
Lunar Lake’s iGPU: Debut of Intel’s Xe2 Architecture

Intel has a long history of making integrated GPUs, and they’ve recognized how important iGPUs are to thin and light laptops. Today Intel is locked in fierce competition with AMD, and the company’s fight to hold on to the laptop market is no less intense on the graphics front. Lunar Lake is Intel’s latest mobile offering, and brings with it a new Xe2 graphics architecture. Xe2 is an evolution of the Xe-LPG/HPG architectures used on the outgoing Meteor Lake mobile chips and Intel’s current Arc discrete GPUs. It aims to better fit expected workloads and improve efficiency, and will be used across both Lunar Lake and Intel’s upcoming “Battlemage” discrete GPUs.

Here I’ll be looking at the Arc 140V iGPU in the Core Ultra 7 258V. ASUS has kindly provided a Lunar Lake laptop for testing. Without their support, this article would not be possible.

For comparisons I’ll be using the iGPU in Intel’s outgoing Meteor Lake, as well as the RDNA 3.5 iGPU in AMD’s competing Strix Point.
GPU Overview
Modern GPUs are modular, scalable designs and Intel’s Xe2 is no different. An Xe2 iGPU is built from Xe Cores, much like how AMD’s RDNA GPUs are built from WGPs (Workgroup Processors) or how Nvidia’s GPUs are built from SMs (Streaming Multiprocessors). Lunar Lake’s iGPU features eight Xe Cores, further divided into two Render Slices with four Xe Cores each. These Render Slices include fixed function graphics hardware like a rasterizer and pixel backends (ROPs). Lunar Lake’s iGPU is therefore laid out similarly to Meteor Lake’s iGPU, which also has eight Xe Cores split across two Render Slices.
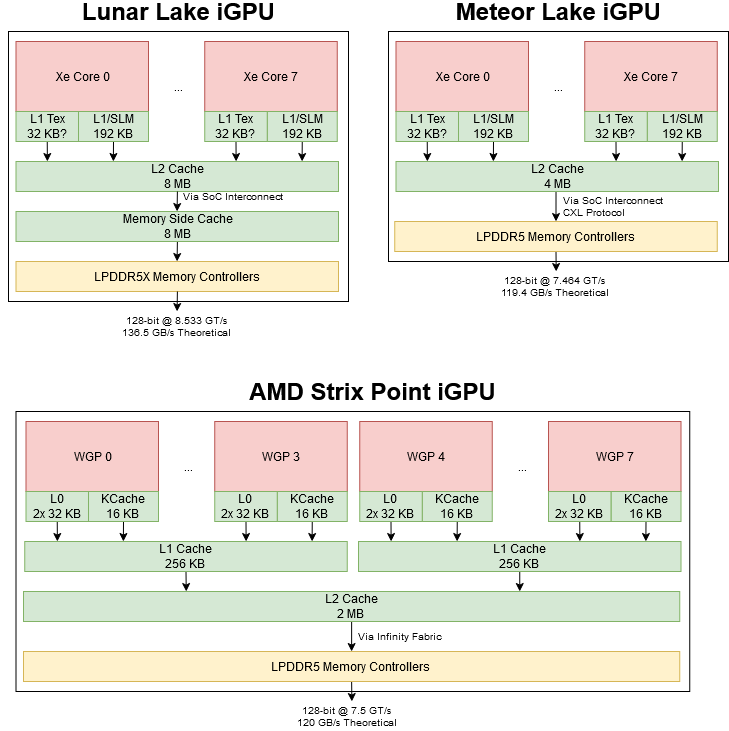
Intel’s Render Slice vaguely corresponds to AMD’s Shader Array, which also includes a rasterizer and ROPs. AMD also has a mid-level L1 cache at the Shader Array level, with 256 KB of capacity on RDNA 3.5. Intel also has caches at the Render Slice level, though only for fixed function graphics hardware. The figure below should be taken with a grain of salt because Intel has not published documentation for Xe-LPG, so I’m taking figures from the closely related Xe-HPG. I also find Intel’s documentation confusing. For example, each pixel backend should have its own color cache, but something changed after Tiger Lake and Intel only documents one color cache instance per slice despite drawing it twice in other diagrams.

