
Turning off Zen 4's Op Cache for Curiosity and Giggles

CPUs start executing instructions by fetching those instruction bytes from memory and decoding them into internal operations (micro-ops). Getting data from memory and operating on it consumes power and incurs latency. Micro-op caching is a popular technique to improve on both fronts, and involves caching micro-ops that correspond to frequently executed instructions.
AMD's recent CPUs have particularly large micro-op caches, or op caches for short. Zen 4's op cache can hold 6.75K micro-ops, and has the highest capacity of any op cache across the past few generations of CPUs. This huge op cache enjoys high hitrates, and gives the feeling AMD is leaning harder on micro-op caching than Intel or Arm. That begs the question of how the core would handle if its big, beautiful op cache stepped out for lunch.

To recap Zen 4's frontend, the core can feed itself from three sources. There's a loop buffer with 144 entries that acts primarily as a power saving measure for small loops. A fetch and decode path can handle up to 4 instructions per cycle. And finally, the op cache can deliver 9 micro-ops per cycle.
Thankfully for my curiosity, AMD has disabled Zen 4's loop buffer in the latest AGESA version. Setting bit 5 in an instruction cache control MSR disables the op cache. AMD has not documented either of these features, but I appreciate their (unintentional) willingness to give me a learning opportunity. With both the loop buffer and op cache off, Zen 4 turns from a 6-wide core to a 4-wide one.
For this article, I'll be testing the Ryzen 9 7950X3D in the ASRock B650 PG Lightning. I ran SPEC CPU2017's workloads on the non-VCache die, and ran a gaming workload on the VCache die. I also went over this topic in video format.
SPEC CPU2017
SPEC CPU2017 is an industry standard benchmark suite. System vendors often use it to advertise expected performance, and hardware designers use it to tune CPU architectures. Disabling the op cache reduces performance by 11.4% in SPEC CPU2017's integer suite, and 6.6% in the floating point suite.

Performance losses are heavier if I run two copies, pinned to SMT siblings on the same core. SPEC CPU2017’s integer suite sees a 16% SMT score decrease, while the floating point suite sees a 10.3% decrease. Not using the op cache already costs some performance for a single thread, but that loss increases with both SMT threads loaded.
Single Threaded Performance
Total scores only tell part of the story, because each SPEC CPU2017 suite consists of many tests, each with different characteristics. Within the integer suite, 548.exchange2 is an outlier. It takes a cripping 32% performance loss with the op cache disabled. On the other hand, 520.omnetpp barely takes a hit.

520.omnetpp sees relatively little loss because it’s not a high IPC workload. From prior testing, omnetpp is primarily limited by backend memory access latency. On Zen 4, it sees more L2 misses per instruction than any other test. Much of that is caught by the L3 cache, but even AMD’s relatively fast L3 takes a lot of cycles to get data from in an absolute sense. Because cache misses prevent omnetpp from approaching 4 IPC in the first place, cutting down frontend throughput doesn’t affect it much.

548.exchange2 is also easy to explain. Zen 4 can normally average over 4 IPC on that workload. Turning off the op cache turns Zen 4 into a 4-wide core, which can no longer sustain such high IPC. Curiously though, 548.exchange2 gets smacked harder by other high IPC workloads like 525.x264. To dig deeper, I collected performance monitoring data using an event that counts ops delivered from the frontend. I also used count masking to get the percentage of core cycles during which ops were dispatched from a particular source.

