
A Preview of Raptor Lake’s Improved L2 Caches

Caching is important. We recently got a subset of our test suite run on an engineering example of Raptor Lake. Those results let us take a look at Intel’s changes to their caching hierarchy. Because clock speeds won’t be final on an engineering sample, we’ll focus on looking at L2 cache changes here, and normalize results for clock speed. There’s no change to the L1. L3 performance is heavily dependent on ring clock, and we can’t normalize for both ring clock and core clock. And of course, memory latency and bandwidth is dependent on memory configuration.
P-Core
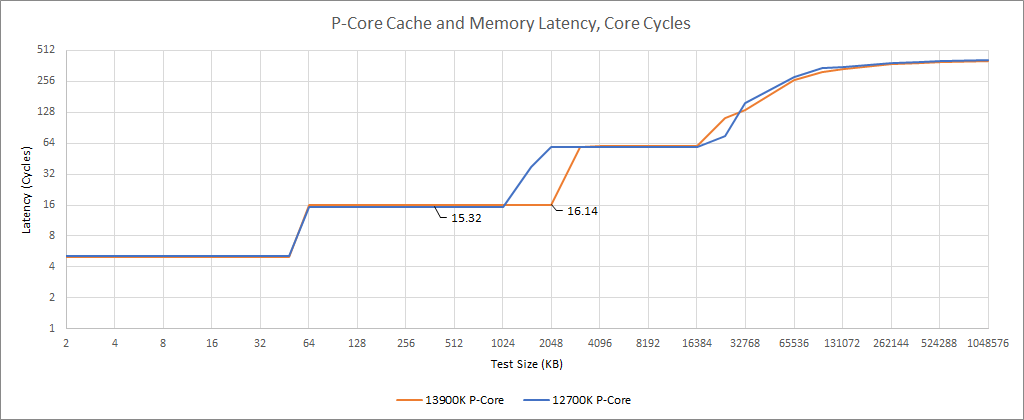
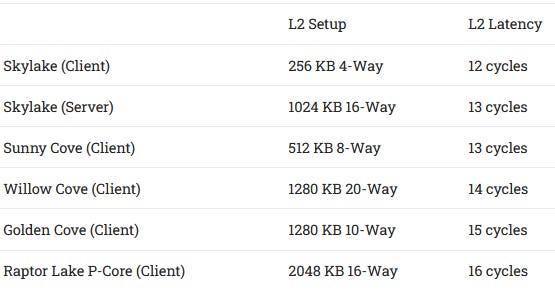
Raptor Lake’s P-Cores get a L2 capacity increase to 2 MB, up from 1.25 MB. Latency increases by a single cycle, but Golden Cove’s massive structures should be able to absorb this quite easily. Pulling data from L1 or L2 instead of L3 means lower latency, higher bandwidth, and lower power costs, because data doesn’t have to be moved as far. Intel has been iterating on their L2 cache for the past few generations, and Raptor Lake continues that trend.
L3 latency might have changed by a cycle or so, but it’s probably not worth reading too much into. Because Intel’s L3 cache sits on the uncore clock domain, its latency will vary based on uncore clock. And uncore clock isn’t final either.
We can also look at bandwidth:

Or not. There’s really nothing unexpected here. L2 and L3 cache bandwidth per cycle is basically identical. The P-Core on Raptor Lake was a touch less efficient with L1D bandwidth, but I’ll chalk that up to engineering sample funkiness.
E-Core
E-Cores on Raptor Lake also enjoy a large increase in L2 capacity. Intel has doubled its size from 2 MB to 4 MB. That’s a lot of cache. For perspective, Intel laptop chips a few years ago had 4 MB L3 caches, and that’s a last level cache. L2 cache latency has not increased, and remains at 20 cycles.
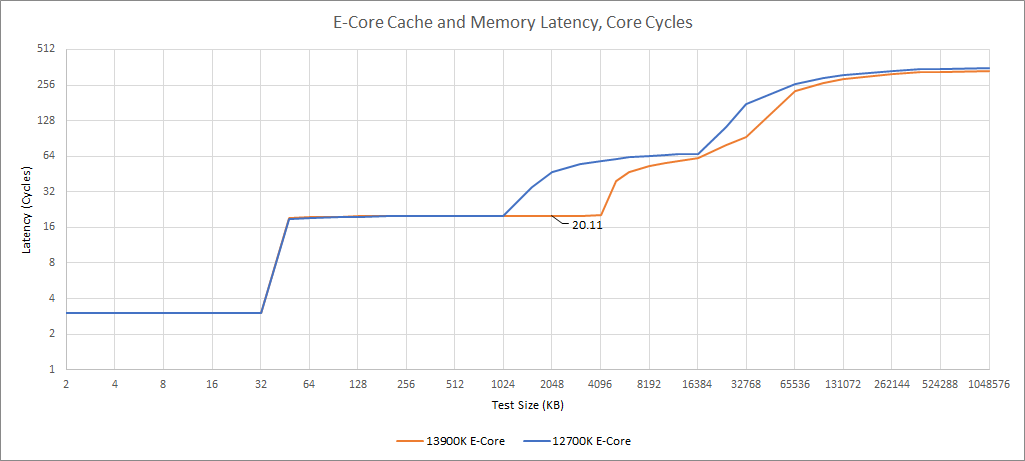
These L2 changes are very good news for the E-Cores, and perhaps even more important than the P-Cores’s L2 change. The E-Cores have smaller out-of-order execution buffers than the P-Cores, and will tend to suffer more when they have to access the higher latency L3 cache. Also, keeping the same latency means that the larger L2 should offer a straightforward IPC increase. Of course, the benefits discussed earlier with the P-Cores still apply – a larger L2 should provide better power efficiency and allow performance to scale better as clock speed increases.
Additionally, L3 latency is lower, both in terms of cycles and actual time. Latency with a 16 MB test size gives 17.68 ns on the 12700K, and 16.64 ns on the 13900K engineering sample. Again we’re not going to look too hard at L3 latency when core clocks, uncore clocks, and the difference between them is not final. Still, this is a promising sign for Raptor Lake, because Alder Lake’s L3 latency from the E-Core perspective was pretty bad. 16.64 ns isn’t great either, but every little bit helps, especially when the E-Cores don’t have out-of-order buffers large enough to hide L3 latency.
Now let’s look at bandwidth:

