
Sapphire Rapids: Golden Cove Hits Servers

Last year, Intel’s Golden Cove brought the company back to competitive against AMD. Unfortunately for Intel, that only applied to the client space. AMD’s Rome and Milan CPUs have steadily eroded Intel’s server dominance. With the bulk of recently added systems on TOP500 using Rome or Milan, both architectures did well in HPC too. Sapphire Rapids (SPR) is set to be Intel’s response to AMD’s recent EPYC success.
Compared to client’s Golden Cove, SPR’s highlights include a modified cache hierarchy, powerful vector units, and of course, higher core count. We already covered Golden Cove, so we’re going to focus on the changes made for the server variant, and go over details that we weren’t able to test last year. Testing was performed on Intel’s Developer Cloud, where the free instance provides access to a few cores on an Xeon Platinum 8480. We also got some data from Google Cloud Platform, which offers preview access to SPR.
Overview
Sapphire Rapids uses the basic Golden Cove architecture, but brings in AVX-512 support with the 2×512-bit FMA throughput similar to Intel server CPUs. To further increase matrix multiplication throughput, SPR adds AMX support. Additionally, it features built-in accelerators for cryptography and compression.
Clock Ramp Behavior
Sapphire Rapids idles at 800 MHz and exhibits very slow clock speed ramp behavior. It reaches an intermediate 2 GHz clock speed after 35 ms. Afterwards, it takes over 1.6 seconds before boosting to 3.1 GHz for about 8 ms, and then reaches its maximum boost clock of 3.8 GHz.

This boosting behavior is likely specific to Intel DevCloud and not indicative of how fast SPR can boost, but it did complicate microbenchmarking.
Vector Execution
Client Golden Cove delivered excellent vector performance, and the server variant is even more ambitious. AVX-512 is enabled because there are no worries about hybrid setups with mismatched ISA extension support.
Like Intel server architectures since Skylake-X, SPR cores feature two 512-bit FMA units, and organize them in a similar fashion. One 512-bit FMA unit is created by fusing two 256-bit ones on port 0 and port 1. The other is added to port 5, as a server-specific core extension. The FMA units on port 0 and 1 are configured into 2×256-bit or 1×512-bit mode depending on whether 512-bit FMA instructions are present in the scheduler. That means a mix of 256-bit and 512-bit FMA instructions will not achieve higher IPC than executing 512-bit instructions alone.
Unlike early AVX-512 chips, SPR does not appear to have fixed frequency offsets when dealing with 512-bit vectors. Instead, clock speeds go all over the place. There’s no clear correlation between clock speed and instruction mix, possibly because turbo boost was active on the shared server. But we did see clock speeds as high as 3.8 GHz with 512-bit vectors, which means there’s no set-in-stone AVX-512 clock penalty.

Besides execution units, SPR needs register files for AVX-512 mask and vector registers. We measured about 144 renames for AVX-512 mask registers. Eight entries would be required to hold architectural state, implying a total of 152 mask register file entries. That’s unchanged from Sunny Cove, suggesting that the mask register file was already large enough to avoid stalling the renamer.
Vector registers are more complicated. Prior Intel CPUs had the same renaming capacity regardless of register width. Golden Cove changes this and only supports 512-bit width for a subset of its vector registers. Sapphire Rapids adopts the same optimization.

We mentioned before that Golden Cove likely used this strategy because Intel wanted to provide increased renaming capacity for scalar and AVX2 code, without the area expense of making every register 512-bit capable. Curiously, the measured register file capacities are slightly lower than on client Golden Cove. Even with this area saving measure, Sapphire Rapids and Golden Cove have significantly more 512-bit register renaming capacity than Zen 4.
Cache Hierarchy
As is Intel tradition, the server variant of Golden Cove gets a modified cache setup starting with L2. Client Golden Cove already had a rather large 1280 KB L2 cache, and SPR bumps capacity to 2 MB. Raptor Lake brings similar L2 capacity to client chips, and we do see similar latency characteristics.

To be specific, Raptor Lake and Sapphire Rapids both have the same 16-cycle L2 latency. That’s one cycle more than Golden Cove, and two cycles more than server Ice Lake. Compared to AMD, Intel continues the trend of using a larger, higher-latency L2. Zen 3, for example, has a 512 KB L2 with 12 cycles of latency. SPR does clock higher, but the difference is not large enough to offset the increase in L2 pipeline depth.
Intel’s decision to trade latency for capacity is likely driven by their focus on high vector performance, as well as an emphasis on high L3 capacity over L3 performance. Sapphire Rapids suffers from an extremely high L3 latency around 33 ns. L3 latency also regressed by about 33% compared to Ice Lake SP. I think this regression is because Intel’s trying to solve a lot of engineering challenges in SPR.

