
Arm’s Cortex A73: Resource Limits, What are Those?

Arm (the company) enjoyed plenty of design wins towards the mid 2010s. Their 32-bit Cortex designs scored wins in Nvidia’s Tegra 3 and Tegra 4. Samsung’s Exynos chips in the Galaxy S4 and S5 also used Cortex cores. But Arm faced constant competition from Qualcomm’s Krait. Then Arm transitioned to 64-bit, and that didn’t go flawlessly. Cortex A57 struggled in the Snapdragon 810, where it suffered heat issues that could tank its performance. Snapdragon 820 switched to Qualcomm’s in-house Kryo architecture, passing over Arm’s Cortex A72. Samsung, another major smartphone SoC maker, opted to use their own Mongoose cores in the Exynos 8890.
Arm had to convince smartphone SoC giants to stop making their own cores and go back to licensing Cortex designs. Cortex A57 and A72 weren’t cutting it. Their theoretically competitive performance didn’t matter if they couldn’t sustain it within a smartphone’s power and thermal budget. That’s where Cortex A73 comes in. Cortex A57’s foundation gets thrown out in favor of a completely different architecture, one with unique traits. A73 stops trying to go after high performance. Instead, it aims to provide adequate performance with better power efficiency.

I’ll be checking it out in the Cortex A73 as implemented in the Amlogic S922X, on the Odroid N2+ single board computer. For comparison I’ll be using a mix of data from Nintendo Switch’s A57 cores and AWS’s Graviton 1 instances, which implement Cortex A72 cores in a higher power envelope.
Overview
A73 is a two-wide out-of-order architecture with theoretically unlimited reordering capacity. It goes against the trend of going wider, deeper, and faster that had characterized prior Arm designs.

Thanks to its shift in focus towards power efficiency, A73 sometimes feels like a step back compared to A72 and A57. A73 isn’t as wide as its predecessors. Scheduler capacity also goes down depending on where you look.

But that’s all part of Arm’s strategy. A bigger core can’t shine if thermal restrictions force it to run at much lower clocks than a smaller one.
Frontend: Branch Prediction
Low power cores have to make careful tradeoffs with their branch predictor. Branch mispredicts reduce performance and power efficiency because work gets wasted. Slow branch prediction can starve the core of instructions due to branching delays. But the branch predictor itself takes power and area.

A73’s branch predictor can’t cope with tons of branches and very long patterns like the ones in higher power cores. It’s different from A57 for sure, but not that far off. Contemporary high power cores can maintain high prediction accuracy with longer patterns and more branches in play.

Branch target caching is also a compromise. A73 has a small 48 entry L1 BTB that can handle one taken branch every two cycles. Occasionally A73 can get a little faster with four or fewer branches, particularly if they’re packed very closely together. The larger main BTB has three cycle latency and possibly has 3072 entries. Taken branch latency dramatically increases if the test loop exceeds L1i capacity, suggesting the main BTB is tied to the instruction cache.

High performance cores (like Haswell) can track far more branch targets in their fastest BTB level, and enjoy single cycle taken branch latency from their L1 BTBs. Overall, A73’s BTBs are comparable to A57’s, with slightly better performance for tiny branch footprints. A73 also does better as branches spill out of L1i.

Indirect branches read their destination from a register, rather than having it directly encoded into the instruction. These branches add another dimension of difficulty for branch predictors, which have to pick from multiple targets.

A73 can track 256 indirect targets with minimal penalty, achieved with 128 indirect branches alternating between two targets each. A single indirect branch can go to 16 different targets before A73 starts having a hard time.
Returns are a special case of indirect branches, and typically go back to where the corresponding call came from. A return stack, where a target is pushed on each call and popped off for return prediction, is typically a very accurate way to predict returns. However, return stacks do have finite capacity.

