
Zen 5's AVX-512 Frequency Behavior

Zen 5 is AMD's first core to use full-width AVX-512 datapaths. Its vector execution units are 512 bits wide, and its L1 data cache can service two 512-bit loads per cycle. Intel went straight to 512-bit datapaths with Skylake-X back in 2017, and used fixed frequency offsets and transition periods to handle AVX-512 power demands. Later Intel CPUs did away with fixed fixed frequency offsets, but Skylake-X's AVX-512 teething troubles demonstrate the difficulties that come with running wide datapaths at high clock speeds. Zen 5 benefits from a much better process node and also has no fixed clock speed offsets when running AVX-512 code.
Through the use of improved on-die sensors, AC capacitance (Cac) monitors, and di/dt-based adaptive clocking, "Zen 5" can achieve full AVX512 performance at peak core frequency.
"Zen 5": The AMD High-Performance 4nm x86-64 Microprocessor Core
But if a Zen 5 core is running at 5.7 GHz and suddenly gets faced with an AVX-512 workload, what exactly happens? Here, I'm probing AVX-512 behavior using a modified version of my boost clock testing code. I wrote that code a couple years ago and used dependent integer adds to infer clock speed. Integer addition typically has single cycle latency, making it a good platform-independent proxy for clock speed. Instead of checking clock ramp time, I'm switching to a different test function with AVX-512 instructions mixed in after each dependent add. I also make sure the instructions I place between the dependent adds are well within what Zen 5's FPU can handle every cycle, which prevents the FPU from becoming a bottleneck.
512-bit FMA, Register Inputs
I started by placing two fused multiply-add (FMA) instructions in each iteration, each of which operates on a 512-bit vector of packed FP32 values. After the Ryzen 9 reaches 5.7 GHz running the scalar integer function, I switch over to AVX-512 instructions.

Impressively, nothing changes. The dependent integer adds continue to execute at ~5.7 GHz. Zooming in doesn’t show a transition period either. I see a single data point covering 1.3 microseconds where the core executed those dependent integer adds at “only” a 5.3 GHz average. The very next data point shows the core running at full speed again.

Evidently, Zen 5’s FPU is not troubled by getting hit with 512-bit vector operations, even when running at 5.7 GHz. If there is a transition period for the increased power draw, it’s so tiny that it can be ignored. That matches Alex Yee’s observations, and shows just how strong Zen 5’s FPU is. For comparison, the same experiment on Skylake-X shows both a transition period and lower clock speeds after the transition completes. Intel’s Core i9-10900X reaches 4.65 GHz after a rather long clock ramp using scalar integer code. Switching to the AVX-512 test function drops clock speeds to 4 GHz, a significant decrease from 4.65 GHz.

Zooming in on Skylake-X data reveals a transition period, which Travis Downs and Alex Yee noted from a while ago. My test eats a longer 55 microsecond transition period though. Travis Downs saw a 20 microsecond transition, while Alex Yee mentions a 50k cycle delay (~12 microseconds at 4 GHz).

I’m not sure why I see a longer transition, but I don’t want to dwell on it because of methodology differences. Travis Downs used vector integer instructions, and I used floating point ones. And I want to focus on Zen 5.
After the transition finishes, the i9-10900X levels out at 3.7 GHz, then briefly settles at 3.8 GHz for less than 0.1 ms before reaching its steady state 4 GHz speed.
Adding a Memory Operand
Zen 5 also doubles L1D load bandwidth, and I’m exercising that by having each FMA instruction source an input from the data cache. I used the following pattern above:
add rbx, r8
vfmadd132ps zmm16, zmm1, zmm0
vfmadd132ps zmm17, zmm2, zmm0
add rbx, r8
vfmadd132ps zmm18, zmm3, zmm0
vfmadd132ps zmm19, zmm4, zmm0
etcI’m changing those FMA instructions to use a memory operand. Because Zen 5 can handle two 512-bit loads per cycle, the core should have no problems maintaining 3 IPC. That’s two 512-bit FMAs, or 64 FP32 FLOPS, alongside a scalar integer add.
add rbx, r8
vfmadd132ps zmm16, zmm1, [r15]
vfmadd132ps zmm17, zmm2, [r15 + 64]
add rbx, r8
vfmadd132ps zmm18, zmm3, [r15 + 128]
vfmadd132ps zmm19, zmm4, [r15 + 192]
etcWith the load/store unit’s 512-bit paths in play, the Ryzen 9 9900X has to undergo a transition period of some sort before recovering to 5.5 GHz. From the instruction throughput perspective, Zen 5 apparently dips to 4.7 GHz and stays there for a dozen milliseconds. Then it slowly ramps back up until it reaches steady state speeds.

