
AMD’s Zen 4, Part 3: System Level Stuff, and iGPU

We covered Zen 4’s core architecture in depth in two articles. This one will focus on anything we didn’t manage to get to. Some of these details may be specific to the particular CPU sample we have, and many of them won’t have a significant effect on application performance. However, we’ve seen enough online discussion on some of these topics to warrant further investigation. Thanks to everyone involved for participating in the discussion.
As an aside, my goal with these articles is to deep dive aspects of processor architectures that other sites aren’t covering. Between real life work and sleep, I don’t have much spare time. Putting hours into benchmark runs doesn’t make sense when dozens of sites and content creators already have benchmark charts. Similarly, all-core clock speeds under sustained load were covered by Hardware Unboxed. Results there are roughly in agreement with those from Gamers Nexus, so I didn’t dive into it. This article will try to cover anything that I’ve found interesting, but wasn’t covered in a batch of other places. There’s no real order to this, so feel free to skip around.
Boost Clock Behavior
AMD advertises a boost clock of 5.7 GHz for the Ryzen 7950X. We’ve heard that the CPU’s maximum frequency is supposed to be 5.85 GHz, but we were unable to achieve that clock speed. Here, we’ll present the test data and discuss other aspects of the 7950X’s design. Keep in mind that the behavior seen here is likely sample specific.
First, we went through all of the 7950X’s cores one by one, and determined what clock speed they boosted to. To measure clock speed, we measured the latency of register to register integer addition instructions. Like prior 16 core AMD desktop parts, not all cores will boost to the CPU’s maximum clock. On our sample of the 7950X, we saw the highest clock frequencies from cores 0, 3, and 4. All three of these cores were located on the first CCD.

All of the cores on the second CCD clocked lower than cores on the first. They ranged from 5.54 GHz to 5.51 GHz, which is 100-200 MHz lower than what we saw on the first CCD. Curiously, prior generations show exactly the same pattern. Cheese’s 5950X hit its highest clocks on cores 1 and 4. Both are located on the first CCD. My 3950X clocked highest on cores 4 and 5. Both are also on the first CCD. This is a curious pattern. Perhaps AMD is only binning one CCD to hit the maximum boost clocks on 16 core parts.
Our Zen 4 and Zen 3 chips also see less clock speed variation than our Zen 2 chip.
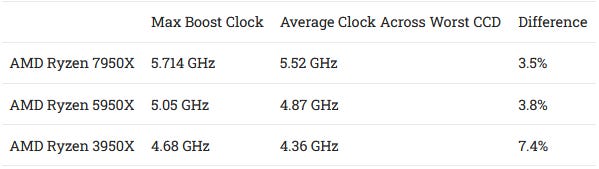
If your operating system’s scheduler doesn’t prioritize scheduling low-threaded tasks on the best cores, the 3950X’s performance could see quite a bit of variability. The Ryzen 5950X and 7950X are much better in this respect. While the clock speed difference is measurable, feeling a 3-4% performance difference will be much harder than feeling a 7-8% one.
(Very) Short Duration Boost Behavior
I also wondered if Zen 4 was momentarily hitting higher clock speeds, then dropping back down within the measurement interval of the previous test. That test generally takes a couple seconds to determine clock speed, in order to give any tested CPU a reasonable amount of time to ramp clocks. To see if clocks changed at a very fine granularity, I used the clock ramp test with more iterations per sample. That test uses RDTSC to take samples with better than millisecond precision. Increasing iteration count per sample lets the test cover a longer duration to capture quick clock speed shifts, but without creating a gigantic spreadsheet of doom. I also ran the test on every core. Results were consistent on the same core, but not across cores.
Let’s take things one CCD at a time, because there’s a lot of data. Depending on the core, we saw clocks slightly higher than 5.71 GHz within a 700 ms time window. However, results varied wildly. Some cores, like core 0 and 2, boosted up to 5.74 GHz for less than 50 ms, and then dropped to 5.71 GHz. Core 2 held 5.74 GHz for almost half a second, and then showed erratic behavior.

The second CCD shows similar characteristics. However, the cores on that CCD actually start closer to 5.6 GHz. They hold that speed for a very short time interval, and then clock down slightly.

