
Running Gaming Workloads through AMD’s Zen 5

Zen 5 is AMD’s newest core architecture. Compared to Zen 4, Zen 5 brings more reordering capacity, a reorganized execution engine, and numerous enhancements throughout its pipeline. In short, Zen 5 is wider and deeper than Zen 4. Like Lion Cove, Zen 5 delivers clear gains in the standard SPEC CPU2017 benchmark as well as many productivity applications. And like Lion Cove, several reviewers have criticized the non-X3D Zen 5 variants for not delivering similar gains in games. Here, I’ll be testing a few games on the Ryzen 9 9900X, with DDR5-5600 memory. It’s a somewhat slower memory configuration than I tested Lion Cove with, largely for convenience. I swapped the 9900X in place of my previous 7950X3D, keeping everything else the same. The memory used is a 64 GB G.SKILL DDR5-5600 36-36-36-89 kit.

The Ryzen 9 9900X was kindly sampled by AMD, as is the Radeon RX 9070 used to run the games here. I’ll be using the same games as in the Lion Cove gaming article, namely Palworld, COD Cold War, and Cyberpunk 2077. However, the data is not directly comparable; I’ve built up my Palworld base since then, COD Cold War multiplayer sessions are inherently unpredictable, and Cyberpunk 2077 received an update which annoyingly forces a 60 FPS cap, regardless of VSYNC or FPS cap settings. My goal here is to look for broad trends rather than do a like-for-like performance comparison.
As with the previous article on Lion Cove, top-down analysis will provide a starting point by accounting for lost pipeline throughput at the rename/allocate stage. It’s the narrowest stage in the pipeline, so throughput lost there can’t be recovered later and results in lower utilization of core width. Lion Cove was heavily bound by backend memory latency, with frontend latency causing additional losses. Zen 5 hits those issues in reverse. From a top-down view, it struggles to keep its frontend fed. Backend memory latency is still significant, but it is overshadowed by frontend latency.
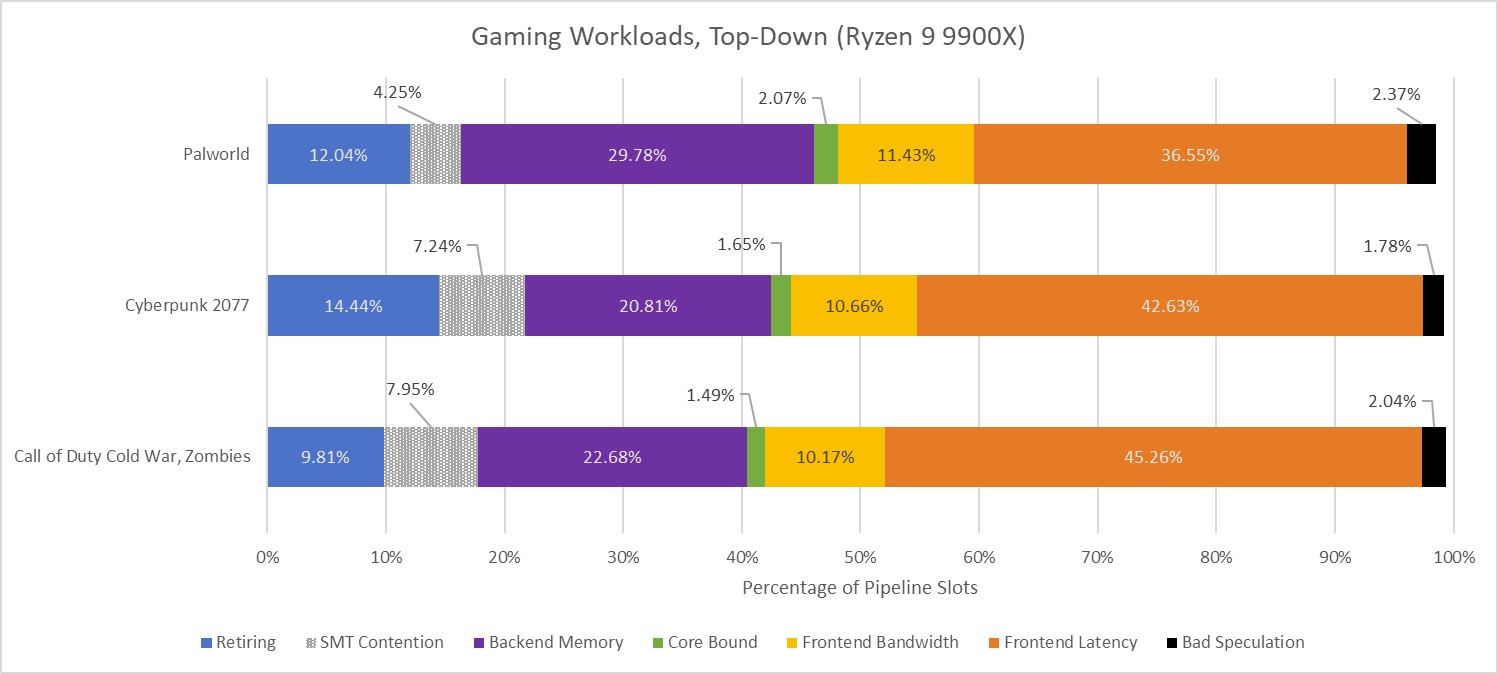
A pipeline slot is considered frontend latency bound if the frontend left all eight rename/allocate slots idle that cycle. Backend bound refers to when the rename/allocate stage had micro-ops to dispatch, but the execution engine ran out of entries in its various buffers and queues. AMD breaks down backend bound slots into core-bound and memory-bound categories, by looking at how often the retirement stage is blocked by an incomplete load versus an incomplete instruction of another type. That’s because backend-bound stalls come up when the execution engine is unable to clear out (retire) instructions faster than the frontend supplies them. Bad speculation looks at the difference between micro-ops that pass through the rename/allocate stage, and ones that were actually retired. That gives a measure of wasted work caused by branch mispredicts and other late-stage redirects like exceptions and interrupts. It’s a negligible factor in all three games.
SMT contention doesn’t indicate lost core throughput. Rather, core performance counters work on a per-SMT thread basis, and SMT contention indicates when the thread had micro-ops ready from the frontend, but the rename/allocate stage serviced the sibling SMT thread that cycle. A very high SMT contention metric could indicate that a single thread can already use much of the core’s throughput, and thus SMT gains may be limited; however, that’s not the case here. Finally, the “retiring” metric corresponds to useful work and indicates how effectively the workload uses core width. It’s relatively low on the three games here, providing a first indication that games could be considered a “low-IPC” workload.
