
AMD’s Chiplet APU: An Overview of Strix Halo

Hello you fine Internet folks!
Today we are looking at AMD’s largest client APU to date, Strix Halo. This is an APU designed to be a true all-in-one mobile processor, able to handle high end CPU and GPU workloads without compromise. Offering a TDP range of 55W to 120W, the chip targets a far higher power envelope compared to standard Strix Point, but eschews the need for dedicated graphics.
To get y’all all caught up on the history and specifications of this APU, AMD first announced Strix Halo at CES 2025 earlier this year to much fanfare. Strix Halo is AMD’s first chiplet APU in the consumer market with AMD using Strix Halo as a bit of a show piece for what both CPU and GPU performance can look like with a sufficiently large APU.

AMD’s Strix Halo can be equipped with dual 8 core Zen 5 CCDs for a total of 16 cores that feature the same 512b FPU as the desktop parts. This is a change from the more mainstream and monolithic Strix Point APU which has “double-pumped” 256b FPUs similar to Zen 4 for use with AVX512 code. What is similar to the more mainstream Strix Point is the same 5.1GHz max boost clock which is a 600MHz deficit compared to the desktop flagship Zen 5 CPU, the Ryzen 9 9950X.
Moving to the 3rd die on a Strix Halo package, a RDNA 3.5 iGPU takes up the majority of the SoC die with 40 compute units, 32MB of Infinity Cache, and a boost clock of up to 2.9GHz placing raw compute capability somewhere between the RX 7600 XT and RX 7700.
To feed this chip, AMD has equipped Strix Halo with a 256b LPDDR5X-8000 memory bus, which provides up to 256GB/s shared between all of the components. This is slightly lower than the 288GB/s available to the RX 7600 XT but is much higher than any other APU we have tested.
Acknowledgments
A massive thank you to both Asus and HP for sending over a ROG Flow Z13 (2025) and a ZBook Ultra G1a 14” for testing which were both equipped with an AMD Ryzen AI Max+ 395. All of the gaming tests were done on the Flow Z13 due to that being a more gaming focused device and all of the microbenchmarking was done on the ZBook Ultra G1a.

Memory Subsystem from the CPU’s Perspective
Starting with the memory latency from Zen 5’s perspective, we see that the latency difference between Strix Point and Strix Halo is negligible with Strix Point at ~128ns of memory latency and Strix Halo at ~123ns of memory latency. However, as you can see the CPU does not have access to the 32MB of Infinity Cache on the IO die. This behavior was confirmed by Mahesh Subramony during our interview about Strix Halo at CES 2025.
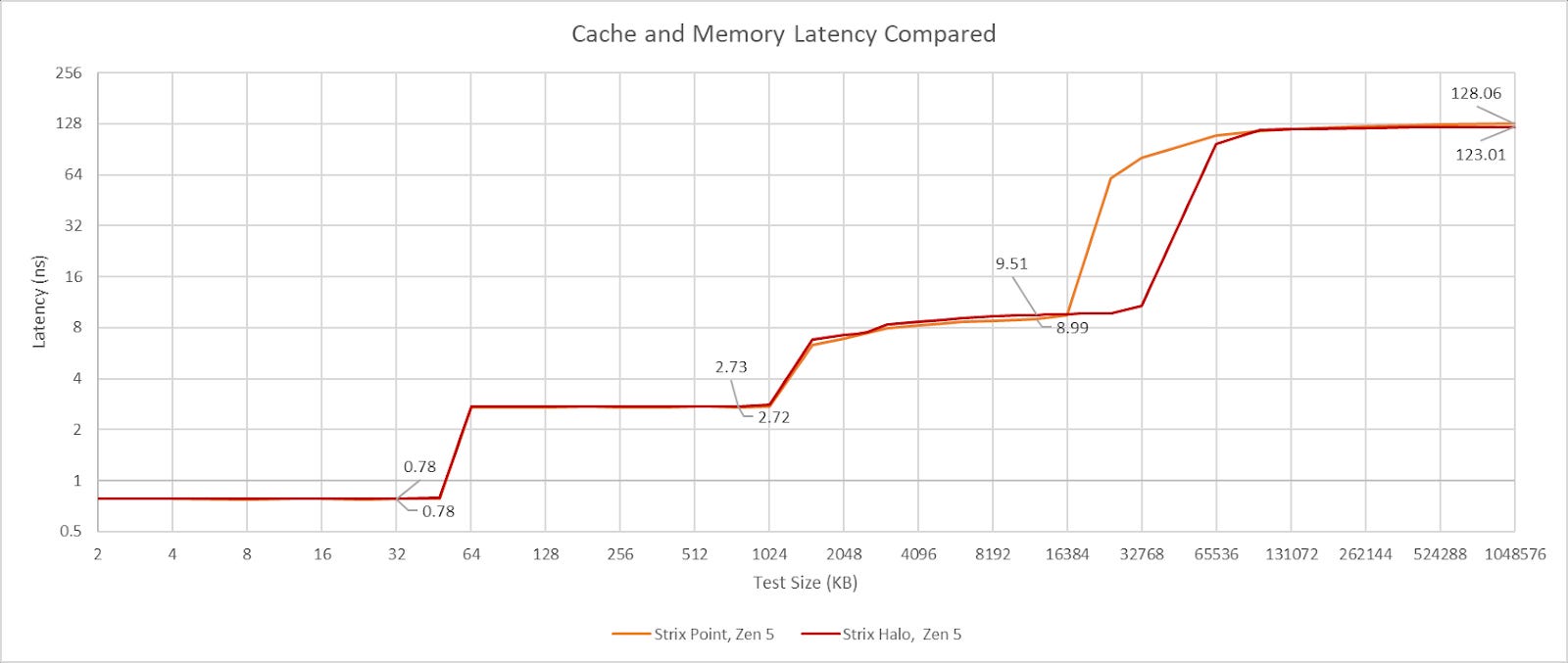
While the 123ns DRAM latency seen here is quite good for a mobile part, desktop processors like our 9950X fare much better at 75-80ns.
Moving on to memory bandwidth, we see Strix Halo fall into a category of its own of the SoCs we have tested.