The Ryzen 9 9900X splits its cores across two Core Complex Dies, or CCDs. The first CCD can reach 5.7 GHz, while the second tops out at 5.4 GHz. Cores on the second CCD show no transition period on this test.

Cores within the fast CCD all need a transition period, but the exact nature of that transition varies. Not all cores reach steady state AVX-512 frequencies at the same time, and some cores take a sharper hit when this heavy AVX-512 sequence shows up.

Per-core variation suggests each Zen 5 core has its own sensors and adjusts its performance depending on something. Perhaps it’s measuring voltage. From this observation, I wouldn’t be surprised if another 9900X example shows slightly different behavior.
Am I Really Looking at Clock Speed?
Zen 5’s frequency appears to dip during the transition period, based on how fast it’s executing instructions compared to its expected capability. But while my approach of using dependent scalar integer adds is portable, it can’t differentiate between a core running at lower frequency and a core refusing to execute instructions at full rate. The second case may sound weird. But Travis Downs concluded Skylake-X did exactly that based on performance counter data.
[Skylake-X] continues executing instructions during a voltage transition, but at a greatly reduced speed: 1/4th of the usual instruction dispatch rate
Gathering Intel on Intel AVX-512 Transitions, Travis Downs
Executing instructions at 1/4 rate would make me infer a 4 GHz core is running at 1 GHz, which is exactly what I see with the Skylake-X transition graph above. Something similar actually happens on Zen 5. It’s not executing instructions at the usual rate during the transition period, making it look like it’s clocking slower from the software perspective.
But performance counter data shows Zen 5 does not sharply reduce its clock speed when hit with AVX-512 code. Instead, it gradually backs off from maximum frequency until it reaches a sustainable clock speed for the workload it’s hit with. During that period, instructions per cycle (IPC) decreases. IPC gradually recovers as clock speeds get closer to the final steady-state frequency. Once that happens, instruction execution rate recovers to the expected 3 IPC (1x integer add + 2x FMA).

I do have some extra margin of error when reading performance counter data, because I’m calling Linux’s perf API before and after each function call, but measuring time within those function calls. That error would become negligible if the test function runs for longer, with a higher iteration count. But I’m keeping iteration counts low to look for short transitions, resulting in a 1-3% margin of error. That’s fine for seeing whether the dip in execution speed is truly caused by lower clock speed.

As you might expect, different cores within CCD0 vary in how much they do “IPC throttling”, for lack of a better term. Some cores cut IPC more than others when hit with sudden AVX-512 load. Curiously, a core that cuts IPC harder (core 0) reaches steady state a tiny bit faster than a core that cut IPC less to start with (core 3).

Load Another FP Pipe?
Now I wonder if Zen 5’s IPC throttling is triggered by the load/store unit, or overall load. Creating heavier FPU load should make that clear. Zen 5’s FPU has four pipes for math operations. FMA operations can go down two of those pipes. Dropping a vaddps into the mix will load a third pipe. On the fast CCD, that increases the transition period from ~22 to ~32 ms. Steady state clock speed decreases by about 150 MHz compared to the prior test.

