
Analyzing Lion Cove's Memory Subsystem in Arrow Lake

A CPU core can perform very differently depending on the platform it's deployed in. That was on full display with Skymont's wildly different performance characteristics in Lunar Lake and Arrow Lake. We've already covered Intel's latest P-Core architecture, Lion Cove, in Lunar Lake. Now, it's time to check it out in Arrow Lake, where it sits on a much higher performance platform.

Arrow Lake's higher power budget lets the Core Ultra 9 285K run its P-Cores at 5.7 GHz, rather than 4.8 GHz in the Core Ultra 7 258V. A higher area budget lets Arrow Lake feed those P-Cores with 36 MB of L3 cache, up from 12 MB in Lunar Lake. Cache capacity increases extend to the core too, with each Arrow Lake P-Core getting 3 MB of L2. It's a slight boost over Lunar Lake's 2.5 MB. Finally, Arrow Lake improves DRAM access latency.
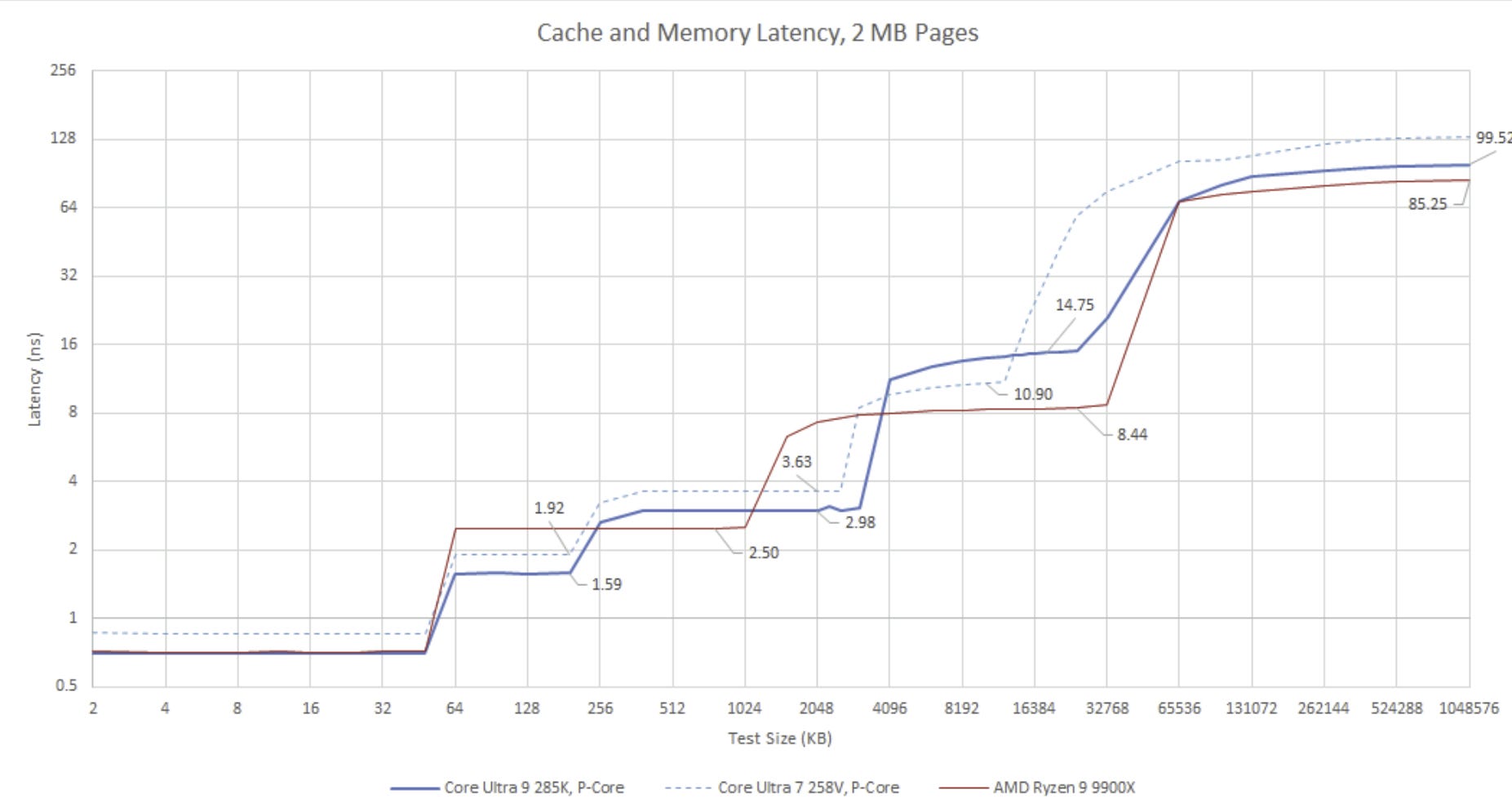
All that means Lion Cove is faster and better fed in Arrow Lake than it was in Lunar Lake. In SPEC CPU2017, that translates to 24.8% and 23.4% gains in the integer and floating point suites, respectively. That’s greater than a typical performance gain between CPU generations. However, it stops short of being over a 50% performance difference like with Skymont. That’s mostly down to Skymont getting the short end of the stick in Lunar Lake, where it had no L3 cache and suffered from high L2 miss latency. Lunar Lake made a decent effort to feed its P-Cores, and actually enjoys lower L3 latency. Arrow Lake’s memory subsystem is better overall, but its advantage for Lion Cove is less extreme than with Skymont.

