
Analyzing Nvidia GB10's GPU
Looking at Nvidia's latest effort to make a big iGPU

GB10’s integrated GPU is its headline feature, to the extent that GB10 can be seen as a vehicle for delivering Nvidia’s Blackwell architecture in an integrated implementation. The iGPU features 48 Streaming Multiprocessors running at up to 2.55 GHz, meaning it’s basically a RTX 5070 integrated. The RTX 5070 still has an advantage thanks to a higher power budget, more cache, and more memory bandwidth. Still, GB10 undeniably has a powerful iGPU, much like AMD’s Strix Halo.

Unlike AMD’s Strix Halo, Nvidia’s GB10 focuses on AI applications. Nvidia’s proprietary CUDA ecosystem is key, because CUDA is nearly the only name in the GPU compute game. GPU compute applications are optimized first and foremost for CUDA and Nvidia GPUs. Everything else is an afterthought, if a thought at all.Combining significant GPU compute power with iGPU advantages and CUDA support gives GB10 a lot of potential. Of course, hardware has to deliver high performance for those ecosystem advantages to show. Achieving high performance involves building a balanced memory hierarchy, as well as tailoring hardware architecture to do well in targeted applications.
Cache and Memory Access
GB10’s GPU-side memory subsystem brings few surprises. It’s basically a Blackwell GPU integrated, with a familiar two-level caching setup. The L2 serves as both a high capacity last level cache and the first stop for L1 misses. AMD in contrast uses more cache levels and gradually increasing cache capacity at each level, which mirrors their discrete GPUs too. In a cache and memory latency test, GB10 and Strix Halo trade blows depending on test size. Larger caches are hard to optimize for high performance, so AMD wins when it’s able to hit in its smaller 256 KB L1 or 2 MB L2 compared to Nvidia’s higher latency 24 MB L2. Nvidia wins when GB10 can keep accesses within L2 while AMD has to service them out of Strix Halo’s 32 MB memory side cache. Both Strix Halo and GB10 use LPDDR5X memory. Strix Halo’s iGPU enjoys better latency to LPDDR5X than Nvidia’s GB10, reversing the situation seen on the CPU side.
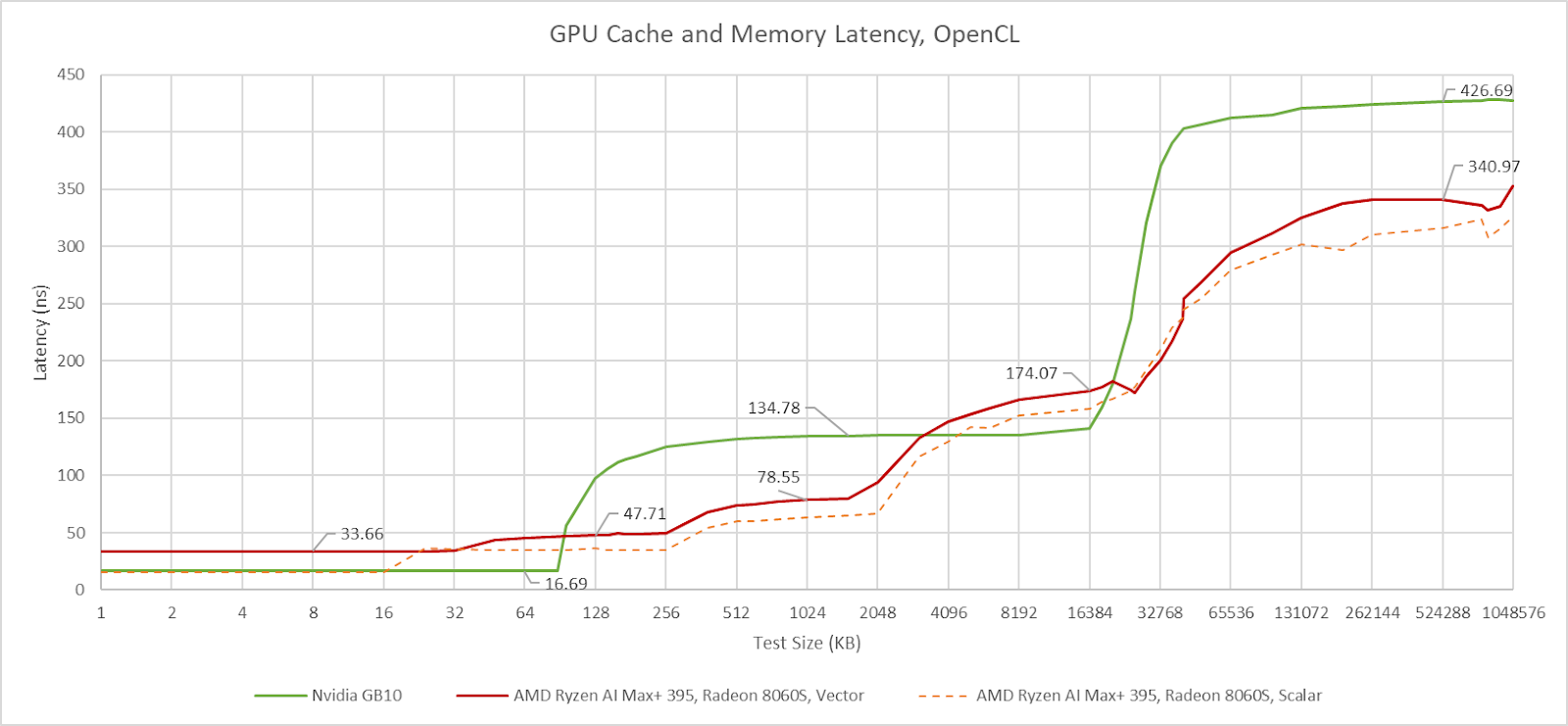
Nvidia’s L1 cache offers an impressive combination of low latency and high capacity. With dependent array accesses, it can return data nearly as fast as AMD’s 16 KB scalar cache while offering more capacity than AMD’s first level scalar and vector caches combined. However, dependent array accesses don’t tell the whole story. Pointer dereferences indicate that AMD takes a lot of overhead from array addressing calculations. Cutting that out shows that RDNA3.5’s scalar cache offers very low latency. Nvidia already had efficient array address generation, so switching to pointer dereferences makes less of a difference on GB10. Regardless of access method, GB10’s L1 offers higher capacity and lower latency than RDNA3.5’s L0 vector cache.

GB10’s system level cache is invisible in the latency plot above because it’s smaller than the GPU’s 24 MB L2. It also doesn’t seem to maintain a mostly exclusive relationship with the GPU L2, so its capacity isn’t additive on top of the L2. Nvidia’s slides say the SLC aims to enable "power efficient data-sharing between engines", implying that feeding compute isn't its primary purpose.
