
Zen 5’s 2-Ahead Branch Predictor Unit: How a 30 Year Old Idea Allows for New Tricks


When I recently interviewed Mike Clark, he told me, “…you’ll see the actual foundational lift play out in the future on Zen 6, even though it was really Zen 5 that set the table for that.” And at that same Zen 5 architecture event, AMD’s Chief Technology Officer Mark Papermaster said, “Zen 5 is a ground-up redesign of the Zen architecture,” which has brought numerous and impactful changes to the design of the core.
The most substantial of these changes may well be the brand-new 2-Ahead Branch Predictor Unit, an architectural enhancement with roots in papers from three decades ago. But before diving into this both old yet new idea, let’s briefly revisit what branch predictors do and why they’re so critical in modern microprocessor cores.
Ever since computers began operating on programs stored in programmable, randomly accessible memory, architectures have been split into a front end that fetches instructions and a back end responsible for performing those operations. A front end must also support arbitrarily moving the point of current program execution to allow basic functionality like conditional evaluation, looping, and subroutines.
If a processor could simply perform the entire task of fetching an instruction, executing it, and selecting the next instruction location in unison, there would be little else to discuss here. However, incessant demands for performance have dictated that processors perform more operations in the same unit time with the same amount of circuitry, taking us from 5 kHz with ENIAC to the 5+ GHz of some contemporary CPUs like Zen 5, and this has necessitated pipelined logic. A processor must actually maintain in parallel the incrementally completed partial states of logically chronologically distinct operations.
Keeping this pipeline filled is immediately challenged by the existence of conditional jumping within a program. How can the front end know what instructions to begin fetching, decoding, and dispatching when a jump’s condition might be a substantial number of clock cycles away from finishing evaluation? Even unconditional jumps with a statically known target address present a problem when fetching and decoding an instruction needs more than a single pipeline stage.
The two ultimate responses of this problem are to either simply wait when the need is detected or to make a best effort guess at what to do next and be able to unwind discovered mistakes. Unwinding bad guesses must be done by flushing the pipeline of work contingent on the bad guess and restarting at the last known good point. A stall taken on a branch condition is effectively unmitigable and proportional in size to the number of stages between the instruction fetch and the branch condition evaluation completion in the pipeline. Given this and the competitive pressures to not waste throughput, processors have little choice but to attempt guessing program instruction sequences as accurately as possible.
Imagine for a moment that you are a delivery driver without a map or GPS who must listen to on-the-fly navigation from colleagues in the back of the truck. Now further imagine that your windows are completely blacked out and that your buddies only tell you when you were supposed to turn 45 seconds past the intersection you couldn’t even see. You can start to empathize and begin to understand the struggles of the instruction fetcher in a pipelined processor. The art of branch prediction is the universe of strategies that are available to reduce the rate that this woefully afflicted driver has to stop and back up.
Naive strategies like always taking short backwards jumps (turning on to a circular drive) can and historically did provide substantial benefit over always fetching the next largest instruction memory address (just keep driving straight). However, if some small amount of state is allowed to be maintained, much better results in real programs can be achieved. If the blinded truck analogy hasn’t worn too thin yet, imagine the driver keeping a small set of notes of recent turns taken or skipped and hand-drawn scribbles of how roads driven in the last few minutes were arranged and what intersections were passed. These are equivalent to things like branch history and address records, and structures in the 10s of kilobytes have yielded branch prediction percentages in the upper 90s. This article will not attempt to cover the enormous space of research and commercial solutions here, but understanding at least the beginnings of the motivations here is valuable.
Enter stage right, Zen 5’s 2-Ahead Branch Predictor.

The 2-Ahead Branch Predictor is a proposal that dates back to the early ’90s. Even back then the challenge of scaling out architectural widths of 8 or more was being talked about and a 2-Ahead Branch Predictor was one of the methods that academia put forth in order to continue squeezing more and more performance out of a single core.
But as commercial vendors moved from a single core CPU to multi-core CPUs, the size of each individual core started to become a bigger and bigger factor in CPU core design so academia started focusing on more area efficient methods to increase performance with the biggest development being the TAGE predictor. The TAGE predictor is much more area efficient compared to older branch predicting methods so again academia focused on improving TAGE predictors.
