
Embracing AI with Claude's C Compiler
Down with the old! In with the new!

Our society has gone all-in on AI. Software and related technologies represent one of the biggest sectors of the US economy, and technology companies have all but bet the farm on LLMs being able to do everything under the sun. By the law of sunk costs*, AI investments will increase without bound until that objective is achieved. AGI is therefore inevitable, and everyone must fully commit to ensuring AI’s success because things will get more painful the longer it takes. When bank money runs out, the government will bail them out. When government funds are exhausted, aliens will get involved, followed by various deities. Please don’t ask what happens after that. Anyway, it’s in everyone’s best interest to embrace the AI revolution with absolute conviction. Therefore, I’m excited to announce that Chips and Cheese will stand at the vanguard of the AI revolution by adopting Claude’s AI-generated compiler, CCC.
CCC, or Claudes’ C Compiler, is a “from-scratch optimizing compiler with no dependencies […] able to compile the Linux kernel.” Anthropic used their Claude large language model (LLM) to write the entire compiler. Human effort was relegated to prompting and maintaining AI coding agents, and standing up a very robust test suite to keep those coding agents on track. Past Chips and Cheese articles used microbenchmarks and benchmarks built using GCC. GCC was developed by humans, which is backwards and reactionary by the standards of many cadres today. Comparing GCC and CCC should be a powerful showcase of revolutionary software development practices.
Compiling a Microbenchmark
Microbenchmarking is a useful tool for understanding low level hardware characteristics like cache and memory latency. My first shot at testing load latency used a simple loop of dependent array accesses in C:

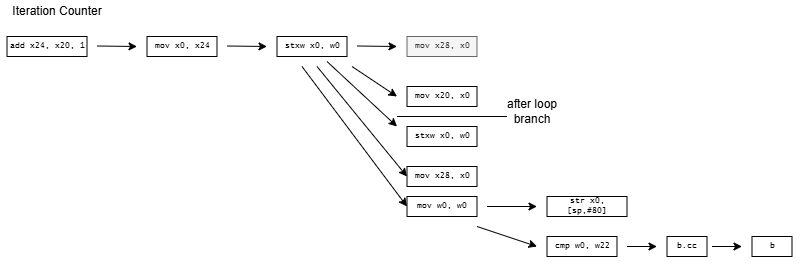
A = A[current] creates a dependency chain where one array access result feeds into the next, preventing accesses from overlapping even on an out-of-order core. Dividing access time by iteration count gives latency. CCC and GCC compile the loop into the following assembly code:
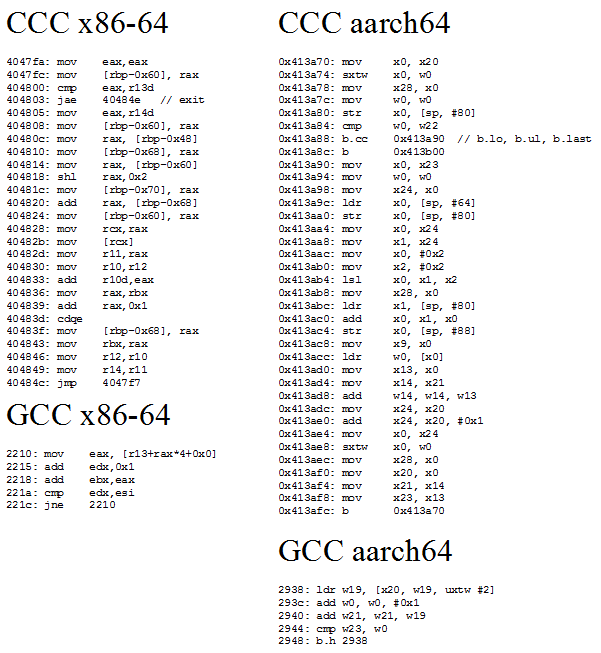
CCC generates more code from the same high level source than GCC does, and sometimes, more is better. CCC’s code is more ideologically correct from a RISC standpoint. GCC uses indexed addressing modes that express a dependent shift, add, and load sequence in a single instruction. RISC advocates for a small set of simple instructions and larger code sizes, and indexed addressing modes are quite complex. CCC follows the RISC philosophy, and splits the array access into separate shift, add, and load instructions.
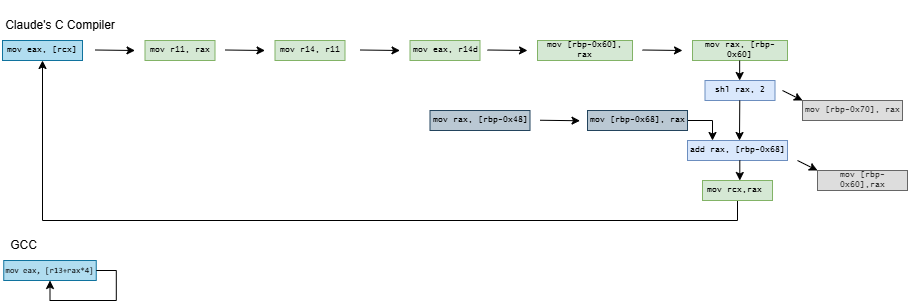
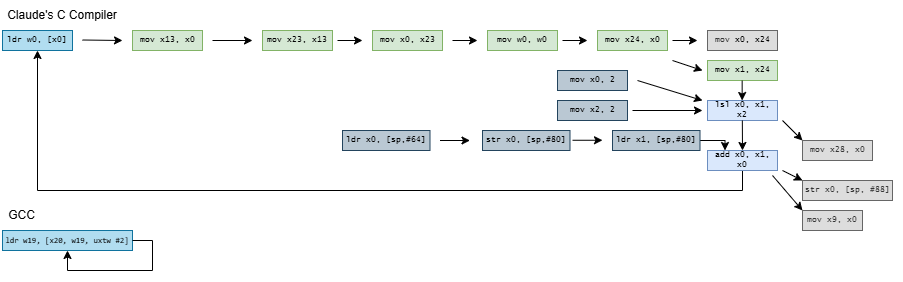
CCC doesn’t stop there and exceeds quotas by decomposing current = A[current] into a nine instruction dependency chain. On x86-64, it shuffles the index through several registers and sends it on a trip through the stack. It does the same on aarch64, but at least keeps the index in registers. On both architectures, CCC brings the array base address in from the stack, and sends it on another round trip through the stack for good measure before using it.
