
AMD Disables Zen 4's Loop Buffer

A loop buffer sits at a CPU's frontend, where it holds a small number of previously fetched instructions. Small loops can be contained within the loop buffer, after which they can be executed with some frontend stages shut off. That saves power, and can improve performance by bypassing any limitations present in prior frontend stages. It's an old but popular technique that has seen use by Intel, Arm, and AMD cores.

As far as I know, Zen 4 is the only high performance AMD core with a loop buffer. Zen 4's Processor Programming Reference mentions it as a micro-op dispatch source, alongside the op cache and decoder. Experimenting with performance counters suggests the loop buffer has 144 entries when the core is running on one thread, and is statically partitioned to give each thread 72 entries when two SMT threads are active. Calls and returns within a loop will prevent it from being captured by Zen 4's loop buffer. AMD's Zen 4 optimization guide makes no mention of the loop buffer and only suggests keeping hot code regions within the op cache's capacity.

From side discussions with AMD employees at Hot Chips 2024, the loop buffer was primarily a power optimization. I never heard AMD discuss the loop buffer elsewhere. That's likely because the loop buffer isn't an important feature from a performance perspective. The op cache can already deliver more bandwidth than the core's downstream rename/allocate stage can consume.
After I updated my ASRock B650 PG Lightning to BIOS version 3.10, hardware performance monitoring indicated the frontend no longer dispatched any micro-ops from the loop buffer. Reverting to BIOS version 1.21 showed the loop buffer was active again. AMD must have disabled the loop buffer somewhere between BIOS 1.21 (AGESA version 1.0.0.6) and BIOS 3.10 (AGESA version 1.2.0.2a). They did so without any announcement or fanfare.
SPEC CPU2017: Looking for Differences
SPEC CPU2017 scores suggest no notable difference with the loop buffer on and off. Total scores for the integer and floating point suites differ by less than 1%. SMT performance gains are also not affected.

None of that comes as a surprise. Again, the op cache provides more than enough bandwidth to feed the renamer. Moreover, performance counters indicate the loop buffer only delivers a small minority of micro-ops, even when enabled. Zen 4 largely feeds itself using the op cache.

523.xalanbmk sees a significant minority of its instruction stream covered by the loop buffer. However, even the subscore changes for that test land within margin of error. It scored 9.48 on the new BIOS, versus 9.44 before. Much of the same applies across SPEC CPU2017's floating point suite. 544.nab has nearly a quarter of its micro-ops delivered from the loop buffer, yet its score actually increased by 1.7% with the loop buffer off (11.7 on the new BIOS, 11.5 before). That could be run to run variance, but overall it's clear turning off the loop buffer didn't cause performance loss.
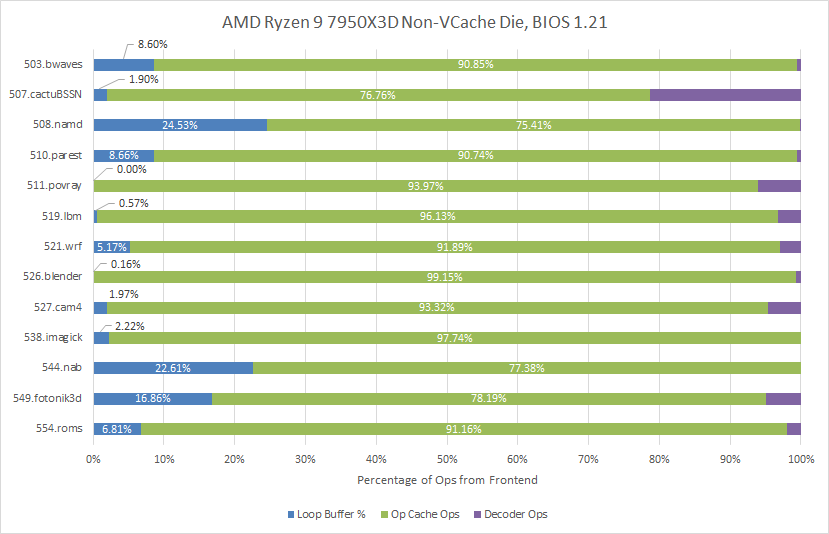
Going over the same performance counter data on the new BIOS shows Zen 4's op cache picking up the slack. The op cache handles an even larger majority of the instruction stream.
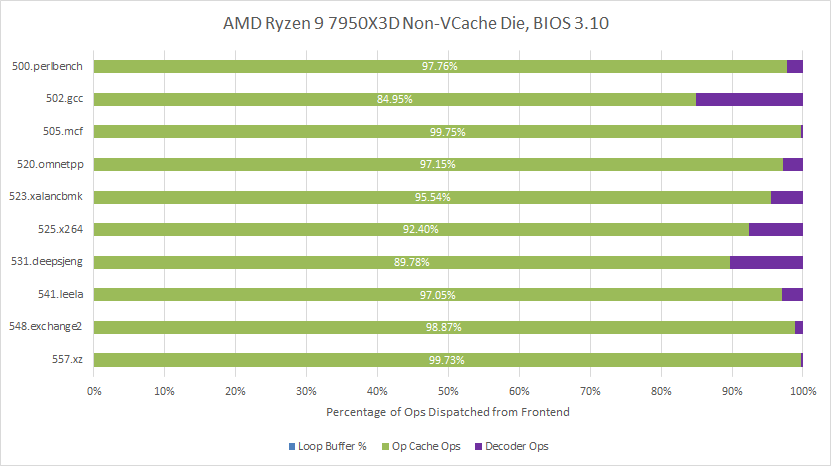
SPEC CPU2017's floating point suite sees a similar pattern. 507.cactuBSSN sees op cache coverage dip somewhat, causing the decoders to deliver about a quarter of total micro-ops. I'm not sure what's going on with that, but it's worth remembering performance counters typically give a general idea of what's going on rather than being 100% accurate. Ops dispatched from the frontend is also a speculative event, and can be influenced for example by incorrectly fetched instructions past a mispredicted branch.