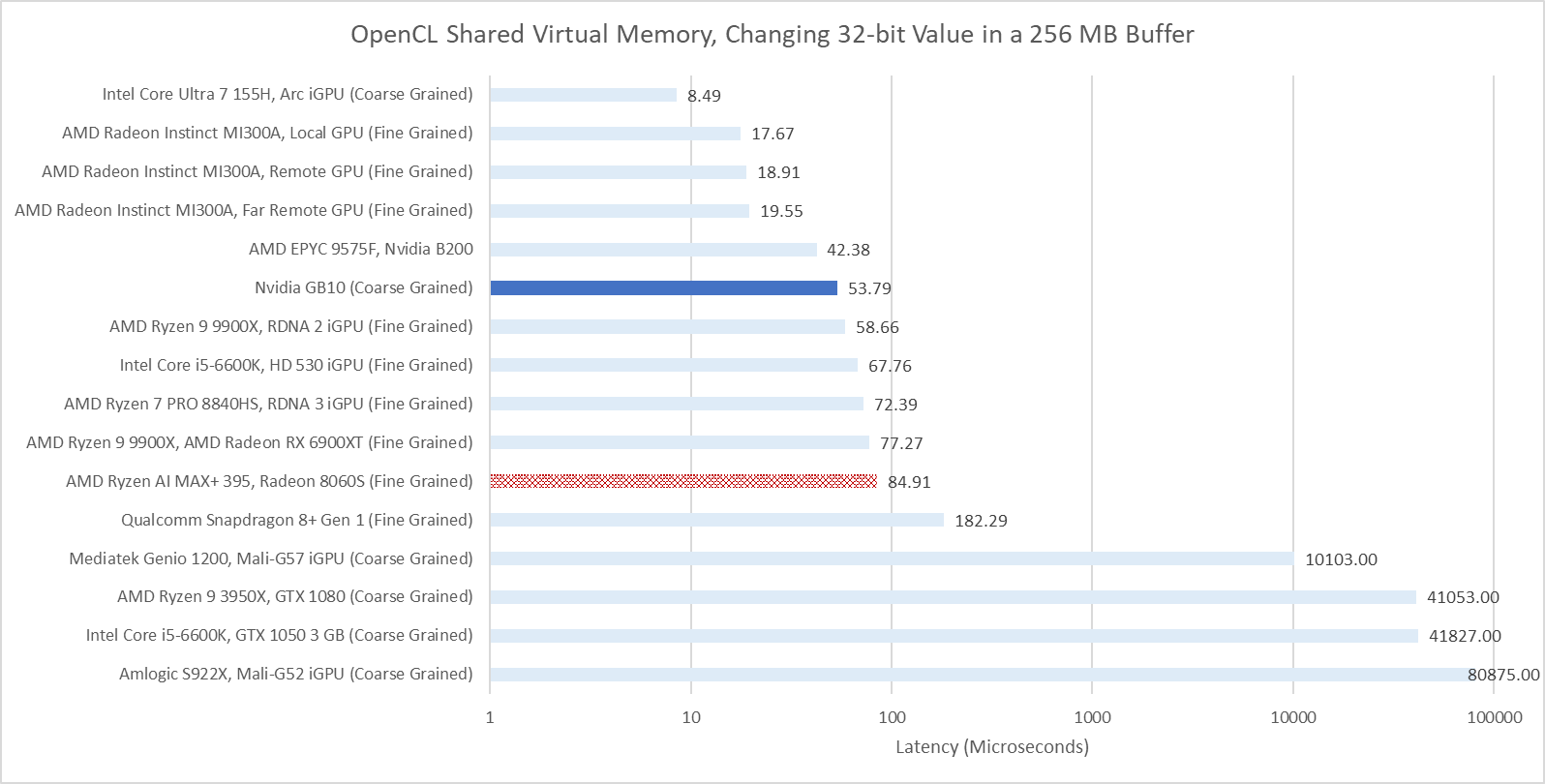
Like many modern GPUs, GB10 supports OpenCL’s Shared Virtual Memory (SVM) feature. SVM allows seamless pointer sharing by mapping a buffer into the same virtual address space on both the CPU and GPU. GB10 supports “coarse grained” SVM, meaning the buffer cannot be simultaneously mapped on both the CPU and GPU. Some GPUs with only coarse grained SVM appear to copy the entire buffer under the hood, as can be seen with Qualcomm and Arm iGPUs. Thankfully, GB10 can handle this feature without requiring a full buffer copy under the hood.
Compared to Strix Halo, GB10’s memory subsystem strategy moves high capacity caching up a level. Strix Halo’s “Infinity Cache” setup was awkward because it placed a GPU-focused cache at the other end of a system level interconnect. That places high pressure on Infinity Fabric, which AMD built to handle nearly 1 TB/s of bandwidth. GB10 in contrast uses the 24 MB graphics L2 to filter out a large portion of GPU memory traffic, so the system level interconnect primarily deals with DRAM accesses. That said, using 16 MB of cache just to optimize data sharing feels awkward too. SRAM is one of the biggest area consumers in modern chips because of how far compute has outpaced DRAM performance. A hypothetical setup that concentrates last level caching capacity in the SLC could be more area efficient, and could boost CPU performance.
Bandwidth Measurements
48 SMs mean 48 L1 cache instances, giving GB10’s iGPU impressive cache hit bandwidth. With Nemes’s Vulkan based benchmark, GB10 easily outpaces Strix Halo. Strix Halo’s iGPU can achieve around 10 TB/s using a narrowly targeted OpenCL kernel that can’t work with arbitrary test sizes, but GB10 is still ahead even with that methodology. Nvidia’s advantage continues at L2, which offers both higher bandwidth and higher capacity than AMD’s 2 MB L2. Needless to say, Nvidia’s L2 continues to compare well as test sizes increase and Strix Halo has to use its 32 MB Infinity Cache. Finally, both iGPUs achieve similar bandwidth from system memory, with GB10 taking a slight lead with faster LPDDR5X.
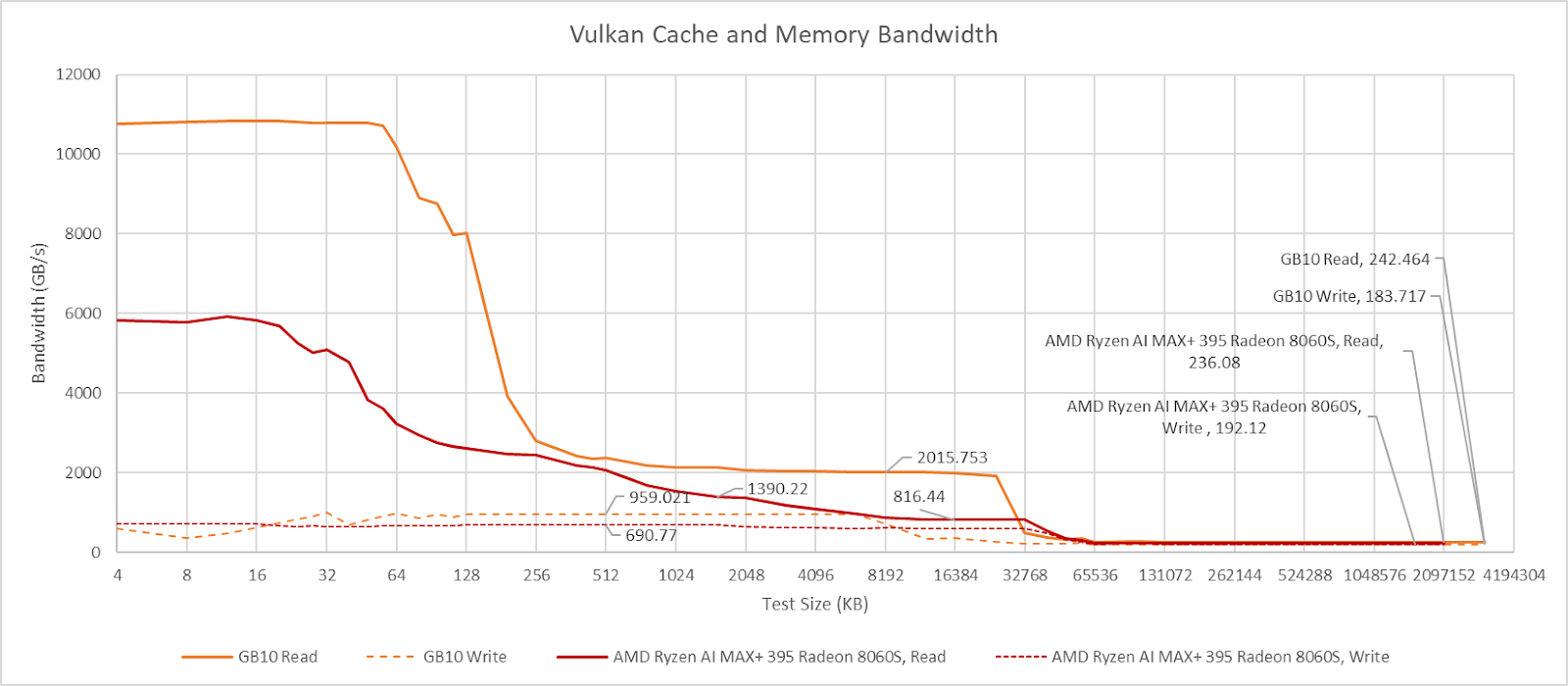
Both GPUs use write-through L1 caches, so writes from compute kernels go straight to L2. GB10’s L2 handles writes at half rate, and provides just under 1 TB/s of write bandwidth. Write bandwidth on Strix Halo is somewhat lower at approximately 700 GB/s. Write behavior on both iGPUs is similar to that of larger discrete GPUs.
L1 and Shared Memory Capacity
Nvidia’s GPUs use a single block of SM-private memory for both L1 cache and Shared Memory. Shared Memory is a software managed scratchpad private to a group of threads. It fills an analogous role to AMD’s Local Data Share (LDS), letting code explicitly keep data close to compute when data movement is predictable. A larger L1/Shared Memory block can let each group of threads use more scratchpad space with lower impact to occupancy or L1 cache capacity. Nvidia’s datacenter GPUs get 256 KB of L1/Shared Memory per SM. GB10 does not.
