
RDNA 4's "Out-of-Order" Memory Accesses
Examining RDNA 4's out-of-order memory accesses in detail, and investigating with testing

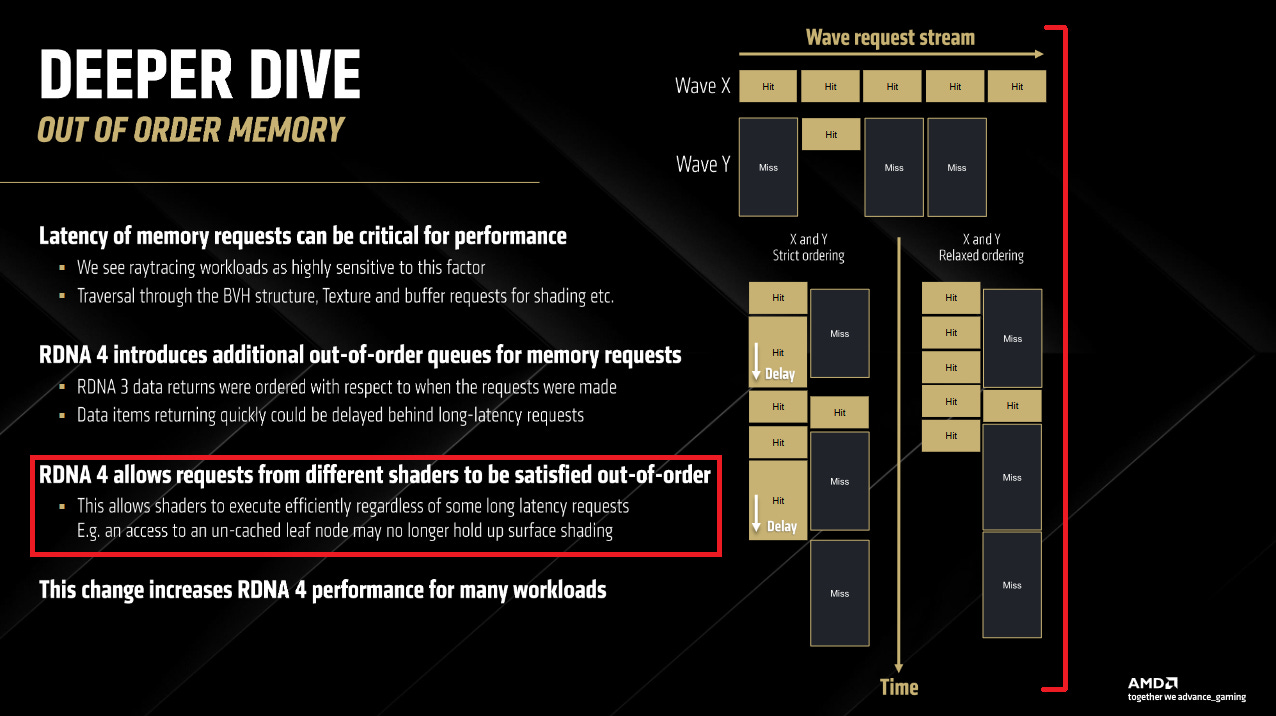
AMD's RDNA 4 brings a variety of memory subsystem enhancements. Among those, one slide stood out because it dealt with out-of-order memory accesses. According to the slide, RDNA 4 allows requests from different shaders to be satisfied out-of-order, and adds new out-of-order queues for memory requests.

Cross-Wave Out-of-Order Memory Accesses
AMD apparently had a false dependency case in the memory subsystem prior to RDNA 4. One wave could wait for a memory loads made by another wave. A "wavefront", "wave", or "warp" on a GPU is the rough equivalent of a CPU thread. It has its own register state, and can run out of sync with other waves. Each wave's instructions are independent from those in other waves with very few exceptions (like atomic operations).
In RDNA 3, there was a strict ordering on the return of data, such that effectively a request that was made later in time was not permitted to pass a request made earlier in time, even if the data for it was ready much sooner.
Navi 4 Architecture Deep Dive, Andrew Pomianowski, CVP, Silicon Design Engineering (AMD)
A fundamental tenet of multithreaded programming is that you get no ordering guarantees between threads unless you make it happen via locks or other mechanisms. That's what makes multithreaded performance scaling work. AMD's slide took me by surprise because there's no reason memory reads should be an exception. I re-watched the video several times and stared at the slide for a while to see if that's really what they meant. They clearly meant it, but I still didn't believe my eyes and ears. So I took time to craft a test for it.
Testing It
AMD's slide describes a scenario where one wave's cache misses prevent another wave from quickly consuming data from cache hits. Causing cache misses is easy. I can pointer chase through a large array with a random pattern ("wave Y"). Similarly, I can keep accesses within a small memory footprint to get cache hits ("wave X"). But doing both at the same time is problematic. Wave Y may evict data used by wave X, causing cache misses on wave X.
Instead of going for cache hits and misses, I tested by seeing whether waiting on memory accesses in one wave would falsely wait in on memory accesses made by another. My "wave Y" is basically a memory latency test, and makes a fixed number of accesses. Each access depends on the previous one's result, and I have the wave pointer chase through a 1 GB array to ensure cache misses. My "wave X" makes four independent memory accesses per loop iteration. It then consumes the load data, which means waiting for data to arrive from memory.

