
Intel’s Redwood Cove: Baby Steps are Still Steps

Intel’s Meteor Lake chip signaled a change in Intel’s mobile strategy, moving away from the monolithic designs that had characterized Intel’s client designs for more than a decade. But radical changes create risk. Intel appears to have controlled that risk by iterating very conservatively on their CPU architectures. I already covered Meteor Lake’s E-Core architecture, Crestmont. Here, I’ll go over the P-Core architecture, Redwood Cove.
Overview
Redwood Cove is a minor upgrade over Intel’s prior Raptor Cove architecture from 2022. In turn, Raptor Cove is a nearly the same as 2021’s Golden Cove, sporting just a larger 2 MB L2 cache and higher maximum clock speeds at the cost of lower stability.

From testing, Intel has not changed any major core structure sizes. The company has therefore used Golden Cove as a foundation to fill out its CPU lineup for the past three years. To Redwood Cove’s credit though, it does make core architecture changes over its predecessors. Intel’s optimization guide documents some of the core’s improvements. I’ll cover that, along with Redwood Cove’s memory subsystem and SMT implementation. I don’t know if Intel changed the SMT implementation since Golden Cove, but I felt I couldn’t dive deep into SMT in prior articles without making them too long.
Frontend
Redwood Cove’s frontend gets minor tweaks aimed at keeping the core better fed. Engineers tend to improve branch prediction with every opportunity they get, so it’s not surprising to see Redwood Cove feature better branch prediction.
Improved Branch Prediction and reduced average branch misprediction recovery latency
Intel 64 and IA-32 Architectures Optimization Reference Manual Volume 1
“Improved branch prediction” by itself can mean just about everything because branch predictors have evolved to become complex monsters. Intel may have improved its accuracy, made it faster, or both. From testing, Redwood Cove’s branch predictor seems to recognize slightly longer patterns than Golden Cove’s. Redwood Cove shows a slight increase in taken branch latency when pattern length exceeds 16 for a single branch, or 16 divided by branch count for more branches.

Likely, Intel has a small, fast global history-based predictor that can be overridden by a more accurate one. Redwood Cove’s second level predictor is still very fast, and seems to take just one extra cycle compared to the small one. Golden Cove shows a similar jump when pattern length exceeds 8, so its first level predictor might be less capable than Redwood Cove’s.

Speed improves too, though it can be matter of perspective. Redwood Cove appears to inherit Golden Cove’s 12K entry BTB capacity, but drops latency from 3 to 2 cycles. Strangely, I can only see half the BTB capacity from a single thread. Two threads together can use the entire BTB.

Smaller and faster BTB levels are similar to Golden Cove’s. The core can handle up to 32 branches at two per cycle, likely by unrolling small loops within the micro-op queue. A 128 entry L1 BTB can handle taken branches with just one cycle of latency. An interesting note is it has a maximum throughput of one branch target per cycle as well. If two threads are spamming branches, each thread sustains one taken branch every two cycles. So, the 128 entry L1 BTB doesn’t have more bandwidth than the main 12K entry BTB, just better latency.
Branch Hint
Intel’s Pentium 4 introduced branch hint extensions. A compiler or assembly programmer can add a prefix indicating whether a branch is more likely to be taken more not taken. The prefixes are as follows:
0x2E: Not-taken hint
0x3E: Taken hint
Subsequent CPUs ignored the hint, likely because increasing transistor budgets allowed better branch predictors, diminishing the value of such static prediction. But Redwood Cove now recognizes the 0x3E taken hint prefix. If its branch predictor has no info about the branch, either because the workload’s branch footprint is too large for the predictor to cope with, or the core’s seeing the branch for the first time, the decoder will re-steer the frontend when it sees the 0x3E hint.
Fetch and Decode
A CPU’s fetch and decode stages fetch instructions and translate them into the core’s internal format. The L1 instruction cache speeds up instruction delivery, and reduces power draw because hits in caches closer to the core tend to cost less power. Redwood Cove doubles L1 instruction cache capacity to 64 KB, a welcome improvement over 32 KB in prior generations. An instruction bandwidth test shows Redwood Cove can sustain 32 bytes per cycle of instruction fetch bandwidth out to 64 KB, though using two threads together does better than one.

Intel continues to use a 4096 entry micro-op cache. I commented on how I couldn’t see Golden Cove’s full micro-op cache capacity back in 2021. Now I can. Using both SMT threads does the trick. I also dug into performance counters to see if a single thread somehow hit a slowdown unrelated to spilling out of the op cache. Apparently not.

