
Intel’s E2200 “Mount Morgan” IPU at Hot Chips 2025

Intel’s IPUs, or Infrastructure Processing Units, evolved as network adapters developed increasingly sophisticated offload capabilities. IPUs take things a step further, aiming to take on a wide variety of infrastructure services in a cloud environment in addition to traditional software defined networking functions. Infrastructure services are run by the cloud operator and orchestrate tasks like provisioning VMs or collecting metrics. They won’t stress a modern server CPU, but every CPU core set aside for those tasks is one that can’t be rented out to customers. Offloading infrastructure workloads also provides an extra layer of isolation between a cloud provider’s code and customer workloads. If a cloud provider rents out bare metal servers, running infrastructure services within the server may not even be an option.

Intel’s incoming “Mount Morgan” IPU packs a variety of highly configurable accelerators alongside general purpose CPU cores, and aims to capture as many infrastructure tasks as possible. It shares those characteristics with its predecessor, “Mount Evans”. Flexibility is the name of the game with these IPUs, which can appear as a particularly capable network card to up to four host servers, or run standalone to act as a small server. Compared to Mount Evans, Mount Morgan packs more general purpose compute power, improved accelerators, and more off-chip bandwidth to support the whole package.
Compute Complex
Intel includes a set of Arm cores in their IPU, because CPUs are the ultimate word in programmability. They run Linux and let the IPU handle a wide range of infrastructure services, and ensure the IPU stays relevant as infrastructure requirements change. Mount Morgan’s compute complex gets an upgrade to 24 Arm Neoverse N2 cores, up from 16 Neoverse N1 cores in Mount Evans. Intel didn’t disclose the exact core configuration, but Mount Evans set its Neoverse N1 cores up with 512 KB L2 caches and ran them at 2.5 GHz. It’s not the fastest Neoverse N1 configuration around, but it’s still nothing to sneeze at. Mount Morgan of course takes things further. Neoverse N1 is a 5-wide out-of-order core with a 160 entry ROB, ample execution resources, and a very capable branch predictor. Each core is already a substantial upgrade over Neoverse N1. 24 Neoverse N2 cores would be enough to handle some production server workloads, let alone a collection of infrastructure services.

