
Deep Diving Zen 3 V-Cache

This is the deeper dive of AMD’s V-Cache that we teased with our short latency article and we will be covering a little more on the latency front along with the bandwidth behavior of V-Cache and the performance of V-Cache SKUs.
A Bit More on Latency
If you have read our teaser article on V-Cache’s latency then you will remember these two graphs.


We’ve also done latency testing using 2 MB pages, which eliminates TLB penalties for test sizes below 128 MB (because Zen 3 has a 64 entry L1 DTLB). Most workloads use 4 KB pages so this isn’t a good indication of latency that applications will experience. But it lets us look at raw cache latency without address translation overhead.
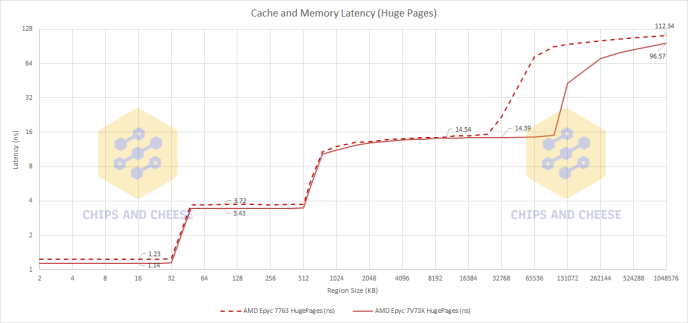

Interestingly while the cycle latency difference is the same using 2MB pages, roughly 3 to 4 cycles, the L3 latency is a little lower yet the memory latency is a little higher.
Now, Milan and Milan-X do not exist in a vacuum so lets first compare them to AMD’s previous architectures Naples and Rome.
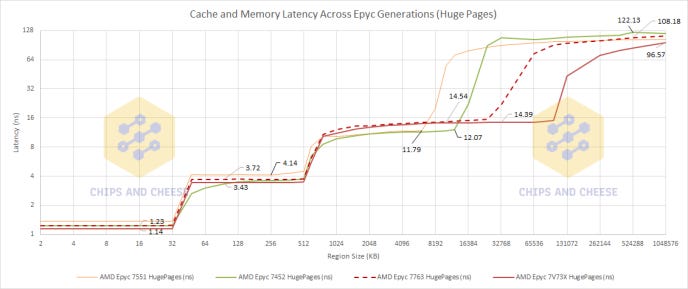

AMD has kept the same L1 and L2 for all released generations of Zen, although it does appear that AMD is going to be increasing the L2 capacity of Zen 4 based on the leaked Zen 4 PPR.
What is interesting here is that increasing the cache size by increasing the set count looks pretty cheap in terms of added latency. Zen 1 to Zen 2 doubled the size of each slice and only increased the latency cost by about 5 cycles. Similarly, Zen 3 to Zen 3 with V-Cache tripled the slice size but only added 3 to 4 cycles to the latency where as the move from Zen 2 to Zen 3 which unified the 2 16MB L3s on a CCD into a single 32MB L3 added 7 to 8 cycles to the L3 latency; now how much of that extra latency was due to AMD preplanning for V-Cache, we simply can not know. But even considering that, it looks like it is cheaper latency wise to increase the set count per cache slice then to unify 2 separate caches into one single unified, same size, cache.
However just like how Milan doesn’t exist in a vacuum, AMD isn’t the only x86 CPU makers so lets compare AMD’s Milan/Milan-X to Intel’s Cascade Lake and Ice Lake.
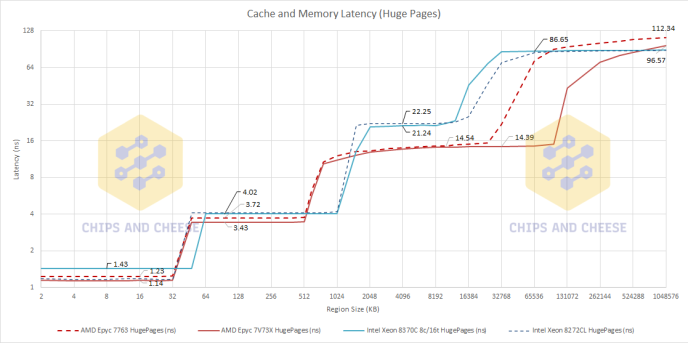

