
Raytracing on Intel’s Arc B580

Edit: The article originally said Intel’s BVH nodes were 4-wide, based on a misreading of QuadLeaf. After inspecting Intel compiler code, QuadLeaf actually means two merged triangles with a shared side (a quadrilateral, not a quad of four triangles).
Intel’s discrete GPU strategy has emphasized add-on features ever since Alchemist launched. Right from the start, Intel invested heavily in dedicated matrix multiplication units, raytracing accelerators, and hardware video codecs. Battlemage continues that trend. Raytracing deserves attention because raytraced effects are gaining prominence on an increasing number of titles.

Here, I’ll be looking at a Cyberpunk 2077 frame rendered on Intel’s Arc B580, with path tracing enabled. As always, I’m focusing on how the architecture handles the workload, rather than absolute performance. Mainstream tech outlets already do an excellent job discussing final performance.
Definitely check out the prior article on Meteor Lake’s raytracing implementation, because Intel uses the same raytracing strategy and data structures on Battlemage. Also be sure to check the Battlemage article, which covers the B580’s architecture and some of Intel’s terminology.
Cyberpunk 2077 Path Tracing, Lighting Shader?
I captured a Cyberpunk 2077 frame at 1080P with no upscaling. Framerate was a bit low at 12 FPS. An occupancy timeline from Intel’s Graphics Performance Analyzer (GPA) shows raytracing calls dominating frame time, though CP2077 surprisingly still spends some time on small rasterization calls.

I’m going to focus on the longest duration RT call, which appears to handle some lighting effects. Output from that DispatchRays call shows a very noisy representation of the scene. It’s similar to what you’d get if you stopped a Blender render at an extremely low sample count. Large objects are recognizable, but smaller ones are barely visible.

Raytracing Accelerator
Battlemage’s raytracing accelerator (RTA) plays a central role in Intel’s efforts to improve raytracing performance. The RTA receives messages from XVEs to start ray traversal. It then handles traversal without further intervention from the ray generation shader, which terminates shortly after talking to the RTA. BVH data formats are closely tied to the hardware implementation. Intel continues to use the same box and triangle node formats as the previous generation. Both box and triangle nodes continue to be 64B in size, and thus neatly fit into a cacheline.

Compared to Alchemist and Meteor Lake, Battlemage’s RTA increases traversal pipeline count from 2 to 3. That brings box test rate up to three nodes per cycle, or 18 box tests. Triangle intersection test rate doubles as well. More RTA throughput could put more pressure on the memory subsystem, so the RTA’s BVH cache doubles in capacity from 8 KB to 16 KB.

During the path tracing DispatchRays call, the B580 processed 467.9M rays per second, or 23.4M rays/sec per Xe Core. Each ray required an average of 39.5 traversal steps. RTAs across the GPU handled just over 16 billion BVH nodes per second, which mostly lines up with traversal step count. Intel uses a short stack traversal algorithm with a restart trail. That reduces stack size compared to a simple depth first search, letting Intel keep the stack in low latency registers. However, it can require restarting traversal from the top using a restart trail. Doing so would mean some upper level BVH nodes get visited more than once by the same ray. That means more pointer chasing accesses, though it looks like the RTA can avoid repeating intersection tests on previously accessed nodes.