Frontend
Zen 5’s frontend combines a large 6K entry op cache with a 32 KB conventional instruction cache. To hide L1i miss latency, Zen 5 uses a decoupled branch predictor with a massive 24K BTB entries. Zen 5’s op cache covers the majority of the instruction stream on all three games, and enjoys a higher hitrate than the 5.2K entry op cache on Lion Cove. The L1i catches a substantial portion of op cache misses, though misses per instruction as calculated by L1i refills looks higher than on Lion Cove. 20-30 L1i misses per 1000 instructions is also a bit high in absolute terms, and Zen 5’s 1 MB L2 does a good job of catching nearly all of those misses. Still, a few occasionally slip past and come from the higher latency L3 just like on Lion Cove.
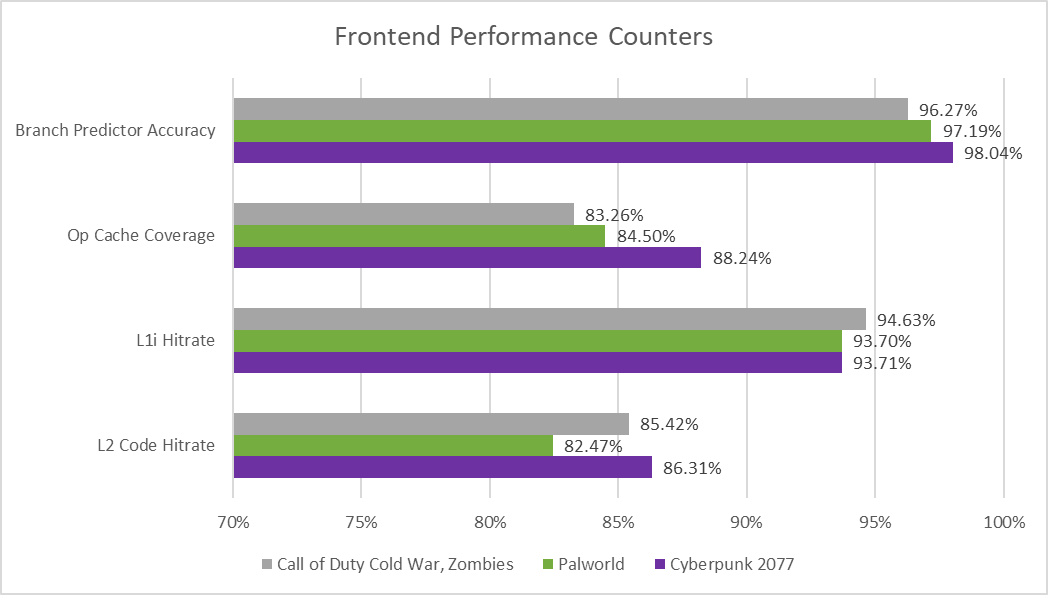
Branch prediction accuracy is high, though curiously slightly worse across all three titles than on Lion Cove. That’s surprising because Zen 5 managed better accuracy across SPEC CPU2017, with notable wins in difficult subtests like 541.leela. There’s a high margin of error in these comparisons, and the aforementioned changes to the tested scenes, but the consistent difference in both prediction accuracy and mispredicts per instruction is difficult to ignore.
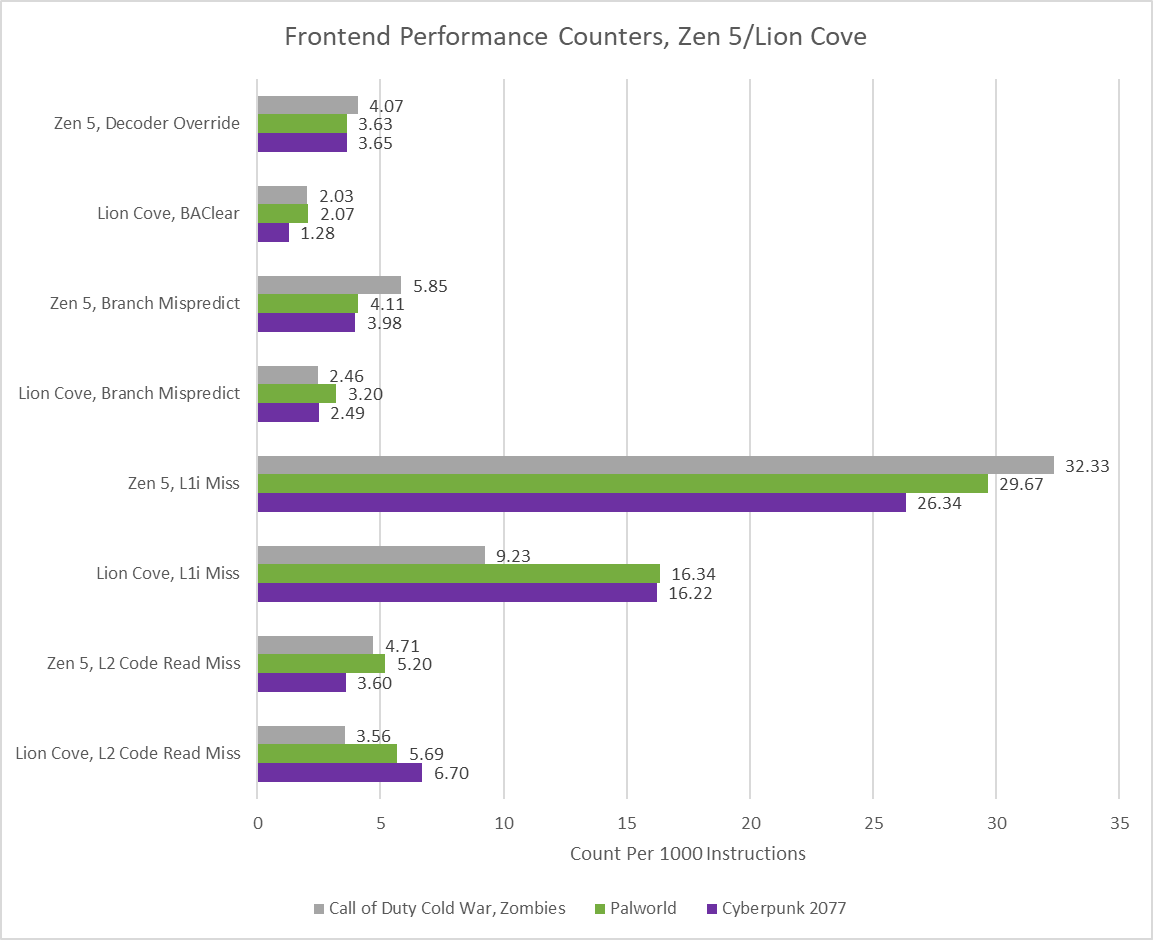
Mispredicts interrupt the branch predictor’s ability to run ahead of instruction fetch, and expose the frontend to cache latency as it waits for instructions to arrive from the correct path. A mispredict is a comparatively expensive redirect because it affects both the frontend latency and bad speculation categories. Another form of redirect comes from “decoder overrides” in AMD terminology, or “BAClears” (branch address clear) in Intel terms. These happen when the core discovers a branch in frontend stages after the branch predictor, typically when seeing a branch for the first time or when the branch footprint goes beyond the predictor’s tracking capabilities. A redirect from later frontend stages prevents bad speculation losses, but it does expose the core to L1i miss latency. Zen 5 surprisingly takes a few more decoder overrides than Intel does BAClears. It’s not great when its branch predictor needs to cover for more L1i misses in the first place.