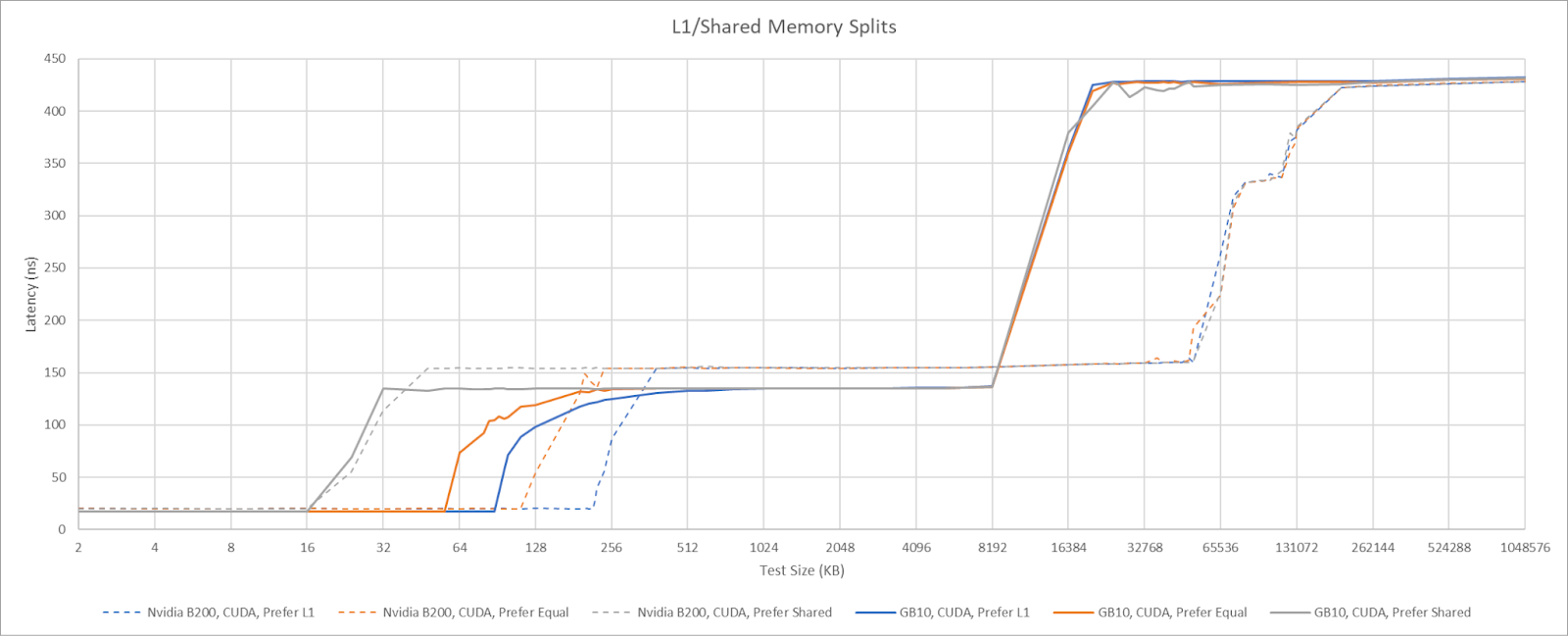
Instead, GB10 behaves much like Nvidia’s consumer Blackwell architecture and has 128 KB of L1/Shared Memory. In exchange for lower L1/Shared Memory capacity, GB10 achieves 13 ns of latency in Shared Memory using dependent array accesses. That’s slightly better than 14.84 ns for B200.
Instruction Caching
Instruction fetch behaves as expected for any Blackwell GPU. Each SM sub-partition has a 32 KB L0 instruction cache, which can fully feed a partition’s maximum throughput of one instruction per cycle. Blackwell uses fixed length 16-byte instructions, so the A 128 KB L1 instruction cache feeds all four partitions, and can also deliver one instruction per cycle. Bandwidth from the L1I is shared by all four partitions, and per-partition throughput drops to 0.5 IPC when two partitions contend for L1I access. GPU shader programs are typically small and simple compared to CPU programs, so I suspect most code fetches will hit in the 32 KB L0 instruction caches.
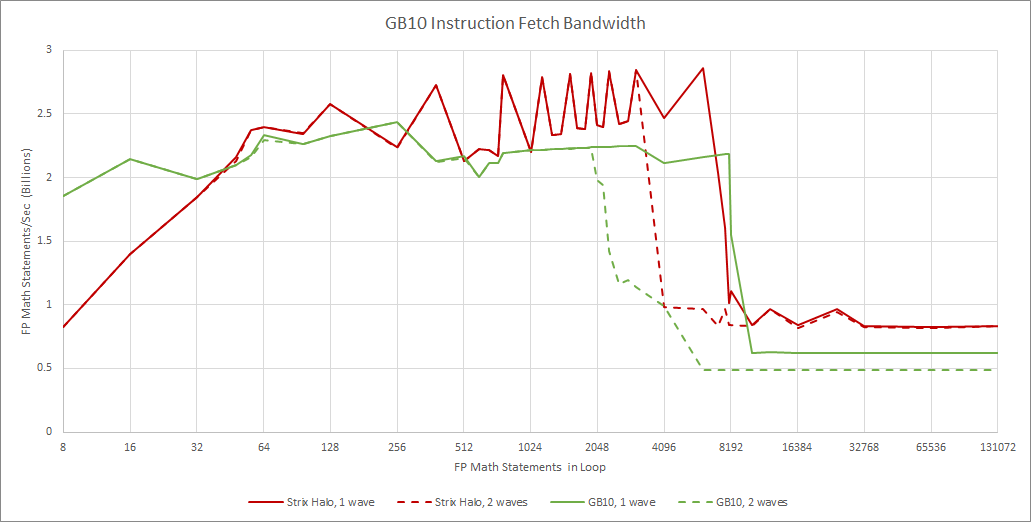
RDNA3.5 Workgroup Processors use a simpler instruction caching strategy, with one 32 KB instruction cache servicing four SIMDs. Bringing a second wave into play does not cause bandwidth contention at the L1I, though two waves executing different code sections do contend for L1I capacity. Running code from L2 leads to poor instruction throughput on both architectures.
Compute Performance
If Strix Halo had high compute throughput for an integrated GPU, GB10 takes things a step further. Strix Halo’s iGPU has 20 Workgroup Processors (WGPs) to GB10’s 48 SMs. These basic building blocks are the closest analogy to cores on a CPU. RDNA3.5 WGPs do have doubled execution units for basic operations and higher clocks. But even in the best case, Strix Halo’s iGPU lands a bit behind GB10’s.
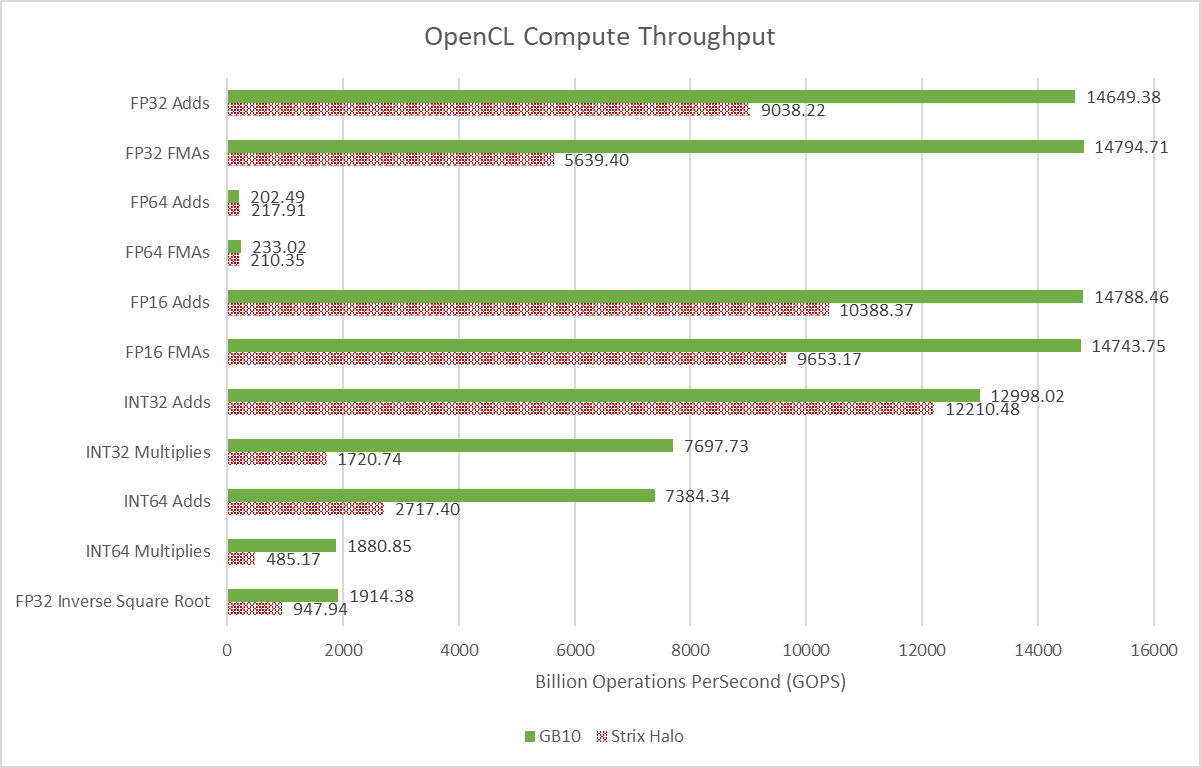
Both GPUs have low FP64 throughput, another characteristic that sets them apart from datacenter ones. GB10 has a 1:64 FP64 to FP32 ratio, while Strix Halo has a 1:32 ratio.