But with logic nodes allowing for more and more transistors in a similar area along with moving from dual and quad core CPUs to CPUs with hundreds of out of order CPUs, we have started to focus more and more on single core performance rather than just scaling further and further up. So while some of these ideas are quite old, older than I in fact, they are starting to resurface as companies try and figure out ways to increase the performance of a single core.
It is worth addressing an aspect of x86 that allows it to benefit disproportionately more from 2-ahead branch prediction than some other ISAs might. Architectures with fixed-length instructions, like 64-bit Arm, can trivially decode arbitrary subsets of an instruction cache line in parallel by simply replicating decoder logic and slicing up the input data along guaranteed instruction byte boundaries. On the far opposite end of the spectrum sits x86, which requires parsing instruction bytes linearly to determine where each subsequent instruction boundary lies. Pipelining (usually partially decoding length-determining prefixes first) makes a parallelization of some degree tractable, if not cheap, which resulted in 4-wide decoding being commonplace in performance-oriented x86 cores for numerous years.
While increasing logic density with newer fab nodes has eventually made solutions like Golden Cove’s 6-wide decoding commercially viable, the area and power costs of monolithic parallel x86 decoding are most definitely super-linear with width, and there is not anything resembling an easy path forward with continued expansions here. It is perhaps merciful for Intel and AMD that typical application integer code has a substantial branch density, on the order of one every five to six instructions, which diminishes the motivation to pursue parallelized decoders much wider than that.
The escape valve that x86 front ends need more than anything is for the inherently non-parallelizable portion of decoding, i.e., the determination of the instruction boundaries. If only there was some way to easily skip ahead in the decoding and be magically guaranteed you landed on an even instruction boundary…
Back to the Future!…. of the 1990s
Starting with the paper titled “Multiple-block ahead branch predictors” by Seznec et al., it lays out the why and how of the reasoning and implementation needed to make a 2-Ahead Branch Predictor.

Looking into the paper, you’ll see that implementing a branch predictor that can deal with multiple taken branches per cycle is not as simple as just having a branch predictor that can deal with multiple taken branches. To be able to use a 2-Ahead Branch Predictor to its fullest, without exploding area requirements, Seznac et al. recommended dual-porting the instruction fetch.
When we look at Zen 5, we see that dual porting the instruction fetch and the op cache is exactly what AMD has done. AMD now has two 32 Byte per cycle fetch pipes from the 32KB L1 instruction cache, each feeding its own 4-wide decode cluster. The Op Cache is now a dual-ported 6 wide design which can feed up to 12 operands to the Op Queue.
