
Inside Nvidia's GeForce 6000 Series

2025 has kicked off with a flurry of GPU activity. Intel's Arc B580 revealed that it's still possible to make a mid-range GPU with more than 8 GB of VRAM. AMD's RDNA 4 marked the continuation of a longstanding AMD practice where they reach for the top-end, before deciding it wasn't worth it after all. Nvidia too has a new generation to celebrate 2025, and their 5000 series launch has come and gone without cards on shelves. But bigger numbers are better, so it's time to talk about the GeForce 6 series.

Gamers demand higher quality graphics with each generation. No one knows this better than Nvidia, so GeForce 6000 series cards are built to deliver near-cinematic quality at framerates high enough to support interactive gameplay. GeForce 6000 GPUs, or the GeForce 6 series for short, are built with the highly parallel nature of graphics rendering in mind. At the same time, they take a great leap forward in terms of programmability, opening up exciting new possibilities for complex in-game effects.
Overview
Graphics rendering involves transforming vertex coordinates from 3D space to 2D screen space before calculating the final pixel colors, a process known as rasterization. Both stages are inherently parallel tasks, and map well to hardware with large arrays of execution units. Accordingly, a GeForce 6 series GPU is a massively parallel machine. It has a strong complement of fixed-function graphics hardware, but the real power of the GPU lies in a collection of vertex and pixel shader cores. These programmable components execute shader programs provided by the game instead of carrying out preset functions. They also serve as basic building blocks, letting Nvidia scale to different power, price, and performance targets. The highest end GeForce 6000 series chip, NV40, implements 6 vertex shader and 16 pixel shader cores.

A highly parallel machine needs a high bandwidth memory subsystem to keep it fed. GeForce 6 series products can feature up to a 256-bit GDDR3 DRAM setup, giving it significantly more memory bus width than typical desktop CPUs. The GPU features a L2 texture cache shared across all pixel and vertex shader cores, which enables short-term reuse of fetched texture data. Nvidia did not disclose cache sizes at this time, but they aim for a 90% hitrate with many misses in flight, rather than the 99% hitrate one often sees with CPU caches. The GPU communicates with the host system via the popular AGP interface, but can also support the upcoming PCI Express standard.
Vertex Shader Core
Vertex shader programs transform coordinates from 3D to 2D screen space. It may sound like a trivial task that involves little more than a camera matrix multiplication and perspective division. But programmable vertex shaders open up new tricks. For example, a vertex shader can sample a texture and use it as a displacement map. Besides supporting texture accesses, GeForce 6000's vertex shader cores support branches, loops, and function calls. Much of this capability was previously unthinkable on anything outside a real CPU, demonstrating the exciting nature of GPU evolution.
Vertex shader execution starts with instruction fetch from a 512-entry instruction RAM. Nvidia uses 128-bit vertex instructions from the driver format, which are translated into a 123-bit internal format. Thus the instruction RAM has approximately 8 KB of capacity. DirectX 9's vertex shader 3.0 standard mandates a minimum of 512 instruction slots, and Nvidia's vertex shader core ISA is closely aligned to DirectX 9's HLSL instructions. Thanks to instruction limits, shader programs are immune to performance losses from instruction cache misses, which CPU programs can often suffer. Furthermore, accessing the instruction RAM doesn't involve tag comparisons like a cache would, saving power.

DirectX 9 vertex shader HLSL instructions broadly fall into scalar and vector categories. Scalar instructions include special operations like inverse square roots. Vector instructions generally involve basic operations like multiply-add, and operate on 128-bit vectors of four 32-bit values. GeForce 6000's vertex shader pipeline is highly optimized for this arrangement, and features separate vector and scalar pipelines. Each ISA instruction specifies both a scalar and vector operation, letting the vertex shader core exploit parallelism in two dimensions within one instruction stream. Vectors specified by the DirectX 9 shader program provide vector-level parallelism. Any scalar+vector dual issue opportunities found by Nvidia's compiler provide additional parallelism.

A third source of parallelism comes from multithreading, and serves to hide latency. The vector operation slot can accept texture sampling instructions. Memory accesses from a vertex shader should still be relatively uncommon, so vertex shader cores don't have a L1 texture cache tied to their texture fetch unit. Nvidia expects a shader program will need 20-30 instructions to hide texture fetch latency, which can be hard to achieve from a single thread. Therefore, vertex shader cores can each track up to three threads and switch between them to hide latency.

