
Pushing AMD’s Infinity Fabric to its Limits

I recently wrote code to test memory latency under load, seeking to reproduce data in various presentations with bandwidth on the X axis and latency on the Y axis. Ampere pretty much described how that was done during their Hot Chips 2024 presentation. To achieve the same results in a semi-automated fashion, I run a latency test thread while also running a variable number of threads that generate bandwidth load.
We run a single latency sensitive application and gradually add bandwidth hungry applications.
Matthew Erler, during the AmpereOne presentation at Hot Chips 2024
Getting good data from the test required more care than I anticipated. Some AMD chips were particularly sensitive to thread placement. Certain core affinity choices would result in dramatic latency spikes, while others showed latency being very well controlled even with similar or higher achieved bandwidth. I worked around this issue when I wrote the Broadwell article. But now, it’s time for a more detailed dig into AMD’s system topology and the various bottlenecks it may present.

AMD chips since Zen have used multiple levels of interconnects to create a modular system, letting AMD hit high core counts quickly and cheaply. Several Zen cores share a L3 cache within a cluster, called a Core Complex (CCX). CCX-es access the rest of the system through AMD’s Infinity Fabric, a flexible interconnect that lets AMD adapt system topology to their needs. Since Zen 2, that meant putting CPU cores on Core Complex Dies (CCDs). CCDs connect to a separate IO die, which talks to system memory and slower components like PCIe, SATA, and USB. That creates a hub and spoke model, and let AMD push core counts higher than Intel.

CCDs connect to the IO die using an Infinity Fabric On-Package (IFOP) interface. A CCD’s IFOP link provides 32 bytes per cycle of read bandwidth and 16 bytes per cycle of write bandwidth, at the Infinity Fabric clock (FCLK). FCLK is typically far lower than L3 and core clocks. In later Zen systems with faster DDR5, one IFOP may not have enough bandwidth to saturate DDR5 bandwidth. Past that potential bandwidth limit, DDR memory has not been able to provide enough bandwidth to handle what all cores can demand in a high core count system.
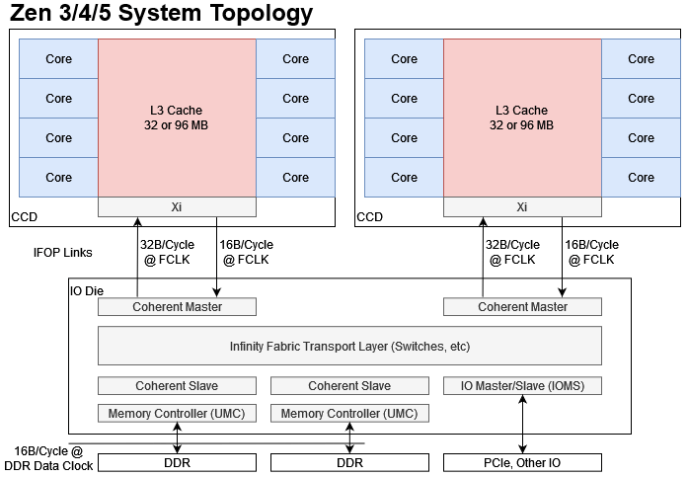
Of course, there can be other points of contention too. On Zen 2, multiple CCX-es can contend for one IFOP interface. Here, I’ll look at how pushing bandwidth limits at multiple points affects a latency sensitive thread contending for the same shared resource. Instead of presenting data with latency on one axis and bandwidth on another, I’m going to plot latency and bandwidth as two separate series to show how latency is affected by core count.
Zen 4: AMD Ryzen 9 7950X3D
Zen 4 is AMD’s outgoing CPU generation, and makes for a convenient testing platform because it’s my daily driver desktop. As a recent member of the Zen line, it has one octa-core CCX per CCD. A single Zen 4 core can read from a 3 GB array at about 50 GB/s, so it can guzzle an incredible amount of memory bandwidth compared to prior Zen generations. That should make any bottlenecks easy to see. I’m using a typical DDR5 configuration with moderately spec-ed DDR5-5600.

Under minimal load, my system has 82-83 ns of DRAM latency. A latency test thread quickly sees worse latency as bandwidth demand from other cores starts filling up queues throughout the memory subsystem. Just a couple bandwidth test threads are enough to push the CCD’s memory subsystem to its limits.
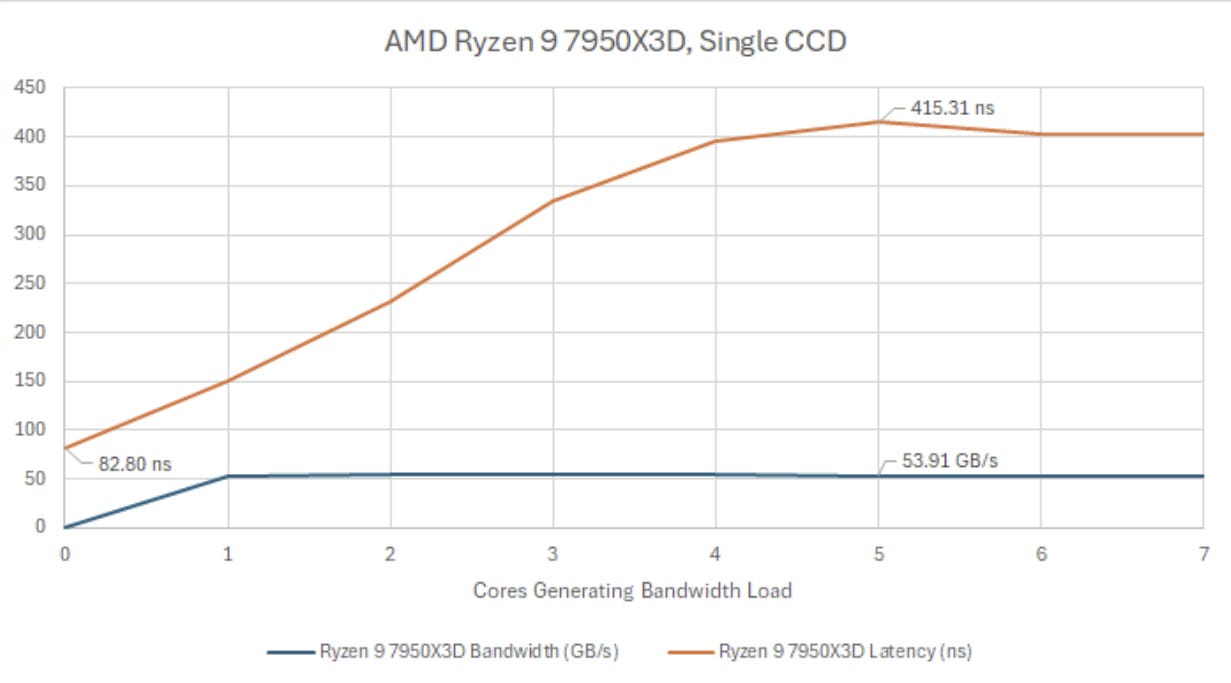
Increasing thread count makes latency skyrocket, probably as more cores cause more contention for queue capacity. Latency shoots past 400 ns when fighting with five bandwidth threads.
Shoving the bandwidth load to the other CCD dramatically improves latency. I see a weird latency spike when CCD0 has one core demanding bandwidth, and CCD1 is running the latency test. Loading more cores on CCD0 curiously brings latency down, even as achieved bandwidth inches up. I wonder if AMD is detecting active core count, and starts reserving queue entries or otherwise throttles per-core bandwidth consumption if enough cores require high bandwidth.