Comparing the L1s of these 4 CPUs, the only difference is that Ice Lake has a larger but slower L1 compared to the other 3 CPUs. The L2s are where things get interesting because Milan and Milan-X has the smallest L2 of the CPUs but it does have the fastest L2.
Again, the L3 is the interesting section here because comparing AMD’s L3 to Intel’s L3 shows no contest between the two in terms of latency. On average, AMD’s L3 latency is 24-28 cycles faster then Intel’s which is a very large difference. This is due to the mesh topology that Intel uses on server CPUs versus AMD’s ring topology and the tradeoffs between the two topologies. Ring being both lower latency and higher bandwidth compared to Mesh but Mesh is more scalable for a monolithic CPU compared to a Ring topology.
One last thing here is that Intel’s latency out to memory is better than AMD’s by a few cycles which is neat considering the much higher latency of the L3.
Bandwidth
Latency is not the only measurement of a cache so lets look at the bandwidth of these caches.
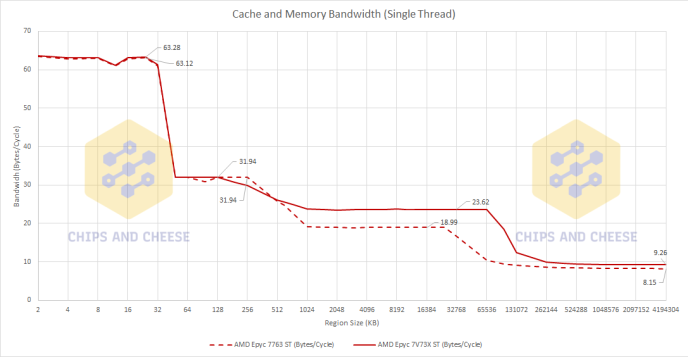

This is an interesting twist to Milan-X. At least in our single threaded test, we do see an increase in the bandwidth like what AMD said in their announcement. However, we are not seeing the doubling that AMD claimed because we are only seeing about 25% Bytes per Cycle increase. But, the clock speed was estimated by the L1 bandwidth so it is possible that there is a clock speed decrease once Milan-X hits the L3 although this is unlikely in my opinion.
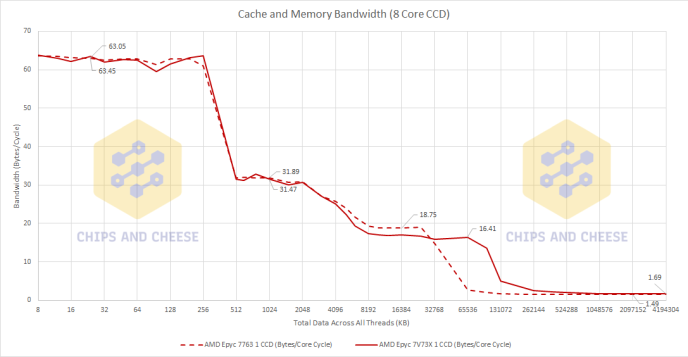

The interesting twist gets even more interesting. When we look at one CCD bandwidth Milan-X’s there is a slight Byte per Cycle regression, about 12.5%, compared to standard Milan. This is probably to keep power down when all 64 cores are active rather than thermal reasons due to servers not running at very high clock speeds.
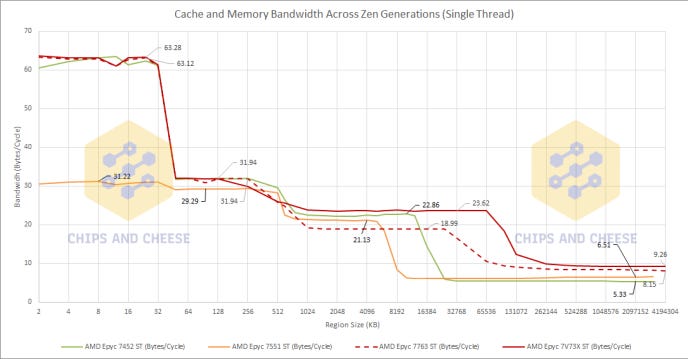

