
RDNA 4’s Raytracing Improvements

Raytraced effects have gained increasing adoption in AAA titles, adding an extra graphics quality tier beyond traditional “ultra” settings. AMD has continuously advanced their raytracing implementation in response. Often, this involved fitting the GPU’s general architecture to the characteristics of raytracing workloads. On RDNA 4, examples include “out-of-order” memory access and dynamic register allocation. Both are targeted at raytracing, but other applications can benefit too, though perhaps not to the same degree.


Compared to RDNA 3, RDNA 4’s RT IP 3.1 gets doubled intersection testing, oriented bounding boxes, primitive compression, and other goodies. Fixed function hardware is tightly tied to predefined data structures, and AMD has unsurprisingly updated those data structures to utilize those updated features.
Doubled Intersection Engines, Wider BVH
RDNA 4’s doubled intersection test throughput internally comes from putting two Intersection Engines in each Ray Accelerator. RDNA 2 and RDNA 3 Ray Accelerators presumably had a single Intersection Engine, capable of four box tests or one triangle test per cycle. RDNA 4’s two intersection engines together can do eight box tests or two triangle tests per cycle. A wider BVH is critical to utilizing that extra throughput.
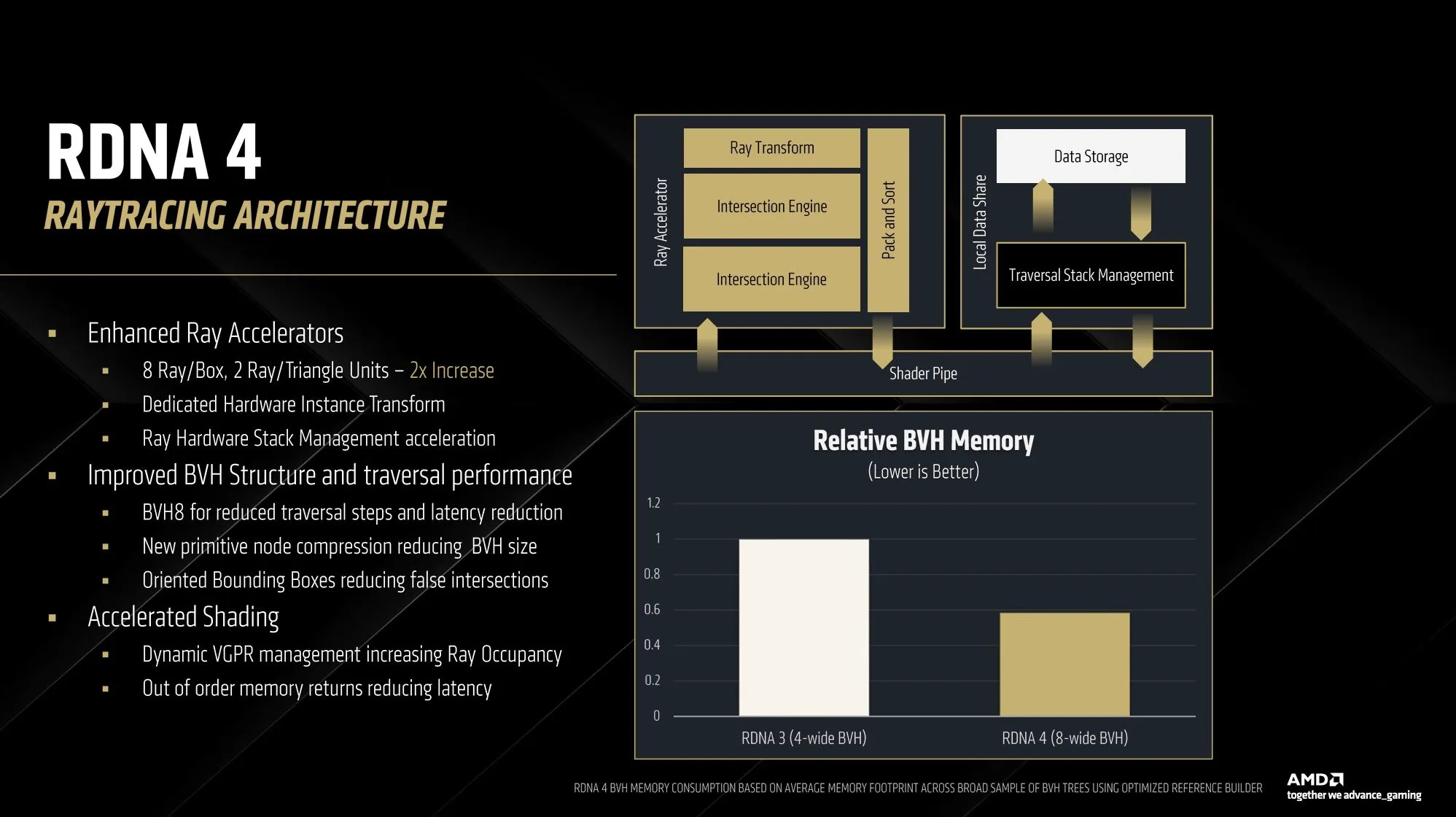
Raytracing uses a Bounding Volume Hierarchy (BVH) that recursively subdivides scene geometry. Each node represents a 3D box-shaped space, and links to sub-boxes. Intersection tests determine which link (child) to follow, until traversal reaches the bottom of the tree where the node contains triangle data instead of links to sub-boxes. Each traversal step therefore scopes down the intersection search to a smaller box. More intersection test throughput can speed up this traversal process.
