
Investigating Split Locks on x86-64
How bad are they, really? And how bad is the medicine?

“Split locks” are atomic operations that access memory across cache line boundaries. Atomic operations let programmers perform several basic operations in sequence without interference from another thread. That makes atomic operations useful for multithreaded code. For instance, an atomic test and set can let a thread acquire a higher level lock. Or, an atomic add can let multiple threads increment a shared counter without using a software-orchestrated lock. Modern CPUs handle atomics with cache coherency protocols, letting cores lock individual cache lines while letting unrelated memory accesses proceed. Intel and AMD apparently don’t have a way to lock two cache lines at once, and fall back to a "bus lock" if an atomic operation works on a value that’s split across two cache lines.

Bus locks are problematic because they’re slow, and taking a bus lock “potentially disrupts performance on other cores and brings the whole system to its knees”. AMD and Intel’s newer cores can trap split locks, letting the kernel easily detect processes that use split locks and potentially mitigate that noisy neighbor effect. Linux defaults to using this feature and inserting an artificial delay to mitigate the performance impact.
Testing Split Locks
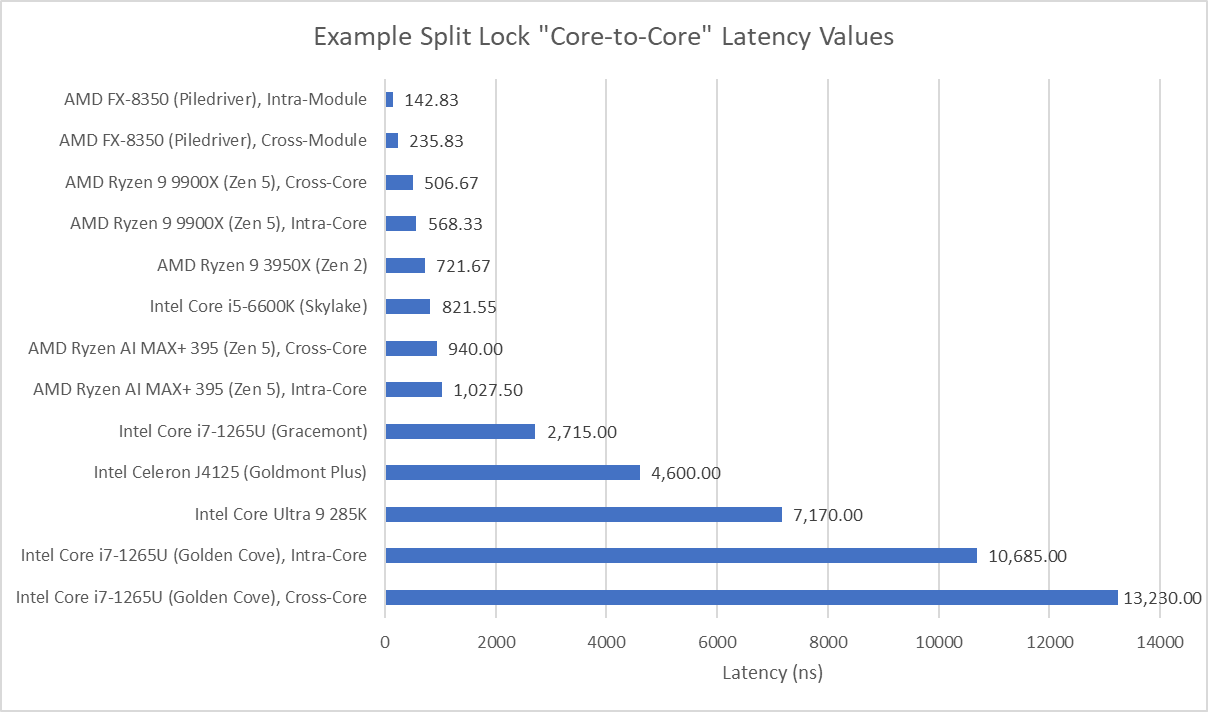
I have a core to core latency test that bounces an incrementing counter between cores using _InterlockedCompareExchange64. That compiles to lock cmpxchg on x86-64, which is an atomic test and set operation. I normally target a value at the start of a 64B aligned block of memory, but here I’m modifying it to push the targeted value’s start address to just before the end of the cache line. Doing so places some bytes of the targeted 8B (64-bit) value on the first cache line, and the rest on the next one. As expected, “core to core latency” with split locks range from bad to horrifying.
To assess the potential disruption from split locks, I ran memory latency and bandwidth microbenchmarks on cores excluded from the core to core latency test. Besides microbenchmarks, I ran Geekbench 6’s photo filter and asset compression workloads. The photo filter workload generates a lot of cache miss traffic, while asset compression tends to be the opposite. Many recent CPUs only achieve their highest clock speeds with two or fewer cores active. One core will be loaded by the workload being tested for contention effects, and another pair will be used for the core to core latency test. I therefore turned off boost or lowered clock speeds on some of the tested hardware to reduce noisy neighbor effects from clock speed variation, helping isolate the effects of split locks.
Intel Core Ultra 9 285K
Intel’s Arrow Lake gets to be the first victim. Normal core to core latency results look like this:
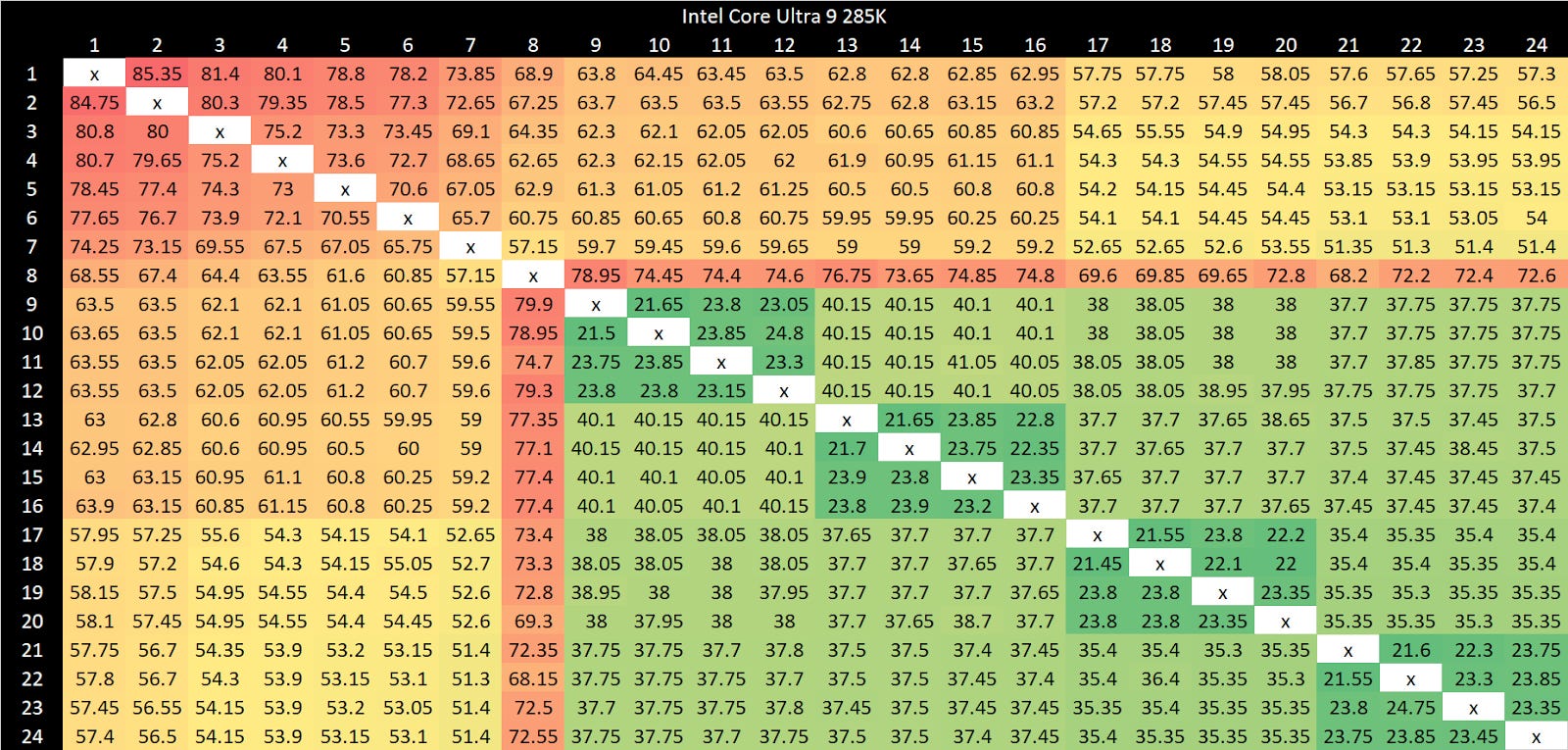
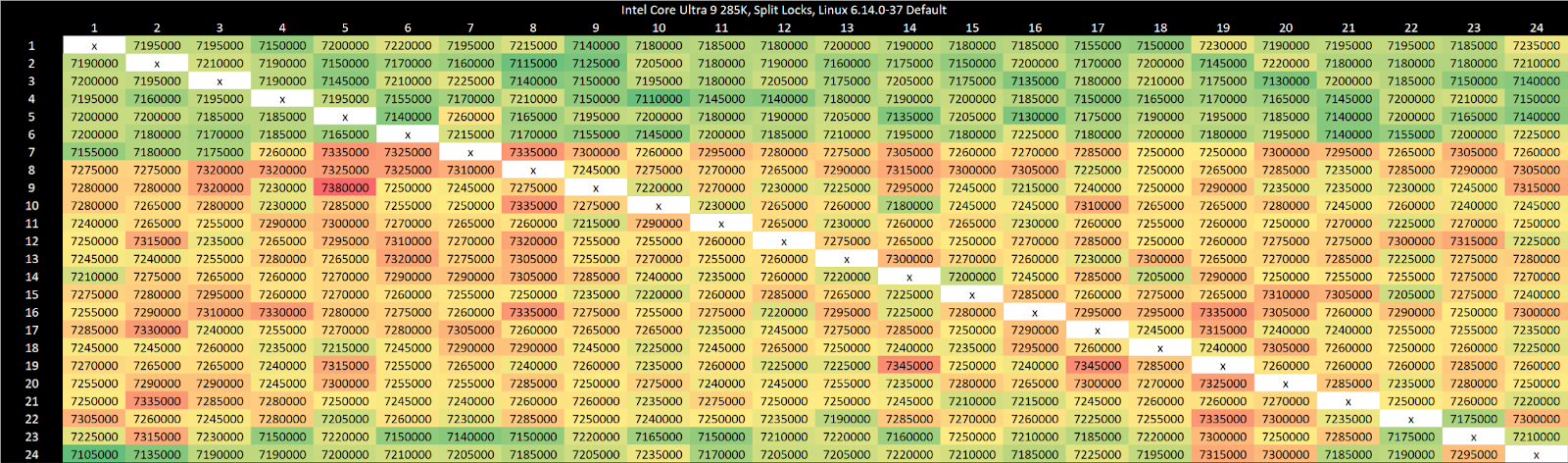
Split locks send latency to 7 microseconds, which remains mostly constant across different core types.
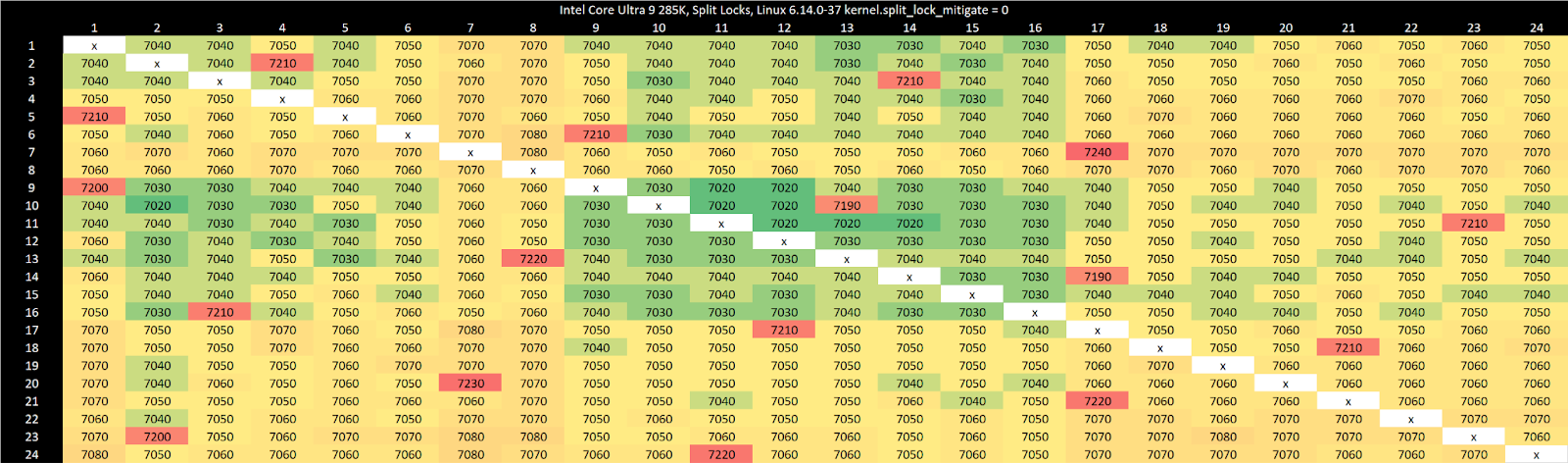
On Arrow Lake, split locks only affect L2 misses. It’s close to a “bus lock” in the traditional sense because it affects the first level in the memory hierarchy shared by all CPU cores. In theory a program can be completely unaffected by split locks as long as it keeps hitting in L2 or faster caches.
