
TOP500 at ISC’26: We have a New Number 1

Hello you fine Internet folks,
Here at ISC 2026 in Hamburg, Germany, we got the 67th TOP500 list where there was a surprise awaiting us. That surprise being a new Number 1 Supercomputer on the TOP500.
LineShine Shining on Through
The new number one Supercomputer on the TOP500 list is the LineShine Supercomputer in Shenzhen, China. This is the first Chinese submission to the TOP500 in 9 years and they came in swinging with a massive CPU-only system.
Starting with the specifications of the CPU that powers the LineShine system, the LX2.
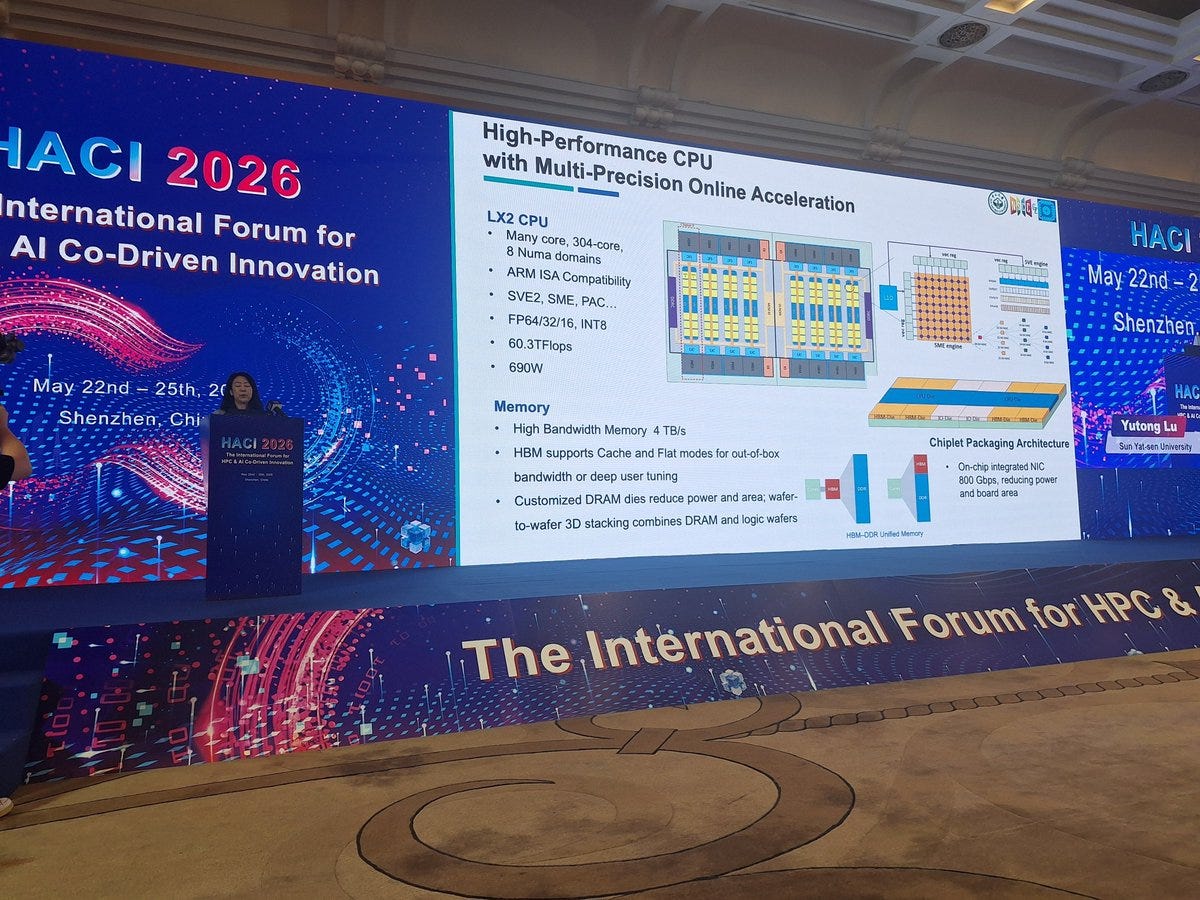
The LX2 is an Armv9-compliant CPU with support for SVE2 and SME. Each core has 32 KB of L1 instruction cache and 32 KB of L1 data cache. Physically, the chip is built from two compute dies, with each die containing four 40-core clusters. Two cores are disabled per cluster, leaving 38 active cores per cluster, or 152 active cores per die. Each cluster is backed by 28.5 MB of L2 cache, giving each die 114 MB of L2 and the full LX2 package 304 active cores with 228 MB of total L2 cache.
