
Qualcomm’s Oryon Core: A Long Time in the Making


In 2019, a startup called Nuvia came out of stealth mode. Nuvia was notable because its leadership included several notable chip architects, including one who used to work for Apple. Apple chips like the M1 drew recognition for landing in the same performance neighborhood as AMD and Intel’s offerings while offering better power efficiency. Nuvia had similar goals, aiming to create a power efficient core that could could surpass designs from AMD, Apple, Arm, and Intel. Qualcomm acquired Nuvia in 2021, bringing its staff into Qualcomm’s internal CPU efforts.

Bringing on Nuvia staff rejuvenated Qualcomm’s internal CPU efforts, which led to the Oryon core in Snapdragon X Elite. Oryon arrives nearly five years after Nuvia hit the news, and almost eight years after Qualcomm last released a smartphone SoC with internally designed cores. For people following Nuvia’s developments, it has been a long wait.

Now, thanks to the wonderful folks who donate to our Patreon members and Paypal donators, we have a Samsung Galaxy Book4 Edge 16 inch Laptop equipped with a Qualcomm Snapdragon X1E-80-100 CPU in our possession.
Note, because there has not been any upstreamed Device Tree for this laptop, we were not able to get a Linux desktop installed on it so a lot of our testing had to be done on Windows Subsystem for Linux (WSL).
System Architecture
The Snapdragon X1E-80-10 implements 12 Oryon cores in three quad-core clusters, each with a 12 MB L2 cache. Like Kryo in the Snapdragon 820, Qualcomm opted against a hybrid core configuration. Instead, Snapdragon X Elite’s Oryon CPU clusters run at different maximum clocks to offer a combination of good single threaded and multithreaded performance.

Snapdragon X Elite’s clustered arrangement is clearly visible from a core to core latency test, which bounces cachelines between core pairs and measures how long that takes. Transfers within a cluster are handled reasonably quickly, but cross-cluster transfers incur high latency especially for a monolithic chip with consumer core counts.

Latencies are less consistent compared to Qualcomm’s prior attempt at making a laptop chip. The 8cx Gen 3 has four Cortex X1 cores and four Cortex A78 cores. It likely uses Arm’s DSU interconnect, which also implements a shared L3 cache.

Nuvia’s co-founder used to work for Apple, making M1 is a notable comparison point. Apple also uses quad core clusters with a shared L2. However, M1 uses a hybrid core arrangement. Core to core latency is similar within a cluster. Cross-cluster transfers incur high latency much like on Snapdragon X Elite, though absolute values are a bit better.

Both Snapdragon X Elite and M1 have a System Level Cache (SLC) that can service multiple blocks on the chip, at the expense of lower performance than a cache dedicated to one block.

Snapdragon X Elite’s main competitors will be AMD’s Phoenix and Intel’s Meteor Lake. AMD’s Phoenix SoC has eight Zen 4 cores with 16 MB of L3. All eight of Phoenix’s cores are placed in the same cluster, so a core to core latency test is pretty boring to look at. Latencies are very low overall. However, it’s worth noting that AMD’s cross-cluster latencies on 16 core desktop Zen 4 variants is still better than Snapdragon X Elite or M1’s, at 80-90 ns.

Intel’s Meteor Lake has a complex hybrid setup with six Redwood Cove performance cores, eight Crestmont efficiency cores, and two Crestmont low power cores. The Redwood Cove and regular Cresmont cores share a 24 MB L3, while the low power Crestmont cluster makes do with a 2 MB L2 as its last level cache.

Core to core latencies are low as long as we stay within Meteor Lake’s CPU tile, but crossing over to the low power E-Core cluster takes much longer.

Clock Behavior
CPUs conserve power by reducing clocks when idle. Transitioning from idle to a high performance state takes time. On battery power, the Snapdragon X Elite doesn’t reach maximum clock speeds until over 110 ms after load is applied. This is almost certainly a deliberate policy on Samsung’s part to extend battery life by avoiding high power states during short bursts of activity. Intel’s Meteor Lake takes that strategy to the extreme, and does not reach maximum boost clocks on battery. AMD has a very fast boost policy on both wall and battery power, reaching 5 GHz in a millisecond or less.

