
Supercomputing 2024: El Capitan, MI300A, and More on the Fastest Supercomputers!
There's a new Number One for the 64th TOP500 list

Hello you fine Internet folks!
We are here at SC24 in Atlanta and there is a new TOP500 list that has just been announced and to celebrate the occasion, we have a video and an article for y’all and I hope that y’all enjoy!
For a bit of background, every year there are 2 TOP500 lists, the first one of the year is usually announced at International Supercomputing which is usually in Hamburg, Germany every year, and the second one is announced at Supercomputing which is held in the US.
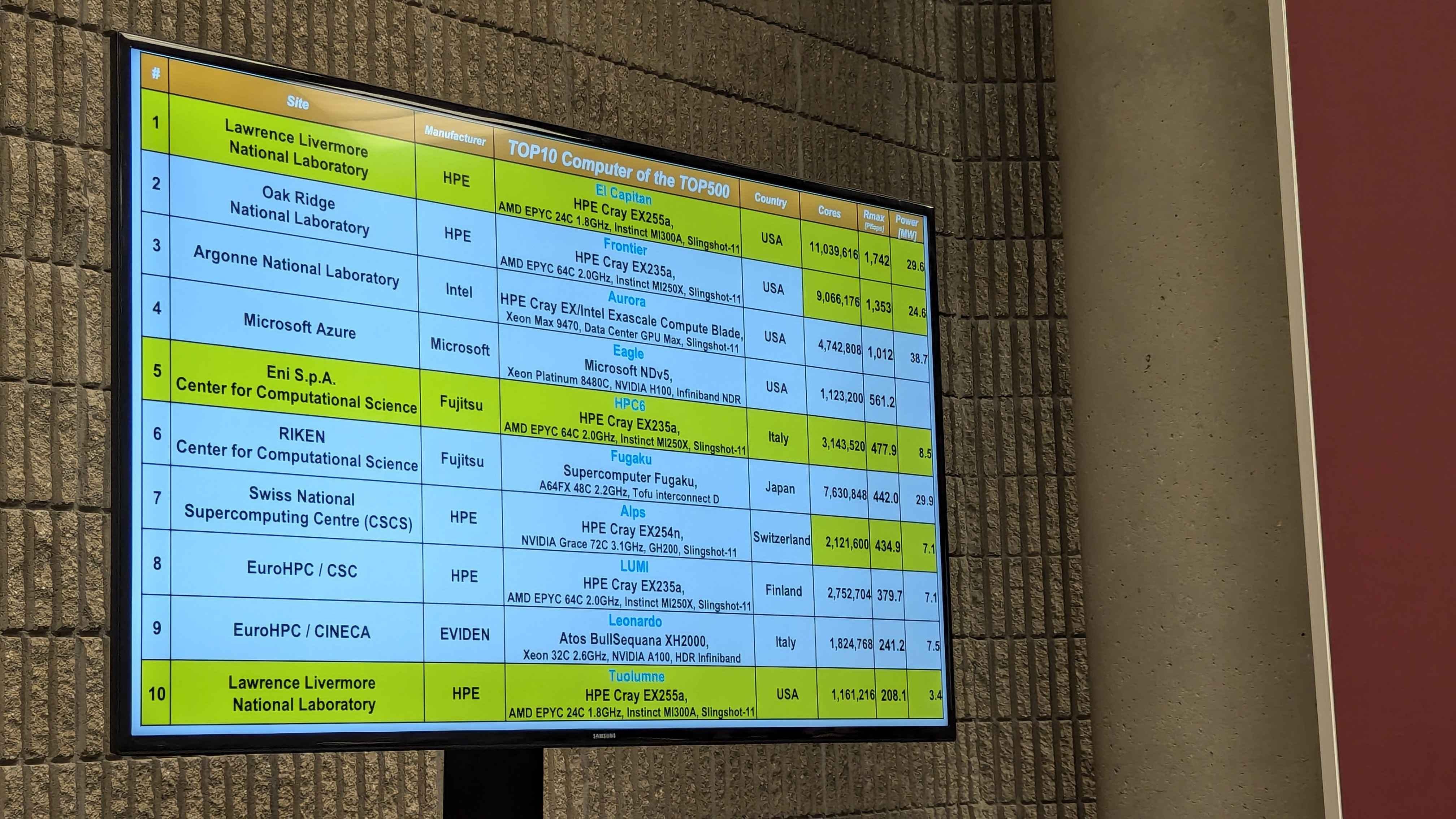
For the 64th TOP500 list, the El Capitan supercomputer at Lawrence Livermore National Laboratory is the new number one supercomputer and the third confirmed Exascale supercomputer in the world.

