
Zhaoxin’s KX-7000

Zhaoxin is a Chinese x86 CPU designer. The KaiXian KX-7000 is Zhaoxin’s latest CPU, and features a new architecture dubbed “世纪大道”. 世纪大道 is a road in Shanghai called “Century Avenue”, following Zhaoxin’s practice of naming architectures after Shanghai landmarks. Zhaoxin is notable because it’s a joint venture between VIA Technologies and the Shanghai municipal government. It inherits VIA’s x86-64 license, and also enjoys powerful government backing. That’s a potent combination, because Zhaoxin’s cores are positioned to take advantage of the strong x86-64 software ecosystem.
x86-64 compatibility is just one part of the picture, because performance matters too. Zhaoxin’s previous LuJiaZui, implemented in the KX-6640MA, was clearly inadequate for handling modern applications. LuJiaZui was a 2-wide core with sub-3 GHz clock speeds and barely more reordering capacity than Intel’s Pentium II from 1997. Century Avenue takes aim at that performance problem.
Core Overview
Century Avenue is a 4-wide, AVX2 capable core with an out-of-order execution window on par with Intel CPUs from the early 2010s. Besides making the core wider and more latency-tolerant, Zhaoxin targets higher clock speeds. The KX-7000 runs at 3.2 GHz, significantly faster than the KX-6640MA’s 2.6 GHz. Zhaoxin’s site claims the KX-7000 can reach 3.5-3.7 GHz, but I never saw the chip clock above 3.2 GHz.

The KX-7000 has eight Century Avenue cores, and uses a chiplet setup reminiscent of single-CCD AMD Ryzen desktop parts. All eight cores sit on a die and share 32 MB of L3 cache. A second IO die connects to DRAM and other IO. Zhaoxin did not specify what process node they’re using. Techpowerup and Wccftech suggests it uses an unspecified 16nm node.
Frontend
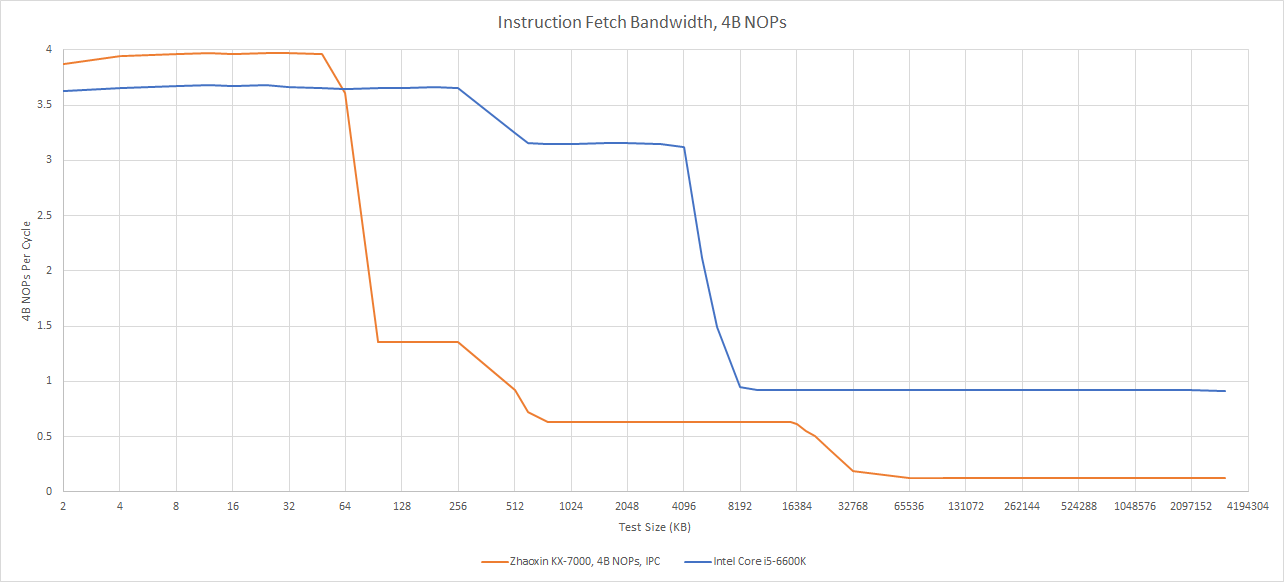
At the frontend, instructions are fetched from a 64 KB 16-way instruction cache. The instruction cache can deliver 16 bytes per cycle, and feeds a 4-wide decoder. Century Avenue uses a thoroughly conventional frontend setup, without a loop buffer or op cache. Instruction cache bandwidth can therefore constrain frontend throughput if average instruction length exceeds 4 bytes.

