
Previewing China’s Loongson 3A5000 with Performance Counters

Loongson’s 3A5000 represents another domestic CPU effort from China. It implements four LA464 cores, and targets everything from desktops to servers to embedded applications. Like the Zhaoxin KX-6640MA and Phytium D2000 that we covered previously, Loongson’s chip runs at low clock speeds. But unlike those other Chinese chips, Loongson uses a MIPS based ISA. Prior Loongson chips were MIPS64 compatible, but the company switched over to an ISA it calls Loongarch. Loongarch shares most of MIPS’s semantics, but uses different instruction encodings. Loongson has also extended the ISA to support 256-bit vector execution.
We’re going to do some brief benchmarking here. The purpose of this isn’t to test a ton of applications to provide a well-rounded performance picture. Phoronix already has some results in case you want to know where the CPU generally sits. Rather, we’re running a couple of tests and profiling them with what little performance counters we have available. We’ll be using this data to help our analysis of Loongson’s architecture.
For comparison, we’ll use AMD’s Zen 1 architecture, because some sites suggest the 3A5000 might be comparable to Zen 1. Titanic has kindly set up a Ryzen 7 1800X system with dual channel DDR4-2400. Ampere Altra, in the form of a free quad core instance from Oracle Cloud, will also be featured here. The Neoverse N1 cores are perhaps more comparable to the ones in the 3A5000, because they similarly don’t hit high clock speeds.
High Level Performance
7-Zip is an efficient compression program, and we’re seeing how long it takes to compress a huge file generated from profiling Firefox compilation. The executed instruction stream consists almost entirely of scalar integer operations. Results here aren’t directly comparable to previous ones on this site, because we’re specifying 16 threads this time. Even though we’re limiting it to four cores, running more threads results in better utilization and higher performance.

The 3A5000 does not match Zen 1 in absolute performance. However, it is competitive in performance per clock if we don’t let Zen 1 use both SMT threads in a core. Loongson’s actual performance is closer to that of a quad core Ampere Altra setup. But even there, it gets outperformed by a significant margin. Again, performance per clock is close, but 2.5 GHz is a very low clock speed, even for a server chip that doesn’t prioritize single threaded performance.
Video Encoding
libx264 is a free software library for dealing with the H264 codec. Despite being quite old, H264 has remained popular because of widespread hardware decode support and licensing issues with newer codecs like H265. Here, we’re transcoding a short clip of Overwatch gameplay, using the “veryslow” preset to prioritize quality. After all, if you didn’t care about quality and wanted the fastest possible encode, you’d just use a GPU’s hardware encoder.

The executed instruction stream in this test contains a high percentage of vector instructions. Loongson has added LSX and LASX support to its distributed version of libx264 using intrinsics. That’s excellent, because trying to do video encoding or other computationally heavy tasks with just compiler generated code will result in extremely poor performance.

Performance unfortunately is not excellent. Relying on plain C code usually causes performance to be an order of magnitude slower. Thankfully, Loongson avoids that. But the 3A5000 underperforms significantly against Zen 1. It also fails to match quad core Ampere Altra. That’s a poor showing considering both of those chips have 128-bit execution units. At least on AVX2 capable x86, chips, more than 10% of instructions executed in this test are 256-bit. Zen 1 does support AVX2, but decodes 256-bit instructions into two micro-ops. Ampere Altra of course is limited to 128-bit NEON instructions. Neither Zen 1 nor Neoverse N1 are known for strong vector performance, but both beat the 3A5000.
Instruction Count and IPC
Performance counters let us track a lot of events, and one of the most important ones is the number of retired instructions. In a CPU with out of order execution, instruction retirement refers to when the core commits an instruction’s results and makes them visible (in other words, has finished execution and passed all the required checks). We’re not testing CPUs with a familiar ISA here. If the ISA has an impact, one sign of that is a large difference in instruction counts.

With 7-Zip, instruction count differences are under 5%. That’s good. No one’s executing significantly more instructions to get the job done.

IPC-wise, Loongson does quite well. IPC is not the same as performance per clock, particularly when different ISAs or ISA extensions are in play. But instruction counts are comparable in this compression benchmark, so IPC correlates well with performance per clock. The 3A5000’s main weakness in this case comes down to its very low clock speed.

libx264 is a different story. Despite having LAVX support, the 3A5000 had to crunch through 12% to 23% more instructions to do the same work. There’s more to ISA than extensions than just vector width. Perhaps LAVX lacks some specialized instructions that NEON and AVX2 have. We don’t have complete LVX and LAVX instruction listings, so that’s just a guess.

Again, Loongson’s IPC is quite decent. But unlike the 7-Zip case, the 3A5000 executes a lot more instructions to get the job done. That means performance per clock is significantly lower than Zen.
Frontend: Branch Prediction
Branch prediction accuracy is important.