This is interesting behavior, though irrelevant to most users. Short and long term boost clocks rarely differ by more than 50 MHz. If you traveled back in time and ran a 266 MHz Pentium II, 50 MHz would be significant. Today, a 50 MHz difference is laughably small. At the clock speeds that Zen 4 runs at, 50 MHz accounts for less than 1% of difference. The biggest takeaway from this test is that Zen 4 adjusts clock speeds in very small timeslices, and that users should not expect a perfectly steady clock speed.
Not So Infinite Fabric?
Like Zen 2 and Zen 3, each Zen 4 core complex has a 32B/cycle read link from fabric, and a 16B/cycle write link. Last article, we noted that write bandwidth to DDR5-6000 was likely limited by the 16B/cycle links from the two CCDs. We see a similar read bandwidth limitation from one CCD. We ran our memory bandwidth test with the 3 GB test size and scaled thread counts to hit all physical cores. CCXes and CCDs were filled one before another. On the 3950X, that meant filling both CCXes on a CCD first. From the results, we see clear signs that a single 7950X CCD is restricted by its 32B/cycle link to fabric.

On Zen 2 and Zen 3, the Infinity Fabric interconnect can generally be run at DDR clock, or one half the DDR transfer rate. Fabric bandwidth available from a single CCD therefore wasn’t an issue. At matched clocks, a single 32 byte per cycle, or 256-bit link offered the same theoretical bandwidth as a 16 byte per cycle, or 128-bit DDR setup. Zen 2 does see a slight increase in measured memory bandwidth as the second CCD becomes active, but the difference is quite small. For Zen 4, this raises an interesting question about whether fast DDR5 is worthwhile for designs with a single CCD. The Genoa (Zen 4 server variant) Processor Programming Reference manual leaked by the Gigabyte hack suggests that each CCD can have two links to fabric. Depending on how they’re configured, pairing fast DDR5 with single CCD parts might not be worth it, especially if the primary goal is to improve performance in memory bandwidth bound applications.
On the Ryzen 3950X, each CCD’s narrower write link meant single CCD write bandwidth limitations could show up under contrived tests. However, both CCDs together can just about saturate a DDR4 setup when writing. As noted in part 2 of our Zen 4 coverage, the 7950X’s write bandwidth appears to be limited by the the 16 byte/cycle links from the CCDs to the Infinity Fabric interconnect. If we repeat the test above with non-temporal writes, we can clearly see similar bandwidth limitations when a single CCD is active.

Both tests, and both tested CPUs, curiously show that we can achieve higher bandwidth by not loading all cores.
Fewer Threads, More Bandwidth?
When we test memory bandwidth, each thread is given its own array, and the total data across all threads adds up to the test size. That strategy prevents the memory controller from opportunistically combining accesses from different threads. Then, we spawn as many software threads as there are hardware threads. How bandwidth scales with increasing thread count is an interesting topic, but I don’t always have the time and energy to get around it. As you can see above though, this case was well worth checking out.

With further testing, I got the highest memory bandwidth with four threads, pinned to two cores in each CCD. Further investigation showed similar behavior from the 3950X. I also checked performance counters for CCX to Infinity Fabric requests, memory bandwidth, and L3 hitrate to ensure that write combining or cache shenanigans weren’t at play.

One explanation for this behavior is that a 32-thread workload is harsher on the memory controller than a 4-thread one. Exposing more parallelism is not a good thing if that makes the access pattern more scattered. The memory controller would have a harder time trying to schedule accesses to maximize page hits while not stalling any access for long enough to make some queues back up.
We can also look at the same data in terms of how effectively the memory controller was able to utilize theoretical bandwidth. Obviously, higher is better, even though we never expect to hit theoretical bandwidth. Page misses, read to write turnarounds, and refreshes will cause lost memory bus cycles, and there’s no way to avoid that.