Xe2 aims to improve efficiency for fixed function units, and part of that involves better caching. The hierarchical Z cache helps reject occluded geometry before it gets past the rasterizer by remembering how far triangles are from the camera. Its capacity increases by 50% on Xe2, from 4 to 6 KB. At the other end of the pipeline, color cache capacity has increased by 33%. Xe-HPG had 16 KB of color cache capacity in each slice, so a 33% increase doesn’t make so much sense. Perhaps Xe-LPG had a larger 24 KB color cache. In that case, a 33% increase would bring capacity to 32 KB.
Xe2’s new Xe Cores
Xe Cores are the basic building block of Intel’s GPUs, and are further divided into Vector Engines that have register files and associated execution units. Xe2 retains the same general Xe Core structure and compute throughput, but reorganizes the Vector Engines to have longer native vector widths. Pairs of 8-wide Vector Engines from Meteor Lake have been merged into 16-wide Vector Engines. Lunar Lake’s Xe Core therefore has half as many Vector Engines, even though per-clock FP32 vector throughput hasn’t changed.

Intel here is completing a transition aimed at reducing instruction control overhead that began with prior generations. Longer vector widths improve efficiency because the GPU can feed more math operations for a given amount of instruction control overhead. Meteor Lake’s Xe-LPG already tackled instruction control costs by using one instance of thread/instruction control logic for a pair of adjacent vector engines.
But using less control logic makes the GPU more vulnerable to branch divergence penalties. That applied in funny ways to Xe-LPG, because sharing control logic forced pairs of Vector Engines to run in lockstep. A Vector Engine could sit idle if its partner had to go down a different execution path.

Because there wasn’t a lot of point in keeping the Vector Engines separate, Intel merged them. The merge makes divergence penalties straightforward too, since each Vector Engine once again has its own thread and instruction control logic. Meteor Lake could do better in corner cases, like if groups of 16 threads take the same path. But that’s an awfully specific pattern to take advantage of, and Xe2’s divergence behavior is more intuitive. Divergence penalties disappear once groups of 32 threads or more take the same path.
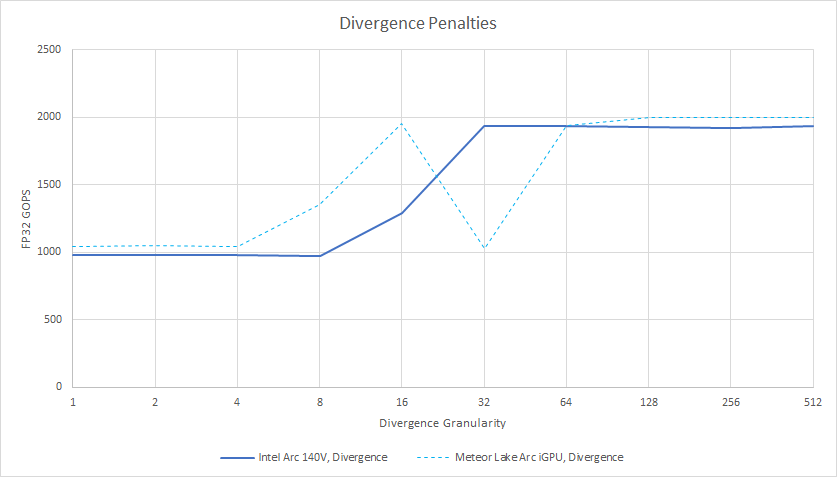
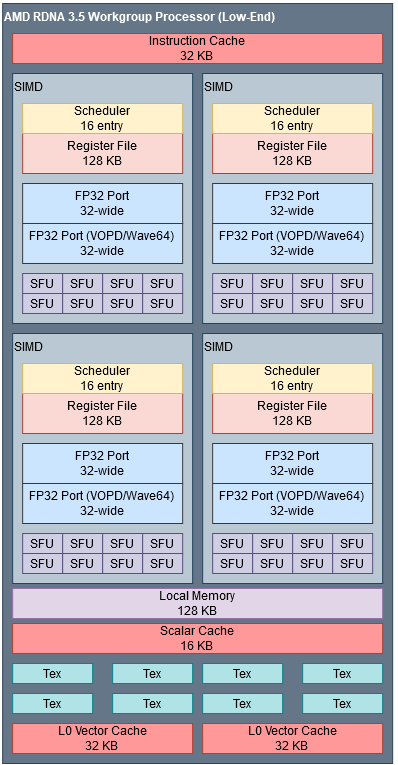
Even though Intel’s execution unit partitions have gotten bigger, they’re still small compared to AMD’s. RDNA 3.5’s SIMDs are equivalent to Intel’s Vector Engines, as both blocks have a register file feeding a set of execution units. AMD’s SIMDs can do 64 FP32 operations per cycle compared to 16 on Intel’s Vector Engines. However, comparisons are complicated because AMD has to use wave64 mode or compiler magic in wave32 mode to feed all of its FP32 lanes.
Compute Throughput
Lunar Lake’s iGPU offers very similar throughput compared to the prior generation, which isn’t a surprise because both have eight Xe Cores. The Core Ultra 7 155H (Meteor Lake) has a slightly higher 2.25 GHz maximum GPU clock than the Core Ultra 7 258V at 1.95 GHz. Sometimes Xe2’s architectural improvements make feeding the execution units easier, so some tests show improvement.