Even with the op cache on and delivering the majority of micro-ops, Zen 4’s frontend is very busy. For perspective, Nvidia’s tuning guides suggest considering an application bound by shader throughput if utilization is over 80%. Zen 4’s frontend is definitely there, even if you look at the op cache alone.
If the SM is the top SOL unit and “SM Throughput for Active Cycles” is greater than 80%, then the current workload is mainly limited by the SM scheduler issue rate
The Peak-Performance-Percentage Analysis Method for Optimizing Any GPU Workload
Zen 4’s op cache of course doesn’t do math, but I think the same principle applies. High average utilization points to a possible throughput bottleneck. I find that curious because the op cache has overkill throughput. It can provide 9 micro-ops per cycle, while the rename and allocate stage downstream can only handle 6 per cycle. That suggests the frontend is operating inefficiently. 16% of 548.exchange2’s instruction stream consists of branches. Only 7.27% of 525.x264’s instruction stream is branches for comparison. I didn’t record performance monitoring data for taken branches, but exchange2 almost certainly sees more taken branches too. Those can cause frontend throughput losses because any instructions fetched after a taken branch aren’t useful. That’s where the op cache’s overkill bandwidth might come in handy. Even if several slots in one fetch are wasted, the op cache can catch up later if it hits straight-line code.

The 4-wide decoder doesn’t have that luxury, because all four of those decode slots need to count. In exchange2, that’s often not the case. Thus the decoders are pushed to the limits, and struggle to keep the core fed. Elsewhere though, the decoders aren’t always in such a dire situation. The frontend is busier without the op cache, but it had plenty of breathing room before, and cutting a bit into that breathing room isn’t the end of the world.
SPEC CPU2017’s floating point suite is less affected by turning the op cache off. Like the integer suite, the floating point suite has a variety of workloads with different characteristics. And a closer examination does turn up a couple outliers. 508.namd and 538.imagick face above average performance losses from disabling the op cache.

Much like 548.exchange2, namd and imagick are high IPC workloads. However, they don’t quite push to 4 IPC and also don’t see the hefty losses that 548.exchange2 did. Besides those high IPC outliers, the floating point suite has interesting examples of workloads taking little to no performance loss. 507.cactuBSSN and 554.roms for example were completely unaffected by the loss of the op cache.

A few other tests like 549.fotonik3d and 518.lbm saw score reductions of less than 1%. I consider that well within margin of error. All of those examples are interesting because op cache hitrates are very high in the floating point suite, just as they were across the integer suite.

Digging deeper shows the frontend isn’t being pushed too hard in most of the floating point workloads. Part of that is down to very high op cache hitrate no doubt. But even with that in mind, the frontend has plenty of room to breathe. From prior data, I know that SPEC CPU2017’s floating point workloads tend to emphasize backend core and memory performance. Frontend throughput can matter, but a 4-wide decoder is often enough.
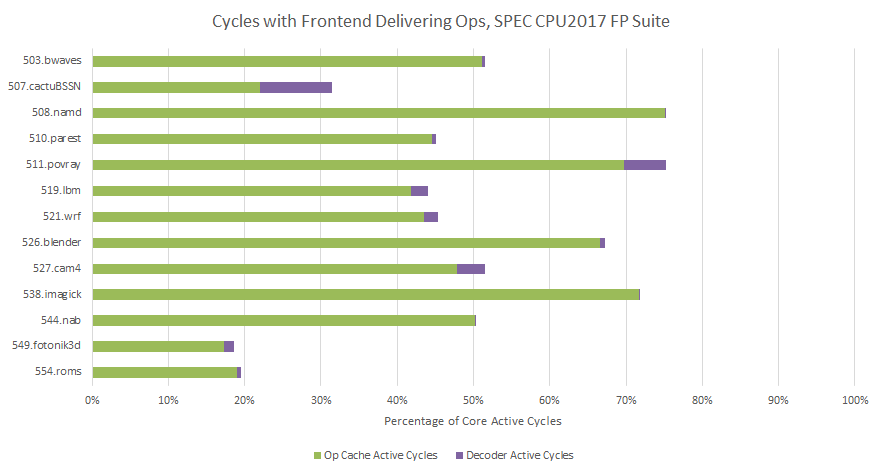
Turning off the op cache increases pressure on the decoders. For 508.namd, that turns a previously busy frontend into one struggling to catch its breath. Elsewhere, like with 554.roms, the decoders get to have their fun and still have time left over for a coffee break.

