
SC25: Estimating AMD’s Upcoming MI430X’s FP64 and the Discovery Supercomputer

Hello, you fine Internet folks,
At Supercomputing 2025, EuroHPC, AMD, and Eviden announced that the second Exascale system in Europe was going to be called Alice Recoque. Powered by Eviden’s BullSequena XH3500 platform using AMD’s upcoming Instinct MI430X as most of the compute for the supercomputer. Alice Recoque is going “exceed a sustained performance of 1 Exaflop/s HPL performance… with less than 15 Megawatts of electrical power.”
Now, AMD hasn’t said what the FLOPs of MI430X is but there is likely enough to speculate as to the potential FP64 FLOPs of MI430X as a thought experiment.
In terms of what we know:
- Alice Recoque is going to be made of 94 XH3500 racks
- Alice Recoque uses less than 15 Megawatts of power in actual usage, but the facility can provide 24 Megawatts of power and 20 Megawatts of cooling
- BullSequena XH3500 has a cap of 264 Kilowatts per rack
- BullSequena XH3500 is 38U per rack
- BullSequena XH3500’s Sleds are 2U for Switch Sleds and 8 Compute Sleds and 1U for 4 Compute Sleds
What we also know is that HPE rates a single MI430X between 2000 watts and 2500 watts of power draw.
Alice Recoque has 3 different possible energy consumption numbers:
Less than 15 Megawatts
The facility thermal limit of 20 Megawatts of cooling
Facility power limit of 24 Megawatts
This allows for 3 possible configurations of the XH3500 racks:
For the sub 15 Megawatt system, 16 Compute nodes each with 1 Venice CPU and 4 MI430X along with 8 switch blades
For the 20 Megawatt system, 18 Compute nodes each with 1 Venice CPU and 4 MI430X along with 9 switch blades
For the 24 Megawatt system, 20 Compute nodes each with 1 Venice CPU and 4 MI430X along with 8 switch blades
For this calculation, I am going to run with the middle configuration of 18 Compute nodes and 9 switch nodes per rack along with a maximum sustained energy consumption of approximately 20 Megawatts for the full Alice Recoque Supercomputer. This puts the maximum power consumption of a single XH3500 rack at about 200 Kilowatts. As such I am going to run with the assumption that each of the Compute nodes can pull approximately 10.5 Kilowatts and as a result each of the MI430Xs will be estimated to have a TDP of about 2300 watts. This gives 1300 watts for the remainder of the Compute blade including the Venice CPU which has a TDP of up to 600 watts.
With 94 racks, 18 Compute nodes, and 4 MI430Xs per blade, this gives a total of 6768 GPUs for the whole Alice Recoque Supercomputer. Assuming the “exceed a sustained performance of 1 Exaflop/s HPL performance” is the HPL Rmax value of Alice Recoque and that the Rmax to Rpeak ratio is approximately 70% (similar to Frontier’s ratio), this puts Alice Recoque’s HPL Rpeak at a minimum of 1.43 Exaflops. Now dividing the HPL Rpeak number by the number of MI430Xs get you a FP64 Vector FLOPs number for MI430X of approximately 211 Teraflops.
MI430X pairs this approximate 211 Teraflops of FP64 Vector with 432 Gigabytes of HBM4 providing the MI430X with 19.6 TB/s of memory bandwidth; this is unsurprisingly the same memory subsystem as MI450X. An important metric in HPC is the amount of compute for the given memory bandwidth which is usually denoted as FLOPs per Byte or F/B. For many HPC tasks, the arithmetic intensity for those problems is low, a lower FLOPs per Byte number is preferred due to the majority of HPC code being memory bandwidth bound.