Still, AMD’s Strix Point has a huge compute throughput advantage for common FP32 operations. AMD’s WGPs have twice as much per-cycle throughput as Intel’s Xe Cores, and AMD can clock their iGPU up to 2.9 GHz. Even if dual issue limitations prevent Strix Point from feeding all its execution units, AMD has a significant compute throughput advantage.

Intel can catch up in some less common integer operations like INT32 multiplies. 64-bit integer performance has dramatically improved on Lunar Lake compared to Meteor Lake, but it’s not enough to catch AMD.
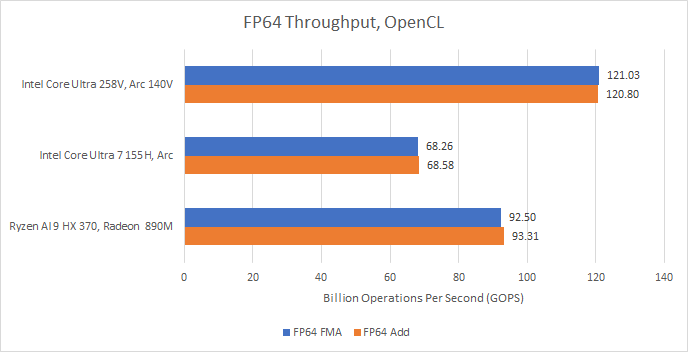
FP64 is another area where Intel catches AMD. Lunar Lake seems to have doubled FP64 throughput compared to its predecessor. None of these GPUs are good at FP64 compute, but Intel is ahead now.
Matrix Units
Matrix units are back in Lunar Lake after being absent in Meteor Lake’s iGPU. Each Vector Engine gets a 2048-bit XMX unit, offering four times as much throughput as the 512-bit vector execution units for the same data types.

In addition, the XMX units support lower precision data types all the way down to INT2. From Intel’s video, they appear to work in SIMD16 mode on a 4×4 matrix with INT8 precision. Per cycle, a lane computes results for a 4-long row of the result matrix. Higher precision data types like FP16 are handled by operating on smaller chunks at a time. AMD RDNA 3.5 has WMMA instructions for matrix multiplication. WMMA operates on larger 16x16x16 matrices, and only goes down to INT4 precision. Unlike Intel, AMD doesn’t have dedicated matrix multiplication units, and executes WMMA instructions on dot product units.

I’m glad to see XMX units show up in Lunar Lake. Matrix multiplication units are often used for upscaling, and upscaling is arguably more crucial in laptops than with discrete GPUs. Laptop GPUs often struggle to deliver playable performance in recent games, even with low settings and resolutions, so upscaling can make the difference between a game being playable or not. For discrete GPUs, upscaling simply allows higher quality settings.
Cache and Memory Latency
Caches remain largely unchanged within a Xe Core. A 192 KB L1 cache serves double duty as local memory, which Intel calls Shared Local Memory (SLM). Higher clock speed means Meteor Lake’s iGPU has slightly better L1 latency, though multiplying latency by clock speed shows cycle count is pretty much the same.