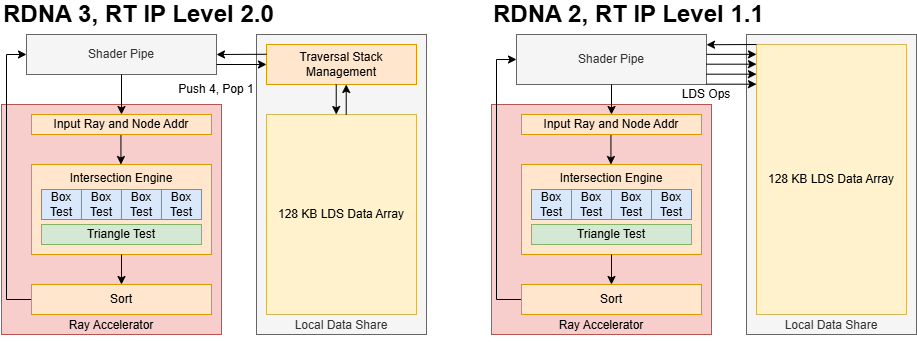
But speeding up traversal isn’t as simple as doubling up intersection test throughput. Each traversal step is a pointer chasing operation, which incurs memory latency. GPUs have high cache and DRAM latency compared to a CPU, but excel at parallel compute. RDNA 4 moves to 8-wide box nodes, up from 4-wide ones in RDNA 2 and 3. A wider box node presents more parallel work at each step. More importantly, it allows a “fatter” tree that requires fewer traversal steps to reach the bottom. Thus the 8-wide BVH shifts emphasis from latency to throughput, avoiding a key GPU weakness.
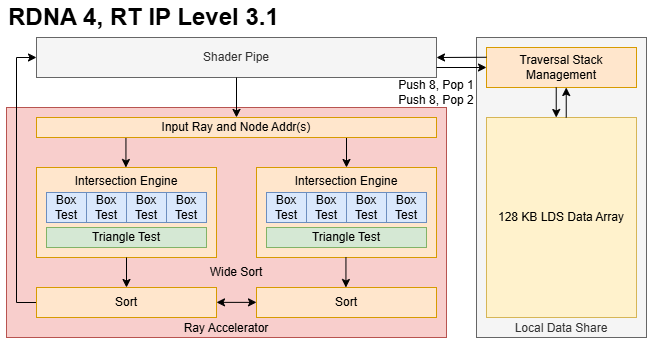
Since RDNA 2, AMD has used a conservative raytracing strategy where a shader program controls the raytracing process from ray generation to result shading. During BVH traversal, a raytracing shader accesses RDNA 4’s Ray Accelerator with a new IMAGE_BVH8_INTERSECT_RAY instruction. This instruction takes a ray and a pointer to a 8-wide BVH node, and uses both Intersection Engines together. Output from both Intersection Engines head to a sorting unit, which can either sort the two 4-wide halves separately or sort across all eight results with a “wide sort” option. To speed up traversal, AMD had hardware traversal stack management in the LDS since RDNA 3. LDS stack management gets updated in RDNA 4 with a new DS_BVH_STACK_PUSH8_POP1_RTN_B32 instruction1.