Bandwidth improves alongside latency. In fact, the CCD running eight bandwidth test threads achieves nearly 64 GB/s. AMD seems to get excellent bandwidth efficiency out of the IFOP interface when the bandwidth test threads aren’t fighting with the latency thread. Taken together, those two observations suggest AMD’s dual CCD setup can act as a QoS mechanism of sorts. Containing bandwidth hungry code within one CCD can let latency sensitive code on the other CCD to proceed with minimal impact.
To test the whole system, I switched up core loading order to alternate between CCDs when adding bandwidth test threads. That lets me use both IFOP links, hopefully maximizing memory bandwidth. Achieved bandwidth of course is higher, and latency remains well under control with a couple of bandwidth test threads in play. I also achieve maximum bandwidth with one bandwidth test thread running on each CCD.

But the situation rapidly gets out of control as I spawn more bandwidth test threads. We’re probably looking at contention at both the CCD and memory controller level. Latency delays at both layers seems to be additive, and the latency test thread really gets the worst of it when it has to fight with more than 10 bandwidth hungry threads.

At this point, the system also started behaving strangely. For example, bringing up the “Details” tab in Task manager took an agonizingly long time, even though my test only loaded up one thread per physical core. Thankfully, I think it’s a rather extreme and non-typical workload.
Hardware Performance Monitoring
Observing latency from software is simple, but I can get more information by asking the hardware what’s going on. Zen 4’s L3 cache has performance monitoring facilities. One of its capabilities is randomly sampling L3 misses and tracking their latency.

While this performance monitoring event provides an idea of average latency just as my C and assembly code does, they don’t measure exactly the same thing. Software can only observe load-to-use latency. That includes latency all the way from address generation within the core to getting the data from somewhere in the memory hierarchy. AMD uses the mnemonic “XiSampledLatency” to describe their event. “Xi” is a component in Zen’s L3 cache complex that interfaces with the rest of the system. Likely, it stands for “eXternal Interface”. It probably has a set of queues to track outstanding requests. Sampling latency would be as simple as noting how long a queue entry remained allocated.
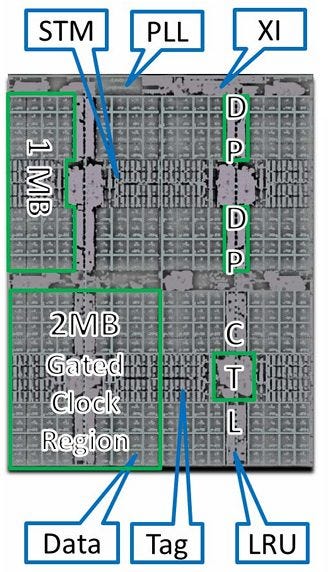
Because this event is likely implemented in the Xi, it only measures latency after a L3 miss. DRAM latency as seen from software will include latency introduced at many other layers. That includes address generation, and checking each cache layer before a L3 miss is discovered.