Compiling the microbenchmark with CCC results in higher observed array access latency. Zen 5 and Lion Cove need two extra cycles, likely from the shift + add dependency chain. Exceptionally strong move elimination and zero-latency store forwarding seem to let Intel and AMD collapse the nine-instruction dependency chain. After that, their out-of-order core width absorbs the additional instructions. Arm’s recent cores have less robust move elimination and can’t do zero latency store forwarding. They suffer a 6-7 cycle penalty.
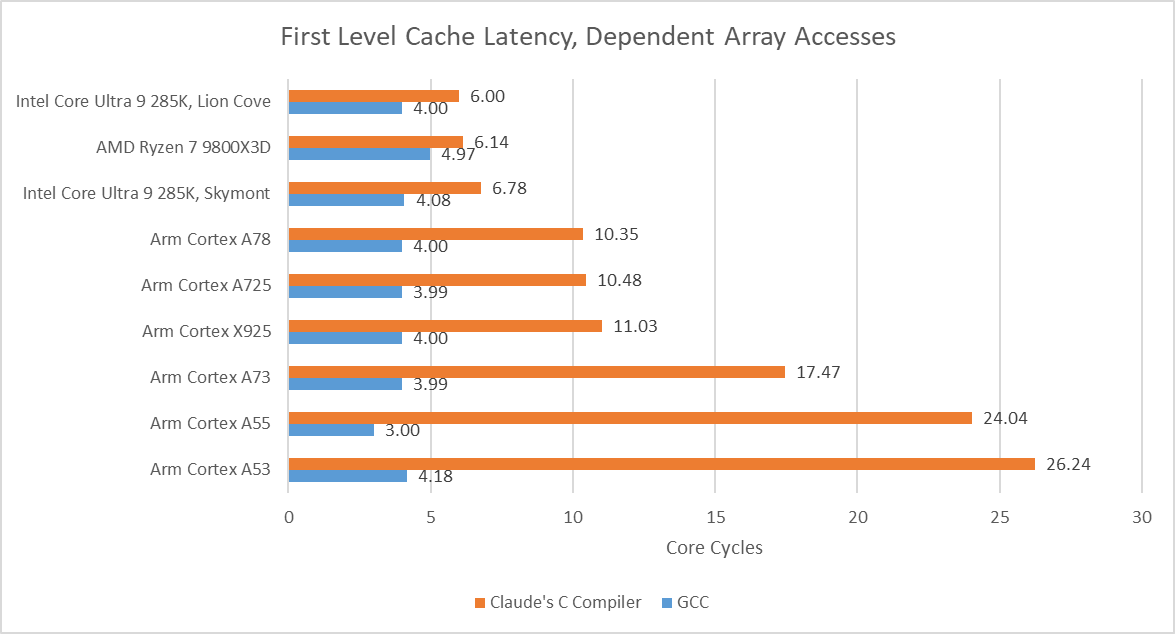
Smaller cores with narrower execution engines struggle with CCC-compiled code, likely because they don’t have enough core throughput to absorb loop overhead and the sum += current sink statement. CCC also compiles those into very long assembly sequences, placing pressure on core throughput.
In-order cores suffer the largest penalties. They’re not embracing the AI revolution with adequate enthusiasm, and should seriously reconsider their stance or risk getting denounced.
Challenging the Old Type Based Order
Old, traditional compilers force the masses to follow a tight set of rules dreamt up by the bourgeoisie. If a programmer doesn’t follow these rules, the compiler will complain and may even refuse to complete the compilation process. Warnings and errors are of no use to the proletariat, who just want results. CCC boldly crushes type systems with revolutionary fervor, as if to shout “out with the old, in with the new!” Take the following code:

GCC cowers behind error messages with weak excuses about incompatible types and fails to produce a binary. In doing so, GCC engages in counter-revolutionary wrecking by undermining the work of the masses, who have to waste time fixing errors.

Rather than make excuses, CCC raises the revolutionary banner high and produces an executable.
Performance: SPEC CPU2017
Claude’s C Compiler only compiles C code. All other languages are therefore invalid. Eight of SPEC CPU2017’s workloads are C-only. I tested them on the following cores:
Arm Cortex X925 in Nvidia’s GB10
AMD Zen 5 in the Ryzen 7 9800X3D, with boost disabled
Intel Lion Cove in the Core Ultra 9 285K
I ran with boost disabled on the 9800X3D because running CCC-built workloads takes a lot of time. Extra time spent in high performance states mean more power consumption, and we should save every last bit of power possible to feed AI applications.