From this initial look at SPEC CPU2017 data, Zen 4’s op cache primarily benefits high IPC workloads. It’s particularly important for workloads that make inefficient use of frontend bandwidth, like ones with a lot of branches. Low IPC workloads see less or even no impact, even though cutting a core from 6-wide to 4-wide feels bad on paper.
Effect on SMT Performance
Running two SMT threads gives the core extra parallelism, because instructions in different threads are almost always independent. That extra parallelism tends to increase core IPC, as core throughput starts to take a front and center role. From before, Zen 4’s op cache is more important for higher IPC workloads. Increasing core IPC with SMT thus makes the op cache more important.

Here, I’m testing by running SPEC CPU2017’s rate test with two copies, both pinned to the same physical core. Comparing SMT scores with and without the op cache shows a generally harsher impact. 548.exchange2 now sees a 35.04% performance loss, up from 32% with a single thread. I suspect the only reason it doesn’t lose more is because 548.exchange2 was already heavily utilizing the core in 1T mode, and had lower than average (~11%) gains even with the op cache on.
525.x264 previously saw a substantial but not terrible 13.81% performance loss with with the op cache turned off in 1T mode. Turning off op cache in two threads active leads to a 19.9% performance decrease, which is much worse.

Performance monitoring data shows increased pressure on the decoder in SMT mode across all integer workloads. In 525.x264, that extra parallelism from two threads push the very busy decoder to its limits, leading to a larger performance loss.

SPEC CPU2017’s floating point suite saw a minor impact from disabling the op cache in single threaded mode. Running two threads however turns a lot of medium-high IPC workloads into high IPC ones. 519.lbm was unaffected by losing the op cache in 1T mode. But in 2T mode, it’s able to push to 3.28 IPC. That puts more pressure on the frontend, and means it can no longer be comfortably fed from a 4-wide decoder. Therefore, 519.lbm sees a 10% performance hit in SMT mode from disabling the op cache.

As with the integer tests, running two threads in a core fed only by the 4-wide decoder results in, well, a very busy decoder. lbm might be an outlier case too, because it posts more than a 30% throughput gain with SMT and the op cache on.

In general, the op cache is even more important for SMT performance than it is for single threaded performance. The higher per-core IPC enabled by SMT can hide some of the backend memory access latency that usually limits performance. That in turn places more pressure on the frontend to keep the backend fed. Weakening the frontend by disabling the op cache therefore causes a larger performance hit in SMT mode.
Cyberpunk 2077
Here, I’m running Cyberpunk 2077’s built-in benchmark with the op cache enabled and disabled. Unlike the SPEC CPU2017 runs earlier, I’m running my 7950X3D with Core Performance Boost off. That caps core clocks to 4.2 GHz, improving consistency. I also capped my RX 6900 XT to 2 GHz.

Turning off the op cache dropped performance by less than 1 FPS, which is also a less than 1% performance decrease. Unlike some of SPEC CPU2017’s workloads, Cyberpunk 2077 doesn’t care if it’s running on a 6-wide or 4-wide core.