Therefore, overall stress on the core (for lack of a better term) determines whether Zen 5 needs a transition period. It just so happens that 512-bit accesses to the memory subsystem are heavy. 512-bit register-to-register operations are no big deal, but adding more of them on top of data cache accesses increases stress on the core and causes more IPC throttling.
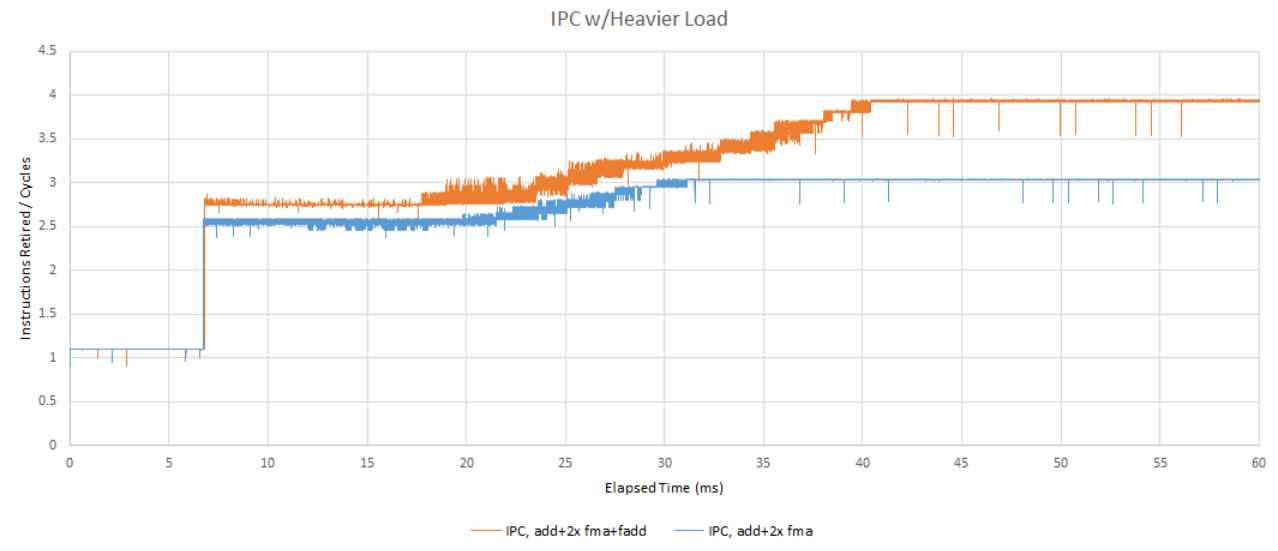
To be clear, IPC during the transition period with the 512-bit FP add thrown in is higher than before. But 2.75 IPC is 68.75% of the expected 4 GHz, while 2.5 IPC in the prior test is 83.3% of the expected 3 IPC.
Performance counter data suggests the core decreases actual clock speed at a similar rate on both tests. The heavier load causes a longer transition period because the core has to keep reducing clocks for longer before things stabilize.
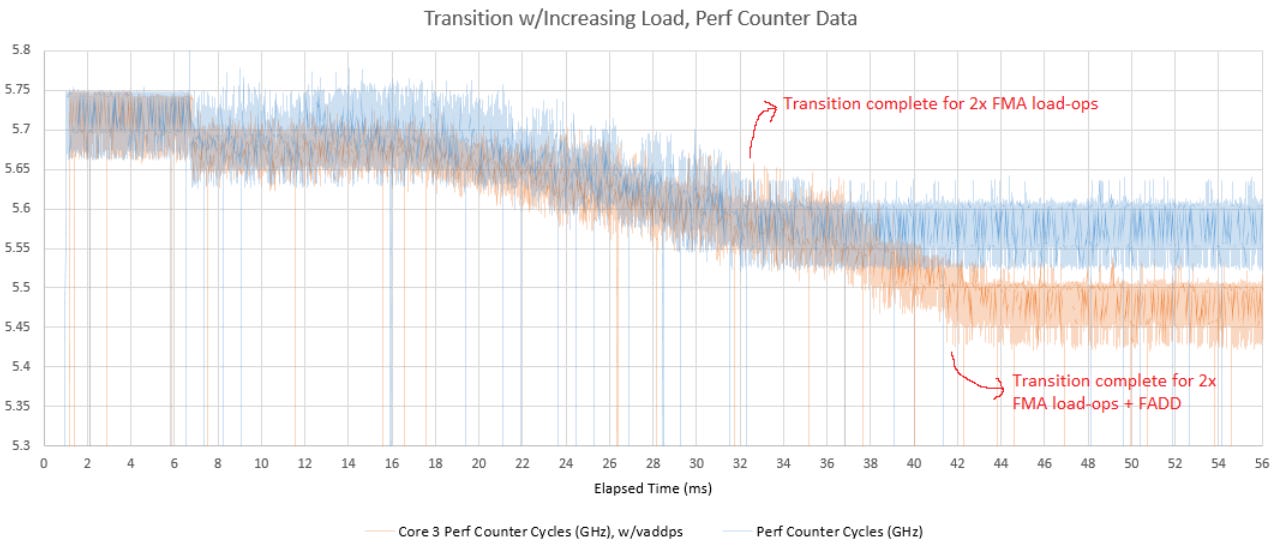
Even with this heavier load, a core on the 9900X’s fast CCD still clocks higher than one on the slower CCD. Testing the add + 2x FMA + FADD combination on the slower CCD did not show any transition period. That’s a hint Zen 5 only needs IPC throttling if clock speed is too high when a heavy AVX-512 sequence comes up.
Transition and Recovery Periods
Transitions and the associated IPC throttling could be problematic if software rapidly alternates between heavy AVX-512 sequences and light scalar integer code. But AMD does not let Zen 5 get stuck repeatedly taking transition penalties. If I switch between the AVX-512 and scalar integer test functions, the transition doesn’t repeat.