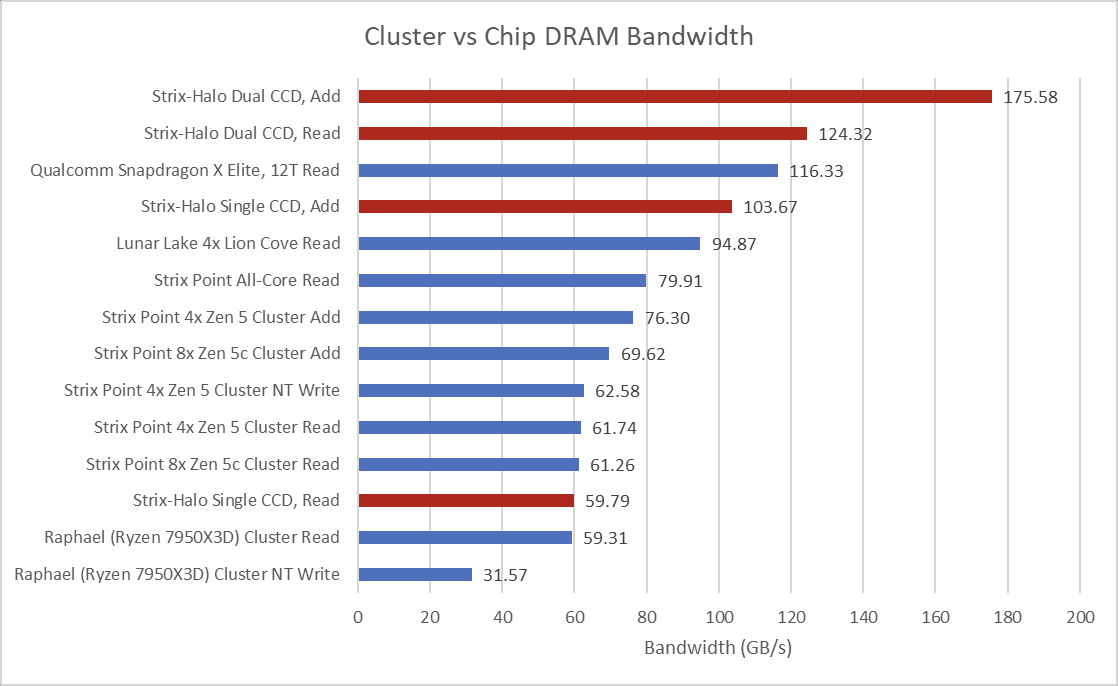
When doing read-modify-add operations across both CCDs, the 16 Zen 5 cores can pull over 175GB/s of bandwidth from the memory with reads being no slouch at 124GB/s across both CCDs.
However, looking at the bandwidth of a single CCD and just like the desktop CPUs a single Strix-Halo CCD only has a 32 byte per cycle read link to the IO die. And just like the desktop chips, the chip to chip link runs at ~2000MHz, which caps out the single CCD read at 64GB/s. Unlike the desktop chips, the write link is 32 bytes per cycle and we are seeing about 43GB/s for the write bandwidth. That brings the total theoretical single CCD bandwidth to 128GB/s and the observed bandwidth is just over 103GB/s.
CPU’s Performance
The performance of Strix Halo’s CPU packs quite a bit more of a punch than Strix Point’s CPU.
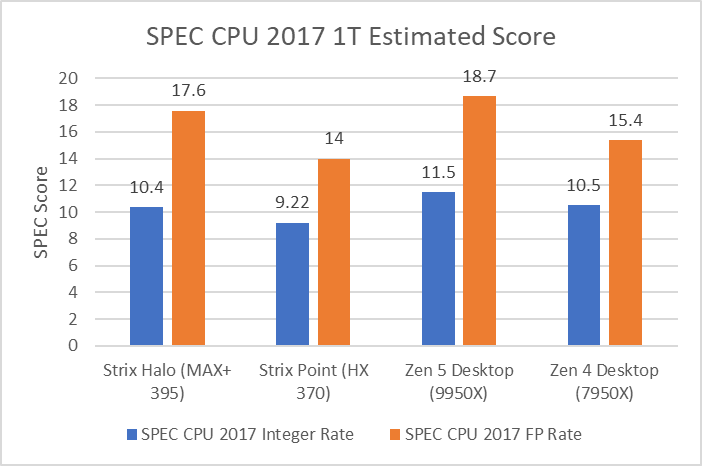
Strix Halo’s CPU can match a last generation desktop flagship CPU, the 7950X, in Integer performance despite a 11.7% clock speed delta. And nearly matches AMD current desktop flagship CPU, the 9950X, in Floating Point performance again with a 11.7% clock speed deficit.
