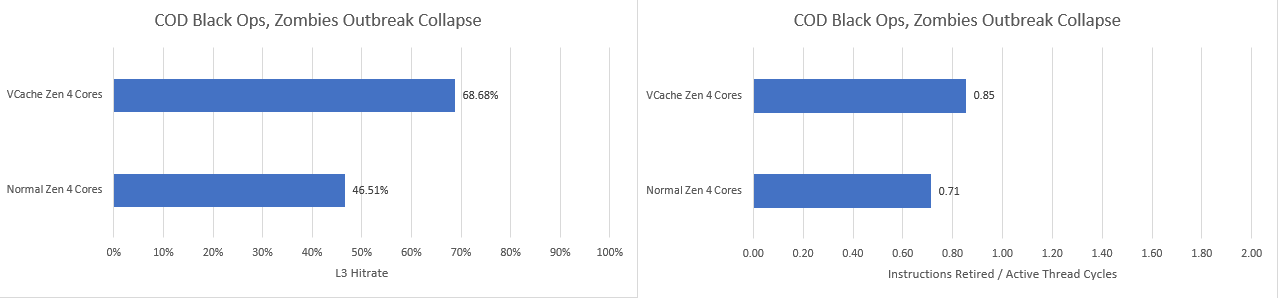
Zen 4’s normal 32 MB cache suffers heavily in this game, eating a staggering 8.66 MPKI while hitrates average under 50%. VCache mitigates the worst of these issues. Hitrate goes up by 47%, while IPC increases by over 19%.
COD also suffers from very low IPC compared to the other games tested above. When IPC is this low, you have to dive a bit deeper. Fortunately, Zen 4 has a new set of performance monitoring events designed to account for lost performance on a per-pipeline-slot basis. Zen 4’s renamer is the narrowest part of the pipeline (just like the past few generations of Intel and AMD cores), so most of the events focus on lost slots at that stage.
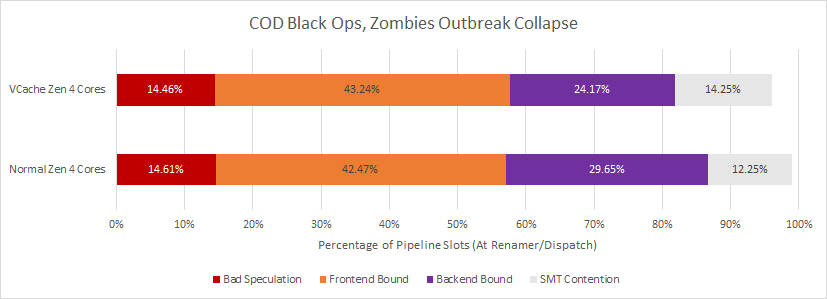
VCache makes Zen 4 less backend-bound, which makes sense because the execution units can be better fed with a higher cache hitrate. However, the core suffers heavily from frontend bottlenecks. VCache seems to have little effect on frontend performance, suggesting that most of the L3 hitrate gain came from catching more data-side misses.
libx264 Video Encoding
Gaming is fun, but it’s not the only thing we do with computers. Software video encoding is an excellent way to get high compression efficiency, at the expense of encoding time. H264 is an extremely popular video codec, with widespread hardware decode support. Here, we’re transcoding an Overwatch POTG clip using libx264’s veryslow preset.

Hitrate improves by 16.75%, going from 61.5% to 72.8%. That’s a measurable and significant increase in hitrate, but like DCS, libx264 doesn’t suffer a lot of L3 misses in the first place. It’s not quite as extreme at 1.48 L3 MPKI with the non-VCache CCD. But for comparison, Cyberpunk and GHPC saw 5 and 5.5 L3 MPKI respectively. We still see a 4.9% IPC gain, but that’s not great when the regular CCD clocks 7% higher. Performance doesn’t scale linearly with clock speed, but that’s mostly because memory access latency falls further behind core clock. But given libx264’s low L3 miss rate, it’ll probably come close.
libx264 therefore ends up being a good demonstration of why AMD is only putting VCache on one CCD. Besides the cost benefits, the non-VCache CCD can provide better performance in some applications. Of course, the situation could be different in servers, where power limitations could prevent regular cores from clocking higher.
7-Zip File Compression
7-Zip is a very efficient file compression program. It comes with a built in benchmark, but as before, we’re going to be compressing a 2.67 GB file instead of using the benchmark. The built in benchmark runs through both compression and decompression, and I don’t care about the latter because it’s fast enough. Compression takes a lot of CPU cycles, and is more worth looking at.