AMD for comparison runs Zen 5 at nearly identical maximum clocks, but uses a smaller L2 cache and faster L3. AMD also enjoys faster DRAM access this generation. Notably, that's not because AMD brought out an amazingly improved memory controller with Zen 5. Rather, Arrow Lake's DRAM latency regressed compared to the prior generation, Raptor Lake.
Raptor Lake is worth discussing too, because its Raptor Cove P-Cores get very close to Arrow Lake's. Against its predecessor, Lion Cove manages a narrow 1.2% lead in SPEC's integer suite, and a 3% lead in the floating point suite. A closer look at individual workloads shows Raptor Lake beating its successor on a few memory bound tests like 505.mcf and 520.omnetpp. I suspect Arrow Lake's higher DRAM latency plays a role. Zen 5 stays ahead of both Intel cores on those tests, likely thanks to a combination of a newer core and reasonably low latency DRAM access. Meanwhile, Lunar Lake's Lion Cove cores fall through the ground when faced with larger data footprints. In 520.omnetpp for example, Arrow Lake's Lion Cove core is 45% faster than the same core implemented in Lunar Lake.
At the other end of the spectrum, Lion Cove excels in high IPC workloads where much of the working set can be contained in cache. Lion Cove isn't an exact repeat of Skymont, but some of the performance characteristics do rhyme. Both are 8-wide cores capable of hitting very high IPC if you can feed them. Zen 5 fits into that category too.

When things get difficult, Zen 5 and Lion Cove remain closely matched despite their different caching strategies, though there’s variation of course. Investigating cache hitrates can be challenging because performance monitoring events are specific to each architecture. Intel and AMD couldn’t be more different in how they characterize cache misses. Intel reports data sources for load instructions at retirement, where the core carries out final checks and makes instruction results visible. AMD breaks down data sources for demand L1D misses. “Demand” means the access was initiated by an instruction, but doesn’t necessarily mean the instruction was actually executed (retired). For example, a demand load could come after a branch mispredict. In that case, the load would never retire and it’s data would likely not be used.

For maximum confusion, Intel's performance monitoring documentation actually calls Lion Cove's 192 KB data cache "Level 1 of the L1 data cache". I suppose Intel's engineers really like L1 hits (who doesn't). So, they made a L1 for their L1 so they could hit in level 1 of their L1 in case the first level of L1 wasn't good enough. I can't believe it actually worked. I'm going to keep calling it a L1.5 cache for simplicity.