AMD does not immediately let Zen 5 return to maximum frequency after AVX-512 load lets up. From the start of the graph we can see Zen 5 can ramp clocks from idle to 5.7 GHz in just a few milliseconds, so this isn’t a limitation of how fast the core can pull off frequency changes. Remember how the slower CCD never suffered transitions? I suspect that’s because it never found itself clocked too high to begin with. Apparently the same also applies to the fast CCD. If it happens to be running at a lower clock when a heavy AVX-512 sequence shows up, it doesn’t need to transition.

Longer function switching intervals bring the transitions back, but now they’re softer. The first transition interval starts at 5.61 GHz and ends at 5.39 GHz. It takes nearly 21 ms.

The next transition starts when Zen 5 has only recovered to 5.55 GHz, and only lasts ~10 ms. IPC throttling is less severe too. IPC only drops to ~3.2 IPC, not 2.7 GHz like before.
With an even longer switching interval, I can finally trigger full-out transitions in repeated fashion. Thus transition periods and IPC throttling behavior vary depending on how much excessive clock speed the core has to shed.
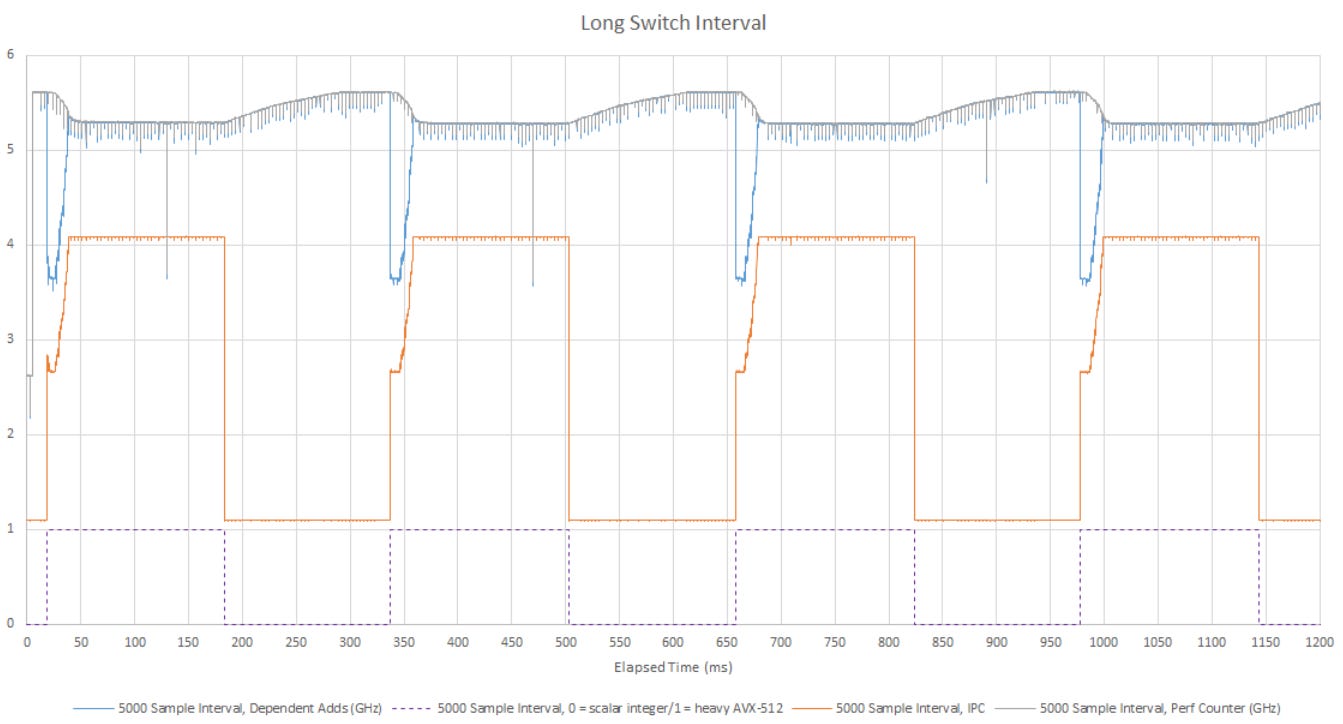
The longer switch interval also shows that Zen 5 takes over 100 ms to fully regain maximum clocks after the heavy AVX-512 load disappears. Therefore, the simple scalar integer code with just dependent adds is running slower for some time. It’s worth noting that “slower” here is still 5.3 GHz, and very fast in an absolute sense. AMD’s Ryzen 9 9900X is not shedding 600 MHz like Intel’s old Core i9-10900X did with a lighter AVX-512 test sequence.