Perhaps Intel decided to permanently partition the micro-op cache between two threads in Golden Cove, unlike prior architectures that could give a thread the entire micro-op cache if the core is in single threaded mode.
Micro-ops from the op cache or decoders are sent to a queue in front of the rename/dispatch stage. Intel increased the size of this queue to 192 entries, up from 144 entries on Golden Cove. If both SMT threads are active, the queue is statically partitioned so that each thread gets half.
Improved LSD coverage: the IDQ can hold 192 uops per logical processor in single-threaded mode or 96 uops per thread when SMT is active
Intel 64 and IA-32 Architectures Optimization Reference Manual Volume 1
IDQ stands for Instruction Decode Queue. LSD isn’t the stuff you were told to avoid in health class. Rather, it stands for “Loop Stream Detector”. As far back as Nehalem, Intel’s P-Cores use the micro-op queue as a loop buffer. Small loops can then be handled with much of the frontend powered off, including the micro-op cache.

Redwood Cove’s LSD is able to capture a notable chunk of the instruction stream in xalancbmk, gcc, and x264. Elsewhere, its contribution ranges from medicore to insignificant.
While I don’t have a Raptor Cove or Golden Cove chip on hand to compare, I do have Zen 4. Zen 4 has exactly the same 144 entry micro-op queue capacity as Raptor and Golden Cove. It’s also the only AMD CPU I’m aware of that can use its micro-op queue as a loop buffer.

Unfortunately a comparison is difficult because Zen 4 and Redwood Cove are such different architectures. Redwood Cove’s larger loop buffer helps in a lot of tests, but curiously Zen 4 uses its loop buffer more in xalancbmk.

Loop buffers prove their worth in SPEC CPU2017’s floating point test suite. Redwood Cove’s loop buffer often covers a substantial minority of the instruction stream. Zen 4 can do so as well, but not nearly as often. In both cases, the loop buffer is a far less consistent means of accelerating instruction delivery than the micro-op cache.

Even for code that doesn’t enjoy good loop buffer coverage, Redwood Cove’s larger micro-op queue can help smooth out micro-op delivery from the frontend. The frontend can pile micro-ops into the queue during a short backend stall. Then a short frontend stall later on can be hidden as the backend is busy going through micro-ops built up in the queue. More generally, larger queues help prevent a stall in one stage going back and causing stalls further up the pipeline.
More Fusion Cases
Besides bringing instructions into the core, the frontend can fuse adjacent instructions to more efficiently use downstream resources. Branch fusion is a notable and common case, but Redwood Cove goes further. A register to register MOV can be fused with a subsequent math instruction.
New LD+OP and MOV+OP macro fusion
Intel 64 and IA-32 Architectures Optimization Reference Manual Volume 1
Intel gives examples where a MOV followed by a math instruction can be used to emulate a non-destructive three operand math operation. Similarly, a load from memory can be fused with an adjacent dependent math instruction. That makes it possible to efficiently represent load + math operations that can’t be encoded in a single x86 instruction.
This sort of fusion can improve core throughput by packing two instructions into a pipeline slot. A core that’s 6 micro-ops wide could sustain 7 instructions per cycle if one of those micro-ops on average corresponds to a fused instruction pair. Fusion also helps a core hide backend memory latency because a fused instruction pair only consumes one slot in backend resources like the reorder buffer or register file. That ultimately lets the core speculate further ahead of a stalled instruction before its backend resources fill up.
Conversely, an instruction that decodes to multiple micro-ops places more load on backend resources. Splitting an instruction into multiple micro-ops however can simplify hardware.

AMD’s Zen 4 supports a different set of fusion cases, and also decodes a different set of instructions to multiple micro-ops. It generally comes off worse than Intel in SPEC CPU2017’s integer tests, though AMD is able to get fewer micro-ops than instructions in many cases.