Delays within the branch predictor can also cause frontend latency. Zen 5’s giant BTB is split into a 16K entry first level and a 8K entry second level. Getting a target from the second level is slower. Similarly, an override from the indirect predictor would cause bubbles in the branch prediction pipeline. However, I expect overrides from within the branch predictor to be a minor factor. The branch predictor can still continue following the instruction stream to hide cache latency, and short delays will likely be hidden by backend stalls in a low IPC workload.
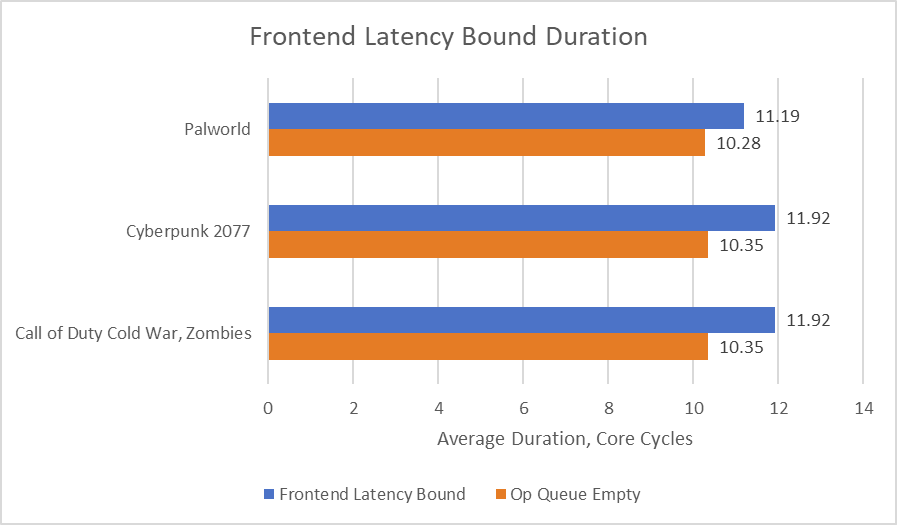
Stalls at the renamer due to frontend latency last for 11-12 cycles on average. Zen 5 doesn’t have events that can directly attribute instruction fetch stalls to L1i misses, unlike Lion Cove. 11-12 cycles however is suspiciously close to L2 latency. Of course, the average will be pulled lower by shorter stalls when the pipeline is resteered to a target in the L1i or op cache, as well as longer stalls when the target comes from L3 or DRAM.
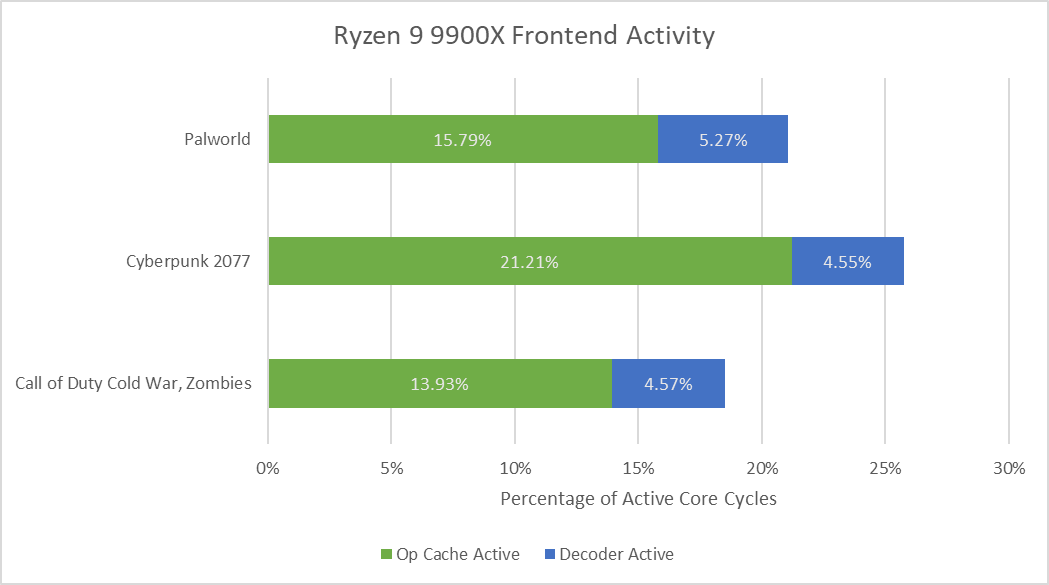
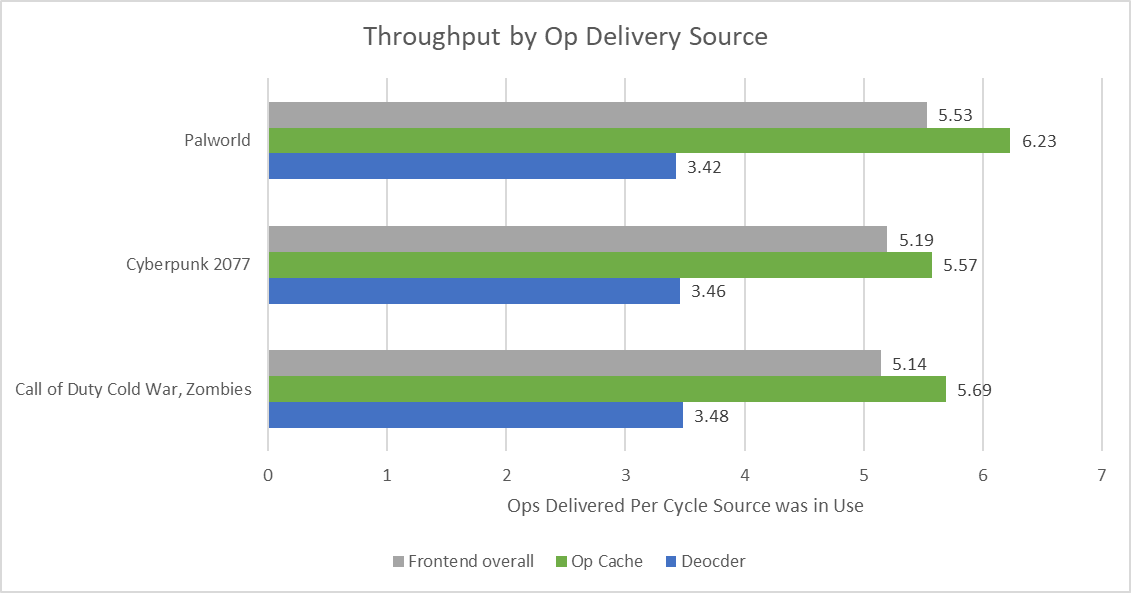
While frontend latency bound slots are a bigger factor, Zen 5 does lose some throughput due to being frontend bandwidth bound. Zen 5’s frontend spends much of its active time running in op cache mode. Surprisingly, average bandwidth from the op cache is a bit under the 8 micro-ops/cycle that would be required to fully feed the core. The op cache can nominally deliver 12 micro-ops per cycle, but average throughput hovers around 6 micro-ops per cycle.