Despite these differences, performance monitoring events do give clues into how their caching strategies interact with different workloads. Starting from the top, Intel's L1.5 cache is surprisingly effective. Even 192 KB is enough to catch a huge portion of L1D misses in certain workloads. In exceptional cases like 525.x264, the L1.5 basically replaces the L2 as the primary data source for L1D misses.
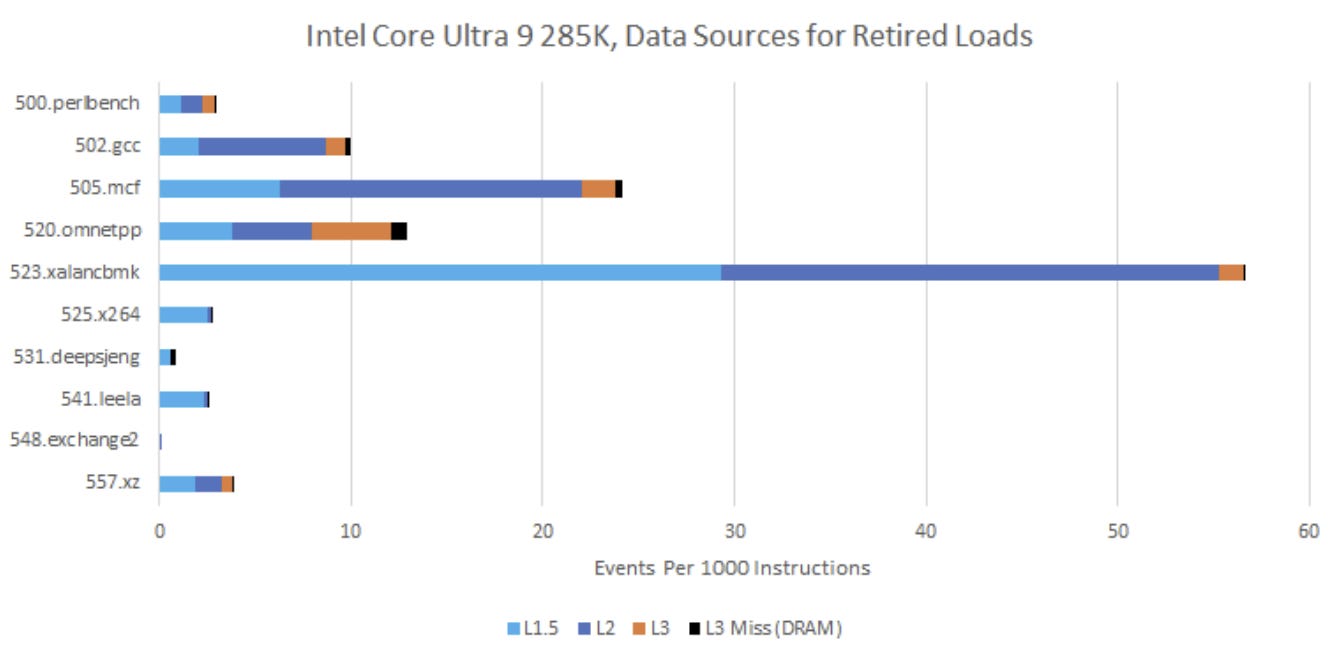
In the same workload, AMD has to service all those L1D misses from its higher latency L2 cache. That could contribute to Lion Cove’s lead over Zen 5 in 525.x264. Even in workloads with less predictable memory access behavior, the L1.5 often reduces traffic heading to L2.

Zen 5 also suffers in those tests, but is able to average about 1.45 IPC in both. I suspect Zen 5’s lower latency L3 and DRAM access play a role.
Across SPEC CPU2017’s floating point suite, Lion Cove’s L1.5 hitrates are all over the place. In several tests, the L1.5 is nearly able the replace the L2, often handing Intel a lead. In others, the L1.5 can’t catch enough requests and Lion Cove handles the bulk of L1 misses from L2, just as Zen 5 does. That can put Intel at a disadvantage due to higher L2 latency.