Intel doesn’t come off nearly as well in SPEC CPU2017’s floating point suite. Its micro-ops can still represent work more efficiently in some cases like 526.blender. But in other cases like 503.bwaves and 510.parset, AMD comes out top.
Instruction Execution
Redwood Cove’s backend is largely identical to Raptor Cove and Golden Cove’s. None of the structure sizes I tested have changed compared to Golden Cove, though Redwood Cove’s better instruction fusion may make better use of those resources. For the execution units though, the optimization guide lists one change:
EXE: 3-cycle Floating Point multiplication
Intel 64 and IA-32 Architectures Optimization Reference Manual Volume 1
Lower latency is always a good thing. But historical context is interesting because Redwood Cove is far from the only core or even the first Intel core to have 3 cycle FP multiplication latency. AMD’s Zen line had 3 cycle FP multiply since Zen 1. Zen 4 actually has lower FP multiply latency courtesy of maintaining that 3 cycle latency while clocking higher than Redwood Cove does in mobile platforms.
Turning back to Intel, the nearly forgotten Broadwell architecture from 2015 brought floating point multiply latency down from 5 cycles in Haswell to 3 cycles. Immediately after, Skylake regressed FP multiply latency back to four cycles. Skylake had 4 cycle latency for FP adds, multiplies, and fused multiply adds. Intel may have reused the fused multiply-add unit with a multiplier of 1 and addend of 0 to implement adds adds and multiplies, respectively. Golden Cove saw Intel cut FP addition latency to 2 cycles. And now Redwood Cove cuts FP multiply latency to 3 cycles. Perhaps Intel now has enough transistor budget to implement extra logic for faster FP adds and multiplies.
Backend Memory Access
Modern CPUs are often limited by branches at the frontend, and memory access latency at the backend. Faster caching can deal with both, whether it’s for code or branch targets at the frontend or data at the backend.
Mid-level-cache size increased to 2 MBs for Client
Intel 64 and IA-32 Architectures Optimization Reference Manual Volume 1
The L2, or mid-level-cache, has become an increasingly important part of Intel’s caching strategy because it insulates the core from L3 latency. But getting a 2 MB L2 isn’t a notable change because Raptor Lake already brought a 2 MB L2 into client designs. Going further back, Sapphire Rapids gave Golden Cove a 2 MB L2 in a server design.

Redwood Cove has larger and higher latency caches at every level compared to Zen 4 mobile. At L3, Intel has 75+ cycle L3 latency compared to AMD’s approximately 50 cycle latency.
Improved Memory Bandwidth.
Increased number of outstanding misses (48 -> 64 Deeper MLC miss queues).
LLC Page Prefetcher
Intel 64 and IA-32 Architectures Optimization Reference Manual Volume 1
Bandwidth and latency are often linked at slower levels in the memory hierarchy. Basically, achievable bandwidth is limited by how many in-flight requests the core can sustain. More in-flight requests can hide more latency. Intel substantially increased the number of pending L2 misses Redwood Cove can track.

However, this advantage is offset by higher latency in Meteor Lake’s cache and memory hierarchy. Actual bandwidth is further reduced by Meteor Lake’s lower clock speed compared to desktop Golden Cove, particularly at the L3 cache. The Golden Cove data below was provided by Raichu on Twitter, though the original post doesn’t appear to be available anymore. Raichu ran a old version of my tests, but the results should still be valid.
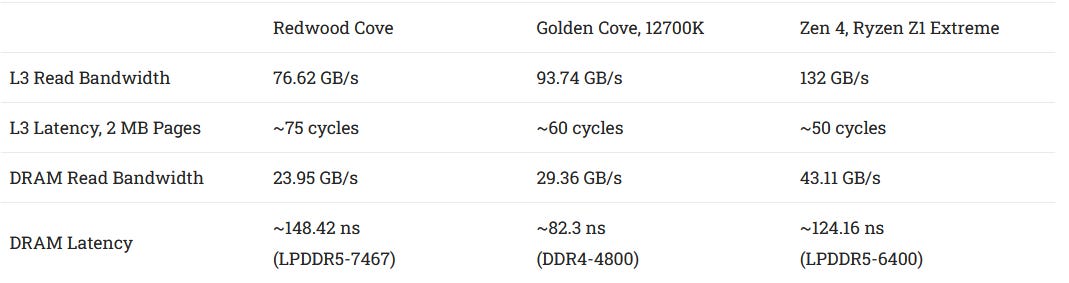
Redwood Cove achieves better bandwidth with a read-modify-write pattern, but bandwidth from a single core is still not great compared to Zen 4.
Prefetch
Out-of-order execution mitigates cache and memory latency by letting a core move some distance ahead of an instruction waiting for data from memory. But engineers can attack the problem from the other side as well. Prefetching looks at a program’s memory access patterns and tries to guess what it’ll need next. If all goes well, a prefetcher will generate a memory access request well before an instruction asks for the data. That in turn lowers latency as seen by the program. Conversely, a prefetcher that guesses wrong will waste bandwidth and power bringing data into caches that’s ultimately never used.