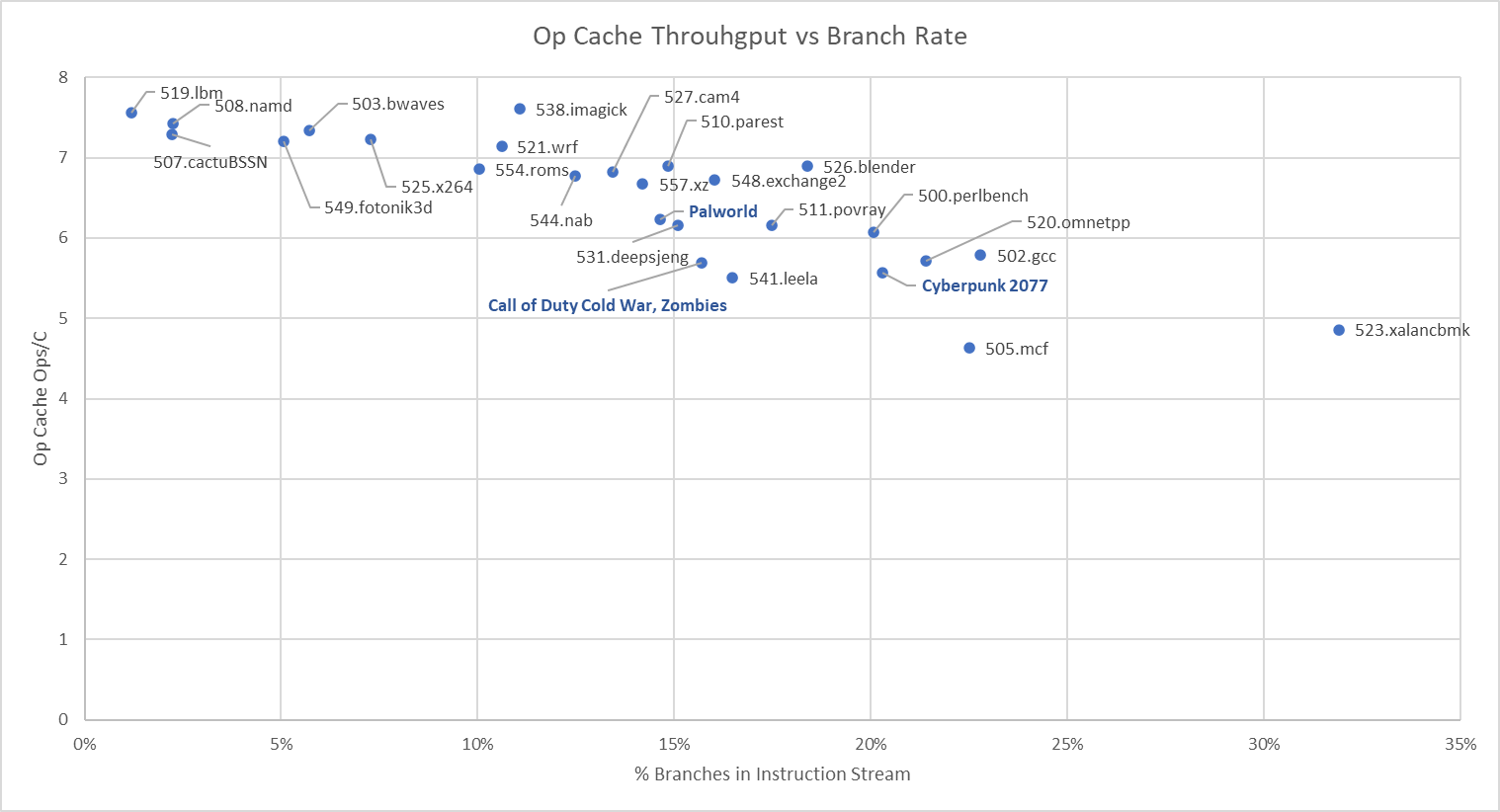
One culprit is branches, which can limit the benefits of widening instruction fetch: op cache throughput correlates negatively with how frequently branches appear in the instruction stream. The three games I tested land in the middle of the pack when placed next to SPEC CPU2017’s workloads. Certainly there’s room for improvement with frontend bandwidth too. But that room for improvement is limited because frontend bandwidth bound slots are few to start with.
Average decoder throughput is just under 4 micro-ops per cycle. The decoders are only active for a small minority of cycles, so they represent a small portion of the already small frontend bandwidth bound category. Certainly wider decoders wouldn’t hurt, but the impact would be insignificant.
Backend
Backend bound cases occur when the out-of-order execution engine runs out of entries in its various queues, buffers, and register files. That means it cannot accept more micro-ops from the renamer until it can retire some instructions and free up entries in those structures. In other words, the core has reached the limit of how far it can move ahead of a stalled instruction.