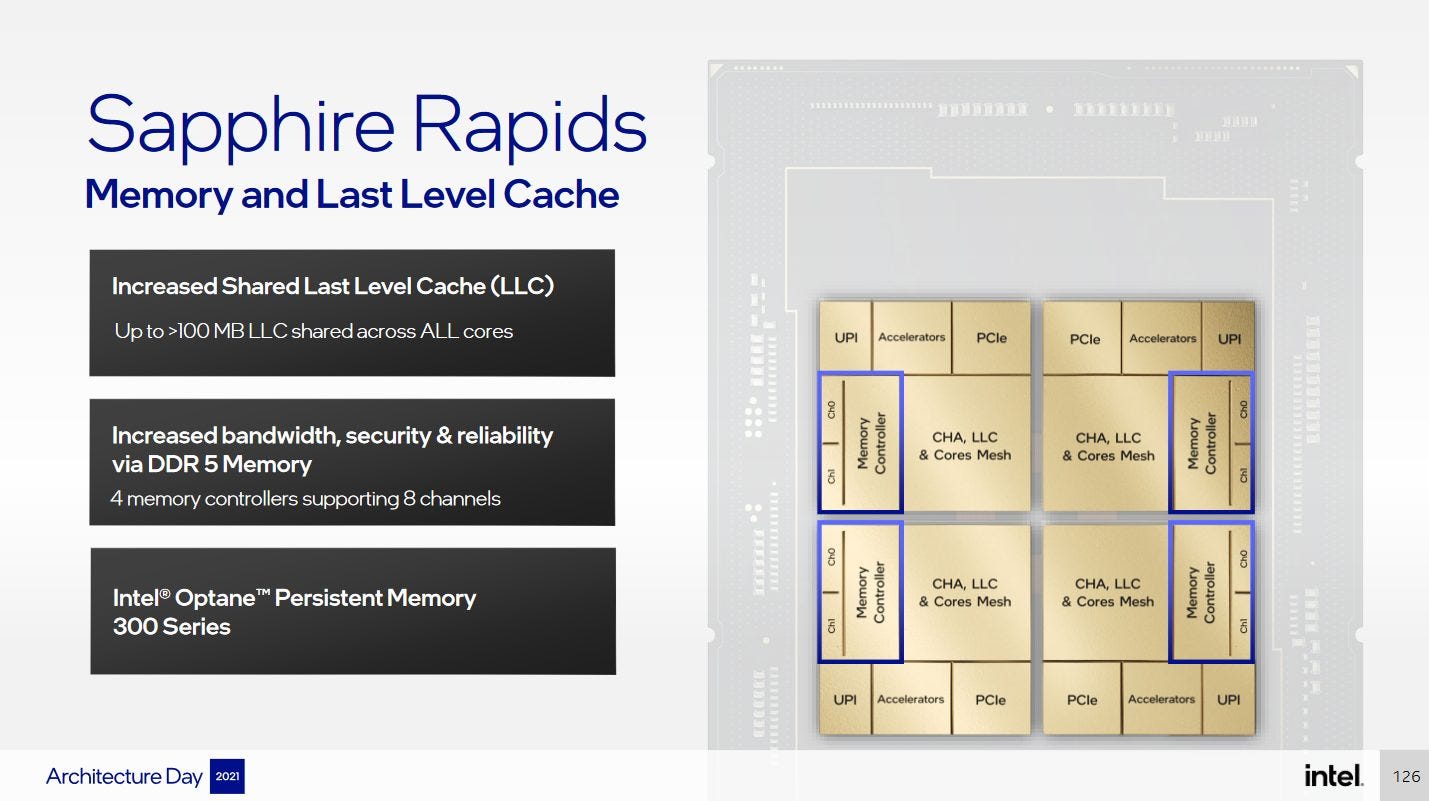
On Intel DevCloud, the chip appears to be set up to expose all four chiplets as a monolithic entity, with a single large L3 instance. Interconnect optimization gets harder when you have to connect more nodes, and SPR is a showcase of this. Intel’s mesh has to connect 56 cores with 56 L3 slices. Because L3 accesses are evenly hashed across all slices, there’s a lot of traffic going across that mesh. SPR’s memory controllers, accelerators, and other IO are accessed via ring stops too, so the mesh is larger than the core count alone would suggest. Did I mention it crosses die boundaries too? Intel is no stranger to large meshes, but the complexity increase in SPR seems remarkable.