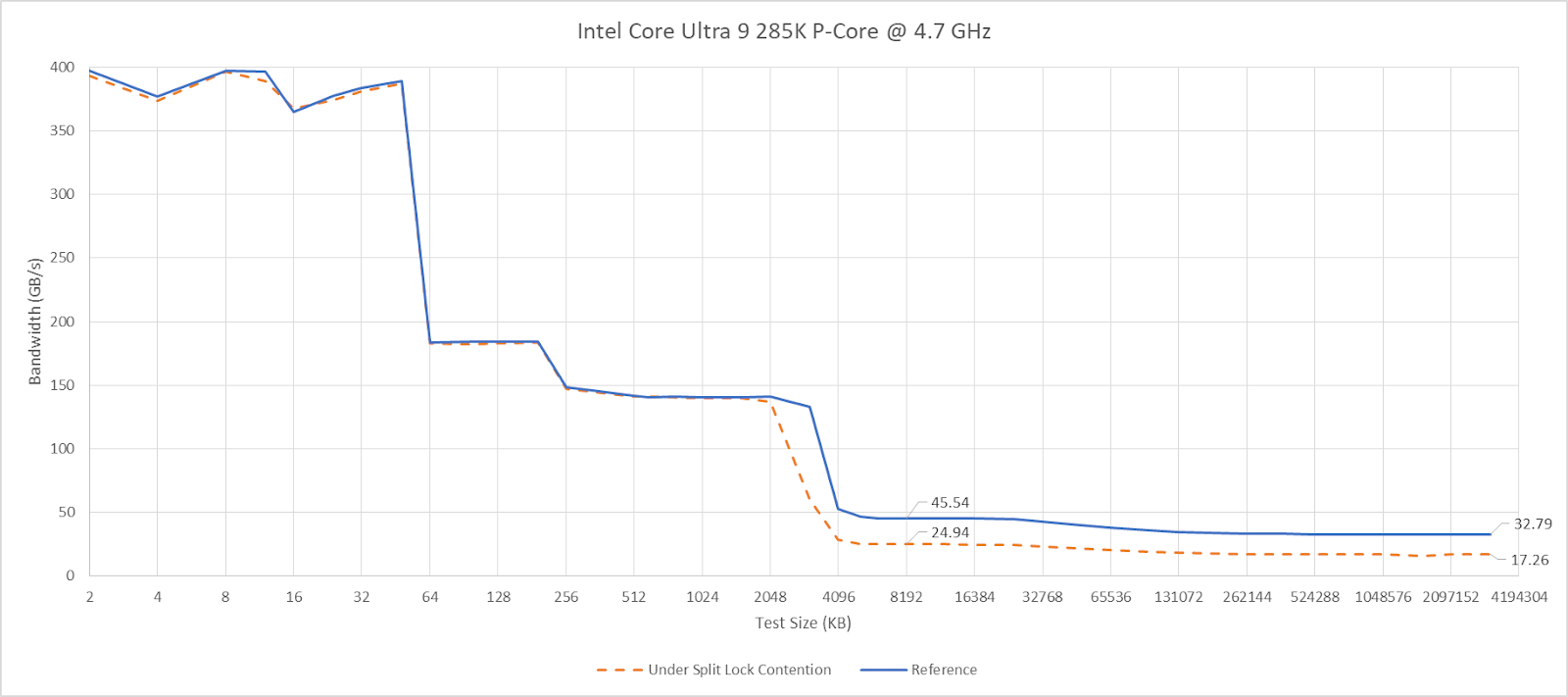
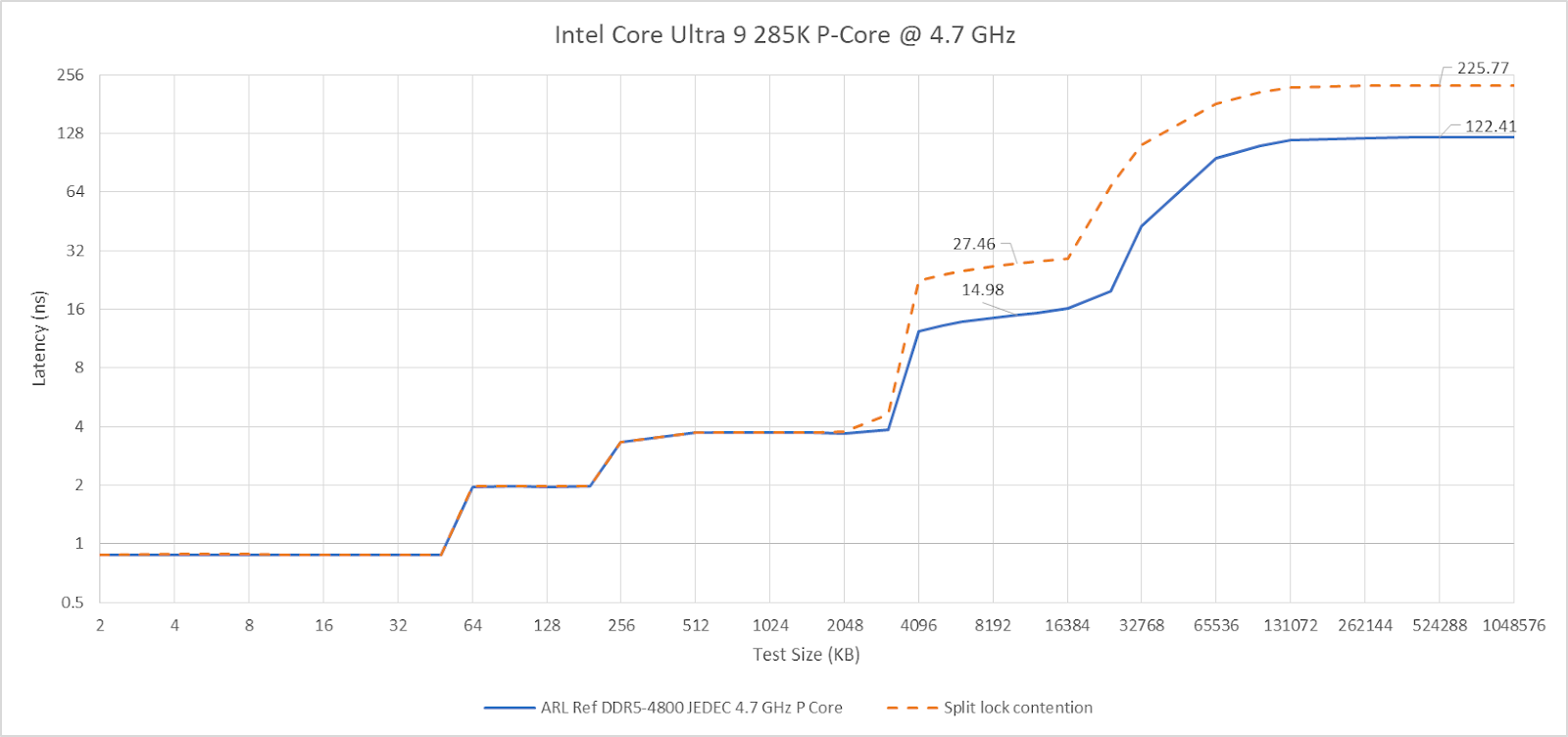
Past L2, split lock contention roughly halves memory access performance. Curiously, the 4 MB L2 caches shared across quad-core E-Core clusters aren’t affected, even if split locks are being looped from a pair of cores within the same cluster.
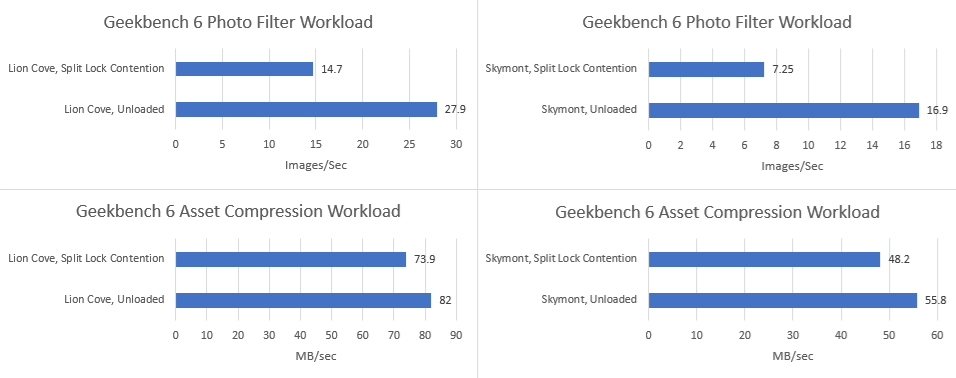
Split locks heavily impact GB6’s photo filter workload. Asset compression also takes a hit, but gets away relatively unscathed.