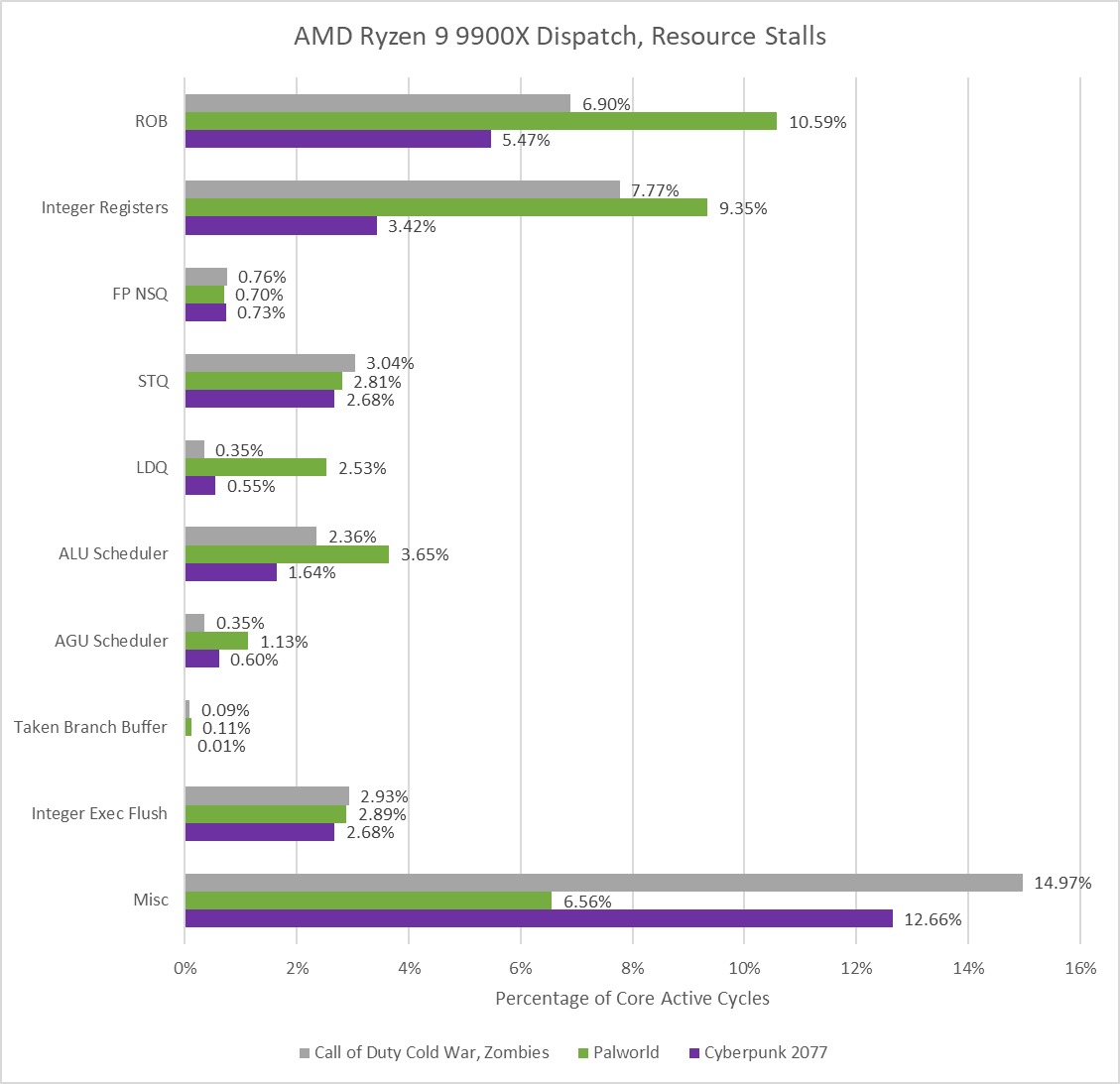
Zen 5’s integer register file stands out as a “hot” resource, often limiting reordering capacity before the core’s reorder buffer (ROB) fills. There’s a good chunk of resource stalls that performance monitoring events can’t attribute to a more specific category. Beyond that, Zen 5’s backend design has some bright points. The core’s large unified schedulers are rarely a limiting factor, unlike on TaiShan v110. Zen 5’s reorganized FPU places FP register allocation after a large non-scheduling queue, which basically eliminates FP-related reasons in the resource stall breakdown. In fairness, the older Zen 4 also did well in that category, even though its FP non-scheduling queue serves a more limited purpose of handling overflow from the scheduling queue. All of that means Zen 5 can often fill up its 448 entry ROB, and thus keep a lot of instructions in flight to hide backend memory latency.
When the backend fills up, it’s often due to cache and memory latency. Zen 5’s retire stage is often blocked by an incomplete load, and when it is, it tends to remain blocked longer than average, for around 18-20 cycles. That’s a sign that incomplete loads have longer latency than most instructions.
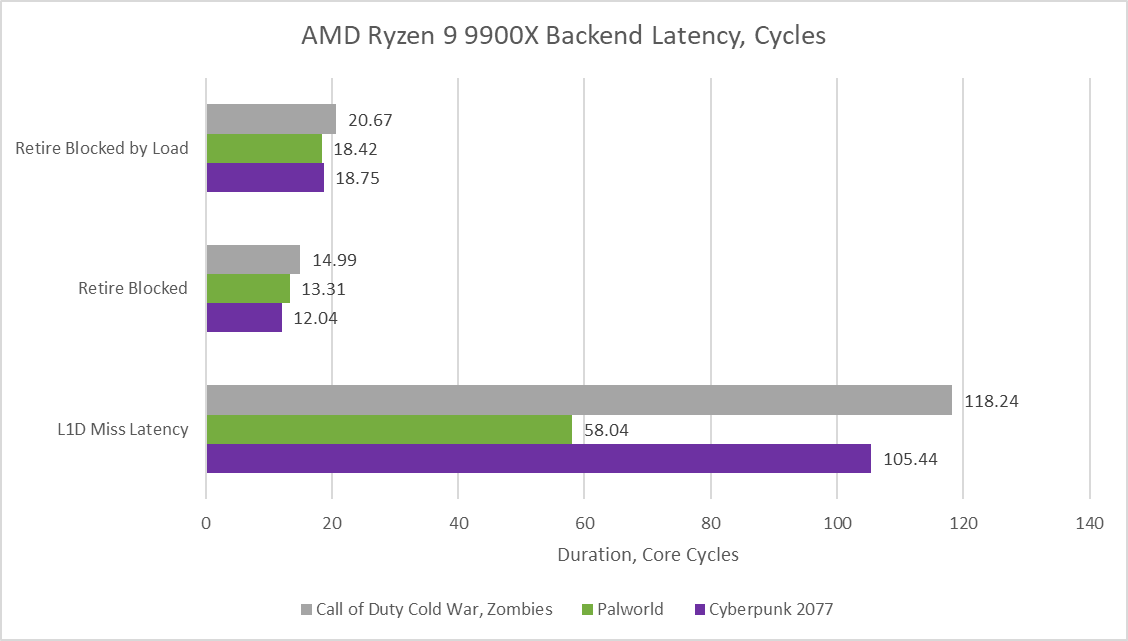
Average L1d miss duration is much longer and broadly comparable to similar measurements on Lion Cove. Curiously, Zen 5 sees higher average L1d miss latency in COD Cold War and Cyberpunk 2077, but lower latency in Palworld. But that’s not because Zen 5 has an easier time in Palworld. Rather, the core sees more L1d misses in Palworld. Those misses are largely caught by L2.