Intel engineers who worked on this probably feel like a college student getting taught Green’s, divergence, and Stokes’ theorems separately during a typical multivariable calculus course. They’re not hard to understand on their own. Similarly, Intel made large meshes before in Ice Lake, and tested EMIB in Kaby Lake G. But then the final exam for next semester’s electromagnetics class makes the poor students put all of those together in a single electrodynamics problem that takes five pages of work to solve, while applying a boatload of new stuff for good measure. In the same way, Intel engineers now have an order of magnitude more bandwidth going across EMIB stops. The mesh is even larger, and has to support a pile of accelerators too. L3 capacity per slice has gone up too, from 1.25 MB on Ice Lake SP to 1.875 MB on SPR.
From that perspective, Intel has done an impressive job. SPR has similar L3 latency to Ampere Altra and Graviton 3, while providing several times as much caching capacity. Intel has done this despite having to power through a pile of engineering challenges. But from another perspective, why solve such a hard problem when you don’t have to?

In contrast, AMD has opted to avoid the giant interconnect problem entirely. EPYC and Ryzen split cores into clusters, and each cluster gets its own L3. Cross-cluster cache accesses are avoided except when necessary to ensure cache coherency. That means the L3 interconnect only has to link eight cache slices with eight cores. The result is a very high performance L3, enabled by solving a much simpler interconnect problem than Intel. On standard SKUs, AMD can’t get anywhere near as much capacity. But AMD can employ 3D stacking on “V-Cache” SKUs, which gets a 64 MB cache die on top of the regular core cluster. Obviously this comes at additional cost, but it gives AMD high L3 capacity with much better L3 performance than SPR. If a program’s threads are mostly working on separate data, a V-Cache equipped AMD chip can also bring more total caching capacity to bear, because the program will use the sum of L3 cache capacities across all the clusters.
Once we get out to DRAM, things tend to even out between the various server chips. SPR’s DRAM latency was measured at just above 107 ns, with a 1 GB array and 2 MB pages. SPR is thus bracketed by two Milan SKUs, with the EPYC 7763 and 7V73X getting 112.34 and 96.57 ns with the same test parameters respectively. Amazon’s Graviton 3 lands in roughly the same area with 118 ns of DRAM latency. All of these were tested on cloud systems with unknown memory configurations, so we’re not going to look too far into memory latency.
Latency with Different Configurations
Intel can divide Sapphire Rapids chips into smaller clusters too, potentially offering improved L3 performance. Google’s cloud appears to do this, since we see less L3 capacity and better L3 latency. However, the latency difference is minimized because Google is running SPR at a much slower 3 GHz.

The improvement from a smaller cluster is more noticeable if we look at cycle counts. L3 latency drops from 125 cycles to 88. However, we can’t attribute all of this to the smaller cluster arrangement. If both clouds ran the mesh at similar clocks, then lower core clocks on Google’s cloud could be partially responsible for the difference.