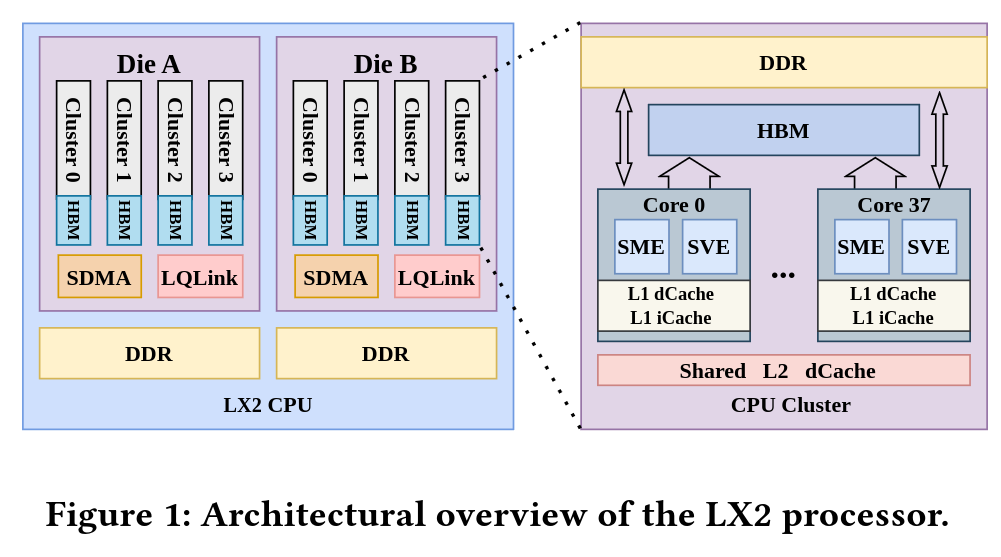
Those 304 cores run at 1.55 GHz and deliver a quoted 60.3 TFLOP/s of FP64 compute at 690 watts per LX2 CPU. The package also includes eight stacks of “high-bandwidth memory,” with 4 GB per stack for 32 GB of on-package high-bandwidth memory and 4 TB/s of bandwidth. However, this memory likely is not conventional HBM, despite being described in similar terms and could be an indigenous Chinese development. Because 32 GB is relatively small for a CPU of this scale, each LX2 is also backed by 256 GB of DDR5 memory that acts as a larger spillover tier.

Transitioning from the CPU level to the node level, each node has two LX2 CPUs with 800 Gbps of networking for a total of 1.6Tbps of networking per node. 8 of these nodes are then combined into a compute blade, with 16 compute blades in a compute frame, and 2 frames per compute cabinet. In total the LineShine supercomputer has 90 compute cabinets which means that there are over 22,000 nodes and 13 million CPU cores in the full system.
This puts the LineShine system at a total of 2.198 Exaflops of sustained FP64 (Rmax) out of an on-paper 2.735 Exaflops of FP64 (Rpeak). For this result, the LineShine system pulled 42.22 Megawatts of power for a FP64 efficiency of 52.07 Gigaflops per Watt, which, while it is well behind the leader of 73.282 FP64 Gigaflops per Watt, is very impressive for a CPU only system. And unlike prior Chinese Supercomputers, this system is not just a “LINPACK-special” but is also the number 1 in the HPCG benchmark with a result of 22.004 Petaflops per second beating out El Capitan’s 17.406 Petaflops per second result.
The Rest of the Owl
There is a new number 6 system on list, the HPC7 system from Eni in Italy. This is functionally El Capitan, just shrunk down to 30% the size. It is using the same HPE Cray EX4000 platform and AMD Instinct MI300A APUs, which is getting an Rmax of 571.5 Petaflops of FP64 performance out of an Rpeak of 861 Petaflops at 8.735 Megawatts of power consumed. With HPC7, Italy now has more compute listed on the TOP500 than any other country in Europe, despite Germany having Europe’s only Exascale system on the TOP500.
The former number 1 supercomputer, Fugaku, may have been pushed down to number 9 in the TOP500 ranking but it is still a lean, mean, science crunching machine. Despite being 6 years old, Fugaku is still number 3 on the HPCG list, which is a testament to the HPC focused design that Fugaku has, as it is still in the top 3 supercomputers as far as the HPCG list is concerned.
Moving to the Green500, there have been no changes to the Green500’s Top 10 list of most efficient supercomputers. This is the first time in the Green500’s history where there have been no changes to the Top 10 list. However that is not to say that HPC hasn’t gotten more efficient.