GPA’s RT_QUAD_TEST_RAY_COUNT and RT_QUAD_LEAF_RAY_COUNT metrics suggest 1.55% and 1.04% utilization figures for the ray-box and ray-triangle units, respectively. Intel isn’t bound by ray-triangle or ray-box throughput. Even if every node required intersection testing, utilization on the ray-box or ray-triangle units would be below 10%. Battlemage would likely be fine with the two ray-box and single triangle unit from before. I suspect Intel found that duplicating the the traversal pipeline was an easy way to let the RTA keep more work in flight, improving latency hiding.
“Percentage of time in which Ray Tracing Frontend is stalled by Traversal”
Description of the
RT_TRAVERSAL_STALLmetric in GPA
Intel never documented what they mean by the Ray Tracing Frontend. Perhaps the RTA consists of a frontend that accepts messages from the XVEs, and a traversal backend that goes through the BVH. A stall at the frontend may mean it has received messages from the XVEs, but none of the traversal pipelines in the backend can accept more work. Adding an extra traversal pipeline could be an easy way to process more rays in parallel. And the extra pipeline of course comes with its own ray-box units. Of course, there could be other workloads that benefit from higher intersection test throughput. Intel added an extra triangle test unit, and those aren’t part of the traversal pipelines.
BVH Caching
BVH traversal is latency sensitive. Intel’s short stack algorithm requires more pointer chasing steps than a simple depth first search, making it even more sensitive to memory latency. But it also creates room for optimization via caching. Using the restart trail involves re-visiting nodes that have been accessed not long ago. A cache can exploit that kind of temporal locality, which is likely why Intel gave the RTA a BVH cache. The Xe Core already has a L1 data cache, but that has to be accessed over the Xe Core’s message fabric. A small cache tightly coupled to the RTA is easier to optimize for latency.

Battlemage’s 16 KB BVH cache performs much better than the 8 KB one on prior generations. Besides reducing latency, the BVH cache also reduces pressure on L1 cache. Accessing 16.03G BVH nodes per second requires ~1.03 TB/s of bandwidth. Battlemage’s L1 can handle that easily. But minimizing data movement can reduce power draw. BVH traversal should also run concurrently with miss/hit shaders on the XVEs, and reducing contention between those L1 cache clients is a good thing.
Dispatching Shaders
Hit/miss shader programs provided by the game handle traversal hit/miss results. The RTA launches these shader programs by sending messages back to the Xe Core’s thread dispatcher, which allocates them to XVEs as thread slots become available. The thread dispatcher has two queues for non-pixel shader work, along with a pixel shader work queue. Raytracing work only uses one of the non-pixel shader queues (queue0).
81.95% of the time, queue0 had threads queued up. It spent 79.6% of the time stalled waiting to for free thread slots on the XVEs. That suggests the RTAs are generating traversal results faster than the shader array can handle the results.

Most of the raytracing related thread launches are any hit or closest hit shaders. Miss shaders are called less often. In total, RTAs across the Arc B580 launched just over a billion threads per second. Even though Intel’s raytracing method launches a lot of shader programs, much of that is contained within the Xe Cores and doesn’t bother higher level scheduling hardware. Just as with Meteor Lake, Intel’s hierarchical scheduling setup is key to making its RTAs work well.
Vector Execution
A GPU’s regular shader units run the hit/miss shader programs that handle raytracing results. During the DispatchRays call, the B580’s XVEs have almost all of their thread slots active. If you could see XVE thread slots as logical cores in Task Manager (1280 of them), you’d see 93.8% utilization. Judging from ALU0 utilization breakdowns, most of the work comes from any hit and closest hit shaders. Miss shader invocations aren’t rare, but perhaps the miss shaders don’t do a lot of work.
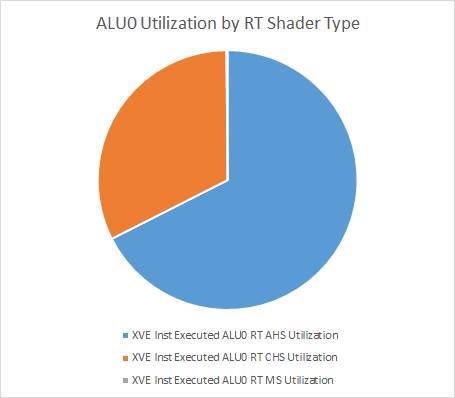
Just as high utilization in Task Manager doesn’t show how fast your CPU cores are doing work under the hood, high occupancy doesn’t imply high execution unit utilization. More threads simply give the GPU more thread-level parallelism to hide latency with, just like loading more SMT threads on CPU cores. In this workload, even high occupancy isn’t enough to achieve good hardware utilization. Execution unit usage is low across the board, with the ALU0 and ALU1 math pipelines busy less than 20% of the time.

