
Starfield on the RX 6900 XT, RX 7600, and RTX 2060 Mobile

I’ve seen quite a few comments on Discord, Reddit, Hacker News, and other places on our previous Starfield article. I wanted to address a few of these without calling anyone out, and touch on a few topics that didn’t make it into the previous article.
RDNA 2
Previously we looked at top end GPUs from AMD and Nvidia. Cards like the 7900 XTX and RTX 4090 serve a tiny portion of gamers thanks to their high prices, so cards from the previous generation remain very attractive. Here, I’ll be looking at the RX 6900 XT. The card was tested using the AMD Ryzen 9 7950X3D instead of the Intel i9-13900K that Titanic used in the previous article. Core performance boost was off for the 7950X3D, giving a constant 4.2 GHz maximum boost clock.

Frame captures were done with the same settings, namely ultra with 100% resolution scaling and FSR enabled. FSR doesn’t actually do any upscaling with these settings and just provides nicer anti-aliasing. RDNA 2 looks a lot like RDNA 3 so I’ll focus on significant changes. To start, let’s look at the three shaders analyzed in the previous article.
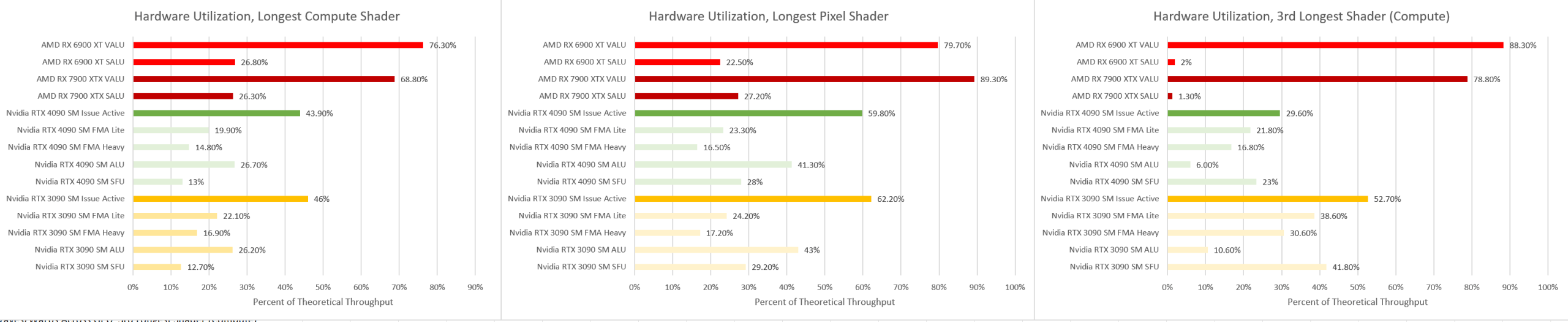
On RDNA 2, the pixel shader took longer than the compute shader. Hardware utilization is similar on the 6900 XT and 7900 XTX for the longest compute shader. However, the pixel shader sees lower utilization on the 6900 XT, while the 3rd longest shader (on RDNA 3) saw the opposite behavior.
Pixel Shader
RDNA 2 still achieves a very impressive 73.6% VALU utilization, but RDNA 3 gets to 89.3%. Unlike compute shaders, pixel shader programs have to send (export) a calculated pixel color value downstream. Then, fixed function GPU hardware (Render Output Units, or ROPs) combine outputs from different pixel shader invocations into a rendered image.