Strangely, Lunar Lake seems to be stuck as if local memory were always allocated, so only 64 KB of L1 cache is visible from a latency test. Meteor Lake couldn’t use the whole 192 KB of L1 for caching like the Intel’s discrete A770, but it could still use 160 KB for caching. Meteor Lake would only drop to 64 KB if a kernel needed local memory. AMD uses a separate 128 KB Local Data Share (LDS) for local memory, so local memory allocations don’t affect AMD’s caching capacity.

If programs do want local memory, Lunar Lake is more efficient with utilizing L1/SLM capacity. Lunar Lake can have threads allocating up to 1 MB of local memory executing concurrently on the GPU, which would correspond to 128 KB per Xe Core. Meteor Lake got stuck at 768 KB, so each Xe Core was only able to allocate 96 KB of local memory.

Xe Cores have a texture cache as well, probably with 32 KB of capacity. Latency is higher because accesses have to go through the texture units, which can do all sorts of texture sampling operations in addition to just grabbing data from memory. Here I’m hitting the texture cache with OpenCL’s image1d_buffer_t data type, and not using any texture sampling options.

Again Lunar Lake behaves just like Meteor Lake with a little extra latency, thanks to lower clock speeds. AMD does not have a separate texture cache, and feeds texture units using the vector cache. Vector cache latency on AMD is actually better when the texture units handle address generation.

Outside the Xe Core, Lunar Lake doubles L2 cache capacity to 8 MB. That’s the biggest L2 cache I’ve seen in a laptop iGPU so far. However, latency has substantially increased over Meteor Lake’s 4 MB L2. Lunar Lake also sees a weird uptick in latency well before the test approaches L2 cache capacity. It’s not address translation latency because testing with a 4 KB stride didn’t show a latency jump until 64 MB, implying a single thread has enough TLB capacity on hand to cover 64 MB.

To investigate further, I split the latency test array into multiple sections. Each thread gets placed into a separate workgroup, and traverses its own portion of the array. I can’t influence which Xe Core handles each thread, but GPU schedulers usually try to evenly balance threads across GPU cores. Eight threads see eight times as much L1D capacity, indicating I have one thread per Xe Core. At L2, using more threads pushes out the latency jump. Perhaps Lunar Lake’s L2 is split into multiple sections, and a Xe Core may have lower L2 access latency if it accesses a closer section.
AMD’s Strix Point has a smaller but lower latency L2 cache. Even though the L2 is smaller, Strix Point has a lower latency penalty for accessing DRAM. On Lunar Lake and Meteor Lake, a GPU-side DRAM access has over 400 ns of latency. Strix Point’s iGPU can get data from DRAM in under 250 ns. Lunar Lake has a 8 MB memory side cache placed in front of the memory controller, but I can’t clearly measure its performance characteristics.
Atomics
Atomic operations can exchange data between threads running on a GPU. And while such operations are comparatively rare from what I can see, it’s still fun to run a core-to-core latency test of sorts on a GPU. Exchanging data through global memory sees Lunar Lake improve slightly over Meteor Lake.

Doing the same through local memory means that data exchange can happen within an Xe Core, or the equivalent structure on other GPUs. There, AMD’s very fast Local Data Share continues to take the top spot. However, Lunar Lake has noticeably improved over its predecessor.