Which Blackwell?
Nvidia’s GB10 presentation at Hot Chips 2025 started by talking about scaling their Blackwell architecture from server racks, to single GB300 GPUs, to the GB10 chip in DGX Spark. GB300, like B200, uses Nvidia’s B100 datacenter Blackwell architecture. The datacenter distinction is important. Ever since Pascal, Nvidia’s datacenter and consumer GPU architectures look quite different even when they use the same name. Cache setup and FP64 performance are often differentiating factors.
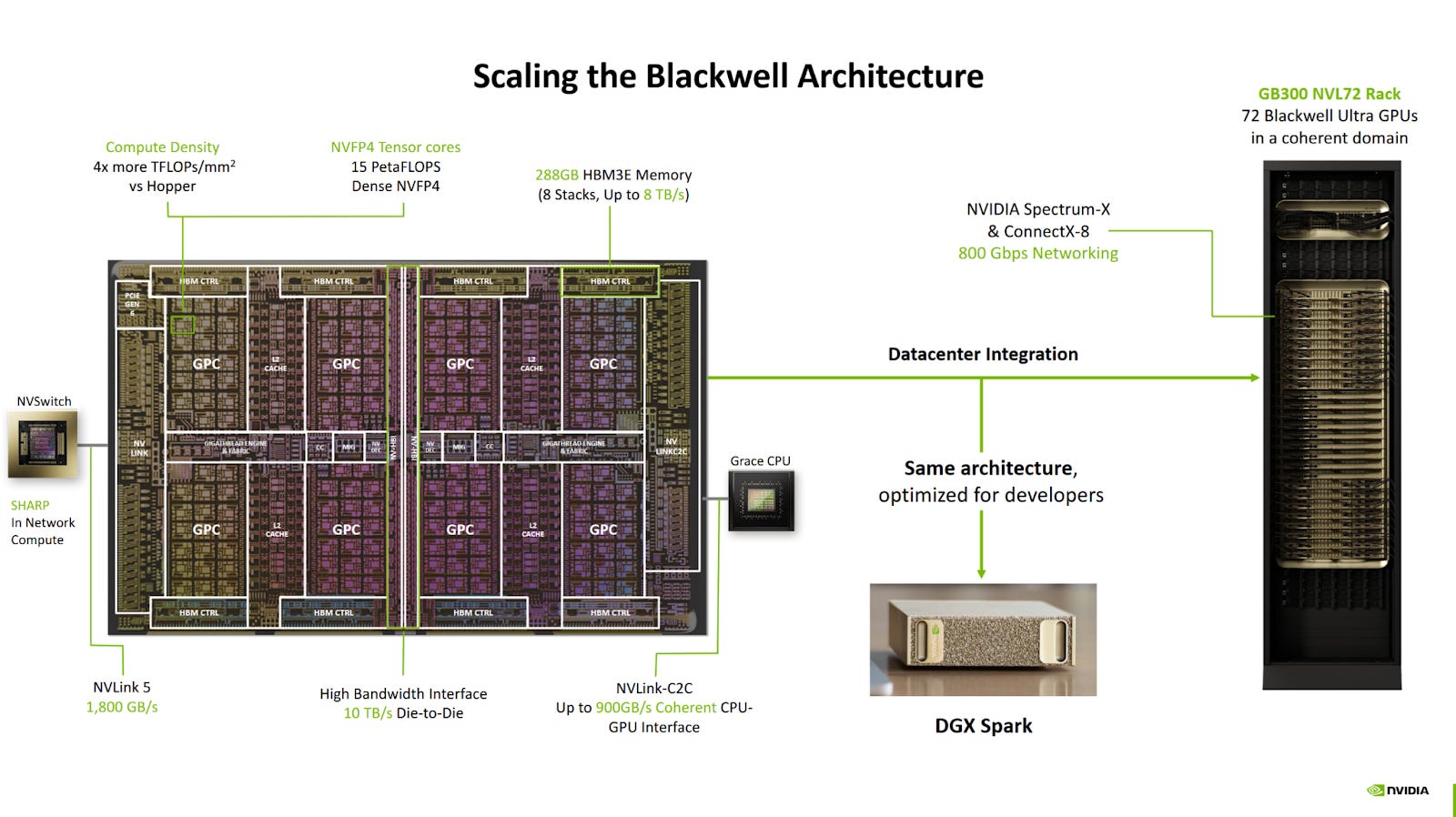
GB10’s GPU uses Blackwell’s consumer variant. It supports compute capability 12.1, putting under the same column that describes Nvidia’s RTX 5xxx consumer GPUs in Nvidia's chart. B200 in contrast has compute capability 10.0. Compared to GB10’s SMs, datacenter variants can keep more work in flight, have more L1/Shared Memory, and more FP64 units. 5th generation Tensor Core features are also limited to the datacenter variant.

These differences mean that GB10 doesn’t act like a smaller version of Nvidia’s Blackwell datacenter GPUs. Presenting GB10 as having the same architecture creates confusion, as can be seen in forum posts and GitHub issues, where kernels written for Nvidia datacenter GPUs can't run on GB10. Even if code doesn’t use any features specific to datacenter Blackwell, GB10 presents a different optimization target. Saying GB10 uses the same architecture as GB300 would be like saying Strix Halo’s RDNA3.5 iGPU uses the same architecture as MI300X. It’s great for investors, but not useful for a more technical audience where accuracy is important. I feel it would have been better to present GB10’s GPU as a member of Nvidia’s consumer RTX lineup. Consumer GPU architectures are perfectly capable of handling a wide variety of compute applications. Nvidia could still position GB10 as a compute-focused GPU.
Nvidia’s consumer Blackwell variant has advantages too. It has hardware raytracing acceleration, which can be useful in workloads like Blender with Optix. Consumer SMs clock higher than their datacenter counterparts, which can reduce per-wave latency on code that doesn’t benefit from any of datacenter Blackwell’s advantages. Finally, consumer Blackwell SMs take less area, which translates to more vector compute throughput with a given die area budget.
Some Light Benchmarking
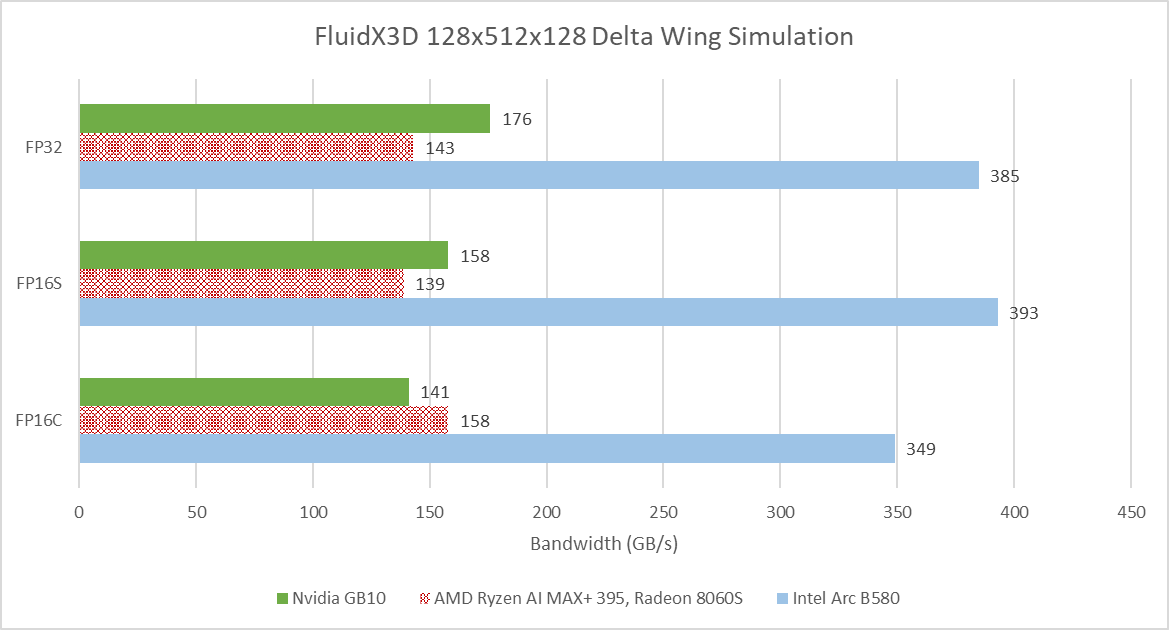
FluidX3D simulates fluid behavior using the lattice Boltzmann method. It carries out computations using FP32, but can store data in 16-bit floating point formats to reduce pressure on memory bandwidth and capacity. FP16S mode stores values in the IEEE-754 standard 16-bit floating point format, and benefits from hardware instructions when converting between FP32 and FP16. FP16C uses a custom 16-bit floating point format to minimize accuracy loss. Conversions between the custom FP16 format and FP32 have to be done in software, increasing the compute to bandwidth ratio.