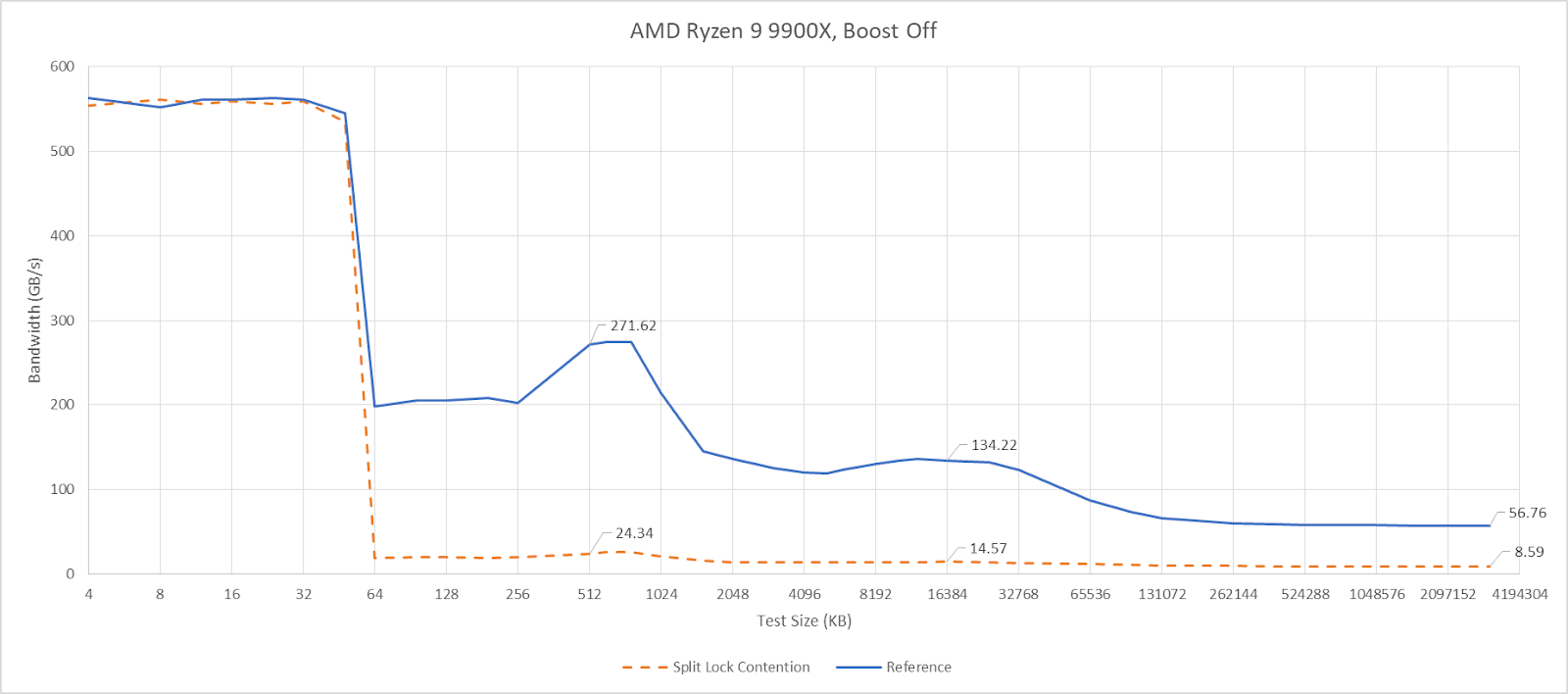
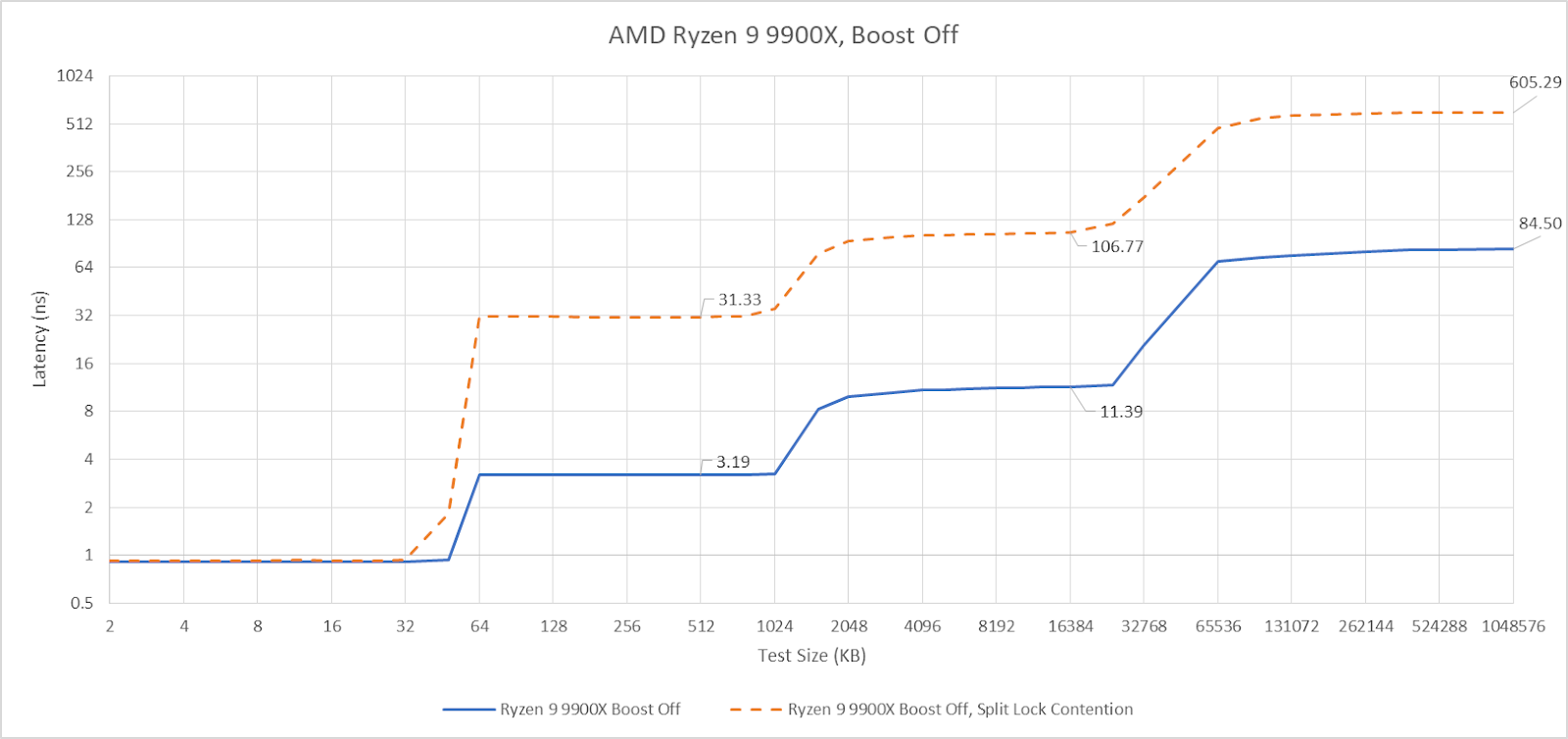
AMD Ryzen 9 9900X
Zen 5 has better split lock latency than Arrow Lake, though 500 ns is still bad in an absolute sense. As on Arrow Lake, core cluster boundaries don’t affect split lock performance.
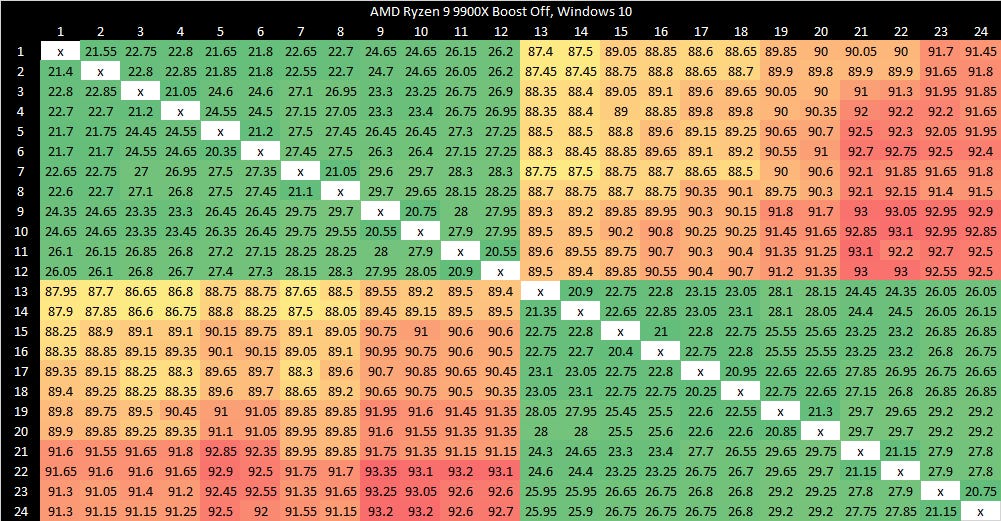
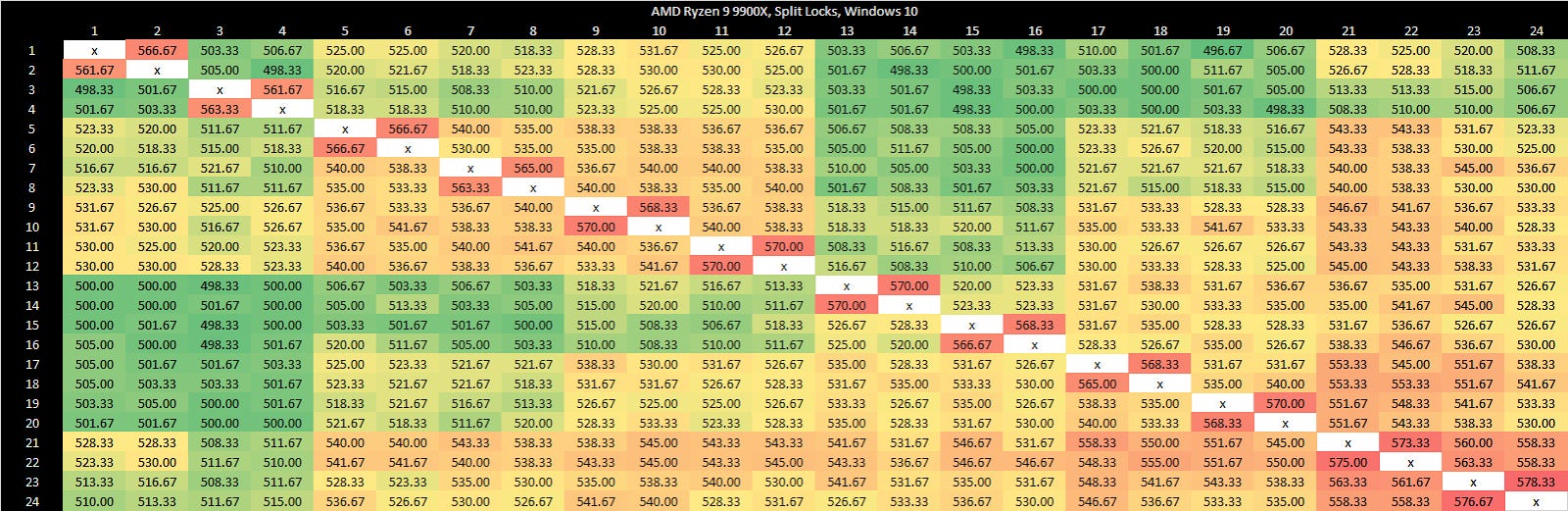
Split locks trash everything beyond L1D. L2 and L3 performance regresses by a factor of ten. Zen 5 suffers severe penalties from split locks compared to Arrow Lake, though this situation is certainly a very contrived and unrealistic one.
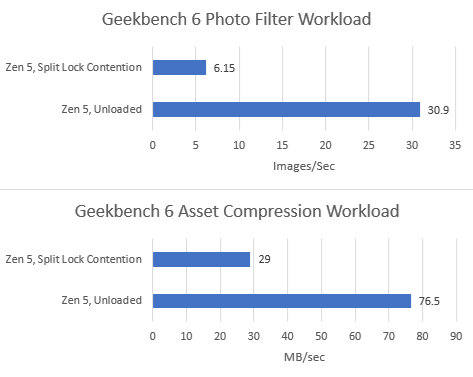
Both Geekbench 6 workloads take heavy performance regressions under split lock contention. Asset Compression doesn’t generate a lot of L3 miss traffic, but even a L1D miss is very costly with split locks being looped on Zen 5.
Intel Core i7-1265U
Alder Lake uses a hybrid core setup with Golden Cove P-Cores and Gracemont E-Cores. Split locks perform horribly, and also invert the latency picture compared to intra-cacheline locks. Bouncing a cache line between P-Cores normally happens with less latency than on the E-Cores. Prior to Arrow Lake, Intel had to take a trip through the ring bus even when bouncing a line between E-Cores in the same cluster.
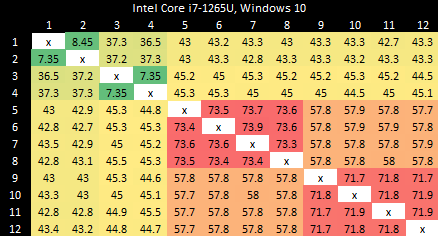
With split locks, P-Cores suffer agonizingly poor latency. Split locks between P and E-Cores have just above 7 microseconds of latency, matching Arrow Lake. E-Cores have the best split lock latency.
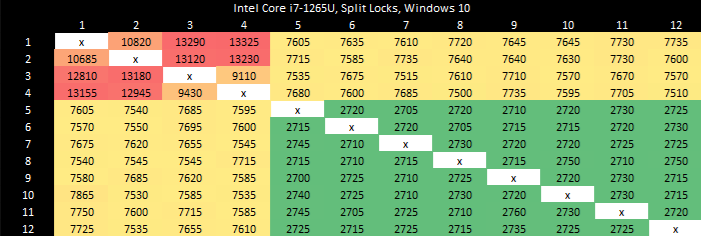
Alder Lake’s memory subsystem tolerates split locks well. L3 performance only takes a modest hit. DRAM latency goes up with split locks come into play, but not by a large amount.
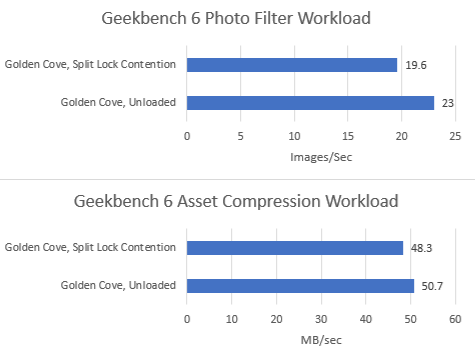
Geekbench 6’s photo filter and asset compression workloads barely show any performance loss, as foreshadowed by microbenchmark results. Alder Lake might have particularly poor split lock performance, but does an excellent job of insulating other applications from their effects.
AMD Ryzen 9 3950X
Zen 2’s split lock latency lands above Zen 5’s, though it’s still better than what Intel’s newer architectures achieve. Latencies remain constant regardless of cluster boundaries, mirroring behavior seen with Zen 5 and Arrow Lake.