Mount Morgan gets a memory subsystem upgrade to quad channel LPDDR5-6400 to feed the more powerful compute complex. Mount Evans had a triple channel LPDDR4X-4267 setup, connected to 48 GB of onboard memory capacity. If Intel keeps the same memory capacity per channel, Mount Morgan would have 64 GB of onboard memory. Assuming Intel’s presentation refers to 16-bit LPDDR4/5(X) channels, Mount Morgan would have 51.2 GB/s of DRAM bandwidth compared to 25.6 GB/s in Mount Evans. Those figures would be doubled if Intel refers to 32-bit data buses to LPDDR chips, rather than channels. A 32 MB System Level Cache helps reduce pressure on the memory controllers. Intel didn’t increase the cache’s capacity compared to the last generation, so 32 MB likely strikes a good balance between hitrate and die area requirements. The System Level Cache is truly system level, meaning it services the IPU’s various hardware acceleration blocks in addition to the CPU cores.

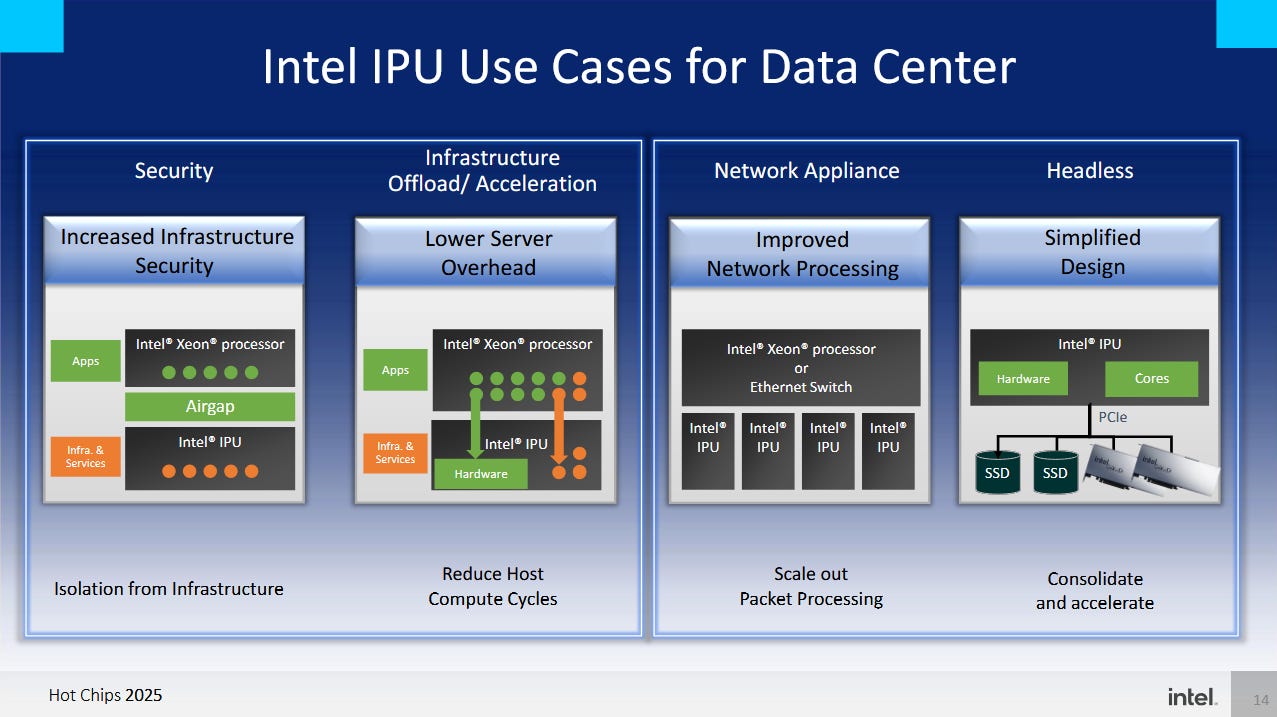
A Lookaside Crypto and Compression Engine (LCE) sits within the compute complex, and shares lineage with Intel’s Quickassist (QAT) accelerator line. Intel says the LCE features a number of upgrades over QAT targeted towards IPU use cases. But perhaps the most notable upgrade is getting asymmetric crypto support, which was conspicuously missing from Mount Evans’s LCE block. Asymmetric cryptography algorithms like RSA and ECDHE are used in TLS handshakes, and aren’t accelerated by special instructions on many server CPUs. Therefore, asymmetric crypto can consume significant CPU power when a server handles many connections per second. It was a compelling use case for QAT, and it’s great to see Mount Morgan get that as well. The LCE block also supports symmetric crypto and compression algorithms, capabilities inherited from QAT.
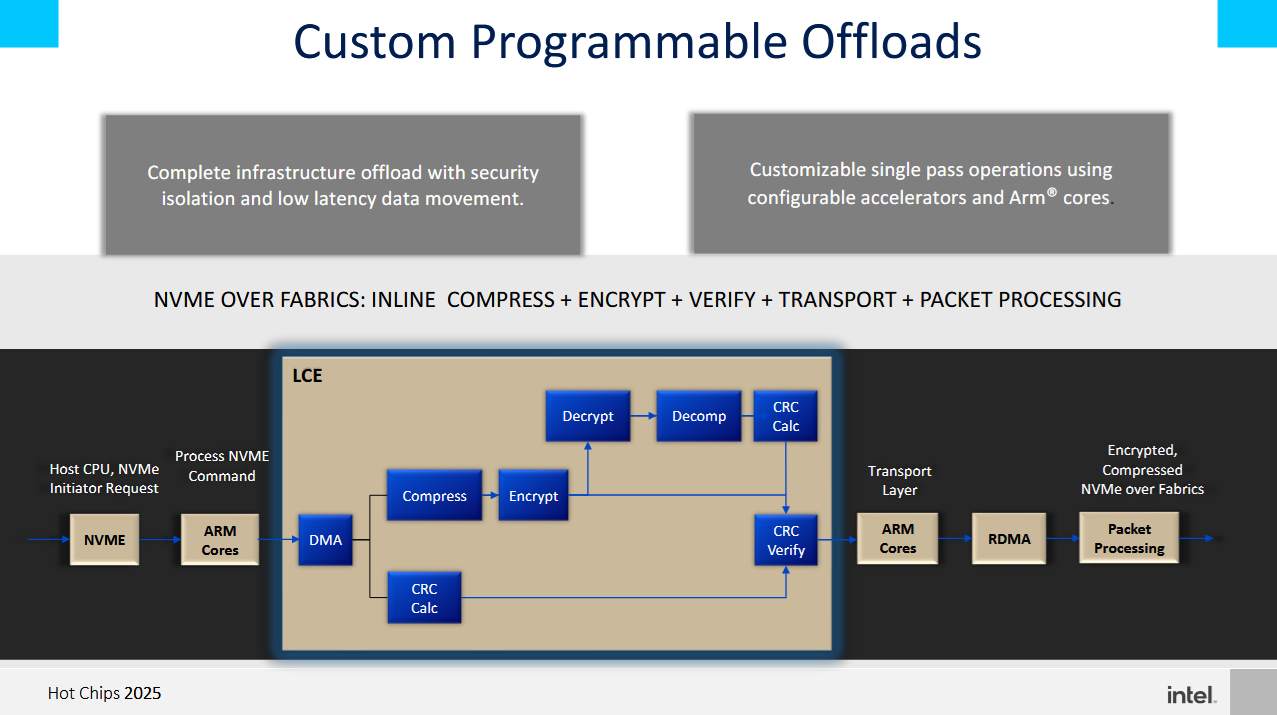
A programmable DMA engine in the LCE lets cloud providers move data as part of hardware accelerated workflows. Intel gives an example workflow for accessing remote storage, where the LCE helps move, compress, and encrypt data. Other accelerator blocks located in the IPU’s network subsystem help complete the process.
