
Digging into Driver Overhead on Intel's B580

Hardware Canucks recently found that Intel's new B580 GPU suffered when paired with older, weaker CPUs. When paired with the Ryzen 7 9800X3D, the B580 could compete against Nvidia's RTX 4060. But with the i5-9600K, the B580 falls significantly behind its Nvidia competition. Hardware Canucks pointed to Intel's drivers as a distinct culprit, and hypothesized that Intel punted optimizations for legacy platforms.
I can’t tell how Intel’s management prioritized different driver features behind the scenes. But Windows does offer tools that can provide insight into how graphics APIs like DirectX or Vulkan get handled behind the scenes. On the application side, 3DMark has an API overhead test that sends off huge numbers of simple draw calls. Futuremark has deprecated that test, saying developers today “are more likely to choose a graphics API based on feature support and compatibility”, and “draw call performance is no longer the deciding factor.” While that may be true, the API overhead test should exaggerate software-side bottlenecks and is an interesting target for analysis.

In 3DMark’s API overhead test, Intel does suffer heavily. I’m testing both cards in the same system and have Core Performance Boost disabled to reduce clock speed fluctuations. CPU performance therefore shouldn’t be a factor. For completeness, the system configuration is as follows:

3DMark’s API Overhead test increases draw call count until framerate dips below 30 FPS. I captured Xperf traces for the tail end of each test run, which lets me focus on frames with the highest number of draw calls and keeps trace file size down.
Driver Overview
Graphics drivers consist of both user-mode and kernel-mode components. The graphics API runtime, whether that be DirectX or Vulkan, loads the user-mode driver (UMD). That executes its code in user-mode, where any failure can be contained to the application’s process. for Intel, I saw the following UMD’s within 3DMarkAPIOverhead.exe’s call stack:

Intel’s kernel mode driver is igdkmdnd64.sys, which describes itself as the “Intel Graphics Kernel Mode New Driver.” It’s probably “new” because Intel has separate drivers for its newer graphics architectures and its older integrated graphics.

For AMD, I observed the following user-mode driver components:

AMD’s kernel mode driver is amdkmdag.sys, and is simply described as the “ATI Radeon Kernel Mode Driver”. The kernel driver handles communication with the GPU hardware, unlike the user mode driver that has to deal with API differences.

Driver CPU Usage, vs Application
Here, I’m looking at the CPU time spent in the respective kernel mode and user mode driver modules, as well as CPU time spent in 3DMarkAPIOverhead.exe (the application). Both AMD and Intel’s user mode driver components do significant processing. That’s both expected and a good thing. UMDs aim to keep much of the complexity out of the kernel mode driver. You really don’t want anything to go wrong in kernel mode.

Intel spends more CPU time in both the user and kernel mode driver components than AMD does. Vulkan mode shows the most extreme difference, which aligns with 3DMark’s API overhead run results.