Latency is dominated by one of the export instructions, indicating that ROP hardware downstream is preventing pixel shader programs from finishing. It’s likely not able to keep up with the massive number of pixels required to render a 4K frame.
Second Longest Compute Shader: Dual Issue
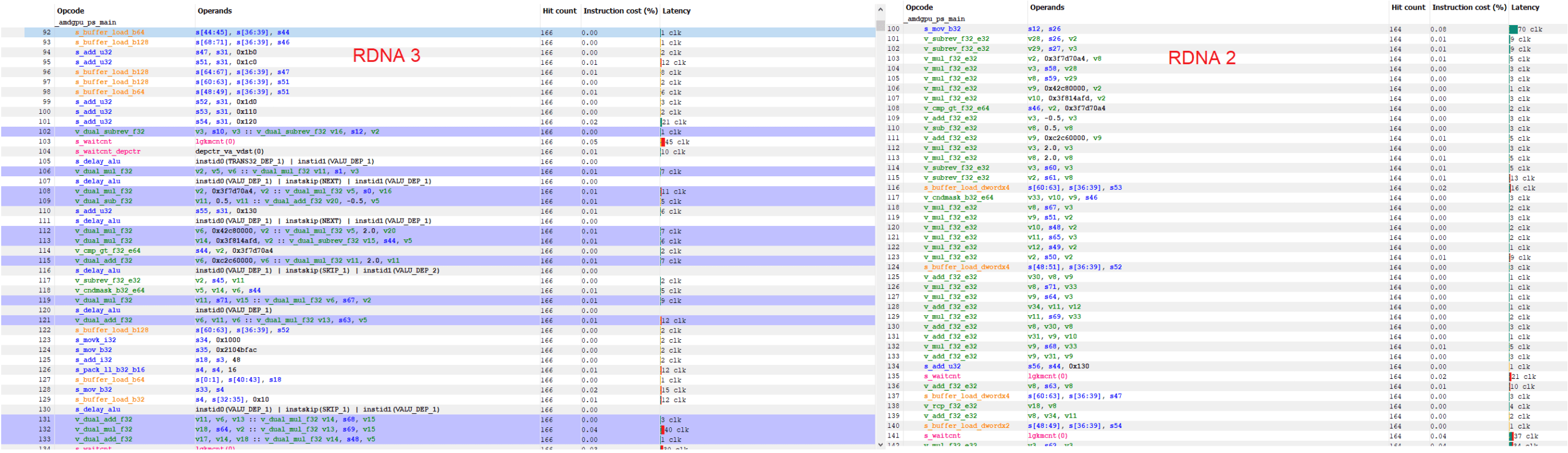
RDNA 2 is extremely compute bound in the second longest compute shader, where it sees 91.3% VALU utilization. Drivers opted for wave32 mode on RDNA 2, while RDNA 3 used wave64. That’s important because RDNA 3’s dual issue capability works very well with wave64. Because a wave64 instruction addresses pairs of 32-bit registers, it always satisfies dual issue constraints:

Because RDNA 3 can dual issue the most common instructions like FP32 adds, multiplies, and fused multiply adds, it ends up less compute bound than RDNA 2. Dual issue is less of a factor in wave32 code, where it depends on the compiler to find dual issue pairs.

As a side note, Nvidia says Turing, Ampere, and Ada Lovelace can “dual issue”, but that’s misleading because a SMSP can never issue more than one warp instruction per cycle. The term likely originated from the Turing era, which had 16-wide FP32 units per SMSP. Turing could only issue a FP32 instruction every other cycle. Ampere added another 16-wide FP32 unit, letting a SMSP issue a FP32 instruction every cycle. Dual issue for Nvidia refers to issuing instructions back-to-back, thus letting a SM achieve the same per-cycle FP32 instruction throughput as a RDNA 2 WGP, or Pascal SM for that matter.

Occupancy
High end RDNA 3 chips feature 192 KB of register file capacity per SIMD, compared to 128 KB on RDNA 2 and lower end RDNA 3 implementations. Even with 128 KB of registers, RDNA 2 still has twice as much register file capacity per SIMD lane than its Nvidia counterparts.

Therefore, RDNA 2 still enjoys an occupancy advantage, though one that’s not as great. The 3rd longest shader is an exception because RDNA 2 used wave32 mode. However, higher occupancy doesn’t really help RDNA 2 because it’s very compute bound. It needs more compute power, not more work in flight to feed the shader array.

Across the whole GPU, Nvidia’s 3090 keeps almost as much work in flight as the 6900 XT.
Caching
Cache hitrates are broadly similar.

RX 7600 at 1440P
Thanks to Jiray, we have a profile of the same scene from the RX 7600. He was only able to capture the profile at 1440p resolution due to VRAM restrictions. The card was able to run the game at 4K, but capturing a profile requires a few hundred MB of VRAM to buffer performance data. 8 GB of VRAM is already marginal for a modern title, and needing extra VRAM for profiling made things go south. On the CPU side, Jiray used a Ryzen 5 5600.

Despite the resolution difference, correlating events across the different cards is still quite easy. However, different resolutions mean smaller invocations. To be specific:

At 1440p, the RX 7600 did reasonably well compared to the RX 6900 XT at 4K. The scene took 39.7 ms to render, for 25.1 FPS. The RX 6900 XT at 4K got 28.3 FPS.

Hardware utilization follow the same patterns, but the RX 7600 had a harder time feeding itself in the pixel shader. 65.3% utilization is still very good and on par with what Nvidia achieved on Ampere and Ada. Unlike on the RX 6900 XT at 4K, ROPs did not appear to be a bottleneck. Rather, the RX 7600’s somewhat lower L2 hitrate could be responsible.