Network Subsystem
Networking bandwidth and offloads are a core function of the IPU, and its importance can’t be understated. Cloud servers need high network and storage bandwidth. The two are often two sides of the same coin, because cloud providers might use separate storage servers accessed over datacenter networking. Mount Morgan has 400 Gbps of Ethernet throughput, double Mount Evans’s 200 Gbps.
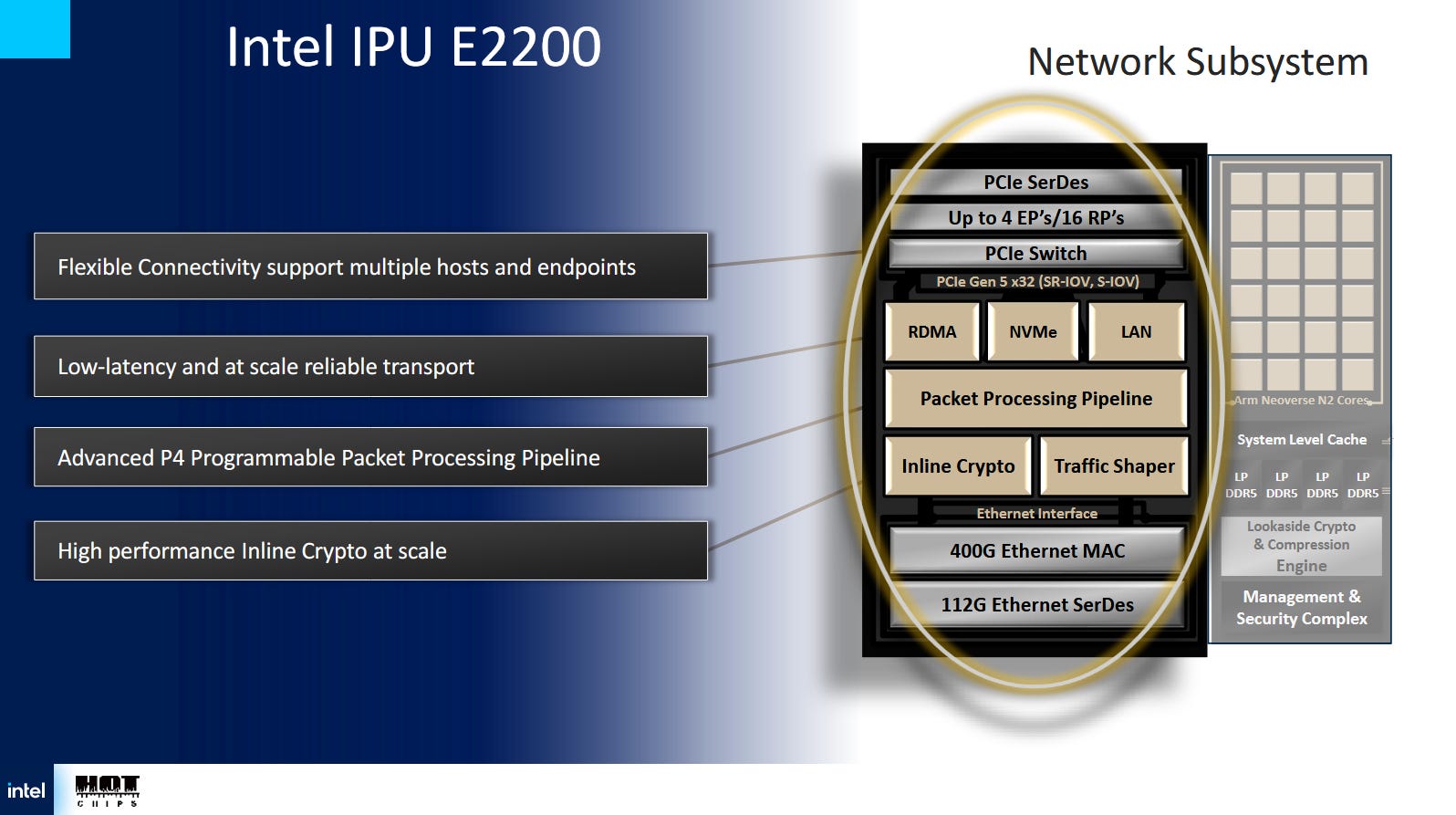
True to its smart NIC lineage, Mount Morgan uses a large number of inline accelerators to handle cloud networking tasks. A programmable P4-based packet processing pipeline, called the FXP, sits at the heart of the network subsystem. P4 is a packet processing language that lets developers express