AMD, in contrast, runs their L3 at core clocks. Zen 3 has around 47 cycles of L3 latency, and around 50 cycles with V-Cache. SPR’s chiplet configuration and EMIB links therefore don’t bear complete blame for the high L3 latency. Even with fewer EMIB links in play, SPR still sees worse L3 latency than Zen 3.
Latency with 4 KB Pages
2 MB pages are good for examining cache latency in isolation, but the vast majority of applications use 4 KB pages. That means virtual addresses are translated to physical ones at 4 KB granularity. Managing memory in smaller page size helps reduce fragmentation and wasted memory, but means that each TLB entry doesn’t go as far.
Like Golden Cove, Sapphire Rapids takes an extra 7 cycles of latency if it has to get a translation out of its L2 TLB. But unlike client Golden Cove, SPR has a very slow L3. Adding address translation latency on top of that makes it even worse.
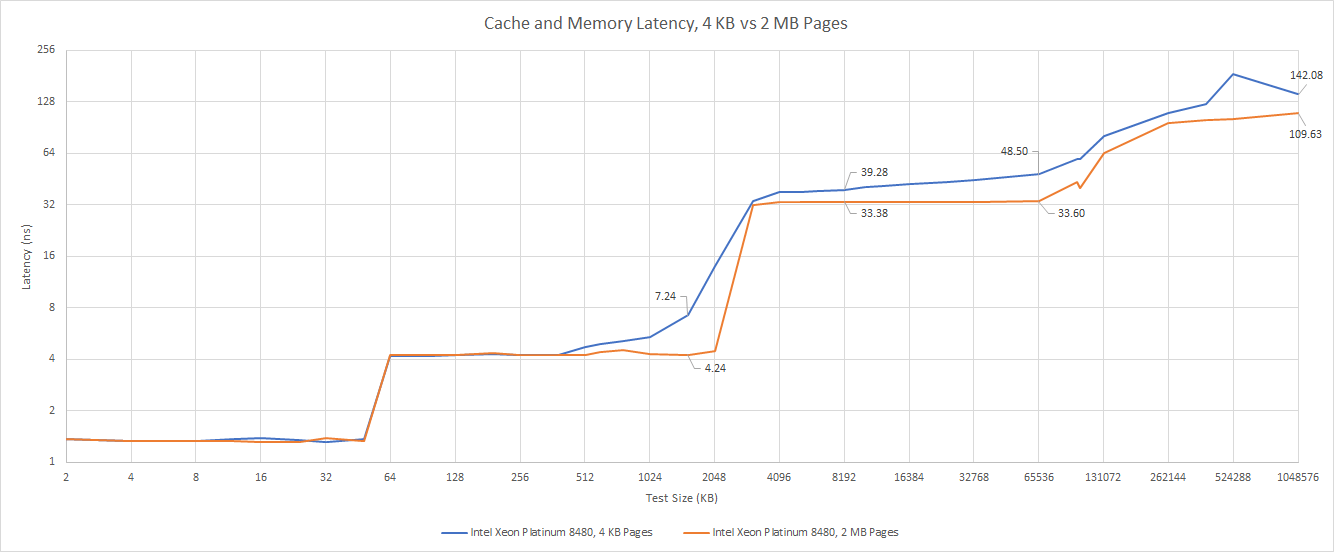
Up until we exceed L2 TLB coverage, we see about 39 ns of effective access latency for the L3 cache. As we spill out of that though, we see an incredible 48.5 ns of effective L3 latency.
Bandwidth
Like prior Intel server CPUs, Sapphire Rapids can sustain very high bandwidth from its core-private caches. The L1 data cache can service two 512-bit loads every cycle, and the L2 has a 64 byte per cycle link to L1. When running AVX-512 code, SPR has a large advantage over competing AMD architectures as long as memory footprints don’t spill out of L2.
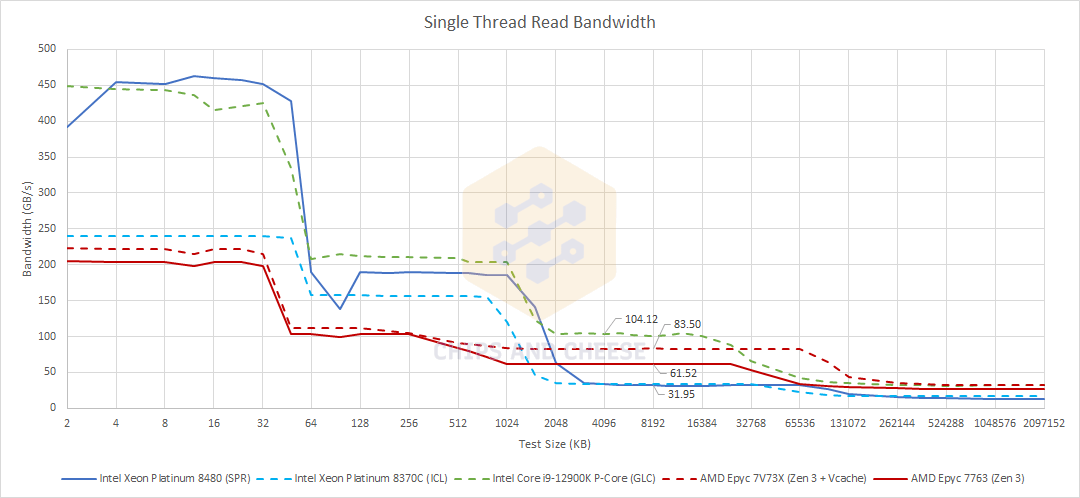
SPR’s L1 and L2 bandwidth is actually neck and neck with i9-12900K’s. That’s quite impressive for a 3.8 GHz core. Even though the i9-12900K can clock above 5 GHz, it’s held back by lack of AVX-512 support. With AVX-512, an i9-12900K’s P-Core can pull over 600 GB/s from its L1D, but that’s not too relevant because AVX-512 is not officially supported on Alder Lake.
AMD takes the lead once L2 capacity is exceeded. Client Golden Cove dramatically improved L3 bandwidth and was competitive against AMD in that regard, but these improvements don’t apply to SPR. SPR’s per-core L3 bandwidth is around the same as server Ice Lake’s. Bandwidth is probably latency-limited here.