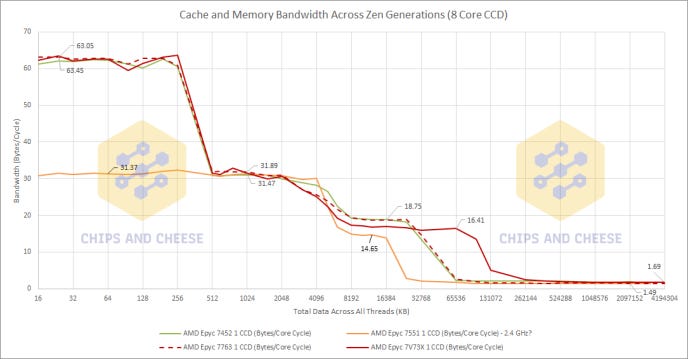

Again, the twists keep on coming. We see a very similar behavior with both Naples and Rome as we did with Milan-X where the single threaded L3 bytes per cycle is higher than the single CCD Bytes per Cycle. This makes Milan the odd one out regarding the single threaded bytes per cycle staying the same as the CCD bytes per cycle. However, the bytes per cycle regression of even Naples is fine in my opinion due to AMD always having very high L3 bandwidth compared to Intel.
Speaking of Intel, lets compare Milan and Milan-X once again to Intel’s Cascade Lake and Ice Lake.