Instruction inputs can come from registers or constant RAM. Both consist of 128-bit vector entries to match vector execution width. Register files are split into input, output, and temporary registers. The input and output registers each have 16 entries, and are read-only or write-only respectively from the shader program's point of view. The temporary register file supports both reads and writes, and has 32 entries. DirectX 9's vertex shader 3.0 specification lets a shader program address up to 32 registers, but Nvidia might share the register file between multiple threads. If so, a vertex shader program should use no more than 10 temporary registers to achieve maximum occupancy.
Pixel Shader Core
Pixel shaders, or fragment shaders, do much of the heavy lifting because rendering a scene typically involves processing far more pixels than vertices. Accordingly, a GeForce 6000 GPU can have up to 16 pixel shader cores. The pixel shader cores themselves are highly programmable just like the vertex shader cores, with branching support among other goodies. However, pixel shader cores are built very differently to exploit increased parallelism typically present at the pixel level.
GeForce 6000's pixel shaders use 128-bit instructions, though the encoding is substantially different from the one used in vertex shaders thanks to hardware differences. Nvidia has chosen to support up to 65536 pixel shader instructions, exceeding the DirectX 9 minimum specification of 512 instruction slots by a wide margin. Using all instruction slots would consume 1 MB of storage, so pixel shader cores might use an instruction cache.
The fragment processor has two fp32 shader units per pipeline, and fragments are routed through both shader units and the branch processor before recirculating through the entire pipeline to execute the next series of instructions
From The Geforce 6 Series GPU Architecture, Emmet Kilgariff and Ramdima Fernando
Where Nvidia's vertex shader core operates much like a CPU with 3-way SMT to hide latency, the pixel shader core uses a SIMD execution model across threads. That parallelism, often referred to as SIMT (Single Instruction Multiple Thread), applies on top of the SIMD you get within a thread from using multi-component vectors. Rather than tracking three separate threads, Nvidia groups many pixel shader invocations into a vector and effectively loops through the "threads" in hardware. This approach lets Nvidia keep thousands of "threads" in flight at low cost, because threads in the same vector must execute the same instruction and cannot take an independent execution path from other threads. Only the data being processed is different.

Programmers must pay attention to divergence penalties with this SIMT threading model. If different threads within a vector take different directions on a conditional branch, the pixel shader core will execute both sides of the branch with non-active threads masked off. That contrasts with the vertex shader core's MIMD execution model, which allows penalty free branching even if branch directions diverge across threads running in the same core. Nvidia suggests keeping branches coherent across regions of over 1000 pixels, or approximately 256 2x2 pixel quads, hinting at very long vector lengths.
Keeping that much work in flight is critical to hiding latency, but places pressure on internal chip storage. DirectX 9 lets pixel shaders address 32 temporary registers, which continue to be 128-bits wide. Keeping 256 threads in flight would require 128 KB of register file capacity per pixel shader core, which will not be achieved in GPUs for several years. GeForce 6000 uses smaller register files of unknown size. Nvidia says pixel shader programs can get the maximum number of threads in flight if they use four or fewer 128-bit registers. As ballpark estimate, 256 threads with four registers per thread would require 16 KB of register file capacity.

The pixel shader core's two 128-bit vector units are placed one after another in different pipeline stages. Both can execute four FP32 operations per cycle, though only the lower one can do multiply-add. The upper one can handle special functions and texture address calculation. Texture operations are issued between the two execution unit stages. Peak FP32 throughput is 12 operations per cycle. That can be achieved for example by issuing a vector FP32 multiply in the upper stage and a FP32 multiply-add in the lower one.

From a shader program's perspective, the upper and lower vector units together can complete two vector operations per cycle. Compared to the vertex shader cores, the pixel shader's sequential "dual issue" arrangement lets the upper unit forward its results to the lower one. Thus two dependent instructions can "dual issue". Besides interleaving instructions for the two vector units, Nvidia's compiler can pack operations that work on different subsets of vector elements into a single instruction, which improves vector unit utilization within a thread. FP16 execution can improve throughput even further. Full 32-bit precision is often not necessary for graphics rendering, especially when it comes to pixel colors. Both vector execution units in the pixel shader core can execute FP16 operations at double rate. Using FP16 also halves register file usage for those values, which in turn can also improve occupancy and therefore latency hiding.
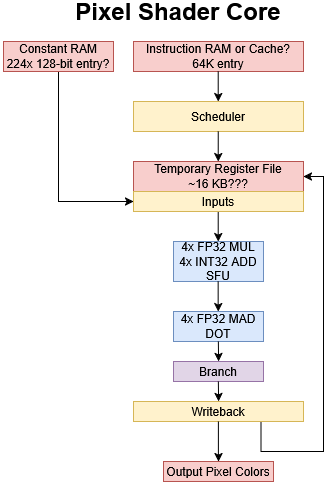
Texture sampling is an important part of pixel shading, so pixel shader cores get an optimized texture sampling path compared to the vertex shader cores: each core has a L1 texture cache, backed by a chip-wide L2 texture cache.
Going Beyond Pixel Shading
Pixel shader programs normally output pixel colors, but colors are really just numbers. The bulk of GeForce 6000's massive parallel compute power is concentrated in its array of pixel shaders, and having lots of GFLOPs is great for non-pixel things too. Furthermore, the flexibility of the pixel processing pipelines can let creative programmers do just about anything.