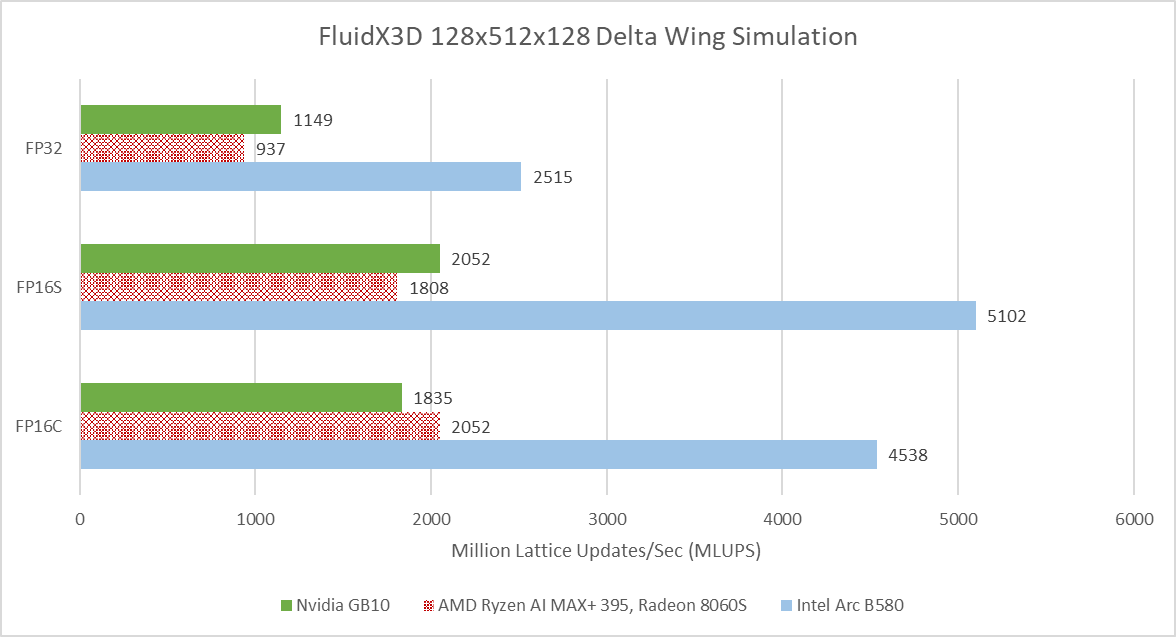
GB10 leads AMD’s Strix Halo when running FluidX3D’s delta wing simulation example with FP32, and continues to have an edge in FP16S. However, it falls behind in FP16C mode. Intel’s Arc B580 nominally sits in the same performance segment as Strix Halo, but manages a huge performance lead over both iGPUs. VRAM bandwidth is likely a factor. FluidX3D has poor memory access locality and therefore tends to be bound by VRAM bandwidth. Besides reporting simulation speed, FluidX3D outputs memory bandwidth figures that account for accesses made from its algorithm’s perspective.
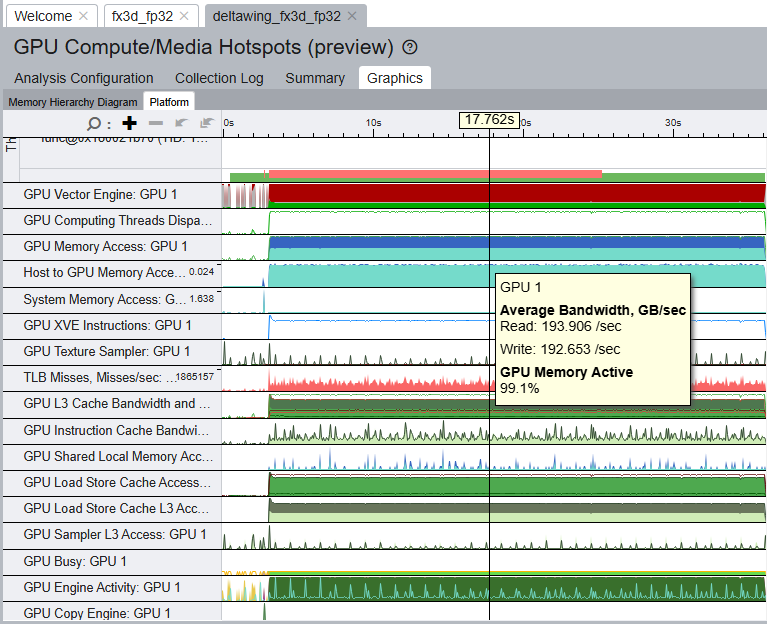
These accesses can include cache hits, which are transparent to user code. Profiling FluidX3D on Intel’s Arc B580 however shows that FluidX3D’s reported bandwidth aligns well with VRAM bandwidth usage from performance monitoring metrics.
GB10 and Strix Halo use 8533 and 8000 MT/s LPDDR5X over a 256-bit bus, giving 273 and 256 GB/s of theoretical bandwidth, respectively. That’s very high bandwidth for a consumer platform, but can’t compare to the 456 GB/s that the Arc B580 gets from GDDR6 over a 192-bit bus. Lack of memory bandwidth mean both iGPUs lean harder on caching than their discrete counterparts, and could suffer in workloads with poor access locality.
VkFFT implements Fast Fourier Transforms in multiple APIs. Here, I’m running its Vulkan benchmarks. GB10 leads Strix Halo, and turns in the most consistent performance across different test configurations. Strix Halo’s performance is more varied, and never beats GB10’s. Intel’s B580 is all over the place. It ends up with a higher average score than GB10, but takes huge losses in certain test configurations.
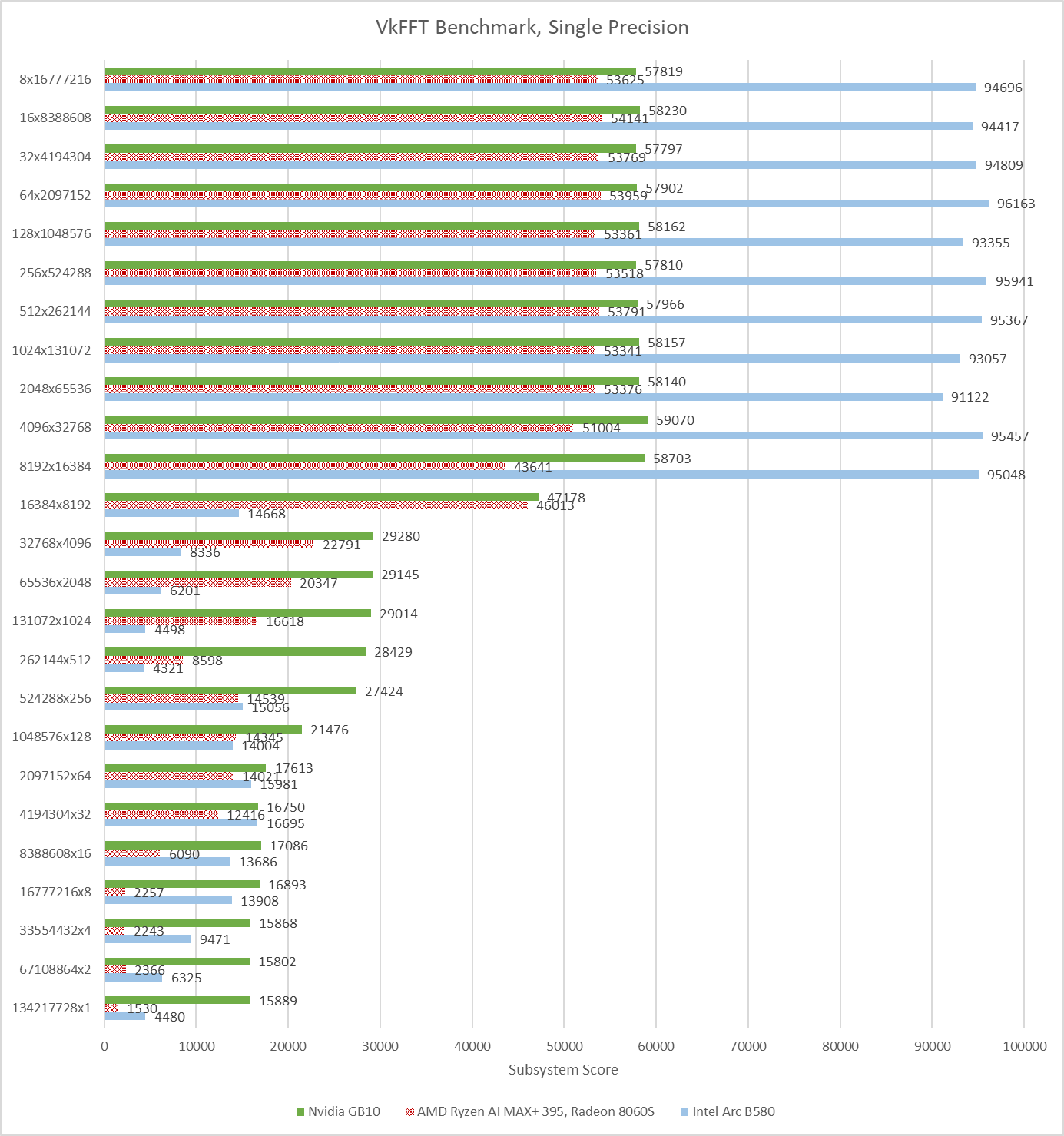
VkFFT outputs bandwidth figures alongside test results, and again shows what a discrete GPU can do with a fast, dedicated memory pool.