Therefore, latency seen by the Xi should be lower than latency seen by software. Still, this event is useful for seeing how the memory subsystem behaves after a L3 miss. Data from the Xi roughly correlates with software observations at the start of my full system bandwidth test, when CC1 runs a latency test and CCD0 runs a single thread generating bandwidth load. Software sees 190 ns of latency, while L3 performance monitoring on CCD1 sees 166 ns.
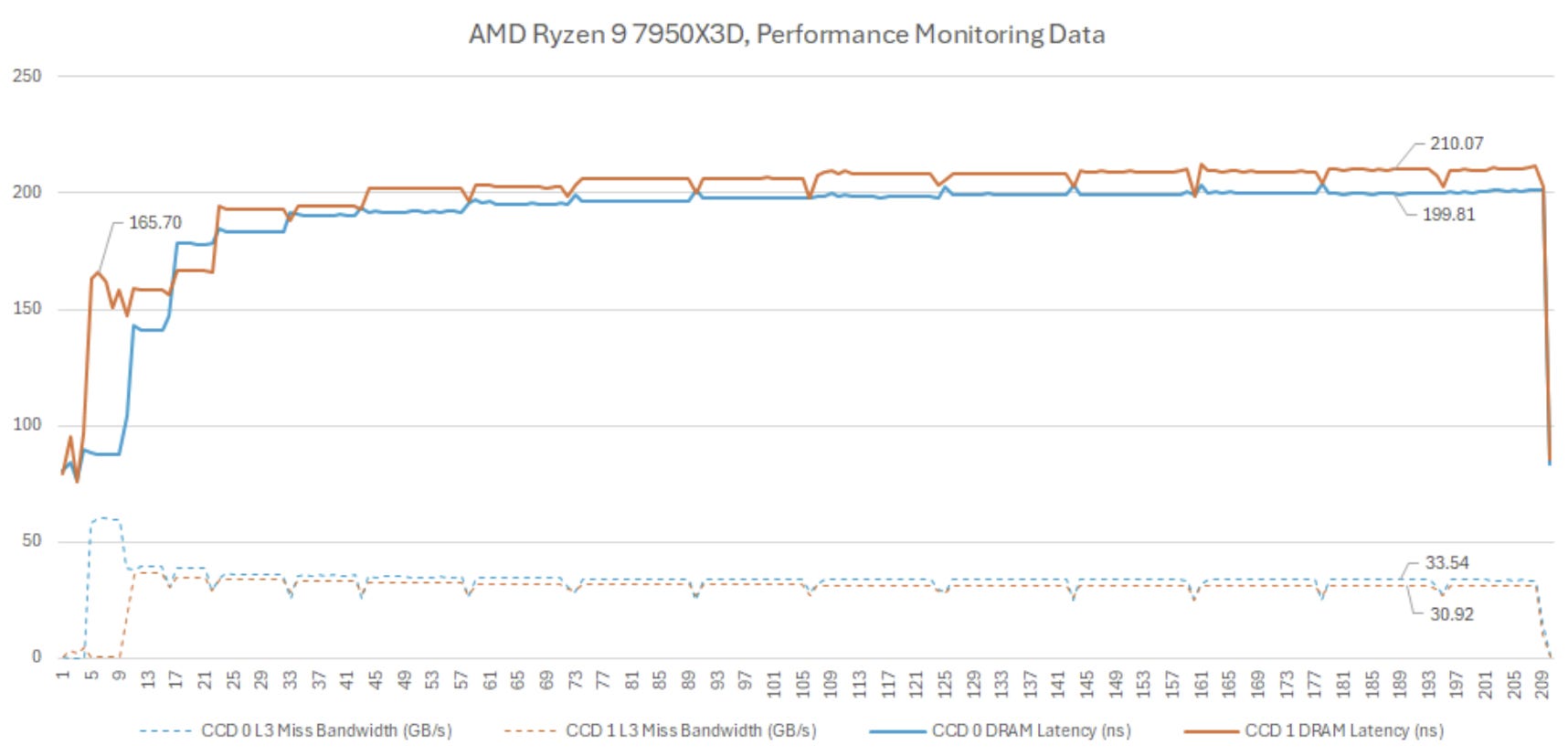
Interestingly, performance monitoring data from the other CCD suggests Zen 4 prioritized the bandwidth hungry thread at the expense of the latency sensitive one. As a sanity check, L3 miss bandwidth from the CCD hosting the bandwidth test thread is 59 GB/s, almost exactly matching what I calculated from software.
Once I spawn more bandwidth test threads, performance monitoring data suggests average latency rises to around 200 ns. However, software observations from the latency test thread sees latency go beyond 700 ns. Requests from the latency test thread account for a small minority of traffic passing through the memory subsystem, so it makes sense that the average latency as seen by the Xi doesn’t reflect my measurements.
Zen 5 with Fast DDR5
Zen 5 is the latest and greatest member of AMD’s Zen line. It uses the same IO die as Zen 4, but the CCDs have changed. Cheese (George) has set the system up with very fast DDR5, and is running Infinity Fabric at a slightly higher clock to boot.

I wouldn’t call this a typical setup. DDR5-8000 kits are expensive. AMD’s reviewer guide recommends 6000 MT/s as a sweet spot. Yet this configuration provides a look into how Infinity Fabric performs with a ton of memory bandwidth available. I shouldn’t come anywhere close to DRAM bandwidth limits from within a single CCD. And indeed, latency is much better as I push to the IFOP’s bandwidth limits. Latency also starts off lower under high load, probably thanks to the very fast DRAM configuration.

Contention within a single CCX still increases latency, but not to the same extent as with Zen 4. Zen 5 cores can also individually gobble down tons of bandwidth just like its predecessor. Perhaps CCX-level changes play a role. At Hot Chips 2024, AMD showed a slide suggesting each Zen 5 CCX has a pair of XIs. The two XIs together likely have more queue entries available than on Zen 4, which the slide also hints at.