Zen 5’s clock ramp during the recovery period isn’t linear. It gains 200 MHz over the first 50 ms, but takes longer than 50 ms to recover the last 100 MHz. I think this behavior is deliberate and aimed at avoiding frequent transitions. If heavy AVX-512 code might show up again, keeping the core clock just a few percent lower is bettert than throttling IPC by over 30%. As clock speed goes higher and potential transitions become more expensive, the core becomes less brave and increases clocks slower.

Quickly switching between scalar integer and heavy AVX-512 code basically spreads out the transition, so that the core eventually converges at a sustainable clock speed for the AVX-512 sequence in question. Scalar integer code between AVX-512 sequences continues to run at full speed. And the degree of IPC throttling is very fine grained. There is no fixed 1:4 rate as on Skylake-X.
Investigating IPC Throttling
Zen 5 also has performance counters that describe why the renamer could not send micro-ops downstream. One reason is that the floating point non-scheduling queue (FP NSQ) is full. The FP NSQ on Zen 5 basically acts as the entry point for the FPU. See the prior Zen 5 article for more details.
If the NSQ fills often, the frontend is supplying the FPU with micro-ops faster than the FPU can handle them. As mentioned earlier, Zen 5’s FPU should have no problems doing two 512-bit FMA operations together with a 512-bit FP add every cycle.