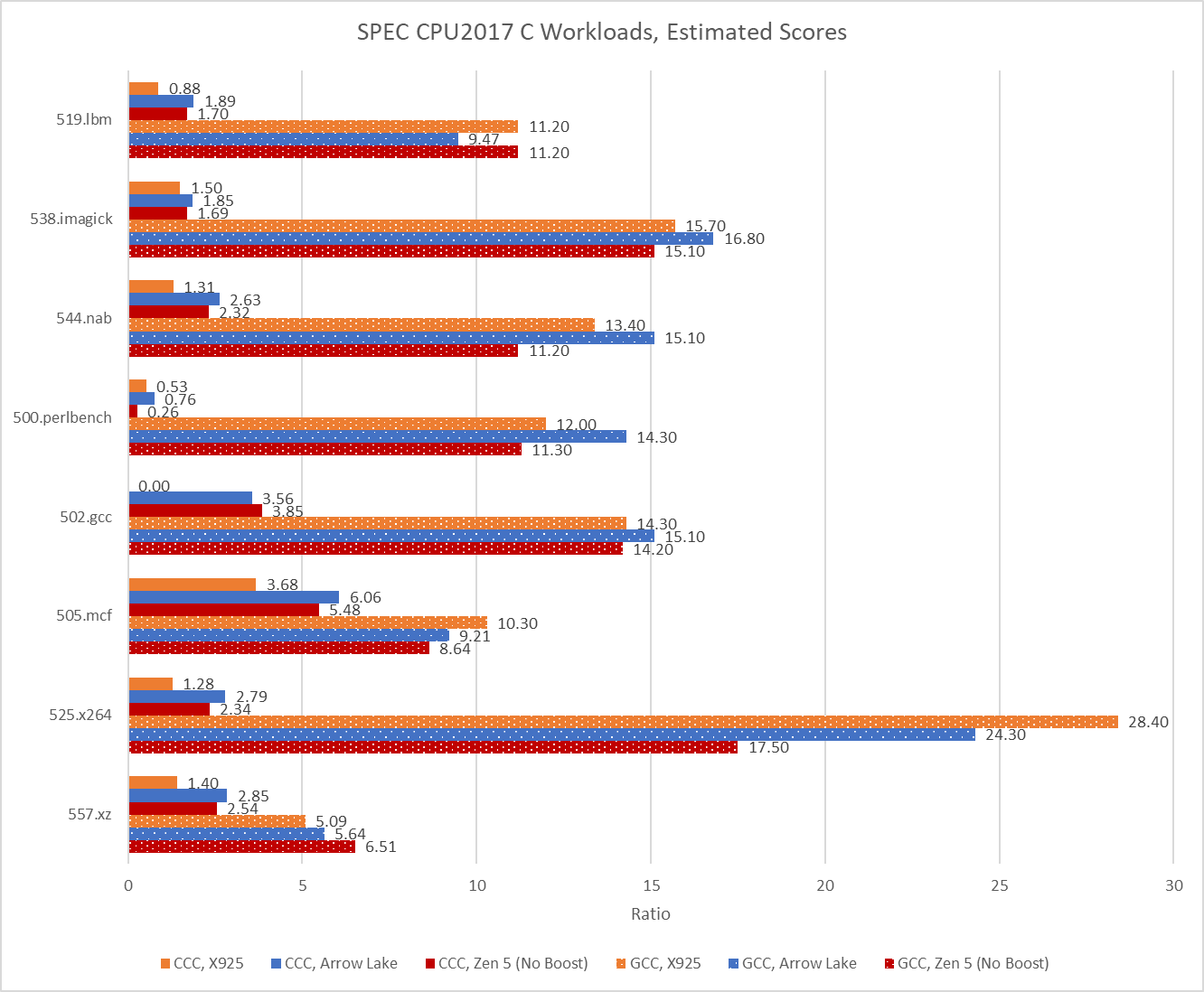
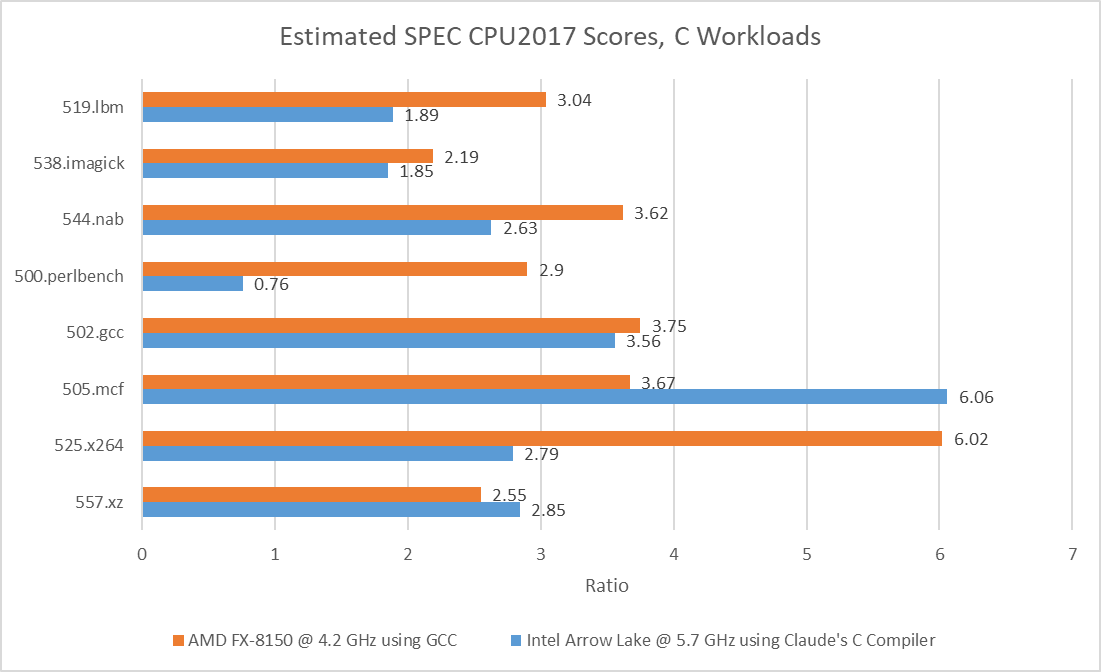
CCC’s version of 502.gcc consistently crashed with a segmentation fault on Cortex X925, even though it managed to complete some runs on x86-64. When it ran to completion on x86-64, CCC’s 502.gcc delivered 23.6% and 27.1% of the performance of its GCC-compiled counterpart on Lion Cove and Zen 5, respectively. CCC hit its relative performance peak on 505.mcf, where it managed less than a 35% regression versus GCC. Across the eight tested SPEC CPU2017 workloads, using CCC on average regressed performance by somewhere above 70%.