how they want packets handled. Hardware blocks within the FXP pipeline closely match P4 demands. A parser decodes packet headers and translates the packet into a representation understood by downstream stages. Downstream stages can check for exact or wildcard matches. Longest prefix matches can be carried out in hardware too, which is useful for routing.
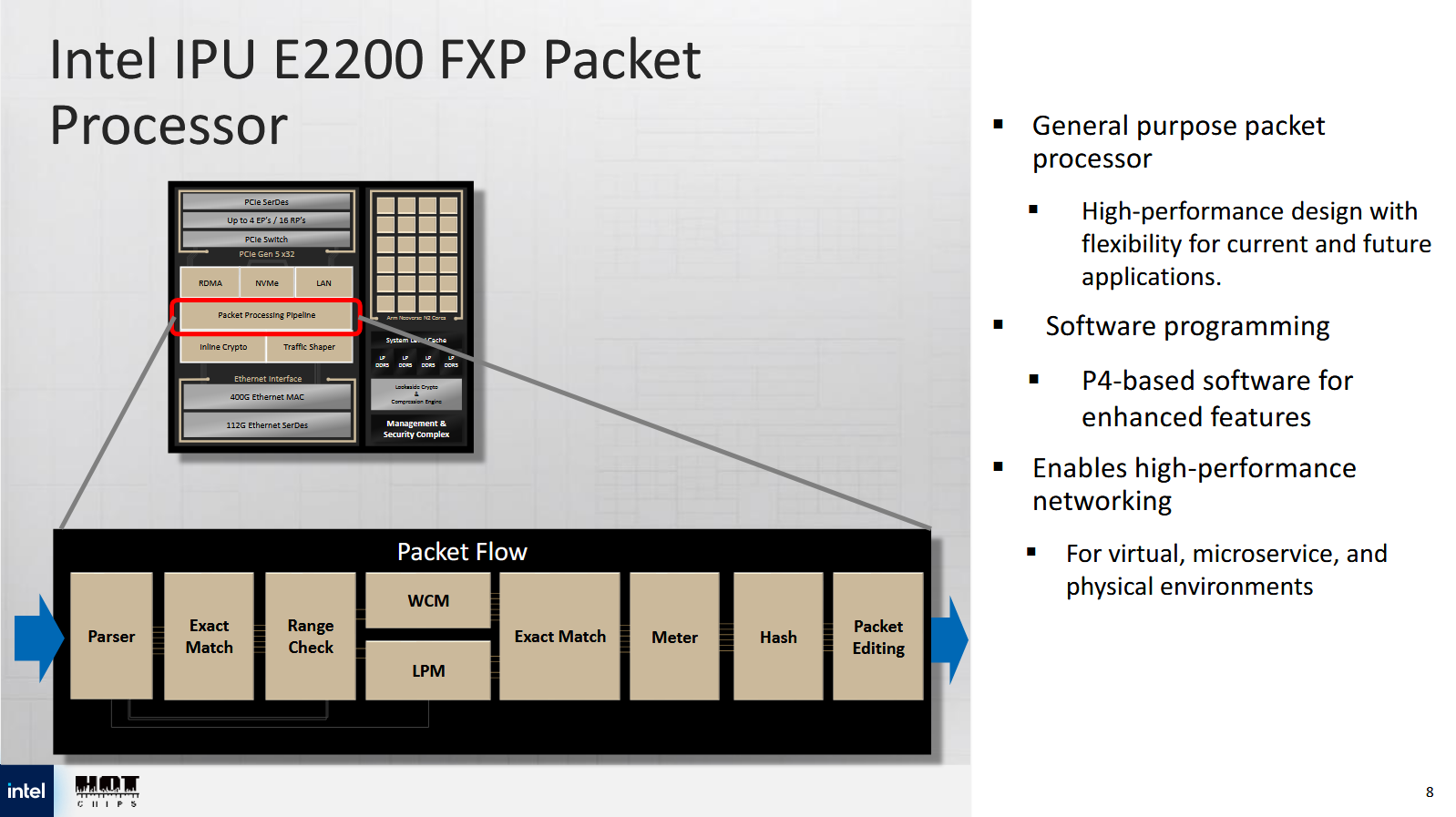
The FXP can handle a packet every cycle, and can be configured to perform multiple passes per packet. Intel gives an example where one pass processes outer packet layers to perform decapsulation and checks against access control lists. A second pass can look at the inner packet, and carry out connection tracking or implement firewall rules.