There’s not much worth commenting about with regards to bandwidth. L2 and L3 cache bandwidth are pretty much the same in terms of bytes per core cycle. The L2 size increase discussed earlier is clearly visible.
L2 evolution in Intel’s Atom line isn’t as straightforward, partially because the L2’s role changed as Atom cores moved from being purely small, low power cores to tackle other roles. In Goldmont Plus’s days, the L2 cache acted as the last level cache and served a similar role to the L3 in mainstream Intel chips. When Atom started filling the E-Core role in Intel’s hybrid setups, it was integrated onto the ring bus, which meant the L2 stopped being the last level cache. Gaining a L3 cache meant a L2 miss didn’t always incur a DRAM access that’d cost hundreds of cycles. The L2 could therefore be smaller.
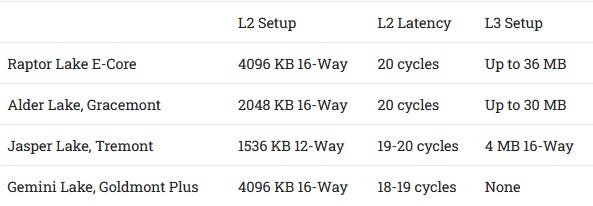
We’ve come full circle with Raptor Lake. Intel’s L3 cache has increased in capacity over the past few generations, but latency has gone up too. Alder Lake’s L3 has a latency of over 60 cycles from the E-Cores, so insulating them from L3 latency could be quite beneficial.
Conclusion
Feeding the cores is a large part of improving CPU performance today. Raptor Lake’s larger L2 caches represent a sensible evolution in Intel’s cache setup. For the P-Cores, their 2 MB L2 caches are a huge step up from the mediocre 256 KB ones found on Comet Lake just a couple generations ago. Meanwhile, the E-Cores get L2 cache capacity that matches the L3 cache size on mobile and console Zen 2 chips, as well as dual core low power Intel chips from a few generations ago. There’s barely going to be any ring bus traffic from the E-Core clusters, since the L2 will be large enough to catch the vast majority of memory accesses.
I ran some Champsim simulations with the different cache sizes, and expect IPC gains to be minor (simulations showed under 1% IPC improvement, though I feel the setup tends to underestimate gains). But focusing on IPC gains at fixed clock speed misses the larger picture. L2 misses decreased by 14.55% and 16.05% on the simulated P-Core and E-Core configurations, respectively. That means less data has to be pulled across the chip’s ring bus, saving power. High performance CPUs are often power limited, so using less power to move data around means that power could be spent hitting higher clocks. At higher clocks, Intel’s ring bus often doesn’t keep pace with core clock. Catching more accesses within L2 will minimize IPC loss as clock speed increases. And of course, there are bandwidth benefits to getting higher L2 hitrate. All of that comes together to give Raptor Lake some nice potential for performance and power efficiency increases, even if Intel doesn’t change the core architecture.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.
Credits
Special thanks to Seby for running the tests. Based on integer addition latency, this Raptor Lake engineering sample appeared to run the P-Cores at 4.9 GHz, and E-Cores at 3.72 GHz. Again, these clocks are definitely not final, as are various other aspects of the chip.