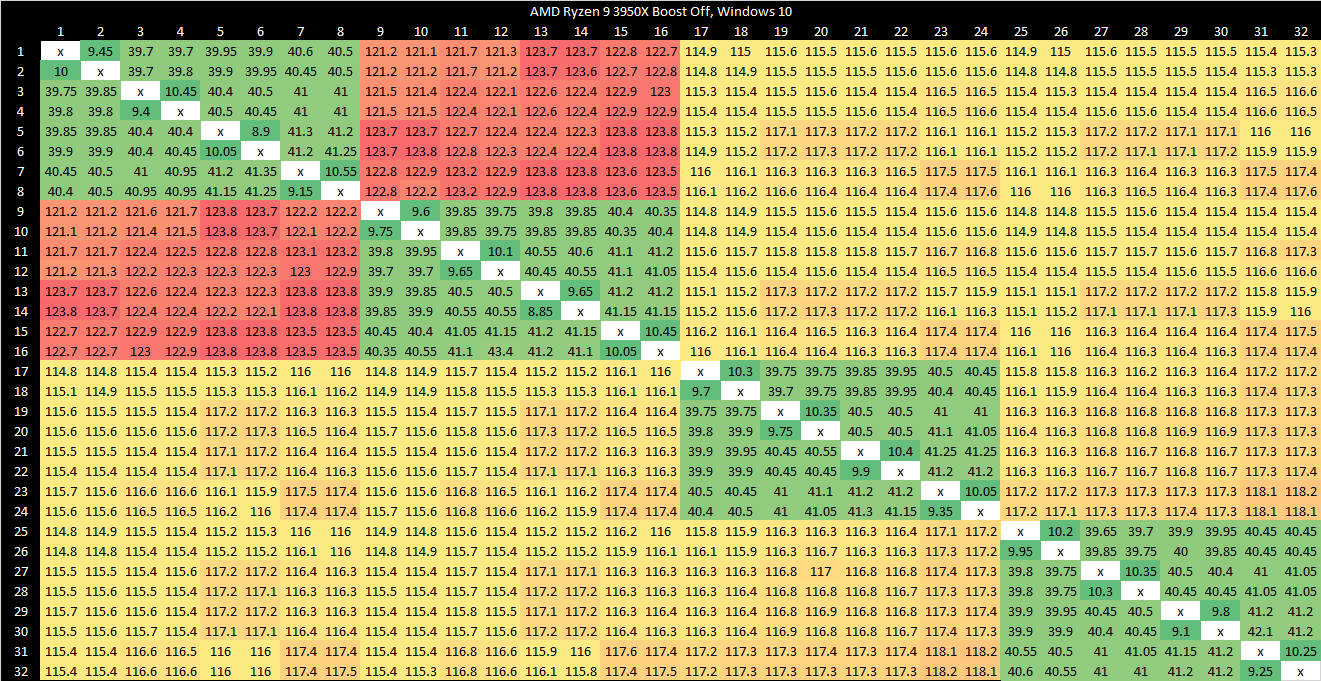
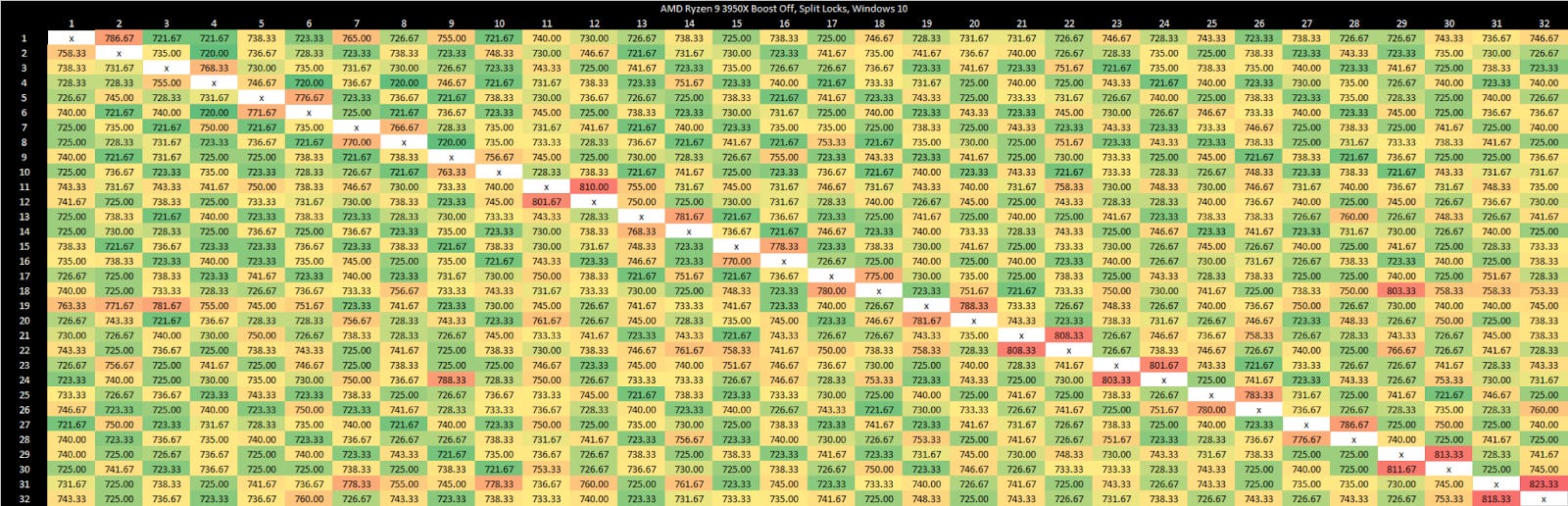
As on Zen 5, split locks have a devastating effect on any L1 miss. Bandwidth and latency regress by around 10x with the core to core latency test spamming split locks.
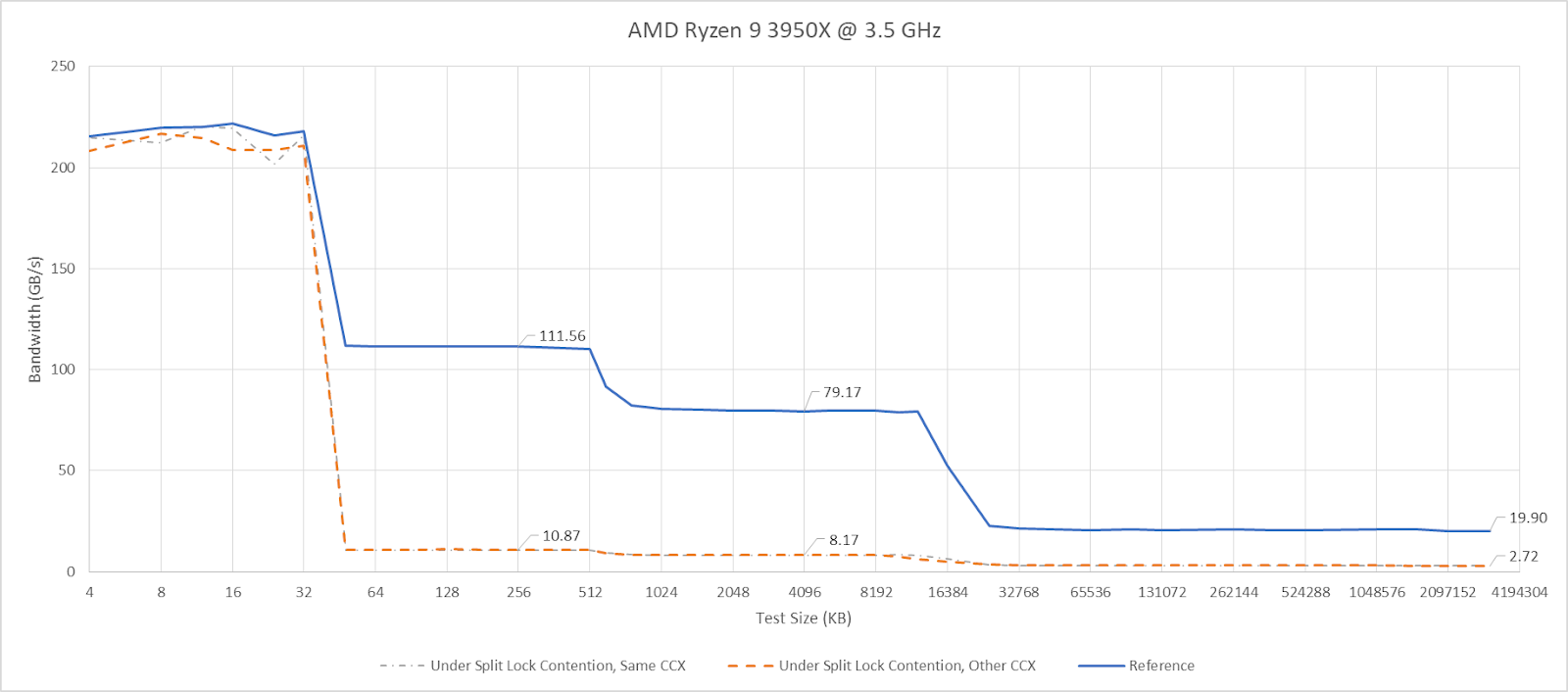
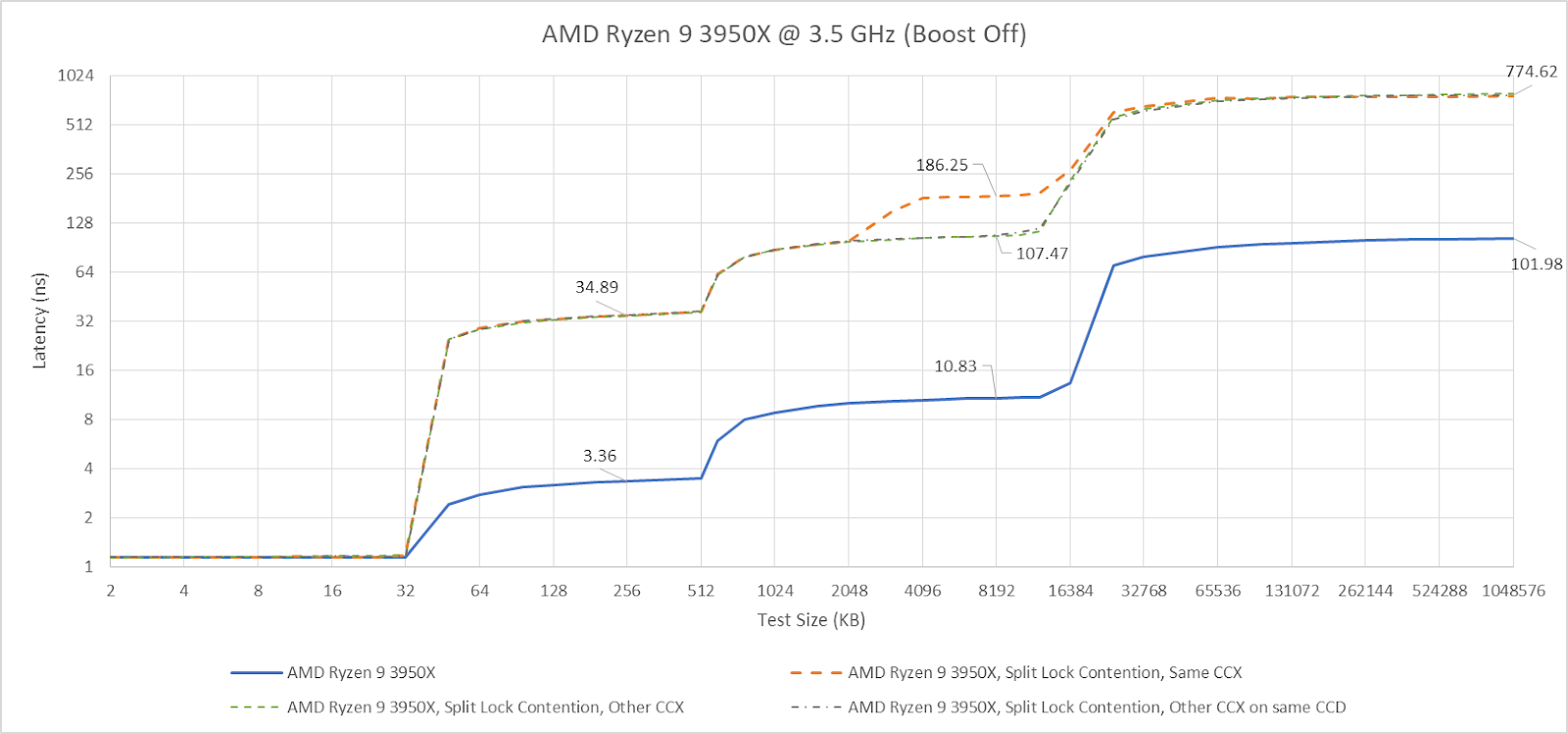
Curiously, L3 latency takes another hit after 2 MB if split locks are being looped on the same CCX. Zen 5 didn’t have an extra inflection point under split lock contention even within the same CCX.