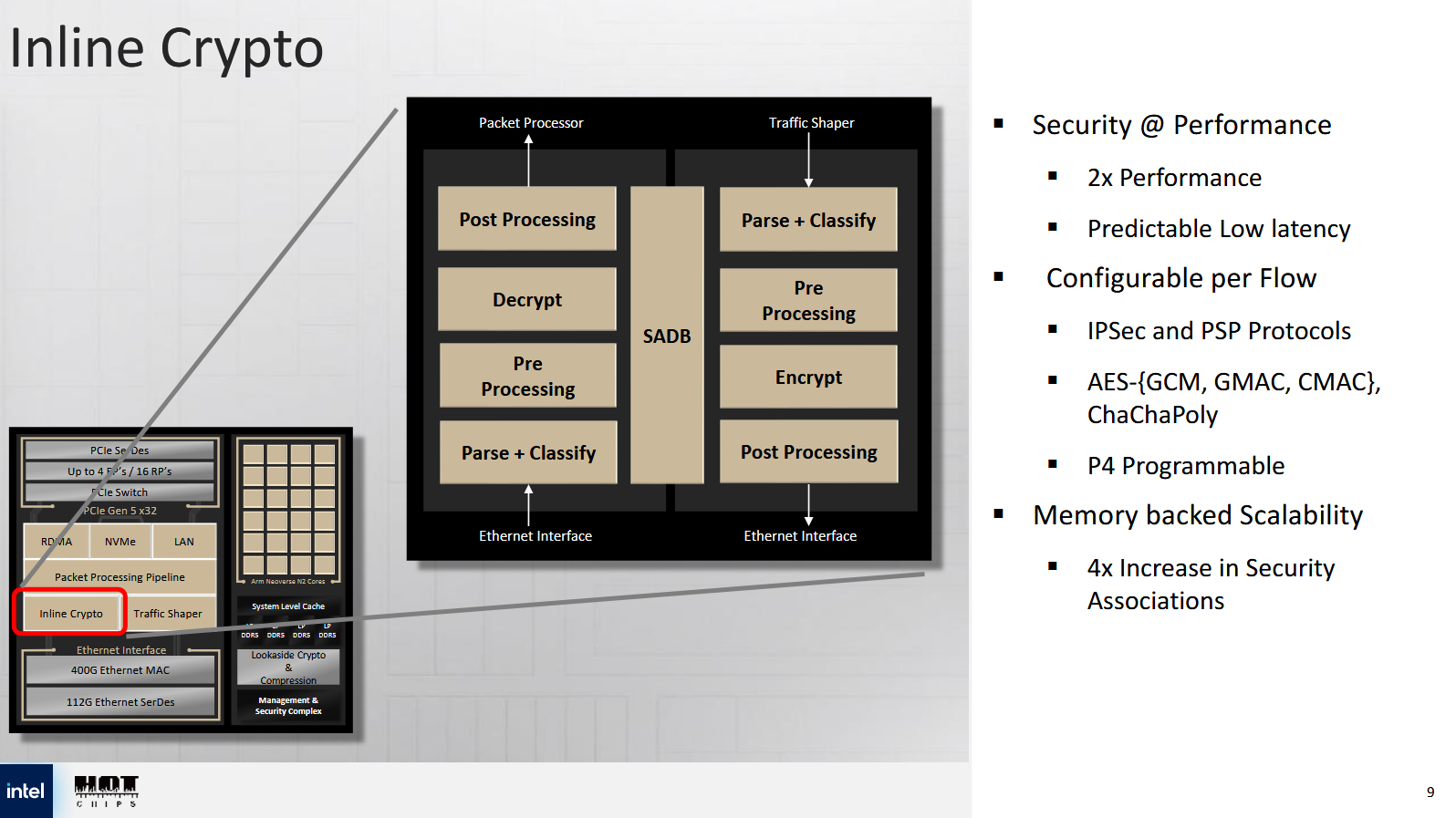
An inline crypto block sits within the network subsystem as well. Unlike the LCE in the compute complex, this crypto block is dedicated to packet processing and focuses on symmetric cryptography. It includes its own packet parsers, letting it terminate IPSec and PSP connections and carry out IPSec/PSP functions like anti-replay window protection, sequence number generation, and error checking in hardware. IPSec is used for VPN connections, which are vital for letting customers connect to cloud services. PSP is Google’s protocol for encrypting data transfers internal to Google’s cloud. Compared to Mount Evans, the crypto block’s throughput has been doubled to support 400 Gbps, and supports 64 million flows.