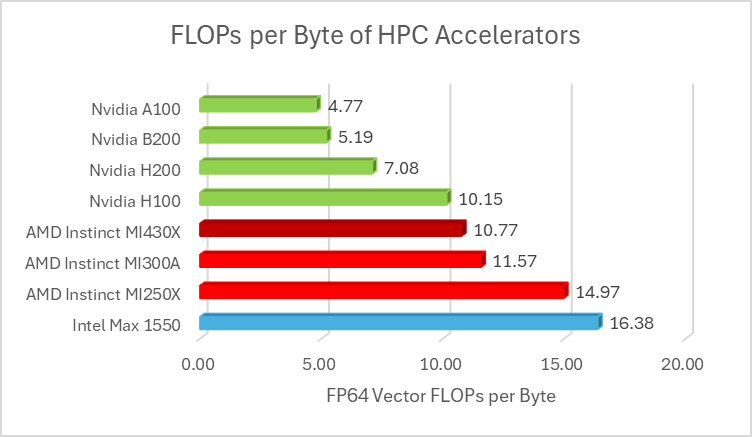
So assuming 211TF of FP64 Vector for MI430X, this puts MI430X ahead of both of AMD’s prior HPC focused accelerators in terms of FLOPs per Byte. However, MI430X does still have a higher FP64 FLOPs per Byte ratio compared to Nvidia’s offerings. But MI430X does have two aces up its sleeve compared to Nvidia’s latest and upcoming accelerators.
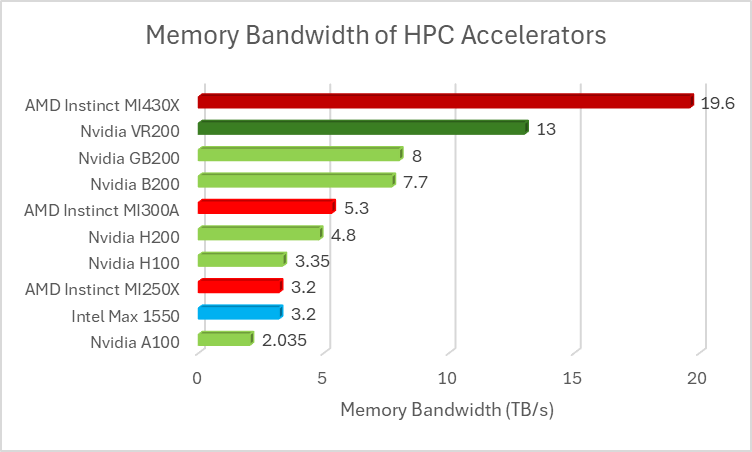
The first ace is that MI430X has significantly more bandwidth compared to AMD’s prior offering along with having even more memory bandwidth than Nvidia’s upcoming Rubin accelerator which is important due to the number of memory bandwidth bound tasks in HPC.
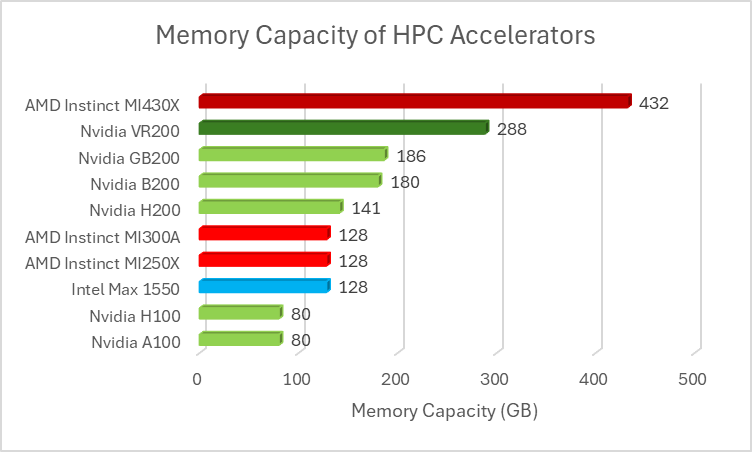
The second ace is that MI430X has nearly 3.5 times the HBM capacity of AMD’s prior accelerators and 50% more HBM capacity than Nvidia’s upcoming Rubin which means that a larger dataset can be fit on a single MI430X.
The Upcoming Discovery Supercomputer at ORNL
Just prior to Supercomputing 2025, AMD, HPE, and the Department of Energy announced the replacement of Frontier, codenamed Discovery, which is due to be delivered in 2028 and turned on in 2029 at the Oak Ridge National Laboratory in Oak Ridge, Tennessee.
Again, we don’t know much about Discovery other than it is going to use HPE’s new GX5000 platform and that it will use AMD’s Venice CPUs and MI430X accelerators.