With two threads per CCD, bandwidth efficiency is quite decent. 81% of theoretical is not bad at all. AMD’s older DDR4 controller is still better at utilizing available bandwidth:

But that doesn’t tell the whole story. If we look at the other access patterns, Zen 4 makes progress in areas besides maximum achievable bandwidth. Zen 2 didn’t know how to avoid read-for-ownership accesses in the REP STOSB case, but Zen 4 does. Zen 4’s DDR5 controller also handles the read-modify-write access pattern better, perhaps indicating that it takes less of a penalty when reads and writes are mixed. With plain AVX writes and all threads loaded, Zen 4 also achieves better bandwidth efficiency. In an absolute sense, Zen 4’s DDR5 controller also provides much higher bandwidth than the older DDR4 one.
FCLK Effect?
We also tested with a lower 1.6 GHz Infinity Fabric clock, or FCLK. Results provide further evidence that write bandwidth is restricted by Infinity Fabric bandwidth. Specifically, we see a sharp reduction in write bandwidth. That reduction aligns very well with the bandwidth loss we’d expect to see if we’re restricted by the two 16 byte per cycle CCD to IO die links.
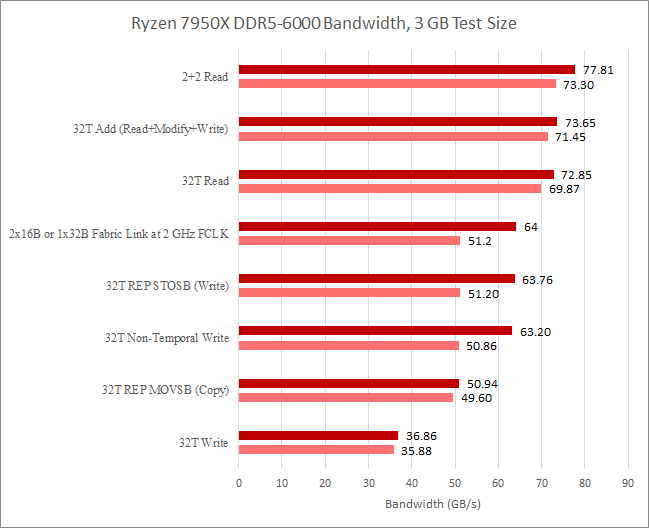
Read bandwidth is clearly not restricted by Infinity Fabric bandwidth. We’re well above 32 bytes per cycle at FCLK. Furthermore the drop in bandwidth does not correspond to the decrease in FCLK. Specifically, a 20% FCLK decrease only brought down maximum read bandwidth by 5.8%. However, it’s certainly interesting that we got a measurable decrease in read bandwidth at lower FCLK.
Integrated GPU
AMD’s desktop Zen 4 platform, Raphael, is the first high performance AMD platform in recent memory to have an integrated GPU. In prior generations, AMD had a split lineup. Desktop chips offered the highest performance CPU configurations, with more cache, more cores, and higher clocks than their mobile counterparts. “APUs” on the other hand, offered a relatively powerful integrated GPU capable of taking on light gaming. They also continued to use a monolithic die to save power, even as their desktop counterparts switched to a chiplet setup to offer higher core counts at reasonable cost.
But Zen 4’s IO die moves to the TSMC 6 nm process, which offers a large density improvement compared to the GlobalFoundries 12nm process used in previous IO dies. IO interfaces typically don’t scale well with process node shrinks, but a die shot of the previous IO die shows a lot of area was occupied by IO controller logic and supporting SRAM. Those blocks probably did scale well with a die shrink, giving AMD room to add a small iGPU.
Raphael’s integrated GPU does not have the performance ambitions of AMD’s APUs, and seems intended to drive a display when no dedicated GPU is available. It features AMD’s modern RDNA2 graphics architecture, but implements it in the smallest configuration possible with just one WGP. Since we’ve been talking about memory and fabric bandwidth, let’s start with a bandwidth test. The Raphael iGPU does give us an extra way to hit the DDR5 controller after all.