Occupancy is similar to RDNA 2 because non-chiplet RDNA 3 implementations use a 128 KB register file per SIMD. The 3rd longest shader is an exception because of wave64 mode, which requires twice as much register file capacity per wave register.

As we saw above, high occupancy isn’t needed to get high hardware utilization in that shader.
L2 caching on the RX 7600 can be weaker even at low resolutions. Going from 6 MB to 4 MB doesn’t make a big difference, but going down to 2 MB can be limiting in the first compute shader.
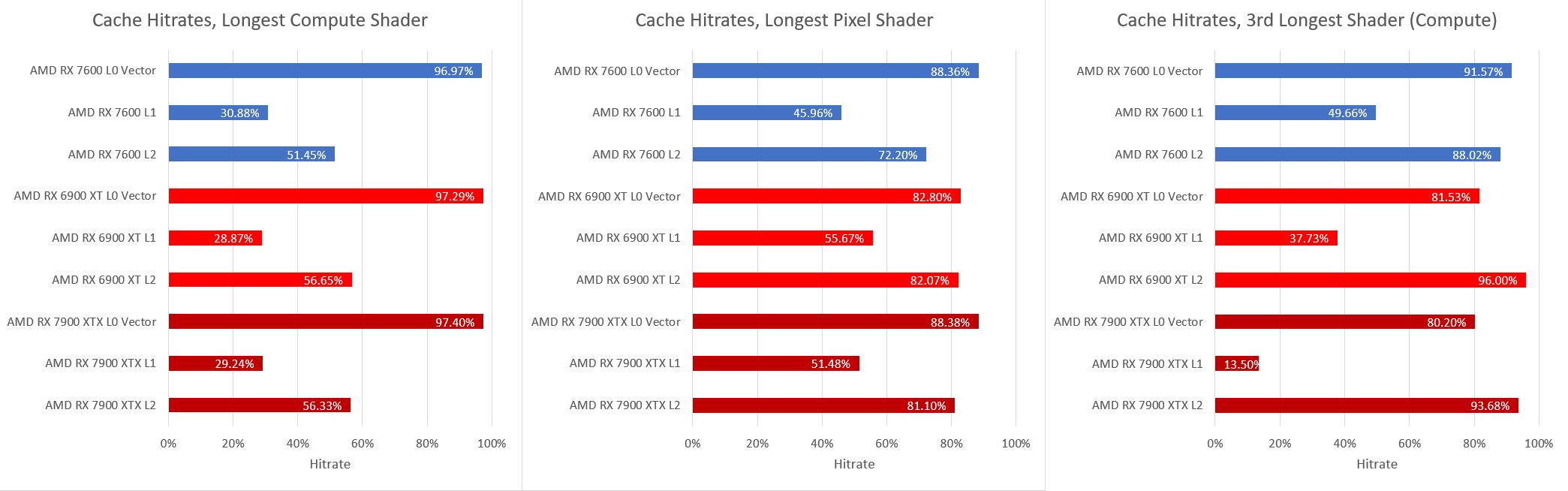
What’s More Expensive
Earlier I focused on the three most expensive events from the RX 7900 XTX’s perspective. However, there’s some variation what takes the most time on each card. The RX 6900 XT suffers on the pixel shader likely due to a ROP bottleneck, but is otherwise similar to the 7900 XTX.
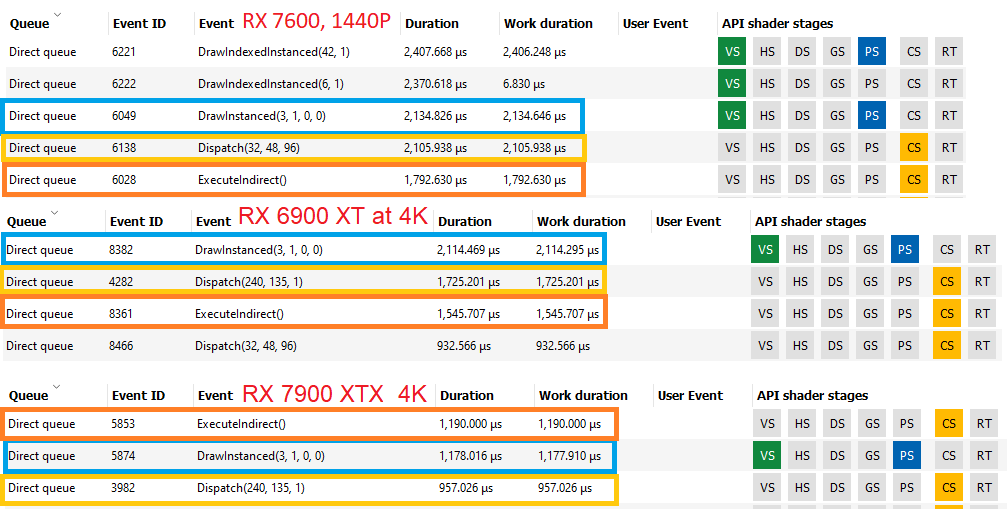
The RX 7600 also struggles on the pixel shader, but two other draw calls take even longer on the RX 7600. We can ignore the vertex shader only call because it only launched a single thread, and execution of that overlapped with the longest duration pixel shader (DrawIndexedInstanced(42,1)).
I’m not sure what’s going on with this pixel shader. The 7900 XTX and 6900 XT both blast through it in 0.56 and 0.75 ms respectively, with over 50% VALU utilization. The RX 7600 suffers with 29.2% VALU utilization and takes 2.4 ms. Infinity Cache capacity could be a factor. The RX 7600 has a much smaller last level cache than the other two cards. It could have suffered more misses, but there’s no way for us to confirm that because RGP doesn’t provide counters for the Infinity Cache.
Another culprit is that this shader didn’t scale down in resolution as much as you’d expect going from 4K to 1440p. The RX 7600 dispatched 676,054 invocations for the 1440p frame, while the 6900 XT dispatched 797,573 invocations. The RX 7600 therefore did 84% as much work, compared to the 44% as much work for the full screen pixel shader.
Nvidia’s RTX 2060: Instruction Starvation
Midrange GPUs represent a large portion of the PC gaming market, and have traditionally represented a sweet spot in terms of value. Today, Nvidia’s RTX 2060 is still up there on Steam’s Hardware Survey alongside midrange Pascal and Ampere cards. Besides being popular, Turing is interesting because Nsight Graphics can break down warp stall reasons. I’m pretty sure I found the longest compute shader and pixel shader in Nsight’s frame profiler, so let’s look at those. I’m running Starfield at 1080P with no upscaling and medium settings, since that can provide around 30 FPS and thus a playable experience. The RTX 2060 was paired with the Ryzen 7 4800H in a laptop.
While Nsight can break down why individual warps were not ready to execute, it does so with very Nvidia-specific terms. Here’s a quick translation to plain English for the most common warp stall reasons:

Warp stalls aren’t necessarily bad because GPUs can hide latency stalls or temporary spikes in execution unit demand by switching to another warp.
On the longest compute shader, SM issue utilization was 32.51% so there’s room for improvement. Occupancy was low at 14.91 warps per SM cycle, or just under 4 warps on average per SMSP out of 8 possible. The compiler allocated 127 registers for this shader, and occupancy was limited by register file capacity. A bigger register file would enable higher occupancy and improve utilization, but improving per-warp performance could help too.

Memory latency is the biggest issue. In life, there is no escaping death, taxes, and memory latency, but you can try. Better caching would lower average memory access latency and improve performance. Turing has a two level cache hierarchy. Both levels perform quite well, and warps averaging 12.34% of cycles stalled on memory latency isn’t a bad result.

Instruction cache misses are up next. GPU shader code has become more complicated over time, and that can mean larger instruction footprints. Turing has a 16 KB per-SMSP L0 instruction cache and a ~46 KB L1.5 instruction cache. With its 128-bit fixed length instructions, the L0 should hold up to 1024 instructions while the L1 holds just under 3072. AMD mainly uses 32-bit or 64-bit instructions (with very occasional 96-bit ones for immediate storage), so RDNA’s 32 KB L1 instruction cache can hold ~2048 to ~4096 instructions. RDNA 2 achieved a 99.83% instruction cache hitrate in this shader. Nvidia’s L1i hitrate is likely a bit lower. Without decoupled branch predictors, GPUs will struggle to hide instruction cache misses, so every miss can hurt hard.
After that, execution latency takes a toll as shown by “wait” and “short scoreboard”. “Short scoreboard” can also account for “shared memory” scratchpad accesses. But the shader didn’t allocate any scratchpad (LDS) space on RDNA 2, so it probably didn’t do that on Turing. Therefore, short scoreboard stalls would come from special math operations.
Pixel Shader
When we move over to the longest pixel shader, instruction cache misses go straight to the top. “No instruction” even eclipses “long scoreboard” as the top suspect for warp stalls. RDNA 2 saw 99.81% instruction cache hitrate in this shader, so something else is going on.