On wall power, Samsung has opted not to let the CPU idle. This allows for better responsiveness because the cores start out at 3.4 GHz, and can reach 4 GHz in 1.44 milliseconds. However, it makes the laptop noticeably warm even at idle, a trait not shared by Meteor Lake or Phoenix.
Core Overview
Qualcomm’s Oryon is an 8-wide core with very high reordering capacity. True to its lineage, Oryon inherits philosophies from both Apple’s Firestorm and Qualcomm’s own much older Kryo. But unlike Kryo and M1, Oryon can run at 4 GHz and beyond. The top end Snapdragon X Elite SKU can reach 4.3 GHz on two cores. The X1E-80-100 we tested here can reach 4 GHz.

Zen 4 still has a clock speed advantage, but the gap isn’t as big with mobile. Next to Oryon, Zen 4’s architecture looks tiny. It’s only 6-wide and has smaller out-of-order buffers. However, Zen 4 can run at higher clock speeds. The Ryzen 7840HS can reach 5.1 GHz in the HP ZBook Firefly 14 G10 A.

Qualcomm states that Oryon has a 13 cycle misprediction penalty, which is the same as the common case for Zen 4.
Branch Predictor
The branch predictor is one of the best ways to get more performance per joule of energy spent. Modern CPUs therefore invest heavily in branch prediction. As core width and reordering capacity increase, an accurate branch predictor gets even more important because a mispredict tends to cause more wasted work.
Direction Prediction
The direction predictor does exactly as it sounds, it tells the branch predictor what direction the branch is likely to go. Oryon appears to have a single level direction predictor much like Golden Cove.
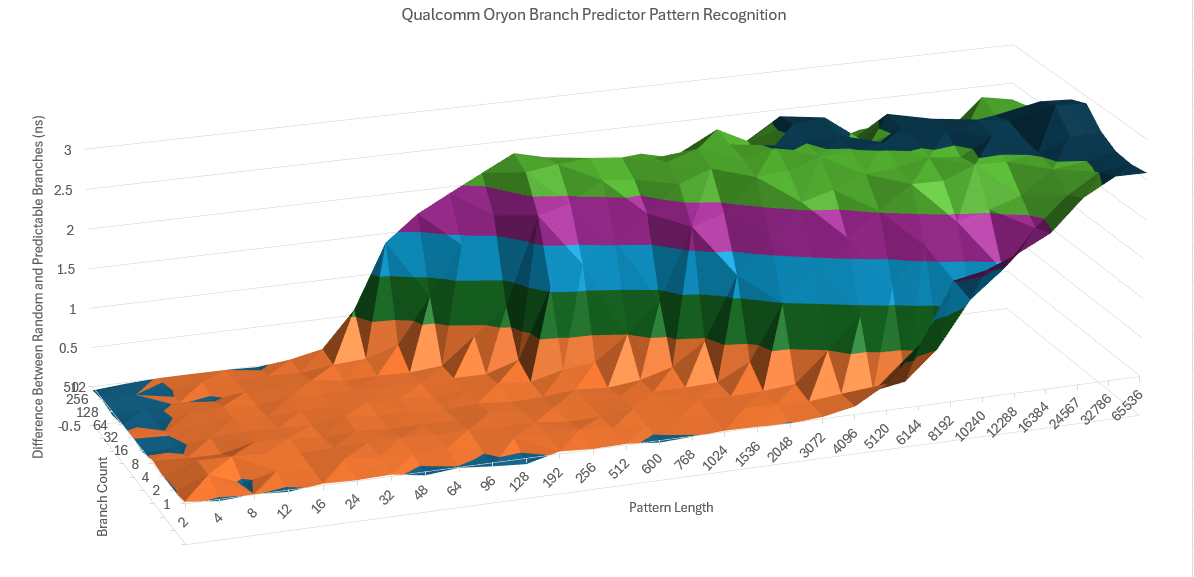
Oryon Branch Prediction Unit direction predictor does well against Golden Cove but does struggle against Zen 4.
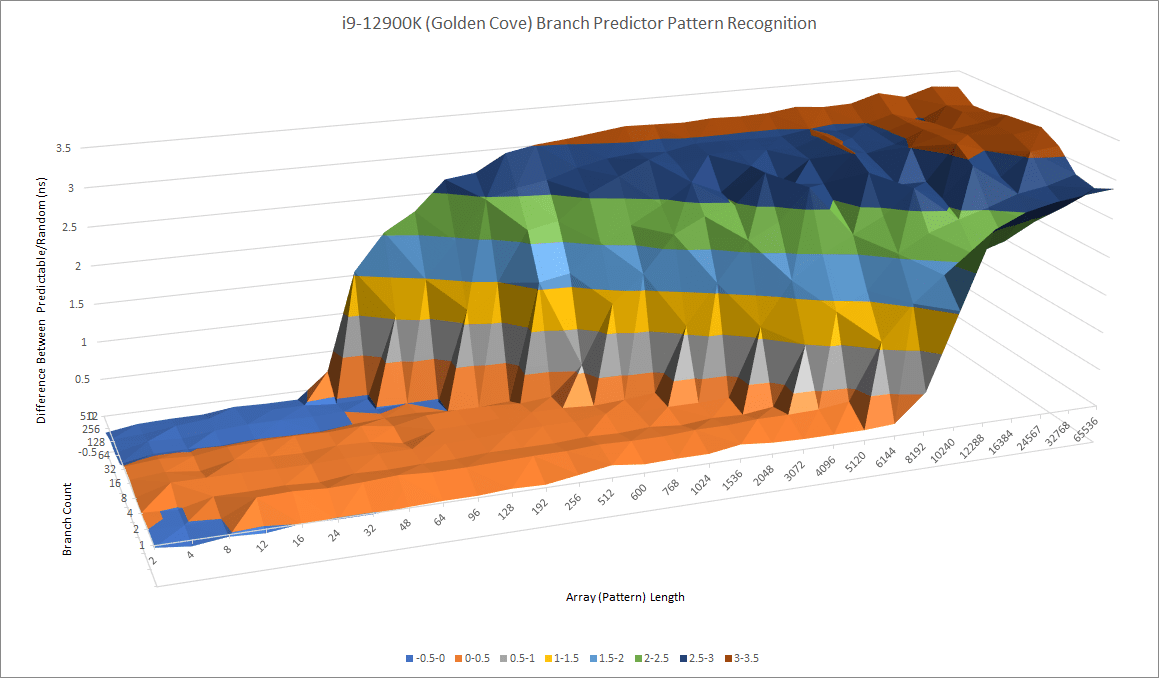