Prediction accuracy is extremely similar across all three tested CPUs. Even Zen 1 doesn’t take much of a hit when both SMT threads are loaded. However, the 3A5000 suffers more mispredicts per instruction, meaning that it’s incurring misprediction penalties more often than the other CPUs here. While its branch predictor appears to be doing a decent job, 17.7% of the Loongarch instruction stream consists of branches, compared to 15.1% on x86-64 and 16.1% on 64-bit ARM.

In the video encode test, Loongson falls behind a bit. Zen 1 and Neoverse N1’s branch predictors both perform better in this test, though the gap isn’t large. Accuracy-wise, the 3A5000 is close to Zen 1’s when AMD’s core has to deal with two threads. Loongson does have a comparable mispredict rate per instruction, but that’s a bit of a red herring. The 3A5000 executes significantly more instructions than Zen 1 to finish the job. So, all that means is that Loongson is dealing with more instructions between branches. Executed branch counts differed by less than 10% across all three CPUs (though funny enough, Loongson had the highest executed branch count at 1.2 trillion, versus 1.1 and 1.16 trillion for Zen 1 and Ampere Altra respectively).
Frontend: Instruction Fetch
The 3A5000 has a 64 KB, 4-way set associative L1 instruction cache to help speed up instruction delivery. Neoverse N1 and Zen 1 also have nice 64 KB L1 instruction caches. On 7-Zip, that’s more than large enough to hold the “hot” instruction footprint. In fact, Zen 1’s micro-op cache provides over 85% of the pipeline’s micro-ops in this test, indicating that 7-Zip’s instruction footprint is quite small.

Misses per instruction are extremely low across all three tested CPUs. It’s especially low for Loongson, which is good because the 3A5000 isn’t as good when it has to fetch code from L2. But with everyone below 1 MPKI, it’s not a huge factor in any case.

libx264 also has high L1i hitrates, though we’re seeing more L1i misses on all three CPUs. Loongson now suffers more, though 2 MPKI is still not particularly concerning.
Backend: L1D Hitrate
The three tested CPUs here have more differences from the data side. AMD’s Zen architecture has a relatively small 32 KB, 8-way set associative L1D. Loongson’s 3A5000 and Neoverse N1 both have a larger 64 KB, 4-way L1D. In 7-Zip, Loongson’s L1D turns in a surprisingly poor performance. According to performance counters, L1D hitrate is substantially lower. Neoverse N1 has the best L1D hitrate even with a similar cache geometry. N1 also beats Zen 1’s L1D hitrate, so a larger L1D with less associativity should be better. Perhaps Loongson doesn’t have a good replacement policy, or is aggressively prefetching and kicking out useful data too often.

Misses per instruction largely tell the same story for 7-Zip, because executed instruction counts are similar.
Loongson’s L1D suffers a lot of misses. In libx264, Loongson turns in a slightly better performance. L1D hitrate still isn’t where it should be considering its capacity advantage, and it still fails to catch Zen. However, it’s not too far off either.

Per-instruction, Loongson doesn’t suffer a lot of misses. But that’s mostly a sign of the CPU doing a lot more computation related instructions in this workload, meaning memory accesses represent less of the executed instruction stream. That also means L1D misses have less of an impact because the core is held back by having to crunch through more math instructions. The opposite is true for Zen.
L2 and L3 Caches
Typically CPUs service the vast majority of accesses from their L1 caches. But DRAM access is so terribly slow that they need lower level caches. Last level caches (L3) have capacities in the megabyte range, making them slow enough that a mid-level cache (L2) can bring performance benefits. Loongson has a 256 KB L2 cache and a nice, 16 MB L3. Zen has a larger 512 KB L2, but smaller 8 MB L3 in a quad core cluster. Ampere Altra uses a very nice 1 MB L2 cache per core, but shares a 32 MB L3 across 80 cores.
Performance counters for the L3 cache don’t appear to work correctly on Ampere Altra. They show more L3 refills than requests to L3, implying the L3 has a negative hitrate. That doesn’t make sense, so we’re starting the graph scale at 0% and will simply not talk about Ampere Altra’s L3.

