
A RISC-V Progress Check: Benchmarking P550 and C910

RISC-V has seen a flurry of activity over the past few years. Most RISC-V implementations have been small in-order cores. Western Digital’s SweRV and Nvidia’s RV-RISCV are good examples. But cores like those are meant for small microcontrollers, and the average consumer won’t care which core a company selects for a GPU or SSD’s microcontrollers. Flagship cores from AMD, Arm, Intel, and Qualcomm are more visible in our daily lives, and use large out-of-order execution engines to deliver high performance.
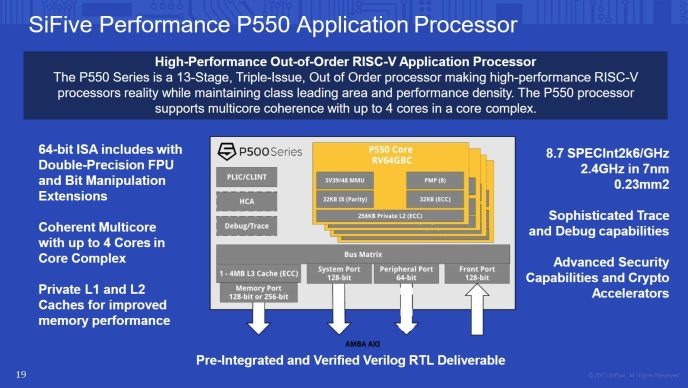
Out-of-order execution involves substantial complexity, which makes SiFive’s Performance P550 and T-HEAD’s Xuantie C910 interesting. Both feature out-of-order execution, though a quick look at headline specifications shows neither core can take on the best from AMD, Arm, Intel, or Qualcomm.

To check on RISC-V’s progress as its cores move toward higher performance targets, I’m comparing with Arm’s Cortex A73 and Intel’s Goldmont Plus. Both have comparably sized out-of-order execution engines.
SPEC CPU2017
SPEC is an industry standard benchmark distributed in source code form. It deliberately attempts to test both hardware and the compilers that target it. As before, I’m building SPEC CPU2017 with GCC 14.2.0. For P550, I used -march=rv64imafdc_zicsr_zifencei_zba_zbb -mtune=sifive-p400-series. For C910, I used -march=rv64imafdc_xtheadvector -mtune=generic-ooo. GCC doesn’t have optimization models for either RISC-V core, though I suspect that doesn’t matter much.
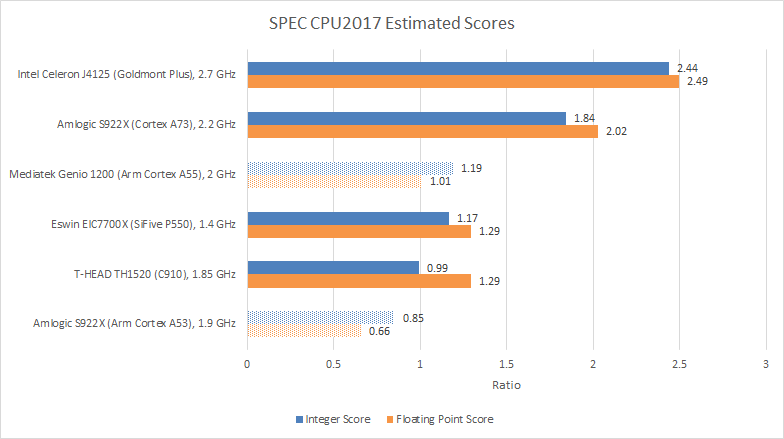
The two RISC-V cores fall short of Arm’s Cortex A73 and well short of Intel’s Goldmont Plus. Clock speed differences play a large role, and the EIC7700X is especially terrible in that respect. Eswin chose to clock its P550 cluster at just 1.4 GHz, even though the chip’s datasheet notes the CPU cores can run at “up to 1.8 GHz”. C910 does better at 1.85 GHz, though that’s still low in absolute terms. Unfortunately for T-HEAD, C910’s higher clock speed does not let it gain a performance lead against the P550. I’m still working on dissecting C910, but at first glance I’m not impressed with how T-HEAD balanced C910’s out-of-order execution engine and memory subsystem.
Cortex A55 and A53 provide perspective on where in-order execution sits today. Neither core can get anywhere close to high performance client designs, but C910 and P550 have relatively small out-of-order engines. They also run at low clock speeds. Mediatek’s Genio 1200 has a particularly strong A55 implementation, with higher clock speeds and better DRAM latency than C910 and P550. Its Cortex A55 cores are able to catch C910 and P550 without full out-of-order execution.
AMD expects to exceed Pentium performance at the same clock rate by about 30%
This isn’t the first time an in-order core does surprisingly well against out-of-order ones. Back in 1996, AMD’s K5 featured 4-wide out-of-order execution and better per-clock performance than Intel’s 2-wide, in-order Pentium. Intel clocked the Pentium more than 30% faster, and came out top. Today’s situation with C910 and P550 against A55 has some parallels. A55 doesn’t win everywhere though. It loses to both RISC-V cores in SPEC CPU2017’s floating point suite. And a less capable in-order core like A53 can’t keep up despite running at higher clocks.

