
Cortex A73’s Not-So-Infinite Reordering Capacity

Cortex A73 aimed to address the power and thermal issues that prevented Arm’s early 64-bit cores from reaching their full potential. It started a trend that saw Arm successfully capture the smartphone CPU market, and did so by emphasizing efficiency. Part of this effort appears to be a unique out-of-order retirement mechanism.

This feature frustrated my prior attempts to dig into A73’s architecture. Henry Wong’s methodology for measuring structure sizes largely didn’t work except for scheduling capacity. muffiny_mcmuffinface on Discord suggested blocking retirement with an unresolved branch, and that did the trick.
Out-of-Order Retire
With conventional out-of-order execution, an in-order frontend brings instructions into the core. The rename/allocate stage assigns backend resources to the instruction. Then the backend calculates results for those instructions without waiting to know whether the instructions actually need to be executed. These speculative results are contained in various internal core structures until they’re known to be good. Register values are held in the speculative portion of renamed register files, and values to be written out to memory are held in a store buffer. Finally, instructions can be retired (leave the core) when they have passed all checks, and all instructions before it have also passed their checks. On retirement, register values are made program-visible and pending store data is written out to the memory hierarchy. Retirement also frees entries from internal core structures, making them available for newer incoming instructions. Therefore, how far a CPU can move past a stalled instruction is limited by how many entries it has in internal structures like register files, load/store buffers, and so on.
In-order retirement is a straightforward way to preserve the illusion of in-order execution, which programs and operating systems expect. If something funny happens, like a program accessing virtual memory that doesn’t have corresponding physical memory mapped, the operating system expects to handle that “exception” with program state preserved right as it was before the offending instruction would be executed. Preserving that state lets the operating system fix the issue, for example by paging to disk, and resume the program as if nothing had happened.

A CPU’s backend can accomplish this by discarding (not retiring) all instructions after the one that hit an exception. It can then show known-good state at the exact point of the exception. If a CPU designer got smart and tried to retire an instruction out-of-order, the core could find itself in an unrecoverable state if an earlier instruction hits an exception. But A73 can do exactly that in certain cases, and at least one of those cases is an incomplete load. I suspect A73 can determine when a load is guaranteed to complete successfully. If address translation competes and access checks against the page table entry are good, there shouldn’t be anything causing the load to fail short of a catastrophic memory subsystem failure.

In that case, A73 can start retiring instructions ahead of the incomplete load, secure in the knowledge that the results it’s committing early won’t have to be thrown out. However, A73 can’t do so past an incomplete branch because it doesn’t know if it predicted that branch correctly. A branch mispredict doesn’t require any attention from software, but the core needs to preserve results from instructions before the branch in order to recover. Therefore, Henry Wong’s methodology can be modified for A73 by adding a branch dependent on the cache miss. To keep mispredictions from influencing results, the branch is never taken.
Working with a Shoestring Power and Area Budget
This modified methodology shows substantial shrinks to most core stuctures compared to A73’s predecessors.

Register Files
On A57, register file entries were 32 bits wide to make register file storage go as far as possible. I suspect those early 64-bit Arm cores were expected to handle a lot of 32-bit code, and wasting the upper half of a 64-bit register wasn’t ideal. 64-bit integer registers and 128-bit vectors were handled by allocating multiple 32-bit registers. A72 made register file entries 64-bits wide and improved FMA performance, which would require more register file storage and more ports.
Register file area is mostly limited by the width and number of access ports, and not so much the number of storage cells per entry
Kai Troester, AMD at Hot Chips 2023
A73 ditches that approach in favor of separate integer and floating point register files. The integer register file has 64-bit entries, with 41 available for speculative results. FP/vector registers are 128-bits wide, with 38 entries available for speculative results. Dedicated register files allow lower port counts from each register file. When building Zen 4’s FP/vector register file, AMD was able to use 512-bit entries with minimal area growth because port count and width had a larger influence register file area than the width of each entry. Arm likely made a similar observation with A73. A unified register file with small entries would make the most of storage cell capacity, but that was the wrong way to go for area efficiency. It was probably the wrong way to go for power efficiency too.

Cortex A72 had a comparatively high number of execution ports, all of which required inputs from one register file. Certainly there are techniques to prevent power and area from exploding like using two duplicate copies of the register file to increase read port count, but it’s impossible figure out details like that from software.
Besides being more area efficient, A73’s register file setup can give it an advantage in vector code. 35 vector register file entries are available for 128-bit results, compared to 31 on A72. A73’s advantage should be even more significant in practice because scalar integer and vector operations won’t contend for capacity in the same register file.
However, A73 can’t perfectly allocate all entries across both register files, and caps out at 66 in-flight instructions with an even mix of operations that write to scalar and vector registers. Other CPUs have similar limitations. Intel CPUs have a “Physical Register Reclaim Table” that tracks which register should be freed when an instruction retires. Lack of entries in that structure can cause a stall before all register file entries are exhausted. A73 may have a similar structure.
Memory Accesses, and Branches?
A73 can have 50 in-flight loads, which is massive compared to its other structures. In fact, 50 in-flight loads can only be achieved by using both integer and vector destination registers. Otherwise, reordering capacity will be limited by how much register file capacity you can reserve to hold loaded data. This is a substantial improvement over A72’s 32 entry load queue, and is unlikely to be a relevant limitation in practice.
Stores are a different story. Cortex A73 can only have 11 in-flight stores after an unresolved branch, a regression from A72’s already small 15 entry store queue. Curiously, independent branches appear to share the same 11 entry resource. If this resource fills, subsequent branches can’t get into the core even if scheduler capacity is available. That creates a funny situation where A73 can have more incomplete branches in flight than complete ones.