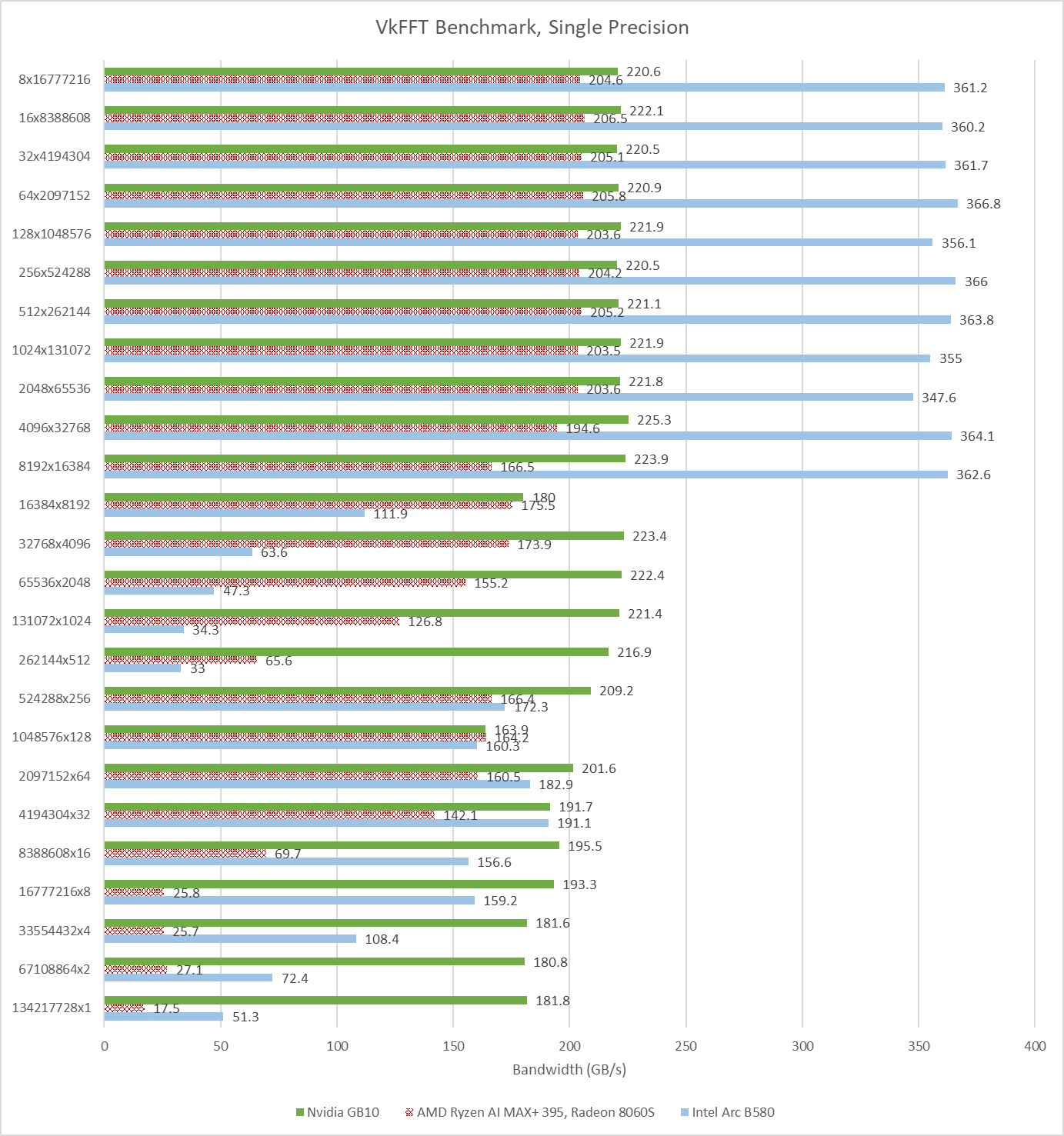
VkFFT can also target double precision (FP64) and half precision (FP16). GB10 is able to take an overall lead with double precision, while Strix Halo still can’t pull ahead in any test. Intel’s B580 can use its bandwidth advantage to win in some configurations, but not enough to get an overall score lead. None of the three GPUs here have strong FP64 performance, but VkFFT is often memory bound. The primary challenge is feeding the execution units, not having more of them.
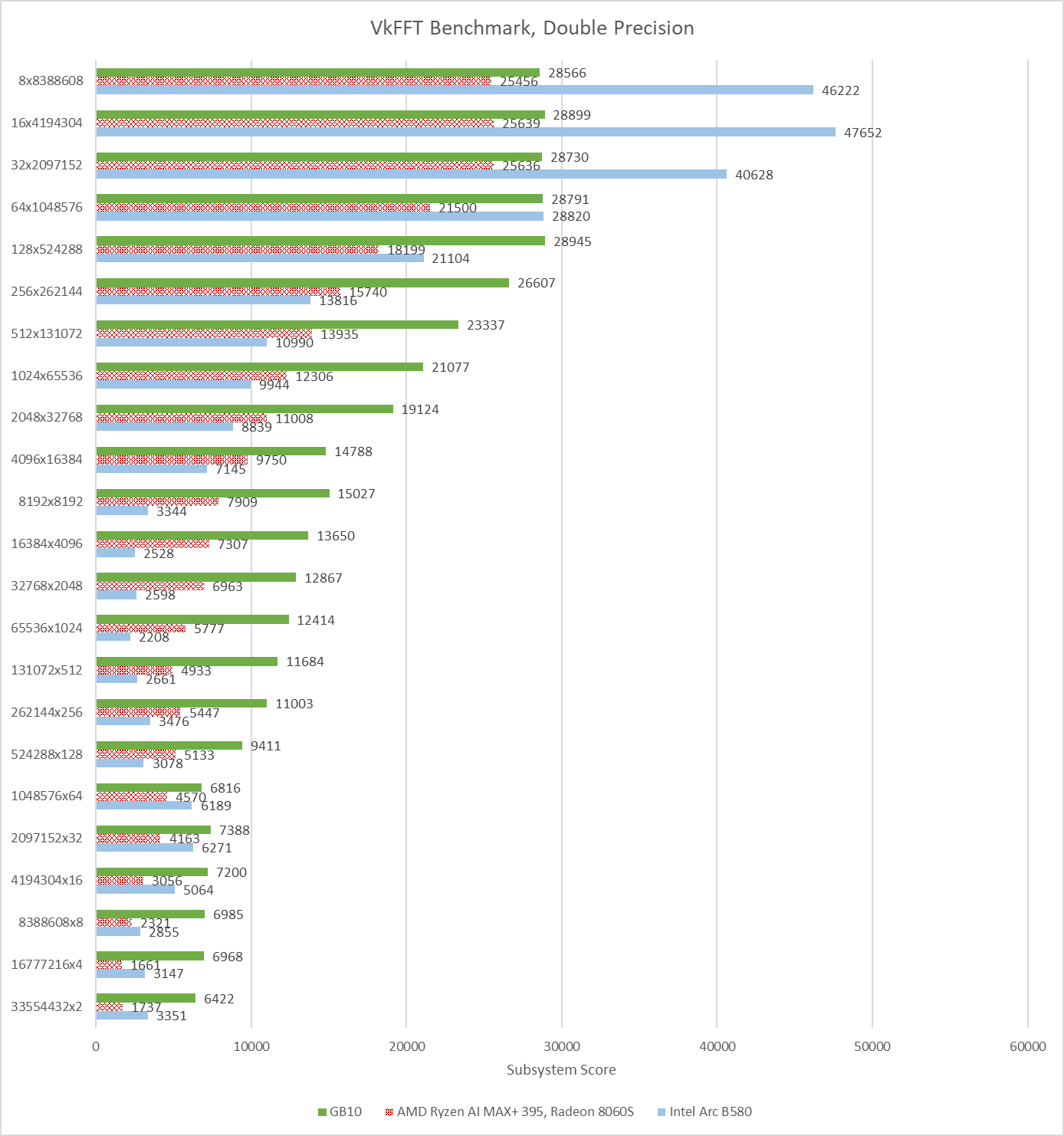
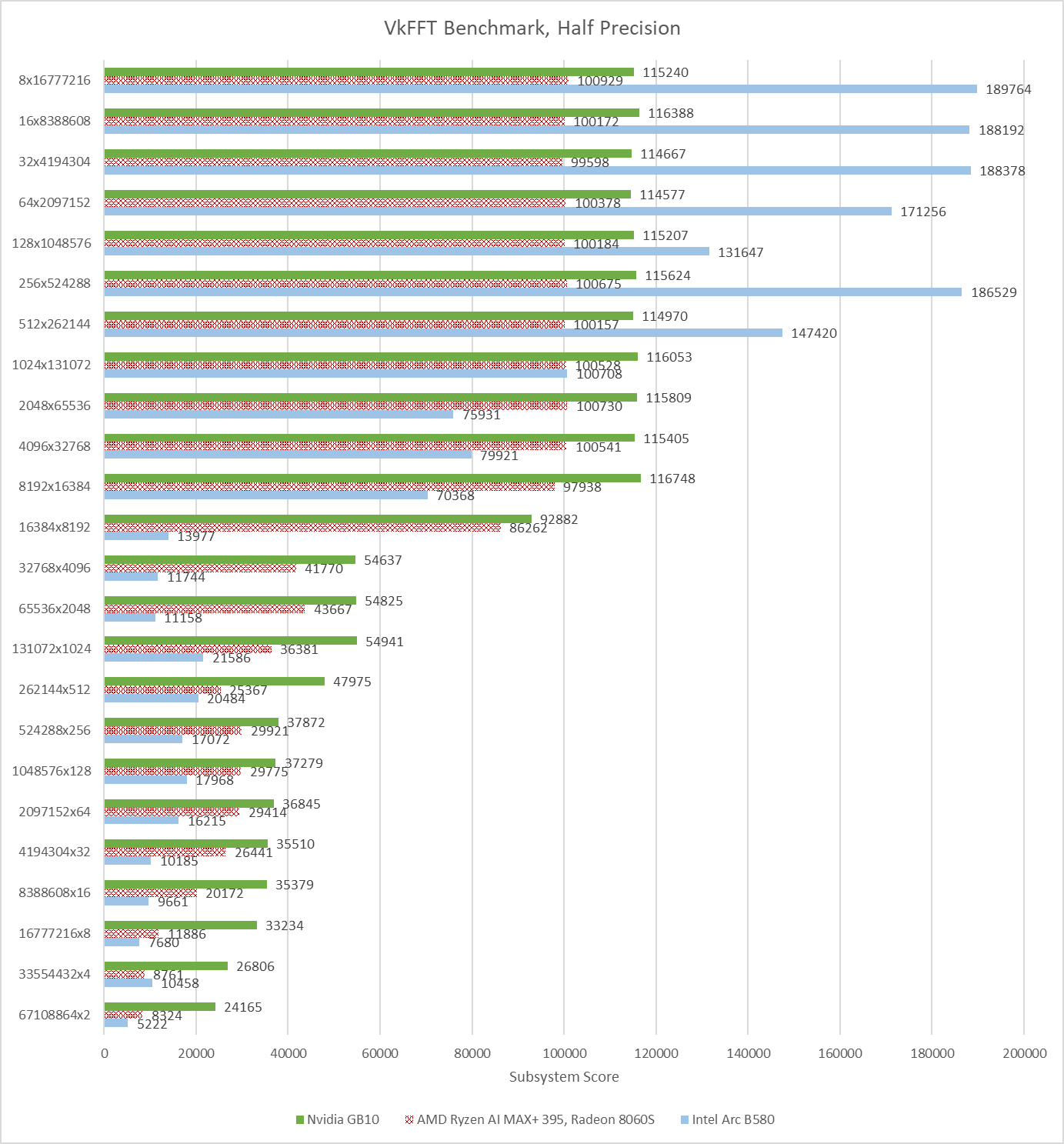
Half precision runs tell a similar story, but with narrower gaps between the three GPUs. GB10, Strix Halo, and B580 average 76793.25, 62498.79, and 70980.17 respectively across all of the half precision test configurations.
