
d-Matrix Corsair: 256GB of LPDDR for AI Models
With Microscaling Number Formats to boot!

Hello you fine Internet folks,
Today is the last of our Supercomputing 2024 coverage, but last does not mean least. Today we are going to be covering a new AI startup company called d-Matrix. d-Matrix first product is called the Corsair and it uses the Microscaling formats from the Open Compute Project with the Microscaling formats being adopted by Nvidia in the Blackwell series of GPUs as well as in Microsoft’s MAIA 100 AI chip.
Looking at the chip itself, it’s very remeniscent of AMD’s Naples series of CPUs with 4 identical rectangular dies on a package. However that is where the similarities between Naples and Corsair end.

Where Naples is a general purpose CPU meant to do all sorts of computing, Corsair is strictly for Machine Learning and Low-Precision Computing.
The basic building block of the d-Matrix architecture is the Digital In-Memory Compute (DIMC) core. The DIMC core integrates a multiplier into a memory bit cell which reduces latency and the energy cost of access memory since you don’t need to move the data anywhere because your multiplier in already in your memory.
The Corsair chip supports the OCP Microscaling, also known as Block Floating Point, formats; MXINT16, MXINT8, and MXINT4.
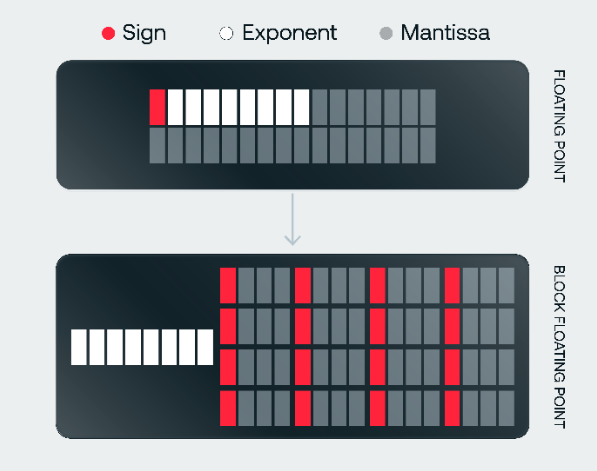
These are a new type of data format where a “block” of numbers share the same exponent which reduces the amount of data needed to compute, move, and store. This not only increases the energy efficiency of the MX formats but also it allows for similar accuracy to floating point numbers such as FP16.
A single Corsair package has 4.8 Petaflops of MXINT4, 1.2 Petaflops of MXINT8, and 300 Teraflops of MXINT16 with each Corsair card having 2 Corsair packages for a total of 9.6 Petaflops of MXINT4, 2.4 Petaflops of MXINT8, and 600 Teraflops of MXINT16 per card.
However, in order to maximize the amount of MX compute, Corsair does not support any IEEE 754 Floating Point numbers such as FP64, FP32, or even FP16 nor does it support popular lower-precision data types such as BF16 or TF32.
Moving out to memory, there are 2 modes that you can run the Corsair system in. The first mode is very similar to Groq’s approach where the models are stored in the 1GB of SRAM that each Corsair package has for a combined 2GB of SRAM. This means that using the MXINT8 format 8 Corsair cards can fit a Llama3-8B model.
However, if you are willing to take a performance hit, the second mode allows you to access the LPDDR5 pool on the Corsair card which is 128GB of LPDDR5 at 200GB/s per Corsair Package for a total of 256GB of LPDDR5 at 400GB/s per Corsair card. This allows a single Corsair card to be able to fit 2 Llama3-70B models at the MXINT8 precision which makes a single Corsair card quite a compelling card for inference work.
Hope y’all enjoy!
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord and subscribing to the Chips and Cheese Youtube channel.
Happy about the simple, instructive schema of block floating point - which also makes it clear that it is not saving in every single possible case.
I am curious to see these block floating point formats being implemented by different vendors: I see an ominous "MX9" among others for AMD Versal, and on Strix Point they say they have some accelerated block floating point computations available, but the one somewhat pragmatic presentation I could find ("Leveraging the Iron AI Engine ...") only mentions int and bfloat16, and that one I assume is google's bfloat16, not block float.