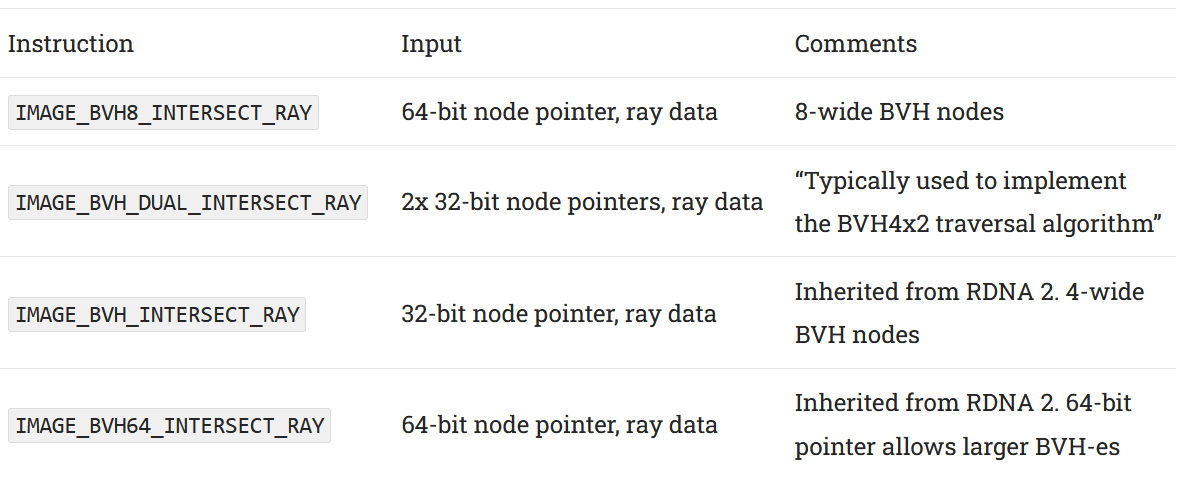
An 8-wide BVH isn’t the only way to use RDNA 4’s doubled intersection test throughput. RDNA 4 adds an IMAGE_BVH_DUAL_INTERSECT_RAY instruction, which takes a pair of 4-wide nodes and also uses both Intersection Engines. Like the BVH8 instruction, IMAGE_BVH_DUAL_INTERSECT_RAY produces two pairs of 4 intersection test results and can intermix the eight results with a “wide sort” option. The traversal side likewise gets a DS_BVH_STACK_PUSH8_POP2_RTN_B64 instruction. AMD doesn’t describe the “BVH4x2” traversal algorithm, but it’s not hard to imagine what is considering what the two instructions above do. A ray can intersect multiple bounding boxes, creating multiple traversal paths. BVH4x2 almost certainly takes two of those paths in parallel, with two paths popped from the LDS and tested in the Ray Accelerator with each traversal step.
So far I’ve only seen AMD generate 8-wide BVH-es for RDNA 4. That includes DirectX 12’s procedural geometry example, 3DMark tests, Cyberpunk 2077, Elden Ring, GTA V Enhanced Edition, and Quake 2 RTX. BVH4x2 traversal is less efficient than using a 8-wide BVH, because it requires more memory accesses and generates more LDS traffic. Furthermore, BVH4x2 relies in having at least two valid traversal paths to fully feed the Ray Accelerator, and how often that’s true may vary wildly depending on the ray in question. I’m not sure why AMD added a way to utilize both Intersection Engines with a 4-wide BVH.
Oriented Bounding Boxes
BVH-es traditionally use axis aligned bounding boxes (AABBs), meaning a box’s boundaries are aligned with the 3D world’s x, y, and z axes. Axis aligned boxes simplify intersection tests. However, game geometry is often not axis aligned. In those cases, an axis aligned box may end up much larger than the geometry it’s trying to contain, creating a lot of empty space. Rays that intersect the empty space end up taking useless traversal steps into the box before further intersection tests realize the path was useless.