To be clear, this is a simplistic way of looking at driver processing cost because it excludes time spent calling into DirectX APIs. For example, Intel’s user-mode DirectX 11 driver eventually calls Lock2CB in d3d11.dll, which locks an allocation in memory and returns its virtual address. Intel’s engineers would have to dig into details like this when working out where they can improve performance. But I’m going to stay at a high level overview here.
The kernel driver defines Interrupt Service Routines (ISRs) that handle interrupts from hardware. Generally ISRs run with interrupts disabled, letting driver code run without interference. ISRs need to be fast to avoid excessively delaying other interrupts, so drivers often offload heavier processing to Deferred Procedure Calls (DPCs).
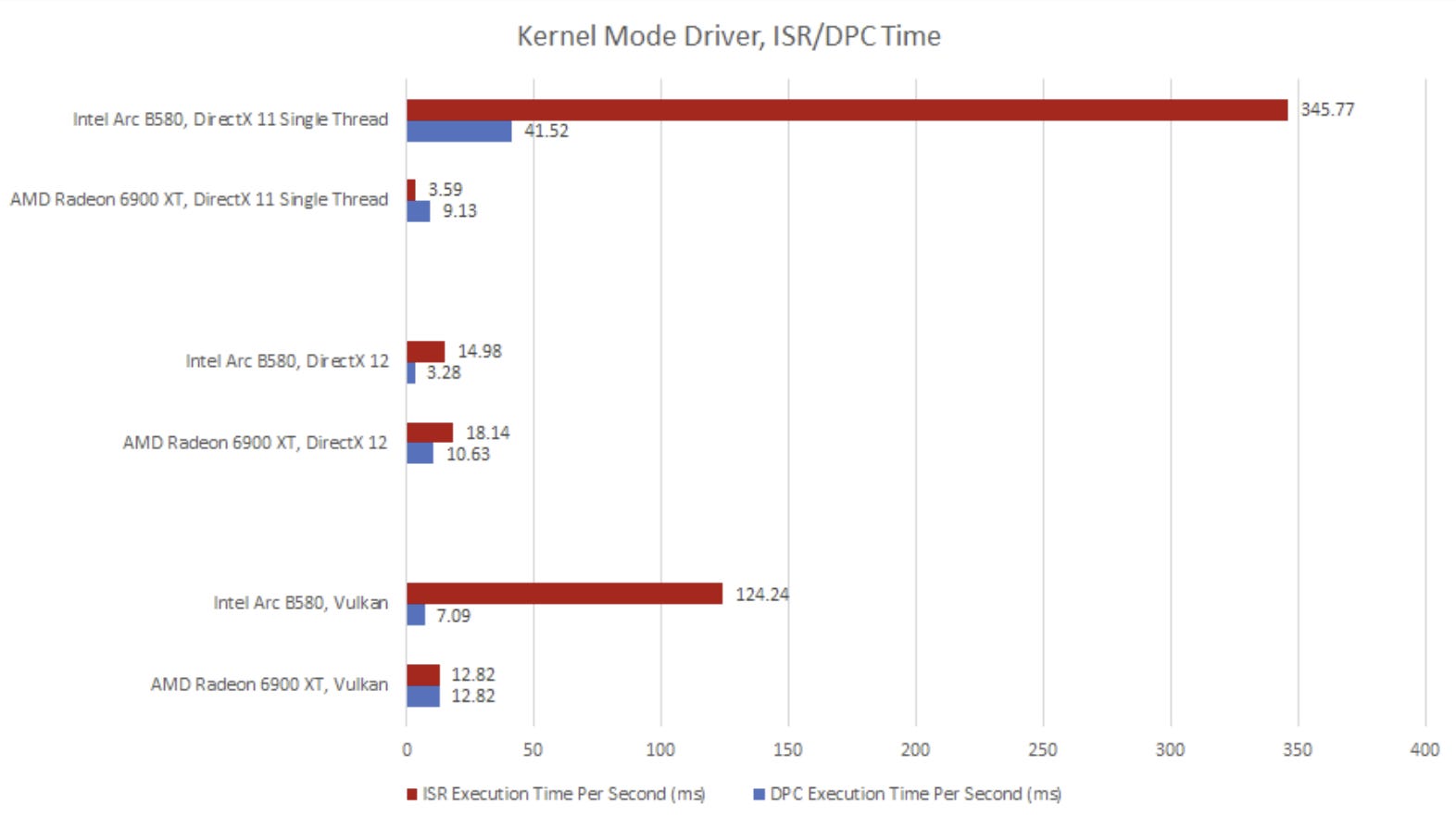
AMD and Intel both use DPCs to reduce ISR execution time. Intel spends significantly more time running ISRs than AMD does in DirectX11 and Vulkan mode. In DirectX 12, Intel’s driver does well.
DirectX 11
GPUView provides a look into how application-side API calls make their way to GPU hardware queues. On the Arc B580, 3DMark’s API Overhead test ends up creating a lot of workitems on its CPU-side queue. Very often, there’s at least 3-4 pending queue packets sitting on the 3DMarkAPIOverhead.exe’s device context. These end up as DMA packets on the hardware queue, which I assume the kernel mode driver then chucks over to the GPU.