Frontend bandwidth drops sharply as code spills out of L1i, creating another contrast with 2010s era western designs. Skylake for example can run code from L2 at over 12 bytes per cycle, adequate for >3 IPC with 4 byte instructions. Century Avenue suffers further if code spills into L3, where frontend bandwidth drops to under 4 bytes per cycle.
A 4096 entry branch target buffer (BTB) provides branch targets, and creates two pipeline bubbles after a taken branch. Taken branch latency jumps as the test spills out of L1i, even with far fewer than 4K branches. The BTB is likely tied to the L1i, and thus can’t be used to do long-distance prefetch past a L1i miss.
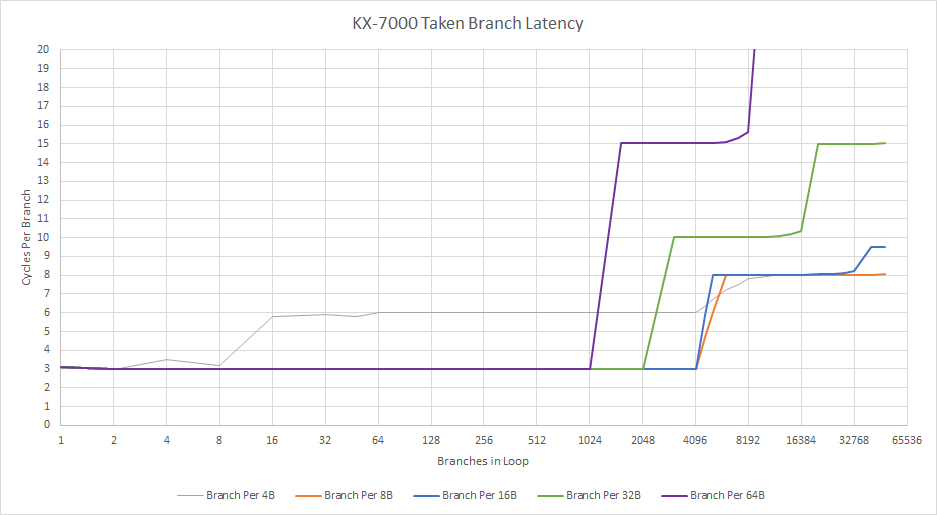
Century Avenue’s branching performance is reminiscent of older cores like VIA’s Nano. Dropping zero-bubble branching capability is a regression compared to LuJiaZui, which could do so from a small 16 entry L0 BTB. Perhaps Zhaoxin felt they couldn’t do zero-bubble branching at Century Avenue’s 3 GHz+ clock speed targets. However Intel and AMD CPUs from over a decade ago have faster branch target caching at higher clock speeds.
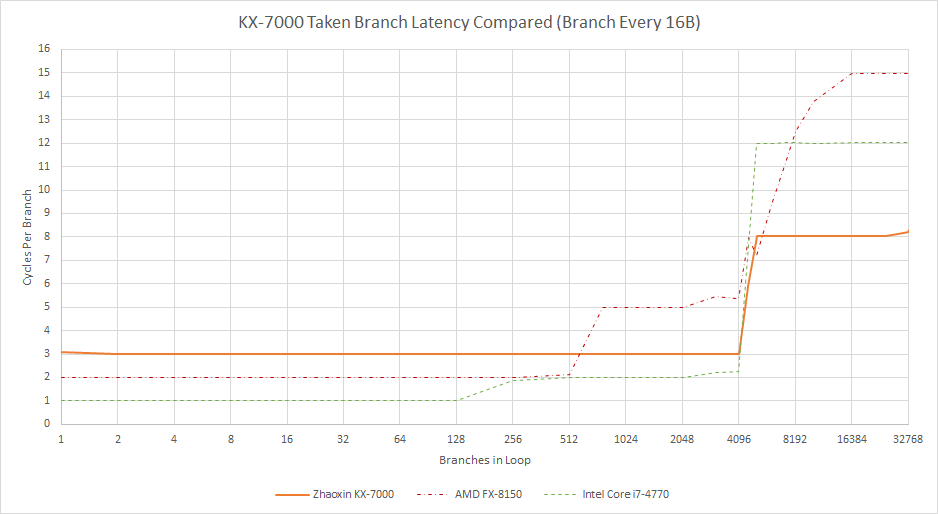
In Century Avenue’s favor, the direction predictor has vastly improved pattern recognition capabilities compared to its predecessor. When given repeating patterns of taken and not-taken branches, the KX-7000 handles a bit like Intel’s Sunny Cove.