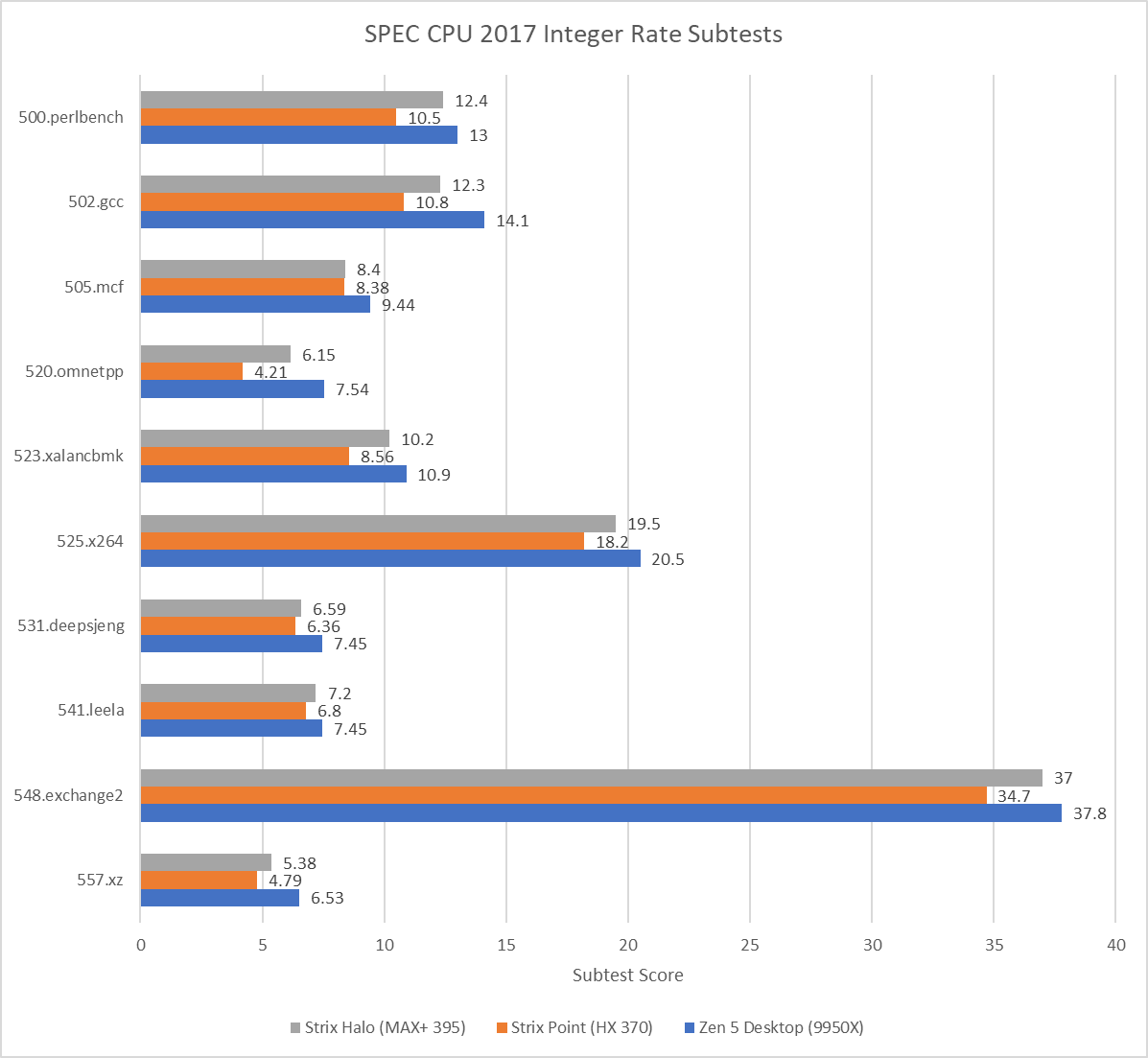
Looking at the SPEC CPU 2017 Integer subtests and while Strix Halo can’t quite match the desktop 9950X, likely due to the higher memory latency of Strix Halo’s LPDDR5X bus, it does get close in a number of subtests.
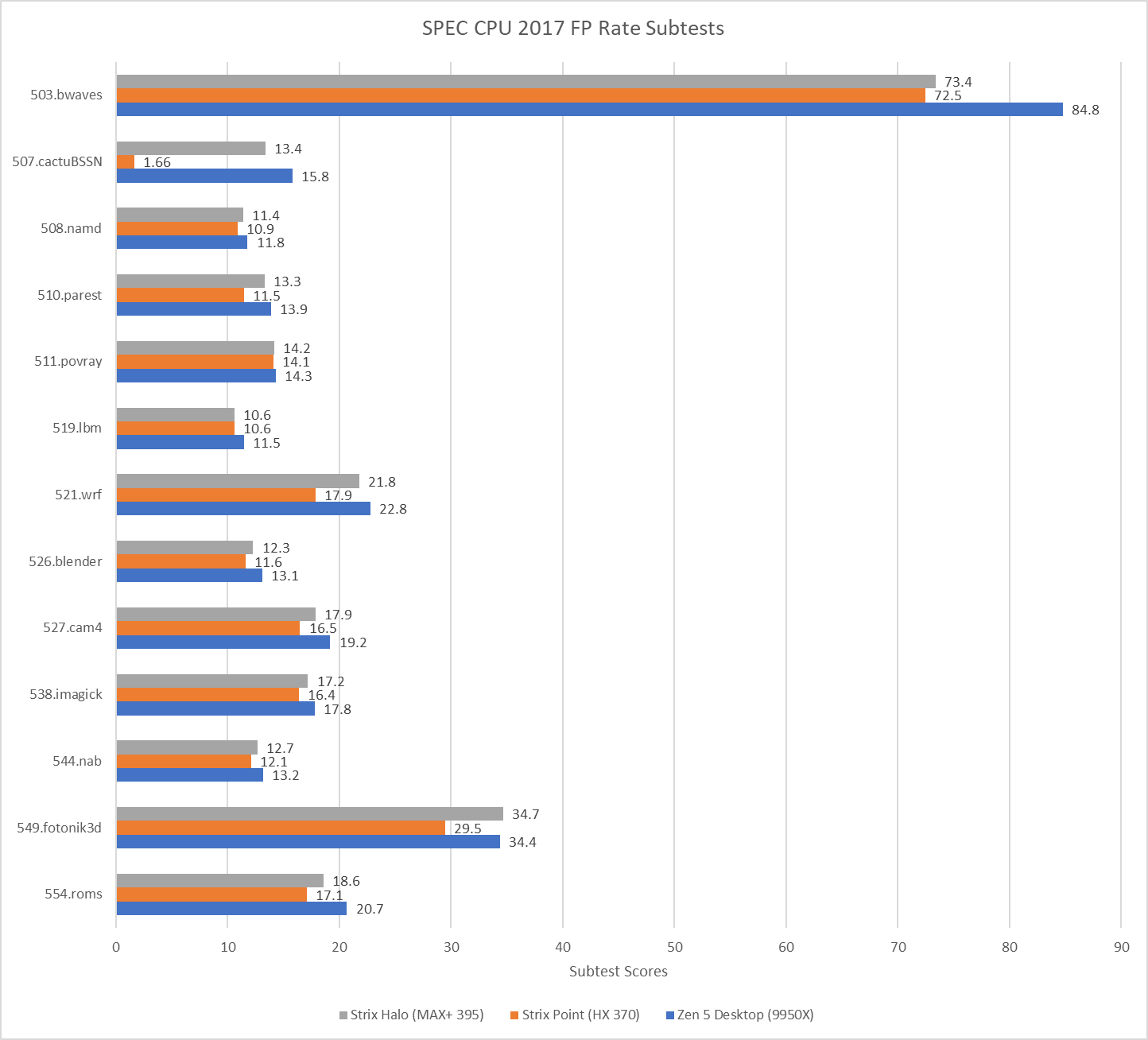
Moving to the FP subtests and the story is similar to the Integer subtests but Strix Halo can get even closer to the 9950X and even beat it in the fotonik3d subtest.