Other cases like 544.nab or 508.namd behave as you'd expect. The loop buffer used to cover 20-something percent of the incoming micro-op stream, but now the op cache does nearly everything. In summary, disabling the loop buffer causes Zen 4 to move from running the vast majority of code from the op cache, to running the overwhelming majority of code from the op cache. It's not very interesting from a performance point of view.
Count Masking
But the loop buffer's primary goal is not to increase performance. Instead, it tries to let the core opportunistically shut off much of the frontend, including the op cache. AMD (and Intel) have excellent hardware performance monitoring facilities that include count masking capabilities.

That is, a performance counter can be programmed to increment by one when event count exceeds a threshold. Setting the threshold to 1 lets me count how many cycles each micro-op delivery source was actively supplying micro-ops. That in turn gives me an estimate of how often the core can power off its frontend with the loop buffer enabled.

How often each op delivery source is active aligns pretty well with the percentage of micro-ops they deliver. In addition, this data also shows the frontend can spend a good percentage of cycles delivering nothing at all. 502.gcc and 520.omnetpp for example are heavily bound by backend memory latency. Often the out-of-order execution engine can't keep enough instructions in flight to hide that latency. That in turn means the frontend has to idle, because it can't send any more instructions down to the backend until some get cleared out.
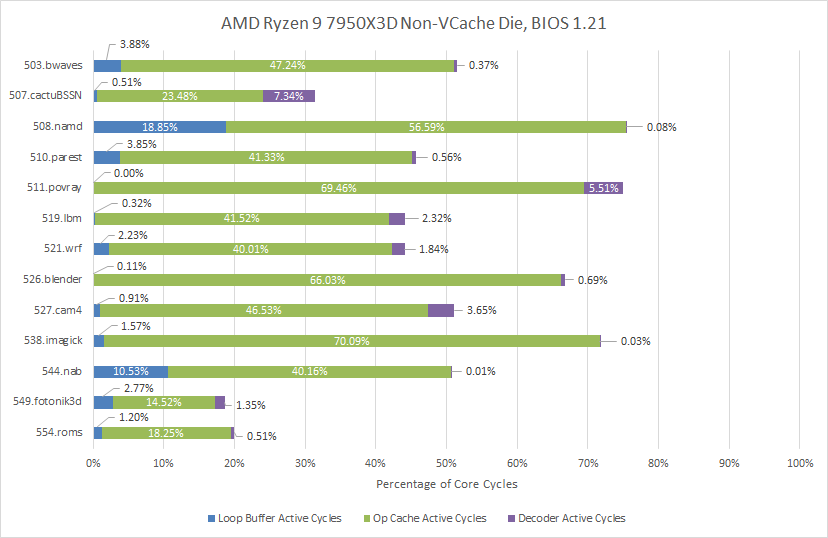
In SPEC CPU2017's floating point suite, 544.nab and 508.namd see the loop buffer active for a decent percentage of core cycles. 508.namd may be particularly interesting because it's a high IPC workload (3.64 IPC), which means the frontend has to sustain high throughput. 508.namd is also friendly to the loop buffer, so it's a good opportunity to save power by shutting off the op cache.
With the loop buffer disabled, Zen 4's op cache feeds the core over more cycles. But in most tests, the difference isn't that big. 523.xalanbmk is an exception. There, the op cache has to be active for an extra 12% of core cycles without the loop buffer.