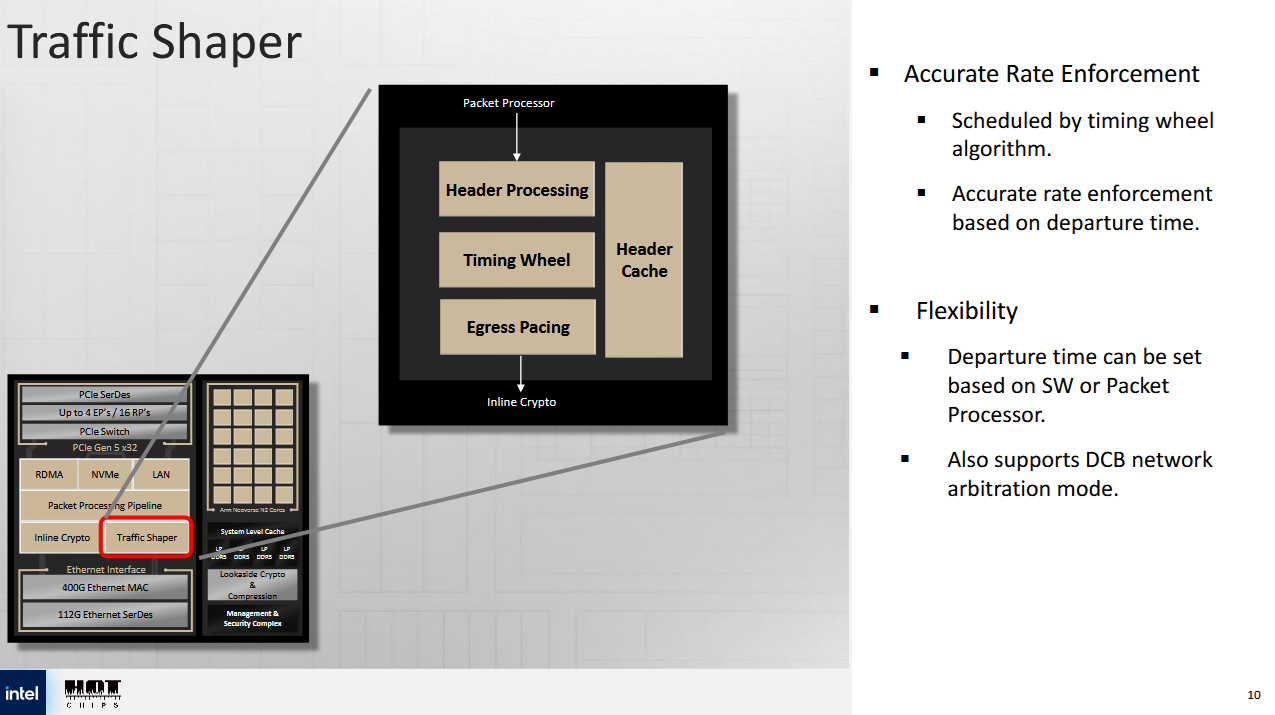
Cloud providers have to handle customer network traffic while ensuring fairness. Customers only pay for a provisioned amount of network bandwidth. Furthermore, customer traffic can’t be allowed to monopolize the network and cause problems with infrastructure services. The IPU has a traffic shaper block, letting it carry out quality of service measures completely in hardware. One mode uses a mutli-level hierarchical scheduler to arbitrate between packets based on source port, destination port, and traffic class. Another “timing wheel” mode does per-flow packet pacing, which can be controlled by classification rules set up at the FXP. Intel says the timing wheel mode gives a pacing resolution of 512 nanoseconds per slot.