Branch Target Caching
A branch predictor’s job can be simplified to telling the frontend what address it should fetch from next. Part of that involves determining whether a branch is taken. If it is, the predictor needs to tell the frontend where that branch goes with minimal delay. Branch Target Buffers (BTBs) cache branch destination addresses to speed that process up. Like any cache, different BTB implementations have varying performance characteristics. Modern CPUs often have multi-level BTBs too to get a balance between speed and ability to cope with large branch footprints.
Oryon appears to tie its BTB to the instruction cache, as taken branches see higher latency as the test loop spills out of the instruction cache. Branches contained within a 8 KB footprint can be handled with single cycle latency, something AMD calls “zero bubble” branching. Applications with a larger branch footprint can do one taken branch every three cycles, as long as code fits in the 192 KB L1 instruction cache.

Qualcomm could have a branch address calculator placed early in the decode pipeline. With that interpretation, Oryon would have a 8 KB L0 instruction cache with single cycle latency. The 192 KB L1i would have 3 cycle latency. Oryon’s BTB setup has parallels to Kryo’s, as both cores enjoy fast branching as long as the test fits within 8 KB. It also shares traits with M1, which also sees taken branch latency increase as the test exceeds certain code footprint sizes. M1 however only gets single cycle branching within 4 KB.

AMD’s Zen 4, as well as Arm Ltd and Intel cores for that matter, decouple their branch target caching from the instruction cache. Clam’s BTB test sees higher latency once branches exceed certain counts, with branch spacing being less of a factor.