Memory from the GPU’s Perspective
Moving to the GPU side of things and this is where Strix Halo really shines. The laptop we used as a comparison to Strix Halo was the HP Omen Transcend 14 2025 with a 5070M equipped which maxed out at about 75 Watts for the GPU.
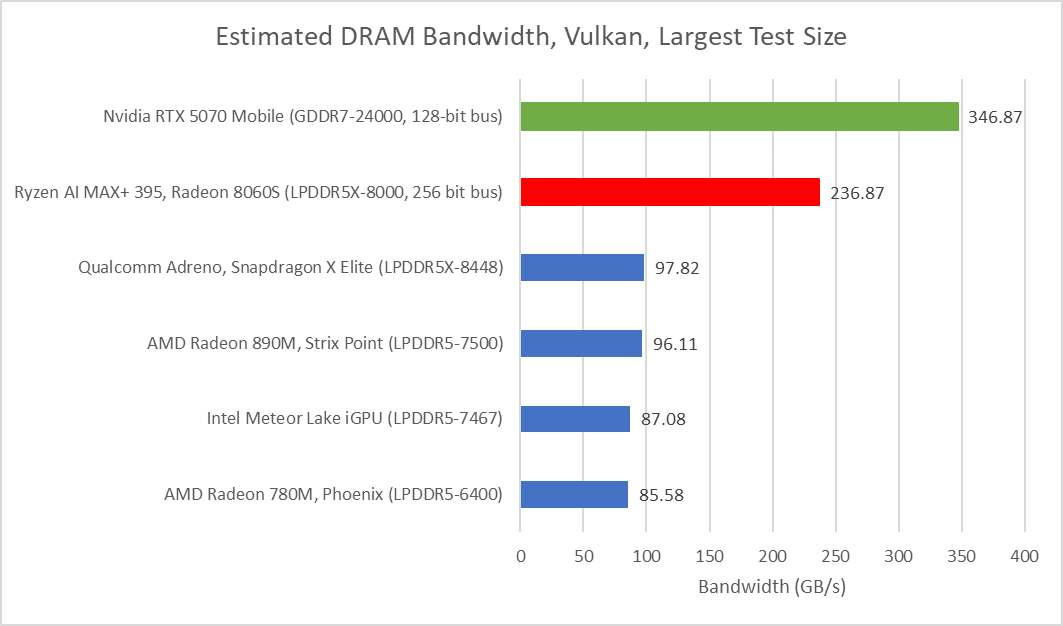
Strix Halo has over double the memory bandwidth of any of the other mobile SoCs that we have tested. However, the RTX 5070 Mobile does have about 50% more memory bandwidth compared to Strix Halo.
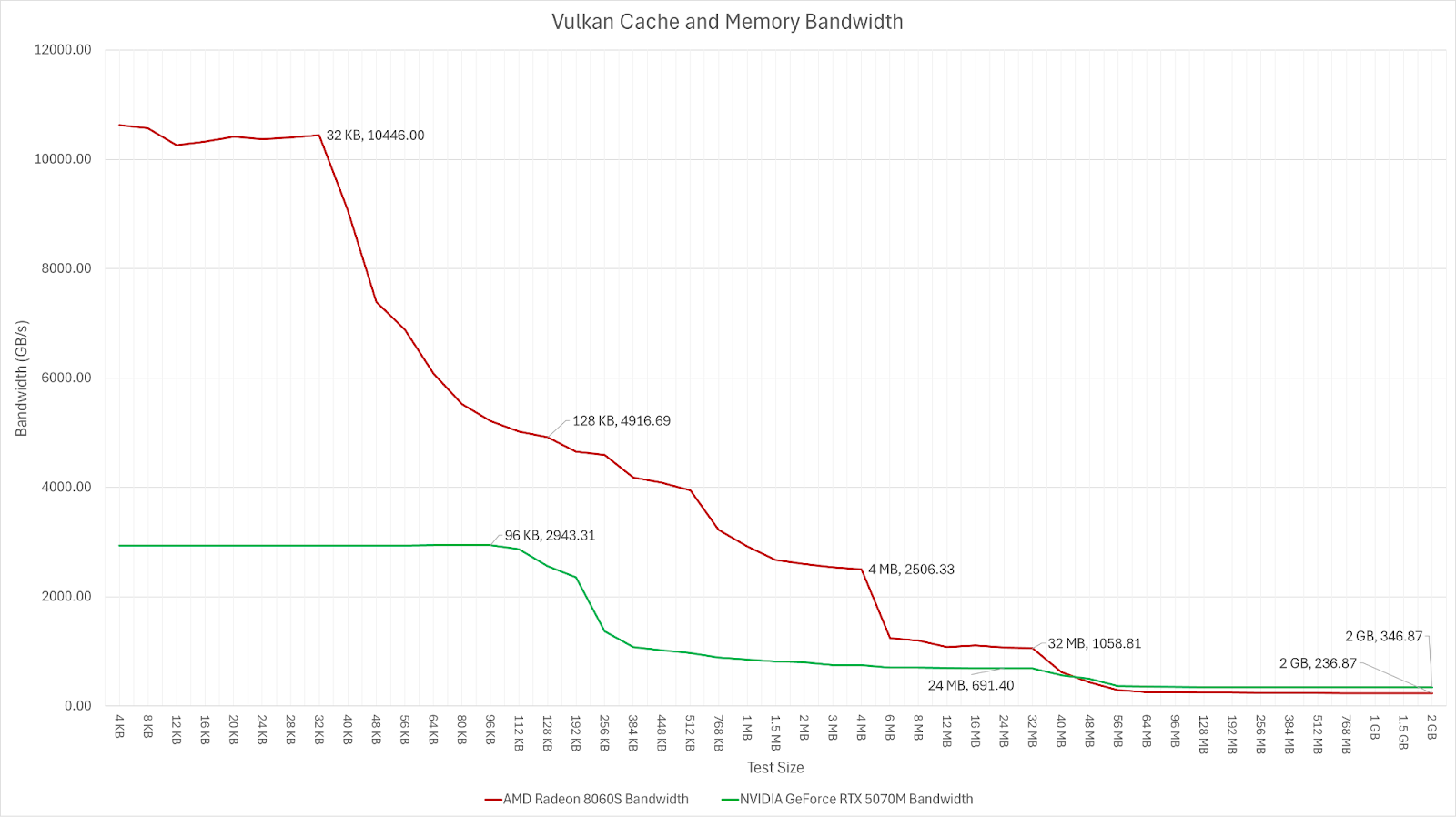
Looking at the caches of Strix Halo, the Infinity Cache, AKA MALL, is able to deliver over 40% higher bandwidth compared to the 5070M’s L2 while having 33% more capacity. Plus Strix Halo has a 4MB L2 which is capable of providing 2.5TB/s of bandwidth to the GPU.