With affinity set to the VCache CCD, we see a 29.37% hitrate improvement. IPC increases by 9.75%, putting it in-line with GHPC. This is a very good performance for VCache, and shows that increased caching capacity can benefit non-gaming workloads. However, AMD’s default policy is to place regular applications on the higher clocked CCD. Users will have to manually set affinity if they have a program that benefits from VCache.
Comparing High Capacity Cache Setups
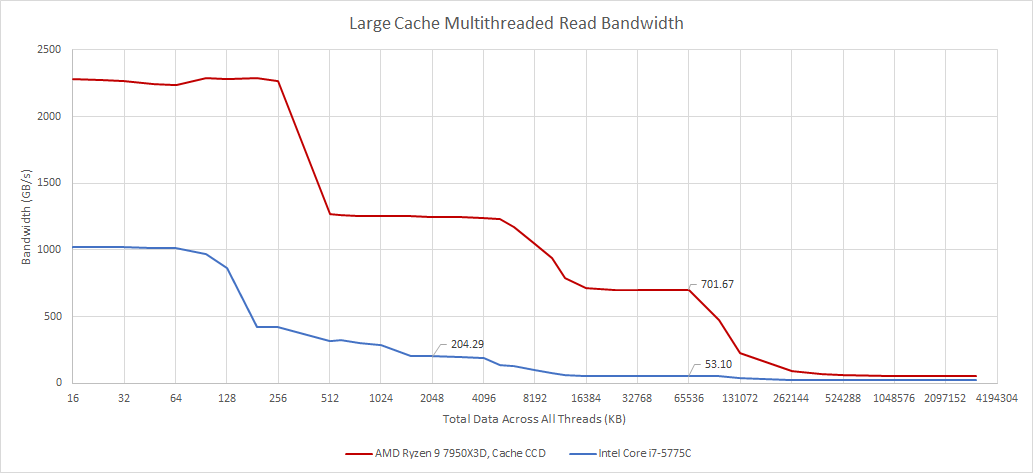
As noted before, VCache is not the first attempt at delivering massive caching capacity to client platforms. Years ago, Intel used an EDRAM chiplet to implement a 128 MB L4 cache on Haswell, Broadwell, and Skylake CPUs. This solution offered impressive capacity, but suffered from poor performance. Latency is extremely high at over 30 ns.

EDRAM bandwidth is similarly unimpressive, at around 50 GB/s. On one hand, 50 GB/s is better than what a dual channel DDR3 setup can offer. On the other, it’s only a quarter of Broadwell’s L3 bandwidth.
Compared to VCache, EDRAM suffers from higher latency because getting to the EDRAM controller involves another trip over the ring bus. Then, data has to be transferred over Intel’s OPIO links, which are optimized more for low power than high performance. OPIO is also partially to blame for EDRAM’s lower bandwidth. It basically has a full-duplex 64-bit interface running at 6.4 GT/s (on Haswell), providing 51.2 GB/s in each direction. In fairness, Zen 4’s cross-die Infinity Fabric links barely do better, providing 64 GB/s of read bandwidth per CCD and half as much write bandwidth. But that’s a sign that on-package traces aren’t well positioned to handle L3 bandwidth requirements.