As on Zen 5, both Geekbench 6 workloads suffer heavily under split lock contention.
Intel Core i5-6600K
Intel’s older Skylake architecture actually has better split lock latency than Arrow Lake and Alder Lake. It’s a bit worse than Zen 2, but doesn’t reach into the microsecond range.
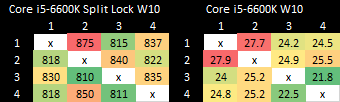
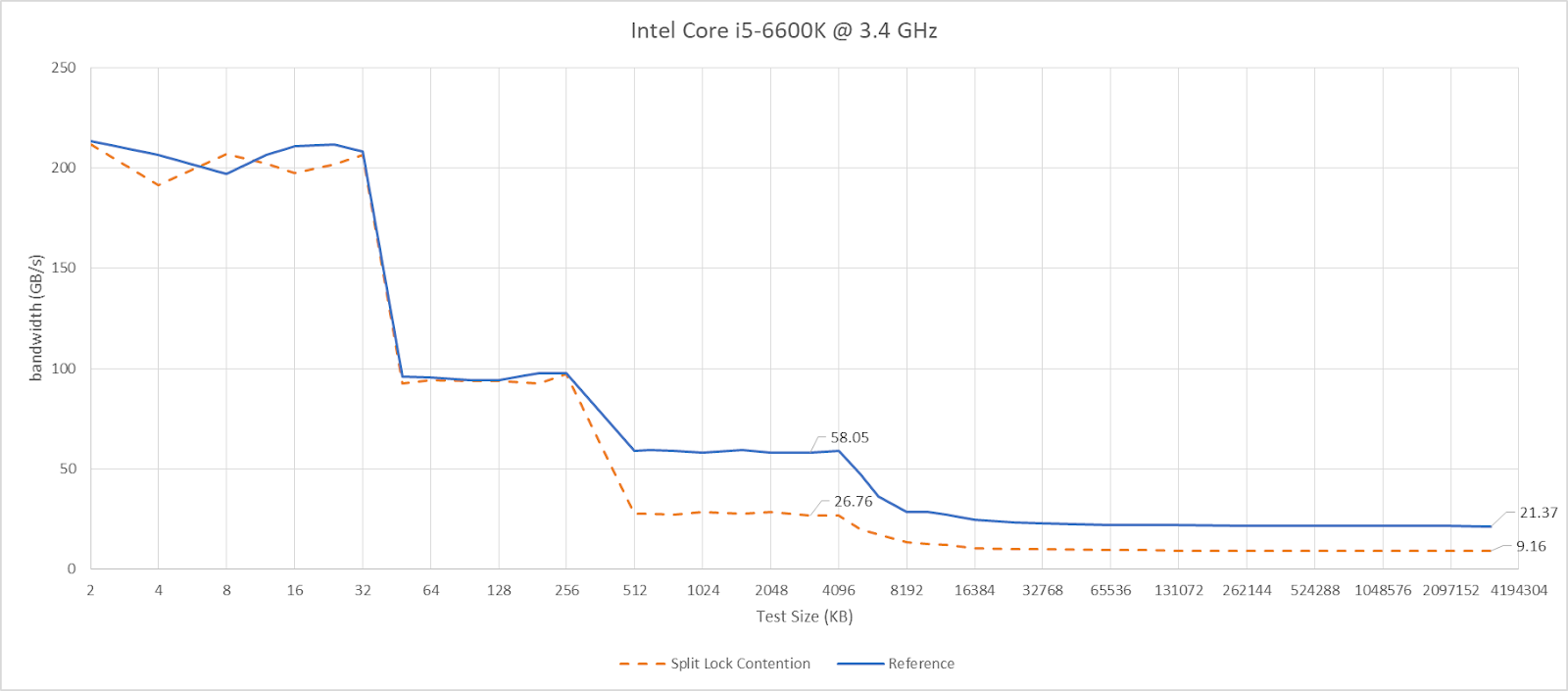
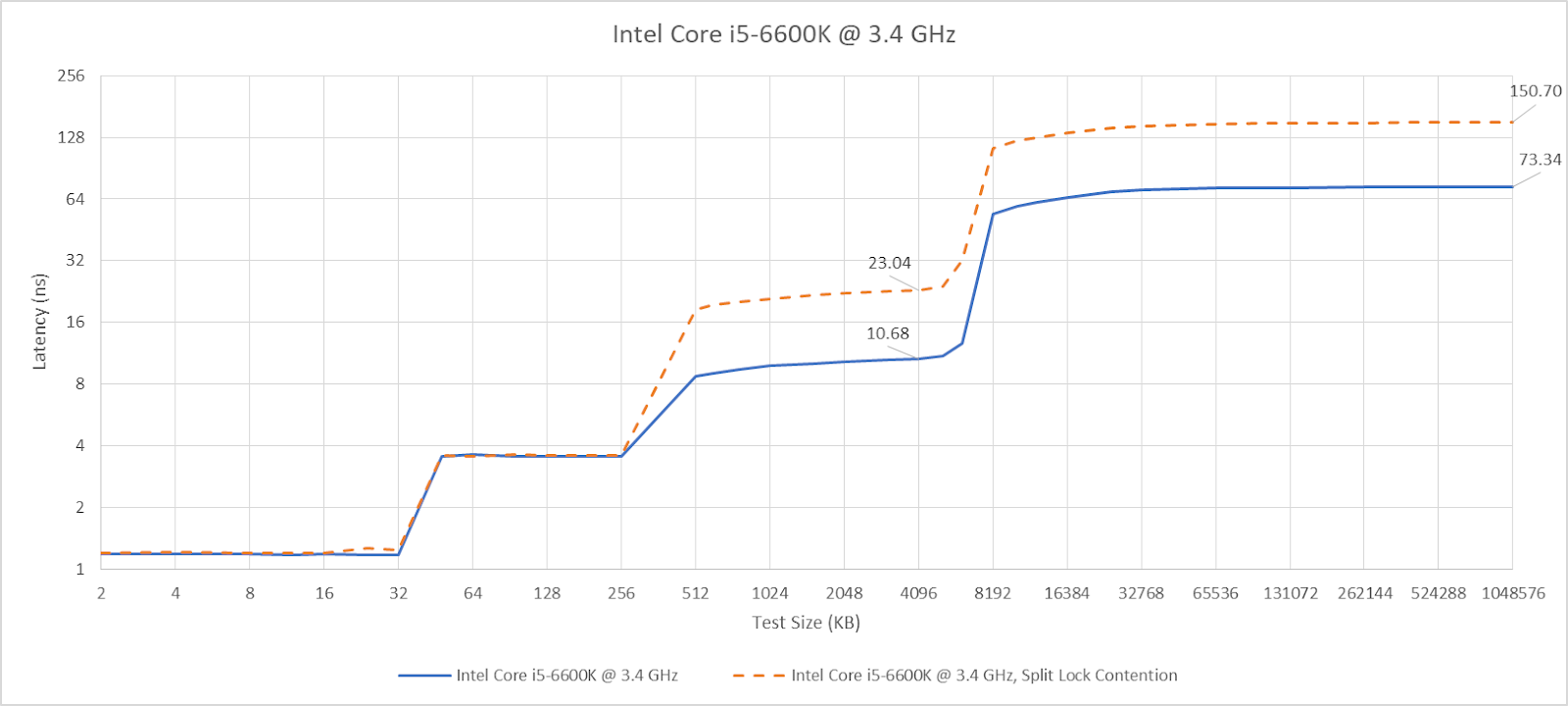
Skylake also takes split lock contention penalties for L2 misses, but not for L2 or L1 hits.
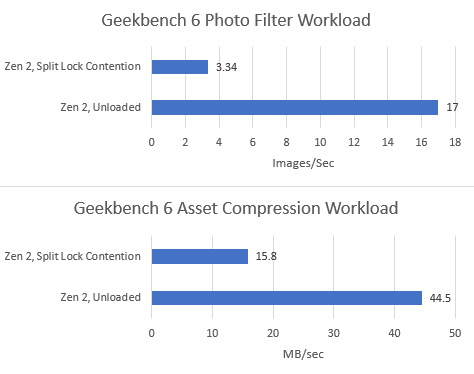
Both tested Geekbench 6 workloads show measurable performance impact from split locks. Photo filter loses 34.24% of its performance, while asset compression takes a lower 16.2% loss.
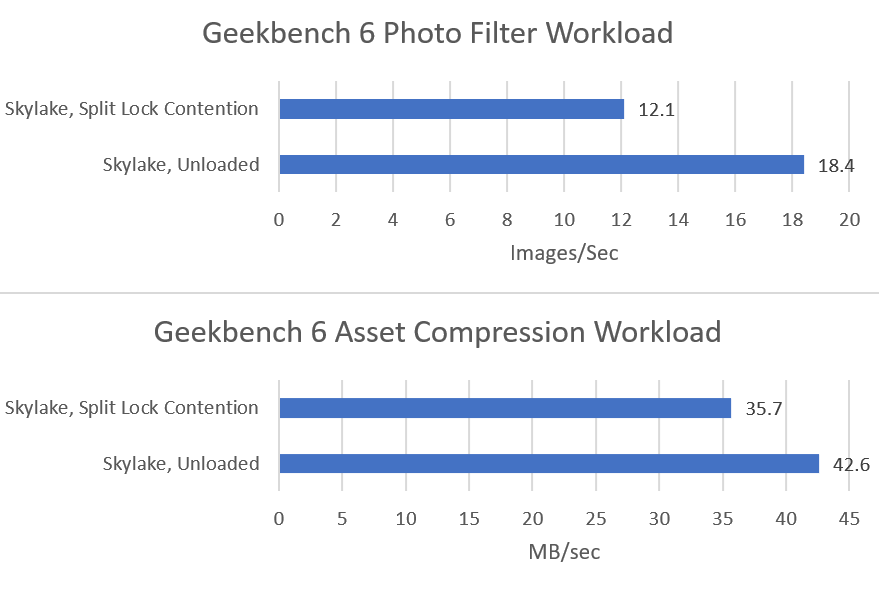
AMD FX-8350
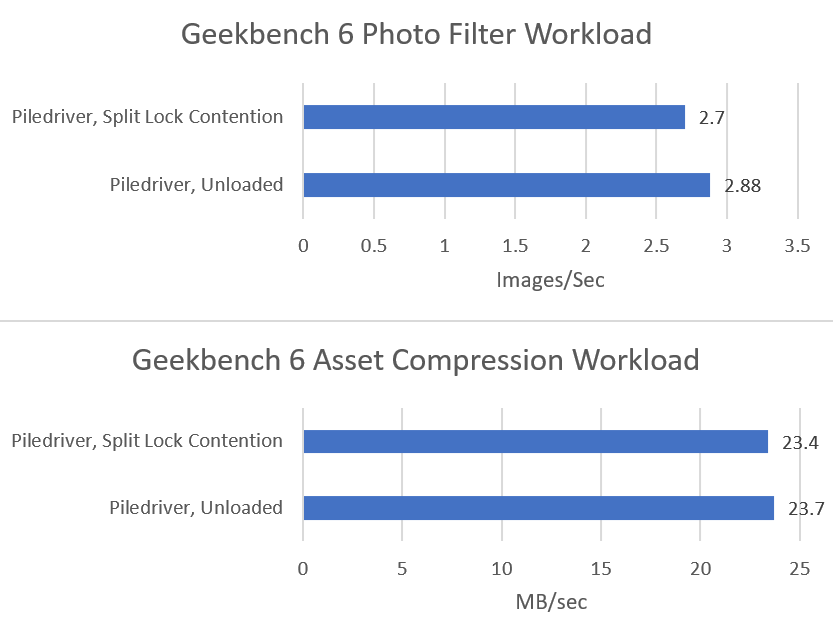
AMD’s Piledriver has high core to core latency results, but remarkably has the best results for split locks. Split lock latency is double to triple the latency of intra-cacheline locks, but that’s worlds better than on newer platforms.