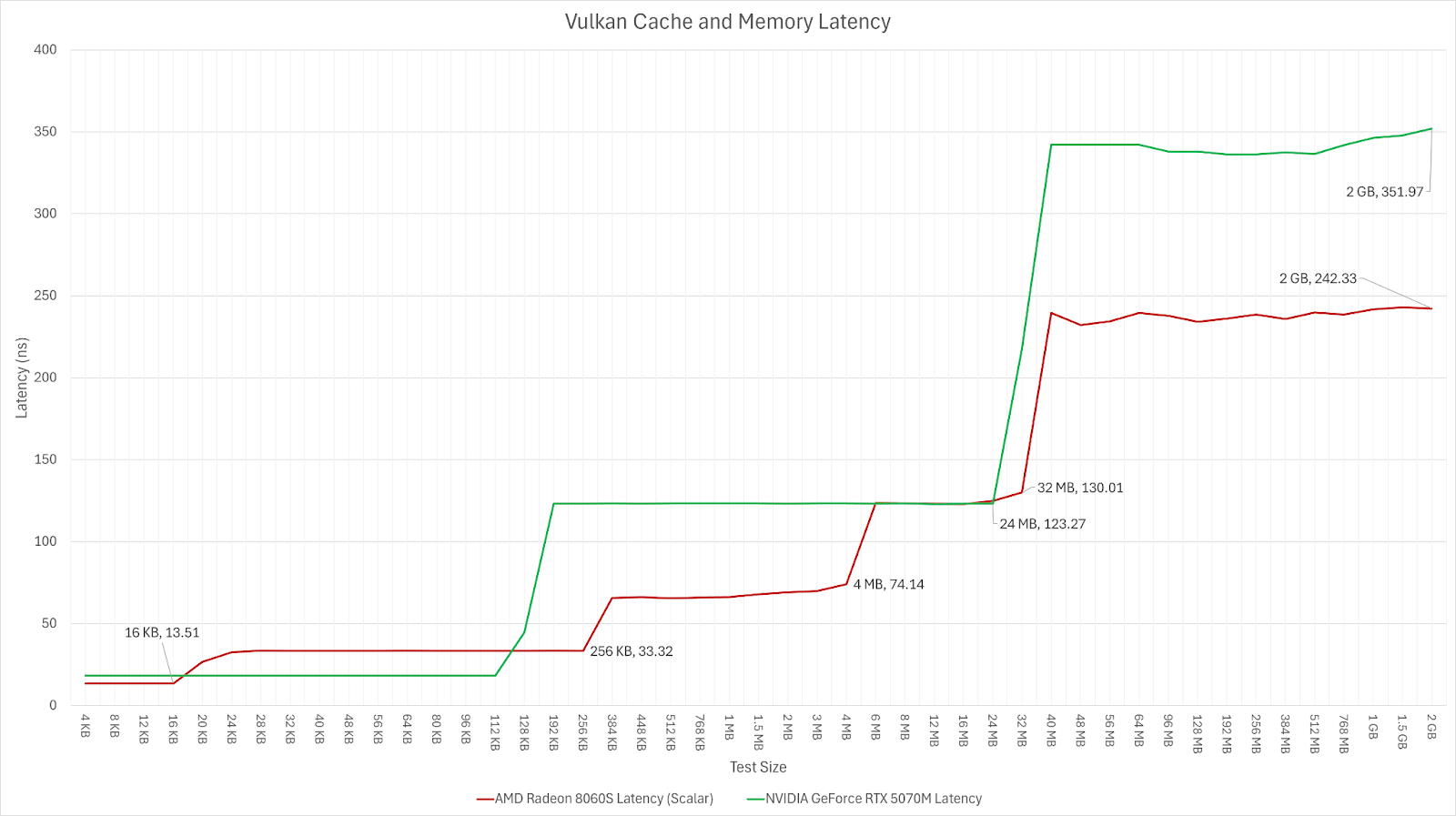
Moving to the latency, the more complex cache layout of Strix Halo does give it a latency advantage after the 128KB with Strix Halo’s L2 being significantly lower latency than the 5070M’s L2 and the larger 32MB MALL that Strix Halo has a similar latency to the 5070M’s L2. And Strix Halo’s memory latency is about 35% lower than the 5070M’s memory latency.