A73’s return prediction speed is best when call depth doesn’t exceed 16, but doesn’t take a sharp upward tick until call depth exceeds 47. Return handling behavior differs from Cortex A57, which sees a gradual increase in return penalties past a call depth of 32.
Frontend: Fetch and Decode
After the branch predictor tells the frontend where to go, the frontend has to fetch instruction bytes from memory and decode them into the core’s internal format. Cortex A72 and A57 predecoded instructions before filling them into the L1 instruction cache. Doing so moved some decode work out of the more heavily used fetch-from-L1i path at the cost of using more storage. Specifically, the intermediate format used 36 or 40 bits per 32-bit instruction, so A72 needed 54 to 60 KB of storage for 48 KB of effective L1i capacity.
A73 switches to a 2-wide frontend, which likely let it ditch the predecode scheme. 2-wide decode is probably cheaper than 3-wide decode, even when translating 64-bit Arm instructions all the way to micro-ops. Reduced storage requirements are a secondary benefit because Arm instructions are smaller than predecoded instructions. A73 increases L1i capacity from 48 to 64 KB, and likely did so with little increase in actual storage budget. L1i associativity increases to 4-way compared to 3-way on the A72, reducing the chance of conflict misses.

Cortex A72 might have a higher IPC ceiling, but A73 enjoys better code fetch bandwidth from L2. 1 IPC certainly isn’t great, but it’s better than Cortex A72’s abysmal performance when running code from L2. Arm’s technical reference manual says A73 can track up to four L1i misses, each corresponding to a 64B cacheline. Cortex A72 in contrast could only track three L1i misses. Higher memory level parallelism helps improve bandwidth, so tracking more misses might help A73 achieve better L2 bandwidth from the code side.
Rename and Allocate
After instructions are translated into micro-ops, the rename and allocate stage does register renaming to break false dependencies, and allocates backend resources to track the instruction until it retires. The renamer is also a convenient place to break dependencies and expose more parallelism to the backend. Examples include copying data between registers, or instructions that always set a register to zero.

A73’s renamer covers the basics and doesn’t recognize zeroing idioms like x86 CPUs do. However, there’s no advantage to using a zeroing idiom like XOR-ing a register with itself on Arm, because it doesn’t reduce code size. All Arm instructions are four bytes, unlike on x86 where XOR-ing two registers is a 2 or 3 byte instruction. For copies between registers, A73 gets some kind of move elimination where A72 had none.
Out of Order Execution
As mentioned earlier, A73 uses an unconventional out-of-order execution scheme. Arm says the architecture has eight “slots”, but I don’t know what that means. Attempts to measure reorder buffer, load/store queue, and register file capacity go nowhere. I use Henry Wong’s methodology to measure structure sizes, which involves seeing how many filler instructions I can put between two cache misses before the core can’t parallelize those cache misses anymore.
On Cortex A73, the cache misses stop overlapping only when there are so many filler instructions that the 2-wide decoder can’t get through them before the first cache miss gets data from DRAM. Therefore, A73 technically has infinite reordering capacity. Completed instructions pending retirement don’t run into resource limits.

I suspect the architecture can determine when a sequence of instructions can’t encounter an exception of any sort, and can “collapse” those intermediate results into a slot. But there are still practical limitations to how far ahead A73 can reach to extract instruction level parallelism. Instructions waiting for an execution unit need scheduler slots, and scheduler capacity on A73 is pretty low. Performance counters also indicate load/store slots can be a restriction, but I’m not sure what that means.
Integer Execution
Cortex A73’s integer cluster has been rearranged to have fewer, better utilized scheduling entries. It’s still a distributed scheduler like A72, but the multi-cycle integer pipe has been deleted. Multi-cycle integer operations get rolled into one of the primary ALU pipes. Removing the multi-cycle integer pipe lets Arm delete an 8-entry scheduling queue and two register file read ports that would have been needed to feed it.