Indirect Branch Prediction
Indirect branches can go to more than one target, adding another degree of difficulty to prediction. Oryon appears to have a 2048 entry indirect branch predictor.

For comparison, here are Zen 4 and Golden Cove.
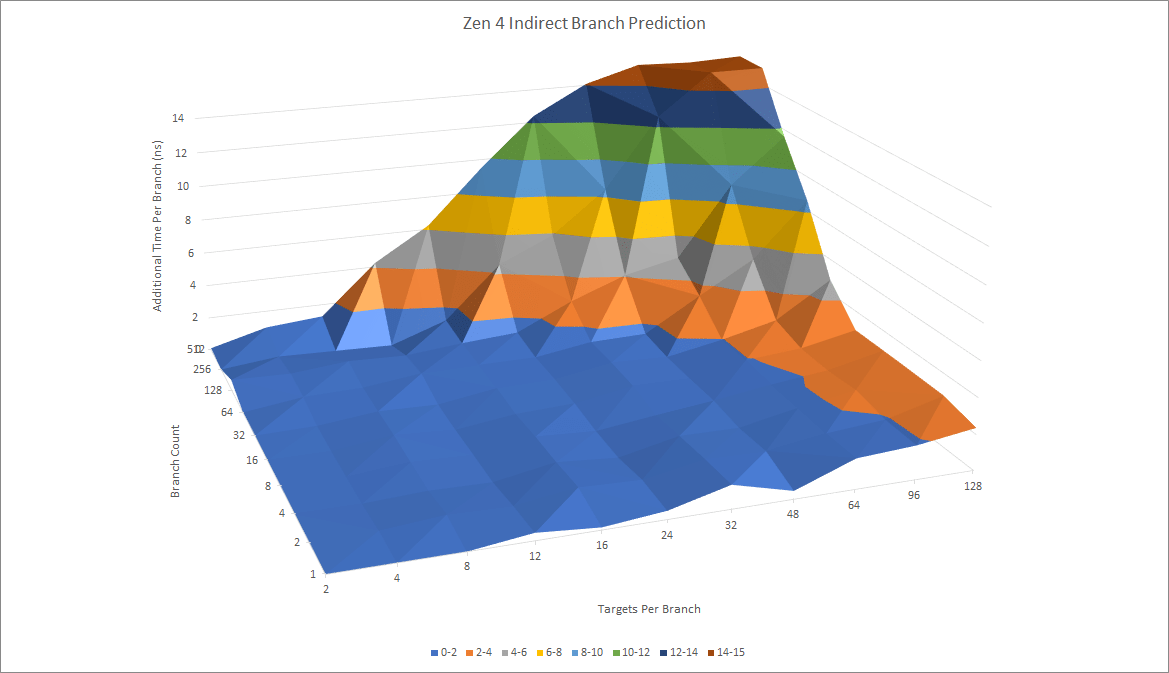
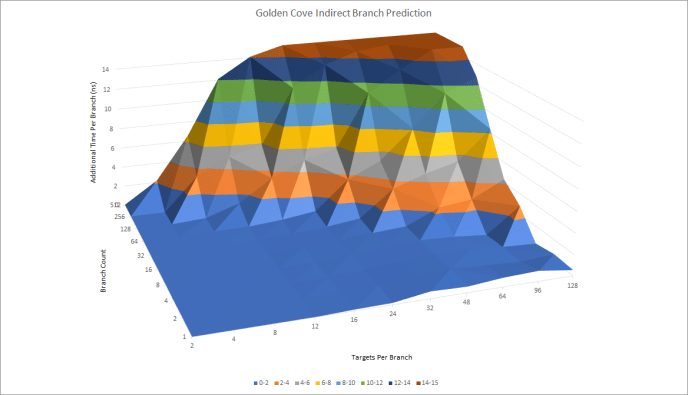
Oryon’s indirect predictor isn’t as big as Zen 4’s 3072 entry indirect branch predictor and can’t track as many targets. But unlike Zen 4, there is no slowly increasing penalty after 32 targets for a single branch. This likely means that Oryon doesn’t use a similar mechanism to Zen 4. Now comparing Oryon to Golden Cove and they are very similar to each other but Oryon can track more targets than Golden Cove can.
Returns are a special case of indirect branches. Oryon has a deep 48 entry return stack. Zen 4 for comparison has a 32 entry return stack. Both are quite deep, and likely enough to handle the vast majority of code. Qualcomm’s strategy mirrors that of Apple M1’s Firestorm architecture, which apparently has a 50 entry return stack.