Other workloads see far less difference. 548.exchange2 is a high IPC workload in the integer suite, averaging an incredible 4.31 IPC. The frontend has to deliver a lot of throughput, but the loop buffer is basically absent even when enabled. Evidently 548.exchange2 doesn't spend a lot of time in tiny loops. The op cache is busy for over 85% of core cycles even with the loop buffer enabled.

508.namd was an interesting example from the floating point suite. Indeed, disabling the loop buffer leads to the op cache being active over 75.1% of core cycles, compared to 56.67% with the loop buffer enabled.
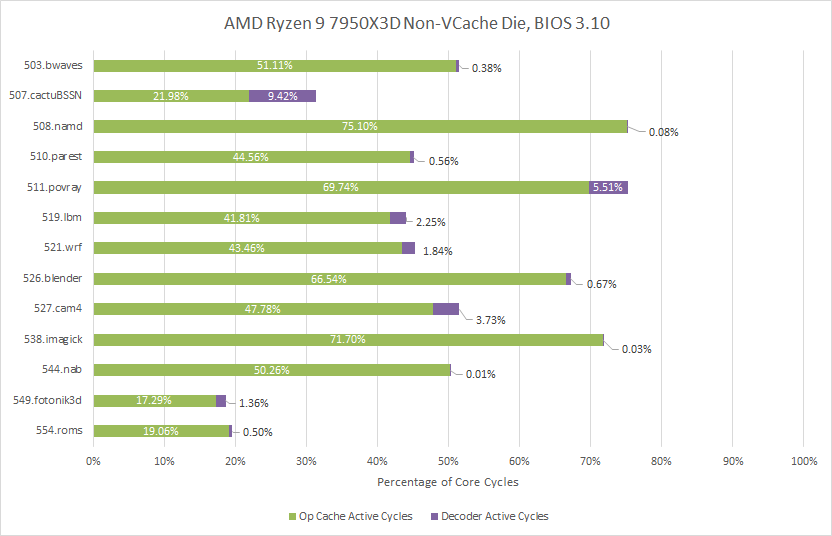
But 508.namd is an exception in my opinion. Differences are minimal elsewhere. A 144 entry loop buffer just isn't big enough to contain much of the instruction stream. The loop buffer only has potential to make a notable impact when a program spends much of its runtime in tiny loops, and is also not bound by backend throughput or latency.