That probably decreases the chance of bandwidth hungry threads monopolizing all queue entries and starving out a latency sensitive one. Moreover, IFOP bandwidth covers just 55% of DDR5 bandwidth in this setup, compared to 71.4% on my Zen 4 system. Lower load on the memory controller gives it more room to manage DRAM inefficiencies like bus turnarounds, refreshes, or bank conflicts. I suspect Zen 5’s better behavior comes down to a combination of both factors.
As with Zen 4, CCD boundaries can insulate a latency sensitive thread from bandwidth hungry code. On this Zen 5 system. faster memory and faster Infinity Fabric clocks make everything better overall. More significantly, the latency spike observed on Zen 4 with one bandwidth thread is gone.
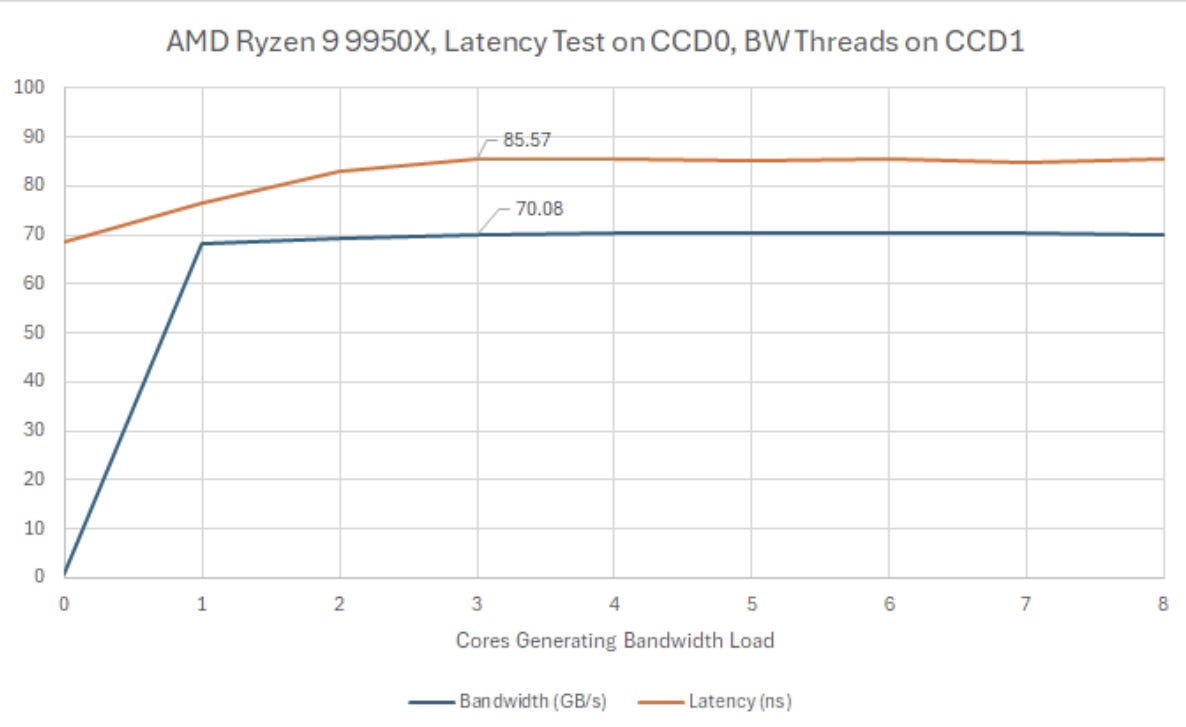
On Zen 4, that spike must have been caused by something within Infinity Fabric. After all, the latency and bandwidth test threads can’t fight for the same XI or IFOP if they’re on different CCDs. Even though Zen 5 uses the same IO die, AMD may have tweaked their traffic management policies to more fairly service cores with varying memory access patterns.
The Ryzen 9 9950X and its fast memory setup continues to impress as I load both CCDs. Even as memory bandwidth passes 100 GB/s, latency remains well under control. Those DDR5-8000 memory sticks appear to cost $250 for a 48 GB kit. For that much money, you better get top-notch performance.
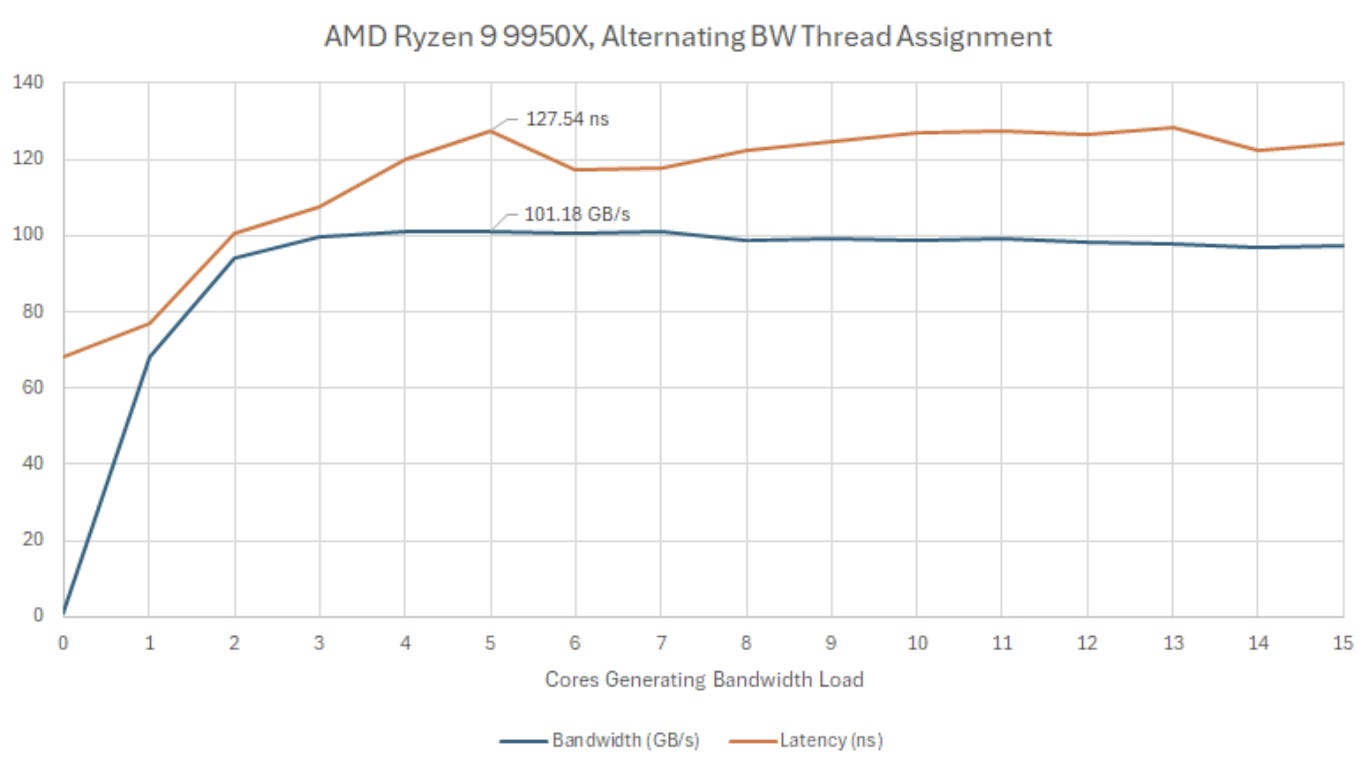
Again, I suspect AMD tweaked something to improve latency under load. Crazy 700 ns measurements from Zen 4 are gone. I’m not pushing as close to DDR5 bandwidth limits on Zen 4, but Zen 4’s performance monitoring data suggests latency shouldn’t have been too far above 200 ns.
Zen 2: Two Clusters Per CCD/IFOP
Zen 2 may be a bit dated, but it did debut AMD’s modern chiplet setup. More interestingly, it has two quad core CCX-es per CCD. That lets me look at CCX-level and CCD-level bottlenecks separately.
Unlike Zen 4 and Zen 5, I’m running Zen 2 with matched FCLK and DRAM speeds. Thus one CCD’s IFOP bandwidth matches DRAM bandwidth. Zen 2 achieves about 84.4% of theoretical DRAM bandwidth from a single CCX. That’s a larger percentage than Zen 4 (71.4%) or Zen 5 (55%). Of course both later generations achieve better absolute bandwidth.
Latency starts at 71.7 ns, and increases to 142.77 ns when three bandwidth hungry threads share the same CCX. But the latency test thread running on one CCX is reasonably well insulated from bandwidth load on another CCX, even if both CCX-es are on the same CCD. That leads me to think the CCX’s XI may be a more significant bottleneck than the IFOP link downstream.