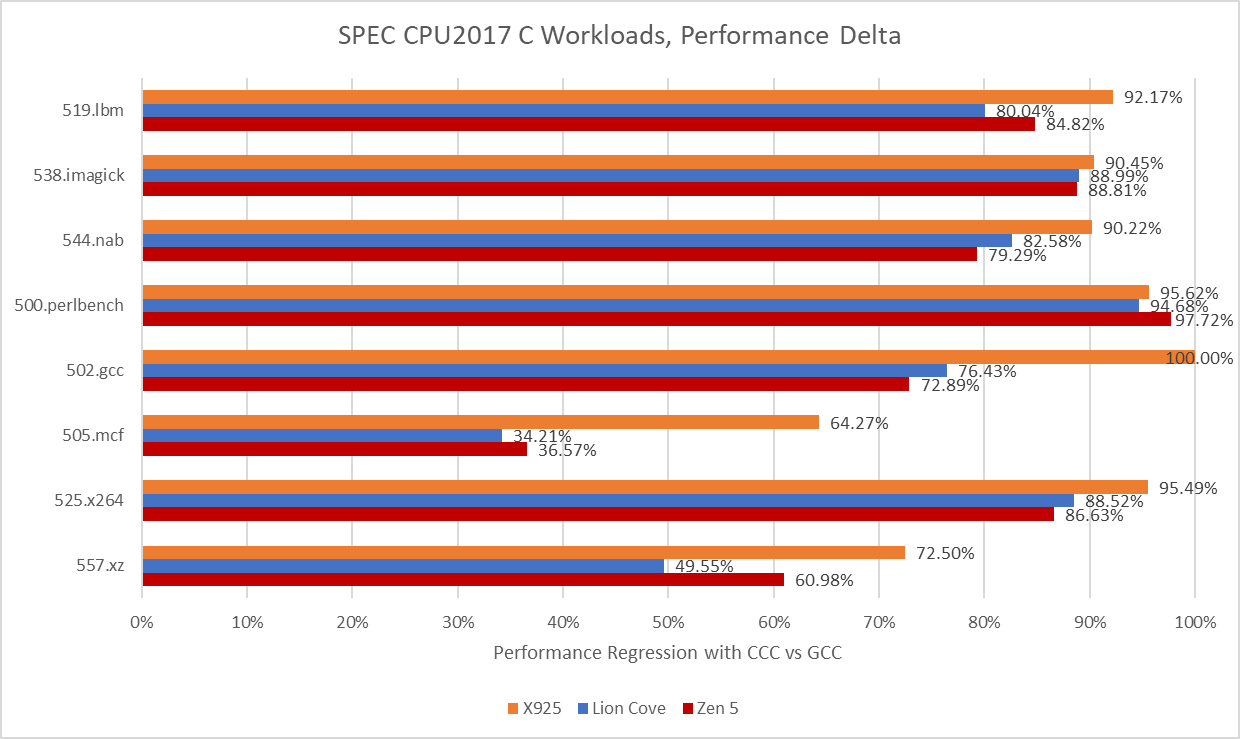
Arm’s Cortex X925 suffers hardest from the CCC switch. With GCC, Arm’s core was very much a match for Zen 5 and Lion Cove. Now, it loses in every workload except for 500.perlbench, where Zen 5 takes a dive to let X925 slip ahead. But X925 still can’t compare to Lion Cove in that workload.
In turn, Lion Cove can’t compare to Sun’s UltraSPARC IV+. SPEC CPU2017 scores are speedup ratios relative to a reference machine, which is “a historical Sun Microsystems server, the Sun Fire V490 with 2100 MHz UltraSPARC-IV+”. Lion Cove may have the best 500.perlbench score of the three cores tested here at 0.76, but that’s below 1. A vibe-coded compiler is the product of the latest software development techniques and can’t be at fault. It therefore follows that Sun’s UltraSPARC-IV+ is amazing. The UltraSPARC-IV+ is a dual core version of the UltraSPARC III, which uses a 4-wide in-order pipeline. Lion Cove is an 8-wide out-of-order design with massive reordering capacity and much higher clock speeds, but clearly none of that is necessary to win.
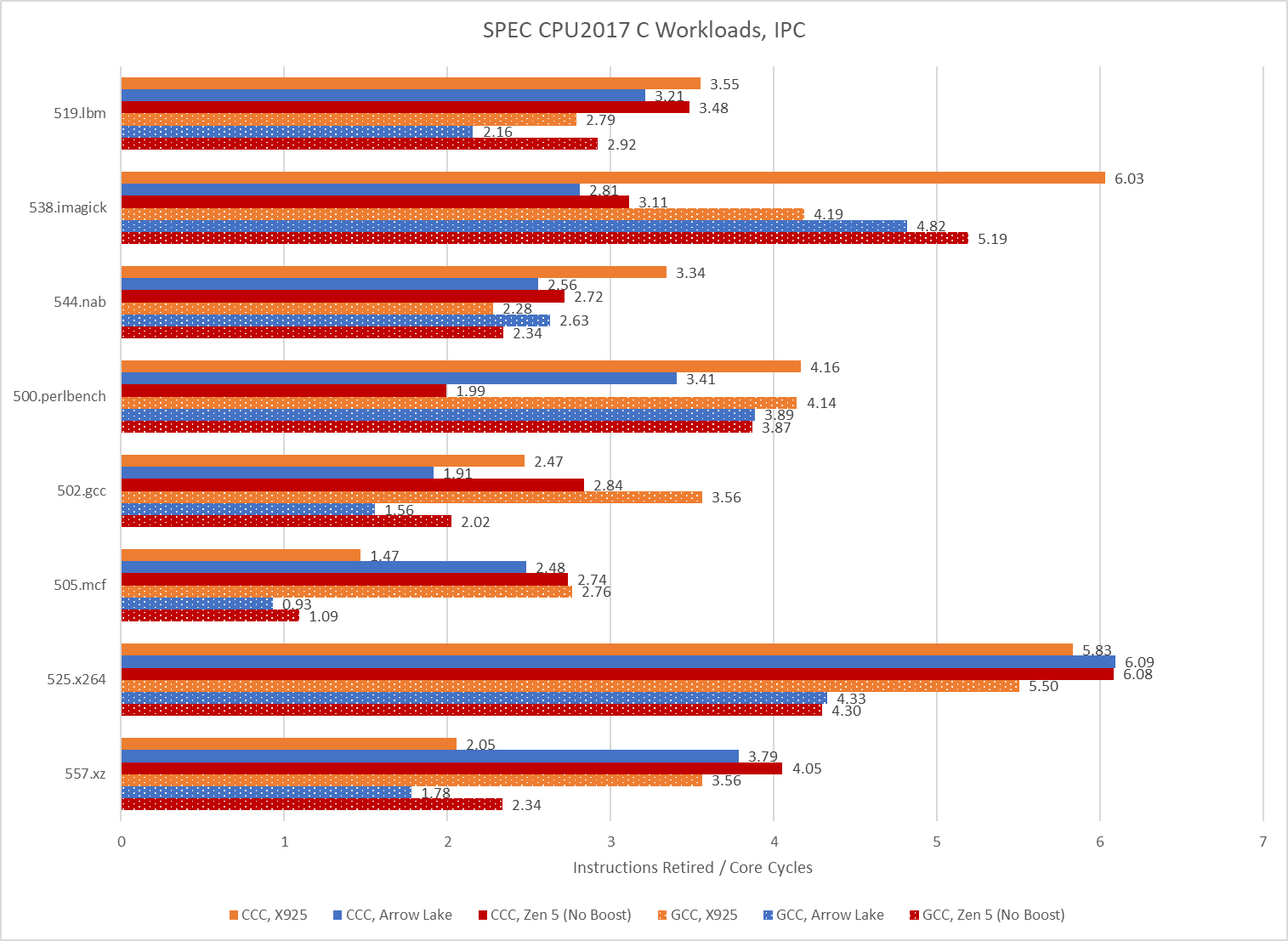
Performance is overrated. Analysts today agree that IPC is more important than performance, and CCC code achieves excellent IPC. On 525.x264, Arrow Lake averages 6.09 IPC when running CCC code. That’s the highest IPC average across all SPEC CPU2017 runs above. GCC’s best IPC average tops out at a wimpy 5.5. CCC’s IPC advantage isn’t universal though, and GCC does manage higher IPC on 538.imagick.