Perhaps stores and branches need to reserve at least one slot in some kind of 11 entry verification queue. If a slot isn’t available, the incoming instruction can’t enter the backend even if a scheduler entry is free. Branches and stores both need extra care before their results can be committed. Branches can be mispredicted. Committing a store means writing its data to cache, making it visible to other cores. Whatever the case, this 11 entry buffer is likely a very hot structure. Capacity is low even if it’s only used by stores. Branches will further increase pressure on those 11 entries.
Memory Ordering Woes
Stores cause another problem for A73 besides taking up valuable space in a small structure. A73 doesn’t have a way to speculate whether a load will be dependent on a prior in-flight store. That means loads can’t be executed until all prior store addresses are known.
Memory dependence prediction isn’t new. Intel’s first implementation was in the 2006-era Core 2, while AMD did so in 2011 with Bulldozer. It’s a huge advantage because most loads don’t overlap with a prior store. Loads that miss cache are among the highest latency instructions a CPU will have to deal with. A73’s inability to do memory dependence speculation will cause loads to be delayed even when that delay isn’t needed to ensure memory operations execute in the right order. That in turn will put more pressure on the core’s limited reordering capacity.
No ROB-Like Structure?
Most out-of-order CPUs use a reorder buffer (ROB) to ensure in-order retirement. The ROB is a list of in-flight instructions being tracked in the backend, and is kept in program order. Reordering capacity can be capped by the ROB’s size if no other resources are exhausted first.
A73 doesn’t appear to have such a structure. NOPs are a good way of finding ROB capacity because they don’t take space in the register file, load/store queues, or other more specific resources. They’re just an instruction that does nothing, taking up a ROB slot. But NOPs have basically infinite reordering capacity even past an unresolved branch.
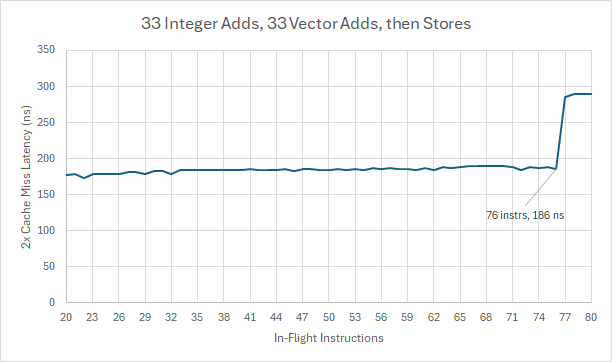
I also extended Henry Wong’s technique of combining in-flight writes to the integer and FP register files by mixing stores in. At that point, A73 can track 76 in-flight instructions, showing that I’m not hitting a reordering capacity limit even when maxing out three separate underlying resources. There’s a practical limit of about 76 instructions with the store queue and register files utilized to their maximum capacity.
Final Words
Out-of-order retirement is part of Arm’s strategy to maintain good performance with smaller core structures. In a sense, it’s goal is similar to that of Skymont’s 16-wide retire stage. Both cores are trying to deallocate resources faster, letting them achieve a certain level of performance with smaller internal core structures. As mentioned in the prior article, that makes A73 a fascinating architecture.

But when A73 has to lean on its core structures, it’s often at a disadvantage compared to A72 or A57. The question then is whether out-of-order retirement is effective enough to keep A73’s performance competitive. Certainly in some cases, A73’s strategy works well and gets it very close to A57. That’s an impressive feat considering how much smaller A73’s structures are in certain places. libx264 encoding is an example of this. Other cases aren’t so clear though, and file compression is a counterexample.

But IPC is only part of the picture. It’s all too easy to tunnel vision on IPC and lose sight of the forest. Clock speed matters, and A73’s lower power draw lets it reach higher clock speeds than A57. The Amlogic S922’s four A73 cores run at 2.2 GHz and can stay there with passive cooling. The Tegra X1’s four A57 cores run at 1.8 GHz, and don’t go faster even though the Nintendo Switch has active cooling.

Thus A73 is able to provide comparable performance at lower power. It does so by running a smaller, narrower core at higher clocks. A73 is a reminder that building a higher IPC architecture is not always the best way to go. The same applies to targeting higher clock speeds. Both strategies can do well, and both can fail depending on how well engineers balance the core for the applications it has to serve.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.