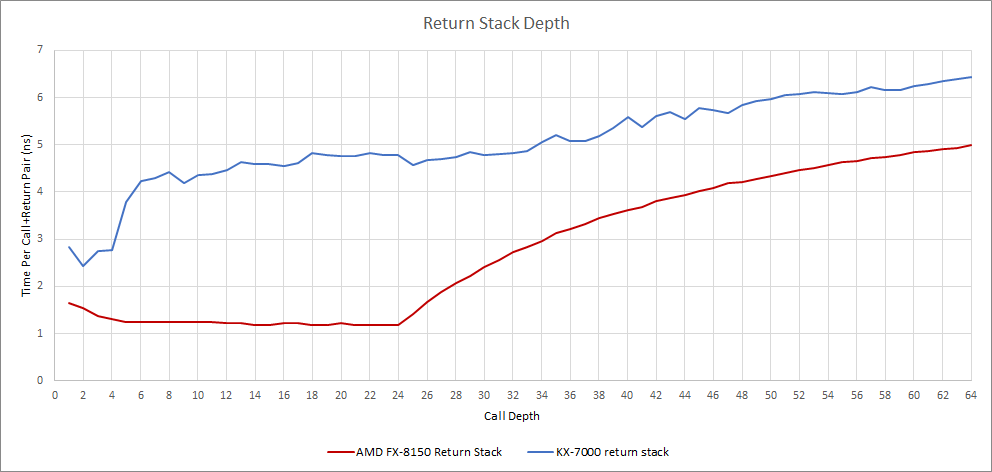
Returns behave much like on LuJiaZui. Call+return pairs enjoy reasonable latency until they go more than four-deep. An inflection point further on suggests a second level return stack with approximately 32 entries. If there is a second level return stack, it’s rather slow with a cost of 14 cycles per call+return pair. Bulldozer shows more typical behavior. Call+return pairs are fast until they overflow a 24 entry return stack.
Century Avenue’s frontend aims to deliver up to four instructions per cycle with minimal sophistication. A conventional fetch and decode setup can be good if tuned properly, but Century Avenue’s frontend has a few clear weaknesses. Average instruction length can exceed 4 bytes in AVX2 code, thanks to VEX prefixes. AMD tackled this by increasing L1i bandwidth to 32B/cycle in 10h CPUs. Intel used loop buffers in Core 2 before introducing an op cache in Sandy Bridge (while keeping 16B/cycle L1i bandwidth). Either approach is fine, but Century Avenue does neither. Century Avenue also does not implement branch fusion, a technique that AMD and Intel have used for over a decade. An [add, add, cmp, jz] sequence executes at under 3 IPC.
Lack of sophistication extends to branch target caching. A single level BTB with effectively 3 cycle latency feels primitive today, especially when it’s tied to the instruction cache. As before, a decoupled BTB isn’t the only way to go. Apple’s M1 also appears to have a BTB coupled to the L1i, but it compensates with a massive 192 KB L1i. Century Avenue’s 64 KB L1i is larger than the 32 KB instruction caches found on many x86-64 cores, but it stops short of brute-forcing its way around large code footprints the way Apple does. To be fair to Zhaoxin, Bulldozer also combines a 64 KB L1i with poor L2 code bandwidth. However, I don’t think there’s a good excuse for 3 cycle taken branch latency on any post-2024 core, especially one running below 4 GHz.
Rename and Allocate
Micro-ops from the frontend are allocated into backend tracking structures, which carry out bookkeeping necessary for out-of-order execution. Register allocation goes hand-in-hand with register renaming, which breaks false dependencies by allocating a new physical register whenever an instruction writes to one. The rename/allocate stage is also a convenient place to carry out other optimizations and expose more parallelism to the backend.
Century Avenue recognizes zeroing idioms like XOR-ing a register with itself, and can tell the backend that such instructions are independent. However such XORs are still limited to three per cycle, suggesting they use an ALU port. The renamer also allocates a physical register to hold the result, even though it will always be zero. Move elimination works as well, though it’s also limited to three per cycle.
Out-of-Order Execution
Zhaoxin switches to a physical register file (PRF) based execution scheme, moving away from LuJiaZui’s ROB-based setup. Separate register files reduce data transfer within the core, and let designers scale ROB size independently of register file capacity. Both are significant advantages over LuJiaZui, and contribute to Century Avenue having several times as much reordering capacity. With a 192 entry ROB, Century Avenue has a theoretical out-of-order window on par with Intel’s Haswell, AMD’s Zen, and Centaur’s CNS. LuJiaZui’s 48 entry ROB is nowhere close.