When return stack capacity is exceeded, Oryon sees a sharp increase in call+return time. 4-5 ns would be 15-18 cycles at 3.7 GHz, which is high enough to be a branch mispredict. That’s similar to what Dougall discovered on Apple’s M1 too, and suggests the core clears the return stack when it overflows instead of implementing a mechanism to more gracefully handle that case.
Fetch and Decode
Next, the frontend has to fetch instructions from memory and decode them into micro-ops. Oryon and Apple’s Firestorm cores use a very similar strategy. Both have a huge 192 KB L1 instruction cache feeding a 8-wide decoder. AMD’s Zen 4 enjoys high instruction bandwidth for small instruction footprints, but sustained bandwidth is restricted by Zen 4’s 6-wide rename stage downstream. Compared to Oryon and Firestorm, Zen 4c’s small 32 KB instruction cache is a distinct disadvantage.

However, AMD maintains high frontend bandwidth for very large code footprints, as it can sustain more than 12 bytes per cycle even when pulling code from L3. Oryon and M1 have much lower code fetch bandwidth after a L1i miss.
Rename/Allocate
Micro-ops from the frontend need to have backend resources allocated to track them during out-of-order execution. That process involves register renaming to break false write-after-write dependencies. The renamer can break other dependencies as well by creatively allocating backend resources. For example, an instruction that moves values between registers can be eliminated by having its “result” point to the source register. Instructions known to set a register to zero can similarly be optimized.
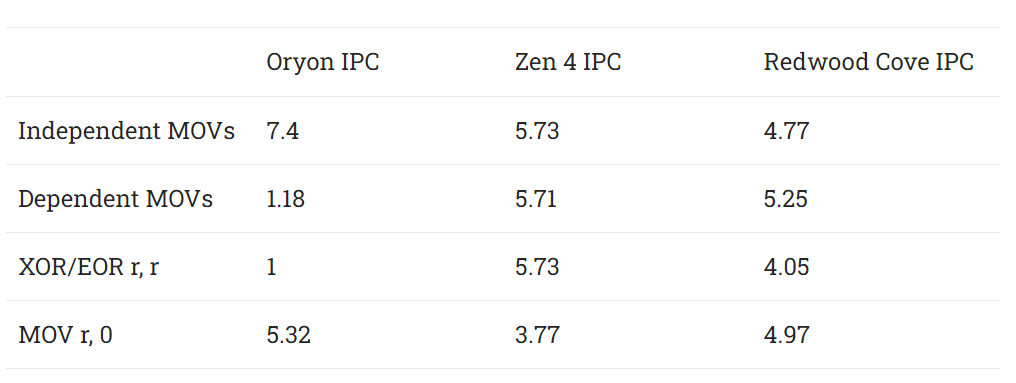
Oryon has move elimination, though it’s not as robust as Intel or AMD’s implementation for chained dependent MOVs. There’s no zeroing idiom recognition for XOR-ing a register with itself, or subtracting a register from itself. Moving an immediate value of zero to a register works of course for breaking dependencies. However, throughput for that doesn’t exceed 6 IPC and suggests Oryon still uses an ALU pipe to write zero to a register.
Out of Order Execution
Oryon features a massive out-of-order execution engine to hide latency and extract instruction level parallelism. Its reorder buffer, which helps commit instruction results in program order, is massive with 680 entries. Both the integer and floating point register files have 384 entries available for speculative results. Add another 32 entries for known-good architectural register values, and that comes out to 416 total entries.

Memory ordering queues are more conservatively sized. The load and store queues have 192 and 56 entries respectively. While the load queue has comparable capacity to Redwood Cove’s and is appropriately sized to cover the reorder buffer, the store queue feels a bit small. It’s strange to see.