A72 and A73 both have a dedicated branch port, which makes a lot of sense on a core with just two ALU ports. Branches usually occur every 5-20 instructions depending on application, so sending branches to a separate port reduces ALU port contention. It naturally prioritizes branches too. Executing branches earlier helps the core discover mispredicts faster, reducing wasted work and bringing the average branch mispredict penalty down. Branch mispredict penalties are often discussed next to a CPU’s pipeline length from instruction fetch to execute, but we have to remember those figures are just a minimum. If a mispredicted branch is delayed before execution, the mispredict penalty goes up. Finally, a dedicated branch port is cheaper than a general purpose ALU port, because branches don’t generate a result and therefore don’t need a register file write port.
Memory operations have their addresses generated by two AGU pipes on both A72 and A73. However, A73 ditches A72’s specialized pipes for two general purpose ones that can handle either loads or stores. Besides improving cache bandwidth because loads are more common than stores, A73 can get by with fewer total scheduler entries attached to the AGU pipes. That’s because A72 needed enough scheduler entries in front of each pipe to handle a series of pending loads or stores without stalling. A73 can flexibly allocate 14 entries to either loads or stores, depending on what shows up more.
Floating Point Execution
Floating point and vector execution is often a compromise on low power cores. Arm continues to use a dual pipe FPU on A73, but has added more scheduler entries. Floating point operations typically have higher latency than integer ones, so larger schedulers can help mitigate the impact of that latency.

A73 reduces fused multiply-add latency, bringing it down from eight cycles to seven. FMA latency is still bad compared to higher performance designs. AMD’s Zen for example had 5 cycle FMA latency, and could run at much higher clock speeds.
Memory Subsystem
Software expects comforts like virtual memory and the appearance of in-order memory accesses. CPU designers have to meet those expectations while hiding latency with memory level parallelism whenever possible. At the same time, they have to keep power and area under control. That leads to interesting compromises, especially in a low power core like the A73.
Address Translation
CPUs use address translation caches, called Translation Lookaside Buffers (TLBs), to mitigate the cost of translating virtual addresses to physical ones. Cortex A73 has two TLB levels. A 48 entry fully associative micro-TLB can provide data-side translations with no penalty. Then, a 1024 entry 4-way set associative main TLB helps with larger memory access footprints. Getting a translation from this main TLB costs an extra 5 cycles.
For comparison, AMD’s Zen 2 architecture has a larger 64 entry L1 data TLB. Its second level TLB is larger too, with 2048 entries, but adds 7 cycles of latency. At the Ryzen 3950X’s 3.5 GHz base clock, 7 cycles is 2 nanoseconds. That’s only slightly faster than the Cortex A73’s main TLB, which takes 2.27 ns at 2.2 GHz. By targeting low clocks, Arm is able to reduce pipeline depth to the main TLB and take less performance loss than clocking down a CPU designed for higher frequencies.

A73’s main TLB only handles small page sizes, namely 4K, 16K, and 64K. A separate 128 entry structure handles translations for larger page sizes, and can cache entries from upper level paging structures to speed up page walks.

High performance desktop and server CPUs like Zen 2 have better TLB coverage, making them better suited to handling workloads with large memory footprints. Arm has to compromise here because TLBs require significant on-die storage. A73’s L2 TLB would require 7 KB of storage for virtual to physical address mappings alone. The TLB also holds address space and virtual machine identifiers, which would consume even more storage. Zen 2’s L2 TLB would require more than twice as much storage, thanks in part to larger address space support.
Memory Disambiguation
In-flight memory accesses need to execute in the right order. A load’s address has to be compared against addresses of prior in-flight stores. If a load does need data from a prior store, partial overlaps can make forwarding quite complex. Cortex A73 can forward data from a store to a dependent load with a latency of 4-5 cycles, which is just a couple extra cycles over a L1D cache hit.

This fastest case only works when the load is 32-bit aligned, though impressively it can handle any case where the load is contained within the store. Things start getting slower when the load is not 32-bit aligned, and extra penalties show up if either access crosses a 64-bit boundary. The worse 9 cycle forwarding latency happens when both the load and the store cross a 64-bit boundary. Unlike later Arm cores and many x86 CPUs, there are no penalties for crossing a 4K aligned page boundary. Cortex A72 for comparison has more predictable store forwarding behavior, but has higher 7 cycle forwarding latency.