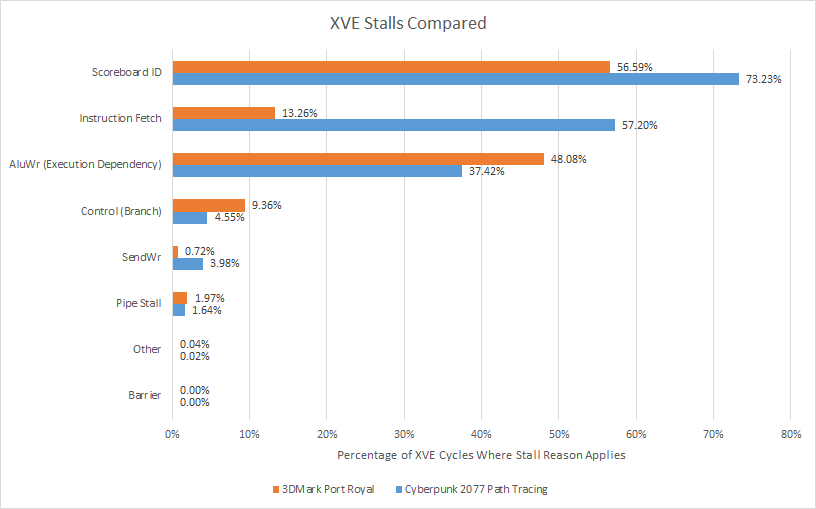
Intel can break down thread stall reasons for cycles when the XVE wasn’t able to execute any instructions. Multiple threads can be stalled on different reasons during the same cycle, so counts will add up to over 100%. A brief look shows memory latency is a significant factor, as scoreboard ID stalls top the chart even without adding in SendWr stalls. Modern CPUs and GPUs usually spend a lot of time with execution units idle, waiting for data from memory. But Cyberpunk 2077’s path tracing shaders appear a bit more difficult than usual.

Execution latency hurts too, suggesting Cyberpunk 2077’s raytracing shaders don’t have a lot of instruction level parallelism. If the compiler can’t place enough independent instructions between dependent ones, threads will stall. GPUs can often hide execution latency by switching between threads, and the XVEs in this workload do have plenty of thread-level parallelism to work with. But it’s not enough, so there’s probably a lot of long latency instructions and long dependency chains.
Finally, threads often stall on instruction fetch. The instruction cache only has a 92.7% hitrate, so some shader programs are taking L1i misses. Instruction cache bandwidth may be a problem too. Each Xe Core’s instruction cache handled 1.11 hits per cycle if I did my math right, so the instruction cache sometimes has to handle more than one access per cycle. If each access is for a 64B cacheline, each Xe Core consumes over 200 GB/s of instruction bandwidth. Intel’s Xe Core design does seem to demand a lot of instruction bandwidth. Each Xe Core has eight XVEs, each of which can issue multiple instructions per cycle. Feeding both ALU0 and ALU1 would require 2 IPC, or 16 IPC across the Xe Core. For comparison, AMD’s RDNA 2 only needs 4 IPC from the instruction cache to feed its vector execution units.
Instruction Mix
Executed shader code usually uses 32-bit datatypes, with some 16-bit types playing a minor role. INT64 instructions also make an appearance, perhaps for address calculation. Special function units (math) see heavy usage, and may contribute to AluWr stalls above.

The close mix of INT32 and FP32 instructions plays well into the XVE’s pipeline layout, because those instruction types are executed on different ports. However, performance is bound by factors other than execution unit throughput and pipe layout.
Cache and Memory Access
Caches within Battlemage’s Xe Core struggle to contain this path tracing workload’s memory accesses. Despite increasing L1 cache capacity from 192 to 256 KB, Battlemage’s L1 hitrate still sits below 60%. Intel services texture accesses with a separate cache that appears to have 32 KB of capacity from a latency test. Texture cache hitrate is lackluster at under 30%.