After L2, it’s a wash. Sometimes Intel’s higher L2 hitrate leaves AMD eating L3 latency. And sometimes, the workload has a large enough data footprint for Intel’s slower L3 and DRAM accesses to hurt.
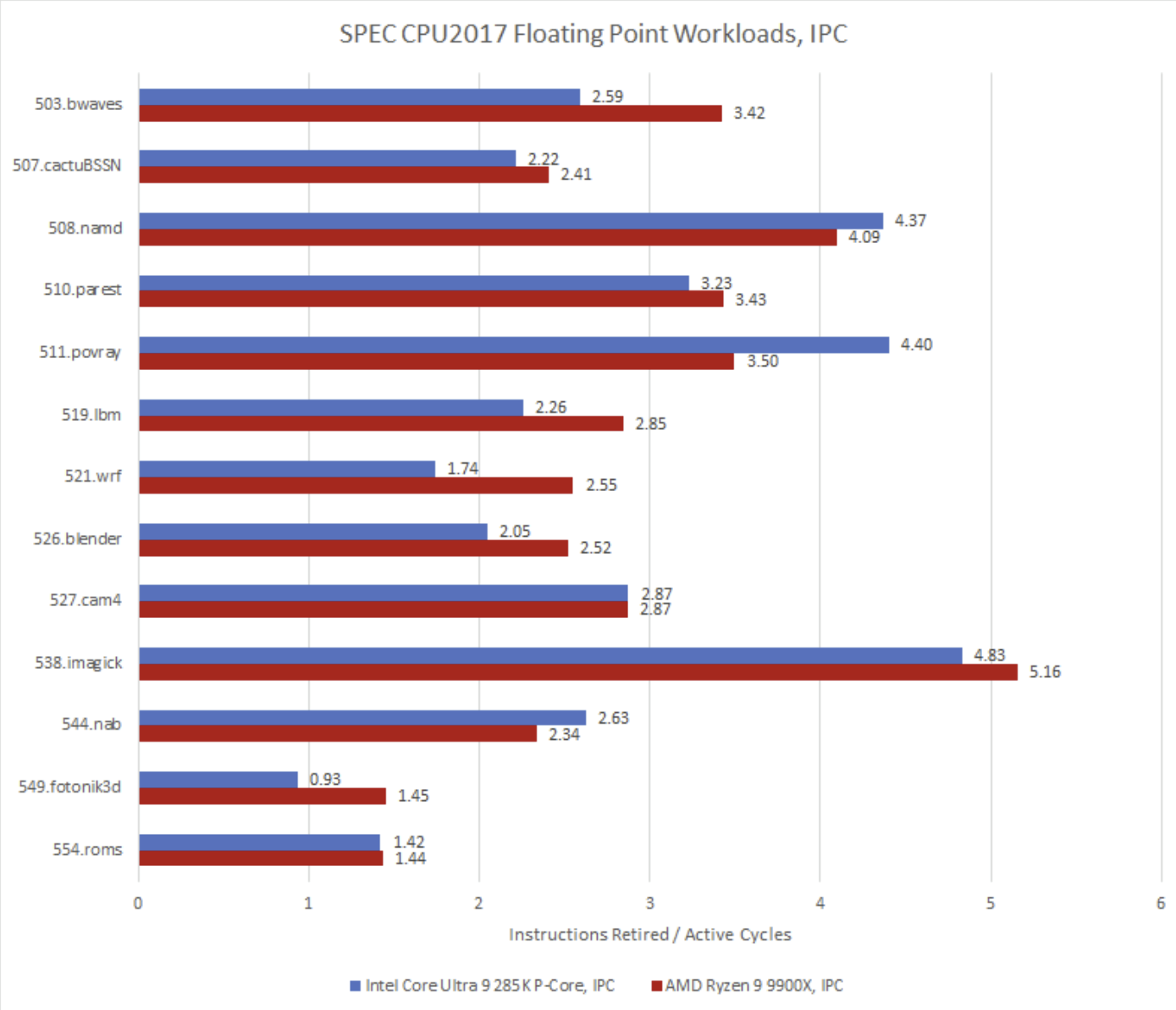
SPEC CPU2017’s floating point suite is also interesting because it includes a few extremely high IPC workloads. Intel reworked their execution port layout with Lion Cove, creating a set of four vector/FP ports separated from the scalar integer ports. For floating point operations, ports V0 and V1 can handle floating point multiplies and fused multiply-adds. Ports V2 and V3 handle floating point adds with lower latency.

Creating a good port layout is all about making sure in-demand execution units are well distributed across ports. If that’s not done well, one or two ports could receive disproportionate load. 508.namd has the highest IPC of any workload in SPEC CPU2017, and heavily exercises the two FMA ports. Actual load could be even higher because the events I used (FP_ARITH_DISPATCHED.Vn) only count floating point operations. Any SIMD integer ops could further increase port usage.

Other workloads don’t demand enough port throughput for execution unit layout to be a concern. Load often isn’t balanced well across the four ports. Putting FADD and FMA units on every port would have been ideal. But floating point execution units are expensive, and doing so would probably provide just a minor benefit for a few very high IPC workloads. With that in mind, Lion Cove’s FP port layout looks well thought out.
libx264 Video Encoding
SPEC CPU2017 relies on compiler generated code, but a lot of software uses intrinsics or assembly to make the best use of vector instructions. I’m using libx264 as an example of that. Lion Cove continues an Intel tradition of doing very well in vectorized code, and pulls ahead of Zen 5 by 4% in a matched core count test. Both high performance cores finish well ahead of Skymont, which can’t keep pace even when Zen 5’s SMT threads aren’t loaded. Intel’s E-Core line has traditionally been weaker with vector workloads. And while every E-Core generation improves vector execution, area constraints limit what can be done.