Warps spent 6.33% of cycles stalled on immediate/constant cache misses. Turing’s ~46 KB L1.5 instruction cache doubles as a mid-level constant cache, so the two are related. If the 2 KB L1 constant cache is seeing a lot of misses, constants are likely fighting with instructions over L1.5 capacity.

Memory latency comes up next. Turing’s cache hitrates are high, and spending 9.86% of cycles stalled waitng for data from cache or memory isn’t too bad. More occupancy would help hide memory latency. Nvidia’s compiler allocated 96 registers, limiting occupancy to 5 warps per SMSP out of eight possible.

Finally, stalls on instruction latency account for 8.2% of stall cycles, and stalls on longer latency special math operations account for another 4.21%. Other warp stall reasons are minor.
Rasterization in Action
Nsight Graphics can show the contents of various render targets, depth buffers, and stencil buffers as a frame is rendered. I don’t do graphics programming and don’t have a lot of insight into what’s going on, but it’s fun to watch a Starfield frame get drawn play by play.
The first notable set of actions fill out a depth buffer. A depth buffer tracks how far away objects are.
https://videos.files.wordpress.com/FSXu1nUz/1_depthbuffer.mp4
Next, the game calculates pixel colors for various objects in the scene. These are written to render target 0. Lighting and post processing effects haven’t been applied yet, so everything looks a bit flat.
https://videos.files.wordpress.com/J7xdYvGm/2_rendertarget0.mp4
Shortly after, pixel colors are calculated and written to another render target. This appears to include underwater plants, some reflections, and distant scenery.
https://videos.files.wordpress.com/knVWtftA/3_rendertarget3.mp4
Starfield then performs low resolution rasterization from a couple different perspectives. The render targets are rotated by 90 degrees. The first one appears to be an elevated view of New Atlantis.
https://videos.files.wordpress.com/HQlGZkAP/4_lowres_rendertarget.mp4
The second includes structures not visible at all from the player’s perspective, like the entrance to the lodge.
https://videos.files.wordpress.com/XuUtTZ8J/5_lowres_rendertarget_behind.mp4
I don’t know what these low resolution renders are used for, but they don’t take very long.
Final Words
AMD’s RX 6900 XT and RX 7600 show similar characteristics to the larger RX 7900 XTX, but there are a few differences worth calling out. The RX 6900 XT is occasionally ROP-bound. The RX 7600 might suffer from lower Infinity Cache hitrate, though we don’t have enough data to say for certain. Different draw calls become more expensive (or vice versa) depending on resolution.
AMD cards still keep themselves better fed thanks to larger register files and higher occupancy. This isn’t a case of optimizing for RDNA while forgetting to do so for Nvidia, because there’s no way around a smaller register file. I suppose it would be come less of an issue with simple shaders that don’t need a lot of registers, but larger, more complex shaders seem to be trending with recent games.

A return to the simplicity of the DirectX 9 and early DirectX 11 era is unlikely outside of small indie games. Nvidia might want to consider larger register files going forward. They haven’t increased per-SM vector register file capacity since Kepler. While Kepler was an excellent architecture, there is room for innovation.
“Of course they compared to Kepler. Everyone compares to Kepler”
Bill Dally at Hot Chips 2023 talking about the first TPU paper
Nvidia’s instruction cache sizes could use improvement too. Static scheduling helps reduce control logic power, but giant 128-bit instructions on Turing and subsequent architectures reduce the number of instructions the L1i can hold. This isn’t a problem for small shaders from the DirectX 9 and DirectX 11 era, but times are changing. To Nvidia’s credit, they have responded by increasing L1.5 cache size in Ampere and Ada. Assuming it’s still shared with the L1 instruction cache, that block of storage now has at least 64 KB of capacity as tested with OpenCL constant memory accesses.
RDNA 3’s dual issue capability is not heavily utilized as some comments imply. It does allow more efficient hardware utilization in wave64 mode, but most shaders use wave32. VOPD code generation is hit or miss there.
In the end, Starfield runs well on a wide range of AMD and Nvidia hardware. I played the game for a while on a GTX 1080 as well, and aside from a few possibly driver related issues that caused occasional black screens, the game ran comfortably at around 30 FPS at 1080P medium. The RTX 2060 mobile also provided a playable experience under the same settings.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.