Cache and Memory Bandwidth
Assuming there’s enough work in flight to hide latency, GPUs can demand a lot of bandwidth from their cache hierarchy. Lunar Lake’s first level caches provide similar bandwidth compared to the outgoing Meteor Lake generation, while AMD’s Strix Point has a massive bandwidth lead. That’s because AMD’s WGPs have two 32 KB vector cache instances, each capable of satisfying a wave32 (1024-bit) vector load per cycle.
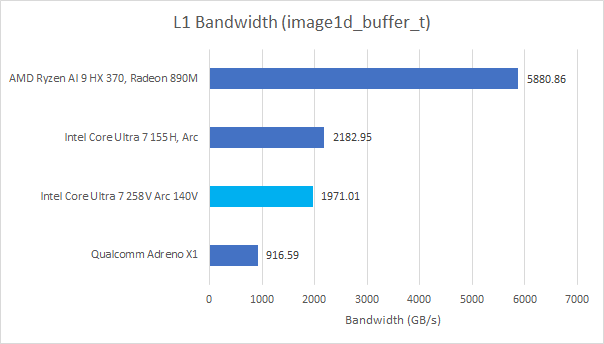
Local memory shows similar behavior. AMD backs local memory with a 128 KB LDS. Since RDNA, that’s been built from two 64 KB arrays each capable of servicing a wave32 load every cycle. Thus AMD’s local memory and vector caches enjoy the same staggeringly high bandwidth. Again, it’s much higher than what Intel’s iGPUs can offer.
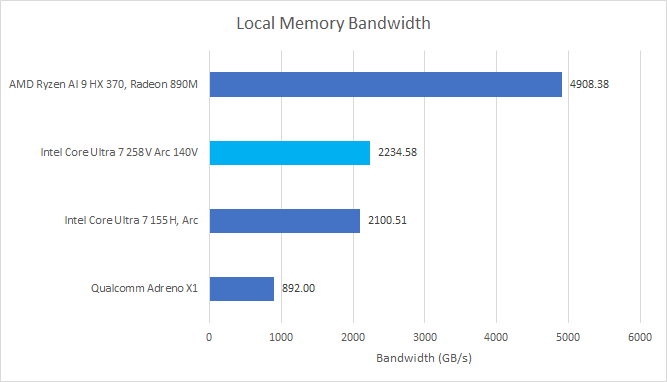
Testing GPU cache and memory bandwidth from a single test can be tricky, and Intel’s latest drivers seem to defeat Nemes’s Vulkan benchmark. Therefore I’m using my OpenCL bandwidth test, which uses the same general methodology.
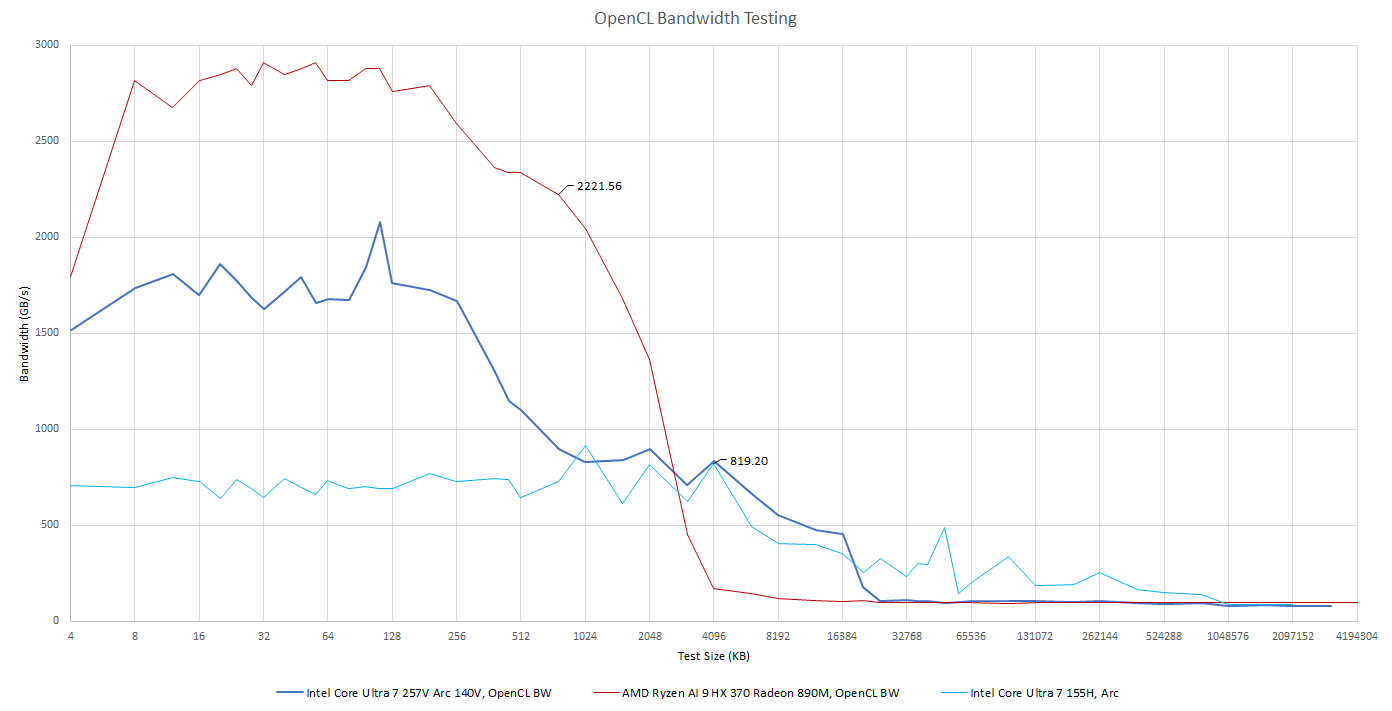
Lunar Lake and Meteor Lake appear to have similar L2 bandwidth. AMD continues to have a huge L2 bandwidth lead.
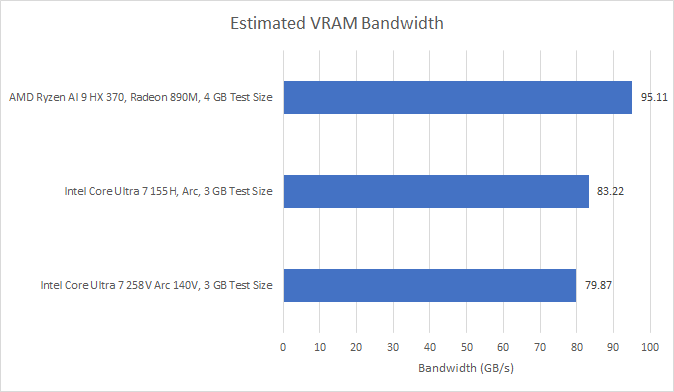