For example, ray tracing is a fundamentally different approach to graphics rendering (compared to rasterization), that involves tracing light rays through a scene. Ray tracing was largely confined to offline applications because of its compute power requirements. However, GeForce 6's programmable pixel shaders are up to the task of real-time rendering, at least for simple scenes.

The possibilities go beyond different graphics rendering techniques. The power of programmable shaders has spurred the development of new GPU programming APIs not directly aimed at graphics. Stanford's Brook API targets general purpose compute on GPUs. Its programming model is tightly tied to the way GPUs are optimized for parallel work. Getting up to speed on such a model can take some getting used to, especially as most programmers have been taught using a serial execution model. But researchers and other developers doing highly parallel and highly regular data processing should take note of these APIs.
Difficulties Remain
Significant barriers still stand in the way of running any parallel task on a GPU: shader programs access memory through textures bound to it; textures have limited size compared to CPU-side memory allocations; floating-point precision is often lacking compared to a full-spec IEEE 754 implementation; shaders can only execute for a short length of time without stalling the display; textures can't be modified during shader execution, etc.
Developers also have to move data between CPU and GPU memory spaces to provide the GPU with data and get the results. The latter can be problematic because GPUs are optimized for presenting pixel shader output as a frame on-screen, before quickly overwriting it with a subsequent frame. Copying data back from the GPU can run into host interface limitations.

Nvidia is no doubt aware of these limitations, and is working to address this. GeForce 6 will support the incoming PCI Express standard alongside AGP. PCI Express's increased bandwidth moves the GPU one step closer to being an accessible parallel accelerator.
Final Words
GeForce 6's pixel and vertex shader pipelines are more flexible than ever, and shows Nvidia is taking programmable shaders seriously. Many of the capabilities introduced in GeForce 6 may seem excessive for current gaming workloads. It's hard to imagine anyone writing a shader hundreds of instructions long with loops, calls and branches mixed in. What GeForce 6's capabilities show is that Nvidia is competing on features beyond basic graphics rendering. It's part of a larger trend arising from the move away from fixed-function hardware, and has exciting implications for GPUs. Perhaps soon, we won't be calling these cards GPUs anymore, considering they can do much more than render graphics.

Despite its programmability, GeForce 6000 GPUs continue to focus strongly on graphics. Nvidia's shader ISA remains closely tied to DirectX 9 specifications, ensuring shader programs in games run well on the hardware. And the hardware is quite powerful; a high-end GeForce 6000 chip has over 200 million transistors. That's made possible by IBM's advanced 130nm process. Providing all that processing power demands serious power delivery too, so high end cards use a pair of molex connectors. Molex connectors are a time-tested standard, with thick pins and wires that can reliably supply power to a variety of peripherals without melting.
In conclusion, GPUs are advancing at an incredible pace. 2005 is an exciting time to be alive. Graphics rendering technologies are moving in lock-step with the nation's economy towards 2008, and undoubtedly everyone is looking forward to that bright future.
Wait, what year is it again? Oh, and happy April Fools!
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
References
Nvidia GeForce 6800 Hot Chips presentation
Emmet Kilgariff and Ramdima Fernando, The GeForce 6 Series GPU Architecture
John Montrym and Henry Moreton, The GeForce 6800
Ashu Rege, Shader Model 3.0
Matthias Wloka, GeForce 6 Series Performance
Ian Buck et al, Brook for GPUs: Stream Computing on Graphics Hardware
I still remember the Nvidia tech demo for the 6800 GPUs.
Chester, if you have any updated information or additional insights on Nvidia's decision to basically dump PhysX support in their Blackwell GPUs*, please let us know. As of now, they won't even provide a wrapper; thus, a 5090 is, with the right-wrong game that wants PhysX, slower that an RTX 950.
* That "*" is here because I don't know if they also just dropped PhysX in their professional Blackwell cards. There is still some professional software that actually uses PhysX, so those customers wouldn't be pleased if their software doesn't run so well on their new Blackwell GPU.