The GPU’s Compute Throughput
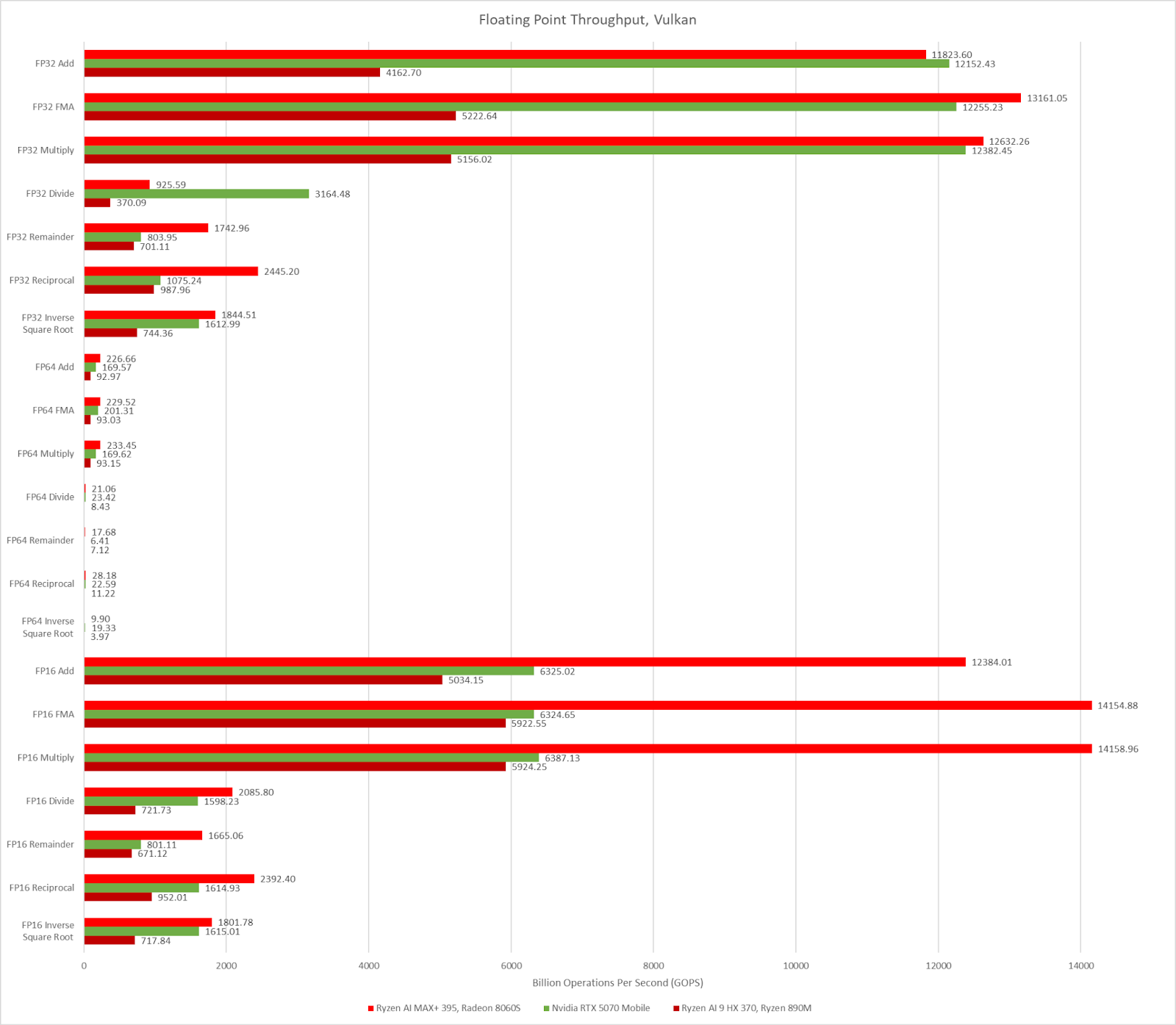
Looking at the floating point throughput, we see that Strix Halo unsurprisingly has about 2.5x the throughput of Strix Point considering it has about two and a half times the number of Compute Units. Strix Halo oftentimes can match or even pull ahead of the 5070 Mobile in terms of throughput. I will note that the FP16 results for the 5070 Mobile are half of what I would expect; the FP16:FP32 ratio for the 5070 Mobile should be 1:1 so I am not positive about what is going on there.
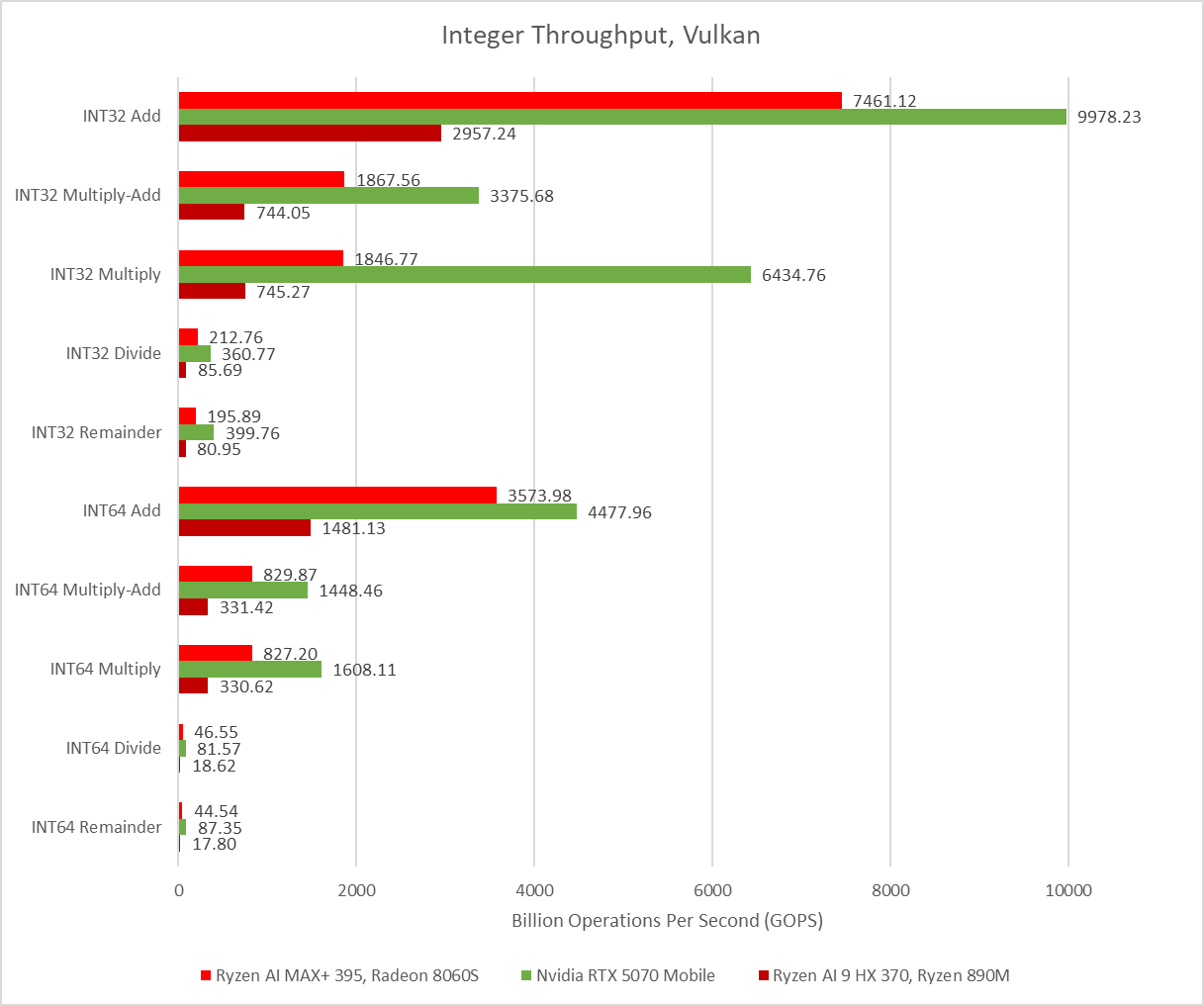
Moving to the integer throughput and we see the 5070 Mobile soundly pulling ahead of the Radeon 8060S.