RDMA traffic accounts for a significant portion of datacenter traffic. For example, Azure says RDMA accounts for 70% of intra-cloud network traffic, and is used for disk IO. Mount Morgan has a RDMA transport option to provide hardware offload for that traffic. It can support two million queue pairs across multiple hosts, and can expose 1K virtual functions per host. The latter should let a cloud provider directly expose RDMA acceleration capabilities to VMs. To ensure reliable transport, the RDMA transport engine supports the Falcon and Swift transport protocols. Both protocols offer improvements over TCP, and Intel implements congestion control for those protocols completely in hardware. To reduce latency, the RDMA block can bypass the packet processing pipeline and handle RDMA connections on its own.
All of the accelerator blocks above are clients of the system level cache. Some hardware acceleration use cases, like connection tracking with millions of flows, can have significant memory footprints. The system level cache should let the IPU keep frequently accessed portions of accelerator memory structures on-chip, reducing DRAM bandwidth needs.
Host Fabric and PCIe Switch
Mount Morgan’s PCIe capabilities have grown far beyond what a normal network card may offer. It has 32 PCIe Gen 5 lanes, providing more IO bandwidth than some recent desktop CPUs. It’s also a huge upgrade over the 16 PCIe Gen 4 lanes in Mount Evans.
Traditionally, a network card sits downstream of a host, and thus appears as a device attached to a server. The host fabric and PCIe subsystem is flexible to let the IPU wear many hats. It can appear as a downstream device to up to four server hosts, each of which sees the IPU as a separate, independent device. Mount Evans supported this “multi-host” mode as well, but Mount Morgan’s higher PCIe bandwidth is necessary to utilize its 400 Gigabit networking.
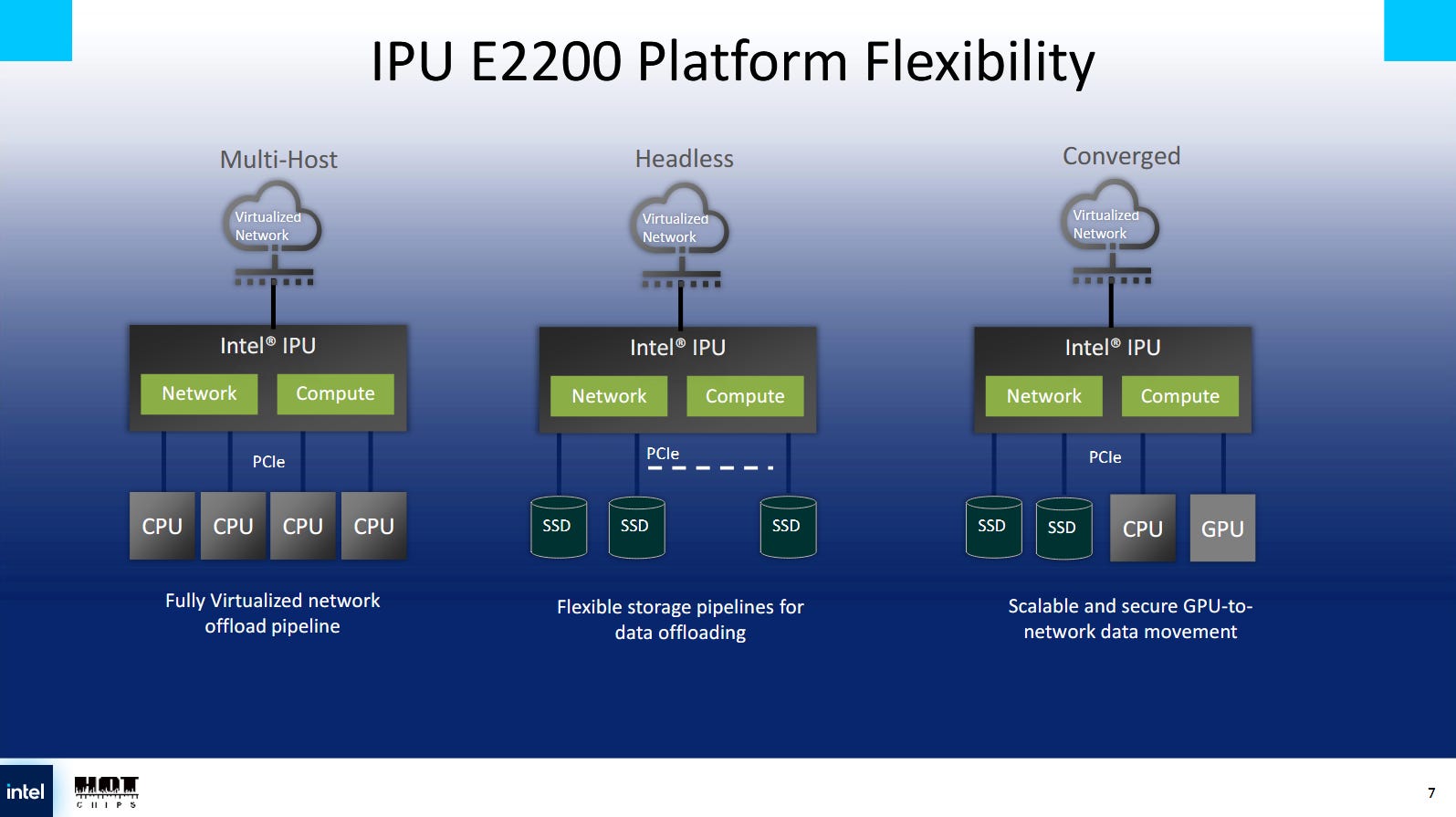
Mount Morgan can run in a “headless” mode, where it acts as a standalone server and a lightweight alternative to dedicating a traditional server to infrastructure tasks. In this mode, Mount Morgan’s 32 PCIe lanes can let it connect to many SSDs and other devices. The IPU’s accelerators as well as the PCIe lanes appear downstream of the IPU’s CPU cores, which act as a host CPU.
A “converged” mode can use some PCIe lanes to connect to upstream server hosts, while other lanes connect to downstream devices. In this mode, the IPU shows up as a PCIe switch to connected hosts, with downstream devices visible behind it. A server could connect to SSDs and GPUs through the IPU. The IPU’s CPU cores can sit on top of the PCIe switch and access downstream devices, or can be exposed as a downstream device behind the PCIe switch.