All three iGPUs tested here have very high DRAM bandwidth compared to those from the DDR4 generation. I’m not sure why Lunar Lake can’t quite match Strix Point or Meteor Lake despite using faster LPDDR5X, but I wouldn’t put too much weight into it because bandwidth testing is hard. I intend to write a different test specifically to target GPU DRAM bandwidth at some point, but time is short.
CPU to GPU Copy Bandwidth
Integrated GPUs share a memory controller with the CPU. Often this can be a disadvantage because CPUs and GPUs are more sensitive to different memory subsystem characteristics, and iGPUs have to be budget friendly too. But iGPUs do have an advantage in being able to exchange data with the CPU faster. Normally I use OpenCL’s clEnqueueWriteBuffer and clEnqueueReadBuffer functions to test PCIe link bandwidth, but here, the test is just hitting the DMA engines.
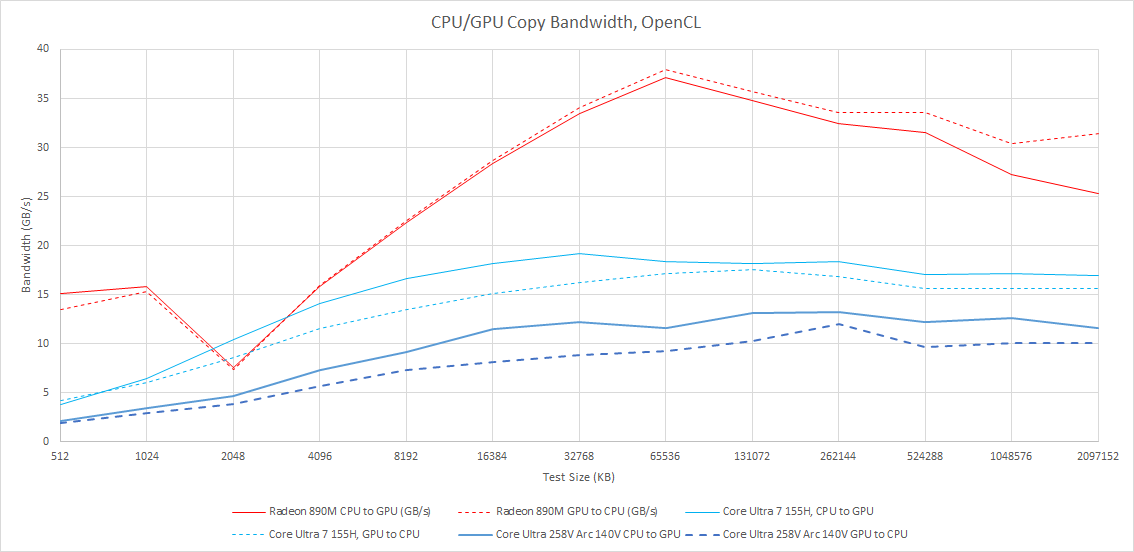
Lunar Lake seems to have weaker DMA engines than its predecessor and AMD’s Strix Point. They come nowhere near saturating memory bandwidth, and don’t offer comparable performance to say, a PCIe 4.0 x16 link.
Improved Raytracing
Intel has scaled up the hardware raytracing unit (RTU) in each Xe Core, giving it three traversal pipelines for handling raytracing BVH-es. Each pipeline can do 6 box tests per cycle for a total of 18 across the RTU. For intersection testing at the bottom level of the BVH, Intel can do two triangle tests per cycle to see if the ray hits any geometry.