El Capitan is powered by AMD’s MI300A Datacenter APU which takes the general principals of their client APUs found in laptops and cranks it to 11. The MI300A is a chip with 24 Zen 4 cores running at 3.7GHz and those are paired with 228 CDNA3 CUs with a peak engine clock of 2100MHz.

Looking at the packaging of MI300A and you’ll see that there are 3 CPU chiplets each with 8 Zen 4 cores plus 6 XCD chiplets that have 38 CUs each. These 9 chiplets are then stacked on top of 4 base chiplets that have all the IO along with 256MB of SRAM that is acting as the chip level last level cache.
This all combines to give MI300A a total of 61.3 teraflops of FP64 vector along with 122.6 teraflops of FP64 matrix worth of compute, but MI300A has advantages beyond massive FP64 compute. Having both the CPU and GPU on the same NUMA node means that you don’t have to worry about memory copies between the CPU and GPU because it all shares the same unified memory. This can give massive speedups in certain applications where transferring data between the CPU and GPU can be a large bottleneck.

4 MI300A are put into a node that then has 768GB/s of bi-directional bandwidth (384GB/s/direction), then 2 nodes are put into a blade which is connected out to the rest of the network with eight 200GbE Slingshot-11 NICs per blade (four 200GbE Slingshot NICs per node) for a total of 1.6TbE of networking per blade (800GbE of networking per node). In total, there are 11,136 nodes in 5,568 blades spread across 87 compute cabinets comprising El Capitan.

This give El Capitan a Rmax of 1.742 Exaflops in High Performance LINPACK (HPL) with a Rpeak of 2.792 Exaflops while using 29.6MW of power.
While the Rmax to Rpeak ratio may not seem amazing, El Capitan was not designed for HPL. It was designed to run simulations and other workloads for the National Nuclear Safety Administration.

However, El Capitan is not the only MI300A system on the TOP500 for this list. At number 10 is the smaller unclassified sister system of El Capitan called Tuolumne with a Rmax of 208 Petaflops and a Rpeak of 288 Petaflops. Then at spots number 20 and 49 are the El Doratio and RZAdams systems which are at Sandia National Labs and a third supercomputer powered by MI300A at Lawrence Livermore National Laboratory respectively.