From this look at SPEC CPU2017 with frontend performance monitoring data, I think disabling the loop buffer is inconsequential. Even from a power savings perspective, the loop buffer only lets the core shut off the op cache over a tiny percentage of cycles.
Cyberpunk 2077
Cyberpunk 2077 is a game where you can sneak and hold tab while looking at enemies. It features a built-in benchmark, letting me conveniently check on whether disabling the loop buffer might impact gaming performance.
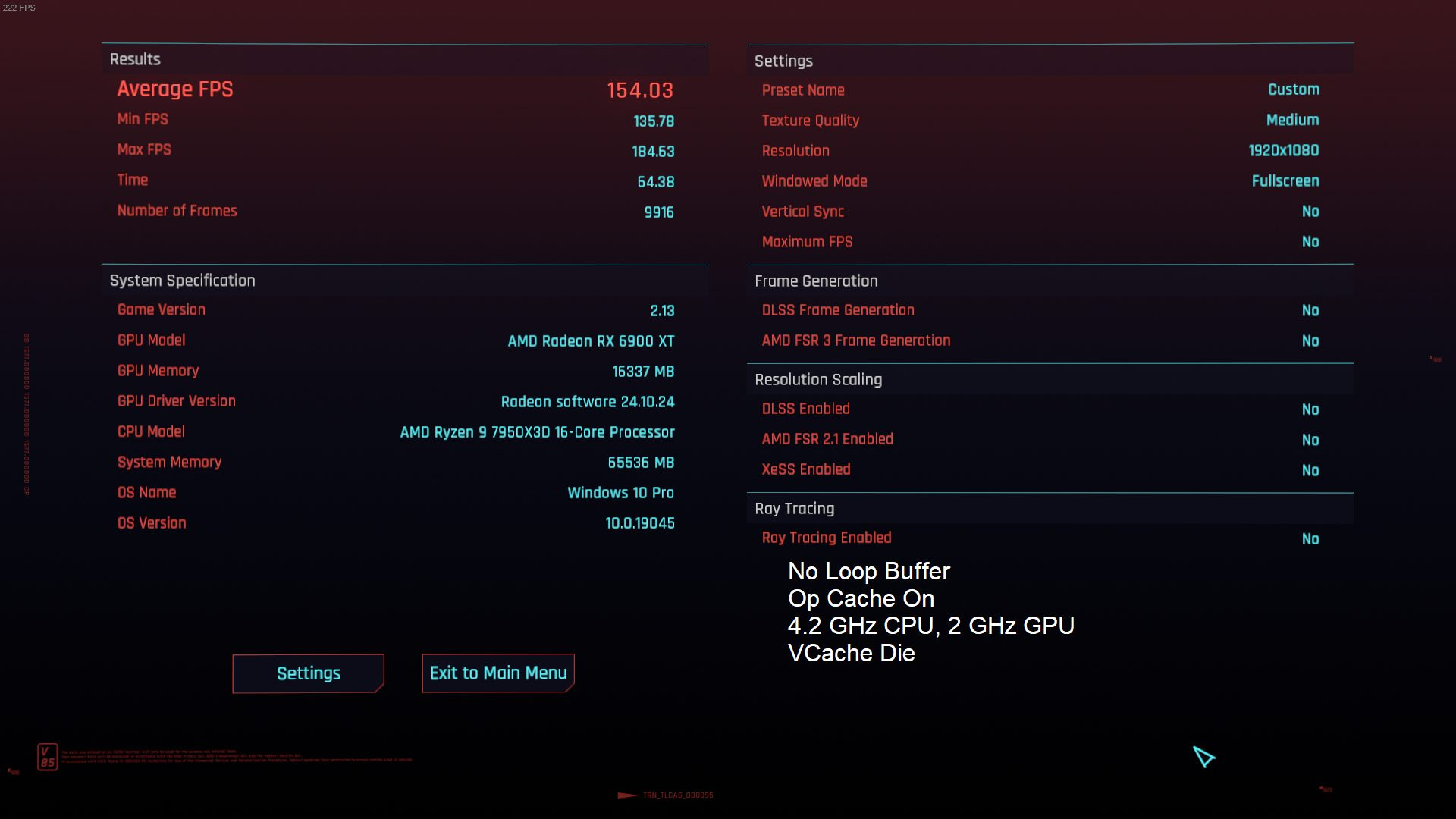
Because I expect negligible performance differences with the loop buffer disabled, I ran the benchmark with an unusual setup to maximize consistency. I disabled Core Performance Boost on the Ryzen 9 7950X3D by setting bit 25 of the Hardware Configuration register (MSR 0xC0010015). That limits all cores to 4.2 GHz. I also capped my RX 6900 XT to 2 GHz. For benchmark settings, I'm using the medium preset at 1080P with no upscaling.

Disabling the loop buffer basically doesn't affect performance with the game pinned to the VCache die. Strangely, the game sees a 5% performance loss with the loop buffer disabled when pinned to the non-VCache die. I have no explanation for this, and I've re-run the benchmark half a dozen times.
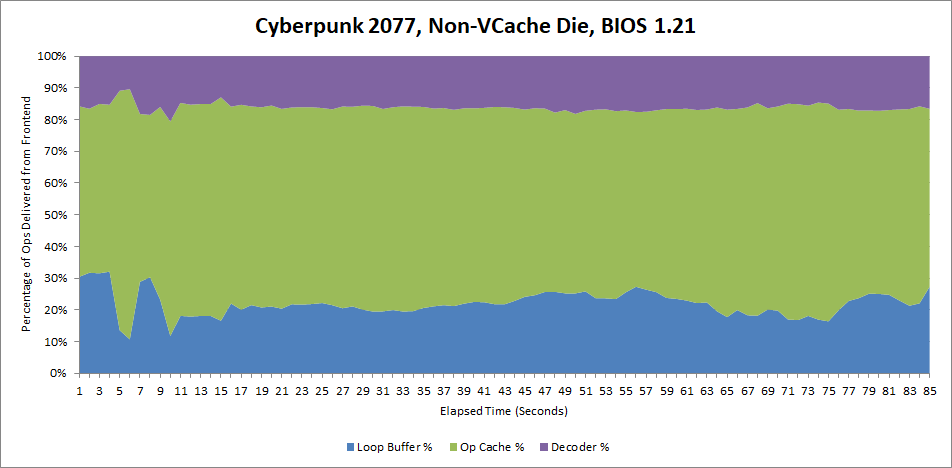
Cyberpunk 2077 is unexpectedly friendly to the loop buffer, which covers about 22% of the instruction stream on average. Disabling the loop buffer causes the op cache to deliver 82% of micro-ops, up from 62% before.