Creating bandwidth demand across both CCX-es within a CCD drives latency up. That’s no surprise because there’s now contention at both the CCX’s XI, and at the IFOP. Still, Zen 2 doesn’t do too badly. 285 ns of latency isn’t great, but it’s better than Zen 4’s 400 ns from a single CCD. Zen 5 is better than both at ~151 ns for a comparable CCD-level contention test.
I suspect Zen 2 does better than Zen 4 because Zen 2 cores individually can’t consume as much bandwidth. DRAM latency is high, which means you need a lot of in-flight requests queued up to sustain high DRAM bandwidth. A Zen 2 core can only sustain enough in-flight requests to achieve 24-25 GB/s of DRAM bandwidth. That’s well short of Infinity Fabric or DRAM bandwidth limits, so the latency test thread has a good chance of finding free queue entries for its own requests.
Zen 2 can benefit from CCD-level isolation too, just like Zen 4 and Zen 5. Like Zen 5, Zen 2 doesn’t see a latency spike with a single bandwidth hungry thread. However, I doubt there’s any sophisticated traffic management going on here. Again, a single thread isn’t able to sustain enough L3 misses to monopolize downstream queues.

Stepping back, Zen 2’s DDR4 controller is doing an excellent job of scheduling memory requests under high load. Despite being pushed closer to its bandwidth limits, the Ryzen 9 3950X is able to keep latency under control. In the bandwidth on CCD1, latency tested from CCD0 scenario, the 3950X maintains better latency than the 7950X3D.

Loading both CCDs does increase latency, but it’s better than drawing all DRAM bandwidth through one CCD’s IFOP. Even though one IFOP interface has enough bandwidth to saturate the DDR4 controller, using both IFOP interfaces together provides better latency. That’s likely because I’m only pushing DDR4 bandwidth limits at this point, rather than pushing both DDR4 and a single IFOP to its limits.

Those observations suggest contention within a CCX is most problematic, though contention over an IFOP interface can slightly increase latency too.
Zen 2 also has a pair of XI performance monitoring events for tracking average L3 miss latency. However, Zen 2 does a more straightforward measurement in cycles, rather than randomly sampling requests. The PPR tells you to divide the latency event by request count to get latency in cycles. Basically, it’s telling you to solve Little’s Law. Working backwards, the latency event is incrementing with the XI’s queue occupancy per cycle.

Looking at the queue occupancy figure on its own shows average queue occupancy around 59-61, which is suspiciously close to 64. Unfortunately AMD’s L3 performance counters don’t support count masking, but the average figure could mean each CCX’s XI has 64 queue entries. If so, two CCX-es together would have 128 XI queue entries.