GCP’s SPR offering can get slightly better L3 bandwidth from a single core, indicating that bandwidth is latency limited. After all, Little’s Law states that steady state throughput is equal to queue size divided by latency. L1 and L2 bandwidth is notably lower on GCP, because Google locks the CPU to 3 GHz. In a cloud offering, SPR is not able to show off its single-threaded performance potential because cloud providers prefer consistent performance. Customers would be unhappy if their clock speeds varied depending on what their neighbors were doing, so clock speeds end up capped at what the chip can sustain under the worst case scenarios.
Of course, this applies to other server CPUs too. But the Milan-based EPYC 7763 does achieve better clocks on the cloud with four more cores. Against higher core count chips from AMD, SPR will need a per-core performance advantage to shine. If SPR gets limited to low clocks, I’m not sure if that’ll happen.
Multi-threaded Bandwidth
Per-core bandwidth provides interesting insights into the architecture. But multi-threaded applications multiply bandwidth demands and put most pressure on shared cache and memory. Unfortunately, we don’t have access to a bare metal SPR machine, but we can make some projections based on testing with up to 32 cores. Let’s start with the L3 cache.

SPR’s L3 is clearly non-inclusive, as the bandwidth test shows that the amount of cacheable data corresponds to the sum of L2 and L3 capacity when each thread is working with its own data. With 32 cores, we get around 534 GB/s of L3 bandwidth.

If L3 bandwidth scaled linearly past that point, which is unlikely, we would see over a terabyte per second of L3 bandwidth. While impressive on its own, a V-Cache-equipped Milan instance can achieve over 2 TB/s, with the same core count.
In DRAM-sized regions, we get just over 200 GB/s bandwidth. With more cores loaded, SPR will probably be able to get close to its theoretical DDR5 bandwidth capabilities.
Frontend Bandwidth
If code footprints spill out of the L1 instruction cache, SPR’s cache changes can have notable effects on instruction bandwidth too. Using 8B NOPs, we can see immediate instruction bandwidth bottlenecks after a L1 instruction cache miss. All CPUs here cap out at 16 bytes per cycle when running code out of L2. However, Sapphire Rapids takes a clear instruction bandwidth hit relative to client Golden Cove and server Ice Lake. This is somewhat surprising, because a cycle or two of latency shouldn’t make a big difference.
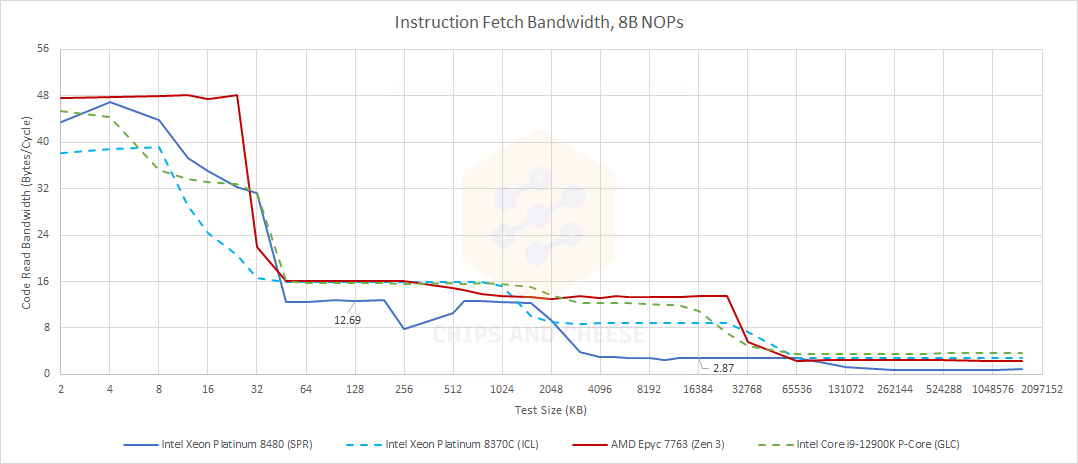
On a L2 miss, SPR’s instruction fetch bandwidth goes straight off a cliff. Golden Cove and Zen 3 by comparison still do fairly well with extremely large code footprints. If we switch over to 4B NOPs, which is more representative of typical instruction lengths, Golden Cove and Zen 3 can maintain very high IPC out of L3. Server Ice Lake is worse of course, but maintaining over 2 IPC is still a very good result.