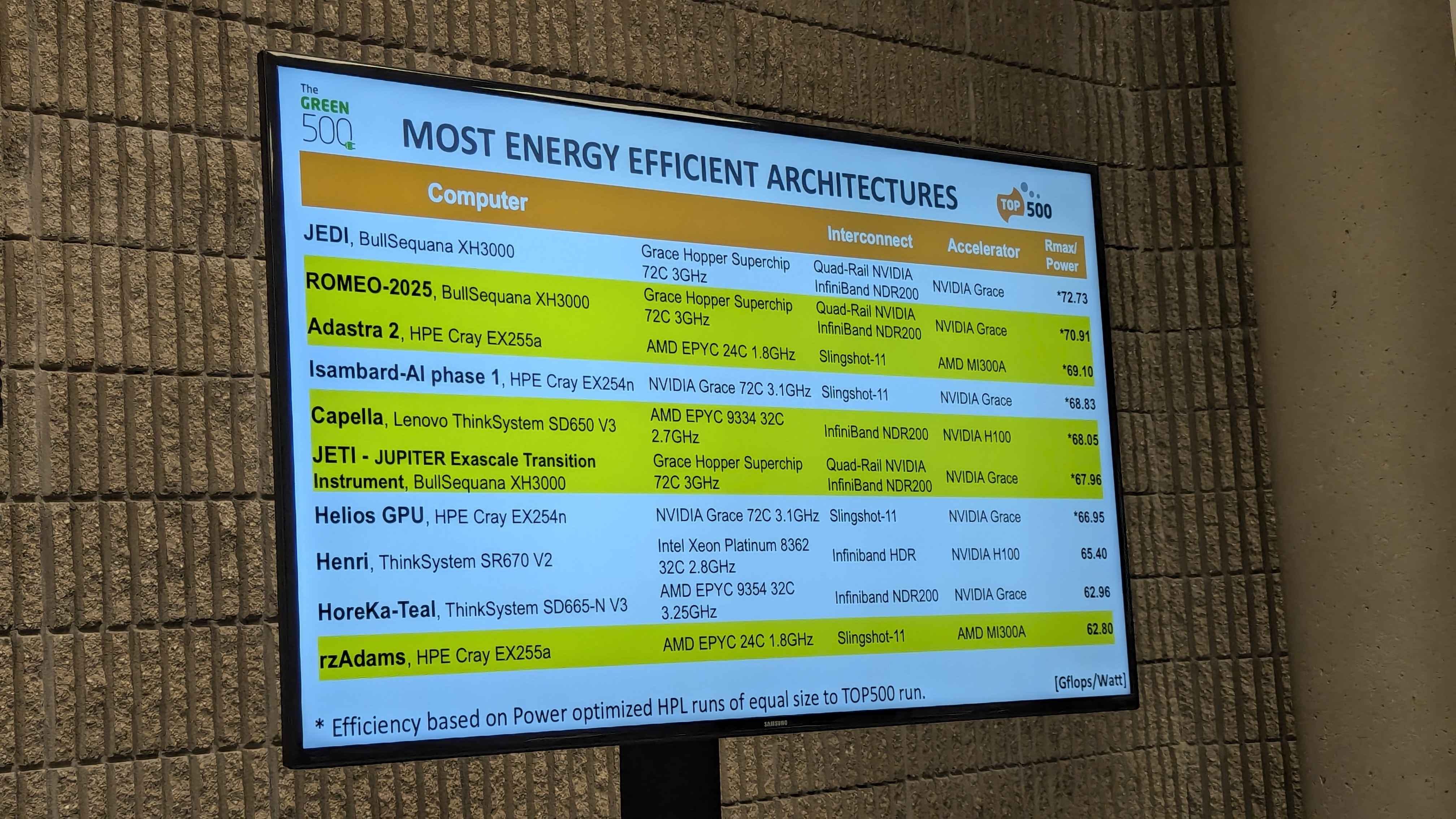
However, not every MI300A equipped system on the TOP500 are in the US. The Adastra 2 system at National Computing Center for Higher Education in France scored number 3 on the Green500 which is the list of the most efficient supercomputers with an impressive 69.10 Gigaflops per watt of FP64 performance in HPL. The number 1 spot at 72.73 Gigaflops per watt went to JEDI which is powered by Nvidia’s GH200 Superchip and is a test system for the upcoming JUPITER Exascale system at Jülich Supercomputing Centre in Germany. The number 2 spot was another Nvidia GH200 system called ROMEO-2025 at 70.91 Gigaflops per watt.