Where Oryon really excels is scheduling capacity. Schedulers are expensive structures because every cycle, they have to check all their entries for micro-ops that are ready to execute. And, they have to see if results coming from freshly completed micro-ops make any pending micro-ops ready. Doing all those checks and comparisons can make schedulers area and power hungry. Qualcomm has likely kept costs down by associating each scheduling queue with one execution port, ensuring each scheduler only has to select one micro-op per cycle.

Oryon can bring an incredible 120 scheduler entries to bear for basic integer operations alone. It’s just short of Firestorm’s 134 entries, and far higher than Zen 4’s 96 entries. The gap between Oryon and Zen 4 is even wider because Zen 4’s ALU scheduling entries are shared with memory access operations. Intel’s Redwood Cove has 97 scheduling entries shared by integer and FP/vector operations.
On the FP/vector side, Oryon similarly has massive scheduling capacity. Arm CPUs traditionally featured weak vector execution, since handing throughput bound workloads would be difficult in a smartphone or tablet power budget. x86 applications however have different expectations, and users expect to carry out intensive tasks locally instead of sending them to be processed on a remote server. Oryon tackles this by feeding four 128-bit execution ports with a total of 192 scheduler entries. All four pipes can handle basic floating point and vector integer operations.

In that respect Oryon is very similar to Firestorm, though the two cores differ in how they handle less common operations. Firestorm also stands apart in using smaller (though still large in an absolute sense) schedulers, and compensating for that with a non-scheduling queue that can delay a stall at the rename stage.
AMD again has the lowest scheduling capacity, instead using a huge non-scheduling queue to prevent full schedulers from causing stalls further up the pipeline. Still, Zen 4’s buffering capacity for incomplete FP/vector operations falls far short of Oryon. However, AVX(2) and AVX-512 can still give Zen 4 an edge, because wide vector operations do more work with a single micro-op. Intel’s Redwood Cove similarly stands to benefit from wider vectors, though Meteor Lake’s hybrid core setup prevents it from supporting AVX-512.
Oryon’s FP/vector side feels like it’s about as strong as any NEON/ASIMD setup can reasonably be. Without SVE support, Oryon can’t use vectors wider than 128-bits. Supporting FMA ops on all four pipes gives it similar floating point throughput to Zen 4, but and potentially gives Oryon an advantage with code that doesn’t use vectors wider than 128 bits. But feeding that setup requires 12 FP register file ports, because each FMA needs three inputs. Pulling that off with a 416 entry register file sounds expensive.

Oryon has less scheduling capacity for address generation ops compared to math ones, but four 16 entry schedulers are nothing to sneeze at. Together, those schedulers can hold more micro-ops than Firestorm’s AGU scheduling and non-scheduling queues combined. Zen 4 can theoretically keep 72 incomplete address generation operations in flight, but those entries are shared with integer math operations.
Address Translation
On any modern CPU, programs operate on virtual addresses that get translated on-the-fly to physical addresses. Address translation caches, called Translation Lookaside Buffers (TLBs), help accelerate this by caching frequently used translations. Oryon features very large TLBs, helping reduce address translation latency.

Oryon’s first level data TLB has 224 entries and is 7 way set associative, providing 896 KB of coverage with 4K pages. That’s a lot of capacity compared to first level TLBs on AMD and Intel CPUs. It’s reminiscent of Kryo’s 192 entry L1 DTLB, which similarly provided fast address translation coverage over a relatively large address space. And, it’s refreshing to see next to AMD, Intel, and Arm’s small L1 DTLBs.

But unlike Kryo, which dropped L1 TLB misses on the floor, Oryon has a large second level TLB with over 8K entries. Getting a translation from the L2 TLB appears to take 7 extra cycles, which is good especially considering Oryon’s 4 GHz+ clocks and the size of the L2 TLB.

Measurements return confusing results though, showing an increase in address translation penalties past 6 MB. That would correspond to 1536 L2 TLB entries, which is far short of the 12 MB that Zen 4’s L2 TLB would cover. Testing sizes past 128 MB shows another increase, but that doesn’t correspond to 8K entries * 4K pages = 32 MB.
Cache and Memory Access
Oryon uses an Apple-like caching strategy. A large 96 KB L1 and relatively fast L2 with 20 cycles of latency together mean Oryon doesn’t need a mid-level cache. Firestorm has a bigger 128 KB L1, but Oryon’s L1 is still much larger than the 32 or 48 KB L1 caches in Zen 4 or Redwood Cove.