Once wave Y completes all of its accesses, it sets a flag in local memory. Wave X makes as many memory accesses as it can until it sees the flag set, after which it writes out its “score” and terminates. I run both waves in the same workgroup to ensure they share a WGP, and therefore share as much of the memory subsystem as possible. Keeping both waves in the same workgroup also lets me place the “finished” flag in local memory. Wave X has to check that flag every iteration, and it’s best to have flag checks not go through the same caches that wave Y is busy contaminating.

If each wave X access gets delayed by a wave Y one, I should see approximately the same number of accesses from both. Instead on RDNA 3, I see wave X make more accesses than wave Y by exactly the loop unroll factor on wave X. AMD's compiler statically schedules instructions and sends out all four accesses before waiting on data. It then waits on load completion with s_waitcnt vmcnt(...) instructions.
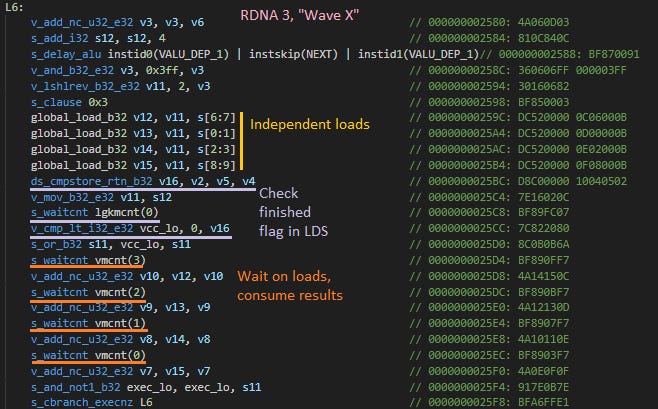
Accesses tracked by vmcnt always return in-order, letting the compiler wait on specific accesses by waiting until vmcnt decrements to a certain value or lower. In wave Y, I make all accesses dependent so the compiler only waits for vmcnt to reach 0.

On RDNA 3, s_waitcnt vmcnt(...) seems to wait for requests to complete not only from its wave, but from other waves too. That explains why wave X makes exactly four accesses for each access that wave Y makes. If I unroll the loop more, letting the compiler schedule more independent accesses before waiting, the ratio goes up to match the unroll factor.

On RDNA 4, the two waves don’t care what the other is doing. That’s the way it should be. RDNA 4 also displays more run-to-run variation, which is also expected because cache behavior is highly unpredictable in this test. I’m surprised by the results, but it’s convincing evidence that AMD indeed had false cross-wave memory delays on RDNA 3 and older GPU architectures. I also tested on Renoir’s Vega iGPU, and saw the same behavior as RDNA 3.
At a simplistic level, you can imagine that requests from the shaders go into a queue to be serviced, and many of those requests can be in flight
Navi 4 Architecture Deep Dive, Andrew Pomianowski, CVP, Silicon Design Engineering (AMD)
AMD's presentation hints that RDNA 3 and older GPUs had multiple waves sharing a memory access queue. As mentioned above, AMD GPUs since GCN handle memory dependencies with hardware counters that software waits on. By keeping vmcnt returns in-order, the compiler can wait on the specific load that produces data needed by the next instruction, without also waiting on every other load the wave has pending. RDNA 3 and prior AMD GPUs possibly had a shared memory access queue, with each entry tagged with its wave's ID. As each memory access leaves the queue in-order, hardware decrements the counter for its wave.
Perhaps RDNA 4 divides the shared queue into per-thread queues. That would align with the point on AMD's slide saying RDNA 4 introduces "additional out-of-order queues" for memory requests. Or perhaps RDNA 4 retains a shared queue, but can drain entries out-of-order. That would require tracking extra info, like whether a memory access is the oldest one for its wave.
Does it Happen to Others?
Sharing a memory access queue and returning data in-order seems like a natural hardware simplification. That raises the question of whether GPU architectures from Intel and Nvidia had similar limitations.
Intel's Xe-LPG does not have false cross-wave memory dependencies. Running the same test on Meteor Lake's iGPU shows variation depending on where the two waves end up. If wave X and wave Y run on XVEs with shared instruction control logic, wave X's performance is lower than in other cases. Regardless, it's clear Xe-LPG doesn't force a wave to wait on another's accesses. Intel's subsequent Battlemage (Xe2) architecture shows similar behavior, and the same applies to Intel's Gen 9 (Skylake) graphics from a while ago.