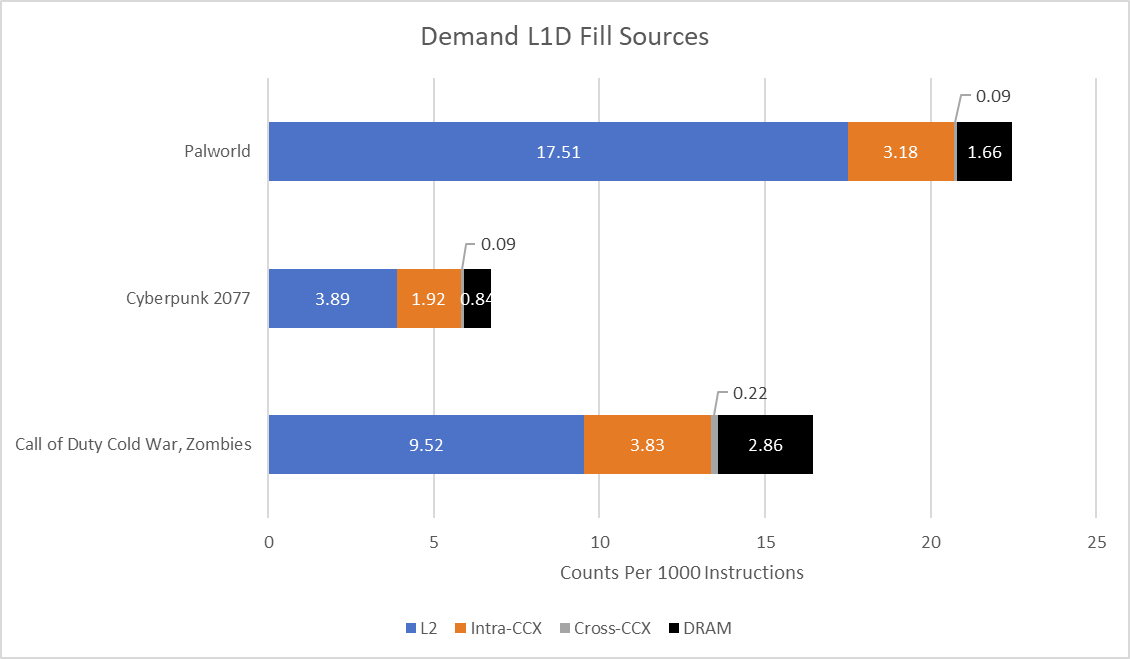
Comparing data from AMD and Intel is difficult for reasons beyond the typical margin of error considerations. Intel’s performance monitoring events account for load data sources at the retirement stage, likely by tagging in-flight load instructions with the data source and counting at retirement. AMD counts at the load/store unit, which means Zen 5 may count loads that don’t retire (for example, ones after a mispredicted branch). The closest I can get is using Zen 5’s event for demand data loads. Demand means the access was initiated by an instruction, as opposed to a prefetch. That should minimize the gap, but again, the focus here is on broad trends.
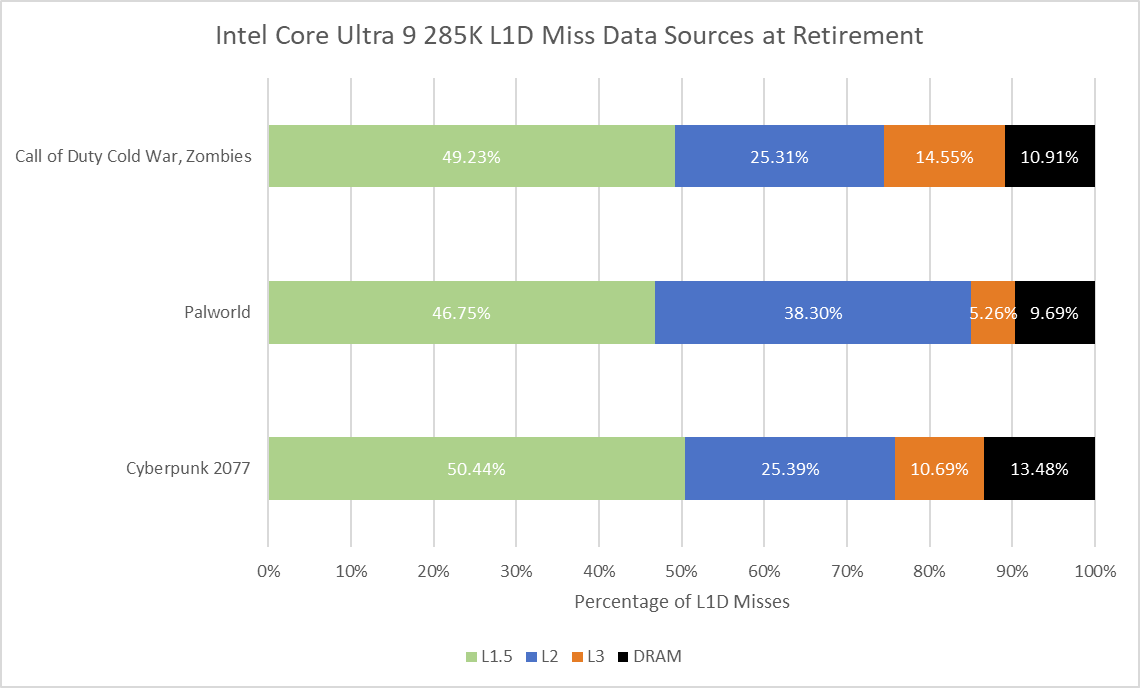
Caveats aside, Palworld seems to make a compelling case for Intel’s 192 KB L1.5d cache. It catches a substantial portion of L1d misses and likely reduces overall load latency compared to Zen 5. On the other hand, Zen 5’s smaller 1 MB L2 has lower latency than Intel’s 3 MB L2 cache. AMD also tends to satisfy a larger percentage of L1d misses from L3 in Cyberpunk 2077 and COD. Intel’s larger L2 is doing its job to keep data closer to the core, though Intel needs it because their desktop platform has comparatively high L3 latency.
On Zen 5, L3 hitrate for demand (as opposed to prefetch) loads comes in at 64.5%, 67.6%, and 55.43% respectively. Most L3 misses head to DRAM. Cross-CCX transfers account for a negligible portion of L3 miss traffic: sampled latency events at the L3 indicate cross-CCX latency is similar to or slightly better than DRAM latency. Therefore cross-CCX transfers are quite performant considering their rarity.