Sapphire Rapids however can’t even maintain 1 IPC when running code from L3. Other CPUs don’t drop to similar levels until code spills out into DRAM. This could be a significant bottleneck for applications with large code footprints.
Load/Store Unit
The load/store unit on out-of-order CPUs tends to take up a lot of die area, and has the unenviable job of making sure memory dependencies are respected without unnecessarily stalling memory operations. At the same time, it has to moderate the amount of work it does to allow high clock speeds and low power consumption. We didn’t cover Golden Cove’s load/store unit in detail, so we’ll take this opportunity to do so.
Like Zen 3, Sapphire Rapids can do zero latency store forwarding for exact address matches, and actually sustain two loads and two stores per cycle in that case. Forwarding isn’t as fast if accesses cross a 64B cacheline boundary, but is still very fast with a 2-cycle latency if only the store is misaligned. If both the load and store are misaligned, latency increases to 8-9 cycles, which is still quite reasonable.

Forwarding latency is 5 cycles if the load is contained within the store, which means there’s no penalty compared to an independent load. Partial overlaps cause store forwarding to fail, with a penalty of 19 cycles.
Zen 3 has a higher 7-8 cycle latency if it has to forward a load contained in a store without a matching start address. However, it’s slightly faster when forwarding accesses that cross a cache line. As long as the address matches, load latency doesn’t exceed 5 cycles.
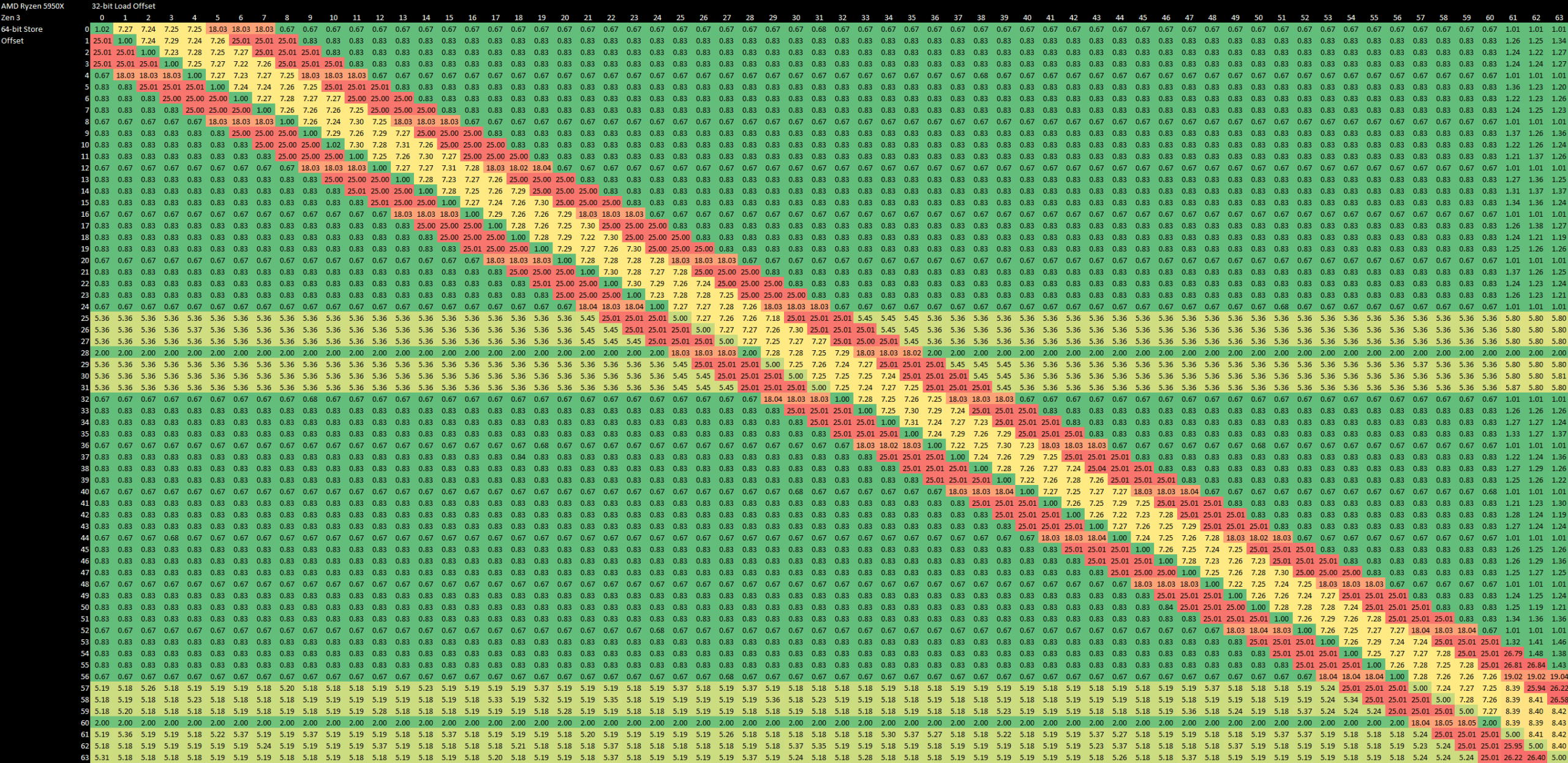
From the integer side, Golden Cove has a very competent forwarding mechanism. The vector side is a bit less flexible though. Golden Cove can forward either half of a 128-bit store to a 64-bit load, but can’t handle other cases where the load is contained within the store. Forwarding latency is higher at 6-7 cycles, and the penalty for a failed forwarding case is 20-22 cycles.