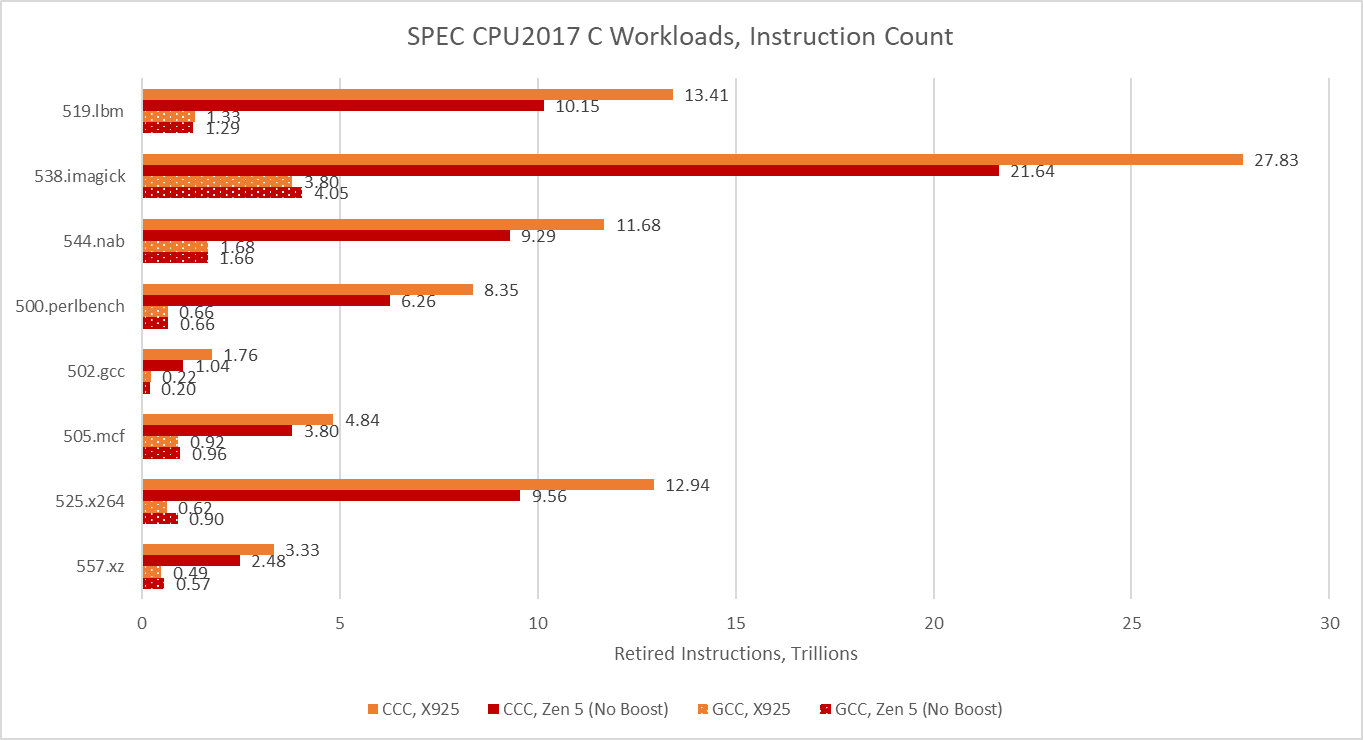
As foreshadowed with the cache and memory latency microbenchmark, CCC takes a great leap forward in instruction counts across all eight SPEC CPU2017 workloads. Some workloads execute more than 10x as many instructions.
A Top-Down View
Hardware performance monitoring reveals a different set of challenges for the CPU pipeline when comparing GCC- and CCC-compiled code. Branch prediction is less important because branch count didn’t grow proportionately to total instruction count. SPEC CPU2017’s three C-only floating point workloads become very core-bound when built with CCC. On Zen 5, that means retirement is blocked by an instruction that doesn’t read from memory. That indicates performance is limited by how fast the core can execute instructions, rather than how fast the memory subsystem can feed the core with data. The five integer workloads become less frontend bound, and face steeper backend challenges. CCC workloads across the board achieve higher core utilization than their GCC-compiled counterparts, as the IPC figures from before suggest.