There's a lot of action in Cyberpunk 2077, but most of it doesn't happen at the CPU's frontend.

Disabling the loop buffer of course doesn't change that.
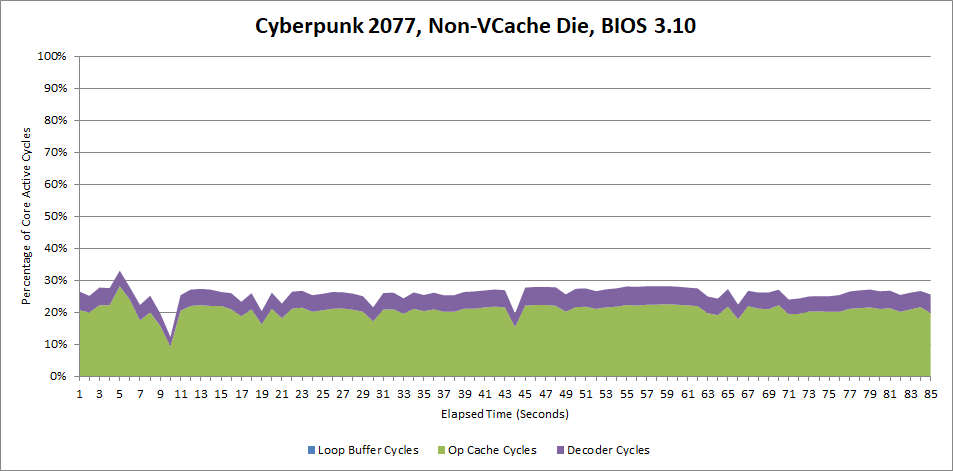
But because the loop buffer covers a significant minority of the instruction stream, turning it off does mean the op cache works harder.
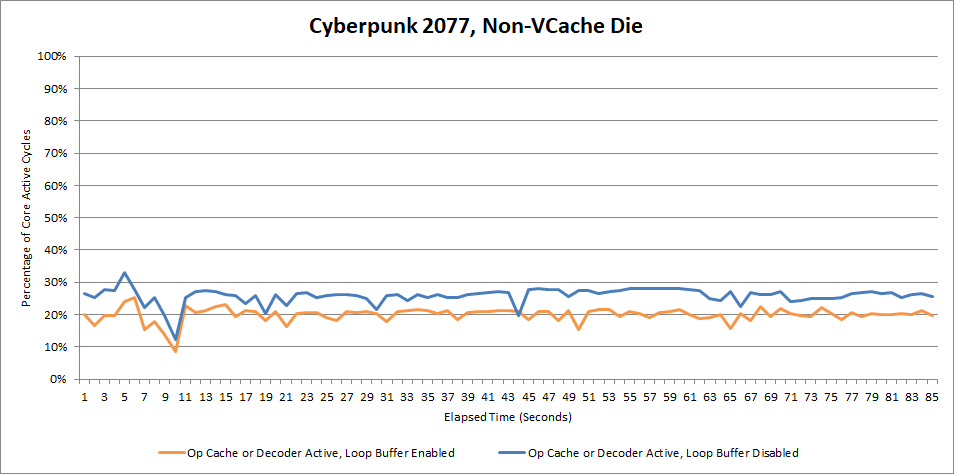
Again, it's not a big difference. With an average IPC of 0.89 with the loop buffer disabled, or 1.02 with the loop buffer enabled, Cyberpunk 2077 is not a high IPC workload. That means frontend bandwidth isn't a big consideration. Perhaps the game is more backend bound, or bound by branch predictor delays.
Still, the Cyberpunk 2077 data bothers me. Performance counters also indicate higher average IPC with the loop buffer enabled when the game is running on the VCache die. Specifically, it averages 1.25 IPC with the loop buffer on, and 1.07 IPC with the loop buffer disabled. And, there is a tiny performance dip on the new BIOS. Perhaps I'm pushing closer to a GPU-side bottleneck at 155 FPS. But I've already spent enough free time on what I thought would be a quick article. Perhaps some more mainstream tech outlets will figure out AMD disabled the loop buffer at some point, and do testing that I personally lack the time and resources to carry out.
Attempt at Checking Power Draw
I also tried to look at Zen 4's core power counters to see whether running from the loop buffer improved power efficiency. To do this, I had to modify my instruction bandwidth benchmark to not use calls or returns in the test section. Apparently, calls or returns cause Zen 4 to not use the loop buffer.