Redwood Cove adds a LLC page prefetcher, which is described in the optimization guide. To unpack Intel’s description, let’s get some terminology out of the way.
LLC: Last Level Cache, or the 12 MB L3 cache in Meteor Lake
IDI: Intra-die Interconnect, the communication protocol used between cores, L3 cache slices, and other agents directly attached to a CPU’s high speed ring or mesh interconnect
DCU: Data Cache Unit. DCU buffers would refer to fill buffers available to track pending L1D misses, which Redwood Cove has 16 of.
MLC: Mid-Level Cache. MLC buffers would refer to the MLC miss queue, which has 64 entries on Redwood Cove
Linear address space: Basically the virtual address space used by programs, as opposed to physical addresses that directly correspond to locations in DRAM or memory mapped IO. Long long ago in a galaxy far far away, x86 had a non-linear address space because the original 8086 used segmentation to address 20 bits of memory with 16-bit addresses (4 bits come from a segment register). x86-64 effectively deletes segmentation.
Prior Intel architectures already had a next-page prefetcher that detects if a program is accessing data close to the end of a 4 KB page. If so, it starts address translation for the next page to get virtual to physical address translation latency out of the way. It then grabs a few lines at the start of the next page.
Redwood Cove takes this a big step further by grabbing the next two 4 KB pages. 8 KB is a lot of data to prefetch, and would eat 1/6 of the core’s 48 KB L1 data cache. Obviously Intel doesn’t need to kick potentially useful data out of L1D to bring in mounds of data that a program might need. Such aggressive prefetch also risks creating a lot of unnecessary bandwidth usage.
Cache pollution is dealt with by only prefetching that 8 KB into the 24 MB L3. 8 KB is less than 1% of the L3’s capacity. If much of that 8 KB turns out to be useless, the L3 only gets polluted a little bit. Wasting bandwidth is countered by only doing so if it’s unlikely to starve other more valuable accesses. The page prefetcher doesn’t allocate entries in the L2 or L1D’s miss tracking structures, leaving them available for demand accesses and less aggressive prefetchers. To avoid fighting with other cores when the ring bus has high traffic the page prefetcher opportunistically uses IDI request slots. If there’s a lot of IDI packets flowing through the ring, the prefetcher will naturally throttle itself.
New HW data prefetcher to recognize and prefetch the “Array of Pointers” pattern
Intel 64 and IA-32 Architectures Optimization Reference Manual Volume 1
Besides the LLC page prefetcher, Redwood Cove gains an “Array of Pointers” (AOP) prefetcher. It’s far from the first core to do so. Apple silicon has used an AOP prefetcher as far back as M1, and that AOP prefetcher has been targeted by researchers investigating speculative execution vulnerabilities. The same researchers found Raptor Cove also had an AOP prefetcher, though it wasn’t aggressive enough to allow information leakage. Maybe Intel had enough frustration over the whole Meltdown vulnerability, and decided not to let the prefetcher run wild.

I tried to benchmark the AOP prefetcher by creating a memory “latency” test that dereferenced an array of pointers. Even cores without AOP prefetchers see significantly reduced latency because accesses to the array of pointers are independent. A basic out-of-order machine can already overlap random accesses to the test array, resulting in low latency. An AOP prefetcher can help of course, but in my opinion the difference isn’t massive. Crestmont can handle such an access pattern quite well already, and Intel didn’t say it has an AOP prefetcher.
Simultaneous Multi-Threading (SMT)
SMT may be absent from Intel’s incoming Lion Cove architecture, at least on client platforms, but it’s very much alive in Redwood Cove.
Improved SMT performance and efficiency
Intel 64 and IA-32 Architectures Optimization Reference Manual Volume 1
SMT lets a core take advantage of explicit thread-level parallelism by appearing as two logical cores to the operating system. If the OS has only scheduled work on one logical core and has the other in halt, that single thread will generally get all core resources to itself. But if the OS puts work on both logical cores, core resources internally get split between the two threads in a few ways:
Duplicated: The core has two copies of a resource, one for each thread. If one thread is idle, the second copy is simply not used.
Statically Partitioned: Each thread gets half of the resource
Watermarked: One thread can use up to a certain quota (high water mark). More flexibility, but creates more potential for one thread starving the other
Competitively Shared: The entire resource can be allocated to one thread on demand. Maximum flexibility, but designers have to be careful to prevent one thread from monopolizing the resource and wrecking performance for the other.
AMD has helpfully disclosed how Zen cores share resources between two threads. Intel hasn’t done so since the Pentium 4. As an introvert I can understand why companies might not talk about internal architecture details like their SMT implementation. But I’m glad to help by multithreading my structure size tests and taking a guess from software. Redwood Cove looks like this:

Both Intel and AMD watermark many of their structures, in contrast to the Pentium 4 where major structures including schedulers were statically partitioned. Some of Redwood Cove’s structures have watermarks set pretty high. For example, one thread can use about 3/4 of the integer register file for in-flight instructions, compared to roughly 58% for AMD.

I ran SPEC CPU2017’s rate tests with two copies pinned to a single core. Like the prior article, I’m using GCC 14.2. Unlike in the previous article, I’m running with -mtune=native -march=native, which lets the compiler use all ISA extensions supported on the CPU.

Redwood Cove enjoys a 17.6% throughput gain in SPEC CPU2017’s integer tests, but the floating point tests see a less impressive 4.2% uplift. AMD’s Zen 4 does very well, gaining over 20% in both the integer and FP test suites.

Other Stuff
Intel’s optimization guide goes further and lists a couple of improvements that only apply to Granite Rapids. Granite Rapids is the codename for Intel’s next generation Xeon Scalable server CPUs, so unfortunately I won’t see those changes in a Meteor Lake client platform.
Code Software Prefetch x86 architecture extension
AMX supports FP16 for AI/ML
Intel 64 and IA-32 Architectures Optimization Reference Manual Volume 1
Code Software Prefetch may indicate support for new instructions that tell the CPU where to prefetch instructions from next. Usually instruction prefetch is driven by the branch predictor, which can run ahead of instruction fetch and queues up cache fill requests. Perhaps Intel saw cases where software hints could help with code prefetch.
AMX, or Advanced Matrix Extensions, is an instruction set extension geared towards matrix multiplication. It lets code access matrix multiplication units along with tile registers to feed them. AI has been very popular among people wishing they had seven fingers on each hand instead of five, and Intel like many other companies wants in on the AI craze.
Final Words
P-Cores have been Intel’s bread and butter for ages. Around 2010, Intel was tick-tocking AMD into oblivion. With each “tick”, Intel would make minor architectural changes while porting a core to a new process. A “tick” often wouldn’t produce a big performance-per-clock gain, but the new process node could provide large benefits especially to power efficiency. A “tock” would be a significant architecture change without moving to a new process node. That let Intel focus on optimizing the microarchitecture without the added complexity of dealing with a new process.

In 2023, Redwood Cove feels like a “tick”. Meteor Lake is a very different from Raptor Lake on both a system level and process node level. Redwood Cove therefore gets minor changes, because change is risky and Meteor Lake came with enough risk already.
Compared to prior “ticks” like Ivy Bridge and Broadwell, Redwood Cove is arguably a bigger change. Still, Intel’s progress feels muted compared to AMD’s. From 2021 to 2023, AMD went from Zen 3 to Zen 4. In one generation, AMD moved from TSMC 7 nm to TSMC 5 nm and made significant architecture changes. Zen 4’s major structure sizes often see large increases, Zen 4 got AVX-512 support too. The latter is still a sticking point in Intel’s client designs, because the company stubbornly refuses to support AVX-512 in their E-Cores.
Redwood Cove is a fine core in isolation. I’ve used Meteor Lake in the Asus Zenbook 14 for a while now, and performance hasn’t been an issue. Still, I look forward to see what Intel brings next. Lion Cove should be very interesting to see, since it’s a major architecture change akin to a “tock”.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.
How does that 64 kB I-cache work, actually? Especially on x86 where I/D-cache coherency is maintained, I'd think I-caches are normally VIPT, which would however make this I-cache 16-way set associative in order for it to be 64 kB with 4 kB pages, which seems very far on the high side.
Are they using some sort of clever strategy to maintain coherency with a VIVT I-cache, or do they get away with a PIPT L1 cache on the instruction side, or what?
On the first diagram at the start , why is the Instruction Queue (IQ) located directly after the Instruction Cache (I-Cache) in the diagram ? Shouldn’t instructions be inserted into the IQ only after they are dispatched?