Across SPEC CPU2017’s integer workloads, C910 fails to win any test against the lower clocked EIC7700X. T-HEAD does better in the floating point suite, where it wins in a number of tests, but fails to take an overall performance lead. Meanwhile, A73 and Goldmont Plus do an excellent job of translating their higher clock speeds into a real advantage.
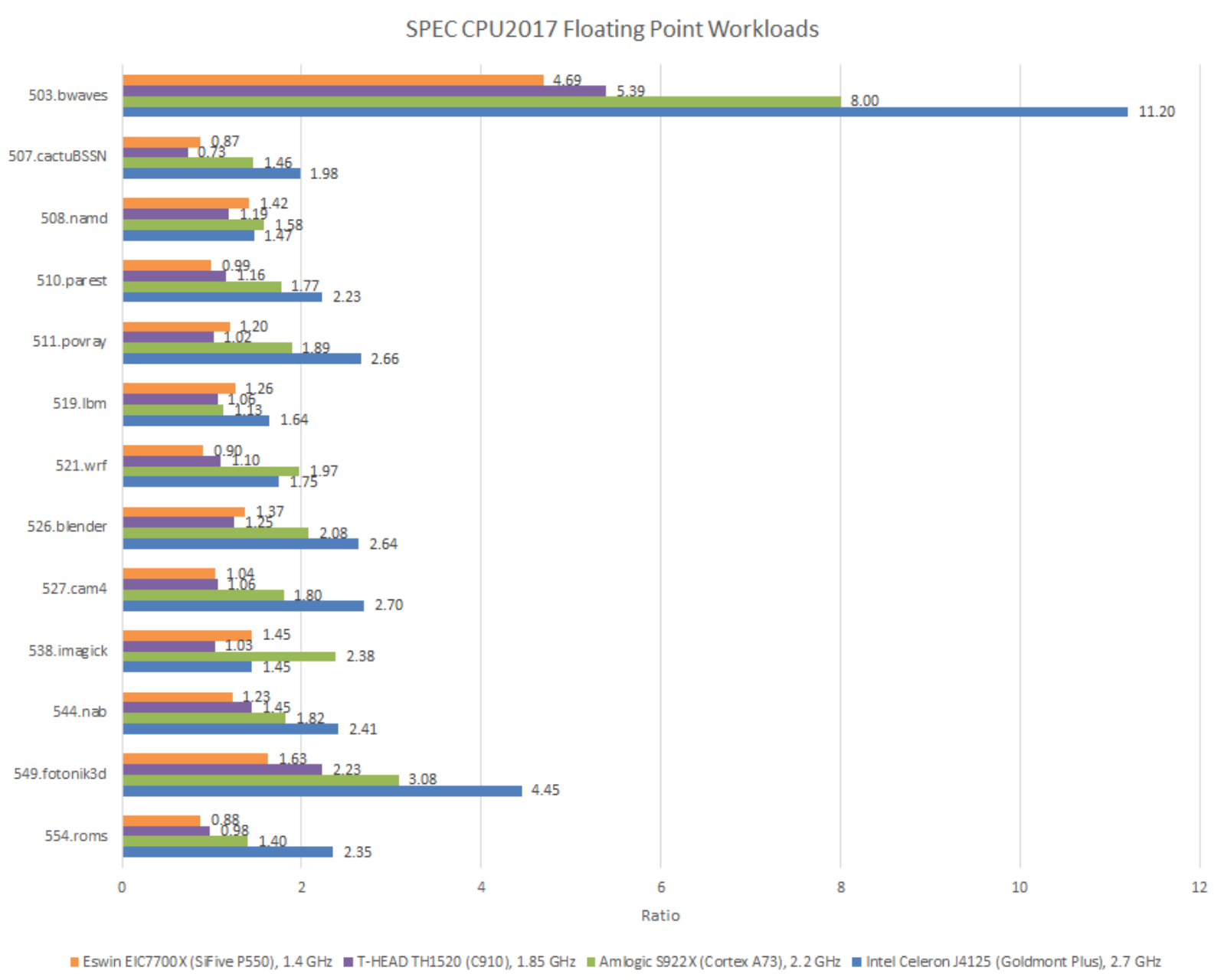
IPC data from hardware performance counters can show how well cores are utilizing their pipeline widths. IPC behavior tends to vary throughout a workload, but generally core width becomes more of a likely limitation as average IPC approaches core width. Conversely, low IPC workloads are less likely to care about core width, and might benefit from better branch prediction or lower memory access latency.
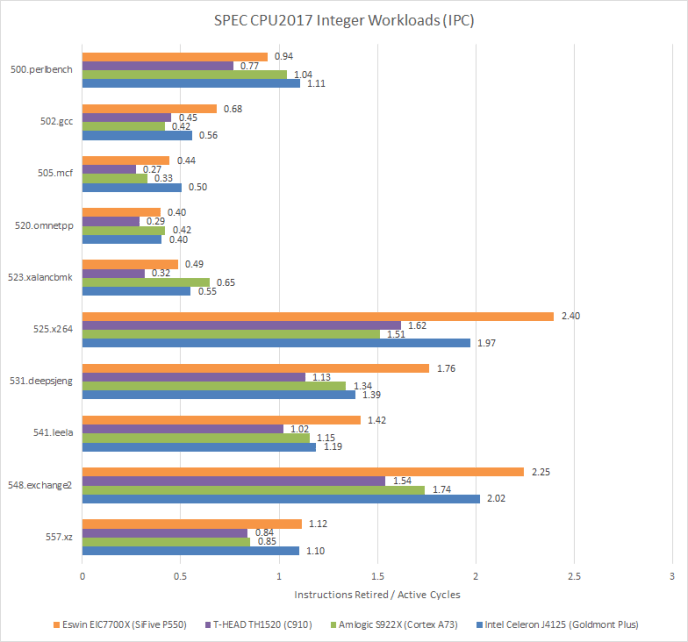
In SPEC CPU2017’s integer workloads, 548.exchange2 and 525.x264 are high IPC workloads. Arm’s 2-wide A73 is at a disadvantage in both. 3-wide cores like P550 and Goldmont Plus can stretch their legs, pushing up to and beyond 2 IPC. C910 is also 3-wide, but struggles to take advantage of its core width.