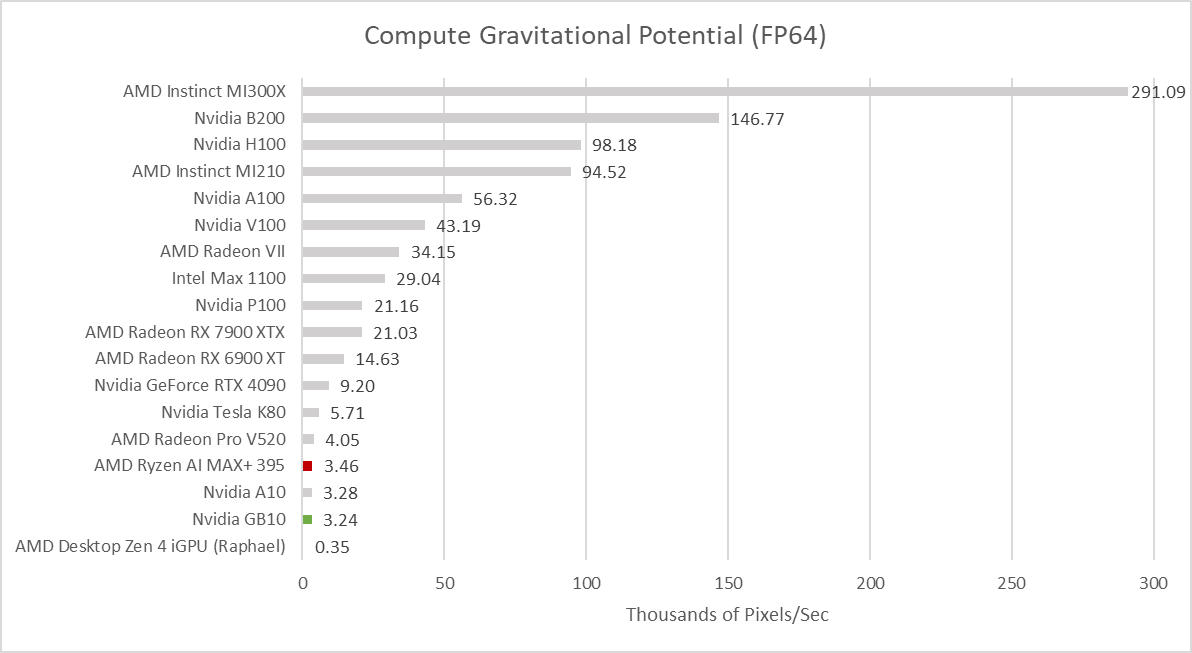
In this self-penned benchmark, I perform a brute-force gravitational potential calculation over column density values. It’s a GPU accelerated version of something I did during a high school internship. Datacenter GPUs tend to do very well because I use FP64 values. GB10 and Strix Halo fall very far behind.
FAHBench is a benchmark for Folding at Home, a distributed computing project that runs protein folding simulations. The benchmark comes with three workloads, which can be run with either single or double precision. Two workloads use a DHFR (dihydrofolate reductase) system in explicit or implicit mode. Explicit simulates all 23558 atoms, while implicit only uses 2489 atoms to approximate a solution. NAV, or voltage gated sodium channel, is the third workload and uses 173112 atoms.