Lion Cove’s L1.5 deserves credit for taking some pressure off L2 in this workload. But Lion Cove and Zen 5 both satisfy most L1 misses from L2. AMD and Intel may strike a different balance, but both companies today use relatively large L2 caches to keep data close to the core. A good number of requests go to L3 and DRAM as well.
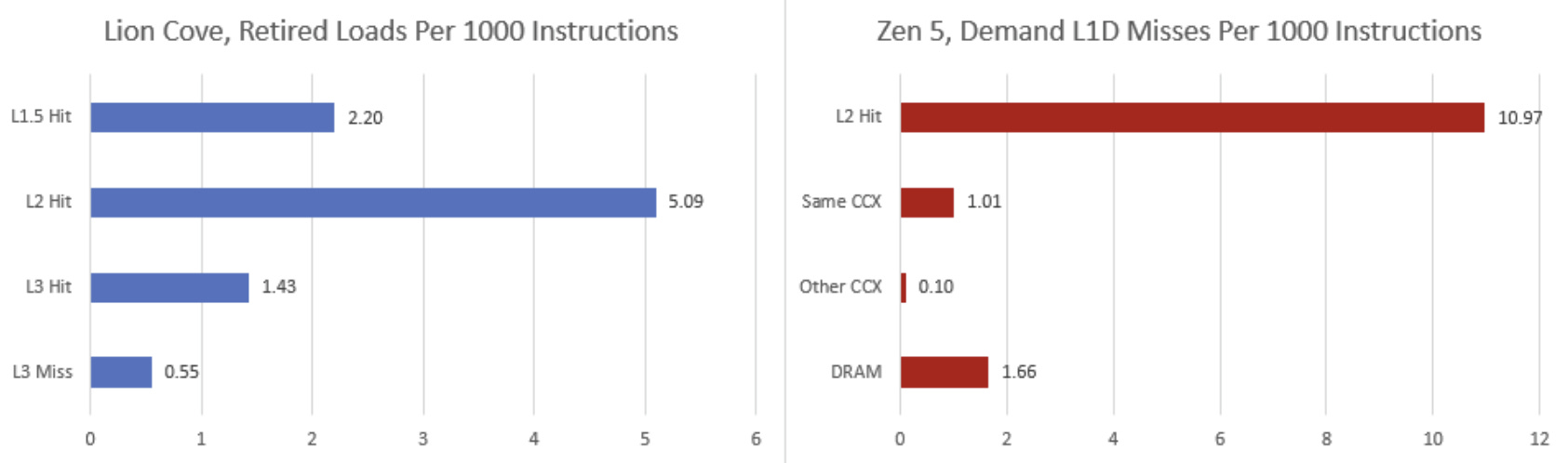
To test eight cores on the Ryzen 9 9900X, I had to split the workload across the chip’s two 6-core clusters. AMD’s memory subsystem may have to carry out cache to cache transfers between the two clusters to maintain cache coherency. However, performance counters indicate such cross-CCX traffic is very rare compared to regular L3 hits or DRAM accesses. That’s why I wouldn’t put much weight into core-to-core latency test results.
7-Zip
7-Zip is a popular file compression program. Here, I’m compressing a 2.67 GB ETL (performance trace) file. 7-Zip almost exclusively uses scalar integer instructions. Skymont improves its relative position, though Lion Cove still holds a good 26% lead over its density optimized partner. It’s not 50%, but that sort of gap is still too large to let Skymont step into the high performance space.

Again, I’m matching core counts by splitting the workload across the 9900X’s two CCDs. Lion Cove seems to struggle in compression workloads, falling behind even the previous generation Raptor Cove in SPEC CPU2017’s 557.xz workload. I tried putting 7-Zip on a single CCD for a hex-core comparison with similar total cache capacity in play, but Zen 5 still came out ahead by similar margins.