In 7-Zip, Loongson’s 16 MB L3 has a pretty good hitrate and likely plays a role in the 3A5000’s decent performance per clock there. Loongson also sees a very good L2 hitrate especially considering its small size. But that’s not necessarily a good thing. L2 hitrate is high largely because the L1D was suffering more misses than it should.
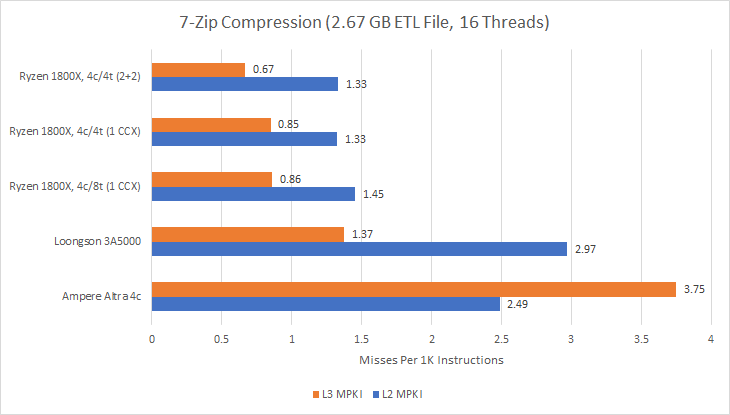
Looking at cache misses per instruction demonstrates that point. As expected, Loongson’s 256 KB L2 sees more misses per instruction than Zen’s 512 KB L2. We can also attribute high L3 hitrate to a large number of L2 misses. Loongson does seem to suffer more L3 misses than Zen, but that could be because I used the events for L1D demand fills on Zen. On Loongson, I’m using the LLC-load-misses event defined in perf. Loongson has not documented performance monitoring events for the 3A5000, so I have no clue if that perf event includes misses from prefetches.

libx264 seems to have a much larger data footprint. We already saw that the L1D caches suffered more misses, and the lower level caches similarly are less effective than with 7-Zip. Neoverse N1’s large L1 definitely helps it out. Zen 1’s L2 is helpful for cushioning the blow of dealing with the data footprint of two threads running in a single core, but hitrate isn’t spectacularly high. Looking at misses per instruction illustrates that well. Zen 1 suffers more L2 misses with both SMT threads active, but the L1D suffers even more and the L2 ends up catching a lot of those accesses.

Loongson’s L2 appears to do well with this metric, but again that’s only because it’s executing so many more instructions that the memory hierarchy has less of an impact. In an absolute count, it actually suffers the most L2 misses of any CPU tested here (over 244 billion, versus 182 and 176 for Zen 1 with 1 SMT thread loaded and Ampere Altra respectively). The same applies to L3 misses, though the gap is lower. Again, take these absolute counts with a grain of salt because we don’t know exactly what Loongson’s perf events are measuring.
First Impressions (Architecture and Performance)
Loongson’s 3A5000 appears to be reasonably competent. Unlike the Phytium D2000 and Zhaoxin KX-6640MA, the 3A5000 has a well balanced core architecture backed by large caches. Performance per clock is decent in fine compression, though it is quite far behind state of the art CPUs from Intel and AMD. But decent performance per clock does not imply acceptable performance. Where Loongson falls behind is in clock speed. 2.5 GHz is extremely low by today’s standards. Even high core count server CPUs have no problem clocking well above 3 GHz. And so far, that looks like Loongson’s biggest weakness.
The terms “architectural efficiency” or “performance at the same clock” are sometimes taken as metrics of goodness in and of themselves. Perhaps this is one way of apologizing for low clock rates or a way to imply higher performance when the microrachitecture “someday” reaches a clock rate that is in fact unobtainable for that design…
David B. Papworth, Tuning the Pentium Pro Microarchitecture, IEEE Micro
We’re currently working on microbenchmarking the 3A5000 to learn more about its architecture. Our initial impressions are that the core has similar ROB capacity to Phytium’s D2000, but other out-of-order buffers are far better sized. Eventually we’ll have a full article out on this, but analyzing this CPU is a bit difficult because most of our benchmarks depend on assembly code. Compilers tend to do unpredictable and complicated things that make it difficult to observe architectural characteristics from high level code.
Unfortunately, that means we had to write a lot of code to look into Loongson’s 3A5000. Writing assembly can be hard, and writing assembly for an unfamiliar ISA (LoongArch64) brings difficulty to another level. Testing microbenchmark code isn’t easy either. Normally, we can validate tests by running them on a CPU with known characteristics and making sure the results are sane. But in this situation, Loongson’s 3A5000 is the only LoongArch64 CPU we have, and most details are not public. We’re pretty much flying blind. Each test takes longer to write, and the chance of error is high.
That brings us to another huge problem: software ecosystem support. As mentioned before, the 3A5000 runs Loongson’s proprietary ISA, Loongarch. Loongarch shares a lot of conventions and semantics with MIPS despite using an incompatible encoding. On one hand, that means Loongson was able to copy and paste a lot of existing MIPS code to get started. On the other, the MIPS software ecosystem is not comparable to that of x86 or ARM. I expect Loongson to have plenty of teething problems bringing their software ecosystem up to scratch.
Zooming back up, China’s domestic chip efforts are in a bit of a funny position. Zhaoxin’s KX-6640MA and Phytium’s D2000 both suffer from poor per-core performance. The 3A5000 is better, and represents the strongest CPU effort we’ve seen from China so far. But it won’t enjoy the strong x86 or ARM software ecosystems, and a CPU’s performance doesn’t mean much if you can’t make it run your software.
If you like our articles and journalism and you want to support us in our endeavors then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way or if you would like to talk with the Chips and Cheese staff and the people behind the scenes then consider joining our Discord.