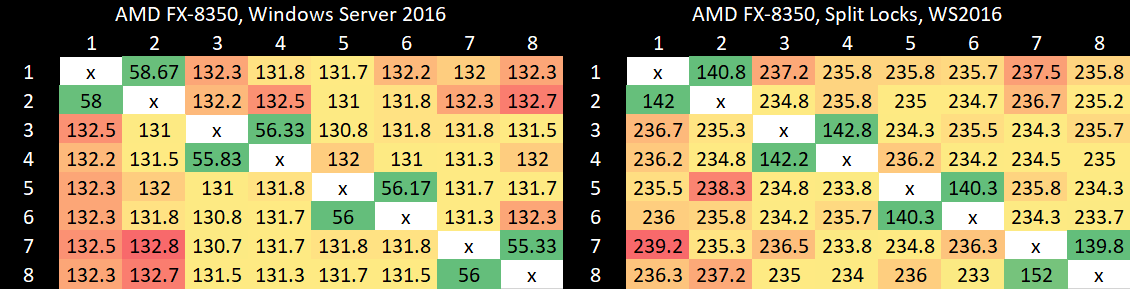
Split locks don’t affect cache hits. Remarkably, that extends to the shared L3 cache. DRAM performance does get hit, with latency doubled and bandwidth cut by more than half.
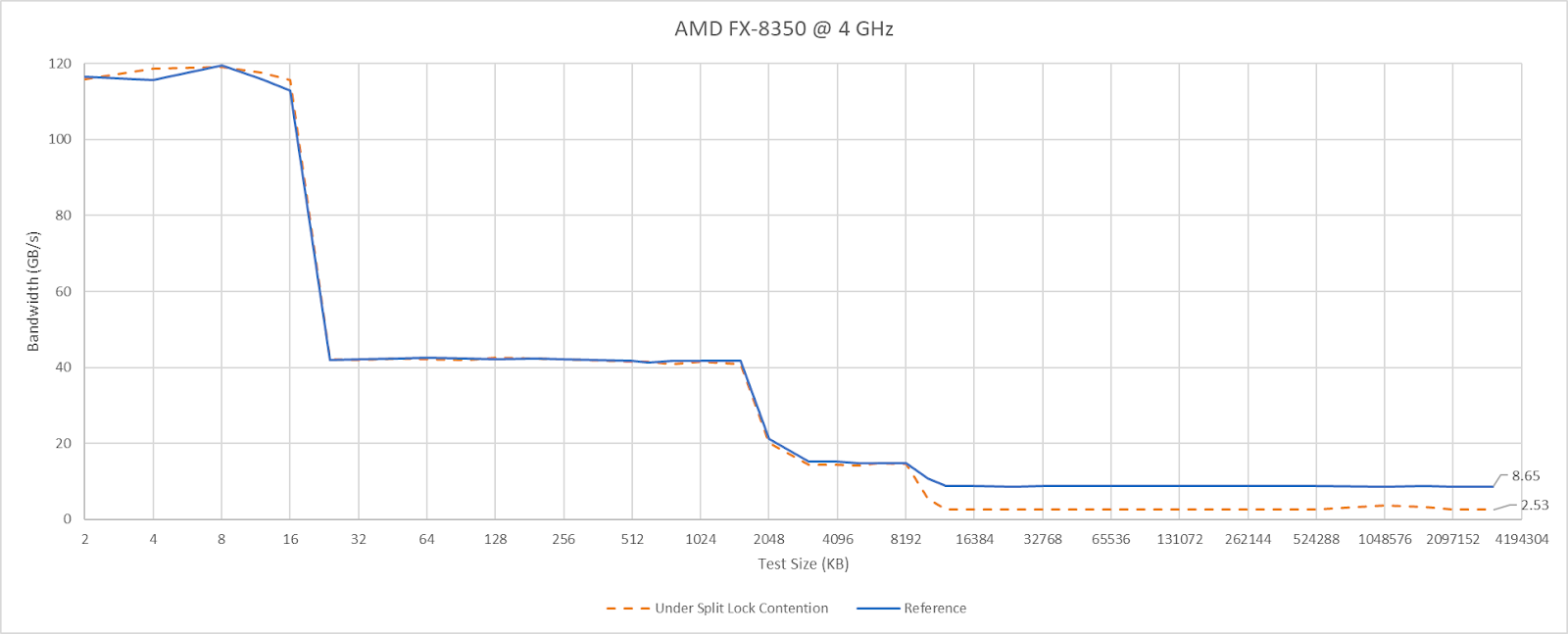
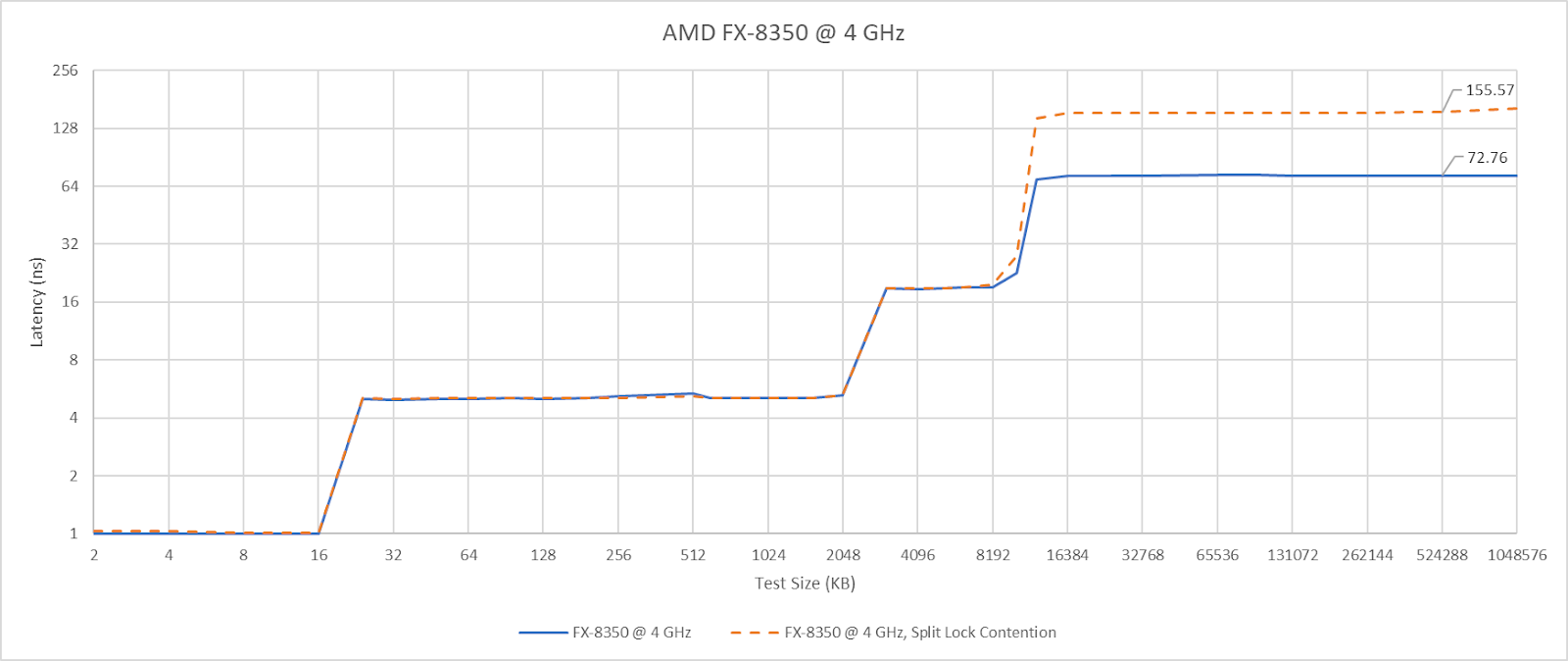
Microbenchmark results translate to higher level workloads. Geekbench 6’s photo filter and asset compression workloads both get away with only minor performance impact. The hit to DRAM performance certainly hurts, but a Piledriver core has 10 MB of cache completely unaffected by split locks. No other hardware tested here can field that much split-lock-unaffected cache capacity.
Intel Celeron J4125
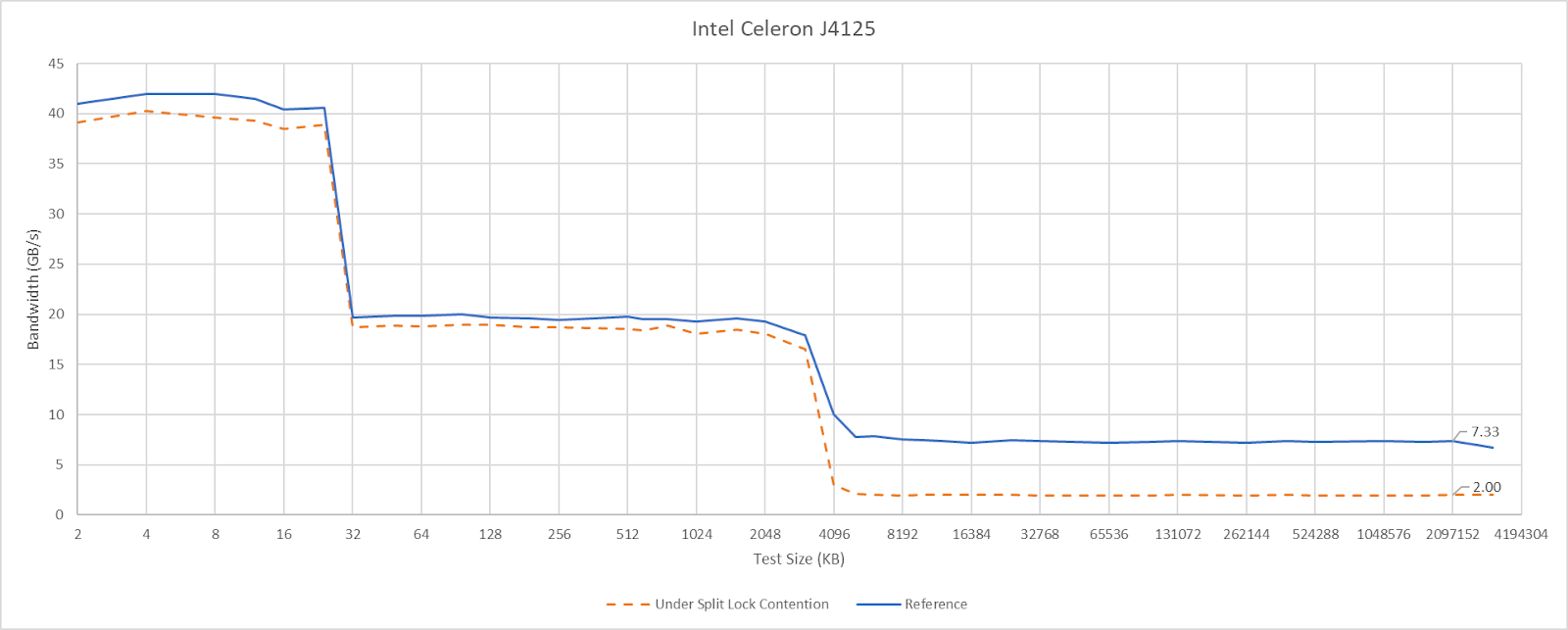
Goldmont Plus has high split lock latency, though it’s still curiously better than Intel’s more modern Arrow Lake and Alder Lake.
Just like Arrow Lake’s E-Cores, Goldmont Plus can hit L2 and be completely unaffected by split locks. DRAM bandwidth does take a substantial drop, but latency only regresses slightly. It’s worth noting that Goldmont Plus starts with very poor baseline DRAM latency though.