At Hot Chips 33, AMD presented a slide indicating the XI for Zen 3’s merged, octa-core CCX has 192 queue entries.
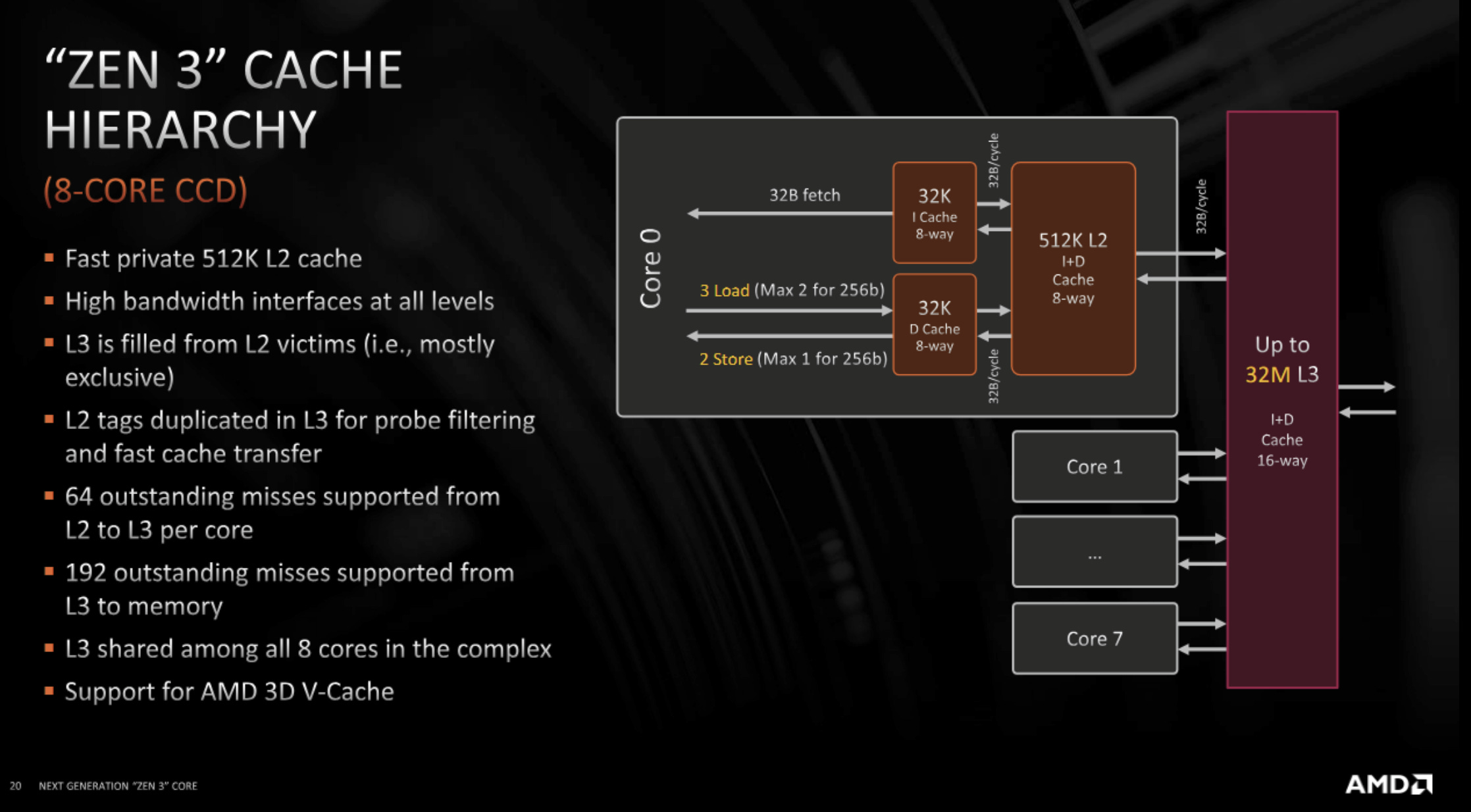
With Zen 5, AMD may have 320 XI queue entries per CCX, likely 160 entries in each of the CCD’s two XI blocks.
Unfortunately, I haven’t found any information on Zen 4’s XI queue capacity. Perhaps Zen 4 increased the number of queue entries, but not by enough to accommodate Zen 4’s massive jump in memory level parallelism capabilities.
Both the L2 and the L3 received larger miss queues to support more outstanding requests
Kai Troester, at AMD’s Hot Chips 2023 presentation on Zen 4
If so, that would explain some of the weird behavior I see on Zen 4. Queue entries of course aren’t free, and larger queues cost both area and power. AMD could have made a sensible tradeoff on Zen 4 if users rarely run into those limitations. AMD likely evaluated many programs and decided on a sensible tradeoff. I don’t have the time or resources to do what a full time employee can, but I can go through a few examples.
Latency and Bandwidth in Practice
Here, I’m running Cyberpunk 2077’s built-in benchmark at 1080P. I ran the benchmark twice with the game pinned to different CCDs, which should make performance monitoring data easier to interpret. On the non-VCache CCD, the game sees 10-15 GB/s of L3 miss traffic. It’s not a lot of bandwidth over a 1 second interval, but bandwidth usage may not be constant over that sampling interval. Short spikes in bandwidth