Reorder buffer size only puts a cap on how far the backend can search ahead of a stalled instruction. Reordering capacity in practice is limited by whatever resource the core runs out of first, whether that be register files, memory ordering queues, or other structures. Century Avenue’s register files are smaller than Haswell or Zen’s, but the core can keep a reasonable number of branches and memory operations in flight.
Century Avenue has a semi-unified scheduler setup, shifting away from LuJiaZui’s distributed scheme. ALU, memory, and FP/vector operations each have a large scheduler with more than 40 entries. Branches appear to have their own scheduler, though maybe not a dedicated port. I wasn’t able to execute a not-taken jump alongside three integer adds in the same cycle. In any case, Century Avenue has fewer scheduling queues than its predecessor, despite having more execution ports. That makes tuning scheduler size easier, because there are fewer degrees of freedom.

Typically a unified scheduler can achieve similar performance to a distributed one with fewer total entries. An entry in a unified scheduling queue can hold a pending micro-op for any of the scheduler’s ports. That reduces the chance of an individual queue filling up and blocking further incoming instructions even though scheduler entries are available in other queues. With several large multi-ported schedulers, Century Avenue has more scheduler capacity than Haswell, Centaur CNS, or even Skylake.
Execution Units
Three ALU pipes generate results for scalar integer operations. Thus Century Avenue joins Arm’s Neoverse N1 and Intel’s Sandy Bridge in having thee ALU ports in an overall four-wide core. Two of Century Avenue’s ALU pipes have integer multipliers. 64-bit integer multiplies have just two-cycle latency, giving the core excellent integer multiply performance.
Century Avenue’s FP/vector side is surprisingly powerful. The FP/vector unit appears to have four pipes, all of which can execute 128-bit vector integer adds. Floating point operations execute at two per cycle. Amazingly, that rate applies even for 256-bit vector FMA instructions. Century Avenue therefore matches Haswell’s per-cycle FLOP count. Floating point latency is normal at 3 cycles for FP adds and multiplies or 5 cycles for a fused multiply-add. Vector integer adds have single-cycle latency.

However, the rest of Century Avenue’s execution engine isn’t so enthusiastic about AVX2. Instructions that operate on 256-bit vectors are broken into two 128-bit micro-ops for all the common cases I tested. A 256-bit FP add takes two ROB entries, two scheduler slots, and the result consumes two register file entries. On the memory side, 256-bit loads and stores take two load queue or two store queue entries, respectively. Zhaoxin’s AVX2 approach is the opposite of Zen 4’s AVX-512 strategy: AMD left execution throughput largely unchanged from the prior generation, however, its 512-bit register file entries let it keep more work in flight and better feed those execution units. Century Avenue’s approach is to bring execution throughput first, and think about how to feed them later.
Core Memory Subsystem
Memory accesses start with a pair of address generation units (AGUs), which calculate virtual addresses. The AGUs are fed by 48 scheduler entries, which could be a 48 entry unified scheduler or two 24 entry queues.
48-bit virtual addresses from the AGUs are then translated into 46-bit physical addresses. Data-side address translations are cached in a 96 entry, 6-way set associative data TLB. 2 MB pages use a separate 32 entry, 4-way DTLB. Century Avenue doesn’t report L2 TLB capacity through CPUID, and DTLB misses add ~20 cycles of latency. That’s higher than usual for cores with a second level TLB, except for Bulldozer.