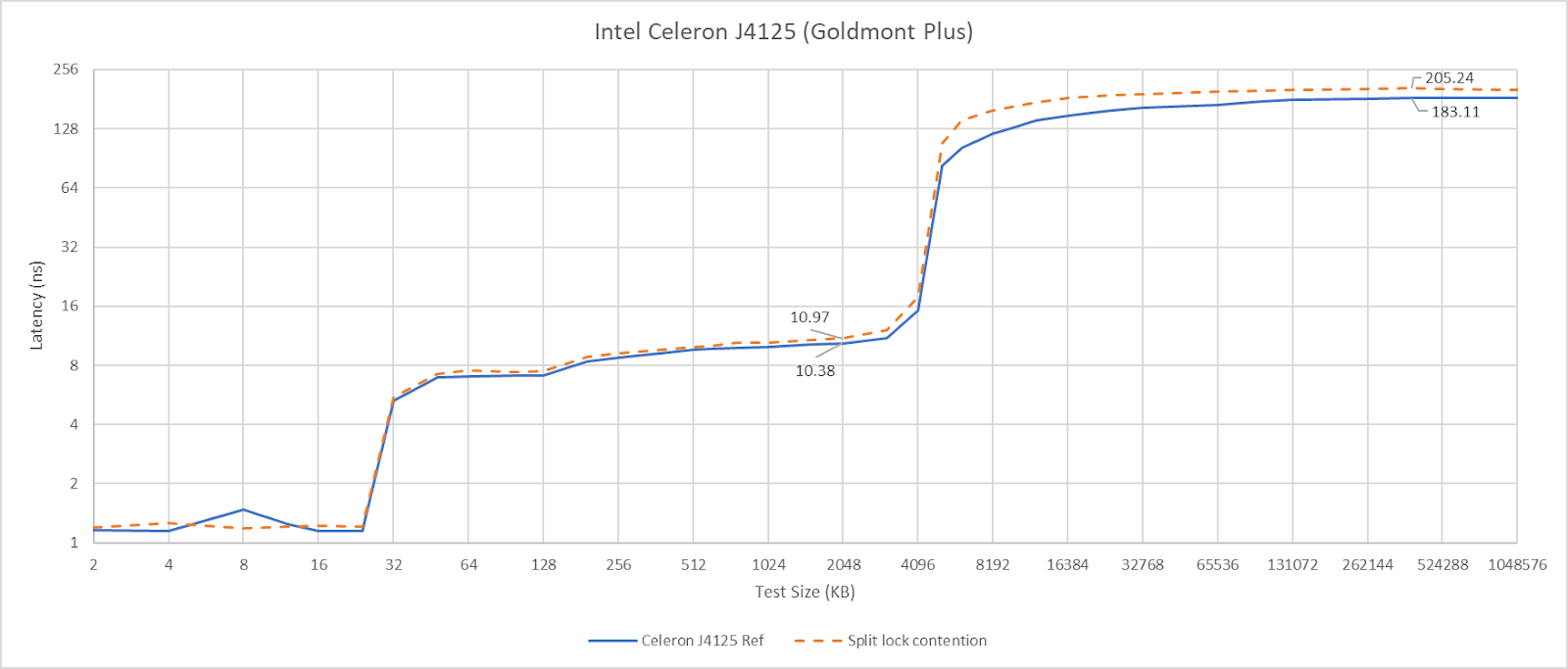
Slight differences in L1D and L2 performance can be attributed to lower clock speeds, since I didn’t underclock the chip.
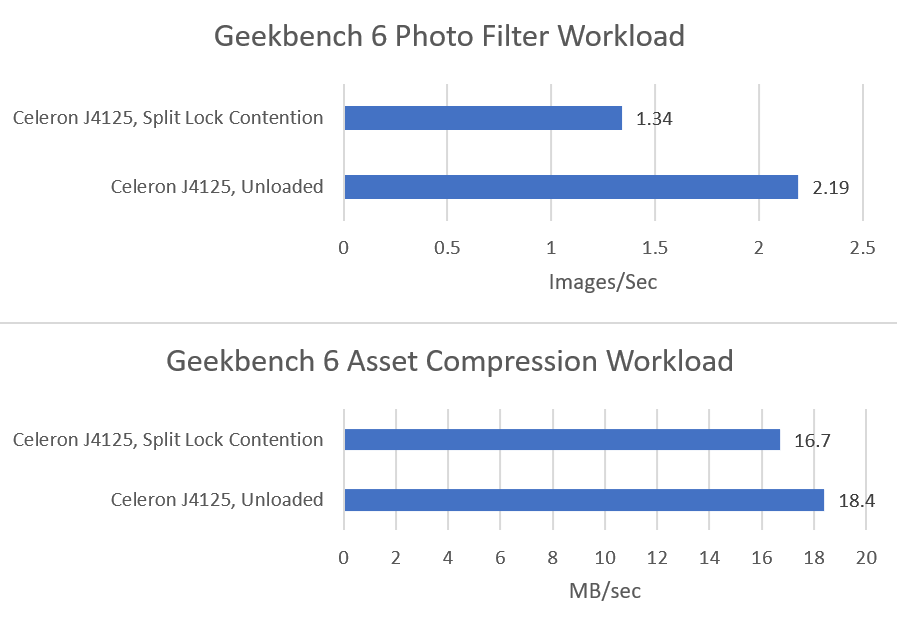
Both Geekbench 6 workloads show performance regressions, but it’s not much considering there’s also multi-core clock speed drops in the mix. Much of the score decrease for asset compression can probably be attributed to lower clocks. The photo filter workload definitely suffers, but not to the same extent as Arrow Lake or AMD’s Zen 2 or Zen 5.
What’s a Bus Lock, Really?
The term “bus lock” dates back to early multiprocessor systems, which placed multiple CPUs on a shared bus. Each CPU had its bus pins connected to the same motherboard traces, which connected them to the chipset. Locking the bus prevents other CPUs from making memory accesses, preventing them from interfering with atomic operations. Modern CPUs no longer use a shared bus, and instead use non-blocking, distributed interconnect setups. It’s not clear what a “bus lock” really means. And while Intel and AMD still use the terminology, “bus locks” caused by split locks clearly have a range of effects depending on the hardware in question.

I suspect Intel’s bus locks are implemented in their IDI (in-die interconnect) protocol. P-Cores and E-Core use IDI to talk to the uncore, which starts with the ring bus on most Intel client designs. Goldmont Plus’s performance monitoring documentation curiously indicates that a “bus lock” is a special request to the L2 controller, though L2 hits aren’t impacted just like on other Intel designs.
AMD’s implementation goes beyond a traditional bus lock in Zen 2 and Zen 5, with core-private L2 caches impacted as well. One possibility is that AMD falls back to the Infinity Fabric layer when handling split locks, though I don’t have strong evidence to support that. Performance monitoring events increment at the Data Fabric’s Coherent Stations during core to core latency test runs. But if they’re responsible, they only handle control path traffic because the increments aren’t proportional to L2 hit traffic observed when also running a memory bandwidth microbenchmark.
Piledriver also throws a wrench into the works when trying to define bus locks. Maybe AMD’s old architecture doesn’t use bus locks at all, and is able to use its cache coherency protocol to let unrelated accesses proceed as long as they hit cache.
Overall, there’s no good analogy to the classical shared bus on a modern CPU. Perhaps CPU designers should drop the term “bus lock” from documentation, and precisely document how a split lock impacts their systems.
Linux’s Split Lock Mitigation
Linux’s split lock mitigation traps split locks and introduces millisecond level delays, aiming to both make split locks “annoying” and provide better quality of service to other applications.
Testing on Linux without touching sysctl settings shows latency comparable to mechanical hard drive seek time, which is an eternity for a CPU. This kind of delay should also eliminate the noisy neighbor effects above, since the split lock core to core latency test simply isn’t running most of the time.
I think Linux’s default makes sense for mutli-user or server systems, which value consistent performance when running a large number of tasks. Limiting noisy neighbor effects from a rogue application, like my test code above that spams split locks, is a sensible option. I can see it being used alongside other QoS mechanisms like running at lower, locked clock speeds, partitioning caches, and throttling memory bandwidth usage to ensure consistency.

For consumer systems though, Linux’s default feels like an overreaction to a problem that didn’t exist. A core-to-core latency test uses locks at a rate no normal application would. A split lock variant of that test is even more ridiculous. Games have apparently been using split locks for quite a while, and have not created issues even on AMD’s Zen 2 and Zen 5. However, a game that runs at 10 FPS on Linux and 200 FPS on Windows is a problem for Linux.
Linux traditionally struggled on the desktop scene because it required a high level of technical skill and substantial troubleshooting time from users. Linux distros have made tremendous progress in chipping away at those requirements over the past two decades. But doing a scream test on users - that is, attempting to impose a vision of the “proper” way to do things by creating an artificial performance problem - is a step backward. Ease of use is everything in the consumer world. Every OS problem that a user has to troubleshoot is a failure on the OS’s part. Going forward, I hope Linux dodges avoidable problems like this.
Final Words
Split locks don’t stop other cores from running code. They’re not the hardware equivalent of Python’s global interpreter lock, or another similar construct that blocks concurrency. On modern CPUs, split locks don’t even block all memory accesses. They only introduce a performance penalty when those memory accesses miss a certain cache level. That performance penalty varies wildly too.
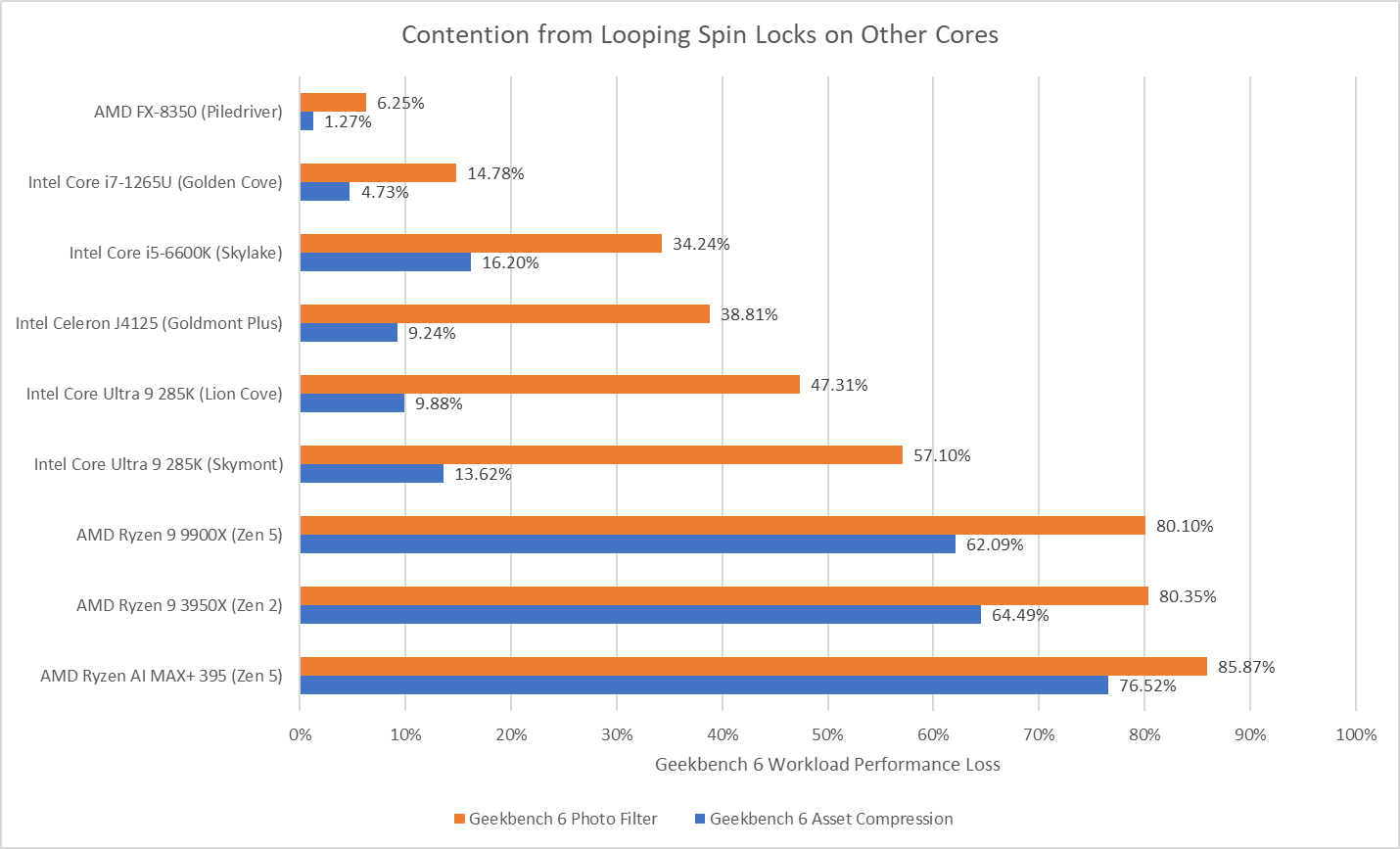
Applications tend to suffer varying degrees depending on how often they miss cache. Hardware has a huge influence too. AMD’s Piledriver and Intel’s Alder Lake do the best job of minimizing noisy neighbor effects. Piledriver is especially impressive because it manages that while delivering the best split lock latency across all hardware tested here. On the other hand, AMD’s Zen 2 and Zen 5 suffer heavily in this corner case. Another application could slow down so much that you’d be forgiven for thinking you got a version of it compiled using Claude’s C Compiler.