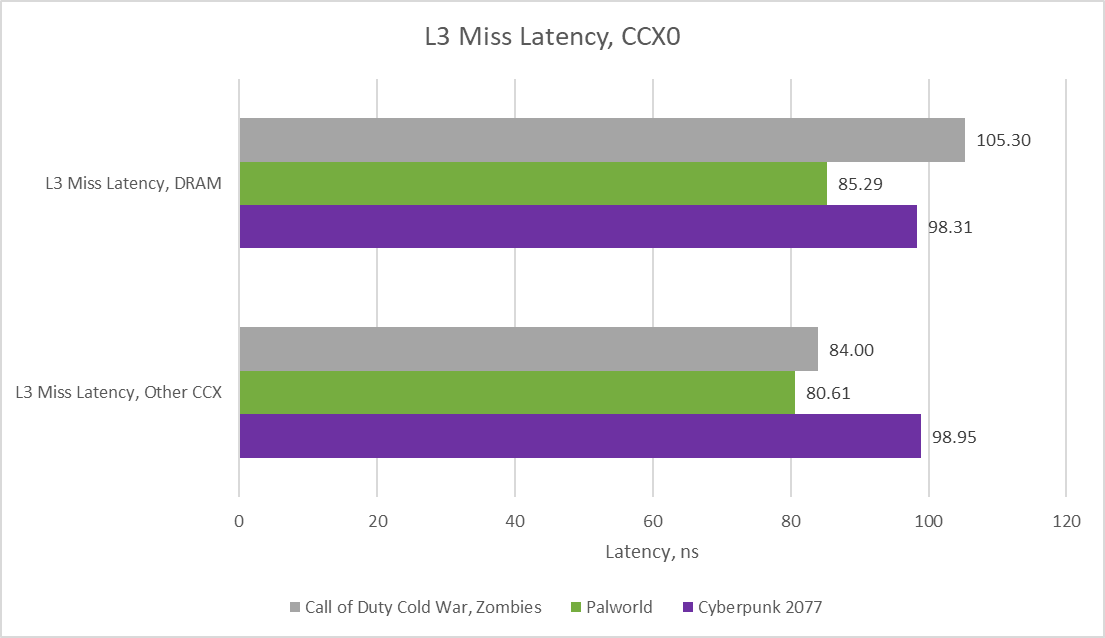
Performance monitoring data from running these games normally does not support the hypothesis that improving cross-CCX latency is likely to yield significant benefits, on account of their rarity, and better performance than DRAM accesses. DRAM latency from the L3 miss perspective is slightly better in Palworld and Cyberpunk 2077 compared to Intel's Arrow Lake, even though the Ryzen 9 9900X was set up with older and slower DDR5. The situation reverses in Call of Duty Cold War, perhaps indicating bursty demands for DRAM bandwidth in that title.
Forcing the Cross-CCX Latency Issue?
Running the games above in the normal manner did not generate considerable cross-CCX traffic. Dual-CCD Ryzen parts have the highest clocking cores located on one CCX, and Windows will prefer to schedule threads on higher clocking cores. This naturally makes one CCX handle the bulk of the work from games.
However, I can try to force increased cross-CCX traffic by setting the game process’s core affinity to split it across the Ryzen 9900X’s two CCX-es. I used Cyberpunk’s medium preset with upscaling disabled for the tests above. However for this test, I’m maximizing CPU load by using the low preset, FSR Quality upscaling, and crowd density turned up the maximum setting. I’ve also turned off boost to eliminate the effects of clock speed variation across cores.
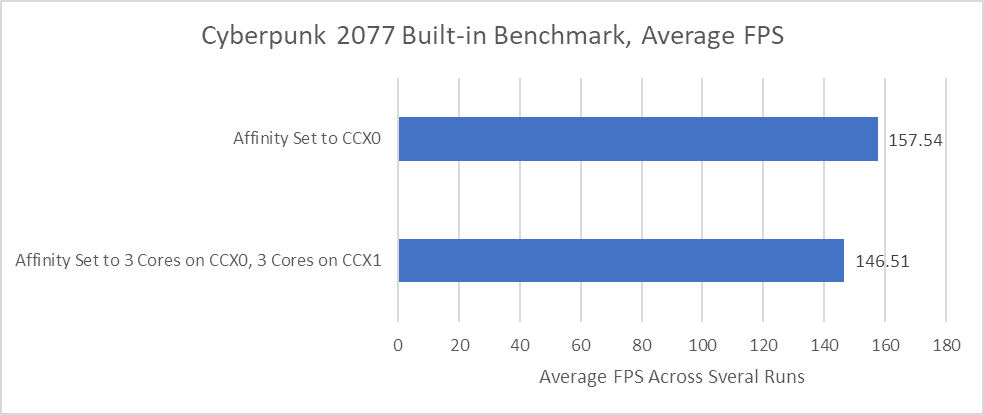
Doing so drops performance by 7% compared to pinning the game to one CCX. Cyberpunk 2077’s built-in benchmark does display a few percentage points of run-to-run variation, but 7% is outside the margin of error. Monitoring all L1D fill sources indicates a clear increase in cross-CCX access. This metric differs from demand accesses and is even less comparable to Lion Cove’s at-retirement account for load sources, because it includes prefetches. However, it does account for cases where a load instruction matches an in-flight fill request previously initiated by a prefetch. There’s also more error because useless prefetches will be included as well.
Performance monitoring events attribute this to cross-CCX accesses, which now account for a significant minority of off-CCX accesses. Fewer accesses are serviced by low latency data sources within the CCX, leading to reduced performance.
Final Words
Games are difficult, low-IPC workloads thanks to poor locality on both the data and instruction side. Zen 5’s lower cache and memory latency can give it an advantage on the data side, but the core remains underutilized due to frontend latency. Lion Cove’s 64 KB L1i is a notable advantage, unfortunately blunted by high L3 and DRAM latency on the Arrow Lake desktop platform. It’s interesting how Intel and AMD’s current cores face similar challenges in games, but comparatively struggle on different ends of the core pipeline.