demand may be smoothed out by queues throughout the memory subsystem, but longer spikes (still on the nanosecond scale) can fill those queues and increase access latency. Some of that may be happening in Cyberpunk 2077, as performance monitoring data indicates L3 miss latency is often above the 90 ns mark.
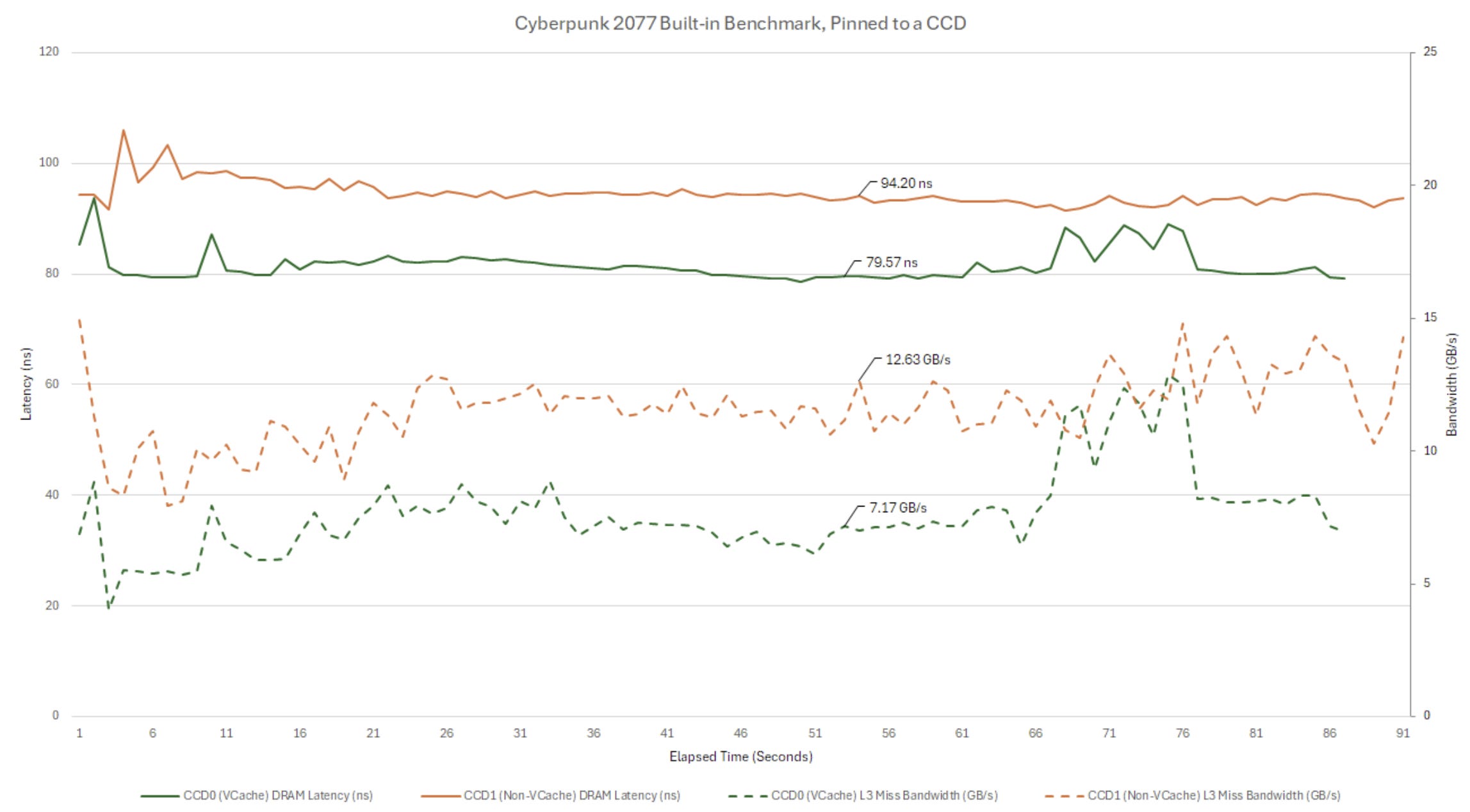
Pinning Cyberpunk 2077 to the VCache die significantly reduces L3 miss traffic, showing the value of having three times as much L3 capacity on hand. L3 misses are serviced with lower latency too. Less memory traffic reduces queuing delays, throughout the memory subsystem. Thus VCache has a secondary benefit of reducing average DRAM latency. It’s a potent combination, and one that’s reflected by the benchmark’s output. Cyberpunk 2077’s benchmark averaged 122.34 FPS when pinned to the non-VCache die, and 153.98 FPS when pinned to the VCache die. Despite clocking lower, the VCache die delivered 25.8% better performance.
Stepping back, neither scenario sees the game push against bandwidth limits anywhere in the memory subsystem. Latency in both cases is well under control, and baseline latency has more of an impact on performance than latency incurred from approaching bandwidth limits.
GHPC is a tank game, and presents another example. Patterns are similar, though with lower bandwidth demands. Again VCache shows its worth by servicing more memory requests on-die. And again, reducing load on the memory subsystem past L3 reduces average L3 miss latency.