A lot of accesses fall through to L2, and the Arc B580’s 18 MB L2 ends up handling over 1 TB/s of traffic. L2 hitrate is good at over 90%, so 18 MB of L2 capacity is adequate for this workload. The Arc B580’s 192-bit GDDR6 setup can provide 456 GB/s of bandwidth, and this workload used 334.27 GB/s on average. GPA indicates the memory request queue was full less than 1% of the time, so the B580’s GDDR6 subsystem did well on the bandwidth front. Curiously, L2 miss counts suggest 122.91 GB/s of L2 miss bandwidth. Something is consuming VRAM bandwidth without going through L2.
A Brief Look at Port Royal
3DMark’s Port Royal benchmark uses raytraced reflections and shadows. It still renders most of the scene using rasterization, instead of the other way around like Cyberpunk 2077’s path tracing mode. That makes Port Royal a better representation of a raytracing workload that’s practical to run on midrange cards. I’m looking at a DispatchRays call that appears to handle reflections.

Rays in Port Royal take more traversal steps. Higher BVH cache hitrate helps keep traversal fast, so the RTAs are able to sustain a similar rays per second figure compared to Cyberpunk 2077. Still, Port Royal places more relative pressure on the RTAs. RT traversal stalls happen more often, suggesting the RTA is getting traversal work handed to it faster than it can generate results.

At the same time, the RTA generates less work for the shader array when traversal finishes. Port Royal only has miss and closest hit shaders, so a ray won’t launch several any-hit shaders as it passes through transparent objects. Cyberpunk 2077’s path tracing mode also launches any-hit shaders, allowing more complex effects but also creating more work. In Port Royal, the Xe Core thread dispatchers rarely have work queued up waiting for free XVE thread slots. From the XVE side, occupancy is lower too. Together, those metrics suggest the B580’s shader array is also consuming traversal results faster than the RTAs generate them.
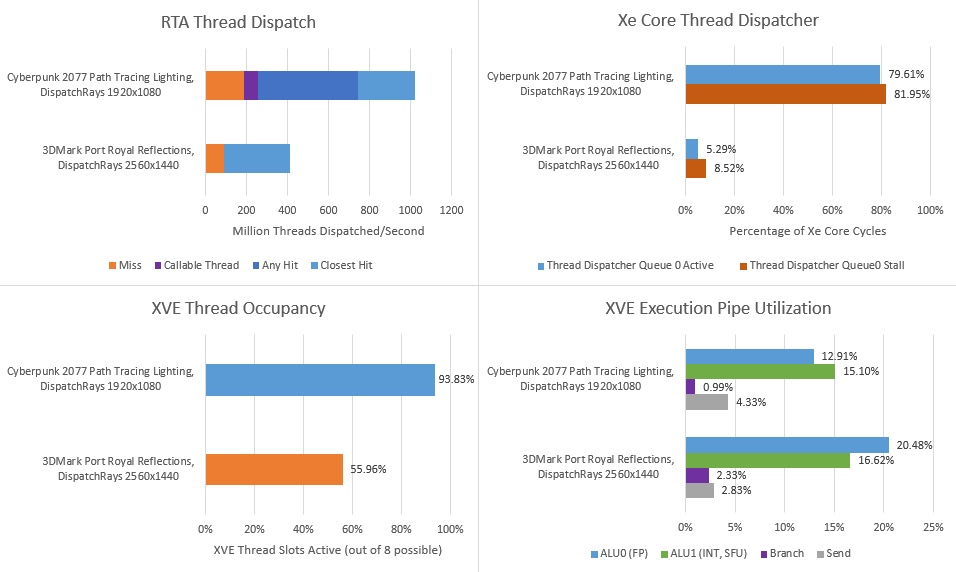
Just as a very cache friendly workload can achieve higher IPC with a single thread than two SMT threads together on a workload with a lot of cache misses, Port Royal enjoys better execution unit utilization despite having fewer active threads on average. Instruction fetch stalls are mostly gone. Memory latency is always an issue, but it’s not quite as severe. That shifts some stalls to execution latency, but that’s a good thing because math operations usually have lower latency than memory accesses.
Much of this comes down to Port Royal being more cache friendly. The B580’s L1 caches are able to contain more memory accesses, resulting in lower L2 and VRAM traffic.