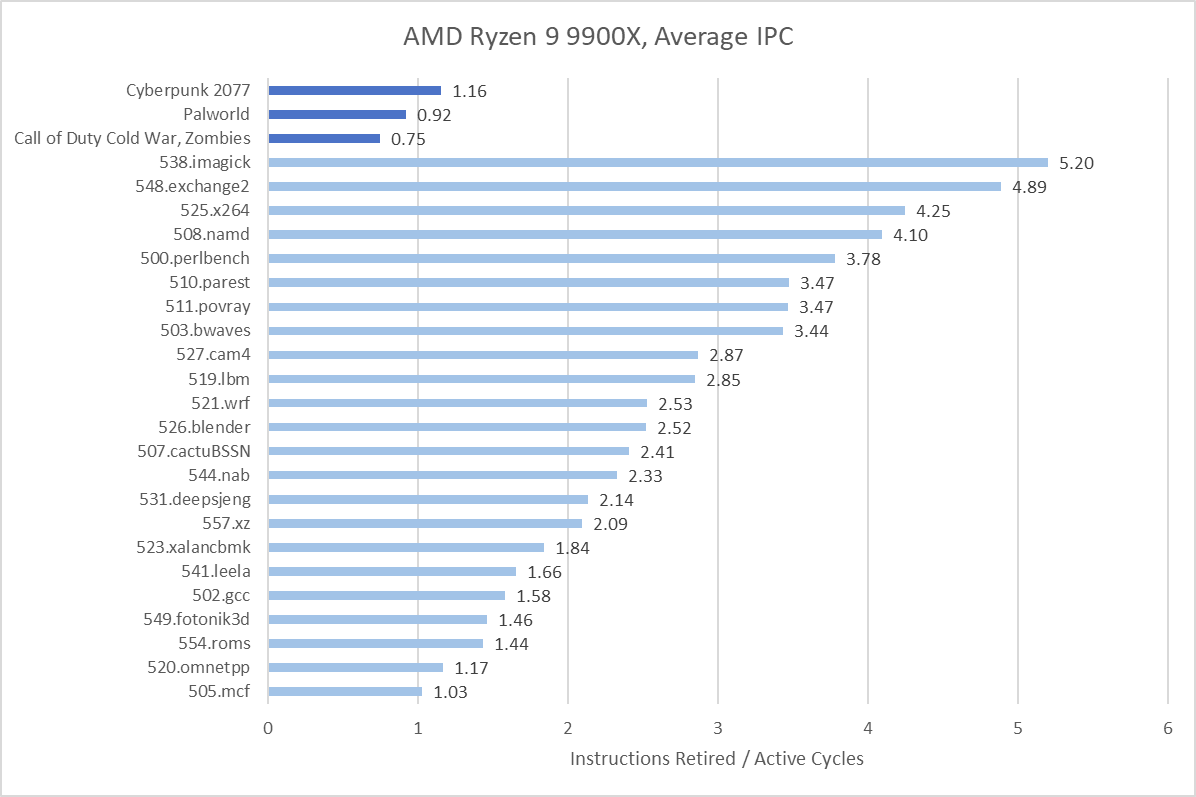
From a higher level view, AMD and Intel’s designs this generation appear to prioritize peak throughput rather than improving performance in difficult cases. A wider core with more execution units will provide the biggest benefits in high IPC workloads, where the core may spend a significant portion of time with plenty of instructions and data to chug through; SPEC CPU2017’s 538.imagick and 548.exchange2 are excellent examples. In contrast, workload with low average IPC will have far fewer “easy” high IPC sequences, limiting potential benefits from increased core throughput.
Of course, Zen 5 and Lion Cove both take measures to tackle those lower IPC workloads. Better branch prediction and increased reordering depth are staples of each new CPU generation; they’re present on Zen 5 and Lion Cove, too. But pushing both forwards runs into diminishing returns: catching the few remaining difficult branches likely requires disproportionate investment in branch prediction resources. Similarly, increasing reordering capacity requires proportionate growth in register files, load/store queues, schedulers, and other expensive core structures.
Besides making the core more latency-tolerant, AMD and Intel could try to reduce latency through better caching. Intel’s 64 KB L1i deserves credit here, though it’s not new to Lion Cove and was present on the prior Redwood Cove core as well. Zen 5’s L2/L3 setup is largely unchanged from Zen 4. L2 caches are still 1 MB, and the CCX-shared 32 MB or 96 MB (with X3D) L3 is still in place. A hypothetical core with both Intel’s larger L1i and AMD’s low latency caching setup could be quite strong indeed, and any further tweaks in the cache hierarchy would further sweeten the deal.
System topology is potentially an emerging concern. High core counts on today’s flagship desktop chips are a welcome change from the quad core pattern of the early 2010s, but achieving high core counts with a scalable, cost-effective design is always a challenge. AMD approaches this by splitting cores into clusters (CCX-es), which has the downside of increased latency when a core on one cluster needs to read data recently written by a core on another cluster. The three games I tested do the bulk of their work on one CCX, but a game that spills out of one CCX can see its multithreaded performance scaling limited by this cross-CCX latency.

For now, this doesn’t appear to be a major problem, contrary to the criticism AMD often takes for high cross-CCX latency. Forcing a game to run on three cores per CCX is a very artificial scenario, and AMD has not used a split CCX setup on their low end 6-core parts since Zen 2. Data from other reviewers covering a larger variety of games suggests multi-CCX parts turn in similar performance to their single-CCX counterparts, with the exception of Zen 4 parts where the two CCX-es have very different clock speeds and cache capacities. AMD’s practice of placing all fast cores on one CCD and more recently, parking cores on a CCD, seem to be working well.
Similarly, Intel’s “Thread Director” has done a good job of ensuring games don’t lose performance by being scheduled onto the density optimized E-Cores. TechPowerUp notes performance differences with E-Cores enabled or disabled rarely exceeded 10% in either direction. Thus the core count scaling techniques employed by both AMD and Intel don’t impact gaming performance to a significant degree. Today’s high end core counts may become mainstream in tomorrow’s midrange or low end chips, and future games may spill out of a 9900X’s CCX or a 285K’s P-Cores. But even in that case, plain cache and memory latency will likely remain the biggest factors holding back gaming performance.
With that in mind, I look forward to seeing what next generation cores will look like. AMD, Intel, and any other CPU maker has to optimize their cores for a massive variety of workloads. Games are just one workload in the mix, alongside productivity applications, high performance computing, and server-side code. However, I would be pleased if the focus shifted away from pushing high IPC cases to even higher IPC, towards maintaining better performance in difficult low IPC cases.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
Quite fascinating. Before Zen 5 launched, various sources, including articles here, seemed to at least vaguely imply that AMD's "two-ahead" branch predictor would be able to follow two branches per cycle even for a single thread, whereas post-launch it quickly became clear that that wasn't the case, and also that, as reiterated by this article, the op-cache only seems to be able to deliver six ops per cycle for one thread, which seems a bit at odds with the 8-wide renamer.
All taken together, I can't help but wonder if there wasn't something that turned out badly with Zen 5's front-end at a late stage, and they were forced to neuter it to prevent bugs. If true, and they manage to fix those problems with Zen 6, that could paint quite a positive picture for Zen 6 IPC improvements, not least coupled with the rumors that Zen 6 is using a new, lower-latency die-to-die interconnect (which they're already kind of using for Strix Halo, aren't they?).
Is there something intrinsic to video games that lead low IPC computations or does low IPC simply follow from lack of optimisation at the software development level?
Also, since Intel is backend latency constrained while AMD is front-end latency constrained, does that mean code needs to be optimised in different ways depending on which processor it will run on?