Performance counter data shows Cyberpunk 2077 isn’t a high IPC workload.
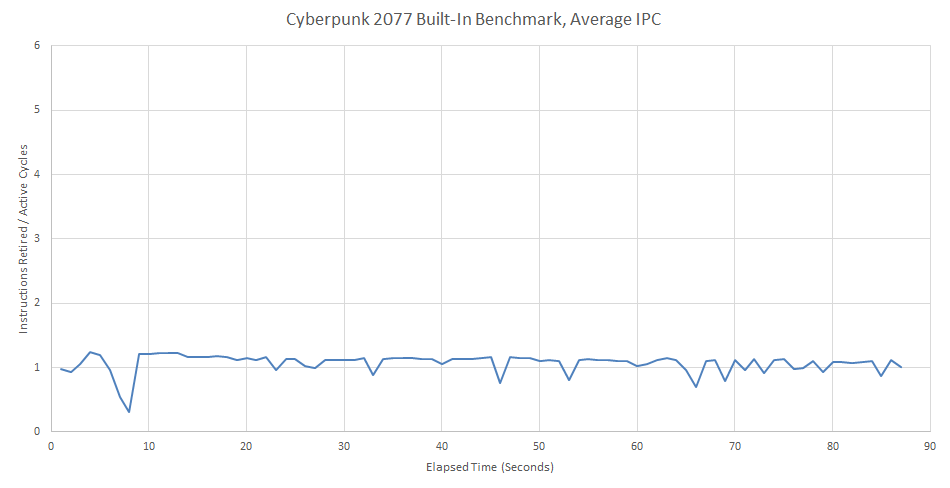
Like many of SPEC CPU2017’s tests, Zen 4 mostly feeds itself from the op cache in Cyberpunk 2077. But forcing all that load into the decoders isn’t a big deal. There’s a lot of action in the game, but it’s not at the frontend. Even a 4-wide decoder has plenty of spare juice on tap when running this game.

Final Words
Micro-op caching is a key part of the frontend strategy across a wide range of modern CPUs. But recent Zen generations like Zen 4 and Zen 5 have larger op caches than competing CPUs. At the same time, their conventional fetch and decode path has seen less investment. Intuitively, turning off the op cache should cripple Zen 4’s performance. After all, the op cache is so large that the core mostly feeds itself from the op cache, and the decoders rarely get in on the fun.
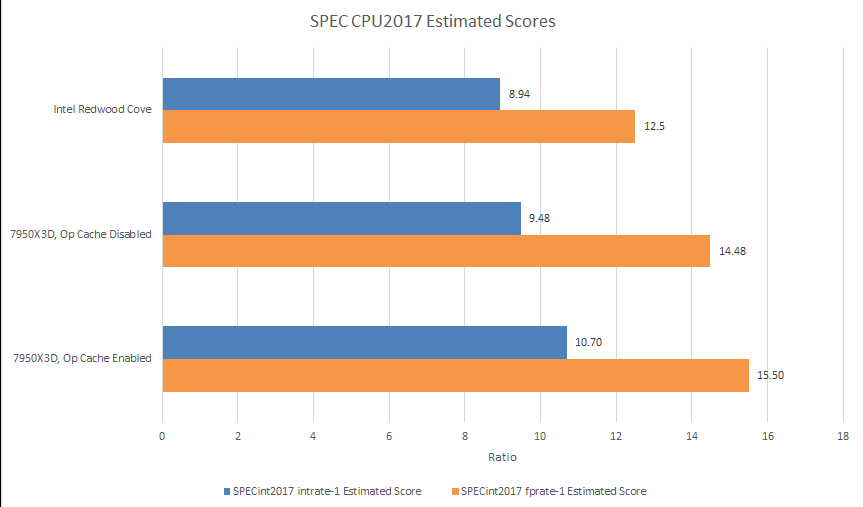
Zen 4 of course takes a performance loss with the op cache off, but even so it’s a very high performing core. It’s a good reminder that frontend throughput and core width is only one part of a high performance CPU design. Workloads that stress those aspects, like high IPC code that fits within L1 caches, certainly take a hit from losing frontend bandwidth. But performance is often limited by other factors like backend memory latency. Thus even without its op cache, Zen 4 can continue to outperform a recent mobile core like Redwood Cove in the Core Ultra 7 155H.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
It would be interesting to add power figures - a major selling point for opcache is that it allows to power down the decoders and fetch and save a lot of energy.
So even though the FP workloads dont benefit from opcache directly, they may benefit greatly from the decteased power consumption of front end.
Can you do similar tests on newer Intel CPUs? Do they let you disable the opcache?
Also, it would be fascinating to do this sort of thing across a wide collection of cpu generations. Going back as far as possible :D