Capturing a trace for AMD’s RX 6900XT shows a drastically different picture. CPU-side work shows up as one submission per frame. AMD further uses smaller DMA packets, which always seem to be 64 bytes in size. Each of these DMA packets points to 9.25 MB of separately allocated memory, which appears to be a 1920×1080 texture with 8-bit RGBA components. For comparison, Intel uses larger DMA packets around 4 KB in size, and don’t reference other allocations.

AMD sends work to the GPU queue almost immediately, because work created on the application’s CPU-side queue lines up well with corresponding work on the GPU’s 3D queue. On Intel, it’s often deferred by a few milliseconds. This could be an attempt at batching, but more likely is because something in the software stack presents a bottleneck.

Arc B580 often has paging packets pop up on its copy queue across most frames. These transfer larger blocks of data between the CPU and GPU. Sometimes it’s 64 KB, and sometimes it’s 576 KB. Each paging packet’s operation is “Transfer Mdl to Memory”. MDL stands for Memory Descriptor List, and describes how a contiguous virtual address corresponds to pages in physical memory. Likely, Intel’s trying to get data generated by the application to the GPU, and needs buffers to be contiguous in physical address space.
I didn’t see any paging packets pop up on the RX 6900XT’s copy queue. AMD may be transferring data with another mechanism, like giving the GPU pointers to host memory.
As a starting point, I feel like the following guesses are reasonable for DirectX 11:
Intel’s user-mode driver doesn’t batch draw calls as aggressively as AMD. Each frame then involves dozens of queue packets on Intel, while AMD uses a single queue packet
Intel’s driver may be taking overhead from copying data to the GPU.
DirectX 12
DirectX 12 has been gaining wider adoption in recent games. With DirectX 12, GPUView now shows a lot of similarity between AMD and Intel. Each frame involves multiple DMA packets, and the copy queue is quiet.
On the Arc B580, a single frame toward the worst part of the 3DMark API Overhead test sees approximately eight DMA packets on the hardware queue, each of which corresponds to a software command. Intel’s DMA packets are small, at 72 bytes, and sometimes reference separate allocations. The 14.1 MB allocation in this case also appears to be a texture.

Curiously, DMA packets with associated allocations take significantly longer to execute. I can’t tell what work each packet represents, but it’s an interesting pattern and leads to a bimodal distribution of packet execution times.
AMD by comparison throws a ton of DMA packets onto the 3D hardware queue. Where Intel uses eight or so packets, AMD uses over 100. Raw packet count however exaggerates the difference because work per frame is not equal across the two GPUs. 3DMark’s API Overhead test works by increasing draw call count until it can’t maintain 30 FPS. AMD handles draw calls nearly 5x faster than Intel, so each frame captured here will have significantly more draw calls on AMD.

As with DirectX 11, AMD’s DMA packets are 64 bytes in size. Individual packets execute very quickly on AMD, though again there’s a bimodal distribution for packet execution times. The same work that takes longer on B580 also takes longer on the 6900XT. However, the 6900XT gets through that presumably more difficult work in about 2.5x more time. Intel’s B580 sees nearly a 10x execution time difference.
On the application’s CPU-side queue for the device context, AMD appears to have a lot of parallelism. Red rectangles represent synchronization fences, and dark rectangles represent actual work. AMD’s driver lets these work packets stack up very high on the CPU-side queue, before draining them into the GPU’s 3D queue. Neither driver lets more than a couple packets stack up on the 3D queue at a time. On Intel, the CPU-side queue doesn’t have nearly as many pending work packets. However, the 3D queue on B580 often has three packets waiting in line, as opposed to 2 on AMD.
For DirectX 12, I wonder if both GPUs are bottlenecked by how fast the GPU-side command processor can blast its way through queue submissions. Both the RX 6900 XT and B580 almost always have work queued up on the 3D queue. Batching strategies may be a bit different, but GPUView makes it look like 3DMark’s API Overhead test is getting GPU-bound rather than being limited by driver components.
Vulkan
Vulkan is another graphics API, and grew out of AMD’s Mantle effort. Several games like Valheim and Doom Eternal support Vulkan.
On B580, a single frame has about 50 DMA packets. Much like in DirectX 11 mode, Intel’s DMA packets are around 4 KB in size and don’t reference allocations. Like DX12 mode, packet execution time almost follows a bimodal distribution. A lot of 4092 byte packets execute in well under a millisecond, while some 4072 byte ones take just over a millisecond. In both cases, the B580 consumes commands off the 3D queue pretty darn quickly.