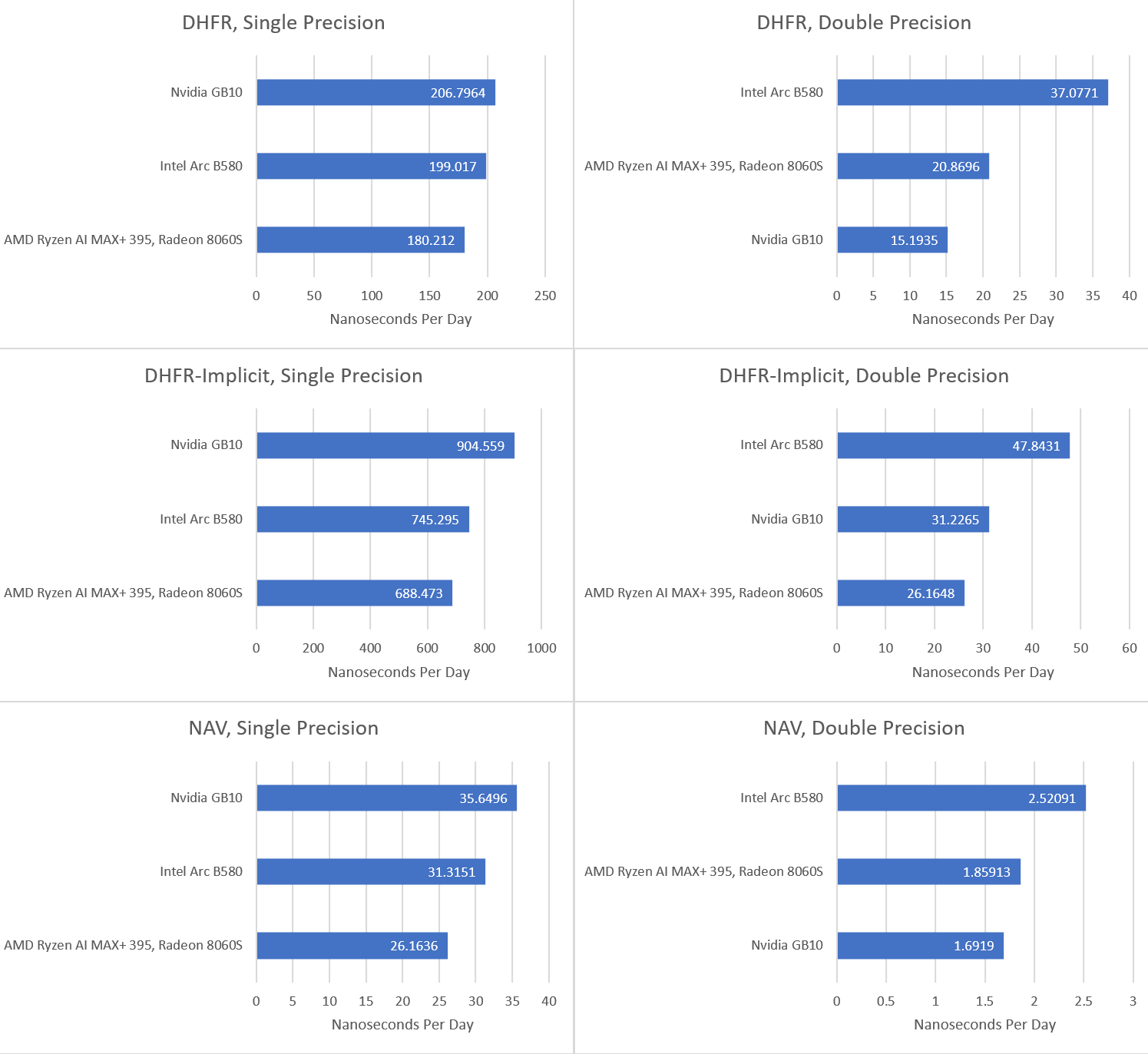
GB10 easily tops FAHBench’s workloads in single precision mode. FAHBench makes good use of local memory to keep data on-chip, reducing pressure on the global memory hierarchy. Global memory accesses that do happen have reasonable locality, even on the heavier NAV workload. Data Fabric performance monitoring on Strix Halo shows about 200 GB/s of GPU memory requests, and ~50 GB/s of traffic at the Unified Memory Controllers. That implies Strix Halo’s 32 MB system level cache caught about 150 GB/s of memory traffic. GB10’s 24 MB L2 is likely almost as effective, which would mean Nvidia also avoids DRAM bandwidth bottlenecks.
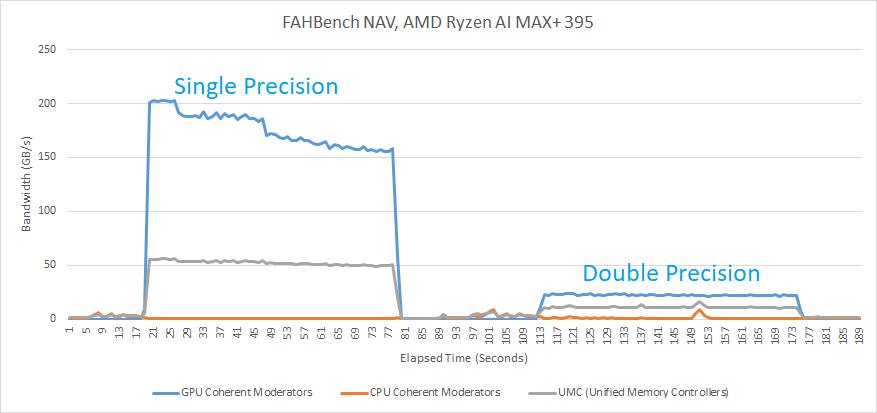
As a result, FAHBench favors compute throughput and plays well into GB10’s advantages. In some cases though, Strix Halo can keep up surprisingly well. In the DHFR single precision test, Strix Halo starts with a score just above 200 ns/day. If it maintained that, it would have nearly tied GB10. However, performance quickly drops as the chip pushes past 90 C. By targeting thin and light devices, Strix Halo has to contend with tighter thermal and power constraints than GB10 does in mini-PCs. Dell’s cooling in their mini-PC is excellent, and manages to keep GB10 in the low 60 C range during FAHBench runs.
Double precision workloads on FAHBench are very compute bound on all three GPUs. Intel’s B580 has the least horrible FP64 to FP32 ratio at 1:16. Strix Halo comes next at 1:32, followed by GB10 at 1:64.
Final Words
Large iGPUs are fascinating, and it’s great to see Nvidia entering the scene. GB10’s GPU has plenty of strengths compared to the one in AMD’s Strix Halo. It uses Nvidia’s latest Blackwell architecture, while Strix Halo makes do with RDNA3.5 instead of AMD’s latest RDNA4. Nvidia also uses TSMC’s 3nm process, while Strix Halo uses 4nm. GB10’s GPU is sized to be a bit larger than Strix Halo’s. Compute benchmarks show GB10’s strength. It beats Strix Halo more often than not. All else being equal, GB10’s iGPU could be a dangerous competitor to Strix Halo and a welcome arrival for PC enthusiasts.
Unfortunately, gaming on GB10 is off to a rough start. iGPU setups are locked into whichever CPU they come with. GB10 uses ARM CPU cores, and quite excellent ones from an ISA-agnostic point of view. However, ISA does matter when software can’t be easily ported. Nearly all PC games target x86-64, are closed source, and lack 64-bit Arm ports. Emulation and binary translation may let some games run, but at a performance cost. For example, Retrotom on Reddit ran Cyberpunk 2077 on GB10 and achieved about 50 FPS at 1080P with medium settings. Similar settings on Strix Halo in Cyberpunk 2077's built-in benchmark give just under 90 FPS. Strix Halo already suffered a CPU performance penalty because of contention at the memory bus and high memory latency compared to desktop discrete GPU setups. Taking another heavy hit to CPU performance is a tough pill to swallow.
Nvidia understandably positions GB10 as a compute solution, aimed at developers who want to test their code without going to a datacenter GPU. Developers can recompile their application to target 64-bit Arm, minimizing compatibility issues. GB10’s strong compute performance, high memory capacity, and iGPU advantages play well into this purpose. In the compute role however, GB10 has a VRAM bandwidth disadvantage compared to discrete peers.
The factors above mean GB10 is an exciting product, but possibly one with a limited audience. Like Strix Halo, GB10’s unified memory and more compact form factor have to face off against iGPU compromises and an extremely high price compared to discrete GPU setups with similar compute throughput. I hope to see both Nvidia and AMD iterate on their large iGPU designs to bring price down and minimize their compromises. There’s a lot of potential for large iGPU designs, and I’m excited to see that segment develop.
What makes the GB10 and Strix Halo interesting to me is that the integrated GPU has access to 128GB of unified RAM. This provides a very different runtime environment than a B580 GPU with 12GB of device memory.
I would like to see further comparisons between just the GB10 and Strix Halo for AI applications that need the larger RAM capacity. More investigation into the extent to which CPU and GPU compute can be combined would also be interesting.
There are lots of long paragraphs.
It will be better if you put line break (html br tag) for each sentence to make it easier to be read, especially in mobile browser.
Using sans serif font also improves readability in screen.