A related issue is that caches only give the illusion of being byte-addressable. In reality they’re accessed in larger aligned blocks, and crossing alignment boundaries requires separate accesses under the hood. A73 works on 8 byte alignment boundaries for both load and stores, while A72 has 16B store alignment and 64B load alignment. That makes A72 less prone to losing throughput from misaligned accesses, but A72 might be accessing its data cache in larger chunks. A73 likely switched to accessing the data cache in smaller blocks to save power.
Caching and DRAM Access
Caching help keep frequently used data close to the core and is vital for performance even on lower power designs. Without caching, performance would slow to a crawl due to DRAM latency and bandwidth bottlenecks. Cortex A73 has a two level cache setup like Cortex A72, with core-private L1 caches and a L2 cache shared by cores within a cluster.
L1 Cache
Cortex A73’s data cache offers better latency and can be configured to a larger size than Cortex A72’s, but gives up some things in the process. Misaligned access penalties are one example. Replacement policy is another sacrifice. Caches have to decide what data to kick out when bringing in new data, ideally preserving data the program’s going to need again soon. Cortex A72 used a LRU (Least Recently Used) replacement policy, which kicks out data that hasn’t been accessed for the longest time. Implementing LRU replacement requires storing metadata to sort cachelines in recently used order, so Cortex A73 ditches that in favor of a pseudo-random replacement policy.
Not taking last access time into account can reduce hitrate because the cache isn’t as smart about what data to keep around. However, A73 does increase associativity from 2 to 8-way. That could compensate for the pseduo-random replacement policy.

A73 also switches to a virtually indexed, physically tagged (VIPT) L1D. That likely let them cut latency to 3 cycles, compared to 4 cycles on A72’s physically indexed and physically tagged (PIPT) L1D. VIPT caches can look up a set of lines in parallel with address translation, while a PIPT cache can’t start the access process until address translation completes.
On the bandwidth side, A73 improves by not suffering a bandwidth drop after 8 KB. Both A72 and A73 can sustain one 128-bit load per cycle, but A73’s two AGUs give it more flexibility with narrower accesses.

L1 data cache misses are passed on to the L2 cache. A73 can queue up eight fill requests to L2, while A72 can only have eight L1D misses at a time.
L2 Cache
In theory, A73’s increased memory level parallelism should allow better L2 bandwidth. Somehow, that’s not the case. Arm’s technical reference manual says A73’s L1D has a 128-bit read interface from L2, but I can’t sustain anywhere near that bandwidth using a simple linear access pattern.
Bandwidth does scale when all four cores try to read from L2, but total throughput is just under 16 bytes per cycle. Arm’s technical reference manual says the L2 has a 512-bit wide fetch path, but I get nowhere near 64 bytes per cycle.
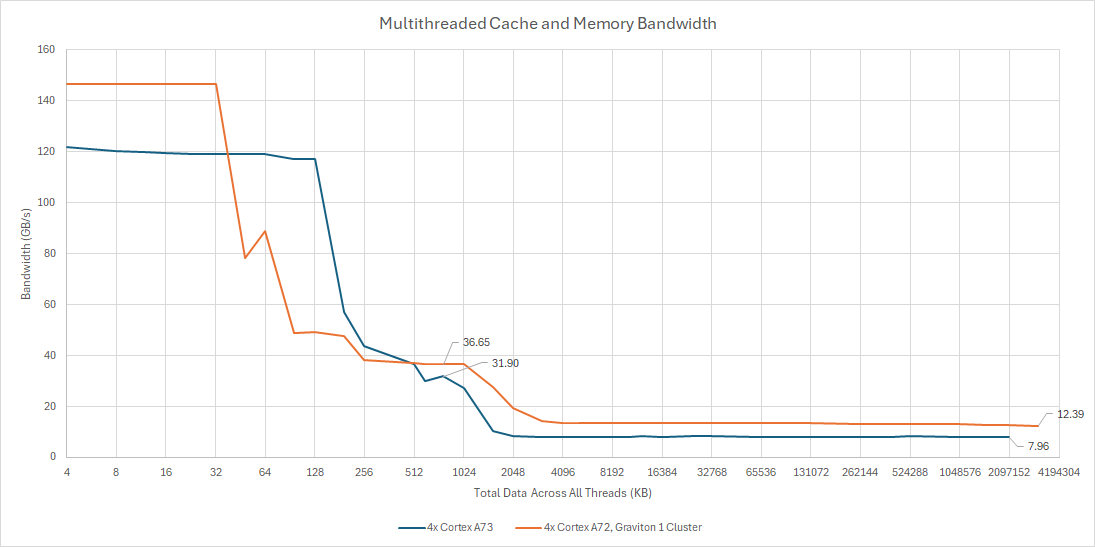
Cache latency is also not great, regressing to 25 cycles compared to 21 cycles on A72. Cortex A73’s is generally disappointing as configured in the Amlogic S922X, with poor capacity and low performance compared to other CPUs with cluster-shared L2 caches.