Intel now uses a strategy very similar to what AMD did with DirectX 12. The driver lets a lot of small packets stack up on the application’s CPU-side queue, then drains those packets and creates corresponding work on the 3D queue. As before, Intel generally has 3 packets waiting in line on the 3D queue.
Curiously, flip commands on the B580 are attributed to dwm.exe (Desktop Window Manager) rather than 3DMarkAPIOverhead.exe. DWM queues up a command packet to make those flips happen. In contrast, AMD handles flips without DWM doing anything.

On AMD, a single frame also has about 55 DMA packets. However, each DMA packet likely corresponds to more draw calls because the 6900XT’s throughput is so much higher, and 3DMark scales draw call count until framerate can’t stay above 30 FPS. Again, all the AMD DMA packets that I checked were 64 bytes in size.

AMD’s strategy looks very similar to what it did with DirectX 12. A lot of work gets queued up on the application side. It gets drained to the 3D queue, with 3D queue occupancy generally staying 2-high. Then, the GPU blasts through those DMA packets with incredible speed. Even the longer running packets execute in under half a millisecond.
Final Words
Driver development is difficult, and I imagine GPU drivers are among the most difficult to optimize and validate. From this brief look, I can’t attribute Intel’s driver overhead to any single cause. Likely, it comes down to a combination of Intel doing more processing in the driver, and the B580 being less efficient at processing certain types of commands. I can’t conclude anything with certainty, but I hope the data above is interesting.
For their part, Intel’s engineers will have their hands full looking at how they can improve driver performance. It’s a complex task, because there’s so many places to look. They could start at looking at where the driver spends its CPU time, and evaluate whether they can simplify processing. They could also look at how the driver is managing work submissions to the GPU, and whether doing batching/DMA packet submissions differently would help.
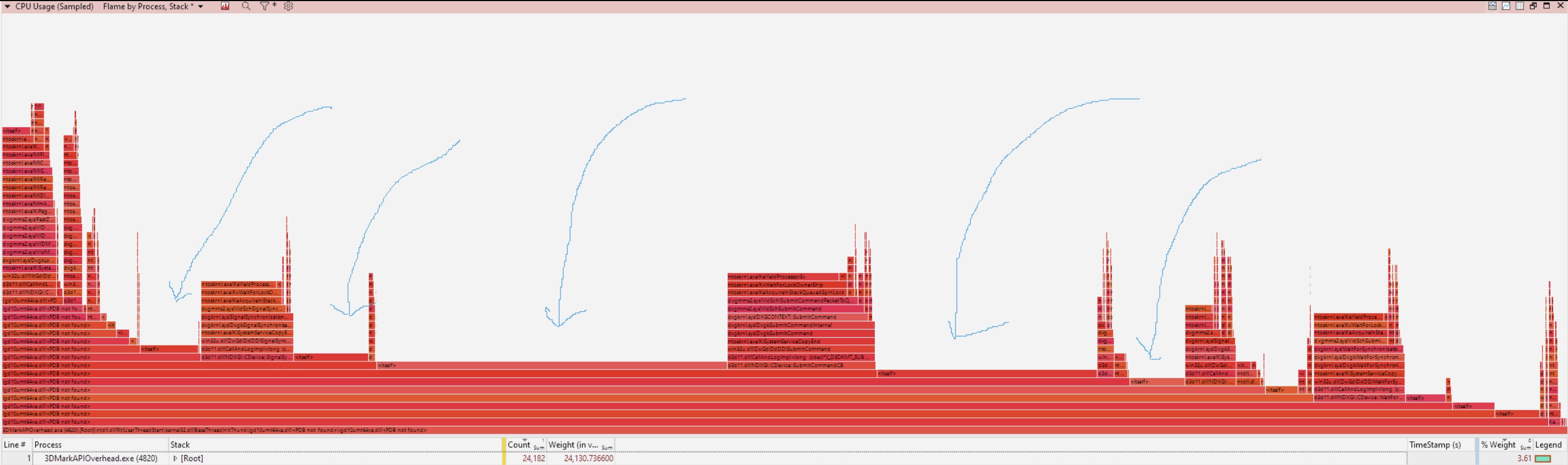
They could also look at how the driver is calling into Windows components. For example, some calls into d3d11.dll spend most of their time waiting for spin lock acquisition. AMD interestingly doesn’t need to do the same, so there may be optimization opportunity there.