7-Zip has a large memory footprint. Large L2 caches on Lion Cove and Zen 5 both do a good job of absorbing L1 miss traffic, and Lion Cove’s L1.5 also turns in a good showing. However, a good portion of accesses that miss L2 aren’t caught by L3 on both CPUs. Even taking 0.7 DRAM accesses per 1000 instructions can be detrimental to performance. A DRAM access takes over 565 core cycles from Lion Cove, or over 484 cycles from a Zen 5 core. From that perspective, I’m impressed at how Lion Cove, Zen 5, and even Skymont all average over 1 IPC in this workload.
Final Words
Arrow Lake shows Lion Cove can generally keep pace with AMD’s latest Zen 5 core, doing better in some workloads but falling behind in others. I don’t find that an impressive result for Intel. I took a convenient and low cost route to setting up a Zen 5 test system, replacing my 7950X3D with the 9900X sampled by AMD while keeping everything else the same. That meant it was running with my existing 2x 32 GB DDR5-5600 kit. George (Cheese) had the Core Ultra 9 285K system set up with a 2x 24 GB DDR5-8000 kit. As of 12-23-2024, my DDR5 kit sells for $150, while the faster memory sells for $250. In matched core count tests, Lion Cove is getting similar performance using more expensive, lower capacity memory. It’s not particularly appetizing.
From there, it’s tempting to dismiss Intel as a company that has lost its way and can’t rebound from a period of stagnation. But looking at the forest makes it easy to miss the detail in the trees, and Lion Cove has plenty of impressive details. Intel can run an eight-wide decoder at 5.7 GHz, and backs it up with a large 64 KB instruction cache. AMD for comparison can only give four decode slots to each thread. Lion Cove’s renamer can handle adds with small immediates with effectively zero latency. At the backend, a L1.5 cache can be surprisingly effective at containing L1 miss traffic. To mitigate latency, Lion Cove still boasts more reordering capacity than Zen 5. And it’s hard to understate the magnitude of changes going from Raptor Cove to Lion Cove. Just about every part of the pipeline has been improved, and the out-of-order engine has been reorganized.

But not all of those features translate to a performance advantage. Take the 8-wide decoder for example. A wider decoder only helps if op cache hitrate is low, and the workload runs at high enough IPC to to push the limits of AMD’s 4-wide decoder. Those factors don’t come together for enough workloads. Op cache hitrate is often very high across AMD and Intel’s newest cores. 507.cactuBSSN comes the closest to making the decoders work hard, but even then the decoders account for less than half the delivered uops on Lion Cove. Zen 5 strikes a different balance, boasting a larger and better optimized op cache that results in the decoders handling less than 25% of uops. All that doesn’t matter because Lion Cove and Zen 5 average 2.22 and 2.41 IPC on that test, respectively. A 4-wide decoder can sustain that kind of throughput given large enough queues to smooth out spikes in demand for instruction bandwidth.
Lion Cove’s advanced renamer should apply more widely, but likely has limited effect outside of very high IPC workloads. The L1.5 cache does help lower L1D miss latency, but it’s partly a necessity to offset higher L2 latency. Then, high L2 latency is driven by needing a bigger L2 because L2 misses are so expensive. That brings me to Arrow Lake’s interconnect and chiplet setup. High latency eats into Lion Cove’s potential.
Perhaps Intel could have stayed the course and put Lion Cove on a monolithic chip, reusing Raptor Lake’s System Agent. That could bring short term success. But I think Intel is trying to make sure they have an extensible foundation to build on with Arrow Lake. It reminds me of how AMD’s Infinity Fabric and chiplet setups eventually let the company combine all sorts of IP blocks seemingly at will. Of course none of that was evident in the first couple Zen generations. AMD’s first chiplet setups also suffered higher DRAM latency than Intel’s monolithic chips, and for several generations AMD couldn’t beat Intel’s single threaded performance.

Arrow Lake and Lion Cove paint a picture of an Intel that isn’t stagnating, but rather is working furiously to put themselves back on a solid foundation. That has led to massive change compared to the previous generation. These changes aren’t always good for Lion Cove’s performance today, but are aimed at enabling better future designs. In a way, Intel is trying to pull off a Zen-type transition, though from a much better starting point than AMD did prior to 2017. Hopefully, it all works out for Intel.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
First, TSMC's pricing depends on the node; anything "N3" is amongst their currently most expensive. In contrast, AMD has their chips fabbed on a slightly older, but also significantly cheaper node (N4/5). Second, TSMC got into a huff over some of Pat Gelsinger's statements about whose upcoming nodes is better and refused to give Intel their customary discount of about 30%. Third, the most expensive fabbing node ( apart from one that basically isn't working at all) is one that sits idle. Intel decided to forgo "Intel 20" and put most of their efforts into Intel 18. That was a gamble, we'll see if it pays off soon.
Lastly, do you have a source for that statement that Intel lost a lot of money on fabbing the Meteor Lake CPU tile in Intel 4? Not doubting you, would just like to read it for myself - Thanks!
So ARL uses d5-8000 to marginally win over RPL d4-3600...
This is almost certainly a regression in spec cpu.