AMD has a 1 MB L2 mid-level cache private to each core, then a 16 MB L3. That setup makes it easier to increase caching capacity, because the L2 cache can insulate the core from L3 latency. However, that advantage is minimal for mobile Zen 4 parts, which max out at 16 MB of L3. Oryon therefore provides competitive latency especially as accesses spill out of Zen 4’s L2. Meteor Lake follows a similar caching strategy to Zen 4, but has more caching capacity at the expense of higher latency.

After L2, Oryon has a 6 MB System Level Cache (SLC) with a claimed latency of 26-29 ns. Test sizes between 12 and 18 MB generally align with that. For example, latency at 14 MB was approximately 25 ns using 2 MB pages. Accurately assessing SLC latency is difficult because many accesses within even a 18 MB array will result in L2 hits. The SLC’s low capacity compared to the L2 cache will likely limit its relevance for CPU-side code.
DRAM latency is 110.9 ns with a 1 GB array, which isn’t far off Qualcomm’s claimed 102-104 ns. The Ryzen 7840HS achieves somewhat lower latency at 103.3 ns, likely because it uses DDR5 memory instead of LPDDR5X. Meteor Lake’s memory latency is worse at over 140 ns.
Bandwidth
x86 CPUs traditionally had a strong focus on vector execution, and have plenty of cache bandwidth to support their vector units. Oryon competes surprisingly well in this area. There’s no SVE support, but Oryon takes 128-bit vector widths about as far as they’ll reasonably go with support for four 128-bit loads per cycle. That’s a match for Zen 4’s 2×256-bit load bandwidth, though a bit behind Redwood Cove’s 3×256-bit load capability.
Oryon’s large L1 cache capacity should let it hold up well for smaller data footprints, but AMD and Intel’s mid-level caches provide a bandwidth advantage if data spills out of L1. AMD’s L3 also does a good job, providing more bandwidth to a single core than Qualcomm’s L2. Apple’s Firestorm doesn’t emphasize vector workloads and is outpaced by other cores in this comparison.

When reading from DRAM, a single Oryon core can achieve an incredible 80 GB/s of bandwidth. Qualcomm says each core can have over 50 in-flight requests to the system, and a L2 instance can track over 220 memory transactions. Those large queues are likely why a single Oryon core can pull so much bandwidth from DRAM.

Shared caches get put under more pressure under multithreaded loads, as more cores ask for bandwidth. Oryon handles this well, with the L2 providing nearly 330 GB/s of bandwidth to four cores. That’s about 82 GB/s per core, and just a bit lower than the 100 GB/s an Oryon core can get without contention.

Again, AMD and Intel enjoy lots of bandwidth from their core-private L2 caches, and AMD’s L3 continues to shine for larger data footprints. Intel’s Redwood Cove P-Cores have very high cache bandwidth, but that advantage falls off once data spills out into L3.
For all-core workloads, Oryon trades blows with Phoenix depending on which level of the memory hierarchy we hit. L1 cache bandwidth is comparable, with AMD’s eight Zen 4 cores clocking higher to take a slight lead. AMD enjoys about 25% higher L2 bandwidth across all cores. Intel’s Meteor Lake generally has a bandwidth lead thanks to a combination of high core count and Redwood Cove’s 3×256-bit per cycle load capability. However, the lead is less significant when all threads are loaded because of clock speed drops and lower bandwidth E-Cores coming into play.

As test sizes exceed AMD’s L2 capacity, Qualcomm’s three L2 instances can provide 16% more bandwidth than AMD’s L3. Snapdragon X Elite has three 12 MB L2 instances for 36 MB of total capacity. Using three L3 instances makes it easier to provide high bandwidth too.
Finally, Qualcomm has much higher DRAM bandwidth thanks to fast LPDDR5X. With over 110 GB/s of measured read bandwidth, the Snapdragon X Elite is comfortably ahead of both Phoenix and Meteor Lake.
Cinebench 2024
Maxon’s Cinebench has been a benchmarking staple for years because it’s able to scale with core count. Modern CPUs have a lot of cores, but delivering high multithreaded performance in a limited power budget is very difficult. Cinebench 2024 has a native ARM64 build, so the Snapdragon X Elite will be free from binary translation penalties.