From these results, programmers should obviously strive to avoid split locks. They perform poorly, and have a heavier effect on other applications than intra-cacheline locks. From the hardware side, there’s clearly room to optimize split locks for better performance and reduced noisy neighbor effects. I hope to see both hardware and software developers take a measured, data-driven approach to tackling the split lock problem, and one that doesn’t involve introducing new performance problems.
Extras
Zen 5 in the Ryzen AI MAX+ 395 (Strix Halo) has higher split lock latency than its desktop Zen 5 counterparts. I suspect split locks are handled at Infinity Fabric’s Coherent Station blocks, but curiously those counters also increment for intra-cacheline locks that are handled within a CCX. Perhaps the Coherent Station gets some sort of notification about a line changing state.
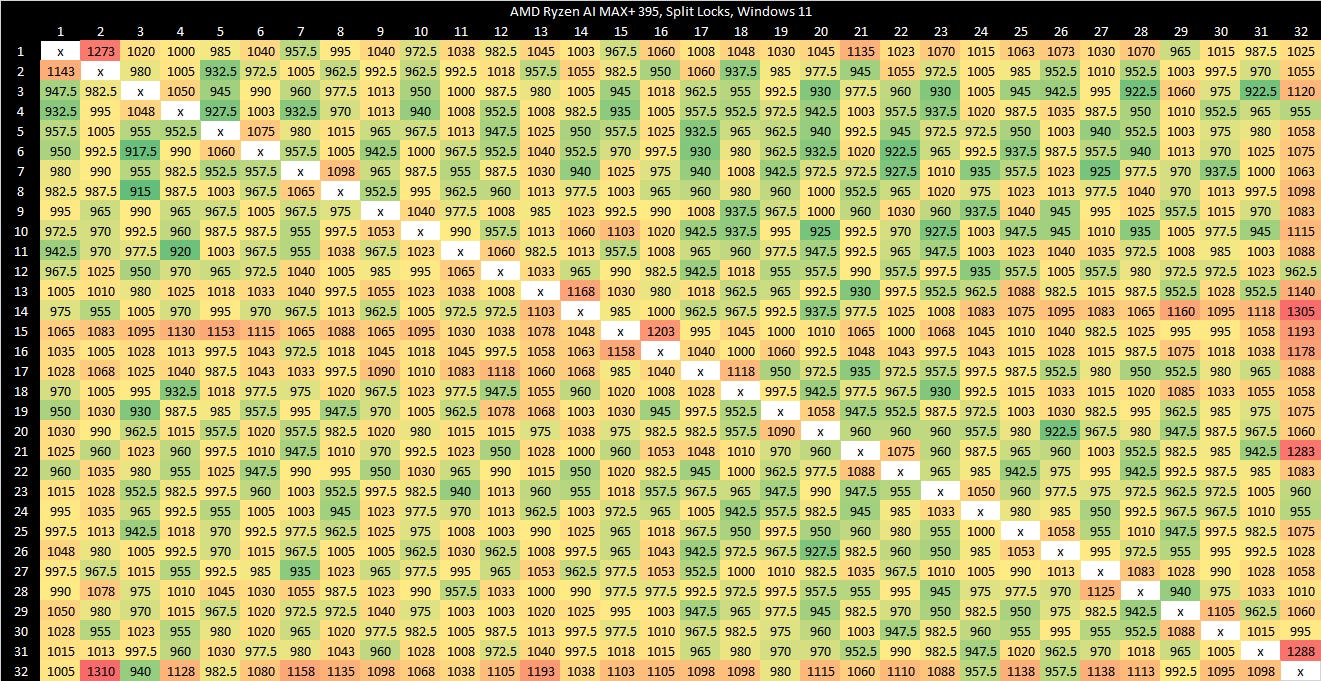
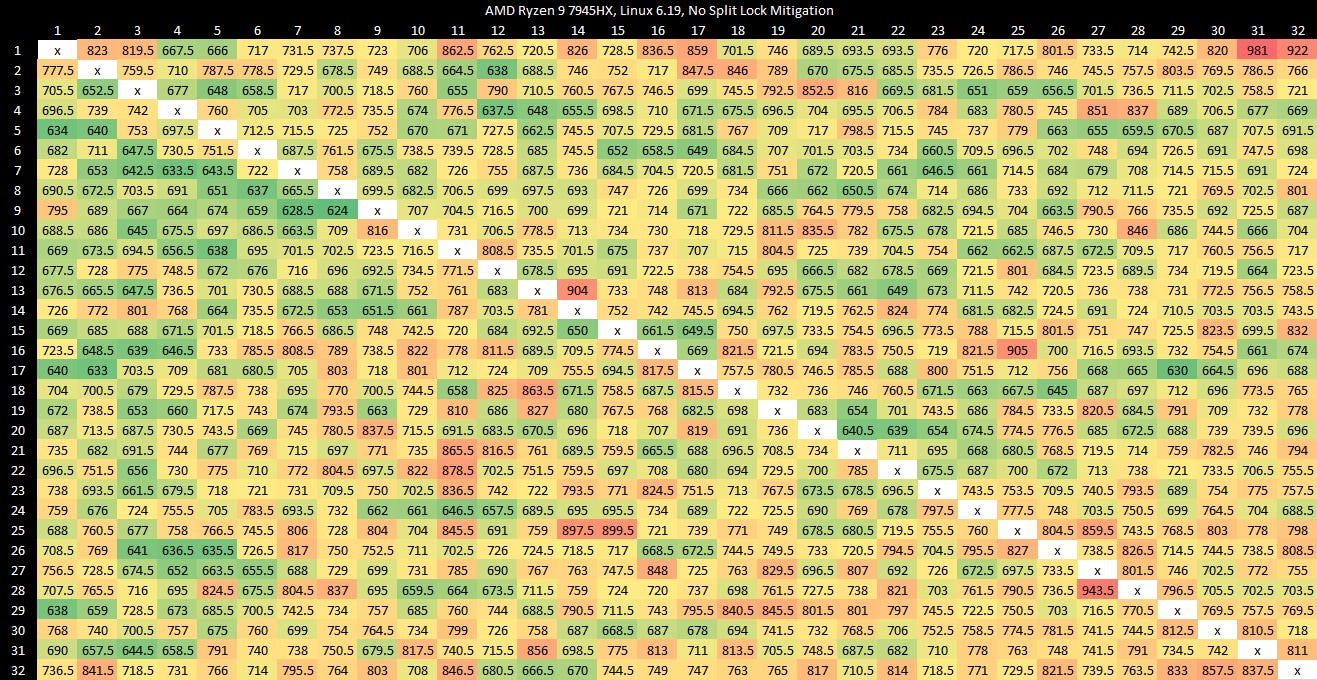
Zen 4 in a high performance mobile implementation shows similar split lock latency to Zen 2.
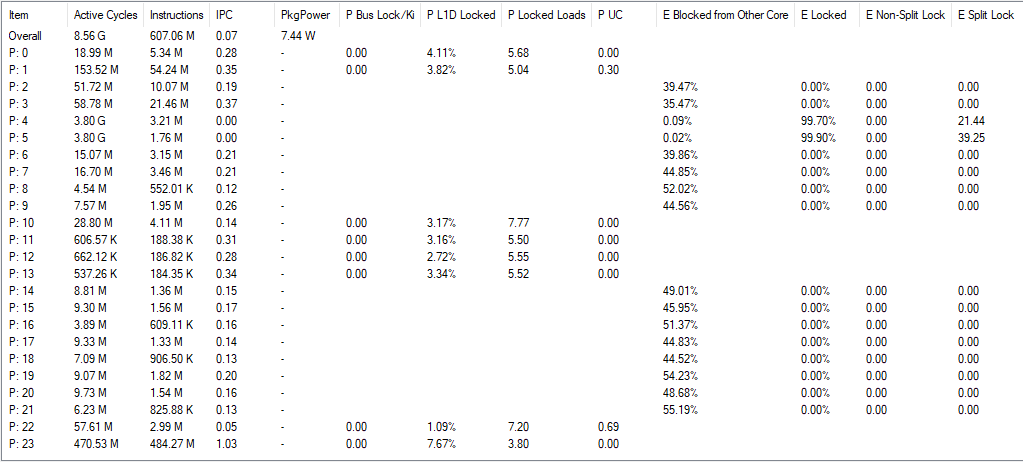
Arrow Lake E-Cores have a lot of monitoring sophistication around bus locks. Under the split lock core to core latency test, any E-Core involved gets blocked for nearly all cycles. However, other E-Cores are only blocked around half the time. That would explain the roughly 50% L3/DRAM performance degradation, though it does not explain how L2 performance remains unscathed.
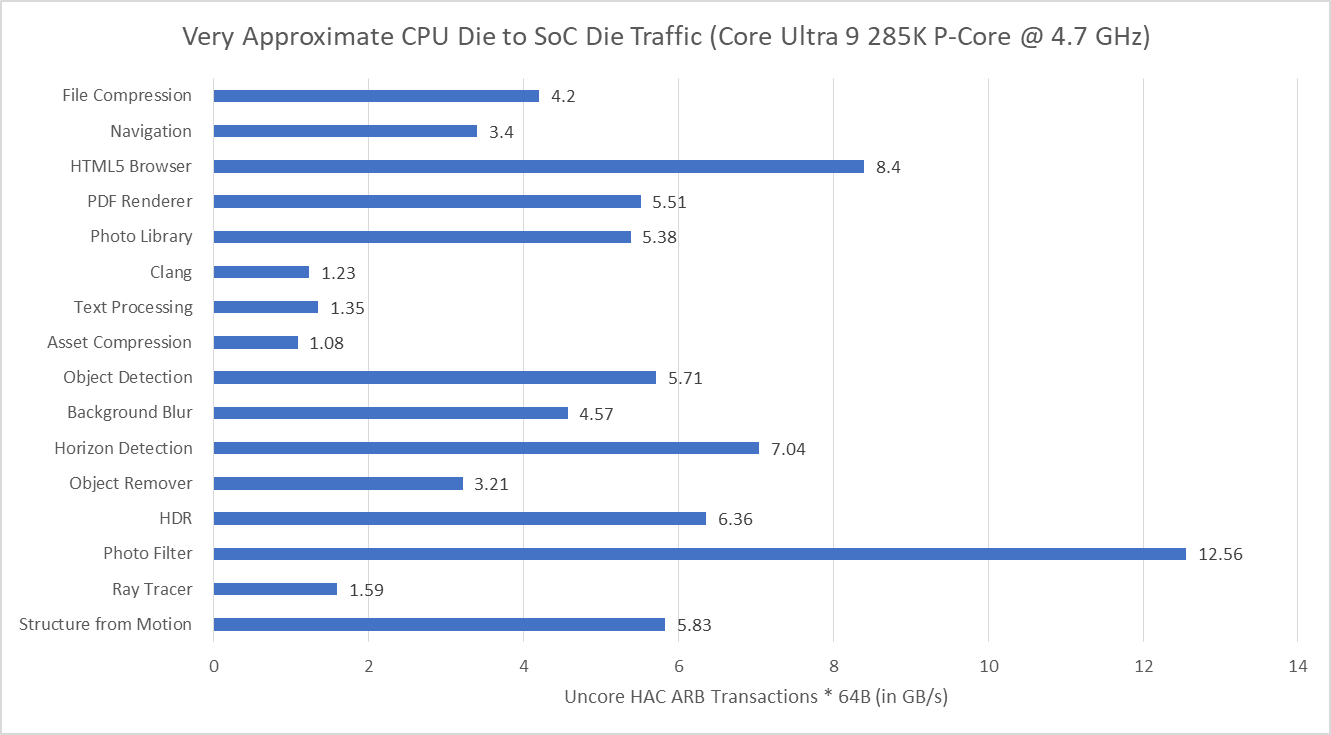
I took rough notes on die to die traffic when running Geekbench 6 workloads on Arrow Lake by observing performance counters sampled at 1 second interval and picking out spikes. My goal isn’t to give an accurate figure for average L3 miss traffic per workload, but rather to select two interesting workloads for measuring split lock impact.
Jeez.. great piece of insightful work.
I guess a lot of time must have went in to do those tests.
Do have a question for Chester:
P-Cores and E-Core use IDI to talk to the uncore, which starts with the ring bus on most Intel client designs.
Here the "uncore" refers to shared L3 cache slices onwards, the ring like interconnect on Arrow lake, I/O and integrated memory controllers?
Also, I'd be curious to know more about how modern x86 CPUs implement nontemporal stores. Back when I first played with it on a Pentium 4, it seemed to me that it had the effect of restricting which L2 cache set could be used. So, it did cause some cache pollution, but it was limited in scope. Do modern x86 CPUs still do something similar, or do they truly bypass the cache hierarchy, entirely?