Baldur’s Gate 3 is a role playing game where you can roll dice and throw things. Bandwidth demands vary wildly from second to second, but sampled memory latency remains well under control. We don’t get anywhere close to the 200 ns that would suggest a bandwidth bottleneck.
Again, Zen 4’s memory subsystem isn’t under significant pressure. VCache continues to do an excellent job, bringing L3 hitrate from 31.65% to 79.46%. But even without VCache, there’s plenty of spare Infinity Fabric and DDR5 bandwidth to go around.
RawTherapee is a free and open source raw file conversion program. Enthusiast cameras can record raw 12 or 14-bit sensor data instead of processed JPEGs. Raw files give photographers much more editing headroom to make exposure and white balance adjustments. They also let the editor make conscious tradeoffs between preserving detail and reducing noise. However, image processing can be computationally intensive. Here, I’m converting a few 45.7 megapixel D850 raw files to JPEGs, with exposure and noise reduction applied.
I didn’t pin RawTherapee to a CCD because image processing is a parallel task that benefits from high core counts (unlike most games). Instead, I’m logging data for both CCDs simultaneously. RawTherapee has spiky bandwidth demand – enough to fill queues, but often not long enough to run for longer than my 1 second sampling interval.

That’s where the sampled latency figure gives valuable insight. Latency spikes to over 200 ns, indicating the memory subsystem is pushed to its limits.
Not all multithreaded programs stress the memory subsystem though. I played Baldur’s Gate 3 while running video encoding jobs in the background. L3 miss traffic is significant but not overwhelming. Latency remained under control, and the game held 60 FPS most of the time.
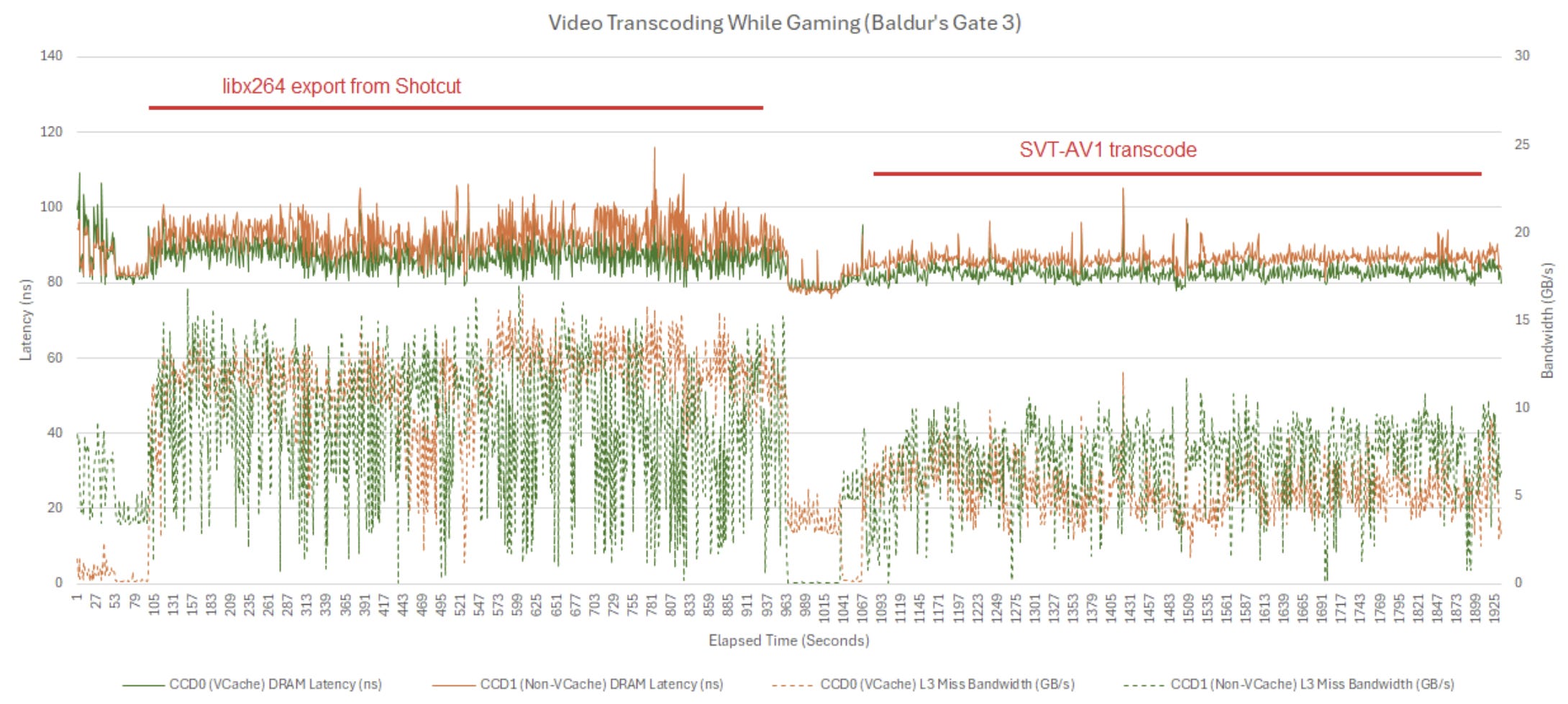
Video encoding can demand a lot of bandwidth, but the Ryzen 9 7950X3D’s L3 cache contains enough of it to avoid contention at the XI, Infinity Fabric, or DRAM controller levels. Off-core traffic exceeded 85 GB/s over some sampling intervals, so a hypothetical Zen 4 setup with no L3 cache would suffer heavily from DRAM and Infinity Fabric bottlenecks. For perspective, here’s a bandwidth plot with L3 hit bandwidth included.

Long ago, chips like AMD’s Llano or Excavator only had 1 MB L2 caches and no L3. A large L3 cache takes significant die area and adds complexity, so I understand why AMD omitted it on certain products. But I can only imagine how hard even a fast DDR5 setup would be pushed by a hypothetical desktop chip with 16 cores, 1 MB of L2 per core, and no L3. Any interconnect sitting between the cores and memory would be heavily loaded too. Of course, such a setup doesn’t exist for good reason.
Final Words
AMD’s successful Zen line stands on top of a scalable system architecture with multiple interconnect levels. But designing a scalable architecture is hard. Several blocks at one level may have to be fed through a choke point in the next level. If many cores are asking for as much bandwidth as they can get their hands on, queues can start filling and cause delays. That risks a “noisy neighbor” problem where latency sensitive code is penalized by bandwidth heavy code running elsewhere on the system.

Delays at level in the memory subsystem are additive. A request held up for a dozen cycles waiting for an XI queue entry will be dozens of cycles late to the party when fighting for IFOP cycles. Any additional delays at the IFOP will mean the request goes through various Infinity Fabric components later, and so on. Zen 4 appears to be most severely affected by compounding delays, probably because AMD let individual cores consume way more bandwidth than before. But as performance counters and observations on Zen 2 show, AMD’s Infinity Fabric and memory controller do a good job of maintaining reasonable latency under load. CCX-level contention seems to cause the worst of the loaded latency spikes I saw.

For the most part, these limitations aren’t seen in typical client applications. Games can be latency sensitive, but the ones I tested don’t create enough bandwidth demand to stress parts of the memory subsystem. Even well threaded productivity workloads may not push bandwidth limits, as AMD’s large L3 cache can contain a lot of memory accesses. Some workloads, like RawTherapee, are both difficult to cache and well threaded. I wouldn’t advise running such a workload alongside a game or another latency sensitive program. Still, Zen 5 shows AMD is paying some attention to ensuring a good baseline level of performance for latency sensitive tasks, even when the memory subsystem is very busy.
If time permits, I intend to test some Intel chips too. Many Intel chips basically have a single level interconnect, with a mesh or ring stop connecting cores to L3, DRAM, an iGPU, and possibly other blocks too. My first impression is that Intel’s Comet Lake behaves much like AMD’s Zen 2, though without the CCX and CCD-level contention points. Loading all cores brings latency up to 233.8 ns, worse than Zen 2 with all cores loaded, but better than Zen 2 with all bandwidth load and the latency test stuck on a single CCD. Eventually, I plan to play with some cloud server instances too.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.
Is there a possibility to get your program for testing memory latency/L3 bandwidth?
Overclocking ddr5 is quite easy, both hynix 16gbit A-die and 24gbit M-die should clock past 8000MT/s on adequate hardware, even if they come from DDR5-6000 kits.