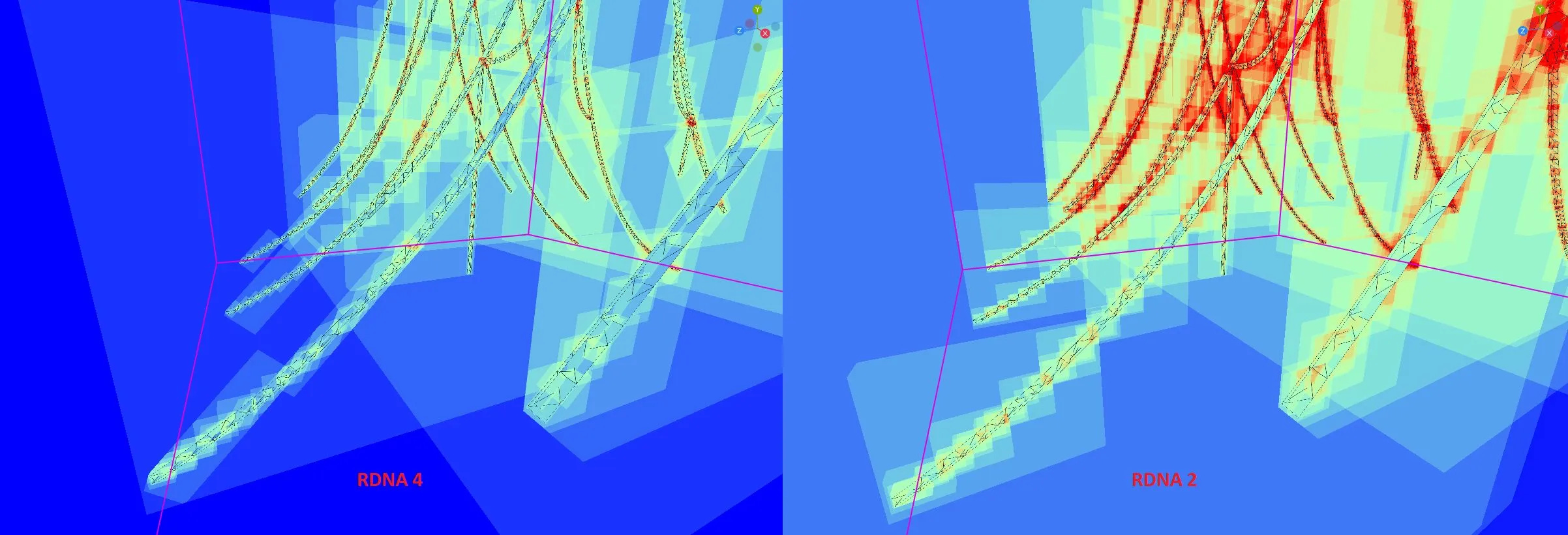
RDNA 4 addresses this with Oriented Bounding Boxes (OBBs), where the bounding box is rotated to better approximate geometry within it. Storing a 3×3 3D rotation matrix for each box would dramatically increase memory usage. RDNA 4 therefore strikes a compromise. Each box node only specifies one OBB rotation for all of its children. For further storage savings, the OBB matrix is not stored in the node at all. Instead, the node stores an OBB matrix index, which is looked up in a table of 104 predefined matrices. In code, the matrix is stored as 9 packed 6-bit indices, which refer to entries in a second level lookup table with 26 unique FP32 values3.

AMD’s OBB strategy therefore takes a best-effort approach to reduce useless box intersections with minimal storage cost. It’s not trying to generate perfectly optimal bounding box rotations every time. Thanks to this strategy, 8-wide box nodes remain reasonably sized at 128 bytes, and continue to match RDNA’s cacheline length. While the lookup table specified in code doesn’t necessarily show the exact hardware implementation, a simplistic calculation indicates the lookup table would use about 800 bytes of storage. That would make it small enough to fit in a small ROM within the Ray Accelerator.
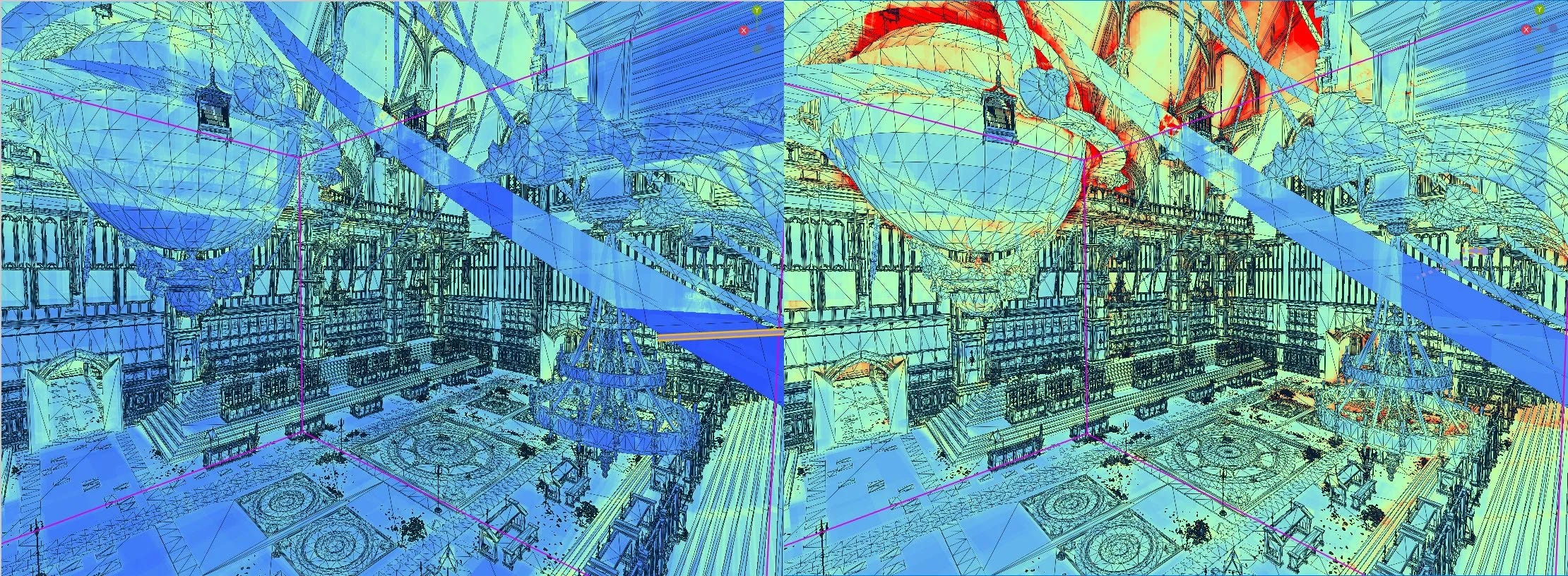
Compromises of course leave room for improvement. Chains hanging from the ceiling in Elden Ring’s Debate Parlor present an optimal case for RDNA 4’s OBBs, because one rotation can fit well across all of the chains on each side. The chandeliers are another story, with four support chains each have different rotations. AMD selects an OBB that matches chain rotation in the Y (up) axis, but not X/Z. As a result the OBBs for each chain leave significant empty space that could result in false intersections. It’s still better than RDNA 2’s aligned bounding boxes, but there’s clearly room for improvement as well.