Final Words
Intel’s Battlemage architecture is stronger than its predecessor at raytracing, thanks to beefed up RTAs with more throughput and better caching. Raytracing involves much more than BVH traversal, so Intel’s improved shader array also provides raytracing benefits. That especially applies to Cyberpunk 2077’s path tracing mode, which seeks to do more than simple reflections and shadows, creating a lot of pressure on the shader array. Port Royal’s limited raytracing effects present a different challenge. Simple effects mean less work on the XVEs, shifting focus to the RTAs.
Raytracing workloads are diverse, and engineers have to allocate their transistor budget between fixed function BVH traversal hardware and regular vector execution units. It reminds me of DirectX 9 GPUs striking a balance between vertex and pixel shader core counts. More vertex shaders help with complex geometry. More pixel shaders help with higher resolutions. Similarly, BVH traversal hardware deals with geometry. Hit/miss shaders affect on-screen pixel colors, though they operate on a sample basis rather than directly calculating colors for specified pixel coordinates.

Rasterization and raytracing both place heavy demands on the memory subsystem, which continues to limit performance. Intel has therefore improved their caches to keep the improved RTAs and XVEs fed. The 16 KB BVH cache and bigger general purpose L1 cache have a field day in Port Royal. They have less fun with Cyberpunk 2077 path tracing. Perhaps Intel could make the Xe Core’s caches even bigger. But as with everything that goes on a chip, engineers have to make compromises with their limited transistor budget.

Cyberpunk 2077’s path tracing mode is a cool showcase, but it’s not usable on a midrange card like the B580 anyway. Well, not at least without a heavy dose of upscaling and perhaps frame generation. The B580’s caches do better on a simpler workload like Port Royal. Maybe Intel tuned Battlemage’s caches with such workloads in mind. It’s a good tradeoff considering Cyberpunk 2077’s path tracing mode challenges even high end GPUs.
Much like Intel’s strategy of targeting the GPU market’s sweet spot, perhaps Battlemage’s raytracing implementation targets the sweet spot of raytracing-enabled games, which use a few raytraced effects help enhance a mostly rasterized scene. Going forward, Intel plans to keep advancing their raytracing implementation. Xe3 adds sub-triangle opacity culling with associated new data structures. While Intel compiler code only references Panther Lake (Xe3 LPG) for now, I look forward to seeing what Intel does next with raytracing on discrete GPUs.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
Agree with Simon, very helpful analysis! I found your interpretation of the B580 limiting its efforts for Path Tracing in very challenging cases like Cyberpunk to make a lot of sense. Even a 4090 is taxed significantly by CP2077 with everything turned up to the highest settings, and you explained well how Path Tracing costs a lot of bandwidth and compute that is then missing elsewhere. Boils down to the graphics (drivers) team choosing wisely which battles to fight. 11 FPS just don't look good 😄.
Would be interesting to know how, for example, Nvidia's drivers deal with those choices across GPUs with very different capabilities. And, if someone from Nvidia reads this: Send Chester a 5090, so he can treat us to a great deep dive on Blackwell !
And, AMD, how about doing likewise with the 9070XT? RDNA4 sounds mighty good, maybe even better after a deep dive into it by Chester!
Great article as always. Man, if only there were a big battlemage chip