Unlike Golden Cove, Zen 3 seems to use a very similar mechanism for dealing with vector memory accesses. Forwarding latency is higher at 9 cycles, but AMD can deal with all cases where the load can get all of its data from an in-flight store. If there’s only a partial overlap, Zen 3 suffers a 20 cycle penalty if the store is 4B aligned, or a 27 cycle penalty if not.

L1D alignment is another difference between Zen 3 and Golden Cove. Zen 3’s data cache deals with data in 32 byte chunks, and incurs misaligned access penalties at 32 byte boundaries. Zen 3 further does some checks at 4 byte granularity, as accesses that cross a 32 byte boundary are more expensive if they aren’t aligned to a 4B boundary.
4K Page Penalties
We saw above that crossing a 64 byte cacheline boundary tends to incur penalties, because one access requires two L1D lookups. Crossing a 4096 byte boundary introduces another layer of difficulty, because you need two TLB lookups as well. Sapphire Rapids handles split-page loads with a 3 cycle penalty. Split page stores incur a hefty 24 cycle penalty. Zen 3 is better with loads and takes no penalty at all, but eats a similar 25-27 cycle penalty for split page stores. The 25 cycle penalty again applies if the store is 4B aligned.
Minecraft Performance
Minecraft, a popular block game, has a variety of ways to completely saturate your CPU. Making it a perfect test for comparing CPU architectures. We have devised three quick tests to compare the most popular server architectures. The first test is the bootup time of a fresh vanilla Minecraft server that at first heavily utilizes your available memory bandwidth followed by very high instruction throughput by the end. The second bootup test utilizes an optimized server software called Paper and focuses more on loading data into memory from a single CPU core. The third test is a world generation speed test on a modified Minecraft server utilizing Fabric. All Minecraft benchmarks were ran on Google Cloud Platform. For the ARM instances we were unable to create 8 vCPU instances so we used 4 vCPU instances instead. All Minecraft testing and this small introduction to our Minecraft testing was conducted by TitanicFreak.