I couldn’t find much on Intel’s prior raytracing implementation, though the Xe-HPG whitepaper does say its RTUs support “a 12-to-1 ratio of ray-box intersection tests per clock to ray-triangle tests per clock”. The prior generation may have had two traversal pipelines per RTU, each capable of 6 box tests per clock.

Meteor Lake already had an aggressive ray tracing implementation, with RTUs autonomously handling ray traversal until a hit or miss is discovered. It performed well in 3DMark’s Solar Bay raytracing benchmark against AMD’s GPUs. Lunar Lake improves over its predecessor, though it’s hard to compete against AMD scaling up its GPU and showing up at much higher clock speeds.

3DMark’s Solar Bay test also displays average framerates. Laptop iGPUs do quite well because Solar Bay is aimed at tablets and cell phones. Its test scene is very limited, and its raytracing effects are too.

Cyberpunk 2077
Unlike Solar Bay, Cyberpunk 2077 has far more complex scenes and long view distances. At 1080P and low settings, mobile GPUs just barely manage playable framerates. Lunar Lake posts a huge performance increase over its predecessor, and manages to slip past AMD’s outgoing Phoenix APU in Cyberpunk 2077’s built in benchmark. But framerates are still low enough that I’d rather not lower it by adding extra eye candy. That includes raytracing.

Even though Lunar Lake manages significant improvements, AMD’s current generation Strix Point APU is still ahead. Part of this is because Strix Point was able to pull more power. HWInfo showed the Lunar Lake laptop pulling an average of 43W from the battery, while the Strix Point laptop averaged 50W.

Lunar Lake’s huge performance gain over Meteor Lake may be down to power too. Microbenchmarking shows similar compute performance across both Intel generations. But Meteor Lake’s CPU cores pull more power, leaving less power available for the GPU. HWInfo couldn’t read GPU frequency for Lunar Lake, but Meteor Lake’s iGPU often ran below 1.6 GHz. I suspect Lunar Lake’s iGPU ran closer to its maximum 1.95 GHz clock.

CPU power counters may not provide the best accuracy, as they only have to be accurate enough to prevent hardware damage. Figures above likely have a generous margin of error. But I think they show how improved architecture and better process nodes combine to let Lunar Lake outperform Meteor Lake in a power constrained laptop.
Caching is another power optimization, as data transfer often contributes significantly to platform power consumption. Lunar Lake’s higher caching capacity means it can outperform AMD’s Phoenix APU while using less memory bandwidth on average. Intel has also improved significantly over Meteor Lake, delivering better performance with lower DRAM bandwidth demand.