Using one OBB rotation across the box is likely a necessary compromise. A simple way to handle OBB intersection testing is to rotate the incoming ray so that the box and ray become axis aligned (just with a different set of axes). RDNA 4 adds a ray transform block to the Ray Accelerator. AMD doesn’t explicitly say the transform block helps with OBBs. Instead, it’s used for transitions between top and bottom level acceleration structures (TLAS/BLAS). DirectX raytracing splits the BVH into two levels because a BLAS can be reused many times with different positions and rotations. That’s convenient for handling several copies of the same object, like the same chair type placed several times around a room.
…the addition of a dedicated ray transform block, and this is used to offload the transformation that occurs as you transition from the top level of the ray acceleration structure into the bottom level…
AMD Radeon Press Briefing Video
A TLAS to BLAS transition would involve rotating the ray to allow axis-aligned intersection tests within the BLAS, a similar operation to rotating a ray for OBB tests. A key difference is that traversal steps involving OBBs may happen more often than TLAS to BLAS transitions. AMD’s Ray Accelerator aims to handle a box node every cycle. Transforming a ray would involve multiplying both the origin and direction vector by a 3×3 rotation matrix, which naively requires 36 FLOPs (Floating Point Operations) per transform. At 2.5 GHz that would be 5.04 ray transformation TFLOP/s across the RX 9070’s ray accelerators. Providing different ray rotations for all eight boxes in a box node would multiply that figure by eight.