Speaking of HPE’s GX5000 platform, it has 3 initial compute blade configurations:
GX250: The GX250 blade has 8 Venice CPUs with up to 40 blades per rack for a total of up to 320 Venice CPUs per GX5000 rack
GX350a: The GX350a blade has 1 Venice CPU and 4 MI430X Accelerators with up to 28 blades per rack for a total of 28 Venice CPUs and 112 MI430X Accelerators per GX5000 rack
GX440n: The GX440n blade had 4 Nvidia Vera CPUs and 8 Rubin Accelerators per blade with up to 24 blades per rack for a total of 96 Vera CPUs and 192 Rubin Accelerators per GX5000 rack
The current GX5000 platform can supply up to 400 kilowatts per rack which is likely for the full GX440n configuration where the 192 Rubins, each rated for 1800 watts, alone pull about 350 kilowatts let alone the CPUs, memory, etc. The GX5000 is also about half the floor area compared to the prior generation of EX4000 (1.08 m^2 vs 2.055 m^2). This means that you can fit 2 GX5000 racks into the area of a single EX4000 rack.
For Discovery, the configuration that we are interested in is the GX350a configuration of the GX5000. Now, what hasn’t been announced yet is the HPL speedup goal but it is expected that Discovery will deliver “three to five times more computational throughput for benchmark and scientific applications than Frontier.”
Due to the vagueness of what exactly the three to five times performance increase refers to, whether this is three to five times faster in actual HPC workloads or if this is three to five times faster in LINPACK, I am going to propose 2 different configurations for Discovery:
A configuration that can fit into the current power and floor footprint of Frontier’s building
A configuration that is approximately 4 times the Rpeak of Frontier at the time of the RFP was closed on August 30th, 2024 which was approximately 1.714 Exaflops
Now for the first configuration, Frontier has 74 EX4000 Racks for its compute system which means that approximately 140 GX5000 racks can fit into that floor space. This means that Discovery would have a total of 3,920 Venice CPUs and 15,680 MI430Xs Accelerators for a rough total of 3.3 Exaflops of HPL Rpeak.
This Rpeak of 3 Exaflops would have a rough power draw of about 35 Megawatts assuming each of the GX5000 racks uses approximately 250 Kilowatts per rack. While this is 10 Megawatts more than what Frontier draws in HPL, the building for Frontier is designed to be able to distribute up to 40 Megawatts so this 140 rack configuration does just fit into the power and floor space of Frontier’s building. However, if you decrease the per-rack power to 160 Kilowatts then Discovery could easily fit into Frontier’s power footprint.
For the second configuration, I am taking the top end estimate of Discovery as five times faster than Frontier and running with a configuration that is approximately five times the Rpeak of Frontier ca. August 2024 which would make Discovery a ~8.5 Exaflop system. This would need approximately 360 GX5000 racks for a total of 10,080 Venice CPUs and 40,320 MI430X Accelerators.
This configuration would likely need a facilities upgrade for both power and floor space to accommodate the system. For the floor space, this configuration may require over 1,600 m^2. And for the power, assuming 250 Kilowatts per GX5000 rack, this configuration would consume over 90 Megawatts; however, toning down the per-rack power to around 160 Kilowatts would put Discovery into the 55 to 60 Megawatt range.
The most likely configuration of Discovery is probably somewhere in-between these two configurations. However, it is rumored that China may have a Supercomputer that is able to get over 2 Exaflops of HPL Rmax at 300 megawatts with a potential companion that uses 2.5 times the power at 800 megawatts which could get over 5 Exaflops of HPL Rmax. So this may drive the Department of Energy to have chosen the largest configuration or possibly a configuration that is even larger than five times Frontier.
Regardless of what Discovery ends up being in terms of the final configuration, it is undeniably an exciting time in the World of HPC!
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
Your power numbers are all wrong here making the wrong assessments.
Typical power load for the 94 racks is 12MW.
TDP is 15MW.
Cooling is always factored up relative to TDP. No datacenter installs cooling at TDP.
Facilities power is also factored up to maximize power supply efficiency, generally 1.5x to 2x TDP.
That means the 2000W figure is a scaling factor for rack level TDP based on number of GPUs or something along those lines.
2500W could approximate per GPU power supply requirements.
15 MW for 94 racks means 160kW rack TDP.
The idea that cooling load = facility power = TDP is ridiculous.
Love the forensic approach to estimating MI430X's specs from Alice Recoque's config. The 211TF FP64 number feels spot-on given the ~70% HPL efficiency assumption. What really standouts is the HBM4 capacity advantage over Rubin (432GB vs 288GB), which could be huge for memory-hungry CFD simulations.