AMD’s Strix Point iGPU stands out as being particularly bandwidth hungry. It’s able to take the top spot by a considerable margin, but in the process requires disproportionately more data transfer from DRAM. A deeper look shows highest observed DRAM bandwidth usage over HWInfo’s 2 second sampling interval was 60.6 GB/s, while Meteor Lake only reached a maximum of 52 GB/s over 0.04 seconds. So while none of these platforms are pushing their bandwidth limits, AMD’s higher DRAM bandwidth usage may put Strix Point at a power disadvantage. That’s because data transfer can consume significant power, and DRAM is one of the most power hungry places for a CPU to get data from.
The situation may get even more extreme for AMD in other games. Elden Ring for example averaged 63.6 GB/s of DRAM traffic on Meteor Lake. In laptops where every last watt matters, Intel’s caching strategy is good to see.
FluidX3D
FluidX3D uses GPU compute to carry out fluid simulations. Unlike games, FluidX3D almost exclusively loads the GPU and places little load on the CPU. Lunar Lake also shows improvement over Meteor Lake in this task. However, it lands just short of AMD’s last generation Phoenix part.
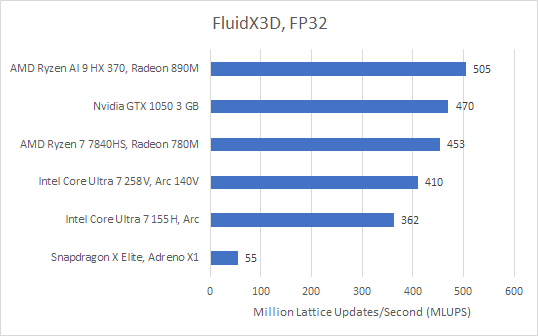
While FluidX3D tends to be memory bandwidth bound on discrete cards, the picture on integrated GPUs isn’t so clear. The benchmark reported 63 GB/s of bandwidth usage on Lunar Lake, and that’s likely close to DRAM bandwidth usage because FluidX3D tends to have low cache hitrates.
Final Words
Lunar Lake’s iGPU is a showcase of Intel’s determination to keep pace with AMD in thin and light laptops. Instead of building a bigger GPU as they did with Meteor Lake, Intel is trying to more efficiently operate a GPU of the same size. More cache reduces power hungry DRAM accesses. Reorganized Vector Engines help improve utilization. More efficient CPU cores mean the GPU gets a bigger power and thermal budget to stretch its legs in.

AMD in contrast is going all out for higher performance. Their Strix Point APU has a bigger GPU than the prior generation with minor architectural changes, but continues to use a 2 MB L2 cache and shares the same die with more CPU cores. From brief testing, Strix Point undoubtedly wins from a performance perspective. But AMD also draws more power to get there. I wonder if AMD will have to adopt something closer to Intel’s caching strategy going forward. Even if Strix Point can deliver better performance with smaller caches, it’s a very bandwidth hungry and therefore power hungry way to do so.
Lunar Lake’s iGPU is perhaps most interesting as a preview of what Intel’s upcoming Battlemage discrete GPUs can offer. With Xe2, Intel is looking to use the same graphics architecture across their product stack. It’s a strategy AMD has used for a long time, and also shows Intel is serious about hitting higher GPU performance targets. Efficiency improvements from reorganized vector units as well as bigger raytracing accelerators should be very fun to see once they hit the desktop market.
Finally, I’ve seen plenty of doom and gloom about Intel’s discrete GPU efforts from various sites. But unlike Intel’s prior dGPU efforts, the company is using their integrated GPUs as a springboard into the discrete GPU market. Integrated GPUs continue to be very important for mobile gaming, so that springboard will continue to exist for the foreseeable future.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.
Some rumors claim AMD had to scrap increased cache on the iGPU due to Microsoft requirements for the NPU.
For the consumer I think AMD has found a more convincing balance for those still seeking x86 laptops in 2024, whereas Intel are clearly trying to stop the dawn of the ARM laptop era by squeezing performance to achieve almost ARM-like power efficiency.
The NPU count is still a bit of a mystery, there doesn't seem to be grand plan for these. AMD laptops like Zenbook S 16 aren't even listed as "co-pilot+" PCs despite advertising 50 TOPS for dedicated AI processing, more than the new Snapdragon X chips. It's clearly just the prevailing "mood" of the chip market, propelled by Apple, that devices without dedicated AI processors are futureless.