AMD could also implement OBB-related ray transforms within the Intersection Engines. RDNA 4 can use OBBs with RDNA 2/3 legacy 4-wide box nodes, slipping the OBB matrix ID into into previously unused padding bits near the end of the 128B structure. BVH4x2 traversal may run into two nodes that specify different OBB rotations. That would require applying two ray transformations to fully feed both Intersection Engines. Even in that case, two ray transforms are far less expensive than eight, so AMD’s compromise makes sense.
Primitive Node Compression
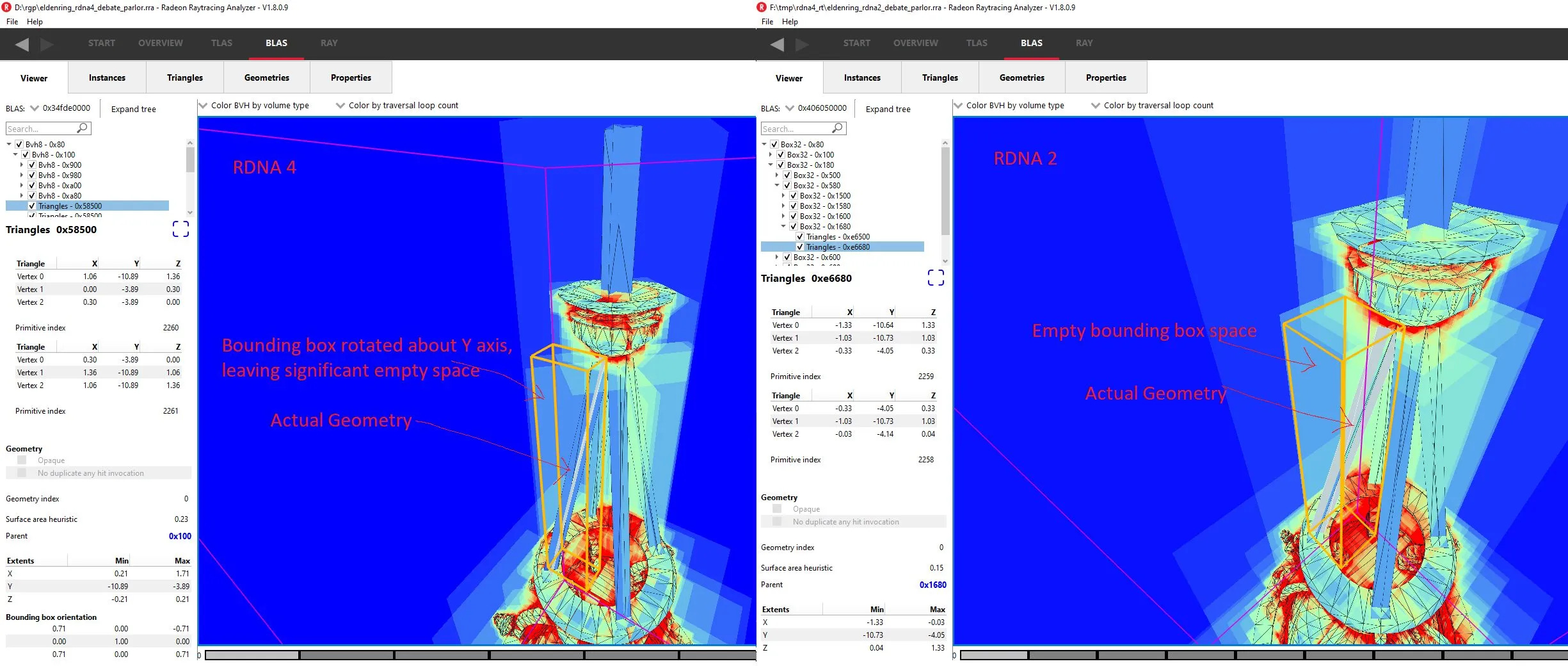
Minimizing BVH footprint is critical. A smaller BVH reduces VRAM consumption, cuts bandwidth requirements, and makes more economical use of cache capacity. RDNA 2 and RDNA 3 took a basic step with compressed triangle pairs, where a 64 byte triangle node could store a pair of triangles that share a side. Intel also does this. RDNA 4 goes further by packing multiple triangle pairs into a new 128 byte compressed primitive node.
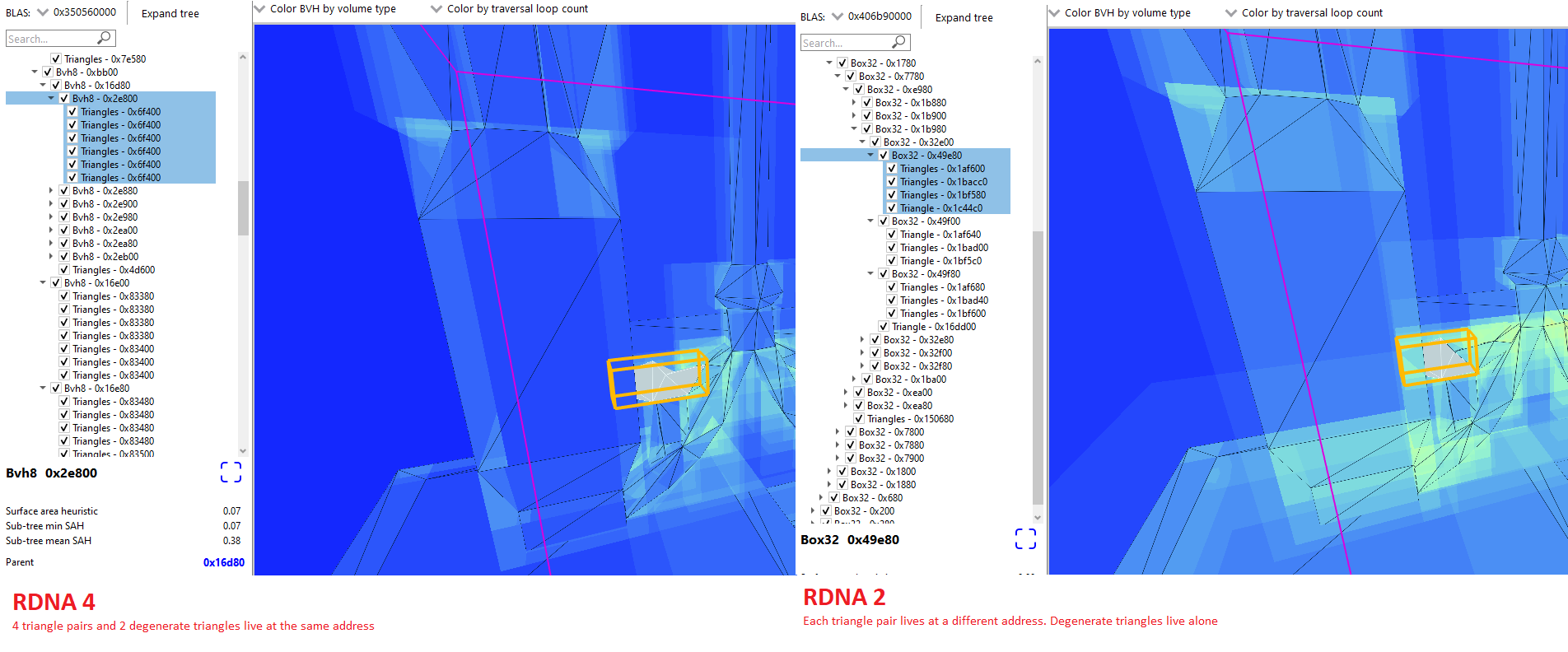
RDNA 4’s compressed primitive node only stores unique vertices across its triangle pairs. Further gains come from finding the minimum number of trailing zeroes across vertex coordinates’s bitwise FP32 representations, and dropping those trailing zeroes from storage5. Code suggests a RDNA 4 primitive node can describe up to eight triangle pairs or up to 16 unique vertices.