I also pinned the test to one core and read the Core Energy Status MSR before and after jumping to my test array, letting me calculate average power draw over the test duration. For consistency, I disabled Core Performance Boost because power readings would vary wildly with boost active.

Results make no sense. On the old BIOS, the Core Energy Status MSR tells me the core averaged 6W of power draw when fetching NOPs from the op cache, and much lower power when doing the same from the loop buffer. Next, I increased the test array size until performance counters showed op cache coverage dropping to under 1%. By that time, the array size had gone well into L2 capacity (128 KB). But even though exercising the decoders and L2 fetch path should increase power draw, the Core Energy Status MSR showed just 1.5W of average core power.
Updating to the new BIOS gave 1.68W of average core power when testing the op cache, and nearly the same power when feeding the decoders mostly from L2. That means the core is achieving better efficiency when running code from the op cache, and makes sense. Of course, I can't test the loop buffer on the new BIOS because it's disabled.
To make things even more confusing, AMD's power monitoring facilities may be modeling power draw instead of measuring it1. There's a distinct possibility AMD modeled the power draw wrong, or changed the power modeling methodology between the two BIOS versions. I don't have power measuring hardware to follow up on this. I feel like I don't understand the power draw situation any more than when I started, and a few hours have gone to waste.
Final Words
I don't know why AMD disabled Zen 4's loop buffer. Sometimes CPU features get disabled because there's a hardware bug. Intel's Skylake saw its loop buffer (LSD) disabled due to a bug related to partial register access in short loops with both SMT threads active. Zen 4 is AMD's first attempt at putting a loop buffer into a high performance CPU. Validation is always difficult, especially when implementing a feature for the first time. It's not crazy to imagine that AMD internally discovered a bug that no one else hit, and decided to turn off the loop buffer out of an abundance of caution. I can't think of any other reason AMD would mess with Zen 4's frontend this far into the core's lifecycle.
Turning off the loop buffer should have little to no impact on performance because the op cache has more than enough bandwidth to feed the subsequent rename/allocate stage. Impact on power consumption is an unknown factor, but I suspect it's also minor, and may be very difficult to evaluate even when using expensive hardware to measure CPU power draw at the 12V EPS connector.

AMD's move to disable Zen 4's loop buffer is interesting, but should go largely unnoticed. AMD never advertised or documented the feature beyond dropping a line in the Processor Programming Reference. It's a clear contrast to Intel, which often documents its loop buffer and encourages developers to optimize their code to take advantage of it.

Combine that with what looks like minimal impact on performance, and I doubt anyone will ever know that AMD turned the loop buffer off. It was a limited feature in the first place, with low capacity and restrictions like no function calls that prevent it from being as useful as an op cache.
Perhaps the best way of looking at Zen 4's loop buffer is that it signals the company has engineering bandwidth to go try things. Maybe it didn't go anywhere this time. But letting engineers experiment with a low risk, low impact feature is a great way to build confidence. I look forward to seeing more of that confidence in the future.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.
References
Robert Schöne et al, Energy Efficiency Aspects of the AMD Zen 2 Architecture
Appendix
Since AMD never offered optimization advice related to the loop buffer, I'll do it. On Zen 4 running an old BIOS version, consider sizing loops to have less than 144 micro-ops, or half that if threads share a physical core. Consider inlining a function called within a small loop to avoid CALL/RET instructions. Do this, and your reward will most likely be absolutely nothing. Have fun.
Restrictions like no CALL/RET could indicate Zen 4 shuts off certain parts of the branch predictor in addition to the op cache and decoder. That could add to power
I can only assume you considered and rejected this idea for an explanation for the confusing performance drop in Cyberpunk, but just in case... I'd put my money on some difference other than the disabled loop buffer between the different firmware versions.
Intel has apparently disabled the LSD on Skylake (SKL150 erratum) and Kaby Lake (KBL095, KBW095 erratum) chips via a microcode update and on Skylake-X out of the box, due to a bug related to the interaction between hyperthreading and the LSD