GPU Performance
Looking at the GPU performance, we see Strix Halo once again shine, with a staggering level of performance available for an iGPU, courtesy of the large CU count paired with relatively high memory bandwidth. Our comparison suite includes several recent iGPU’s from Intel/AMD, along with the newest generation RTX 5070 Mobile @ 75W to act as a reference for mid to high-range laptop dedicated graphics, and the antiquated GTX 1050 as a reference for budget dedicated graphics.
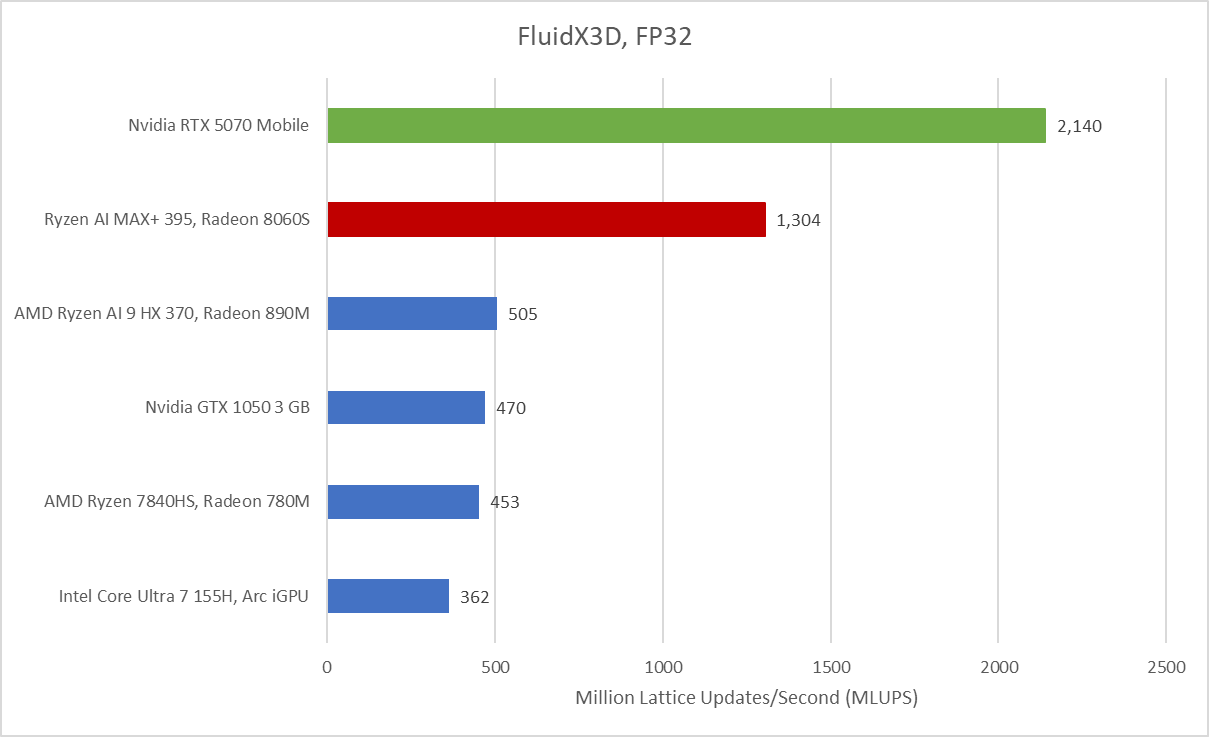
Looking at Fluid X3D for a compute-heavy workload, we can see the Radeon 8060S absolutely obliterates the other iGPU’s from Intel/AMD, putting itself firmly in a class above. The 5070 is no slouch though, and still holds a substantial 64.1% lead largely due to the higher memory bandwidth afforded to the 5070M.
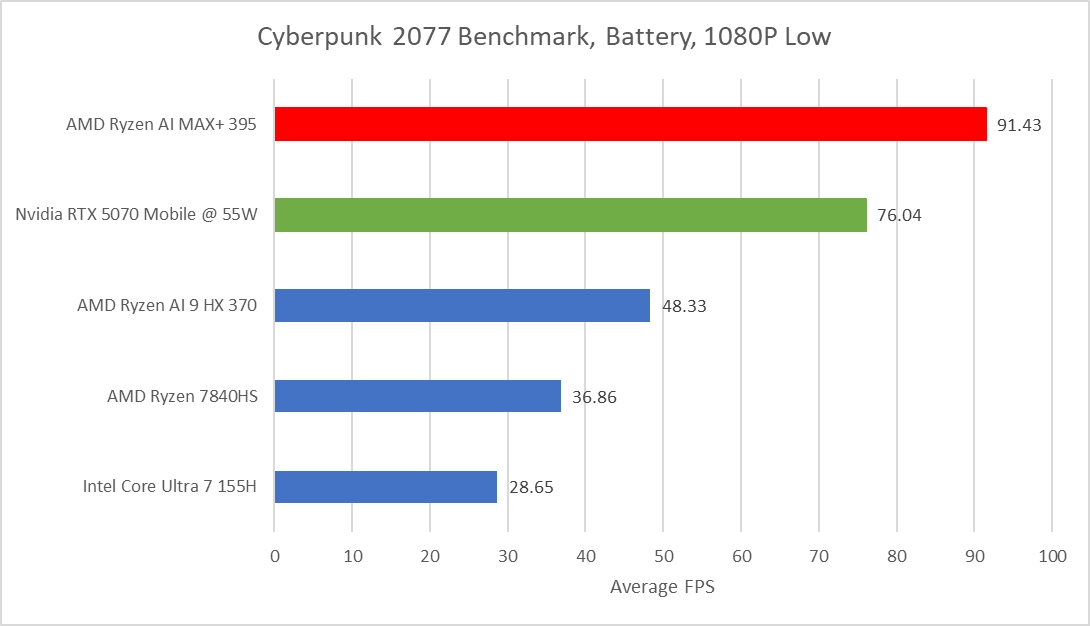
Switching to gaming workloads with Cyberpunk 2077, we start with a benchmark conducted while on battery power. The gap with other iGPU’s is still wide, but now the 5070M is limited to 55W and exhibits 7.5% worse performance at 1080p low settings when compared to the Radeon 8060S.