I would have liked to see better L2 performance from the A73. Perhaps Arm had to make sacrifices to keep power under control. Amlogic didn’t help things by implementing just 1 MB of L2 capacity, even though A73 can support larger L2 sizes.
Core to Core Latency
The L2 cache also comes with a “Snoop Control Unit” that determines whether requests hold access L2, or get data from another core’s L1 cache.

With a core-to-core latency test that bounces cachelines between core pairs, A73 enjoys low latency as long as transfers happen within a cluster. The Amlogic S922X has a dual core A53 cluster too, and going between clusters carries a hefty latency penalty. It’s much worse than going between clusters on the Ryzen 3950X or 7950X3D, even though such accesses have to cross die boundaries on AMD’s chips.
DRAM Access
DRAM performance is important in any scenario, but is especially important for the Amlogic S922X’s Cortex A73 cores because 1 MB of last level cache is a bad joke. The Amlogic S922X’s DDR4 controller has internal buffers for tracking up to 32 read and 32 write commands. For comparison, early DDR3 controllers like the ones on Intel’s Nehalem-EX and Westmere EX could track 32 and 48 in-flight request per memory controller instance, respectively.

On the Odroid N2+, this memory controller is connected to 4 GB of DDR4-2640. With a 32-bit interface, theoretical bandwidth is just 10.56 GB/s. The four Cortex A73 cores can achieve 8.06 GB/s when reading from a 1 GB array. Bandwidth isn’t far off what AMD’s budget Athlon 5350 can achieve with single channel DDR3, but that chip came out years before A73. A quad core cluster of Cortex A72 cores can get better bandwidth, likely because Graviton 1 is equipped with a higher power server memory setup.

Memory latency isn’t great either. Even with 2 MB pages used to minimize address translation penalties, A73 does substantially worse than other low power designs. A 32-bit DDR4 bus might save power, but it doesn’t offer a lot of bandwidth.

Older desktop CPUs are able to achieve much better memory latency. The Amlogic S922X’s memory controller isn’t optimized for high performance by any means. Even CPUs with the memory controller off-chip, like the Core 2 Extreme, enjoy better memory latency.
Final Words
Cortex A73 is a unique step away from the conventional out-of-order architectures I’m used to seeing. It’s quite refreshing to see something I can’t measure reorder buffer or load/store queue capacities for. It’s also refreshing to see Arm turn towards prioritizing efficiency over performance, especially next to today’s CPUs pushing past 400W for slight performance gains.
Arm achieved that efficiency by cutting down decoder width, reducing execution port count, and using small schedulers. The data cache might be optimized for smaller scalar integer reads too, which makes load/store unit more prone to misaligned access penalties. All that is balanced out by tweaks throughout the pipeline. A73’s scheduler layout is better. “Slot-based” execution provides theoretically infinite reordering capacity. The core can track more L1 misses for increased memory level parallelism.

The resulting core sips power, but doesn’t drop performance compared to Arm’s older 3-wide Cortex A57. Doing so on the desktop space leads to yawns from enthusiasts looking for better performance. But in smartphones where performance is often dictated by thermal constraints, it’s a winning strategy. A57 and A72 might achieve good IPC, but IPC alone is a meaningless metric particularly if high temperatures force clock speed reductions.
Cortex A73 was therefore very successful. Qualcomm selected the Cortex A73 for the Snapdragon 835, marking an end to the company’s in-house cores for many generations. A73 also made its way into some Samsung products, though Samsung would not drop its in-house cores until several generations later.
If there’s any criticism I have of A73, it’s that Arm cut things down too much. 6 entry ALU scheduling queues are really bare bones in the late 2010s, especially when there are only two of them. A 2-wide core is also on the edge of being too narrow. Subsequent Arm cores would increase core width and out-of-order execution resources, bringing things back into balance.
Again, we would like to thank our Patreon members and Paypal donators for donating and if you like our articles and journalism then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.