Besides address translation, the load/store unit has to handle memory dependencies. Century Avenue appears to do an initial dependency check using the virtual address, because a load has a false dependency on a store offset by 4 KB. For real dependencies, Century Avenue can do store forwarding with 5 cycle latency. Like many other cores, partial overlaps cause fast forwarding to fail. Century Avenue takes a 22 cycle penalty in that case, which isn’t out of the ordinary. For independent accesses, Century Avenue can do Core 2 style memory disambiguation. That lets a load execute ahead of a store with an unknown address, improving memory pipeline utilization.
“Misaligned” loads and stores that straddle a cacheline boundary take 12-13 cycles, a heavy penalty compared to modern cores. Skylake for example barely takes any penalty for misaligned loads, and handles misaligned stores with just a single cycle penalty. Century Avenue faces the heaviest penalties (>42 cycles) if a load depends on a misaligned store.
Core-Private Caches
Century Avenue has a 32 KB, 8-way associative data cache with a pair of 128-bit ports and 4 cycle load-to-use latency. Only one port handles stores, so 256-bit stores execute over two cycles. Century Avenue’s L1D bandwidth is therefore similar to Sandy Bridge, even though its FMA capability can demand higher bandwidth. When Intel first rolled out 2×256-bit FMA execution with Haswell, their engineers increased L1D bandwidth to 2×256-bit loads and a 256-bit store per cycle.

L2 latency is unimpressive at 15 cycles. Skylake-X has a larger 2 MB L2 for example, and ran that with 14 cycle latency at higher clock speeds.
Shared Cache and System Architecture
Century Avenue’s system architecture has been overhauled to improve core count scalability. The KX-7000 adopts a triple-level cache setup, aligning with high performance designs from AMD, Arm, and Intel. Core-private L2 caches help insulate L1 misses from high L3 latency. Thus L3 latency becomes less critical, which enables a larger L3 shared across more cores. Compared to LuJiaZui, Century Avenue increases L3 capacity by a factor of eight, going from 4 MB to 32 MB. Eight Century Avenue cores share the L3, while four LuJiaZui cores shared a 4 MB L2. Combined with the chiplet setup, the KX-7000 is built much like a single-CCD Zen 3 desktop part.