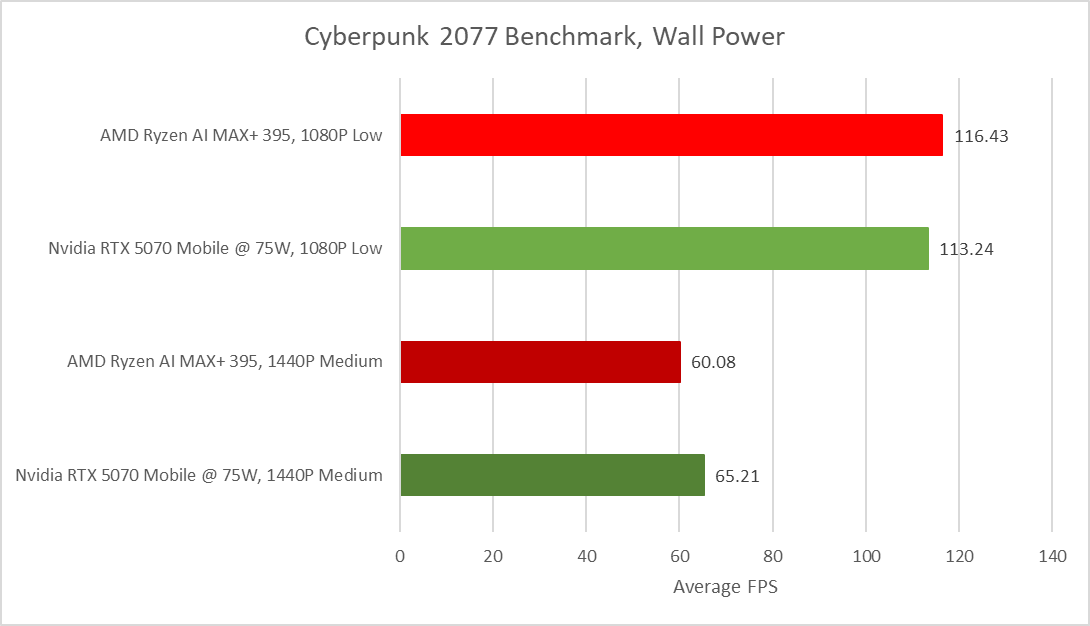
Finally, moving to wall power and allowing both the Radeon 8060S and 5070M to access the full power limit in CP2077, we can see that the 8060S still pulls ahead at 1080p low by 2.5%, while at 1440p medium we see a reversal, with the 5070M commanding an 8.3% lead. Overall the two provide a comparable experience in Cyberpunk 2077, with changes in settings or power limits adjusting the lead between the two. This is a seriously impressive turnaround for an iGPU working against dedicated graphics, and demonstrates the versatility of the chip in workloads like gaming, where iGPU’s have traditionally struggled.
Conclusion
Strix Halo follows in the footsteps of many other companies in the goal of designing an SoC for desktop and laptop usage that is truly all encompassing. The CPU and GPU performance is truly a class above standard low power laptop chips, and is even able to compete with larger systems boasting dedicated graphics. CPU performance is especially impressive with a comparable showing to the desktop Zen 5 CPUs. GPU performance is comparable to mid range dedicated graphics, while still offering the efficiency and integration of an iGPU. High end dedicated graphics still have a place above Strix Halo, but the versatility of this design for smaller form factor devices is class leading.

However, this is not to say that Strix Halo is perfect. I was hoping to have a section dedicated to the ML performance of Strix Halo in this article, however AMD only just released preview support for Strix Halo in the ROCm 7.0.2 release which came out about a week ago from time of publication. As a result of the long delay between the launch of Strix Halo and the release of ROCm 7.0.2, the ML performance will have to wait until a future article.
However, putting aside ROCm, Strix Halo is a very, very cool piece of technology and I would love to see successors to Strix Halo with newer CPU and GPU IP and possibly even larger memory buses similar to Apple’s Max and Ultra series of SoCs with 512b and 1024b memory respectively. AMD has a formula for building bigger APUs with Strix Halo, which opens the door to a lot of interesting hardware possibilities in the future.
If you like the content then consider heading over to the Patreon or PayPal if you want to toss a few bucks to Chips and Cheese. Also consider joining the Discord.
ML workloads will be really interesting. An ok sized GPU with access to 128GB of RAM could be faster than any other consumer device in cases where those just can't fit the model into memory. Intels B60 showed already that memory alone can make a difference.
Thank you for the article!
Could you double check the rtx 5070 mobile cache bandwith, i think it's not correct data.
In theory blackwell sm can reach 128 byte/clock cycle from L1. Of course it's the upper limit.
But in the article of rtx pro 6000 blackwell one sm can ca. 100 byte/clock cyle.
If we do the math with this number, and suppose a minimal 1.5 ghz operating frequency and the sm count of 5070M which is 36, than the l1 bandwith should be 36*100*1.5 Gbyte/sec which is 5400 Gbyte/sec. If we suppose 2 ghz opperating frequency than we reach 7200 Gbyte/sec and at 2.5 ghz 9000 Gbyte/ sec. So why is this big difference between your measurement (ca. 3000 Gbyte/sec) and the math. Thank you verry much for the answer, and sorry about my english!