In practice compression efficiency varies wildly depending on the nature of game geometry, but RDNA 4 often represents more than two triangle pairs in a 128 byte primitive node. While not mentioned in AMD’s presentation, RDNA 4 represents box extents with quantized 12-bit integers instead of FP32 values6. That lets RDNA 4 keep its 8-wide box node at 128 bytes, just like RDNA 2/3’s 4-wide box nodes.

Like OBBs, primitive compression increases hardware complexity. Compressed primitive nodes don’t require additional compute in the Ray Accelerator. However, they do force it to handle non-aligned, variable length data fields. An Intersection Engine would have to parse the 52-bit header before it knows the data section’s format. Then, leading zero compression would require shifting the packed values to reconstruct the original FP32 values. Reducing memory footprint often comes with extra hardware complexity. In a latency critical application like raytracing, placing a higher burden on hardware is probably worth it.
BVH Optimizations in Practice
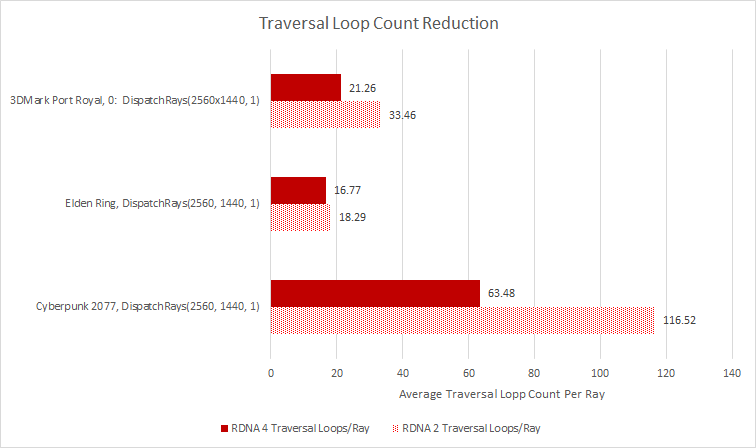
In Elden Ring and 3DMark’s Port Royal benchmark, AMD’s Radeon Raytracing Analyzer indicates that RDNA 4 achieves a decent BVH size reduction. The same curiously doesn’t apply to Cyberpunk 2077. However, Cyberpunk 2077 has a more dynamic environment with unpredictable NPC counts and movement paths, so the margin of error is definitely higher.
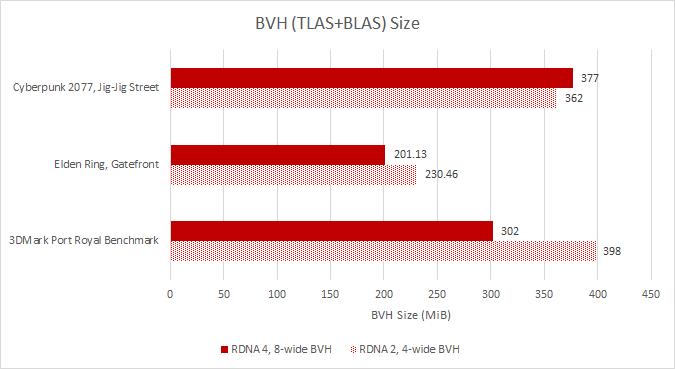
RDNA 4’s biggest wins come from reducing traversal step count. Lining up corresponding DispatchRays calls shows RDNA 4 goes through fewer traversal steps per ray. Cyberpunk 2077 is a particularly good case. RDNA 4 is still doing more intersection tests overall, because each traversal step requires eight intersection tests compared to four on RDNA 2, and traversal step count isn’t halved or lower. The additional work is well worth it though. GPUs aren’t latency optimized, so trading latency-bound pointer chasing steps for more parallel compute requirements is a good strategy. Gains in Elden Ring are minor by comparison, but any reduction is welcome considering high GPU cache latency.