Qualcomm does very well. SMT helps AMD by giving each Zen 4 core explicit parallelism to work with. However, that’s not enough to counter the Snapdragon X Elite’s higher core count. The Snapdragon X Elite has 12 cores to AMD’s eight, and comes away with a 8.4% performance lead while drawing just 2% more power. From another perspective though, each Zen 4 core punches above its weight. Qualcomm is bringing 50% more cores to the table, and bigger cores too. Snapdragon X Elite should be crushing the competition on paper, but thermal and power restrictions prevent it from pulling away.

Qualcomm’s slides suggest a higher power reference device can indeed achieve such results. Higher core counts need more power and better cooling to shine. We don’t know what clock speeds Qualcomm’s higher power reference device was able to sustain. In the Samsung Book Edge4, the Snapdragon X Elite averaged 2.71 GHz. In the HP ZBook Firefly G10 A, the Ryzen 7840HS averaged 3.75 GHz, explaining how AMD’s able to get so close with fewer cores.
Intel’s Meteor Lake has an even higher core count but fails to impress at similar platform power. It’s only slightly faster than Apple’s M2. In the Asus Zenbook 14 OLED, the Core Ultra 7 155H’s Redwood Cove P-Cores averaged 2.75 GHz. The Crestmont E-Cores averaged 2.33 GHz. One of the six P-Cores and the two LPE-Cores didn’t see significant load during the Cinebench 2024 run.
Final Words
Oryon combines design philosophies from both Firestorm and the company’s much older Kryo. The result is a very solid architecture, because Qualcomm took care to bring forward the best of those worlds. Qualcomm has wanted to move beyond smartphones and take a chunk of the laptop market for a long time, and Snapdragon X Elite is the strongest shot the company has taken yet. On paper, 12 big Oryon cores should be a formidable opponent for both AMD’s eight Zen 4 cores and Meteor Lake’s 16 cores of various types.
We’ll leave detailed benchmarking to mainstream tech sites, since they can do so in a more controlled environment and have the budget to provide more comparison points. But at a glance, Snapdragon X Elite provides competitive performance when running native applications. Even with binary translation, Oryon is fast enough to provide usable performance. With that in mind, Oryon has fulfilled two of the conditions that drove Apple Firestorm’s 2020 success.

But Snapdragon X Elite has a steeper hill to climb than Apple’s M1. Where Apple Silicon was the only upgrade option within the Apple ecosystem, PC customers have up-to-date AMD and Intel options to choose from. The PC ecosystem owes its popularity and staying power to a tradition of excellent software compatibility. Oryon relies on binary translation to execute x86 code, which comes with a performance penalty. Compatibility expectations extend to the operating system too. PC users expect to be able to (re)install an operating system of their choice. Generally a stock Linux or Windows image will boot on x86 CPUs going back several generations, regardless of device or motherboard manufacturer. Arm devices suffer from severe platform fragmentation, and Snapdragon X Elite is no exception. OS images have to be customized for each laptop, even ones that use the same Oryon cores.

Finally, Snapdragon X Elite devices are too expensive. Phoenix and Meteor Lake laptops often cost less, even when equipped with more RAM and larger SSDs. Convincing consumers to pay more for lower specifications is already a tough sell. Compatibility issues make it even tougher. Qualcomm needs to work with OEMs to deliver competitive prices. Lower prices will encourage skeptical consumers to try Snapdragon X Elite, getting more devices into circulation. That in turn leads to more developers with ARM64 Windows devices and more ARM64 native applications.
Qualcomm has their work cut out for them. We look forward to their next generation of CPU cores, and hope it’ll be strong enough to keep pace with AMD and Intel’s next generation products.
Again, we would like to thank our Patreon members and Paypal donators for donating and if you like our articles and journalism then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.