Something of note, Ice Lake’s L1 bandwidth should be the same as Cascade Lake’s L1 bandwidth because both CPUs have AVX512 support but for whatever reason we couldn’t get Ice Lake’s L1 to cooperate with our bandwidth test. Still, in the L1 region, Intel holds the lead for bandwidth over AMD.
Moving on to L2, we can see that Intel holds on to the bandwidth advantage with Intel’s L2 theoretically being able to do 64 bytes per cycle but due to the limitation that Intel’s L1 can’t both write to the L1 and read from the L2, we only see 40 to 42 bytes per cycle but that does still compare favorably to AMD’s 32 bytes per cycle.
When we hit the L3 region, that is when the tables turn and AMD now has over double the L3 bytes per cycle bandwidth of Intel even with the bandwidth drop of Milan-X. However, due to Infinity Fabric being limited to roughly dual channel DDR4-3200 in terms of bandwidth, Intel regains the lead once you hit memory.
Performance
For this section, we will only be looking at Milan versus Milan-X because the primary point of this article is looking at V-Cache and, to be frank, trying to compare Intel to AMD in the server space is complicated because of Intel’s similar lightly threaded performance and lower core count compared to AMD.
As mentioned in the bandwidth section, the clock speed had to be estimated based on the L1 bandwidth results that we got because there is no way on the VMs we were using to get the clock speed performance counters. This would mean that Milan is clocking around 3.3GHz and Milan-X is clocking around 3.15GHz or about a 5% clock difference. This is the clock speed difference that we assumed for all of our testing.
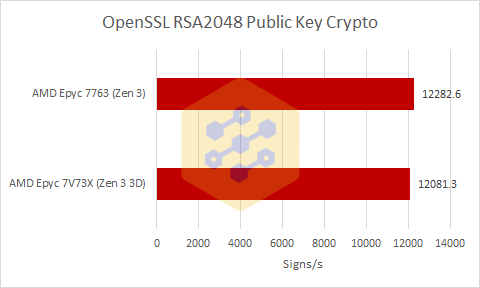
And right away we start with a test that doesn’t look all flattering to Milan-X, but there are a few things to consider here. OpenSSL does not stress the caches at all which removes the primary advantage of Milan-X and Milan-X does clock a little lower then Milan when you are stressing a whole CCD so this result is not at all unexpected for a workload like this.
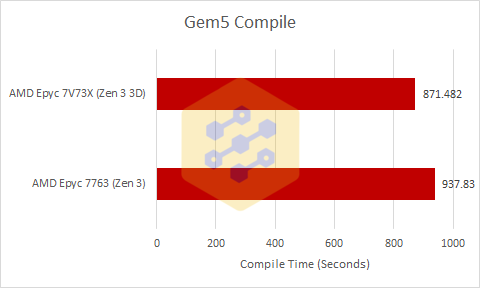
This is a more interesting result then the OpenSSL result because while the performance difference is only 7.6% in favor of Milan-X, it is also clocking about 5% lower than Milan which means that iso-clock V-Cache is giving around a 12.5% performance increase in this test.
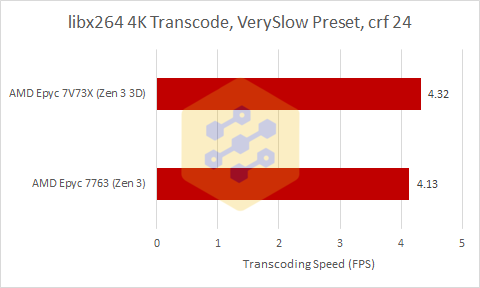
Libx264 gives a result similar to the Gem5 tests where the slightly lower clocked Milan-X is about 5% faster than standard Milan meaning that iso-clock V-Cache adds roughly 10% to the performance of Milan-X compared to Milan.
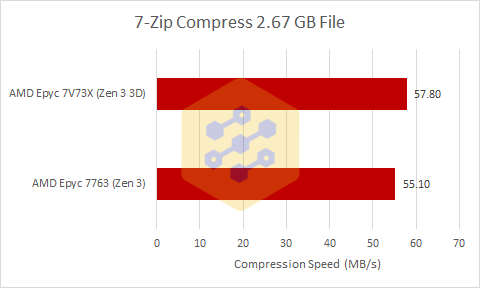
This result looks to be a repeat of the libx264 result from above where the slightly lower clocked Milan-X wins by 5% so lets move on to the last test we ran on Milan-X.
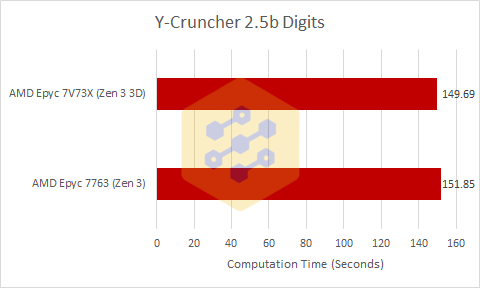
Now this at first glance does not look to be a very interesting result because while the performance difference between these two CPUs is negligible, Y-Cruncher is both a very FPU heavy and very memory heavy test meaning that Milan-X likely dropped straight to its 1 CCD boost clock. Regular Milan likely didn’t drop clocks, because it’s a shared cloud instance. This means that V-Cache was more than making up for the performance loss due to the lower clocks.
Conclusion
V-Cache is a very interesting addition to Milan because in our testing it did not degrade performance with the exception of OpenSSL where the performance difference was a wash because it’s completely compute bound. And in some tests V-Cache did add performance to the already very performant Milan.
V-Cache is also a large technical achievement for AMD considering that the latency increase of 3 to 4 cycles is trifling considering the tripling of the L3. On the bandwidth front, while AMD did sacrifice Milan’s lack of variation of L3 bandwidth for around 25% more single threaded bytes per cycle bandwidth but 10% less whole CCD bandwidth with Milan-X, that is similar behavior to previous generation server CPUs from AMD and even with the slight bandwidth reduction, it blows Intel’s L3 bandwidth out of the water.
All in all, V-Cache is both a very interesting technology and a decent performance enhancer which makes me very excited for what AMD does next with the technology.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.