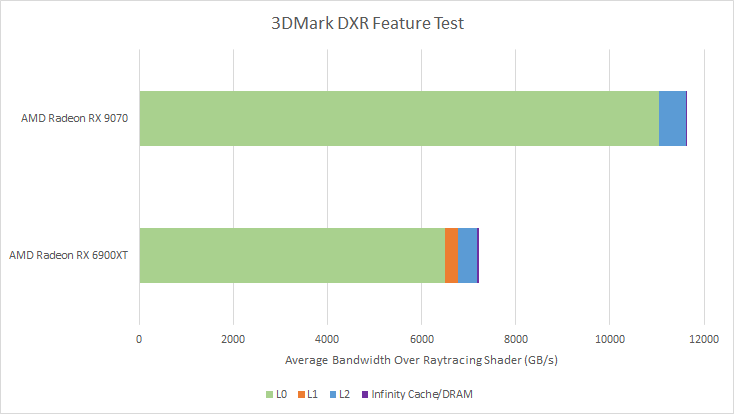
In a frame captured from 3DMark’s DXR feature test, which raytraces an entire scene with minimal rasterization, the Radeon RX 9070 sustained 111.76G and 19.61G box and triangle tests per second, respectively. For comparison the RDNA 2 based Radeon RX 6900XT did 38.8G and 10.76G box and triangle tests per second. Ballparking Ray Accelerator utilization is difficult due to variable clock speeds on both cards. But assuming 2.5 GHz gives 24% and 10.23% utilization figures for RDNA 4 and RDNA 2’s Ray Accelerators. RDNA 4 is therefore able to feed its bigger Ray Accelerator better than RDNA 2 could. AMD has done a lot since their first generation raytracing implementation, and the cumulative progress is impressive.
Final Words
RDNA 2 introduced AMD’s first hardware raytracing implementation in the PC scene. It took a conservative approach to raytracing by accelerating intersection testing but little else. AMD has made steady progress since then, shaping GPU hardware and the raytracing workload to match each other. RDNA 4 continues to use RDNA 2’s high level raytracing strategy, with a compute thread managing the raytracing process all the way from ray generation to traversal to result handling. But over several generations, AMD’s engineers have piled on improvements that put RDNA 4 leagues ahead.

AMD’s tools like the Radeon Raytracing Analyzer and Radeon GPU Profiler provide a fascinating look into how those improvements work together under the hood. Open source code further paints a picture where AMD is working nonstop on their raytracing hardware. Unused (possibly Playstation related) RT IP 1.0 and 3.0 levels provide more snapshots into AMD’s hardware raytracing evolution.
Still, RDNA 4 has room for improvement. OBBs could be more flexible, and first level caches could be larger. Intel and Nvidia are obvious competitors too. Intel has revealed a lot about their raytracing implementation, and no raytracing discussion would be complete without keeping them in context. Intel’s Raytracing Accelerator (RTA) takes ownership of the traversal process and is tightly optimized for it, with a dedicated BVH cache and short stack kept in internal registers. It’s a larger hardware investment that doesn’t benefit general workloads, but does let Intel even more closely fit fixed function hardware to raytracing demands. Besides the obvious advantage from using dedicated caches/registers instead of RDNA 4’s general purpose caches and local data share, Intel can keep traversal off Xe Core thread slots, leaving them free for ray generation or result handling.

AMD’s approach has advantages of its own. Avoiding thread launches between raytracing pipeline steps can reduce latency. And raytracing code running on the programmable shader pipelines naturally takes advantage of their ability to track massive thread-level parallelism. As RDNA 4 and Intel’s Battlemage have shown, there’s plenty of room to improve within both strategies. I’m excited to see how everything plays out as AMD, Intel, and Nvidia evolve their raytracing implementations.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
References
primitiveNode.hlsli in AMD’s GPU Ray Tracing Library
OrientedBoundingBoxes.hlsl and ObbCommon.hlsl in AMD’s GPU Ray Tracing Library
EncodeHwBVH3_1.hlsl in AMD’s GPU Ray Tracing Library
PrimitiveStructureEncoder3_1.hlsl in AMD’s GPU Ray Tracing Library. Describes trailing zero compression, and ComputeCompressedRanges has each lane find its vertex in the LDS during BVH build, set corresponding bits in a bitmask, then count set bits to find the unique vertex count
Multiple RT IP 3.1 BVH building functions call ComputeQuantizedBounds with numQuantBits=12, which then calls ComputeQuantizedMin/ComputeQuantizedMax, which appears to quantize to a 12-bit integer because the max value is (1 << numQuantBits -1) * 1.0f. It’s the maximum integer value that’ll fit in the specified quantization bits multiplied by a FP value of 1 to provide the max quantized value as a float.
BoxNode1_0.hlsli, defines a 4-wide box node for RT IP 1.0
As much as I love RDNA4’s ray tracing improvements, I’ve been reading about them for two weeks straight and I’m getting SO THIRSTY for some new C&C content!!!
"Transforming a ray would involve multiplying both the origin and direction vector by a 3×3 rotation matrix, which naively requires 36 FLOPs (Floating Point Operations) per transform."
There's an error in your calculations. A naive 3x3 matrix-vector multiplication without FMA requires 15 operations, and with FMA it reduces down to 9 operations.