Unlike AMD’s recent designs, L3 latency is poor at over 27 ns, or over 80 core cycles. Bandwidth isn’t great either at just over 8 bytes per cycle. A read-modify-write pattern increases bandwidth to 11.5 bytes per cycle. Neither figure is impressive. Skylake could average 15 bytes per cycle from L3 using a read-only pattern, and recent AMD designs can achieve twice that.
The KX-7000 does enjoy good bandwidth scaling, but low clock speeds combined with low per-core bandwidth to start with mean final figures aren’t too impressive. A read-only pattern gets to 215 GB/s, while a read-modify-write pattern can exceed 300 GB/s. For comparison, a Zen 2 CCD enjoys more than twice as much L3 bandwidth.
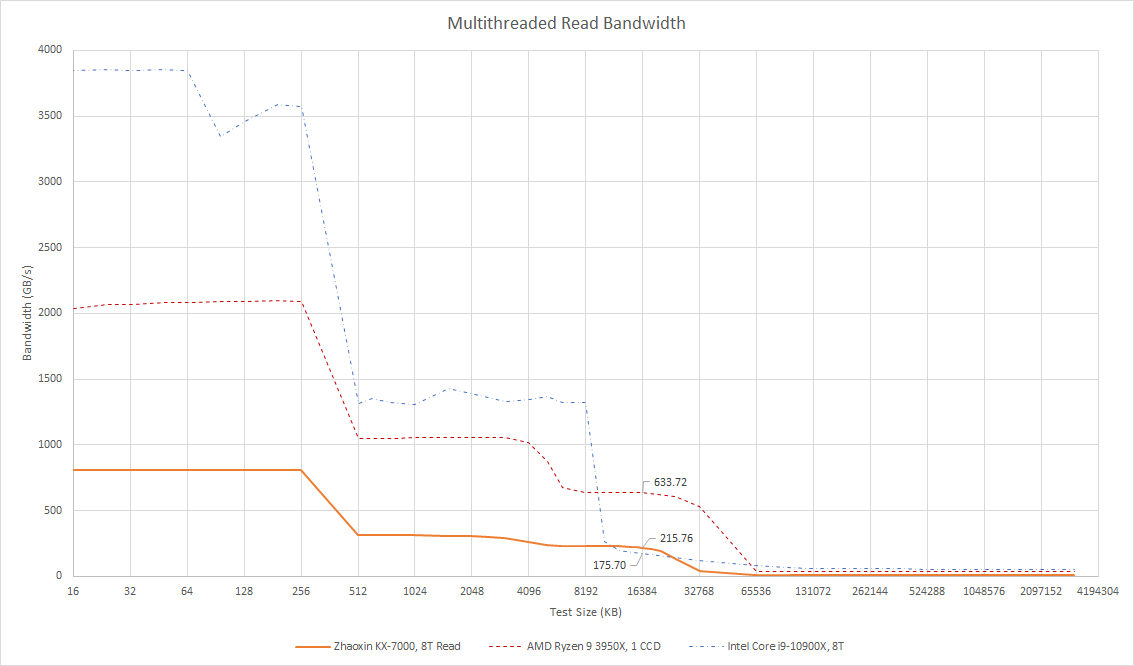
The KX-7000 does have more L3 bandwidth than Intel’s Skylake-X, at least when testing with matched thread counts. However, Skylake-X has a larger 1 MB L2 cache to insulate the cores from poor L3 performance. Skylake-X is also a server-oriented part, where single-threaded performance is less important. On the client side, Bulldozer has similar L3 latency, but uses an even larger 2 MB to avoid hitting it.
DRAM Access
DRAM performance is poor, with over 200 ns latency even when using 2 MB pages to minimize address translation latency. Latency goes over 240 ns using 4 KB pages, using a 1 GB array in both cases. The KX-7000’s DRAM bandwidth situation is tricky. To start, the memory controller was only able to train to 1600 MT/s, despite using DIMMs with 2666 MT/s JEDEC and 4000 MT/s XMP profiles. Theoretical bandwidth is therefore limited to 25.6 GB/s. However measured read bandwidth gets nowhere close, struggling to get past even 12 GB/s.
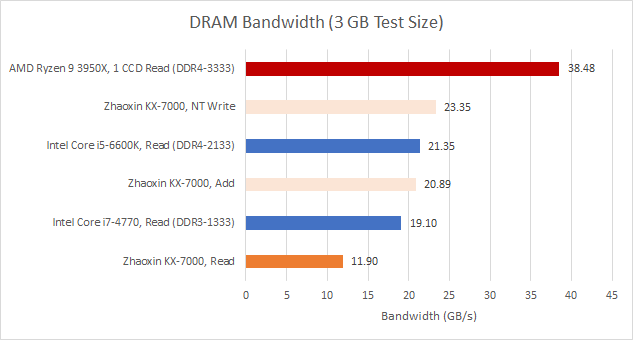
Mixing in writes increases achievable bandwidth. A read-modify-write pattern gets over 20 GB/s, while non-temporal writes reach 23.35 GB/s. The latter figure is close to theoretical, and indicates Zhaoxin’s cross-die link has enough bandwidth to saturate the memory controller. Read bandwidth is likely limited by latency. Unlike writes, where data to be written gets handed off, reads can only complete when data returns. Maintaining high read bandwidth requires keeping enough memory requests in-flight to hide latency.

Often loading more cores lets the memory subsystem keep more requests in flight, because each core has its own L1 and L2 miss queues. However the KX-7000’s read bandwidth abruptly stops scaling once a bandwidth test loads more than two cores. That suggests a queue shared by all the cores doesn’t have enough entries to hide latency, resulting in low read bandwidth.
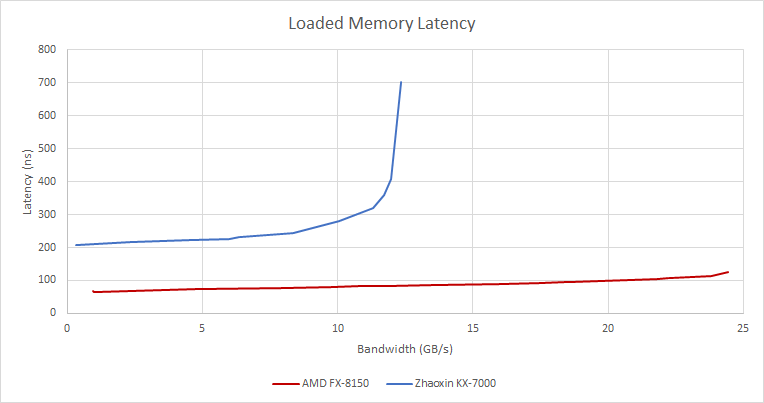
To make things worse, the KX-7000’s memory subsystem doesn’t do well at ensuring fairness between requests coming from different cores. A pointer chasing thread sees latency skyrocket when other cores generate high bandwidth load. In a worst case with one latency test thread and seven bandwidth threads, latency pushes past 1 microsecond. I suspect the bandwidth-hungry threads monopolize entries in whatever shared queue limits read bandwidth.
AMD’s Bulldozer maintains better control over latency under high bandwidth load. The FX-8150’s Northbridge has a complicated setup with two crossbar levels, but does an excellent job. Latency increases as the test pushes up to the memory controller’s bandwidth limits, but doesn’t rise to more than double its un-loaded latency. In absolute terms, even Bulldozer’s worst case latency is better than the KX-7000’s best case.