Now, Seznac et al. also recommends dual porting the Branch Target Buffer (BTB). A dual-ported L1 BTB could explain the massive 16K entries that the L1 BTB has access to. As for the L2 BTB, it’s not quite as big as the L1 BTB at only 8K entries but AMD is using it in a manner similar to how a victim cache would be used. So entries that get evicted out of the L1 BTB, end up in the L2 BTB.
With all these changes, Zen 5 can now deal with 2 taken branches per cycle across a non-contiguous block of instructions.

This should reduce the hit to fetch bandwidth when Zen 5 hits a taken branch as well as allowing AMD to predict past the 2 taken branches.
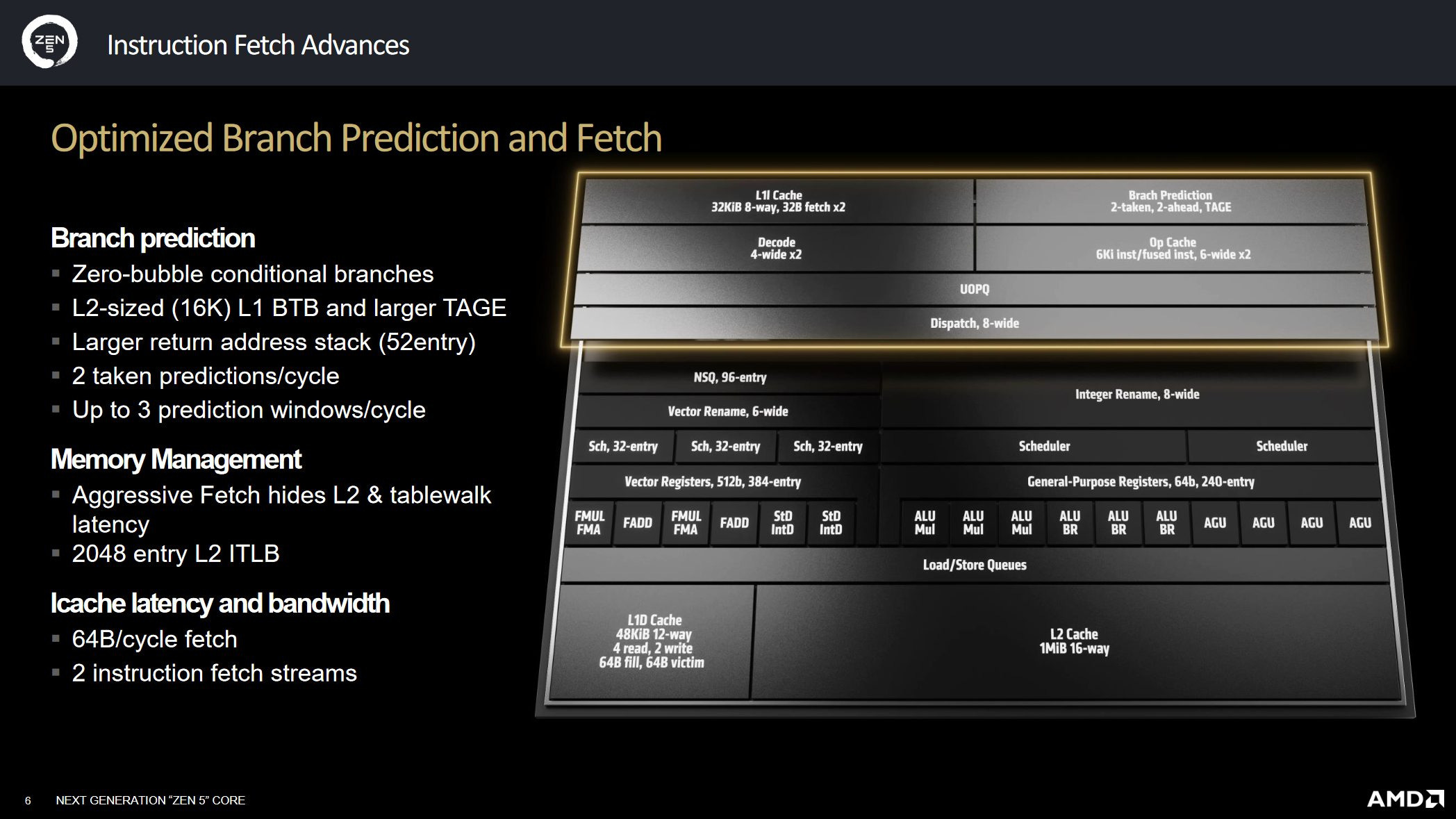
Zen 5 can look farther forward in the instruction stream beyond the 2nd taken branch and as a result Zen 5 can have 3 prediction windows where all 3 windows are useful in producing instructions for decoding. The way that this works is that a 5 bit length field is attached to the 2nd prediction window which prevents the over subscription of the decode or op cache resources. This 5 bit length field while smaller than a pointer does give you the start of the 3rd prediction window. One benefit of this is that if the 3rd window crosses a cache line boundary, the prediction lookup index doesn’t need to store extra state for the next cycle. However a drawback is that if the 3rd prediction window is in the same cache line as the 1st or 2nd prediction window, that partial 3rd window isn’t as effective as having a 3rd full prediction window.
Now when Zen 5 has two threads active, the decode clusters and the accompanying fetch pipes are statically partitioned. This means that to act like a dual fetch core, Zen 5 will have to fetch out of both the L1 instruction cache as well as out of the Op Cache. This maybe the reason why AMD dual-ported the op cache so that they can better insure that they can keep the dual fetch pipeline going.
Final Words
In the end, this new 2-Ahead Branch Predictor is a major shift for the Zen family of CPU architectures moving forward and is going to give new branch prediction capabilities that will likely serve the future developments of the Zen core in good stead as they refine and improve this branch predictor.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.
Endnotes
If you want to learn more about how multiple fetch processors work then I would highly recommend the papers below as they helped with my understanding of how this whole system works:
“Multiple-block ahead branch predictors” by Seznec et al. – ASPLOS 1996
“Optimization of Instruction Fetch Mechanisms for High Issue Rates” by Conte et al. – ISCA 1995
“Out-of-Order Instruction Fetch using Multiple Sequencers” by Oberoi and Sohi – ICPP’02
“Parallelism in the Front-End” by Oberoi and Sohi – ISCA 2003
 | A guest post by
|