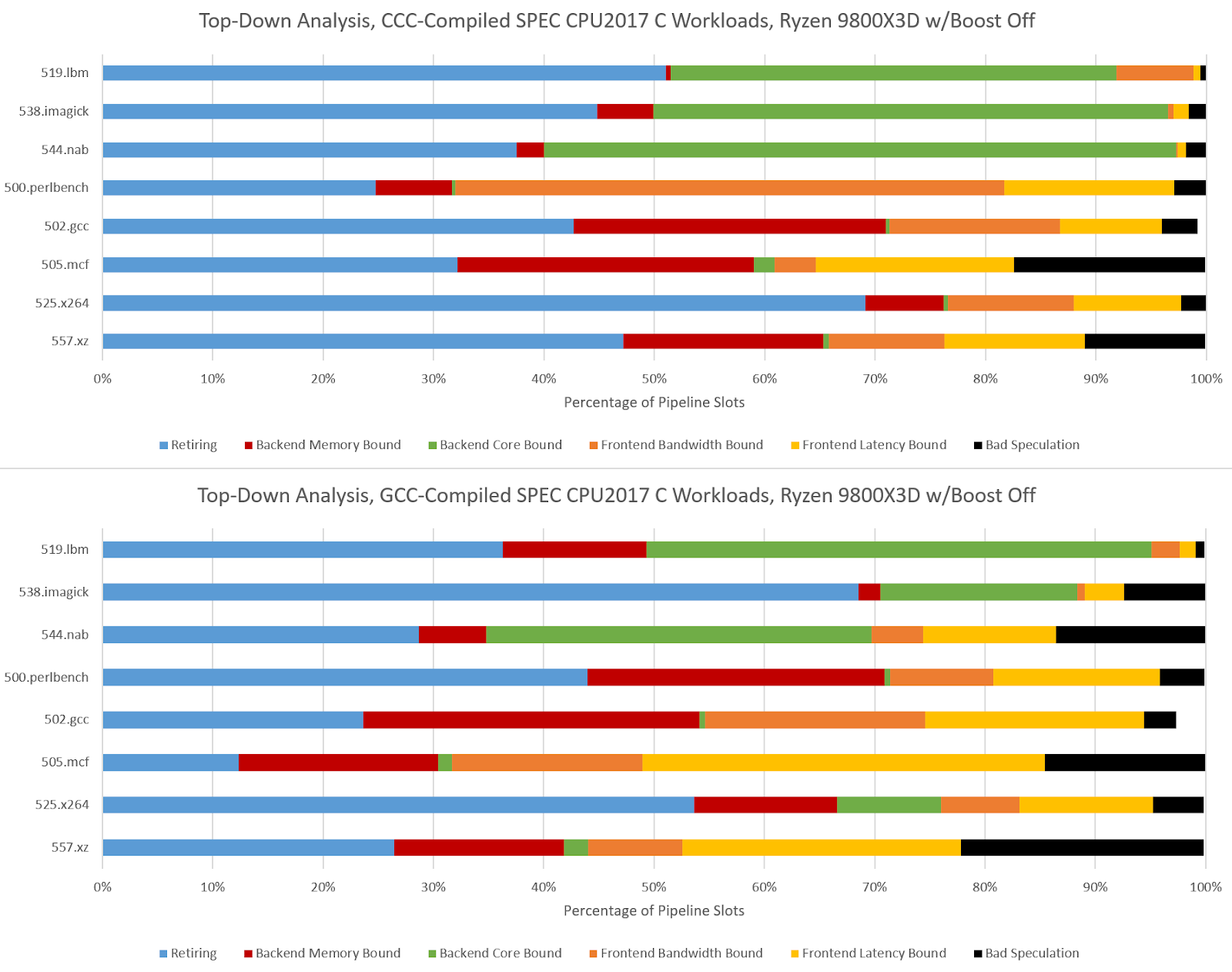
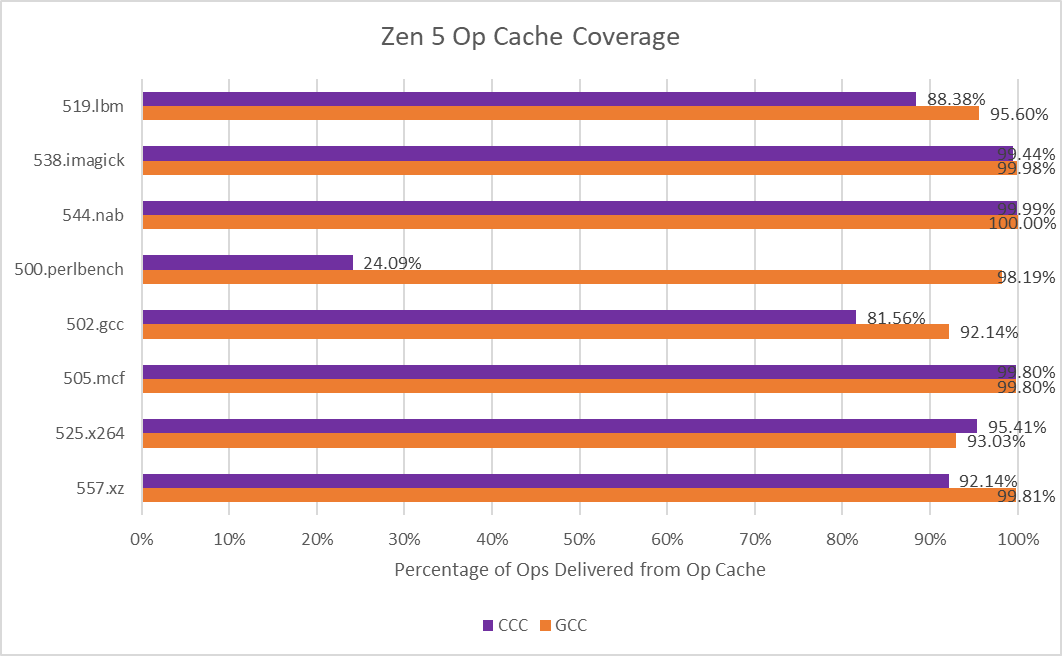
500.perlbench is a catastrophically bad case for Zen 5 when compiled with CCC because of a much lower op cache hitrate. Zen 5 primarily feeds itself with a 6K entry, 16-way op cache, which can fully feed the 8-wide rename/allocate stage. 4-wide, per-thread decoders handle larger instruction footprints. Typically applications with poor code locality suffer from other IPC limiters besides frontend throughput, especially when the core isn’t running a second thread that can hide latency. 500.perlbench has higher IPC potential if not for the per-thread decode throughput limitation, putting Zen 5 behind X925 and very far behind Lion Cove. It’s the first case I’ve seen outside a microbenchmark where Zen 5’s decoder arrangement comes out to bite. Zen 5’s op cache manages high coverage in other workloads, so 500.perlbench is an exceptional case.