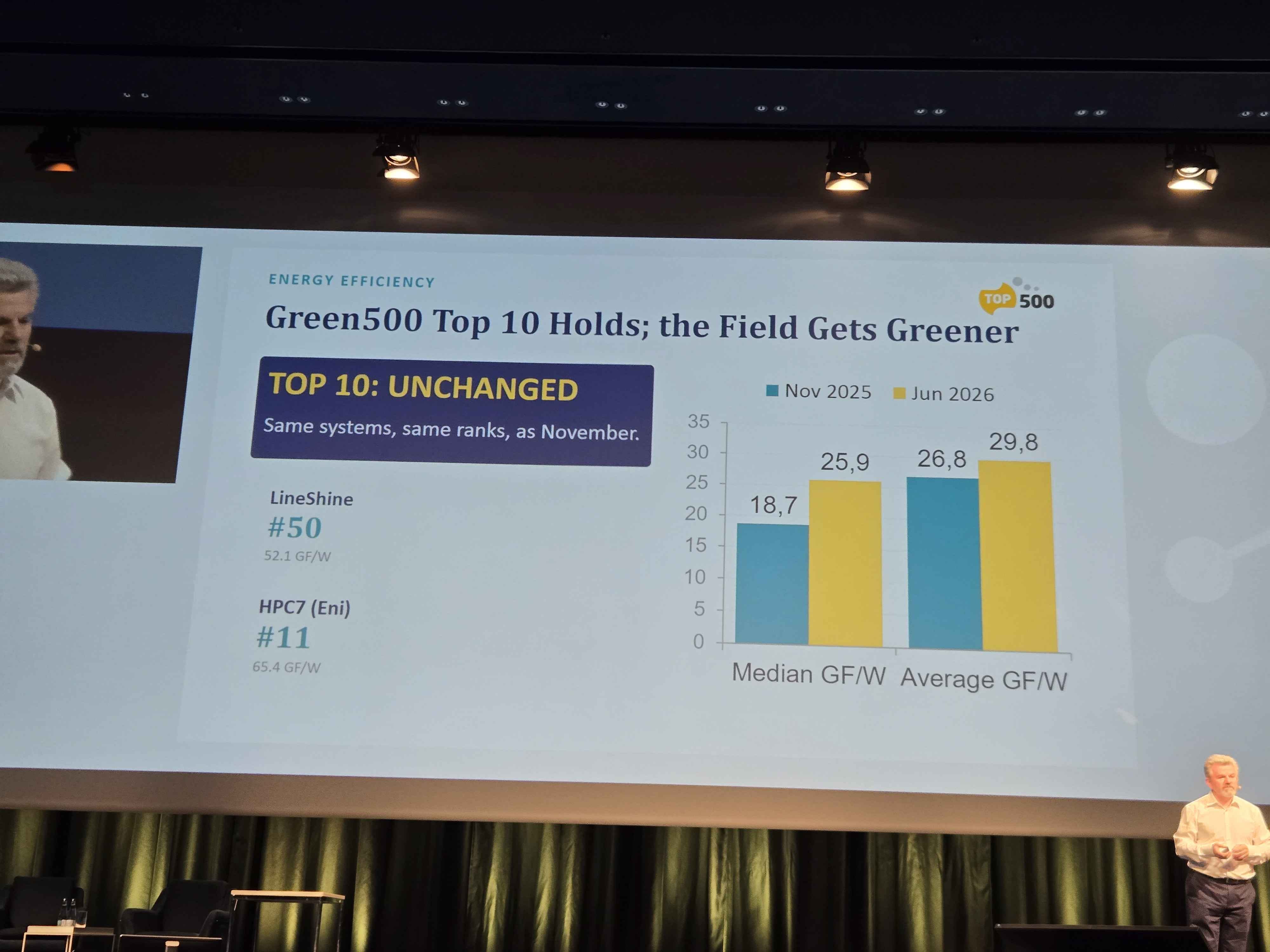
Due to retirements of older systems, the overall field of HPC has gotten more efficient in the past 6 months.
Conclusion
Personally, I wasn’t expecting to see a new number 1 on the TOP500, until either Discovery or Fukagu-Next was brought online. We have known that China has Exascale systems for a while now, but this is the first time that we have seen a China Exascale system on the TOP500.
This does beg the question of if China will also submit TOP500 results for their other exascale systems, Sunway Oceanlight and CNIS, or if they will keep those off of the TOP500 list.
I do wonder if this will cause the US Government to spend more money for large DOE systems and I am not the only one thinking that it could drive more money towards the DOE.

If the submission of LineShine ends up with the DOE getting more funding for more, and larger, supercomputers, then bully for us in the HPC community.
Something that is quite interesting is that Eni, an oil and gas company, has been submitting their systems to the TOP500 and they currently have 2 of the Top 10 systems on the TOP500. Which then begs the question, why aren’t the truly large AI systems, such as xAI’s Colossus 2 with over 550,000 Blackwell GPUs, on the TOP500? Why aren’t these AI companies submitting to the TOP500 to show off their computing prowess? To be honest, I don’t know why. A full HPL run on a supercomputer seems like a good way to stress all of the compute, memory, and networking of the system before declaring it to be operational.
There was one last key piece of news that came out of the TOP500 here at ISC 2026 and that is that the ISC Group will be handing over the TOP500 list to ACM SIGHPC moving forward. This functionally means that now all TOP500 lists will have dedicated DOI numbers which will make referencing specific TOP500 lists easier moving forward.
These systems for fp64 compute are so much more interesting than AI data centers that are all about low precision compute.
I wonder what the process is for an organisation, after setting up their machine, to run benchmarks and be able to claim a spot among the top500. Is there a set of benchmarks that I could run, say, on my homelab cluster to tell me how far from the 500th spot my gear is?