But during the transition period, the FP NSQ fills up quite often. At its worst, it’s full over nearly 10% of (actual) cycles. Therefore Zen 5’s frontend and renamer are running at full speed. The IPC throttling is happening somewhere further down the pipeline. Likely, Zen 5’s FP scheduler is holding back and not issuing micro-ops every cycle even when they’re ready. AMD doesn’t have performance counters at the schedule/execute stage, so that theory is impossible to verify.
Final Words
Running 512-bit execution units at 5.7 GHz is no small feat, and it’s amazing Zen 5 can do that. The core’s FPU by itself is very efficient. But hit more 512-bit datapaths around the core, and you’ll eventually run into cases where the core can’t do what you’re asking of it at 5.7 GHz. Zen 5 handles such sudden, heavy AVX-512 load with a very fine grained IPC throttling mechanism. It likely uses feedback from per-core sensors, and has varying behavior even between cores on the same CCD. Load-related clock frequency changes are slow in both directions, likely to avoid repeated IPC throttling and preserve high performance for scalar integer code in close proximity to heavy AVX-512 sequences.

Transient IPC throttling raises deep philosophical questions about the meaning of clock frequency. If you maintain a 5.7 GHz clock signal and increment performance counters every cycle, but execute instructions as if you were running at 3.6 GHz, how fast are you really running? Certainly it’s 5.7 GHz from a hardware monitoring perspective. But from a software performance perspective, the core behaves more like it’s running at 3.6 GHz. Which perspective is correct? If a tree falls and no one’s around to hear it, did it make a sound? What if some parts of the core are running at full speed, but others aren’t? If a tree is split by lightning and only half of it falls, is it still standing?

Stepping back though, Zen 5’s AVX-512 clock behavior is much better than Skylake-X’s. Zen 5 has no fixed frequency offsets for AVX-512, and can handle heavier AVX-512 sequences while losing less clock speed than Skylake-X. Transitions triggered by heavier AVX-512 sequences are interesting, but Zen 5’s clocking strategy seems built to minimize those transitions. Maybe corner cases exist where Zen 5’s IPC throttling can significantly impact performance. I suspect such corner cases are rare, because Zen 5 has been out for a while and I haven’t seen anyone complain. And even if it does show up, you can likely avoid the worst of it by running on a slower clocked CCD (or part). Still, it was interesting to trigger it with a synthetic test and see just how AMD deals with 512-bit datapaths at high speed.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
I'm interested in how much a fairly light AVX-512 workload (say, a small but highly optimized loop that just runs for a couple of microseconds) affects core behavior. If I recall correctly, a common criticism with Skylake-X was that the core dropped completely as soon as *any* AVX-512 instructions were executed, causing many developers to just avoid AVX-512 completely since it left their code running actively worse than AVX2 code that should nominally be slower.
The "rapid switching" graph seems to indicate that it shouldn't be nearly as big of a deal on Zen 5, since the core at least seems to recover immediately when small-ish AVX-512 sequences end, but it does also clearly shows IPC throttling immediately , but this could of course just be due to measurement granularity. Do you think there might be a "maximum size" of AVX-512 workload that would cause the core not to throttle at all?
Very interesting!
I was wondering whether the frequency behavior could actually be impacted by max possible current that core can handle as mentioned: https://numberworld.org/blogs/2024_8_7_zen5_avx512_teardown/
I've noticed that running heavy AVX512 code on 9955hx3d is limitted by 125A current rather than thermal/voltage or wattage.