With TSVs and hybrid bonding technology, AMD was able to get orders of magnitude higher pin counts. Each nominally 4 MB L3 slice gets its own interface to a 8 MB extension, which comes complete with tags and LRU arrays. Zen 4’s L3 cache controller probably determines whether data’s cached on the stacked die or base die by checking a subset of the address bits. Then, it checks a set of 16 tags retrieved either from the base die or cache die, and returns data from the respective source if there’s a hit. This tightly integrated extension to the L3 cache means the stacked die ends up servicing a lot of L3 requests, but TSVs make cross-die accesses cheap enough that it’s not a problem.
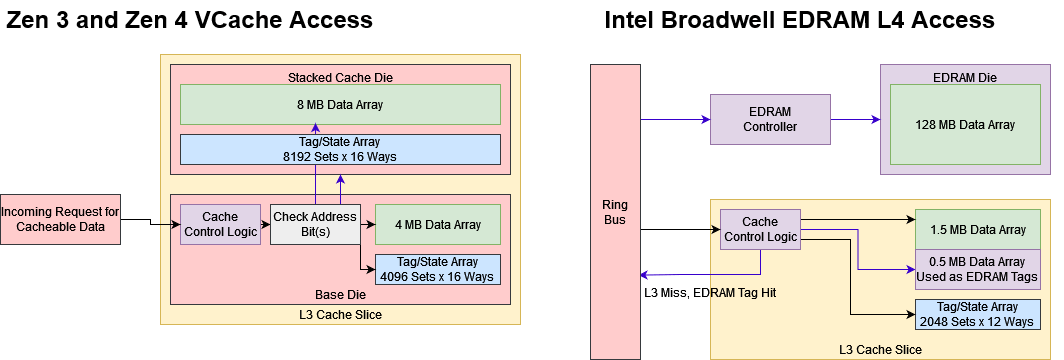
Broadwell, in contrast, has to use EDRAM as L4 because it’s too slow to get tightly integrated into the L3. The L3 remains in place to insulate cores from high EDRAM latency. To cut latency down somewhat, Broadwell uses some of the L3 cache’s data array as tags for the L4. This scheme lets the L3 controller figure out whether a miss can be satisfied from EDRAM, without taking a trip across dies. For comparison, AMD’s VCache die contains dedicated tag and LRU arrays, likely with specialized SRAM macros for higher performance.

Skylake uses a different scheme where the EDRAM controller is placed in the system agent, alongside dedicated tags. Somehow, Skylake’s EDRAM is even worse than Broadwell’s, with longer latency and nearly identical bandwidth. In any case, EDRAM is fundamentally less performant than the SRAM used on AMD’s stacked cache. Just like other forms of DRAM, EDRAM requires refreshes and doesn’t run particularly fast. The lower performance cross-die interface also dictates its use as a L4 cache, instead of an extension of L3.
Intel may be planning to bring back a L4 cache in Meteor Lake. A patch to the Linux kernel driver for Meteor Lake’s iGPU suggests there is a L4. Intel revealed that Meteor Lake would use stacked dies in Hot Chips. Advanced packaging technology could help this L4 achieve far higher bandwidth than EDRAM, but I’m worried that it’s still a L4 cache. As a separate cache level, it’ll probably be less tightly integrated and suffer lower performance than VCache. I suspect it’ll be more iGPU oriented, helping to alleviate DRAM bandwidth bottlenecks while not doing so well on the latency front. GPUs are less sensitive to latency than CPUs, but high latency will reduce its potential on the CPU side.
Final Words
Zen 4’s VCache implementation is an excellent follow-on to AMD’s success in stacking cache on top of Zen 3. The tradeoffs in L3 latency is very minor in comparison to the massive capacity increase, meaning that VCache can provide an absolute performance advantage in quite a few scenarios. Zen 4’s larger L2 also puts it in a better position to tolerate the small latency penalty created by VCache, because the L2 satisfies more memory requests without having to incur L3 latency. The results speak for themselves. While we didn’t test a lot of scenarios, VCache provided an IPC gain in every one of them. Sometimes, the extra caching capacity alone is enough to provide a generational leap in performance per clock, without any changes to the core architecture.
At the same time, VCache doesn’t always provide an absolute performance advantage, largely because of the clock speed reduction. Therefore, AM5 doesn’t have a clear top-of-the-line Zen 4 configuration. VCache configurations do well for programs that benefit from large cache capacity increases, while the more standard configuration is better for applications that like higher clocks. Of course, this puts users in a difficult situation. It’s hard to tell what a program will from benefit without benchmarking it, and one user might need to run both types of applications on the same system.
Unfortunately, there’s been a trend of uneven performance across cores as manufacturers try to make their chips best at everything, and use different core setups to cover more bases. VCache is honestly a very mild example of this. If you put the wrong application on the wrong core, you’re probably not going to end up with an annoyingly large performance difference. Looking beyond AMD, Intel has been mixing up core setups as well. Alder Lake and Raptor Lake see even larger performance differences across cores on a chip. Specialized architectures and core setups are going to become increasingly normalized as manufacturers try to chase down every last bit of performance.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.