I also checked generated assembly to ensure Intel's compiler wasn't unrolling the loop further.

Nvidia's Pascal has varying behavior depending on where waves are located within a SM. Each Pascal SM has four partitions, which are arranged in pairs that share a texture unit and a 24 KB texture cache. Waves are assigned to partitions within a pair first. It's as if the partitions are numbered [0,1]-> tex, [2,3]-> tex. Waves in the same sub-partition pair have the false dependency issue. Evidently they share some general load/store logic besides the texture unit, because I don't touch textures in this test.

If a wave is not offset from another one by a multiple of four or multiple of 4 plus one, it doesn't have the false dependency problem. Turing, as tested on the GTX 1660 Ti, doesn't have a problem either.
Better Nonblocking Loads
Besides removing false cross-wave delays, AMD also improved memory request handling within a wave. Much like in-order CPU cores, like Arm's Cortex A510, GPUs can execute independent instructions while waiting on memory access. A thread only stalls when it tries to use the memory access's result. GPUs have done this for decades, though the implementation details differ. Intel and Nvidia's GPUs use a software managed scoreboard. AMD used pending request counters from GCN onward.

RDNA 4 uses the same scheme but splits out the vmcnt category into several counters. A thread can interleave global memory, texture sampling, and raytracing intersection test requests, and wait on them separately. That gives the compiler more flexibility to move work ahead of a wait for memory access completion. Another interpretation of AMD's slide is that the each counter corresponds to a separate queue, each of which has out-of-order behavior across waves (but may have in-order behavior within a wave).

Similarly, lgkmcnt gets separated into kmcnt for scalar memory loads and dscnt for LDS accesses. Scalar memory loads are out-of-order, which means the compiler must wait for all scalar memory loads to complete (kmcnt=0 or lgmkcnt=0) before using results from any pending scalar memory load. On RDNA 4, the compiler can interleave scalar memory and LDS accesses without having to wait for lgkmcnt=0.
Intel and Nvidia's GPUs use software managed scoreboards. A scoreboard entry can be set or and waited on by any instruction, regardless of memory access type. Therefore RDNA 4's optimization isn't applicable to those other GPU architectures. A cost to Intel/Nvidia's approach is that utilizing a big memory request queue would require a correspondingly large scoreboard. AMD can extend a counter by one bit and double the number of queue entries a wave can use.
Final Words
RDNA 4's memory subsystem enhancements are exciting and improve performance across a variety of workloads compared to RDNA 3. AMD specifically calls out benefits in raytracing workloads, where traversal and result handling may occur simultaneously on the same WGP. Traversal involves pointer chasing, while result handling might involve more cache friendly data lookups and texture sampling. Breaking cross-wave memory dependencies would prevent different memory access patterns in those tasks from delaying each other.
Likely this wasn't an issue with rasterization because waves assigned to a WGP probably work on pixels in close proximity. Those waves may sample the same textures, and even take samples in close proximity to each other within the same texture. If one wave misses in cache, the others likely do too.
Breaking up vmcnt and lgmkcnt probably helps raytracing too. Raytracing shaders make BVH intersection and LDS stack management requests during traversal. Then they might sample textures or access global memory buffers during result handling. Giving the compiler flexibility to interleave those request types and still wait on a specific request is a good thing.

But RDNA 4's scheme for handling memory dependencies isn't fundamentally different from that of GCN many years ago. While the implementation details differ, RDNA 4, GCN, and Intel and Nvidia's GPUs can all absorb cache misses without immediately stalling a thread. Each GPU maker has improved their ability to do so, whether it's with more scoreboard tokens or more counters. RDNA 4 indeed can do Cortex A510 style nonblocking loads, but it's far from a new feature in the world of GPUs.
Resolving false cross-wave dependencies isn't new either. Nvidia had "out-of-order" cross-wave memory access handling in Turing, and presumably their newer architectures too. Intel had the same at least as far back as Gen 9 (Skylake) graphics. Therefore RDNA 4's "out-of-order" memory subsystem enhancements are best seen as generational tweaks, rather than new game changing techniques.
Still, AMD's engineers deserve credit for making them happen. RDNA 4’s arguably makes the most significant change to AMD’s GPU memory subsystem since RDNA launched in 2019. I'm glad to see the company continue to improve their GPU architecture and make it better suited to emerging workloads like raytracing.
What I see here is that since vega AMD could have a much more competent and efficient architecture using this type of implementation.
I wonder if the RDNA3.5+ architecture, which will be used in the next batch of APUs, will focus solely on this kind of optimization and support for FP8 (FSR4). This is because RDNA4's RT cores take up significant space, making the design overly bulky without providing enough ray tracing performance to justify it(?) Just guessing.