The IPU’s multiple modes are a showcase of IO flexibility. It’s a bit like how AMD uses the same die as an IO die within the CPU and a part of the motherboard chipset on AM4 platforms. The IO die’s PCIe lanes can connect to downstream devices when it’s serving within the CPU, or be split between an upstream host and downstream devices when used in the chipset. Intel is also no stranger to PCIe configurability. Their early QAT PCIe cards reused their Lewisburg chipset, exposing it as a downstream device with three QAT devices appearing behind a PCIe switch.
Final Words
Cloud computing plays a huge role in the tech world today. It originally started with commodity hardware, with similar server configurations to what customers might deploy in on-premise environments. But as cloud computing expanded, cloud providers started to see use cases for cloud-specific hardware accelerators. Examples include "Nitro" cards in Amazon Web Services, or smart NICs with FPGAs in Microsoft Azure. Intel has no doubt seen this trend, and IPUs are the company's answer.

Mount Morgan tries to service all kinds of cloud acceleration needs by packing an incredible number of highly configurable accelerators, in recognition of cloud providers’ diverse and changing needs. Hardware acceleration always runs the danger of becoming obsolete as protocols change. Intel tries to avoid this by having very generalized accelerators, like the FXP, as well as packing in CPU cores that can run just about anything under the sun. The latter feels like overkill for infrastructure tasks, and could let the IPU remain relevant even if some acceleration capabilities become obsolete.
At a higher level, IPUs like Mount Morgan show that Intel still has ambitions to stretch beyond its core CPU market. Developing Mount Morgan must have been a complex endeavor. It’s a showcase of Intel’s engineering capability even when their CPU side goes through a bit of a rough spot. It’ll be interesting to see whether Intel’s IPUs can gain ground in the cloud market, especially with providers that have already developed in-house hardware offload capabilities tailored to their requirements.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
Mount Evans has 12 × 16-bit LPDDR4-4276 channels grouped into three 64-bit groups, for a total of ~100GB/s raw DDR bandwidth.
Mount Morgan has 16 × 16-bit LPDDR5-6400 channels grouped into four 64-bit groups, for ~200GB/s raw DDR bandwidth.
Thanks Chester! Maybe I missed it, but will Intel fab Mount Morgan themselves, and in what node(s)?