Sometimes, the memory subsystem has to satisfy a request by retrieving data from a peer core’s cache. These cases are rare in practice, but can give insight into system topology. The KX-7000 posts relatively high but even latency in a core-to-core latency test. Some core pairs see lower latency than others, likely depending on which L3 slice the tested address belongs to.
Single Threaded Performance: SPEC CPU2017
Compared to LuJiaZui, Century Avenue posts a huge 48.8% gain in SPEC CPU2017’s integer suite, and provides more than a 2x speedup in the floating point suite. Zhaoxin has been busy over the past few years, and that work has paid off. Against high performance western x86-64 chips, the KX-7000 falls just short of AMD’s Bulldozer in the integer suite. The FX-8150 leads by 13.6% there. Zhaoxin flips things around in the floating point suite, drawing 10.4% ahead of Bulldozer.
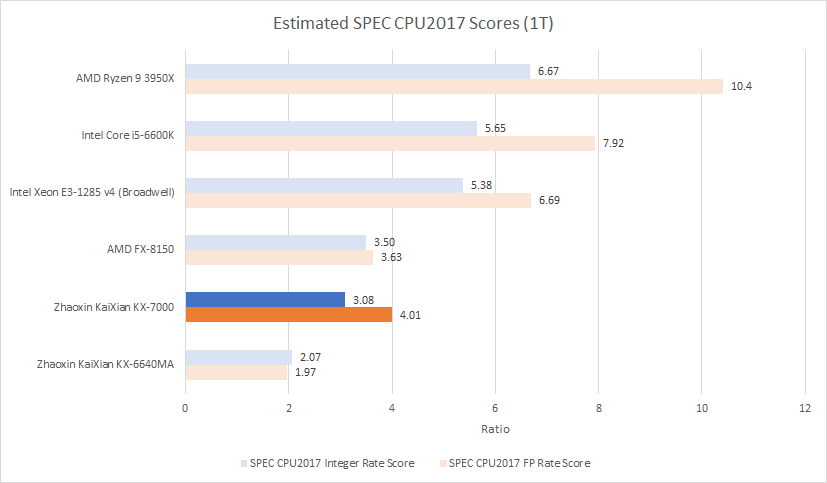
Newer cores like Broadwell or Skylake land on a different performance planet compared to Century Avenue, so Bulldozer is the best relative comparison. Against Bulldozer, Century Avenue tends to do best in higher-IPC tests like 500.perlbench, 548.exchange2, and 525.x264. I suspect Century Avenue’s additional execution resources give it an advantage in those tests. Meanwhile Bulldozer bulldozes the KX-7000 in low IPC tests like 505.mcf and 520.omnetpp. Those tests present a nasty cocktail of difficult-to-predict branches and large memory footprints. Bulldozer’s comparatively strong memory subsystem and faster branch predictor likely give it a win there.

SPEC CPU2017’s floating point suite generally consists of higher IPC workloads, which hands the advantage to the KX-7000. However, the FX-8150 snatches occasional victories. 549.fotonik3d is a challenging low IPC workload that sees even recent cores heavily limited by cache misses. Bulldozer walks away with an impressive 46.2% lead in that workload. At the other end, 538.imagick basically doesn’t see L2 misses.

Overall the SPEC CPU2017 results suggest the KX-7000 can deliver single-threaded performance roughly on par with AMD’s Bulldozer.
Multithreaded Performance
Having eight cores is one of the KX-7000’s relative strengths against the FX-8150 and Core i5-6600K. However, multithreaded results are a mixed bag. libx264 software video encoding can take advantage of AVX2, and uses more than four threads. However, the KX-7000 is soundly beaten even by Bulldozer. 7-Zip compression uses scalar integer instructions. With AVX2 not playing a role, Bulldozer and the Core i5-6600K score even larger wins.