SPEC’s floating point suite has a few high IPC tests too, like 538.imagick and 508.namd. Low power cores don’t seem to do so well in these tests, unlike high performance cores like AMD’s Zen 5 or Intel’s Redwood Cove. Goldmont Plus gets destroyed in 538.imagick. But Intel’s low power core does well enough across other tests to let its high clock speed show through, and translate to a large overall lead. C910 again fails to impress. P550 somewhat makes up for its low clock speed with good IPC, though it’s really hard to compete from 1.4 GHz.
7-Zip File Compression
7-Zip is a file compression utility. It almost exclusively uses scalar integer instructions, so floating point and vector execution isn’t important in this workload. I’m compressing a 2.67 GB file using four cores, with 7-Zip set to use four threads.

C910 and P550 turn in a similar performance. Both fall slightly behind the in-order Cortex A55, again showing how well fed, higher clocked in-order cores can still pack a punch. For perspective though, I’ve included A55 cores from two cell phone chips.

In Qualcomm’s Snapdragon 855 and 670, A55 suffers from much higher DRAM latency and runs at lower clocks. Both fall behind P550 and C910, showing how performance for the same core can vary wildly depending on the chip it’s implemented in.
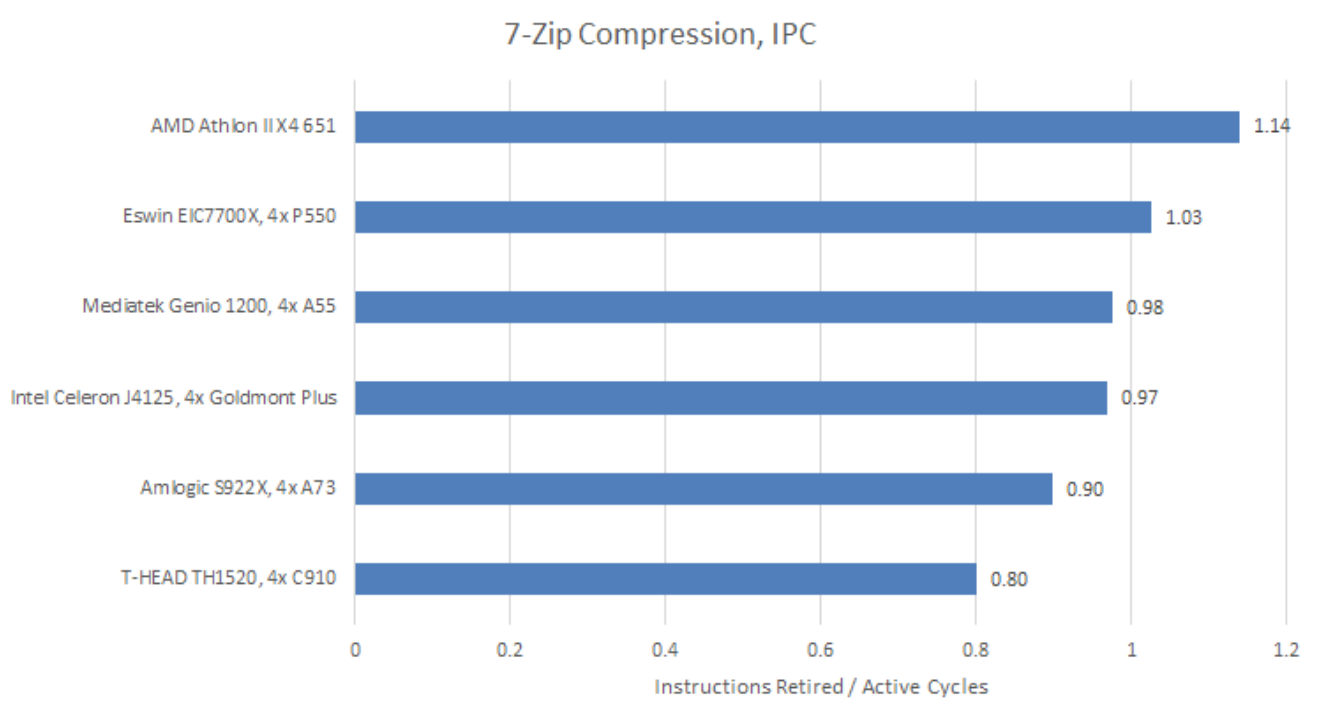
7-Zip is relatively challenging from an IPC perspective, with a lot of branches and cache misses. P550 gets reasonably good utilization out of its pipeline.
Calculate SHA256 Checksum
Hash functions are used to ensure data integrity. Most desktop CPUs have more than enough power to hash gigabytes upon gigabytes of data without taking too long. Low power CPUs are a different story. I also find this checksum calculation workload interesting because it often reaches very high IPC on CPUs that don’t have specific instructions to accelerate it. I’m simply using Linux’s sha256sum command on the same 2.67 GB file fed into 7-Zip above.

Cortex A55 takes a surprisingly large lead. sha256sum‘s instruction stream seems to mostly consist of math and bitwise instructions, with few memory accesses or branches. That creates an ideal environment for in-order cores. Impressively, A55 manages higher IPC than A73.

3-wide cores also have a field day. P550 and Goldmont Plus sustain well over 2 IPC. C910 doesn’t enjoy the field day so much, but still gets close to 2 IPC.
Both RISC-V cores execute more instructions to get the same work done. x86-64 represents this workload more efficiently, and aarch64 is able to finish using even fewer instructions.