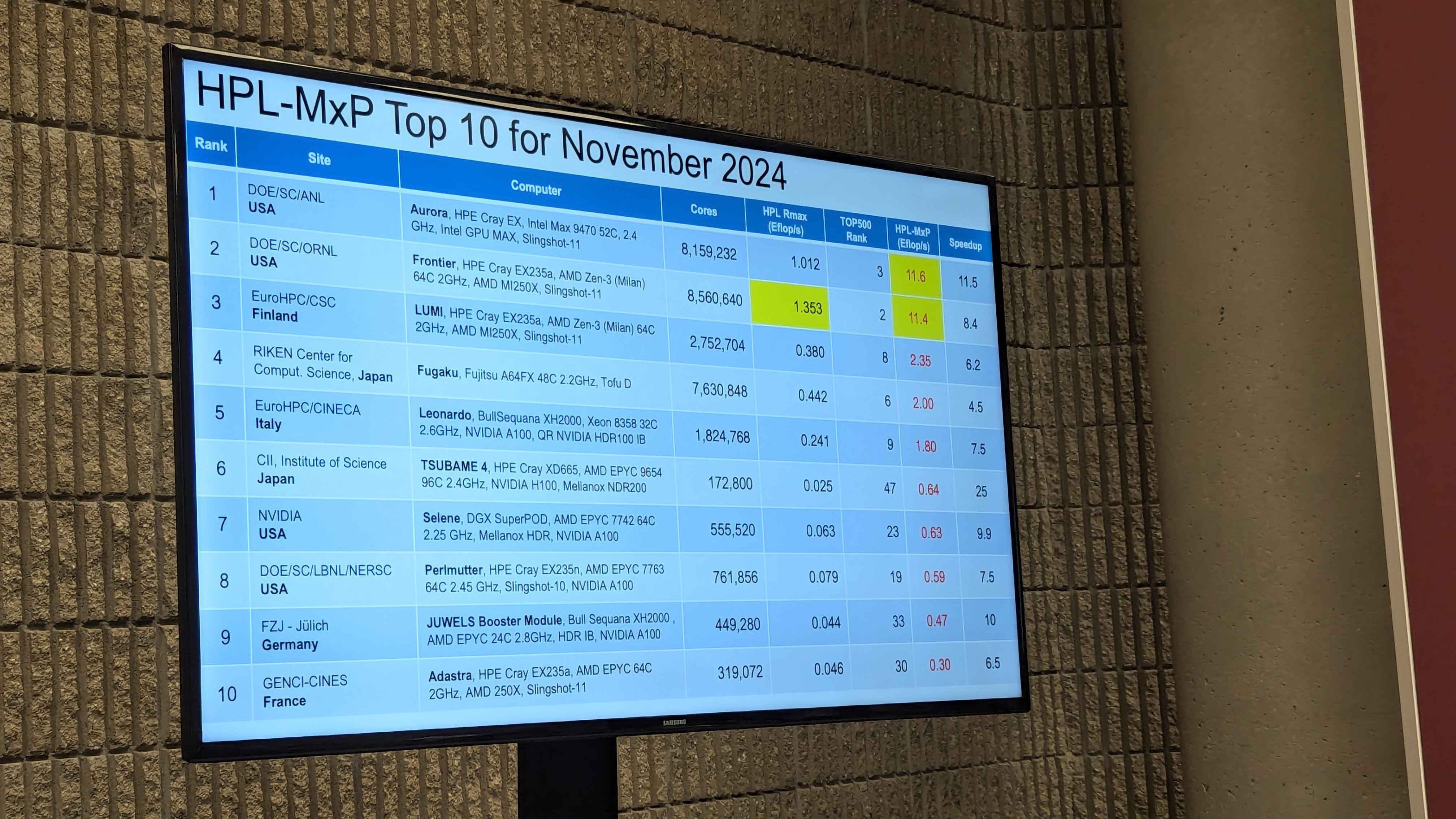
Aurora also made the news by clinching the number 1 spot on the HPL-Mixed Precision list at 11.6 Exaflops with Frontier closely following at 11.4 Exaflops.
As for the HPCG benchmark, Fugaku still holds the top spot at 16 Petaflops per second for an impressive 4 years running.