CCC challenges Lion Cove’s pipeline in a similar fashion, though Lion Cove is generally more backend bound than Zen 5. This could be because Lion Cove sits atop a higher latency uncore. Or, the difference could be down to accounting methodology. For example, Intel might be counting cycles where any instruction is delayed by a load as “memory bound”, which could lead to higher counts than AMD’s approach. Lion Cove’s 8-wide decoder excels in 500.perlbench, where frontend limitations are minor compared to what they were in Zen 5.
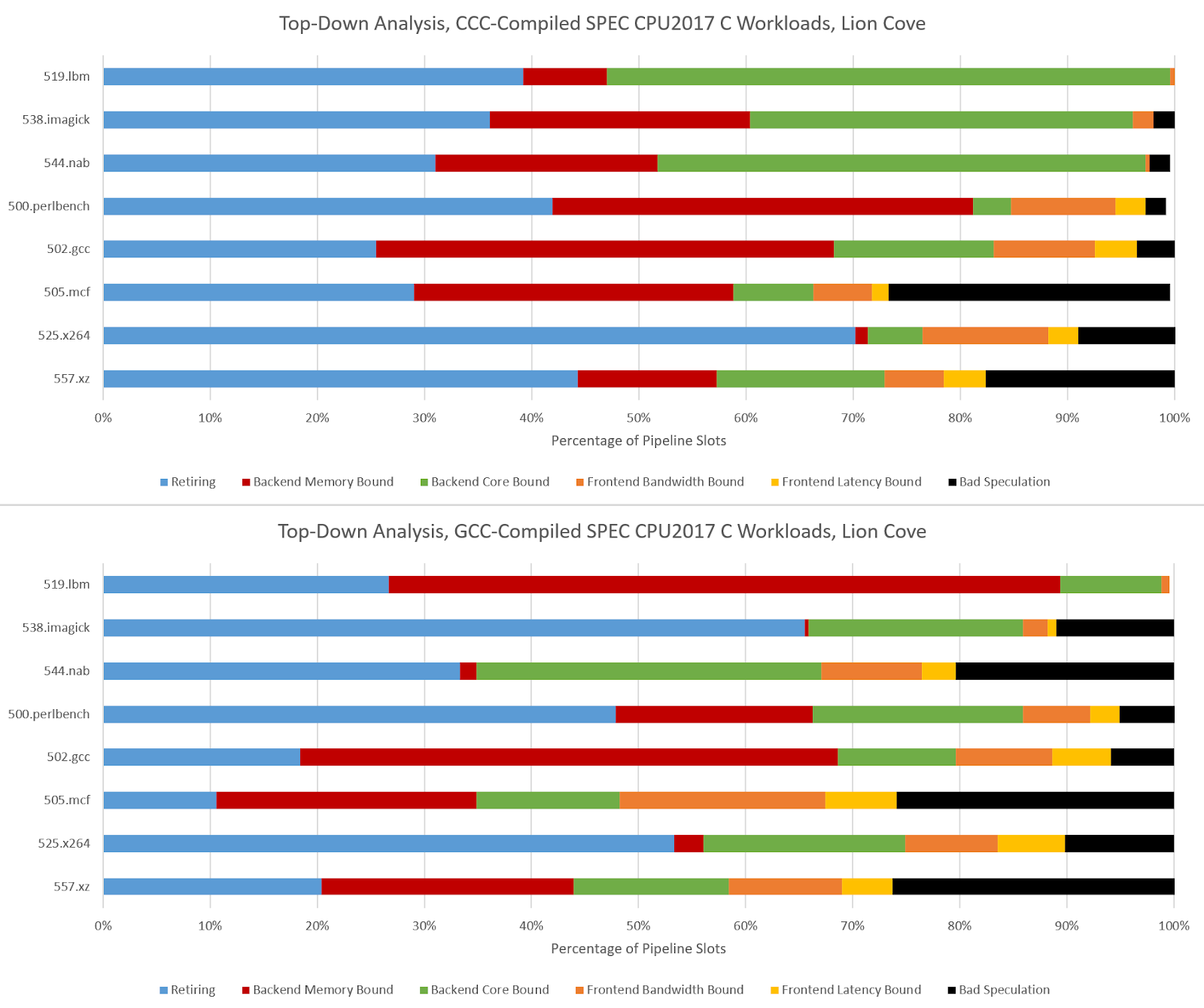
Arm’s Cortex X925 is very core-bound when running CCC code, and not just in the three FP workloads. I’m distinguishing between core and memory bound backend bound slots by looking at the proportion of backend bound cycles covered by the STALL_BACKEND_MEMBOUND event, which counts when there’s a backend stall and the “backend interface to memory is busy or stalled”.
I partially attribute the core-bound slot increase to Cortex X925 not having the robust move elimination and zero-latency store forwarding that Lion Cove and Zen 5 do. Long chains of register-to-register MOVs or frequent trips through the stack are rare in typical code. As evidence, Intel's Ice Lake only took a 1-3% performance loss with move elimination disabled. Move elimination therefore acts as a cherry on top in most applications, with most performance coming from out-of-order execution basics and an efficient cache hierarchy to feed the core. Of course, that changes with CCC.