SPR achieves very good server start times. Intel’s new server CPU certainly has potential in this workload, especially considering its low 3 GHz clock speed on Google Cloud. For comparison, Zen 2 and Zen 3 ran at 3.22 GHz, while Cascade Lake and Ice Lake ran at 3.4 GHz. However, chunk generation performance was not as good. In that test, SPR failed to match prior CPUs from both Intel and AMD.
Chunk generation has a small cache footprint, and SPR gets a very high 2.6 IPC in that workload. There aren’t any big performance issues here. SPR sees just 0.33 memory loads retired that experienced a L2 miss for every 1000 instructions (MPKI). Zen 3 sees 1.03 L2 MPKI, though that count includes speculative accesses. From the instruction side, Zen 3 and SPR both enjoy over 91% micro-op cache hit rate. One guess is that all the CPUs are limited by the amount of instruction level parallelism in the workload, and how well they can exploit that ILP with the execution latency and L1/L2 latency they have. SPR runs at a lower clock speed on Google’s cloud, which means it has longer actual execution latencies and cache latencies. Without being able to exploit some architectural advantage to get much higher IPC than Zen 3, SPR falls behind.
Conclusion
Since Skylake-X, Intel’s server strategy has prioritized scaling core counts within a monolithic setup, while providing very strong vector performance. Sapphire Rapids continues that strategy. Golden Cove already provided a foundation with very strong vector performance. Sapphire Rapids takes that further by implementing two 512-bit FMA units. AMX is a cherry on top for workloads that focus on matrix multiplication. AI workloads come to mind, though such tasks are often offloaded to GPUs or other accelerators.
The monolithic setup front is more interesting, because SPR’s high core counts and large vector units made a monolithic die impractical. Intel accomplished their goal by running a huge mesh over EMIB links. Behind the scenes, Sapphire Rapids must have required some herculean engineering effort, and the drawbacks are noticeably heavy. L3 latency is high and bandwidth is mediocre. If SPR faces an all-core load with a poor L2 hit rate, multi-threaded scaling could be impacted by the limited L3 bandwidth. With that in mind, Sapphire Rapids should offer Intel some valuable engineering experience for future products. A number of cutting edge architectural features that were initially deployed in Netburst later came back in Sandy Bridge, and put Intel in an incredibly strong position. SPR should give Intel a better understanding of very high bandwidth cross-die connections. They also get insights from handling a mesh that services a lot of agents with varying bandwidth demands. On top of that, SPR debuts AMX, on-die accelerators and HBM support with modes similar to what we saw in Knight’s Landing. There’s a lot of potential learning experiences Intel can have with SPR, and you bet Intel’s going to learn.
SPR’s approach has advantages too. The unified L3 offers a lot of flexibility. One thread can use all of the L3 if it needs to. Data shared across threads only has to be cached once, while EPYC will duplicate shared data across different L3 instances. Intel also enjoys more consistent latency for cache coherency operations. However, I haven’t come across any applications that seem to care about that last point. Every time I look, memory accesses are overwhelmingly satisfied from the regular cache/memory path. Contested atomics are extremely rare. They tend to be an order of magnitude rarer than L3 misses that go to DRAM. But that doesn’t mean such an application doesn’t exist. If it does, it may see an advantage to running on Sapphire Rapids.
On that note, I can’t help but think SPR only has a narrow set of advantages in the server market. The cache coherency advantage will only apply if a workload scales out of an EPYC cluster, but doesn’t scale across socket boundaries. We already saw AMD’s V-Cache providing situational advantages. SPR has slightly higher caching capacity but far worse performance characteristics, which will make its advantages even less widely applicable. The L3 capacity flexibility is overshadowed by AMD’s L3 performance advantages, and EPYC has so much L3 that it can afford to duplicate some shared data around and still do well.
There’s really something to be said about working smarter, not harder. AMD avoids the problem of building an interconnect that can deliver high bandwidth and low latency to a ton of connected clients. This makes CCD design simpler, and let EPYC go from 32 cores to 64 to 96 without worrying about shared cache bandwidth. The result is that AMD has a large core-count advantage over Intel, while maintaining very good per-core performance for applications that aren’t embarrassingly parallel. SPR’s features may let it cope under specific workloads, but even that advantage may be blunted simply because Genoa can bring so many cores into play. Zen 4 cores may not have AMX or 512-bit FMA units, but they’re still no slouch in vector workloads, and have excellent cache performance to feed their execution units.
Final Words
Sapphire Rapids however might do well in the workstation role. There, users want solid performance in tasks with varying amounts of parallelism. SPR may not have chart topping core counts, but it can still scale well over the 16 cores available in desktop Ryzen platforms. With low parallelism, SPR could use high boost clocks and lots of cache to turn in a decent performance.
Of course AMD can combine good low-threaded and high-threaded performance in their Threadripper products. But Threadripper has not been given a thorough refresh since the Zen 2 days. Zen 3-based Threadripper only got a “Pro” launch with extremely high prices. This leaves a gaping hole in AMD’s offerings between 16 core Ryzens around $700 and the 24 core Threadripper Pro 5965WX sitting above $2000. Intel can use SPR to drive a truck through that hole.
In any case, I’m excited about future server products from Intel. The company no longer enjoys server market dominance as they did ten years ago, and SPR is unlikely to change that. But Intel is building a lot of technical know-how when they develop a product as ambitious as SPR. Certainly there’s a lot of blocks within SPR that have a lot of potential on their own. Accelerators, HBM support and high bandwidth/low latency EMIB links come to mind. Perhaps after a few generations, they can use that experience to shake up the server market, just as Sandy Bridge shook up everything years after Netburst went poof.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.