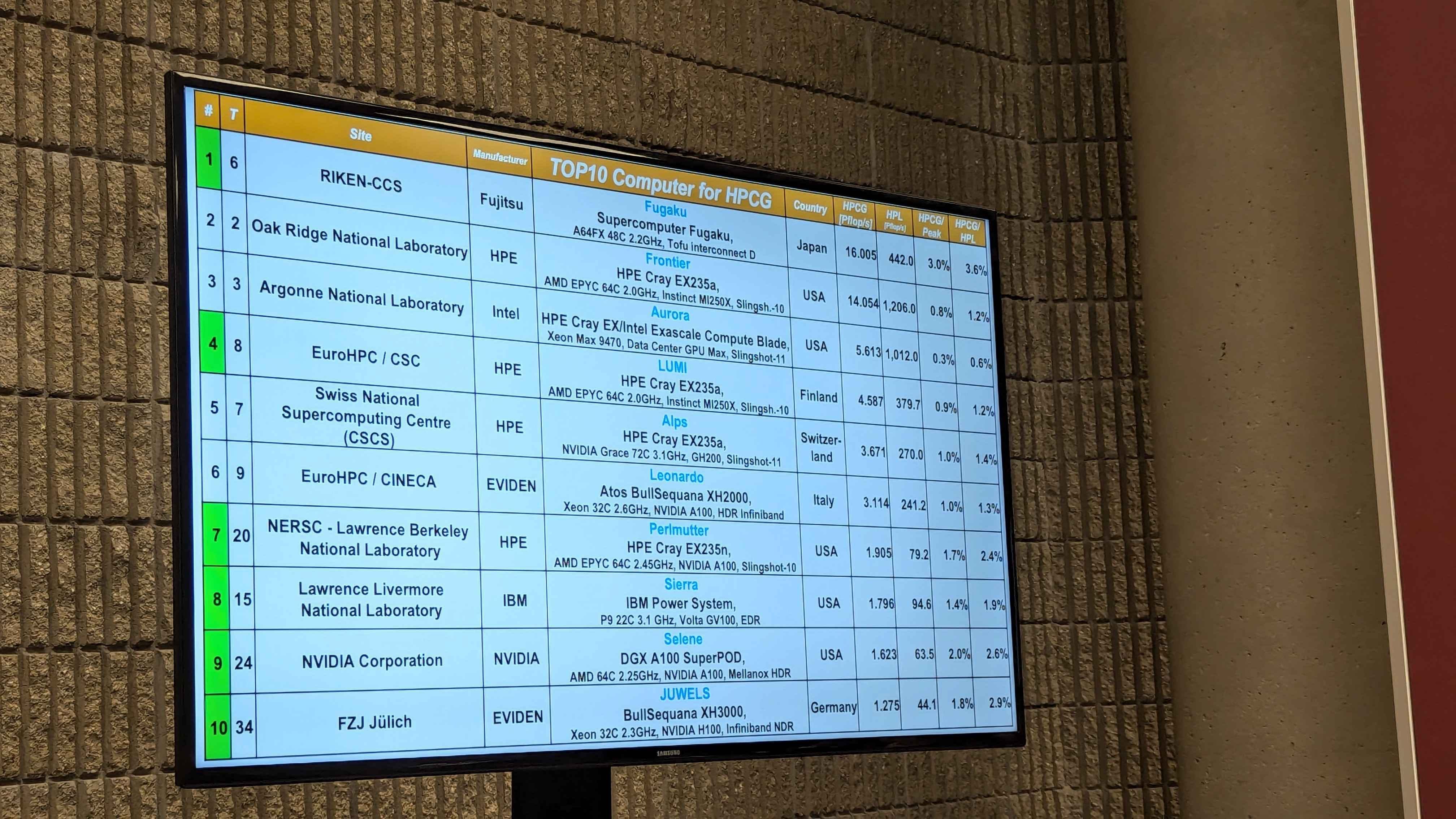
El Capitan did not submit a HPL-MxP run or a HPCG run and that is because the Lawrence Livermore team wanted to get the system running actual workloads on it as quickly as possible. However, they didn’t rule out possibly running these benchmarks in the future.
Wrapping up, the 64th TOP500 list has had many exciting announcements but there is also the rest of Supercomputing 2024 to talk about and get excited for and I can’t wait to bring you coverage of as much of SC24 as I can!
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord. And if you like our video content then please subscribe to the Chips and Cheese Youtube channel.
I this point I'd imagine it'd be worth to add some DPU chiplets to each MI300A chip, kind of what IBM is doing with their Telum II.