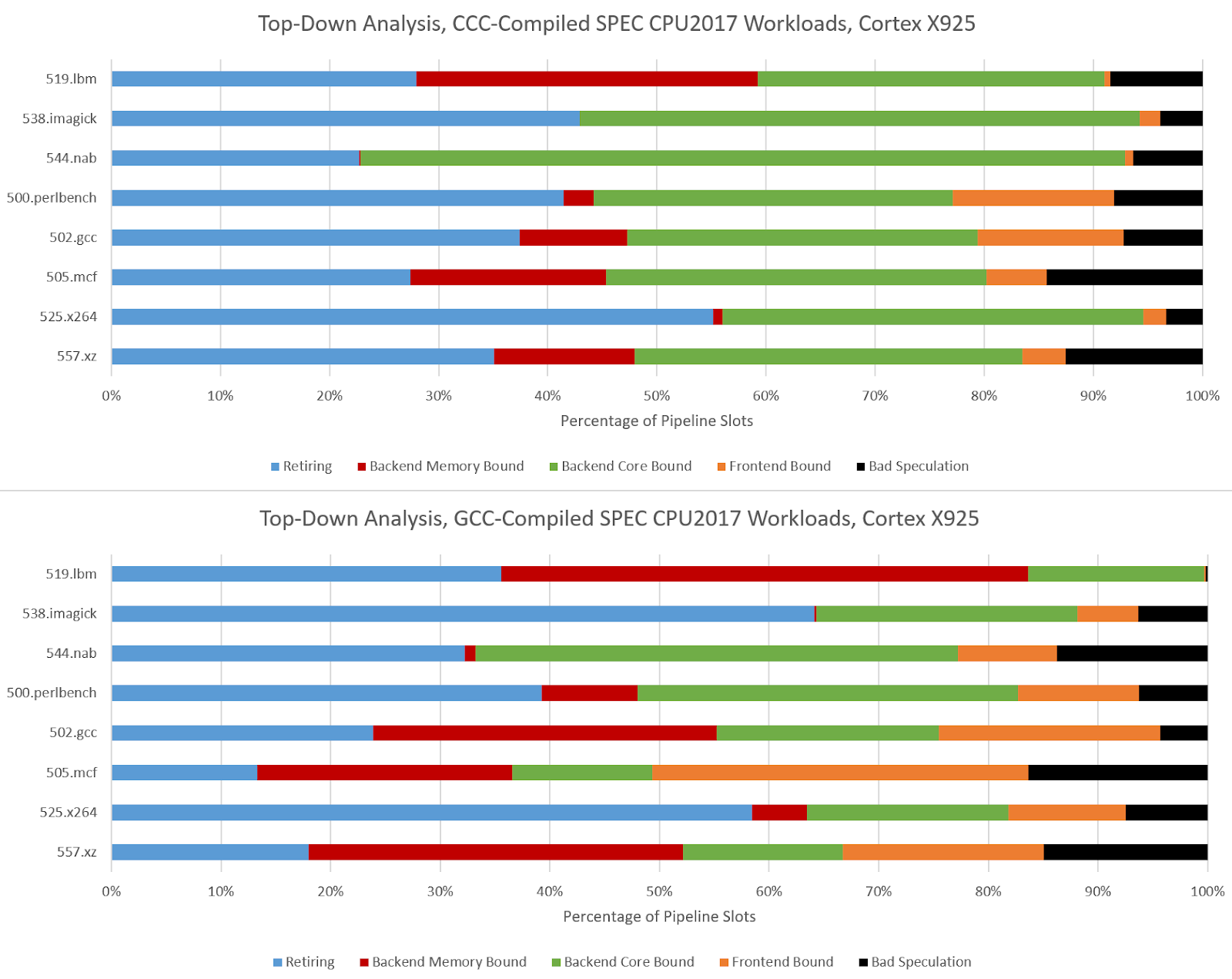
519.lbm’s large increase in backend memory bound slots looks related to store forwarding latency. A hot section in CCC-compiled 519.lbm repeatedly spills register x0 to the stack, only to reload it several instructions later, making sure the memory system contributes to all phases of code execution. Store forwarding latency forms part of a long dependency chain, and X925 can’t do zero-latency forwarding the way Zen 5 and Lion Cove can.

Final Words
Compilers are crucial to modern software development, and performance of compiled code is key to making high level languages practical. Switching to CCC causes a 70%+ performance degradation across C-only SPEC CPU2017 workloads. Most consumers will readily accept this, because a fast core like Intel’s Lion Cove still does well when running CCC code. As evidence, AMD’s Bulldozer architecture fascinated enthusiasts about 15 years ago. Bulldozer is 36.8% faster than Lion Cove, the fastest CPU tested here for running CCC code. Simply overclocking Lion Cove to 8 GHz could close much of the performance gap.
Of course, some provocateurs may only reach 7.5 GHz, undoubtedly due to a combination of personal skill issues and insufficient enthusiasm for the AI revolution. Severe agitators may theorize that Bulldozer’s level of single threaded performance is not top-notch in some scenarios, and demand ever more performance. To prevent these people from discrediting the revolution, the stock performance problem must be addressed.
Performance problems can be addressed from either hardware or software, because hardware and software optimization go hand-in-hand. Well optimized software performs well across a wide variety of hardware. Likewise, well designed hardware delivers good performance across a wide range of software. CCC-generated code dramatically shifts what software demands from hardware, upsetting the existing social contract between software and hardware. Faulting the software side would undermine the crowning achievements of the AI revolution. Therefore, hardware must boldly tackle the performance question.
Completely addressing the performance gap would be easy by my estimate. With 20-30 GHz clock speeds and several generations worth of architectural improvements, CCC code could reach the performance achieved by GCC-compiled binaries on current generation hardware. These targets might have been dismissed in the past. But they’re achievable now because the AI revolution isn’t just any revolution. Rather, it is a cultural revolution that upends views regarding power consumption. Infinite power can make many previously unthinkable designs a reality. Some hardware designers may see red flags in this approach and persistently complain. But proper hardware engineers will rally around those flags and chant slogans. By correctly following the path of the revolution, they’ll be sure to succeed and may even exceed their quotas. May the odds be ever in their favor.
Footnotes
* The proof is trivial and similar to the proof for the gambler’s law (99% of gamblers quit just before they win big)
If it's an April Fools' Day article, then it's the best I have ever seen :-)
This is the best, most committed April Fools joke I have ever seen