The KX-7000 turns in a better performance in Y-Cruncher, possibly with AVX2 giving it a large advantage over Bulldozer. However, eight Century Avenue cores still fail to match four Skylake ones. For a final test, OpenSSL RSA2048 signs are a purely integer operation that focuses on core compute power rather than memory access. They’re particularly important for web servers, which have to validate their identity when clients establish SSL/TLS connections. Zhaoxin again beats Bulldozer in that workload, but falls behind Skylake.
Final Words
Zhaoxin inherits VIA’s x86 license, but plays a different ball game. VIA focused on low-power, low-cost applications. While Centaur CNS did branch into somewhat higher performance targets with a 4-wide design, the company never sought to tap into the wider general purpose compute market like AMD and Intel. Creating a high-clocking, high-IPC core that excels in everything from web browsing to gaming to video encoding is a massive engineering challenge. VIA reasonably decided to find a niche, rather than take AMD and Intel head-on without the engineering resources to match.
However Zhaoxin is part of China’s effort to build domestic chips in case western ones become unavailable. Doing so is a matter of national importance, so companies like Zhaoxin can expect massive government support, and survive even without being profitable. Zhaoxin’s chips don’t need to directly compete with AMD and Intel. But AMD and Intel’s chips have driven performance expectations from application developers. China needs chips with enough performance to substitute western chips without being disruptively slow.
Century Avenue is an obvious attempt to get into that position, stepping away from LuJiaZui’s low power and low performance design. At a high level, Century Avenue represents good progress. A 4-wide >3 GHz core with Bulldozer-level performance is a huge step up. At a lower level, it feels like Zhaoxin tried to make everything bigger without slowing down and making sure the whole picture makes sense. Century Avenue has 2×256-bit FMA units, which suggest Zhaoxin is trying to get the most out of AVX2. However Century Avenue has low cache bandwidth and internally tracks 256-bit instructions as a pair of micro-ops. Doing so suits a minimum-cost AVX2 implementation geared towards compatibility rather than high performance. Besides AVX2, Century Avenue has small register files relative to its ROB capacity, which hinders its ability to make use of its theoretical out-of-order window.
Zooming out to the system level shows the same pattern. Century Avenue’s L2 is too small considering it has to shield cores from 80+ cycle L3 latency. The KX-7000’s DRAM read bandwidth is inadequate for an octa-core setup, and the memory subsystem does a poor job of ensuring fairness under high bandwidth load. Besides unbalanced characteristics, Century Avenue’s high frontend latency and lack of branch fusion make it feel like a 2005-era core, not a 2025 one.
Ultimately performance is what matters to an end-user. In that respect, the KX-7000 sometimes falls behind Bulldozer in multithreaded workloads. It’s disappointing from the perspective that Bulldozer is a 2011-era design, with pairs of hardware thread sharing a frontend and floating point unit. Single-threaded performance is similarly unimpressive. It roughly matches Bulldozer there, but the FX-8150’s single-threaded performance was one of its greatest weaknesses even back in 2011. But of course, the KX-7000 isn’t trying to impress western consumers. It’s trying to provide a usable experience without relying on foreign companies. In that respect, Bulldozer-level single-threaded performance is plenty. And while Century Avenue lacks the balance and sophistication that a modern AMD, Arm, or Intel core is likely to display, it’s a good step in Zhaoxin’s effort to break into higher performance targets.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
Hi all, I have motherboad ASUS XC-KX700M D4 with this CPU KX-7000. In my test power consumpting whole system is like below.
KX-7000 @3GHz turbo off with iGPU + 2x8GB DDR4 3200MHz + Nvme 128GB:
- Idle: 32W
- Cinebench R23 multi: 100W
KX-7000 @3-3,6GHz turbo on with iGPU + 2x8GB DDR4 3200MHz + Nvme 128GB:
- Idle: 32W
- Cinebench R23 multi: 120W
It’s 6nm for CCD. https://forums.anandtech.com/threads/zhaoxins-zx-f-kx-7000-kh-40000-and-beyond.2564975/page-20#post-41133323
Also VIA Next advertised 6nm project on their website.
Last year VIA taped out 5nm project.
It's propably VIA, who send Zhaoxin projects to production at TSMC. Like AMD-Hygon, what is on entity list.
I'll be not suprised if higher clocked kx-7000 is from TSMC and lower clocked versions are produced on 7nm SMIC. IOD is slow, and GPU c-1190 on IOD has 2/3 clock of c-1080, so maybe it is 16/12 SMIC.