Unfortunately, testing bandwidth doesn’t tell us much about any possible fabric limitations. We get just over 60 GB/s from DRAM sized regions. Data from another RDNA2 implementation suggests that a single WGP can’t pull much more than 60 GB/s from DRAM anyway. If the iGPU had a 32 byte/cycle link to fabric, a 2 GHz fabric clock would provide 64 GB/s of bandwidth. That’s more than enough to feed a single WGP.
The bandwidth test also shows signs that we’re dealing with a very small caching configuration. Previously, we looked at several iGPUs, and noted AMD Renoir’s iGPU used a relatively large 1 MB L2 cache, in order to compensate for sharing a relatively low bandwidth DDR4 bus with the CPU. Raphael’s iGPU has no aspirations for competing with even low end graphics cards, and L2 size drops to 256 KB. Interestingly, AMD has also dropped L1 cache size to 64 KB. All RDNA(2) implementations we’ve seen so far have used 128 KB L1 caches. But it looks like RDNA2’s L1 can be configured down to half that size. Unlike discrete RDNA2 GPUs, Raphael’s iGPU doesn’t have an Infinity Cache. L2 misses go straight out to memory.
We can confirm the cache setup details with a latency test. Recently, we discovered that our simple latency test implementation was hitting AMD’s scalar datapath on GCN and RDNA GPUs. Looking at the compiled assembly showed that s_load_dword instructions were generated because the compiler realized that loaded values would be uniform across a wavefront. s_load_dword accesses the scalar cache instead of the vector cache, and these caches are separate on GCN and RDNA. Applying a hack to prevent the compiler from being able to determine whether loaded values would be uniform results in global_load_dword instructions, and higher measured latency. On recent Nvidia and Intel architectures, this hack has no effect because the same caches are used even if the whole wavefront or warp is loading the same value. This complicates GPU benchmarking, because going forward we’ll have to present two sets of latency results for modern AMD GPUs. Let’s start with latency from the scalar side.

We see confirmation that Raphael’s iGPU has a 64 KB L1, backed by a 256 KB L2. It seems to clock slightly lower than desktop RDNA2, leading to higher L1 scalar and shared L1 latencies. However, Raphael’s tiny L2 has better latency than the 6900 XT’s. Like its desktop counterpart, Raphael’s iGPU enjoys lower scalar load latencies than the older GCN architecture used in Renoir. However, Renoir has a much larger L2 cache to help insulate the iGPU from memory bandwidth bottlenecks.
Raphael’s iGPU also enjoys much better DRAM access latency than Renoir. The Ryzen 4800H tested here does suffer from higher memory latency, hitting 84.7 ns at the 1 GB test size compared to the 7950X’s 73.35 ns. However, that relatively small gap doesn’t explain the large discrepancy in GPU-side DRAM latency. The jumps in latency after exceeding L2 capacity suggest the test is spilling out of GCN’s TLB levels. After 128 MB, we’re probably seeing outright TLB misses.
DRAM access latency on Raphael’s iGPU also compares well to that of desktop RDNA2. Desktop RDNA2 sees over 250 ns of DRAM access latency, while Raphael’s iGPU can hit DRAM in just over 191 ns. That advantage is likely because the iGPU is very small, meaning that it doesn’t have to traverse a very complex interconnect and large caches on its way to DRAM. The iGPU also sits right on the IO die, which also has the memory controller.
AMD suffers a lot of additional latency when we exercise the vector load path. AMD probably put a lot of effort into optimizing latency to the scalar cache, and expects latency sensitive operations to take place there. The vector path is optimized more for bandwidth than latency, and the latency penalty there is especially obvious on GCN. RDNA2 is a dramatic improvement. Unfortunately, we didn’t get vector cache latency tested on Raphael, but here’s a preview of the difference between GCN and RDNA2:

While iGPUs are typically smaller than their discrete cousins and have access to less memory bandwidth, they do enjoy faster communication with the host CPU. In some cases, data can be moved between the CPU and GPU without actually copying it, by mapping the same physical memory into both the CPU and GPU’s page tables. Here, we’re testing what happens if copying is required.

Intel shares a L3 cache between the CPU and GPU, allowing very fast copies between the GPU and host. AMD doesn’t have this, but AMD iGPUs still benefit from sharing a DDR bus. DDR4 or DDR5 might not offer the bandwidth of a GDDR setup, but copying data through a DDR bus is still faster than going through PCIe. At larger copy sizes where Intel’s L3 cache doesn’t help, Raphael’s higher bandwidth DDR5 setup comes into play, and lets the Raphael iGPU edge out Tiger Lake’s.
Raphael’s iGPU is a very interesting look at an extremely small RDNA2 implementation. It shows how RDNA2 can scale down to very small setups by cutting back on the L1 cache size, while retaining the low latency cache behavior of larger RDNA2 implementations.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.