Collecting performance monitoring data comes with some margin of error, because tools like perf must interrupt the targeted workload to read out performance counter values. Hardware performance counters also aren’t validated to the same strict standard as other parts of the core, because results only have to be good enough to properly inform software turning decisions. Still, the gap between P550 and C910 is larger than I’d expect. P550 executes more instructions to finish the same work, and I’m not sure why.
x264 Encode
Software video encoding provides better compression efficiency than hardware video encoders, but is computationally expensive. SPEC CPU2017 represents software video encoding with the “525.x264” subtest, but in practice libx264 uses handwritten assembly kernels to take advantage of CPU vector extensions. Assembly of course can’t make it into SPEC – which needs to be fair to different ISAs and can’t use ISA specific code.
Unfortunately real life is not fair. Both CPU vector capabilities and software support for them can affect performance. x264 prints out CPU capabilities it can take advantage of:
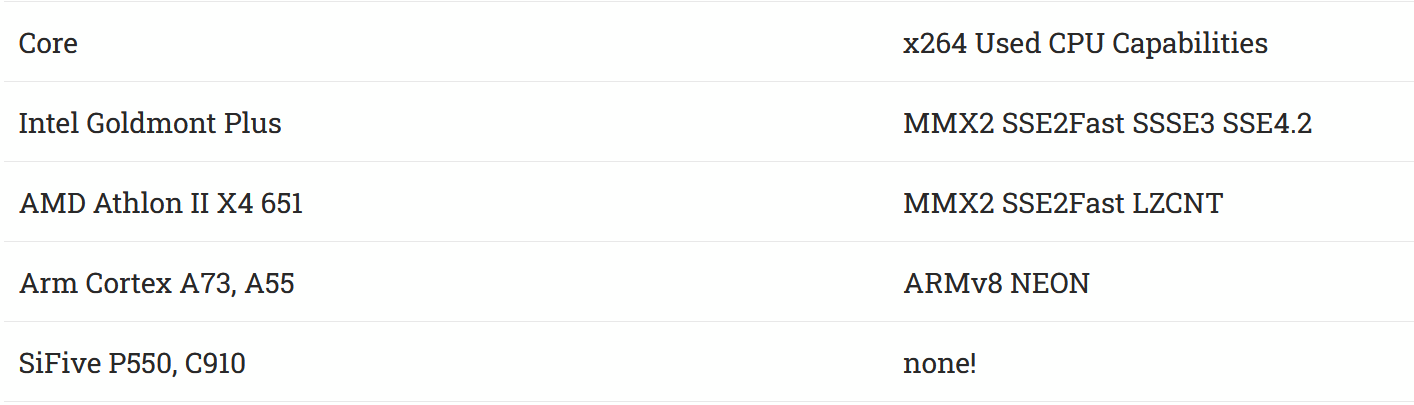
C910 supports RVV 0.7.1, but libx264 does not have any assembly code written for any RISC-V ISA extension. Performance is a disaster for the RISC-V contenders, with A73 and Goldmont Plus landing on a different performance planet. Even A55 is very comfortably ahead.
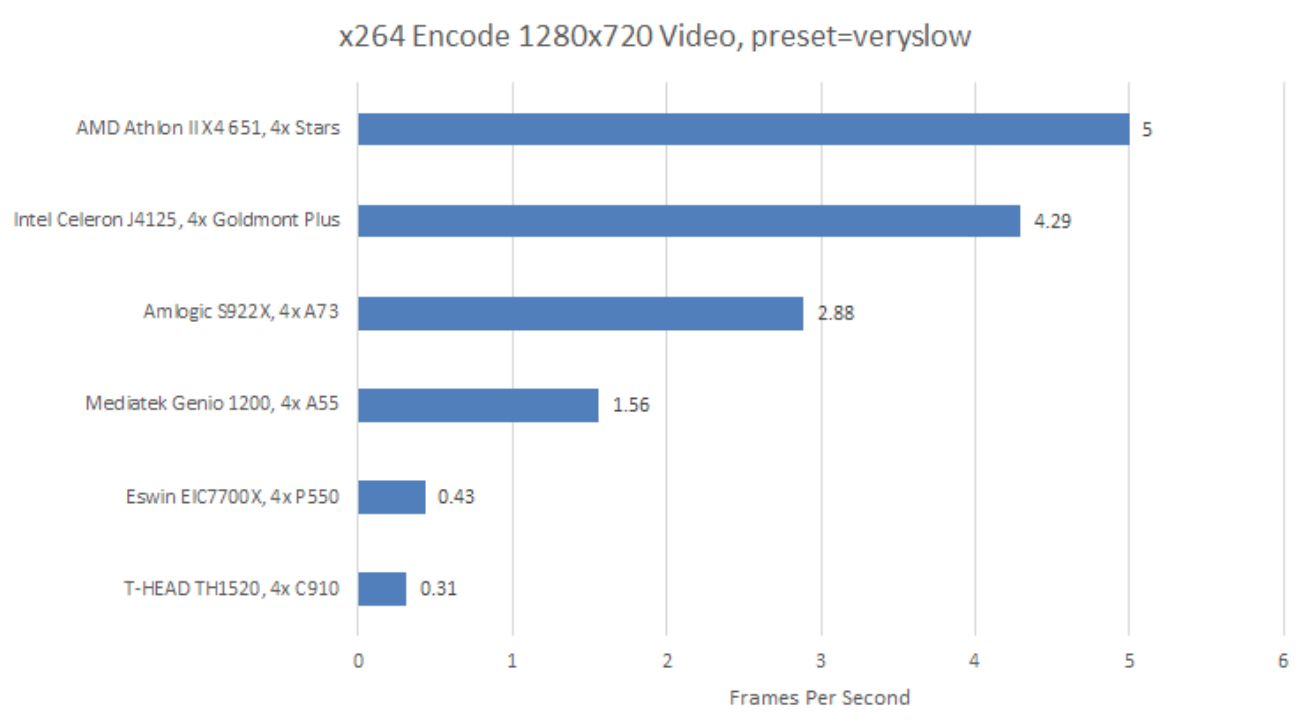
Both RISC-V cores top the IPC chart, executing more instructions per cycle on average than the x86-64 or aarch64 cores I tested. P550 is especially impressive, pushing close to its 3 IPC limit. C910 doesn’t do as well, but 1.38 IPC is still respectable.