I wish Intel's developers the best of luck as they dig through the driver and look for optimization opportunities. Intel's journey to move into higher performance graphics is also worth discussing. Intel has decades of experience writing graphics drivers, but much of that focused on low end iGPUs. Those iGPUs have low framerate targets, and CPU-side bottlenecks often surface at high framerates. Perhaps more importantly, moving data between CPU and GPU memory spaces is cheaper on iGPUs than discrete GPUs. AMD and Nvidia have decades of experience writing discrete GPU drivers, optimizing both for high framerates and slower PCIe communication. Their GPUs tend to handle well on lower end systems, and don't excessively rely on PCIe Resizeable BAR to achieve high performance.

Therefore, I think it's unlikely Intel's developers or management deliberately deferred optimization for legacy platforms. Rather, Intel is still a new player on the high performance GPU scene. It's a game that plays by different rules compared to relatively low performance integrated GPUs. Learning how to play optimally within that new ruleset is an arduous process.
Stepping back, I find Intel’s Arc B580 to be a refreshing and exciting product. The midrange GPU market has been an unattractive dumpster fire over the past few years. With a powerful enough CPU, the B580 can offer competitive performance against the more expensive RTX 4060 while providing more VRAM capacity to boot. It’s a compelling combination, and I hope Intel can optimize its driver going forward. The less money gamers have to spend on hardware to get acceptable performance, the better. That applies to both CPU and GPU upgrades.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
Very well written! Hopefully, these insights are allowed past the marketing department, managers, and other bureaucratic mechanisms that "protect" the developers. Hopefully, the driver team has enough bandwidth to address this, compared to working on new features, new hardware, or fixing other bugs.
Some of the issues you can see in the graphs indicate architectural issues, such as batching strategy and DMA chunk sizes. Other things could be hardware choices, such implementing less of the DMA mastering on the GPU side (i.e., using Windows paging to transfer data to the GPU instead of sending a physical address to the GPU DMA engine).
We can always speculate on the thoughts behind the implementation, but the results clearly show room for improvement. In the mean time, great job on creating something that is close the ideal bug report: specific, data-driven, repeatable, and fully described.
That ISR/DPC graph is crazy. Spending 1/3 of a CPU-second in ISRs for every 1 second of wall clock time running a single threaded DX11 application is insane. Even if they moved that into a DPC, that's still going to be disruptive to other latency-sensitive applications on the system. I'd be curious to know how evenly distributed they are across CPUs and whether it's a lot of short ISRs or a few long ones that add up.
It's unlikely that it's contributing significantly to the poor 3DMark API Overhead test results at these kind of frame rates, but it's certainly interesting that Intel can't seem to do Independent Flip on Vulkan swapchains. Having to context switch to DWM to present each frame isn't free and almost certainly is costing them significant performance in very high frame rate Vulkan applications. Nvidia's driver can also directly present Vulkan swapchains like you saw on the AMD test.