But IPC in isolation is misleading. Clock speed is an obvious factor. Instruction counts are another. In x264, the two RISC-V cores have to execute so many more instructions to get the same work done that IPC becomes meaningless.

Building a strong ecosystem takes a long time. RISC-V will need software developers to take advantage of vector extensions. But before that happens, RISC-V hardware needs to show those developers that it’s powerful enough to be worth the effort.
Final Words
SiFive’s Performance P550 and T-HEAD’s Xuantie C910 are both notable for featuring out-of-order execution in the RISC-V scene. Both are plagued by low clock speeds, even against older aarch64 and x86-64 cores. Arm’s Cortex A73 and Intel’s Goldmont Plus are good demonstrations of how even small out-of-order execution engines can pull a large lead against in-order cores. P550 and C910 don’t always do that.

Between the two RISC-V cores, P550 has a well balanced out-of-order execution engine. It’s able to sustain higher IPC and often keep pace with C910. In some easier workloads, P550 is able to get very close to its core width limits. SiFive has competently balanced P550’s out-of-order execution engine. C910 in comparison is less well balanced, and often fails to translate its higher clock speed into a real performance lead. I wonder if P550 has a lot more potential behind it if an implementer runs it at higher clock speeds, and backs it up with low DRAM latency.
From a hardware perspective, RISC-V is some distance away from competing with Arm or x86-64. SiFive has announced higher performance RISC-V designs, so the RISC-V world is making progress on that front. Beyond hardware though, RISC-V has a long way to go from the software perspective. RISC-V is a young instruction set and some of its extensions are younger still. These extensions can be critical to performance in certain applications (like video encoding), and building up that software ecosystem will likely take years. While I’m excited by the idea of an instruction set free from patents and licensing restrictions, RISC-V is still in its infancy.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
> P550 executes more instructions to finish the same work, and I’m not sure why.
If you're using sha256sum without compiling it yourself, chances are the RISC-V binaries are compiled without bitmanip instructions, so it's likely having to use less efficient sequences for stuff like bit rotates.
Which I think is a major issue with RISC-V in general - all the fragmentation means that Linux distributions target the lowest common denominator. RISC-V's attempts with profiles is nice, but distros still compile for x86-64v1 despite v2 being standard on x86 CPUs for the past ~15 years.
Any idea how the P550 or C910 compare to the A53 or A55 area- or power-wise? Since they seem roughly comparable in performance, it would be interesting to know how they compare in such metrics.